Introdução lírica
Uma noite, colocando as coisas em ordem em um armário na parede, tropecei em uma grande caixa de papelão. Ela sobreviveu a duas realocações e não abriu por tantos anos que eu esqueci completamente o que estava armazenado nela. Aconteceu que havia fotos - em álbuns, envelopes de uma loja, e algumas eram exatamente assim.
Muitas fotografias foram tiradas há mais de setenta anos. Um deles era avô - em seus anos de estudante, ainda jovem e bonito, em óculos absolutamente
destrutivos . "Uau, meu avô usava roupas hipster mesmo antes de se tornar popular", pensei e sorri involuntariamente. Eu o reconheci imediatamente, mas depois foram as fotos de pessoas das quais não me lembro nada. Nas características faciais, você pode adivinhar vagamente o relacionamento - e é isso.

Quando eu tinha quinze anos, minha avó mostrou repetidamente esses cartões e falou sobre aqueles que estão retratados neles. Infelizmente, o valor de tais histórias é entendido apenas quando não há ninguém para lhes contar. Naquela época, era absolutamente desinteressante para mim, pela décima vez, ouvir algumas histórias musgosas sobre os anos anteriores à guerra, acenei e passei os ouvidos. Agora, de repente, percebendo completamente que parte da história da minha família estava irremediavelmente perdida, tive a ideia de sistematizar e preservar o que restava.
A solução ideal para armazenar dados da família me pareceu um híbrido de um mecanismo wiki e um álbum de fotos. Não havia soluções adequadas prontas, então tive que escrever as minhas. É chamado de
bonsai e é de código aberto sob a licença MIT. Depois, haverá uma história sobre como ela é organizada e como usá-la, bem como a história de seu desenvolvimento e um pouco de
DRAMA .

Outra bicicleta?
Hoje, existem muitas ferramentas que permitem criar árvores genealógicas e catalogar informações sobre parentes. Eles são condicionalmente divididos em duas grandes categorias - serviços online e aplicativos de desktop.
No caso de um aplicativo de desktop, o banco de dados geralmente é armazenado como um arquivo em disco. Você abre o aplicativo e o reabastece no modo de usuário único. Se necessário, os dados podem ser exportados para backup ou transferência para outro sistema (por exemplo, no formato
GEDCOM ). Entre os que eu assisti, os mais agradáveis de usar pareciam o
Gramps (gratuito) e a
Árvore da Vida doméstica (requer uma compra única).
O lado oposto do espectro são os serviços da web. Eles armazenam seus dados em servidores remotos e cobram uma taxa de uso periódica. Como este é um produto comercial com uma base centralizada e boa monetização, os serviços desse plano oferecem a oportunidade, por exemplo, de procurar parentes perdidos por teste de DNA ou registros de arquivo.
Os prós e contras de ambas as opções são bastante óbvios. No primeiro caso, você armazena o banco de dados localmente e controla totalmente o acesso a ele e a criação de backups. Se o aplicativo for de código aberto, se necessário, você poderá adicionar funcionalidades adicionais a ele. No entanto, será difícil trabalhar com esse banco de dados em conjunto ou visualizar dados de outro dispositivo. No segundo, pelo contrário, o acesso é de qualquer dispositivo, mas você fornece seus dados a terceiros e espera pela decência deles. Na história da minha família, não há segredos desacreditadores e terríveis; no entanto, ainda considero essas informações puramente pessoais e, em princípio, não quero que mais ninguém as armazene ou analise.
Dadas as deficiências de ambas as abordagens, podemos formular uma lista de requisitos para o mecanismo "ideal":
- Aplicativo da Web hospedado em seu próprio servidor
- Criando artigos sobre pessoas, animais de estimação, lugares, eventos etc. como um wiki
- Download de mídia
- Marcas de pessoas em fotos e vídeos
- Construção automática de árvore genealógica
- Calendário com todas as datas importantes.
- Ferramentas para co-edição e preenchimento
Para ser honesto, consegui encontrar vários projetos com uma implementação auto-hospedada, mas eles estavam em um estado deplorável: a aparência congelou em meados dos anos 2000, não havia um conjunto completo da funcionalidade necessária e eu não queria me aprofundar nos scripts herdados do PHP. Além disso, o projeto anterior para animais de estimação havia terminado e havia um desejo de assumir algo novo.
A regra de ouro diz:
se você quer fazer o bem - faça você mesmo!As tecnologias utilizadas foram selecionadas de acordo com três critérios: minha experiência com elas, popularidade e sem abertura. Aqui está o resultado:
- Rantime : .NET Core 2.1
- Back - end : ASP.NET Core MVC
- Banco de Dados : PostgreSQL
- Lógica de front-end : parcialmente Vue, parcialmente jQuery.
- Estilos de front-end : Bootstrap + Sass
As funções de suporte incluem Elasticsearch para pesquisa de texto completo e ffmpeg para tirar capturas de tela do vídeo.
Esquema de dados
Os principais objetos no banco de dados do Bonsai são uma
página e um
arquivo de mídia . Eles são conectados por um relacionamento muitos-para-muitos através de
marcas . Uma tag pode ter um título sem um link - por exemplo, se você precisar marcar alguém em uma foto, mas não houver informações em uma página inteira sobre ela.
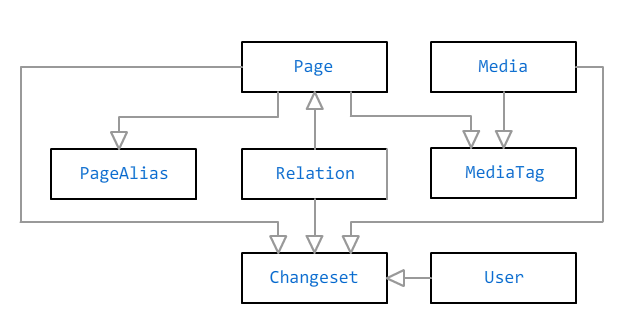
Além do texto livre, a página pode conter
fatos inseridos em campos especiais no painel do administrador. Fatos adicionais são calculados com base nos fatos: por exemplo, se você indicar a data de nascimento da pessoa, ela será marcada no calendário e a página dele mostrará a idade atual (ou expectativa de vida, se a data da morte também for indicada), o sexo pode ser usado para determinar o nome correto do relacionamento ("pai ”Ou“ mãe ”em vez dos“ pais ”comuns) e assim por diante. Os fatos são armazenados no banco de dados como um documento JSON.
Existem cinco tipos de páginas para escolher: pessoa, animal de estimação, evento, local e assim por diante. A lista de fatos disponíveis depende do tipo de página: por exemplo, "educação" é relevante apenas para uma pessoa, "data de nascimento" - para uma pessoa e um animal e "endereço" - apenas para um local.
As páginas são interconectadas por
relacionamentos : "pai", "cônjuge", "amigo", "proprietário", "residente" e muitos outros. Alguns relacionamentos podem ser limitados no tempo (cônjuge, proprietário, residente), outros são considerados permanentes.
Quando você salva qualquer página ou relacionamento, o modelo resultante é verificado quanto à consistência. Por exemplo,
os anos de vida dos cônjuges devem se sobrepor , uma pessoa não pode ter mais de um pai biológico de cada sexo e você também não pode se
tornar seu próprio pai . Casamentos do mesmo sexo, no entanto, são permitidos.
A edição de uma página, arquivo de mídia ou relacionamento salva a
alteração no banco de dados. Isso permite salvar o histórico de edições e revertê-las, se necessário.
Relacionamento
Parentesco é um dos conceitos mais antigos da sociedade. Já no
idioma pré-indo-europeu, havia muitos nomes para eles, que, de uma forma ligeiramente modificada, migraram para os idiomas modernos de vários grupos: a palavra "mãe" será entendida por russo, inglês e chinês.
Existem muitas opções para o parentesco, mas as básicas são três:
pai ,
filho e
cônjuge . Eles permitem que você construa um gráfico direcionado da família em que esses relacionamentos são arestas e as pessoas são nós. Nesta coluna, você pode expressar qualquer outro relacionamento, conhecendo o caminho entre os participantes e seu sexo: por exemplo, para identificar o avô de alguém, você deve primeiro encontrar o pai (qualquer gênero) e, em seguida, o pai desse pai (masculino) e assim por diante.
No painel de administração do Bonsai, você pode inserir as relações desses três tipos básicos. O oposto será criado automaticamente para cada relacionamento - pai para filho, cônjuge para cônjuge, proprietário para animal de estimação. Todos os relacionamentos adicionais são calculados pelo mecanismo e mostrados na barra lateral na página:
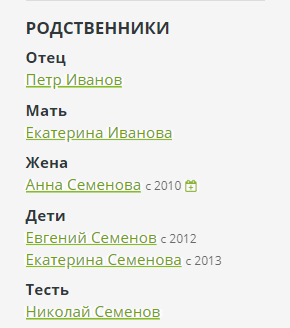
Para calcular o relacionamento, é utilizado um percurso de gráfico elementar e os nomes dos relacionamentos são definidos na forma de uma DSL especial:
public static RelationDefinition[] ParentRelations = { new RelationDefinition("Parent:m", ""), new RelationDefinition("Parent:f", ""), new RelationDefinition("Parent Child:m", "", ""), new RelationDefinition("Parent Child:f", "", ""), new RelationDefinition("Parent Parent:m", "", ""), new RelationDefinition("Parent Parent:f", "", "") };
Mesmo uma pessoa pode ter
muitos parentes diretos. O bonsai divide os links nos seguintes grupos:
- A relação sanguínea mais próxima é a família na qual a pessoa cresceu: mãe e pai, avós, irmãos e irmãs. Se você olhar para o gráfico, este é o caminho 1-2 etapas acima e 1 lateralmente.
- Família própria : um grupo para cada cônjuge e filhos dele. Isso também inclui os parentes do cônjuge - sogra, cunhado e similares.
- Outros : parentes mais distantes (netos, tios, tias) e laços de não parentesco (amigos, colegas).
Às vezes, uma maneira de determinar a associação ao grupo não é suficiente. Os dados podem estar incompletos, mas ainda precisam ser exibidos da maneira mais adequada possível. Considere o seguinte gráfico de irmão:
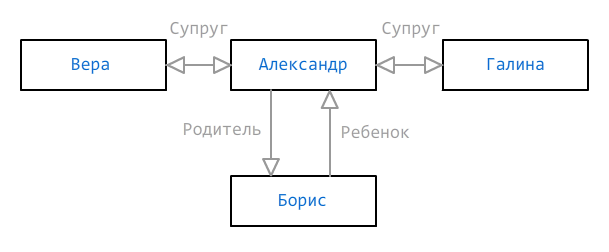
Como vemos, duas esposas (Vera e Galina) e um filho (Boris) são indicados para Alexander, mas não sabemos qual das esposas é a mãe da criança - talvez esse seja algum tipo de terceira mulher, mas ela ainda não foi adicionada. Para tais casos, podem ser indicados vários caminhos que deveriam existir ou não, e são marcados com os sinais
+ e
- respectivamente:
new RelationDefinition("Spouse Child+Child", "||", "") new RelationDefinition("Spouse Child-Child:m", "") new RelationDefinition("Spouse Child-Child:f", "")
Árvore genealógica
Qualquer mecanismo de genealogia decente deve ser capaz de construir uma árvore genealógica. Essa é a maneira mais visual de mostrar informações gerais sobre as pessoas e seus relacionamentos familiares. Os dados são armazenados no banco de dados na forma de um gráfico direcionado e, em teoria, deve ser fácil de visualizar. Na prática, foi com a exibição da árvore que a maioria das dificuldades surgiu.
Aqui estão alguns exemplos de como as árvores genealógicas podem se parecer:

Árvore genealógica de Targaryenov. Muito compacto, porque é feito à mão. Gerar essa árvore a partir de dados arbitrários será extremamente difícil automaticamente.
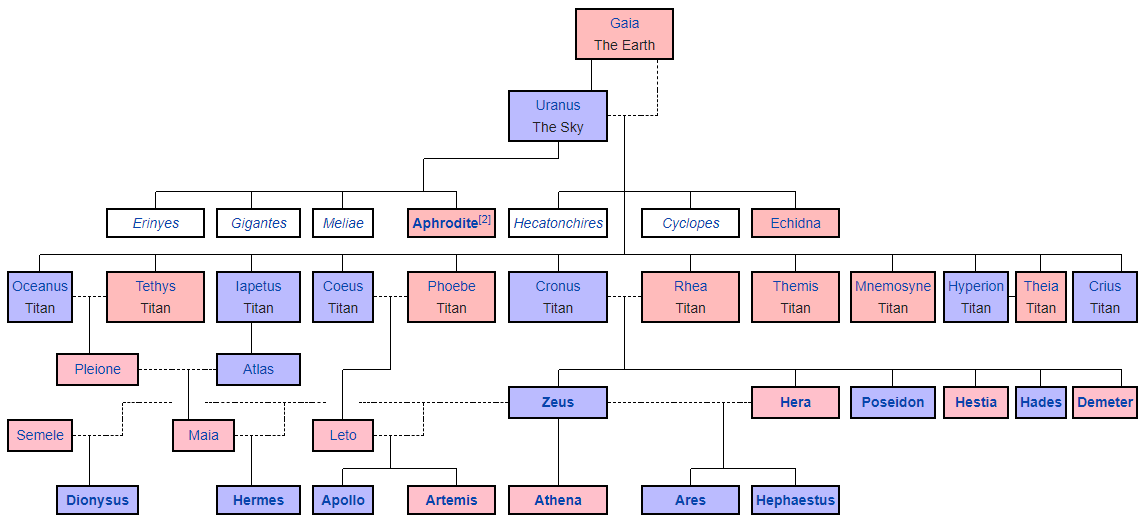
Deuses gregos. A representação gráfica é gerada a partir de uma
sintaxe de remarcação especial , na qual você ainda precisa organizar manualmente todos os blocos e desenhar os links entre eles. Um pouco como a arte ASCII.

Apresentação de uma árvore na forma de um diagrama semicircular. Facilmente gerado automaticamente, mas leva em consideração apenas ancestrais diretos.
Eu olhei através de muitas opções. O mais esteticamente agradável foi no site MyHeritage:
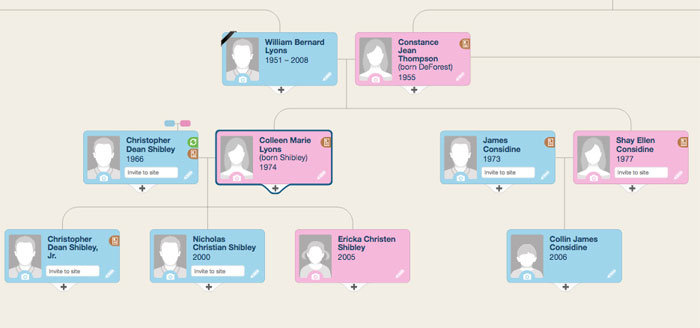
A renderização dessa árvore pode ser dividida em três etapas condicionais: obter dados do banco de dados, organizar blocos / linhas de conexão e exibi-los diretamente na página. Se tudo era trivial com o primeiro e o terceiro passo, no segundo eu tropecei.
As tentativas de lançar uma solução feita às pressas terminaram em um completo fiasco. Um arranjo competente de elementos gráficos é uma área tão complexa que
são escritas dissertações e os
componentes acabados são como um apartamento em Moscou. Ok, você não será capaz de se escrever, mas certamente existem soluções gratuitas decentes?
A maioria das minhas esperanças estava na
biblioteca D3.js. Talvez essa seja a primeira coisa que vem à mente se você precisar desenhar um gráfico ou gráfico em uma página da web. Infelizmente, entre mais de trezentos (!) Exemplos no wiki, não havia um mais ou menos semelhante a uma árvore no MyHeritage.
O próximo passo foi mergulhar nas bibliotecas que não estavam envolvidas na renderização, mas no cálculo da organização ideal dos elementos no gráfico. A maioria deles oferece o chamado
layout Force . Essa é uma abordagem muito simples, baseada em fórmulas físicas: os nós do gráfico são representados por corpos elásticos e as linhas de conexão são representadas por molas. Ele pode ser facilmente reconhecido por sua animação característica - o gráfico parece "se endireitar" em movimento, e esse não é um recurso adicional, mas uma consequência inevitável da natureza da simulação do algoritmo. A abordagem de layout de força é boa para visualizar dados sem uma hierarquia clara (por exemplo, conexões em redes sociais), mas a árvore genealógica neste formulário parece falho.
Outra opção considerada é a biblioteca
Graphviz . O resultado de seu trabalho pode ser facilmente reconhecido pelas setas características. Uma linguagem especial
DOT é usada para descrever o gráfico. Os casos de teste parecem ainda mais ou menos, mas surgem problemas com dados reais: as setas "se quebram" e se conectam em ângulos estranhos, o gráfico aumenta e você não pode ajustá-lo e contorná-lo.
Como não encontrei uma solução adequada por conta própria, decidi solicitá-la como freelancer e, então, o próprio
DRAMA começou.
O pedido foi feito na manhã de 22 de outubro e, em uma hora, recebeu várias respostas. Um dos entrevistados se chamava Vladislav; ele enviou um exemplo de solução semelhante e prometeu concluir a tarefa em
um dia . Essa velocidade parecia suspeita para mim, mas eu esperava a experiência dele e, para mim mesmo, dei ao sujeito um erro de uma semana. Nos primeiros dias, Vladislav fez perguntas adicionais, nunca deixando de me surpreender com uma profunda imersão no projeto e uma atitude atenta aos detalhes, e então ele desapareceu. Ele acordou em 1º de novembro, pediu desculpas pelo desaparecimento forçado por motivos familiares e enviou um link com uma versão beta que parecia bastante semelhante ao que ele queria, se não fosse o nó nas linhas de conexão no centro:
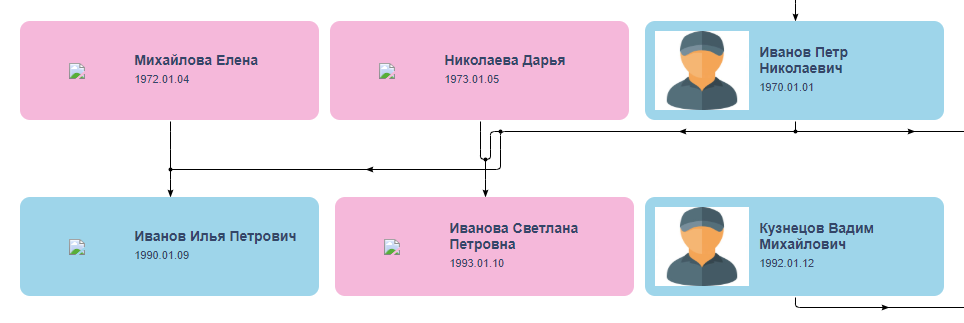
O desaparecimento do artista é sempre um sinal de alerta, mas você nunca sabe, acontece alguma coisa, porque ele fez alguma coisa. Deixe ele continuar! Enviei um pré-pagamento e comecei a esperar por melhorias. Depois de alguns dias, Vladislav escreveu que não poderia resolver o problema e desapareceu novamente - desta vez por três semanas. Durante esse período, ele não fez nada e se recusou a devolver o adiantamento, porque "a tarefa foi realmente realizada por um
ex-amigo estúpido que o decepcionou e não devolve o dinheiro". Depois de algumas perguntas esclarecedoras, o infeliz delegador parou de tentar se desculpar e calou a boca. Então agora nós vivemos - periodicamente eu o lembro da dívida e, em resposta, ele envia uma captura de tela do aplicativo bancário - eles dizem: "não há dinheiro, mas assim que - imediatamente." Desejo ao Vladislav sucesso nos negócios e fique rico mais rápido!
Jogou a criança - sem karma!Perder dinheiro não era tão chato, mas um mês se passou, e a tarefa não saiu do papel, e agora não havia lugar para esperar ajuda. Antes de tudo, fiquei com raiva de mim mesmo: segui o caminho de menor resistência, violei a
regra de ouro - e aqui está o resultado. Cheio de raiva justa, sentei-me novamente para estudar bibliotecas para desenhar gráficos e - eis que eis! - de repente encontrou exatamente o que você precisa.
A biblioteca foi denominada
Eclipse Layout Kernel , abreviado ELK. Como você pode imaginar, ele é usado para exibir diagramas no Eclipse IDE, mas também pode ser usado de forma autônoma. Em geral, ele é escrito em Java, mas há uma transmissão de versão em JS. Sim, o código dela é um
pesadelo e pesa um megabyte e meio, mas essas deficiências podem ser perdoadas pelo fato de
funcionar e fazer exatamente a coisa certa. A interface é elementar: nós, arestas e configurações são transmitidas para a entrada e, na saída, obtemos as coordenadas. Você pode desenhar uma árvore usando-as de qualquer maneira conveniente: escolhi o SVG para conectar linhas e divs com posicionamento absoluto para blocos.
A integração da biblioteca e a seleção de configurações ideais levaram duas noites de força. Isso, é claro, não é "um dia", como prometeu meu infeliz e arrogante freelancer, mas bem próximo. Como resultado, o Bonsai conseguiu exibir a árvore aproximadamente desta forma:
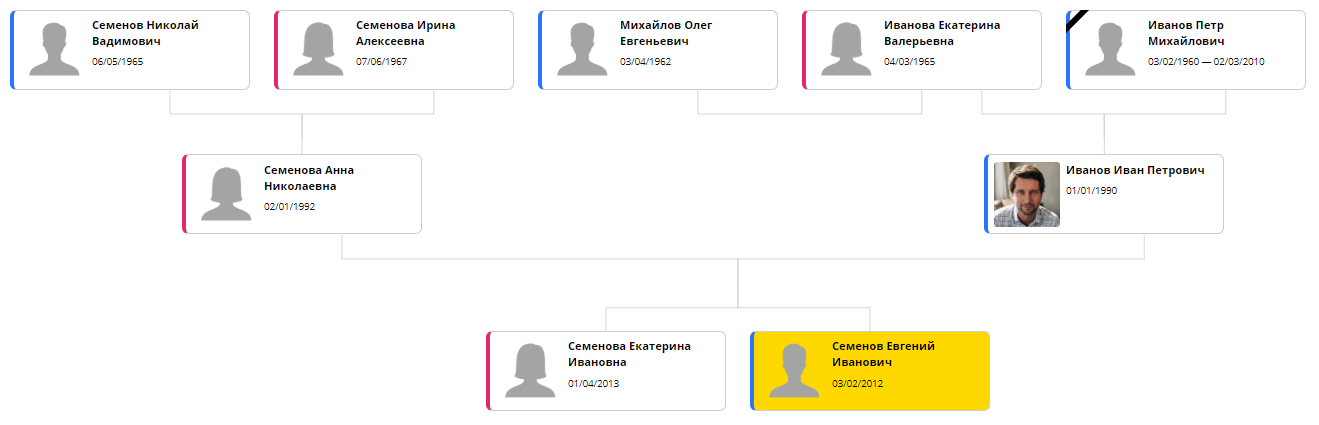
Agora, o único problema que resta é o tempo de processamento. O ELK usa um algoritmo iterativo: você pode se aproximar do posicionamento ideal gastando tempo extra. Em uma árvore de 20 a 30 elementos, um bom resultado requer cerca de 5 segundos. Por esse motivo, uma página com uma árvore é aberta todas as vezes por muito tempo e rapidamente começa a incomodar. Na próxima versão, o cálculo será transferido para o back-end, para que possa ser feito uma vez ao alterar a página e o cache.
Pesquisa de texto completo
Um sistema para armazenar informações textuais seria inútil sem a pesquisa conveniente de texto completo. O Bonsai usa o banco de dados PostgreSQL, então a primeira coisa que decidi foi verificar o que ele poderia oferecer imediatamente. Outra decepção:
tsvector lida com palavras comuns, mas se recusa a procurar a coisa mais importante - nomes e sobrenomes:
SELECT to_tsvector('') @@ to_tsquery(''),
Os trigramas também não deram nada de bom. No final, decidi por uma opção bastante esperada: ElasticSearch +
Morfologia Russa . Acabou sendo muito inconveniente trabalhar com ele no .NET, no entanto, ele lida com a busca de cinco sólidos com seu nome completo.
Imperfeição Consciente
Ao trabalhar em um projeto, ocorriam situações regularmente quando um
perfeccionista interno ficava furioso com a solução escolhida. A área de assunto é bastante fora do padrão e as “boas maneiras” geralmente aceitas nem sempre funcionam.
Por exemplo, o que acontece quando abrimos qualquer página?
- O texto da página é compilado do Markdown para o HTML. Se o texto contiver links para outras páginas e arquivos de mídia, você precisará acessar o banco de dados para obter mais informações.
- Os fatos são desserializados a partir do JSON no qual estão armazenados no banco de dados, no modelo de visualização.
- Os relacionamentos são determinados. Para fazer isso, no banco de dados de longa data, é necessário obter o gráfico de conexão inteiro e encontrar nós nele de acordo com uma lista de caminhos conhecida anteriormente.
À primeira vista, isso parece uma operação terrivelmente difícil, mas, na verdade, não é por causa da quantidade relativamente pequena de dados. Quantos parentes você consegue se lembrar e querer escrever? Tente recontá-los por interesse e verifique que será muito difícil discar pelo menos cem. E quantas pessoas querem dar acesso? Mesmo um número astronomicamente grande para uma família é de mil pessoas! Pelos padrões dos bancos de dados modernos, continua sendo ridículo.
Obviamente, o modelo de exibição de página compilado ainda é armazenado em cache na primeira vez em que é aberto e reutilizado nos modelos subsequentes, principalmente porque era muito fácil de implementar. A regra de invalidação de cache para alterações no painel de administração também é adotada da maneira mais simples possível: se alterarmos apenas o texto e alguns fatos
locais (lista de idiomas, tipo sanguíneo, cor do cabelo etc.), basta redefinir esta página específica. Com qualquer outra alteração - nome da página, data de nascimento ou sexo, adição ou alteração de qualquer conexão - o cache é
completamente redefinido. Sim, essa não é a maneira mais inteligente de limpar. Sim, com certeza, você poderia escrever um algoritmo complexo que redefiniria apenas o que você precisa - mas, para este projeto, isso não justificaria os custos.
O projeto não suporta localização e alteração de aparência, a autorização funciona no OAuth no Facebook \ Google e o painel de administração é feito nos formulários usuais, e não em alguma estrutura do SPA baseada na última moda. Tudo isso
poderia ser realizado ou aprimorado, mas não teria resolvido nenhum problema e, portanto, o tempo seria desperdiçado.
Ansioso pelo futuro
Outro motivo pelo qual não faz sentido investir na complexidade do dispositivo do mecanismo é a natureza efêmera da implementação em comparação com os dados que ele armazena. Apenas pense por um momento: a web em sua forma atual existe há quase vinte anos e a história da família existe
há séculos . Ninguém ainda resolveu esse problema simplesmente porque o próprio setor de tecnologia da informação existe muito menos. O que pode ser feito?
O mecanismo terá que ser reescrito regularmente do zero - assim como há milhares de anos, os monges têm se esforçado para copiar textos de livros em ruínas para novos. A única diferença é que o livro pode ficar cem anos com o manuseio e a aplicação adequados - com a força de 15 a 20 anos. Espero que daqui a vinte anos ainda seja capaz de fazer isso sozinho, mas em outros vinte anos meus filhos ou netos terão que fazê-lo. Gostaria de deixá-los uma fonte simples, compreensível e documentada.
Nos primeiros estágios do design, eu queria incorporar uma certa linguagem semelhante ao SQL no mecanismo, com a ajuda de obter respostas para perguntas específicas: "qual é a porcentagem de meus ancestrais com olhos azuis", "quando Ivan comprou o primeiro carro" e assim por diante. Essa ideia teve que ser abandonada, porque exigiria, em vez do texto simples, inserir todas as informações de uma certa forma formalizada, e apenas uma descrição desse tipo levaria anos. Por outro lado, o entendimento da linguagem natural está ganhando força. Não ficarei surpreso se, em dez ou dois anos, for possível solicitar à Siri que leia o texto para você, siga os links e, como resultado, apresente um extrato dos fatos. Gente, empurre!
Como tentar?
Infelizmente, não posso fornecer um link para a demonstração final: não há servidor que resista ao efeito habra. Mas existem algumas capturas de tela visuais (as imagens são clicáveis).
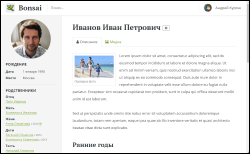

Se o Bonsai lhe pareceu útil e você deseja executá-lo, o código-fonte pode ser baixado no Github:
https://github.com/impworks/bonsaiInstruções de instalação detalhadas são fornecidas no Leia-me. Você precisará disso:
- .NET Core 2.1 ou superior
- PostgreSQL 10+
- ElasticSearch 5.xe plugin de morfologia russa
- Facebook ou Google app para autorização oAuth
Após o primeiro lançamento, várias páginas e fotos de teste são criadas no banco de dados. Para produção, esse comportamento não é necessário e é desabilitado pelo sinalizador nas configurações.
Há apenas um mês, lancei minha própria instância e comecei a executá-la, obtendo dados reais. Alguma rugosidade é encontrada, mas, caso contrário, estou completamente satisfeito com o resultado. Agora o projeto será gradualmente desenvolvido e finalizado. As principais tarefas são acelerar a exibição da árvore, permitir o download de documentos na forma de PDF e adicionar um ajuste fino dos direitos de acesso. Seria bom melhorar a usabilidade do painel de administração em alguns lugares ou reconhecer automaticamente os rostos na foto -
mas isso não é exato .