Os serviços devem ser escritos para que a funcionalidade mínima seja sempre mantida - mesmo que componentes críticos falhem. Ilya Sidorov, chefe de uma das equipes de desenvolvimento de produtos do back-end Yandex.Taxi, explicou em seu relatório como deixamos o usuário pedir um carro quando certas partes do sistema não funcionam e por que lógica ativamos as versões simplificadas do serviço.
É importante escrever não apenas serviços que funcionem bem, mas também serviços que funcionem bem.
"Estou muito feliz em ver todos vocês." Hoje vou falar sobre degradação graciosa. Se você procurá-lo no Yandex, provavelmente aprenderá como fazer seu site funcionar sem JS. Vou lhe contar um pouco sobre outra coisa. Sobre degradação graciosa em relação ao back-end.

Vamos começar com a definição. Como é na realidade?
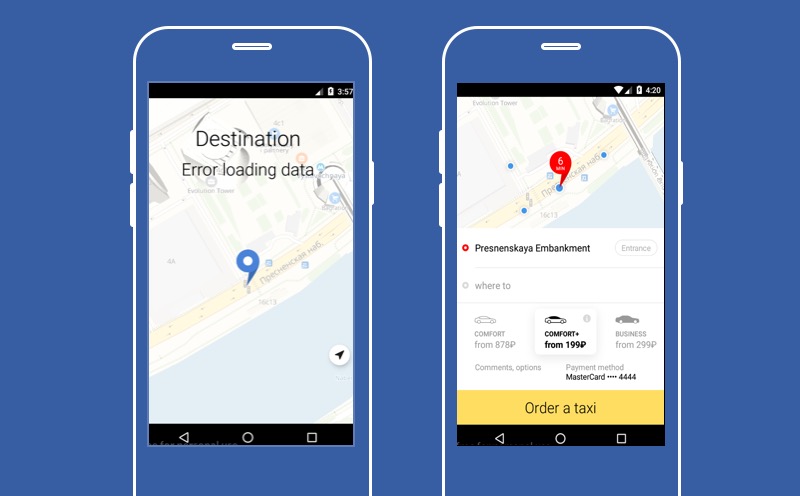
É aqui que nosso aplicativo Yandex.Taxi é apresentado caso um dos serviços não funcione - o serviço para escolher o destino para onde o motorista o levará. Como você pode ver, nesta tela não há um botão grande "Pedir um táxi", o que significa que o usuário não poderá usar o serviço. Mas você pode tentar degradar e permitir que o usuário não escolha o ponto B.
Então ele não conseguirá descobrir o preço exato da viagem, não poderemos construir uma rota, mas o usuário terá um botão "Solicitar um táxi" e poderá usar nosso serviço. A principal função do nosso aplicativo estará disponível. É sobre isso que quero falar hoje. Sobre como degradar corretamente e o que pode ser feito com um serviço que foi quebrado.
Plano de desempenho. Vou lhe dizer como degradar o que fazer com o serviço. Você pode desativá-lo e também usar um comportamento diferente. Depois, mostrarei como entender quando é hora de desligar nosso serviço. E no final, falarei sobre algumas nuances que tivemos que enfrentar ao criar um sistema de degradação automática para o Yandex.Taxi.
O que pode ser feito com um serviço que está quebrado? Você pode desativar a funcionalidade. Se o serviço de previsão de destinos individuais não funcionar, desative esse serviço. Se o bate-papo entre o motorista e o passageiro não funcionar, você o desligará. Se você não pode pedir um carro, desativa o botão "Encomendar um carro". Ah, não, isso não funciona. Nem todas as funcionalidades podem ser desativadas. E se você não pode desativar algo, precisa usar uma abordagem diferente. Por exemplo, você pode tentar criar um layout ou funcionalidade simplificada. Chamamos um comportamento tão simplificado em Yandex de abóbora - dizemos que o serviço se transformou em abóbora.
Vamos considerar essas soluções em mais detalhes.
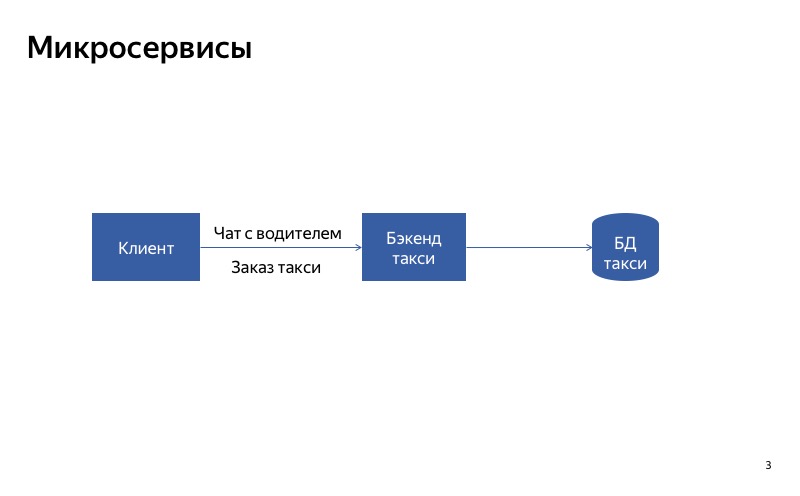
Como desativar serviços? Você provavelmente pode fazer a arquitetura certa. Suponha que tenhamos um serviço monolítico. Se uma de suas partes falhar, o serviço inteiro será interrompido. Mas se dividirmos o serviço em partes para que os clientes usem serviços diferentes para diferentes solicitações, ele se tornará muito melhor.
Como isso funcionará em um exemplo? Existe um serviço Yandex.Taxi, no qual existem duas funções principais: pedir um táxi e conversar com o motorista. Desde que tenhamos um back-end monolítico, se o bate-papo com o motorista falhar, a funcionalidade básica de pedir um táxi será afetada.
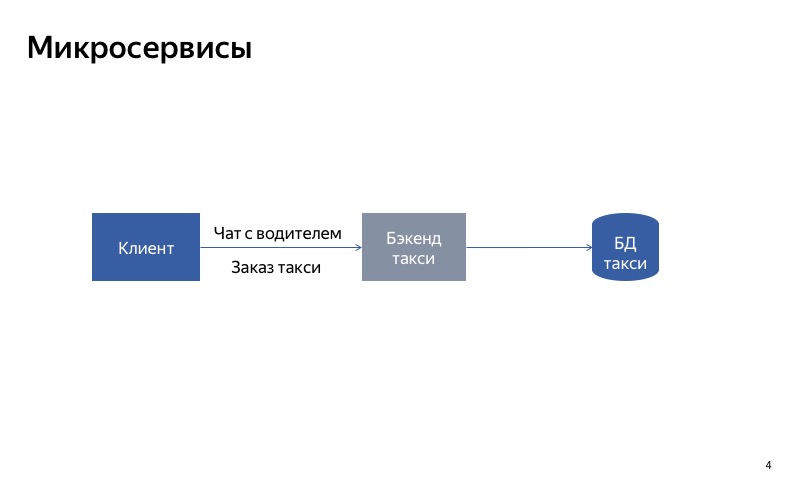
O que você pode tentar fazer? Divida o serviço monolítico em duas partes. Uma parte será responsável por pedir um táxi e a outra - pela comunicação com o motorista.
Agora tudo parece muito melhor. Se o bate-papo com o motorista for interrompido, todo o resto continuará funcionando corretamente.
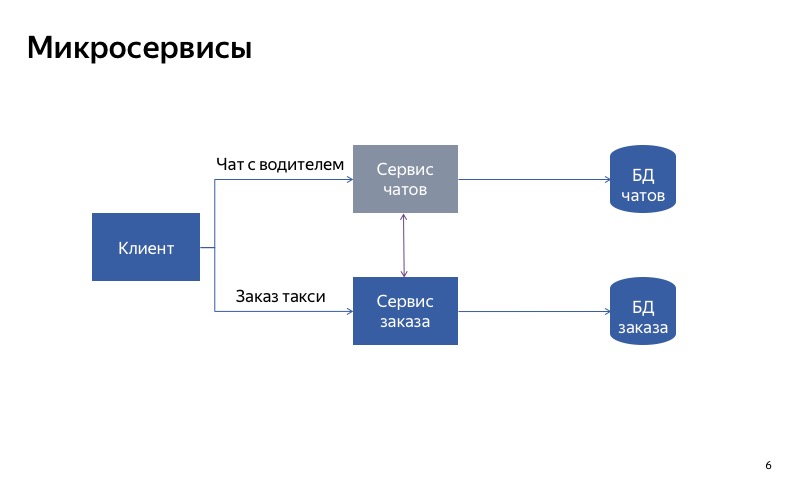
Como você pode ver, o cliente usa APIs diferentes, solicitações diferentes para fazer um pedido e se comunicar com o driver.
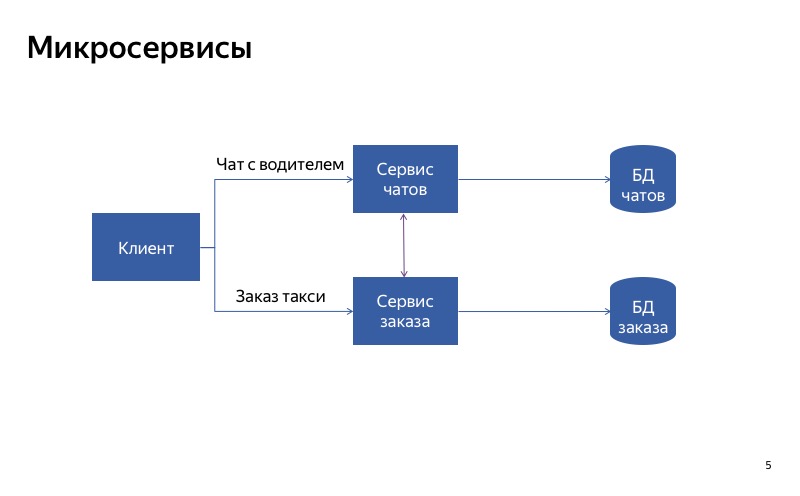
Mas, de fato, parece que agora tudo não está tão bem, porque há uma conexão espúria entre o serviço de bate-papo e o serviço de pedidos. E pode acontecer que o serviço de pedidos use um serviço de bate-papo ocioso. Nesse caso, a funcionalidade principal não funcionará.
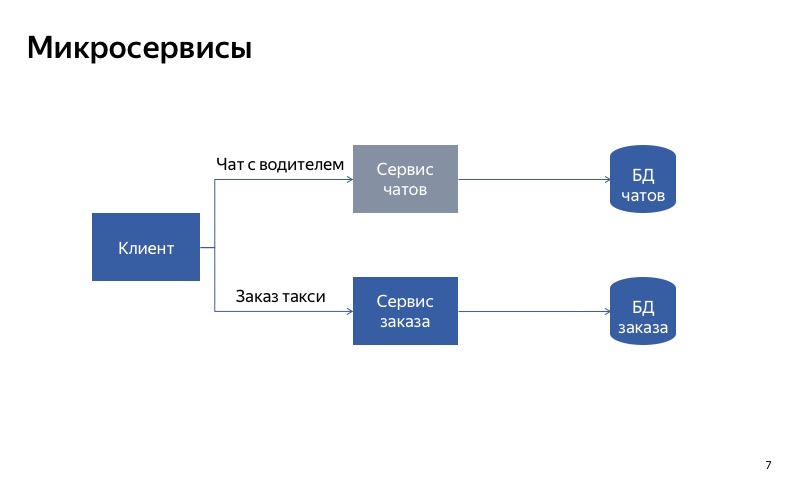
E, neste caso, tudo está muito melhor. A comunicação falsa desapareceu e agora nossos serviços são verdadeiramente independentes um do outro. Portanto, se o serviço de bate-papo falhar, você ainda pode pegar um táxi.
A conclusão é a seguinte: se você deseja degradar usando a separação de serviços, é muito importante tornar os serviços independentes um do outro. Isso significa que eles devem ter diferentes pontos de entrada, diferentes pontos de extremidade. Eles devem ter tempos de execução diferentes. E, é claro, eles devem usar bancos de dados diferentes. Caso contrário, um serviço quebrado pode interromper todos os outros serviços ao longo da cadeia.
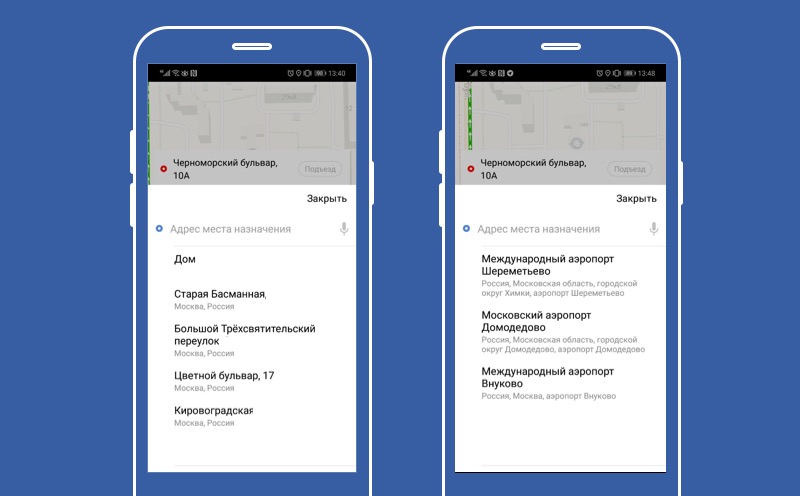
Bem, descobrimos como desativar a funcionalidade. Vamos agora ver como fazer a funcionalidade padrão, como fazer abóbora. Nesta tela, nosso serviço de previsão de destinos. O serviço usa IA inteligente para prever o usuário os melhores destinos para ele no momento. E se a IA estiver cansada, usamos o comportamento padrão e oferecemos ao usuário que saia de Moscou.
Vamos ver como isso funciona na prática.

Temos um cliente, ele entra em contato com o serviço de destino e recebe um erro.
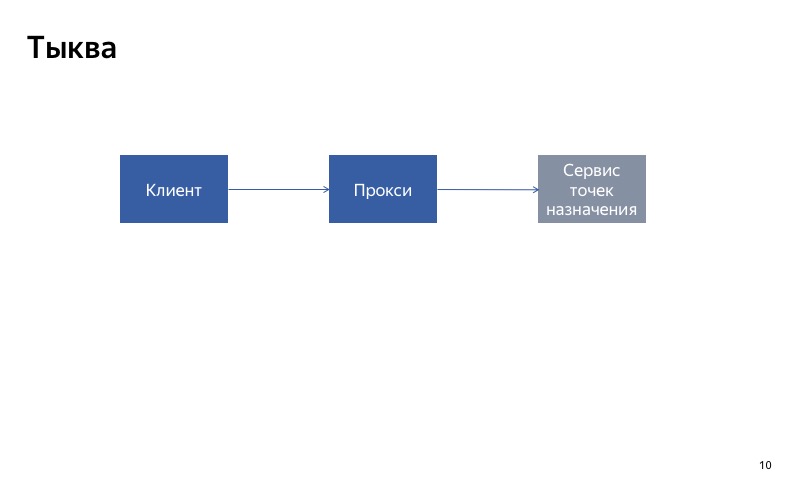
Agora duas situações são possíveis. A primeira situação, se a falha foi única, é apenas uma solicitação com falha. Nesse caso, apenas cometemos um erro no cliente, ele fará uma solicitação novamente e obterá seus destinos favoritos.
Mas se a falha for grande, ligamos a abóbora e o usuário obtém o comportamento padrão.

Mas esse comportamento de pele dura é muito mais fácil de implementar, e essa abóbora é muito confiável, por isso nos permite trabalhar mesmo quando a IA falha. Se soubermos que os usuários frequentemente viajam para os aeroportos, não perceberemos uma deterioração significativa na vida dos usuários.
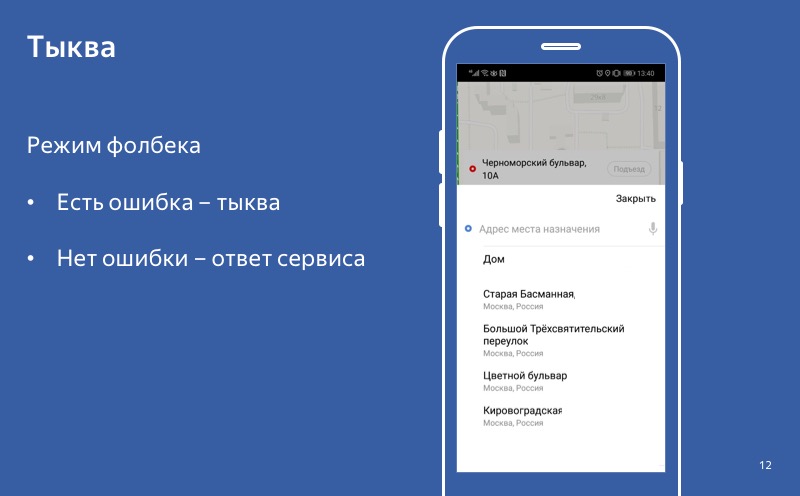
Mesmo que o modo de degradação esteja ativado, a abóbora está ligada, mas o usuário entra em contato com o serviço e recebe uma resposta bem-sucedida, então usamos essa resposta, não a abóbora. E esse comportamento - quando, no caso de uma resposta, a usamos, e no caso de um erro, usamos uma abóbora - chamamos o modo fallback.
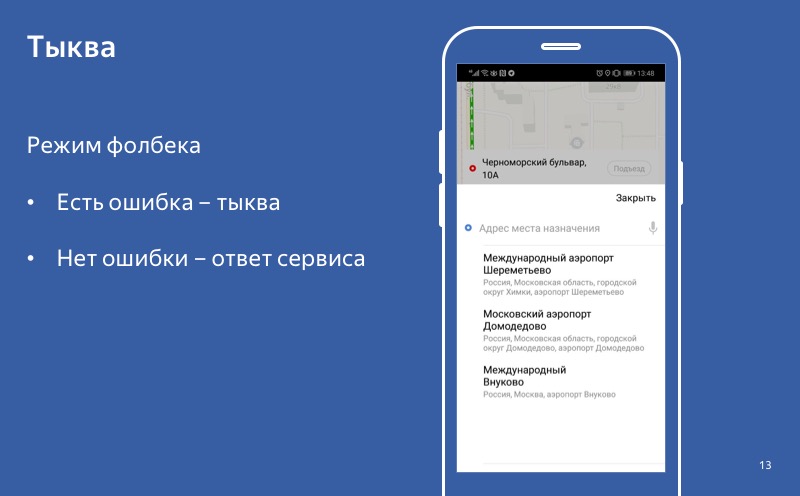
Sem erro - uma resposta bem-sucedida. Há um erro - uma abóbora. Dizemos que o fallback foi ativado.
Eu resolvi o que pode ser feito com um serviço que foi quebrado. Você pode desligá-lo ou ligar a abóbora. Vamos agora passar para a segunda parte e ver como diagnosticar.
Temos duas grandes perguntas que precisam ser respondidas. A primeira é quando você precisa desligar o serviço e ligar a abóbora. A segunda é quando você precisa desligar a abóbora e ligar novamente o serviço. Antes de podermos responder a essas perguntas, precisamos esclarecer um ponto.
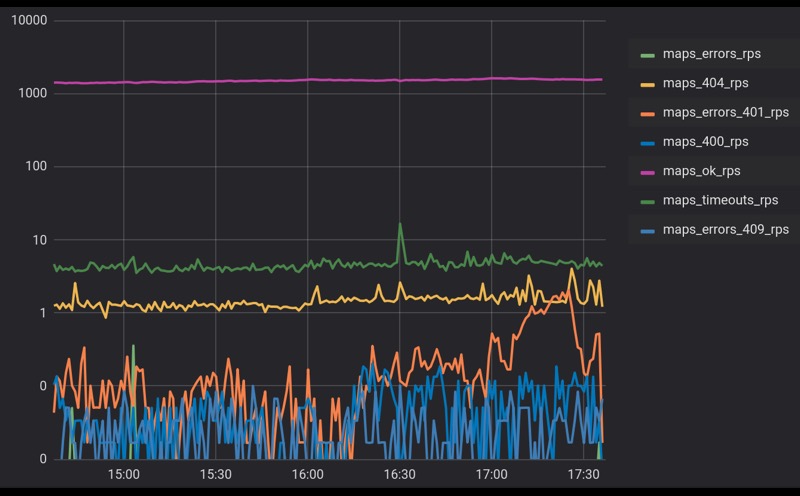
Em qualquer sistema complexo que interaja com um grande número de agentes, sempre há algum histórico de erros. Neste slide, vemos uma programação real de chamadas para um de nossos serviços. Vários milhares de RPS chegam a ele, temos um pouco menos de 1% de erros. Aqui está a escala logarítmica.
Erros podem ser causados por várias coisas. Talvez seja algum tipo de processo interno, atualizando algum tipo de banco de dados ou apenas processos em segundo plano. Talvez os clientes atendam às solicitações erradas, mas o fato permanece: sempre teremos um histórico de erros. Vamos pegar e seguir em frente.
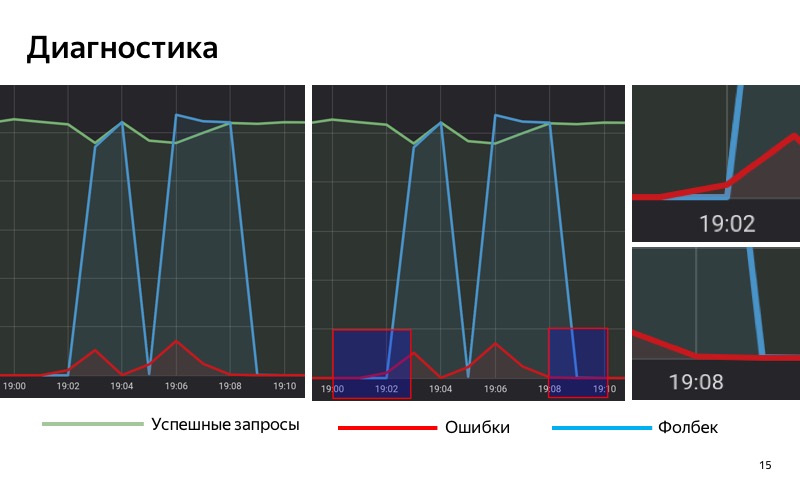
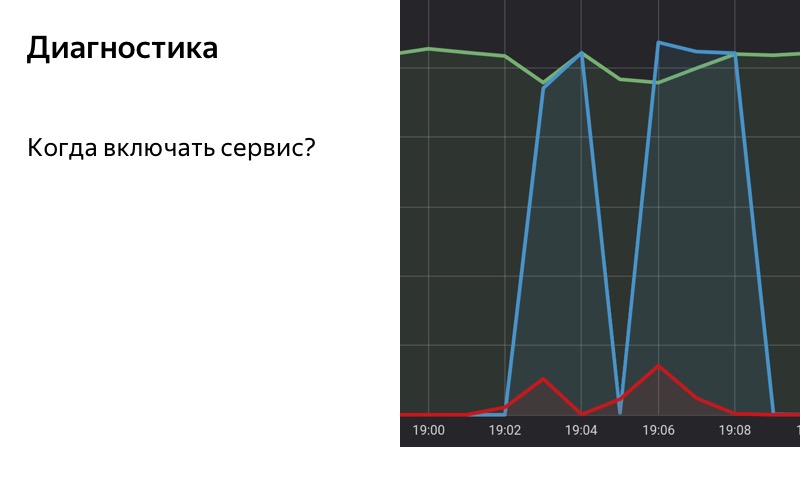
Então, usamos a solução com base em estatísticas. Temos um banco de dados especial no qual salvamos estatísticas, salvamos o número de consultas bem-sucedidas, o número de consultas com erros e as consultas para as quais o fallback foi incluído. Tomamos e acumulamos estatísticas de nosso serviço por um período de tempo com uma janela deslizante. Quando a proporção de solicitações com erros nessa janela deslizante excede um determinado limite, ativamos o fallback. E quando o número de erros se torna menor que o limite, nós o desativamos.
Preste atenção nas áreas selecionadas. Às 19:01, os primeiros erros começaram a aparecer, mas até agora a participação deles é muito pequena e, até 19:02, não incluímos fallback. Às 19:02, o limite foi excedido, ativamos o fallback. Às 19:08, o processo inverso: os erros foram encerrados, mas por algum tempo o fallback foi ativado, porque o limite ainda é excedido em nossa janela deslizante. Às 19:09, desativamos o fallback.
Nós descobrimos quando desligar o serviço. É necessário responder à segunda pergunta: quando ativá-la. É simples: usamos a mesma solução com base em estatísticas.
É importante não removermos a carga do serviço, mesmo se ativarmos o modo de degradação. É isso que nos permite continuar recebendo estatísticas, mesmo se mostrarmos uma abóbora ao usuário. Assim, podemos determinar que os erros terminaram, o serviço foi reparado. Assim, você pode ativá-lo novamente.
Quando falamos de degradação, não podemos dizer sobre monitoramento. Um bom monitoramento é metade do sucesso, a meio caminho do desligamento automático ou degradação automática. É importante entendermos que tipo de problemas acontecem com nosso serviço, qual a natureza dos erros e com que frequência eles ocorrem. E talvez no primeiro estágio nem precisamos de um disjuntor. Simplesmente, se a luz de monitoramento acender, podemos ligar e desligar o serviço manualmente. Quando a lâmpada de monitoramento se apaga, ligamos o serviço.
Se fizermos a degradação automática, uma troca automática, é importante fazer o monitoramento do fallback em si. Se o sistema de degradação funcionar bem o suficiente, os usuários, de fato, poderão não perceber que algo está quebrado em nós. Nós mesmos podemos, se não houver monitoramento, não notá-lo. É importante monitorar o fallback, é importante entender quando ele está ativado, quando está desativado, para que as estatísticas estejam disponíveis e possamos entender por quanto tempo a funcionalidade não funciona, se nosso back-end fica pior ou melhor com o tempo, dependendo de quanto tempo achamos que o fallback .
Tudo está com a parte principal.
No final, gostaria de dizer algumas nuances que tivemos que enfrentar quando desenvolvíamos um sistema de degradação automática no Yandex.Taxi.
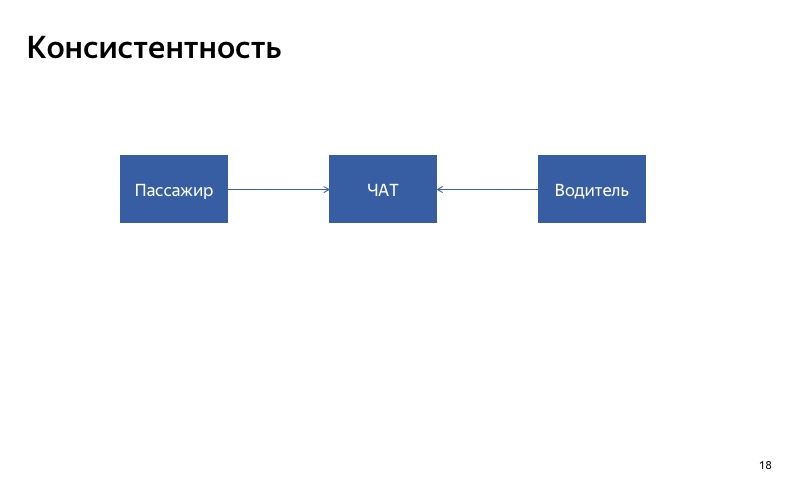
A primeira coisa que você deve prestar atenção é a consistência. Se você estiver degradando automaticamente um determinado serviço, é importante que o serviço responda consistentemente a todos os seus clientes. Se você tiver dois clientes que usam o serviço, é importante que as respostas para esses dois clientes em caso de degradação sejam consistentes. E se você tiver um serviço envolvido em algum processo demorado, precisará entender: talvez no início e no final do processo o serviço funcione corretamente e em algum lugar no meio do fallback esteja ativado.
Parece complicado, mas vamos tentar explicar com um exemplo. Talvez fique mais claro.
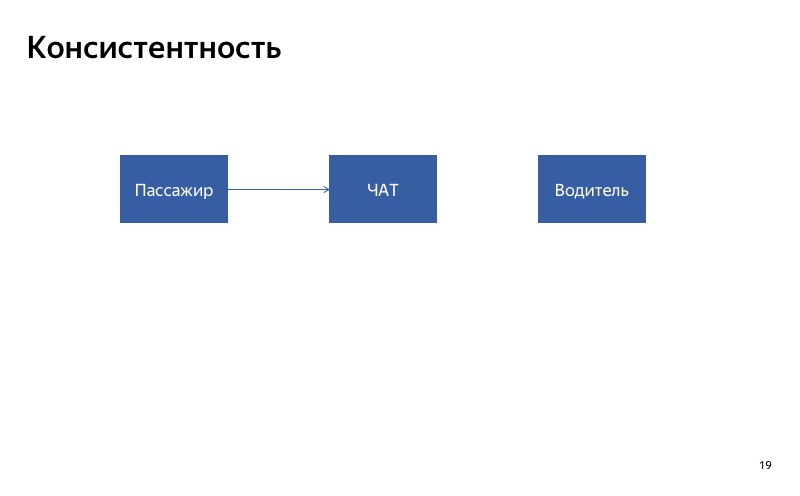
Aqui está o nosso bate-papo entre motorista e passageiro. A maneira mais fácil de degradá-lo é desativá-lo. Vamos imaginar que o bate-papo para o motorista esteja interrompido. O que vai acontecer? O cliente gravará no bate-papo, mas o driver não verá as mensagens. Eles provavelmente serão muito infelizes, jurarão nossa aplicação quando se conhecerem. Nesse caso, é importante que o bate-papo seja ativado ao mesmo tempo ou desligado ao mesmo tempo para todos os participantes no bate-papo. Isso é o que chamo de consistência.

A segunda nuance diz respeito ao fato de que nosso aplicativo Yandex.Taxi é distribuído geograficamente: os táxis podem ser encomendados em Moscou, Krasnoyarsk ou Helsinque. Isso deve ser levado em consideração mesmo no desenvolvimento de sistemas de degradação. Imagine que temos muitas solicitações bem-sucedidas e muito poucas solicitações com erros. Parece que esta é uma situação normal, o fundo de erros está sempre presente. Mas você pode olhar para a mesma imagem de maneira diferente.
Você pode ver que o serviço não funciona no Mytishchi e é necessário ativar o fallback para esses usuários. A conclusão é: você precisa criar as estatísticas certas. Para nós, como um serviço de distribuição geográfica, isso também significa que precisamos criar estatísticas por cidade. Se fizermos as estatísticas corretamente, veremos imediatamente que a maioria das solicitações do Mytishchi são interrompidas e ativamos o fallback especificamente para usuários do Mytishchi. E para todos os outros usuários, continuaremos trabalhando no modo normal, porque para eles o serviço funciona corretamente.

Talvez para outros serviços haja condições diferentes e outras nuances.
Nossos serviços estão se tornando mais complexos. Muitas vezes, eles dependem do mundo exterior, o que não podemos prever. Portanto, é importante escrever não apenas serviços que funcionem bem, mas também serviços que funcionem bem. Se você aprender algo novo, diga aos colegas, compartilhe. Curta, compartilhe, republique. Degrade corretamente.