
Bom dia
Na prática real, você frequentemente encontra tarefas que estão longe de serem complexos algoritmos de ML, mas ao mesmo tempo não são menos importantes e urgentes para os negócios.
Vamos falar sobre um deles.
A tarefa se resume a distribuir (serrar, rasplitovat - o jargão da empresa é inesgotável) os dados de alguma tabela de destino com agregados (valores agregados) em uma tabela de granularidade mais detalhada.
Por exemplo, o departamento comercial precisa dividir o plano anual acordado no nível da marca - em detalhes para os produtos, para os profissionais de marketing dividirem o orçamento anual de marketing por país, o departamento de planejamento e econômico para dividir as despesas gerais de negócios por centros de responsabilidade financeira, etc. etc.
Se você acha que tarefas como essa já estão surgindo à sua frente no horizonte ou já está tratando as pessoas afetadas por essas tarefas, peço um gato.
Considere um exemplo real:
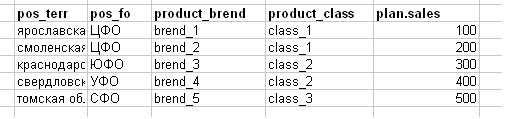
Eles reduzem o plano de vendas como uma tarefa, como na figura abaixo (intencionalmente simplifiquei o exemplo, na realidade - um banner de excel de 100 a 200 mb).
Explicação do título:
- pos-território (região) da tomada
- pos_fo - o distrito federal da tomada (por exemplo, o Distrito Federal Central - Distrito Federal Central)
- product_brend - marca do produto
- product_class - classe de produto
- plan.sales é um plano de vendas para qualquer coisa.
E eles pedem, por exemplo, para quebrar sua mega-mesa (no quadro do exemplo de nossos filhos, é claro que é mais modesto) - para o canal de vendas. Para a pergunta - de acordo com a lógica a ser desmembrada, recebo a resposta: “mas faça as estatísticas das vendas reais para o quarto trimestre desse e daquele ano, obtenha as partes reais dos canais em% para cada linha do plano e desmonte essas partes da linha do plano”.
De fato, esta é a resposta mais frequente em tais tarefas ...
Até agora, tudo parece bastante simples.
Eu entendo esse fato (veja a imagem abaixo):
- pos_channell - canal de vendas (atributo de destino do plano)
- fact.sales - vendas reais de algo.
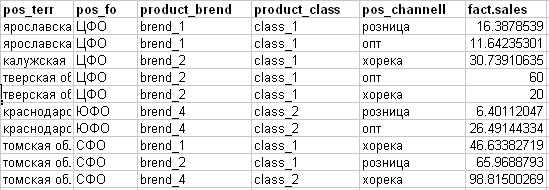
Com base na abordagem obtida para "serrar" no exemplo da primeira linha do plano, a detalharemos com base no fato de algo como isto:

No entanto, se compararmos o fato com o plano de toda a placa para entender se todas as linhas do plano podem ser adequadamente "cortadas" em compartilhamentos, obtemos a seguinte imagem: (verde - todos os atributos da linha do plano coincidem com o fato, as células amarelas não coincidem).
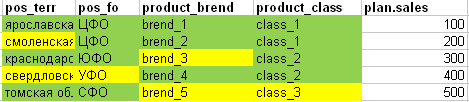
- Na 1ª linha do plano, todos os campos são completamente encontrados no fato.
- Na 2ª linha do plano, o território correspondente não foi encontrado no fato
- A terceira linha do plano não é suficiente no fato da marca
- A quarta linha do plano não é suficiente no fato de o território e o distrito federal
- A quinta linha do plano carece de fato da marca e da classe.
Como Panikovsky disse: "Vi o Shura, vi - eles são dourados ..."

Vou ao cliente comercial e esclareço o exemplo da 2ª linha, que tipo de abordagem ele vê para essas situações?
Eu recebo a resposta: "nos casos em que não é possível calcular a parcela de canais da marca número 2 na região de Smolensk (levando em conta o fato de termos a região de Smolensk no Distrito Federal Central - Distrito Federal Central) - então quebre essa linha de acordo com a estrutura dos canais em todo o Distrito Federal Central!"
Ou seja, para {Smolensk region + brand_2} agregamos o fato no nível do Distrito Federal Central e dividimos a região de Smolensk da seguinte forma:

Voltando e digerindo o que ouvi, tento generalizar para uma heurística mais universal:
Se não houver dados no nível atual de detalhes da tabela de fatos, antes de calcular os compartilhamentos para o campo de destino (canal de vendas), agregamos a tabela de fatos até o atributo de hierarquia acima.
Ou seja, se não for para o território, agregamos o fato a um nível hierárquico mais alto - ações para o mesmo Distrito Federal Central que o plano. Se não for a marca, na hierarquia acima há uma classe de produto - portanto, recontamos os compartilhamentos para a mesma classe e assim por diante.
I.e. combinamos o plano e o fato nos campos de acoplamento para os quais consideramos as ações no fato e a cada iteração de acordo com o plano não distribuído restante, reduzimos sucessivamente a composição dos campos de acoplamento.
Um certo padrão de distribuição de dados já está aparecendo aqui:
- Distribuímos o plano de fato com base na completa coincidência dos campos correspondentes
- Temos um plano quebrado (o acumulamos no resultado intermediário) e um plano contínuo (nem todas as linhas correspondem)
- Tomamos um plano ininterrupto e o dividimos de fato em um nível hierárquico mais alto (ou seja, abandonamos um determinado campo de acoplamento dessas 2 tabelas e agregamos o fato sem esse campo para calcular os compartilhamentos)
- Temos um plano quebrado (o adicionamos ao resultado intermediário) e um plano contínuo (nem todas as linhas correspondem)
- E repetimos os mesmos passos até que não haja um plano "não resolvido".
Em geral, ninguém nos obriga a remover consistentemente os campos de engate somente dentro da hierarquia. Por exemplo, já removemos a marca e o território dos campos de engate e distribuímos o plano restante por: product_class (hierarquia acima da marca) + Fed.krug (hierarquia acima do território). E ainda tem algum saldo não alocado do plano.
Além disso, podemos remover dos campos de acoplamento a classe do produto ou o distrito federal, conforme eles não estão mais incorporados na hierarquia um do outro.
Considerando que existem dezenas e linhas de campos nessas tabelas - até um milhão fazendo essas manipulações com as mãos - a tarefa não é a mais agradável.
E, considerando que tarefas desse tipo vêm a mim regularmente no final de cada ano (aprovação de orçamentos para o próximo ano no conselho de administração), você precisava traduzir esse processo em algum tipo de modelo universal flexível.
E como na maioria das vezes trabalho com dados por meio de R - a implementação é a mesma.
Primeiro, precisamos escrever uma função mágica universal que terá uma tabela base (tabela base) com dados para uma análise detalhada (em nosso exemplo, um plano) e uma tabela para calcular compartilhamentos (sharetab) com base na qual "veremos" os dados (em nosso exemplo, fato). Mas a função também deve entender o que precisa ser feito com esses objetos, para que a função ainda aceite o vetor de nomes de campo do acoplamento (merge.vrs) - ou seja, os campos que são nomeados de forma idêntica nas duas tabelas e nos permitem conectar uma tabela à outra com esses campos em que ela funciona (ou seja, associação correta). Além disso, a função deve entender qual coluna da tabela base deve ser levada para a distribuição (basetab.value) e com base em qual campo contar os compartilhamentos (sharetab.value). Bem, e mais importante - o que levar para o campo resultante (sharetab.targetvars), no nosso caso, queremos detalhar o plano através do canal de vendas a partir do fato.
A propósito, essa variável sharetab.targetvars não é aleatória no meu plural - pode não ser um campo, mas um vetor de nomes de campos, para casos em que você precisa adicionar não um campo à tabela base da tabela de compartilhamento, mas vários de uma vez (por exemplo, com base no fato, você não pode dividir o plano somente pelo canal de vendas, mas também pelo nome dos produtos incluídos na marca).
Sim, e mais uma condição :) minha função deve ser o mais local e legível possível, sem nenhum edifício de vários andares em 2 telas (eu realmente não gosto de grandes funções).
Na última condição, o popular pacote dplyr se encaixa o mais confortavelmente possível e, considerando que seus operadores de dutos devem entender os nomes textuais dos campos que foram reduzidos para a função, isso não poderia acontecer sem a
avaliação Standart .
Aqui está este bebê (sem contar os comentários internos):
fn_distr <- function(sharetab, sharetab.value, sharetab.targetvars, basetab, basetab.value, merge.vrs,level.txt=NA) { # sharetab - = # sharetab.value - - # sharetab.targetvars - - # basetab - = # basetab.value - # merge.vrs - 2- # level.txt - . ( merge.vrs) require(dplyr) sharetab.value <- as.name(sharetab.value) basetab.value <- as.name(basetab.value) if(is.na(level.txt )){level.txt <- paste0(merge.vrs,collapse = ",")} result <- sharetab %>% group_by(.dots = c(merge.vrs, sharetab.targetvars)) %>% summarise(sharetab.sum = sum(!!sharetab.value)) %>% ungroup %>% group_by(.dots = merge.vrs) %>% mutate(sharetab.share = sharetab.sum / sum(sharetab.sum)) %>% ungroup %>% right_join(y = basetab, by = merge.vrs) %>% mutate(distributed.result = !!basetab.value * sharetab.share, level = level.txt) %>% select(-sharetab.sum,-sharetab.share) return(result) }
Na saída, a função deve retornar data.frame da união de duas tabelas com as linhas do plano + fato onde foi possível dividir o plano na versão atual dos campos de acoplamento e com as linhas originais do plano (e fato vazio) nas linhas em que o plano não pôde ser dividido na iteração atual.
Ou seja, o resultado retornado pela função após a primeira iteração (quebrando a primeira linha do plano para a região de Yaroslavl) terá a seguinte aparência:
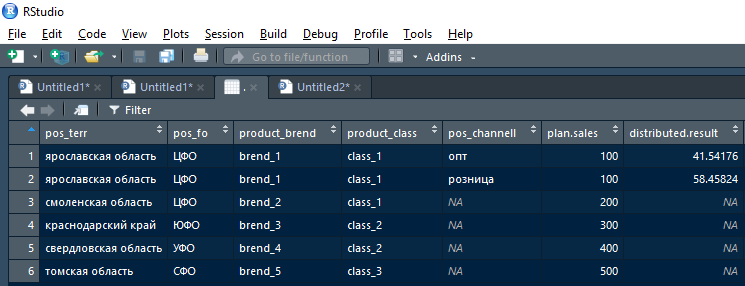
Além disso, esse resultado pode ser obtido pelo resultado distribuído não vazio no resultado cumulativo e pelo resultado distribuído vazio (NA) - enviado para a próxima iteração típica, mas dividido por compartilhamentos em um nível hierárquico mais alto.
Todo o charme e toda a comodidade é que o trabalho é realizado no mesmo tipo de bloco e em uma função universal, tudo o que é necessário em cada etapa (iteração) é corrigir o vetor merge.vrs e observar como a mágica faz todo esse trabalho tedioso para você:

Sim, eu quase esqueci uma pequena nuance: se algo der errado e no final tivermos um plano quebrado, que no total não será igual ao plano antes do colapso - será difícil rastrear em que iteração tudo deu errado.
Portanto, fornecemos a cada iteração uma soma de verificação:
(_)-(___ )-(___.)=0
Agora vamos tentar executar nosso exemplo através do modelo de distribuição e ver o que obtemos na saída.
Primeiro, obtenha os dados de origem:
library(dplyr) plan <- data_frame(pos_terr = c(" ", " ", " ", " ", " "), pos_fo = c("", "", "", "", ""), product_brend = c("brend_1", "brend_2", "brend_3", "brend_4", "brend_5"), product_class = c("class_1", "class_1", "class_2", "class_2", "class_3"), plan.sales = c(100, 200, 300, 400, 500)) fact <- data_frame(pos_terr = c(" ", " ", " ", " ", " "," ", " ", " ", " ", " "), pos_fo = c("", "","","", "", "", "", "", "", ""), product_brend = c("brend_1", "brend_1", "brend_2", "brend_2","brend_2", "brend_4", "brend_4", "brend_1", "brend_2", "brend_4"), product_class = c("class_1", "class_1", "class_1","class_1","class_1", "class_2", "class_2", "class_1", "class_1", "class_2"), pos_channell = c("", "", "","", "", "", "", "", "", ""), fact.sales = c(16.38, 11.64, 30.73,60, 20, 6.40, 26.49, 46.63, 65.96, 98.81)) </soure> ( ) . <source> plan.remain <- plan result.total <- data_frame()
1. Distribuímos por Terr, FD (distrito federal), marca, classe merge.fields <- c("pos_terr","pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) # - plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) # = cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 2. Distribuímos por pho, marca, classe (ou seja, abandonamos o território de fato)
2. Distribuímos por pho, marca, classe (ou seja, abandonamos o território de fato)A única diferença do primeiro bloco é que eles encurtaram um pouco o merge.fields removendo pos_terr nele
merge.fields <- c("pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
3. Distribua por pho, classe merge.fields <- c("pos_fo", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
4. Distribua por classe merge.fields <- c( "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 5. Distribuir pelo DF
5. Distribuir pelo DF merge.fields <- c( "pos_fo") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
Como você pode ver, não existe um plano "não serrado" e a aritmética do plano distribuído é igual ao plano original.

E aqui está o resultado com os canais de vendas (na coluna da direita, a função exibe para quais campos o acoplamento / agregação era, para que depois possamos entender de onde veio essa distribuição):

Só isso. O artigo não era muito pequeno, mas há mais texto explicativo que o próprio código.
Espero que essa abordagem flexível economize tempo e nervos não apenas para mim :-)
Obrigado pela atenção.