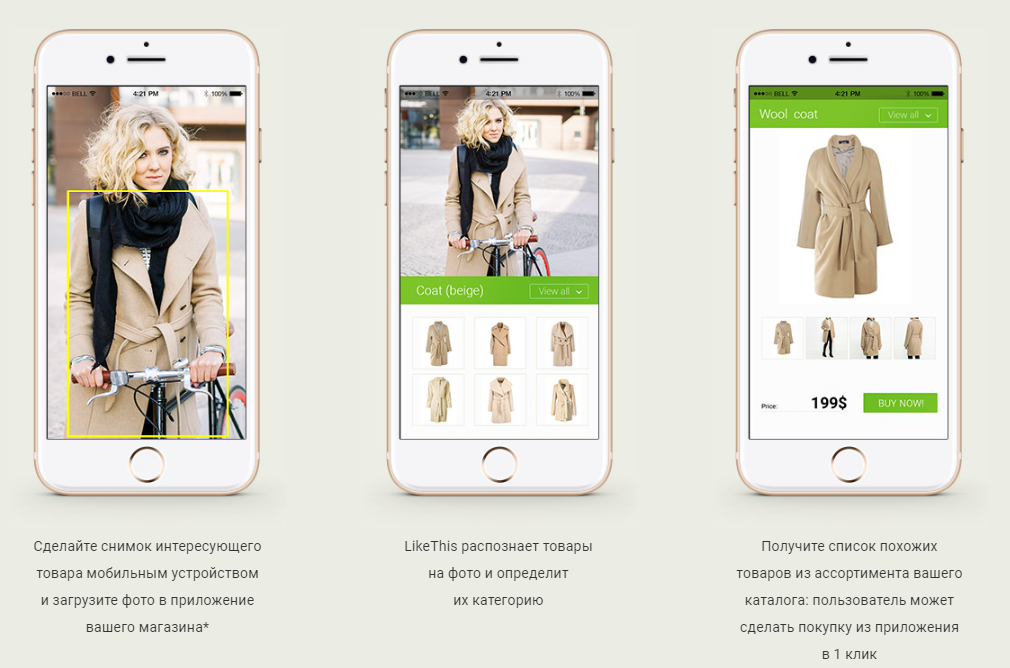
Neste artigo, quero falar sobre como criamos um sistema de pesquisa de roupas semelhantes (mais precisamente roupas, sapatos e bolsas) a partir de fotografias. Ou seja, em termos comerciais, um serviço de recomendação baseado em redes neurais.
Como a maioria das soluções de TI modernas, podemos comparar o desenvolvimento do nosso sistema com o conjunto do construtor Lego, quando tomamos muitos pequenos detalhes, instruções e criamos um modelo pronto a partir disso. Aqui está uma instrução: quais detalhes levar e como aplicá-los para que sua GPU possa selecionar produtos similares de uma fotografia, você encontrará neste artigo.
De que partes nosso sistema é construído:
- detector e classificador de roupas, sapatos e bolsas em imagens;
- rastreador, indexador ou módulo para trabalhar com catálogos eletrônicos de lojas;
- módulo de busca de imagens semelhantes;
- API JSON para interação conveniente com qualquer dispositivo e serviço;
- interface da web ou aplicativo móvel para visualizar os resultados.
No final do artigo, descreveremos todos os “ancinhos” que adotamos durante o desenvolvimento e recomendações sobre como neutralizá-los.
Declaração do problema e criação do rubricador
A tarefa e o principal caso de uso do sistema parecem bastante simples e claros:
- o usuário envia para a entrada (por exemplo, por meio de um aplicativo móvel) uma fotografia na qual existem artigos de vestuário e / ou bolsas e / ou sapatos;
- o sistema determina (detecta) todos esses objetos;
- encontra para cada um deles os produtos mais relevantes (relevantes) em lojas on-line reais;
- dá ao usuário produtos com a capacidade de acessar uma página específica do produto para compra.
Simplificando, o objetivo do nosso sistema é responder à famosa pergunta: "E você não tem o mesmo, apenas com botões de madrepérola?"
Antes de avançar para o conjunto de codificação, marcação e treinamento de redes neurais, você precisa determinar claramente as categorias que estarão dentro do seu sistema, ou seja, aquelas que a rede neural detectará. É importante entender que quanto mais ampla e detalhada a lista de categorias, mais universal ela é, pois um grande número de categorias pequenas e estreitas, como minivestido, midi-dress, maxi-dress, sempre pode ser combinado com um toque em uma categoria do tipo de vestido MAS NÃO vice-versa. Em outras palavras, o rubricador precisa ser bem pensado e compilado no início do projeto, para não refazer o mesmo trabalho três vezes depois. Compilamos o rubricador, baseando-se em várias lojas grandes, como Lamoda.ru, Amazon.com, e tentamos torná-lo o mais amplo possível, por um lado, e o mais versátil possível, por outro, para facilitar a associação de categorias de detectores a diferentes categorias no futuro. lojas on-line (falarei mais sobre como criar esse grupo na seção rastreador e indexador). Aqui está um exemplo do que aconteceu.
 Categorias de exemplo
Categorias de exemploNo momento, em nosso catálogo, existem apenas 205 categorias: roupas femininas, roupas masculinas, sapatos femininos, sapatos masculinos, bolsas, roupas para recém-nascidos. A versão completa do nosso classificador está disponível
no link .
Indexador ou módulo para trabalhar com catálogos eletrônicos de lojas
Para procurar produtos similares no futuro, precisamos criar uma base extensa do que procuraremos. Em nossa experiência, a qualidade da pesquisa de imagens semelhantes depende diretamente do tamanho da base de pesquisa, que deve exceder pelo menos 100 mil imagens e, de preferência, 1 milhão de imagens. Se você adicionar 1-2 pequenas lojas online ao banco de dados, provavelmente não obterá resultados impressionantes simplesmente porque em 80% dos casos não há nada realmente semelhante ao item desejado no seu catálogo.
Portanto, para criar um grande banco de dados de imagens, você precisa processar catálogos de várias lojas online, e é isso que este processo inclui:
- Primeiro, você precisa encontrar os feeds XML das lojas on-line, geralmente você pode encontrá-los disponíveis gratuitamente na Internet, ou solicitando na própria loja ou em vários agregadores, como o Admitad;
- o feed é processado (analisado) por um programa especial - um rastreador, que baixa todas as imagens do feed, as coloca no disco rígido (mais precisamente, no armazenamento de rede ao qual o servidor está conectado), grava todas as meta-informações sobre os produtos no banco de dados;
- então, outro processo é iniciado - o indexador, que calcula vetores binários de 128 dimensões dimensionais para cada imagem. Você pode combinar o rastreador e o indexador em um módulo ou programa, mas historicamente desenvolvemos que esses eram processos diferentes. Isso ocorreu principalmente devido ao fato de inicialmente calcularmos descritores (hashes) para cada imagem distribuída em uma grande frota de máquinas, pois esse era um processo que consumia muitos recursos. Se você trabalha apenas com redes neurais, a primeira máquina com uma GPU é suficiente para você;
- vetores binários são gravados no banco de dados, todos os processos são concluídos e pronto - o banco de dados do seu produto está pronto para pesquisas adicionais;
- mas ainda resta um pequeno truque: como todas as lojas possuem catálogos diferentes com categorias diferentes, é necessário comparar as categorias de todos os feeds contidos no banco de dados com as categorias do detector (mais precisamente, o classificador) de mercadorias, que chamamos de processo de mapeamento. Essa é uma rotina manual, mas um trabalho muito útil, durante o qual o operador, editando manualmente um arquivo XML comum, compara as categorias de feeds no banco de dados com as categorias do detector. Aqui está o resultado:
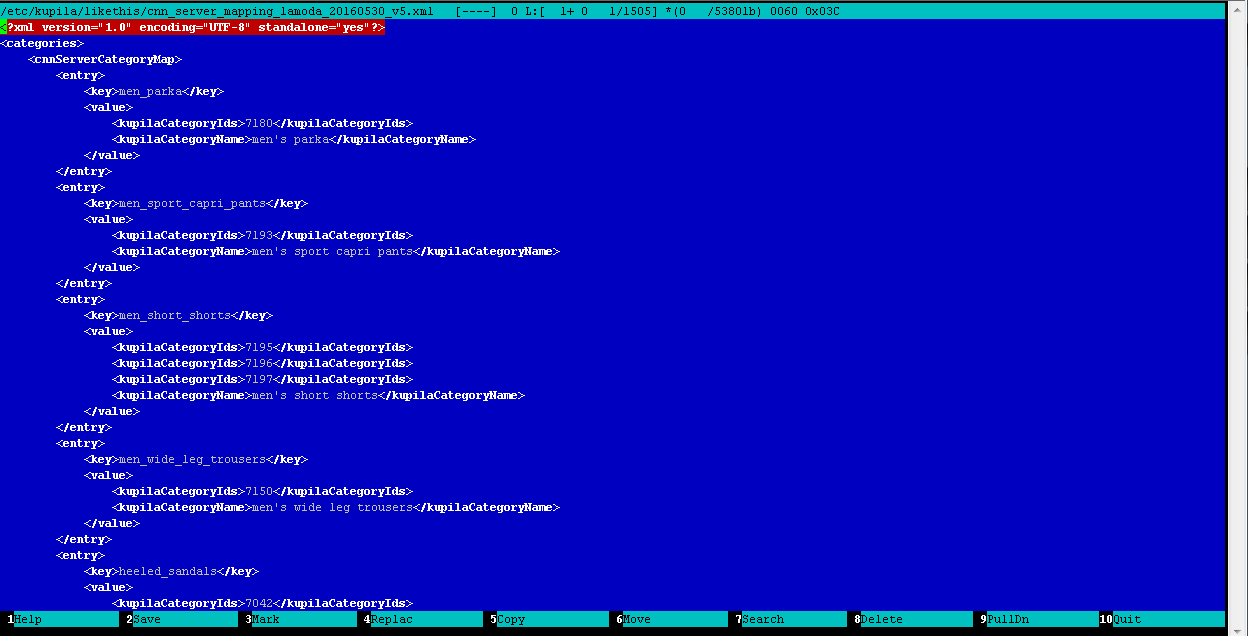 Exemplo de arquivo de mapeamento de categoria: catalogador-classificador
Exemplo de arquivo de mapeamento de categoria: catalogador-classificadorDetecção e classificação
Para encontrar algo semelhante ao que nossos olhos encontraram na foto, precisamos detectar esse "algo" primeiro (ou seja, localizar e selecionar o objeto). Percorremos um longo caminho na criação de um detector, começando pelo treinamento em cascatas OpenCV que não funcionavam para essa tarefa e terminando com a tecnologia moderna para detectar e classificar o
R-FCN e o classificador com base na rede neural
ResNet .
Como os dados usados para treinamento e teste (os chamados exemplos de treinamento e teste), tiramos todos os tipos de imagens da Internet:
- pesquise imagens do Google / Yandex;
- conjuntos de dados marcados por terceiros;
- redes sociais;
- sites de revistas de moda;
- Lojas na Internet de roupas, sapatos, bolsas.
A marcação foi realizada usando uma ferramenta samopisny, o resultado da marcação foram conjuntos de imagens e arquivos * .seg, que armazenam as coordenadas dos objetos e os rótulos das classes. Em média, de 100 a 200 imagens foram rotuladas para cada categoria, o número total de imagens em 205 classes foi de 65.000.
Depois que as amostras de treinamento e teste estiverem prontas, fizemos uma verificação dupla da marcação, fornecendo todas as imagens para outro operador. Isso nos permitiu filtrar um grande número de erros que afetam fortemente a qualidade do treinamento da rede neural, ou seja, o detector e o classificador. Começamos a treinar a rede neural usando ferramentas padrão e "decolamos" o próximo instantâneo da rede neural "no calor do dia" em alguns dias. Em média, o tempo de treinamento do detector e classificador no volume de dados de 65.000 imagens em uma GPU Titan X é de cerca de 3 dias.
Uma rede neural pronta deve, de alguma forma, ser verificada quanto à qualidade, ou seja, para avaliar se a versão atual da rede se tornou melhor que a anterior e por quanto. Como fizemos:
- a amostra de teste consistia em 12.000 imagens e foi apresentada exatamente da mesma maneira que o treinamento;
- escrevemos uma pequena ferramenta que executou toda a amostra de teste no detector e compilamos uma tabela desse tipo (a versão completa da tabela está disponível aqui );
- essa tabela é adicionada ao Excel em uma nova guia e comparada com a anterior manualmente ou usando as fórmulas internas do Excel;
- na saída, obtemos os indicadores gerais do detector e classificador TPR / FPR em todo o sistema em e para cada categoria separadamente.
 Exemplo de uma tabela de relatório sobre a qualidade do detector e classificador
Exemplo de uma tabela de relatório sobre a qualidade do detector e classificadorMódulo de Pesquisa de Imagens Similares
Depois de detectarmos os itens de vestuário na fotografia, iniciamos o mecanismo de busca de imagens semelhantes, eis como funciona:
- para todos os fragmentos de imagem cortada (produtos detectados), os vetores de recursos binários da rede neural de 128 bits são calculados em forma e cor (de onde vêm, veja abaixo);
- os mesmos vetores calculados anteriormente no estágio de indexação para todas as imagens de mercadorias armazenadas no banco de dados já estão carregados na RAM do computador (já que para pesquisar por similares, será necessário fazer um grande número de pesquisas e comparações aos pares, carregamos o banco de dados inteiro imediatamente na memória, o que nos permitiu aumentar a velocidade de pesquisa é dezenas de vezes, enquanto a base de cerca de 100 mil produtos não cabe mais que 2-3 GB de RAM);
- os coeficientes de pesquisa para essa categoria vêm da interface ou das propriedades codificadas, por exemplo, na categoria "vestido", pesquisamos mais em cores do que em forma (por exemplo, pesquisa de forma de cor 8 a 2) e na categoria "sapatos de salto alto" Cor de forma 1 para 1, pois forma e cor são igualmente importantes aqui;
- Além disso, os vetores da colheita (fragmentos) da imagem de entrada são comparados em pares com a imagem do banco de dados, levando em consideração os coeficientes (a distância de Hamming entre os vetores é comparada);
- como resultado, uma matriz de produtos similares do banco de dados é formada para cada fragmento de produto cortado e um peso é atribuído a cada produto (de acordo com uma fórmula simples, levando em consideração a normalização, de modo que todos os pesos estejam na faixa de 0 a 1) para a possibilidade de saída para a interface, bem como para mais informações. triagem;
- uma matriz de produtos similares é exibida na interface via web-JSON-API.
As redes neurais para a formação de vetores de redes neurais em forma e cor são treinadas da seguinte maneira.
- Para treinar a rede neural, tiramos todas as imagens marcadas, recortamos os fragmentos de acordo com a marcação e os distribuímos em pastas de acordo com a classe: ou seja, todos os suéteres em uma pasta, todas as camisetas em outra e todos os sapatos de salto alto na terceira, etc. d. Em seguida, treinamos um classificador comum com base nesta amostra. Assim, meio que “explicamos” para a rede neural nossa compreensão da forma do objeto.
- Para treinar a rede neural em cores, pegamos todas as imagens marcadas, recortamos os fragmentos de acordo com a marcação e os distribuímos em pastas de acordo com a cor: ou seja, colocamos todas as camisetas, sapatos, bolsas etc. na pasta "verde". cor verde (como resultado, todos os objetos de cor verde geralmente se acumulam em uma pasta), na pasta “despojado” colocamos todas as coisas em uma tira e na pasta “vermelho-branco” todas as coisas vermelho-branco. Em seguida, treinamos um classificador separado para essas classes, como se “explicasse” à rede neural sua compreensão da cor de uma coisa.
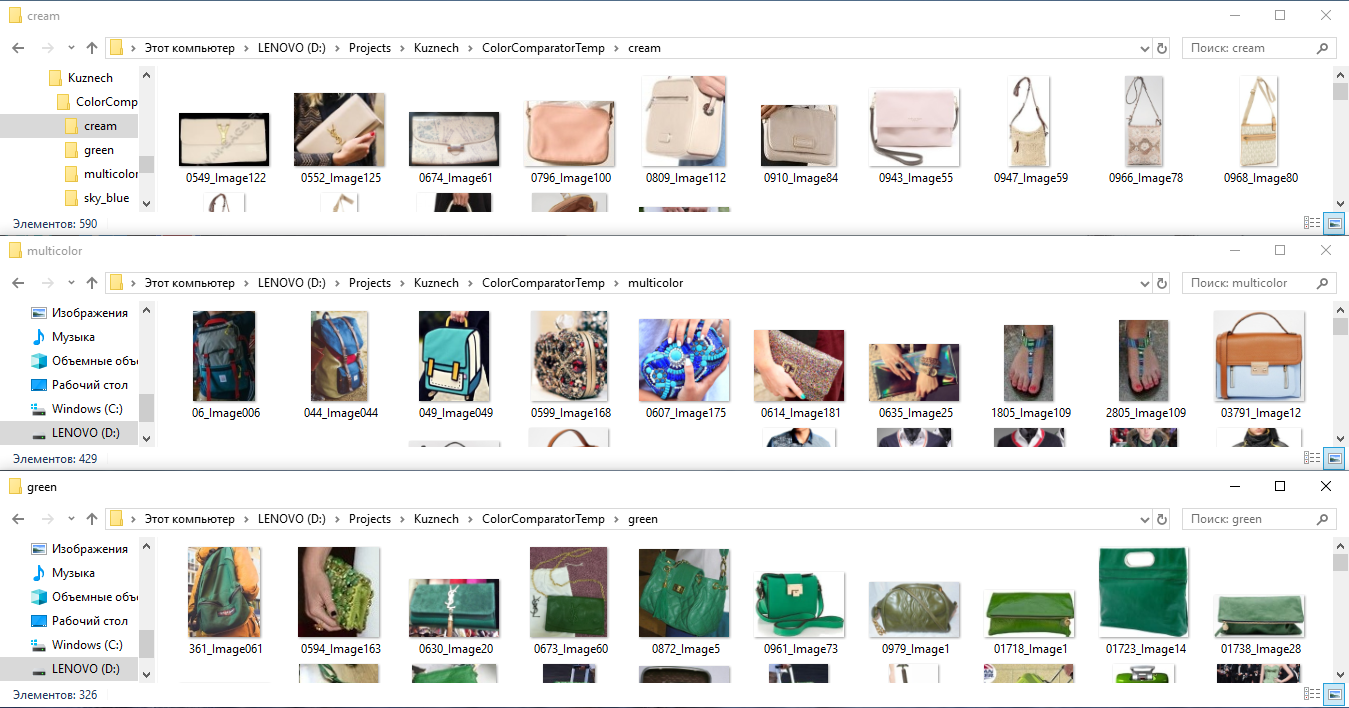 Um exemplo de marcação de imagens por cor para obter vetores de redes neurais de sinais por cor.
Um exemplo de marcação de imagens por cor para obter vetores de redes neurais de sinais por cor.Curiosamente, essa tecnologia funciona bem mesmo em fundos complexos, isto é, quando fragmentos de coisas são cortados não claramente ao longo do contorno (máscara), mas ao longo de uma moldura retangular que o marcador definiu.
A busca de similares é baseada na extração de vetores de características binárias da rede neural, desta maneira: a saída da penúltima camada é obtida, compactada, normalizada e binarizada. Em nosso trabalho, compactamos em um vetor de 128 bits. Você pode fazê-lo de maneira um pouco diferente, por exemplo, conforme descrito no artigo do Yahoo, “
Deep Learning of Binary Hash Codes for Fast Image Retrieval ”, mas a essência de todos os algoritmos é a mesma: imagens semelhantes à imagem são pesquisadas comparando-se as propriedades que a rede neural opera dentro das camadas.
Inicialmente, como uma tecnologia para procurar imagens semelhantes, usamos hashes ou descritores de imagem com base em (mais precisamente calculados) certos algoritmos matemáticos, como o operador Sobel (ou contorno), o algoritmo SIFT (ou pontos singulares), construindo um histograma ou comparando o número de ângulos em uma imagem . Essa tecnologia funcionou e deu um resultado mais ou menos sadio, mas os hashes não se comparam à tecnologia de busca de imagens semelhantes com base nas propriedades alocadas por uma rede neural. Se você tentar explicar a diferença em duas palavras, o algoritmo de comparação de imagens com base em hash é uma “calculadora” configurada para comparar imagens usando alguma fórmula e funciona continuamente. Uma comparação usando recursos de uma rede neural é "inteligência artificial", treinada por uma pessoa para resolver um problema específico de uma certa maneira. Você pode dar um exemplo tão grosseiro: se você procurar suéteres com listras em preto e branco, provavelmente encontrará todas as coisas em preto e branco como semelhantes. E se você pesquisar usando uma rede neural, então:
- em primeiro lugar, você encontrará todos os suéteres com listras preto e branco,
- então todos os suéteres preto e branco
- e depois todos os suéteres listrados.
API JSON para interação conveniente com qualquer dispositivo e serviço
Criamos uma WEB-JSON-API simples e conveniente para comunicar nosso sistema com quaisquer dispositivos e sistemas, o que, obviamente, não é uma inovação, mas um bom padrão de desenvolvimento forte.
Interface da Web ou aplicativo móvel para visualizar resultados
Para verificar visualmente os resultados, bem como demonstrar o sistema para os clientes, desenvolvemos interfaces simples:
Erros que foram confirmados no projeto
- Inicialmente, é necessário definir com mais clareza a tarefa e, com base na tarefa, selecionar fotografias para o layout. Se você precisar pesquisar fotos UGC (Conteúdo Gerado pelo Usuário) - este é um caso e exemplos de layout. Se você precisar de uma pesquisa de fotos em revistas brilhantes, esse é um caso diferente e, se você precisar de uma pesquisa de fotos em que um objeto grande esteja localizado em um fundo branco, essa é uma história separada e uma amostra completamente diferente. Misturamos tudo em uma pilha, o que afetou a qualidade do detector e classificador.
- Nas fotografias, você deve sempre marcar TODOS os objetos, pelo menos pelo menos de alguma maneira se adequa à sua tarefa, por exemplo, ao escolher uma seleção de guarda-roupa semelhante, você deve marcar imediatamente todos os acessórios (miçangas, óculos, pulseiras etc.), cabeça chapéus, etc. Porque agora que temos um grande conjunto de treinamento, para adicionar outra categoria, precisamos redistribuir TODAS as fotos, e esse é um trabalho muito volumoso.
- Provavelmente, a detecção é melhor realizada com uma rede de máscaras, a transição para a Mask-CNN e uma solução moderna baseada em Detectron é uma das áreas do desenvolvimento do sistema.
- Seria bom decidir imediatamente como você determinará a qualidade da seleção de imagens semelhantes - existem 2 métodos: "a olho" e este é o método mais simples e barato e o 2º - método "científico", quando você coleta dados de "especialistas" (pessoas, que estou testando seu algoritmo de pesquisa semelhante) e com base nesses dados, forme uma amostra de teste e um catálogo especificamente para pesquisar imagens semelhantes. Este método é bom em teoria e parece bastante convincente (para você e para os clientes), mas, na prática, sua implementação é difícil e bastante cara.
Conclusão e outros planos de desenvolvimento
Essa tecnologia está pronta e adequada para uso, agora opera em um de nossos clientes na loja online como um serviço de recomendação. Recentemente, também começamos a desenvolver um sistema semelhante em outro setor (ou seja, agora estamos trabalhando com outros tipos de mercadorias).
De planos imediatos: a transferência da rede para o Mask-CNN, bem como a remarcação e a remarcação de imagens para melhorar a qualidade do detector e classificador.
Concluindo, quero dizer que, de acordo com nossos sentimentos, essa tecnologia e as redes neurais em geral são capazes de resolver até 80% das tarefas complexas e altamente intelectuais que nosso cérebro realiza diariamente. A única questão é quem é o primeiro a implementar essa tecnologia e a descarregar uma pessoa do trabalho rotineiro, liberando espaço para criatividade e desenvolvimento, que é, em nossa opinião, o maior objetivo do homem!
Referências