
No artigo anterior, falamos sobre um problema de aprendizado de máquina, como exemplos adversos e alguns tipos de ataques que permitem que eles sejam gerados. Este artigo se concentrará nos algoritmos de proteção contra esse tipo de efeito e nas recomendações para modelos de teste.
Protecção
Antes de tudo, vamos explicar imediatamente um ponto - é impossível se defender completamente contra esse efeito, e isso é bastante natural. De fato, se resolvêssemos o problema de exemplos adversos completamente, resolveríamos simultaneamente o problema de construir um hiperplano ideal, o que, é claro, não pode ser feito sem um conjunto de dados geral.
Existem dois estágios para defender um modelo de aprendizado de máquina:
Aprendizado - Ensinamos nosso algoritmo a responder corretamente a exemplos adversos.
Operação - estamos tentando detectar um exemplo contraditório durante a fase de operação do modelo.
Vale a pena dizer imediatamente que você pode trabalhar com os métodos de proteção apresentados neste artigo usando o IBM Adversarial Robustness Toolbox .
Treinamento adversário

Se você perguntar a uma pessoa que acabou de se familiarizar com o problema Adversarial com exemplos, a pergunta: "Como se proteger desse efeito?", 9 de 10 pessoas dirão: "Vamos adicionar os objetos gerados ao conjunto de treinamento". Essa abordagem foi proposta imediatamente no artigo Propriedades intrigantes de redes neurais em 2013. Foi neste artigo que esse problema foi descrito pela primeira vez e o ataque de L-BFGS, permitindo obter exemplos adversos.
Este método é muito simples. Geramos exemplos de Adversarial usando vários tipos de ataques e os adicionamos ao conjunto de treinamento a cada iteração, aumentando assim a “resistência” do modelo Adversarial aos exemplos.
A desvantagem desse método é bastante óbvia: a cada iteração do treinamento, para cada exemplo, podemos gerar um número muito grande de exemplos, respectivamente, e o tempo para modelar o treinamento aumenta muitas vezes.
Você pode aplicar esse método usando a biblioteca ART-IBM da seguinte maneira.
from art.defences.adversarial_trainer import AdversarialTrainer trainer = AdversarialTrainer(model, attacks) trainer.fit(x_train, y_train)
Aumento Gaussiano de Dados
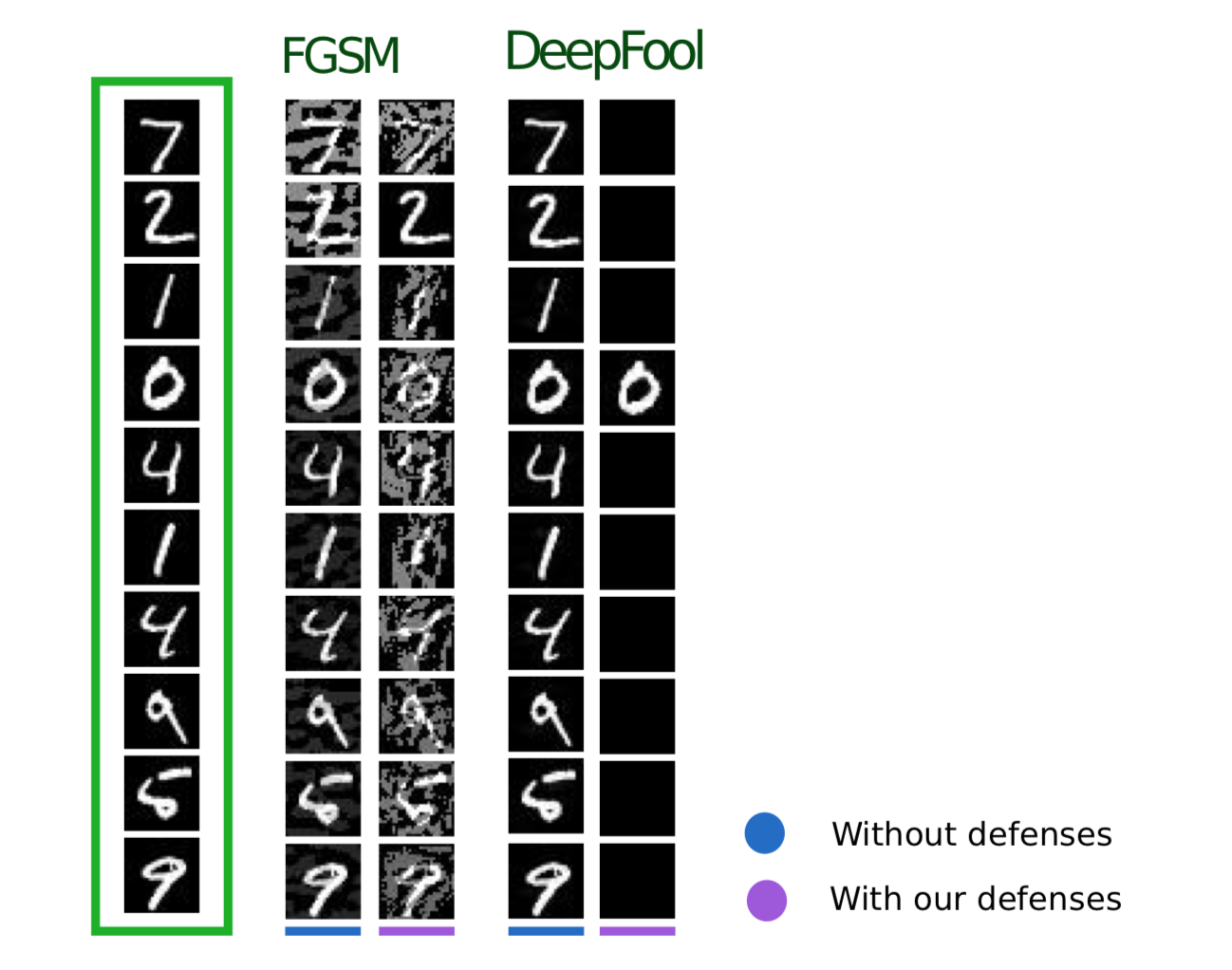
O método a seguir, descrito no artigo Efficient Defenses Against Adversarial Attacks , usa uma lógica semelhante: também sugere adicionar objetos adicionais ao conjunto de treinamento, mas, diferentemente do Adversarial Training, esses objetos não são exemplos de Adversarial, mas objetos de conjunto de treinamento um pouco barulhentos (Gaussian é usado como ruído ruído, daí o nome do método). E, de fato, isso parece muito lógico, porque o principal problema dos modelos é justamente a falta de imunidade a ruídos.
Este método mostra resultados semelhantes ao Treinamento Adversarial, enquanto gasta muito menos tempo na geração de objetos para treinamento.
Você pode aplicar esse método usando a classe GaussianAugmentation no ART-IBM
from art.defences.gaussian_augmentation import GaussianAugmentation GDA = GaussianAugmentation() new_x = GDA(x_train)
Suavização de etiquetas
O método de suavização de etiqueta é muito simples de implementar, mas ainda assim carrega muito significado probabilístico. Não entraremos em detalhes da interpretação probabilística desse método; você pode encontrá-lo no artigo original Repensando a arquitetura de criação para visão computacional . Mas, resumindo, Label Smoothing é um tipo adicional de regularização do modelo no problema de classificação, o que o torna mais resistente ao ruído.
De fato, esse método suaviza os rótulos de classe. Fazendo-os, digamos, não 1, mas 0,9. Assim, os modelos de treinamento são multados por uma "confiança" muito maior no rótulo de um objeto específico.
A aplicação deste método em Python pode ser vista abaixo.
from art.defences.label_smoothing import LabelSmoothing LS = LabelSmoothing() new_x, new_y = LS(train_x, train_y)
Relu limitado
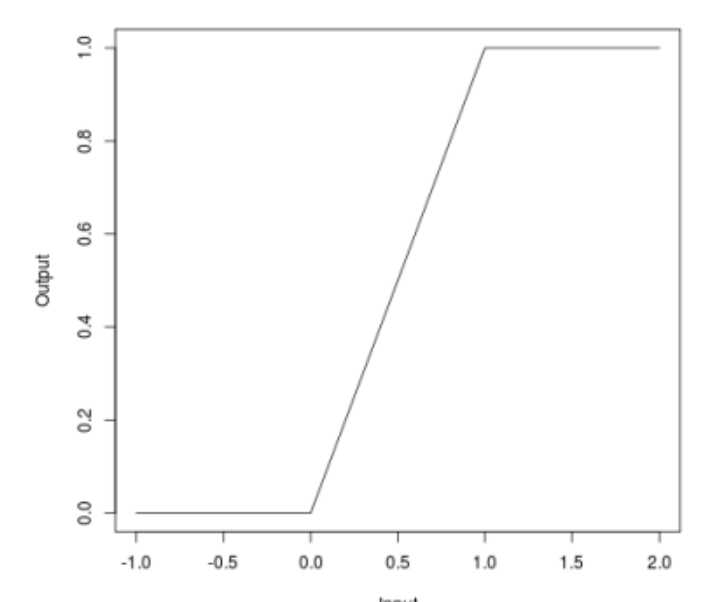
Quando falamos sobre ataques, muitos podem perceber que alguns ataques (JSMA, OnePixel) dependem da força do gradiente em um ponto ou outro na imagem de entrada. O método simples e "barato" (em termos de custos computacionais e de tempo) do ReLU vinculado está tentando lidar com esse problema.
A essência do método é a seguinte. Vamos substituir a função de ativação do ReLU em uma rede neural pela mesma, que é limitada não apenas por baixo, mas também por cima, suavizando mapas de gradiente e, em pontos específicos, não será possível obter um splash, o que não permitirá que você engane o algoritmo alterando um pixel da imagem.
\ begin {equação *} f (x) =
\ begin {cases}
0, x <0
\\
x, 0 \ leq x \ leq t
\\
t, x> t
\ end {cases}
\ end {equação *}
Esse método também foi descrito no artigo Defesas eficientes contra ataques adversos
Conjuntos de modelos de construção
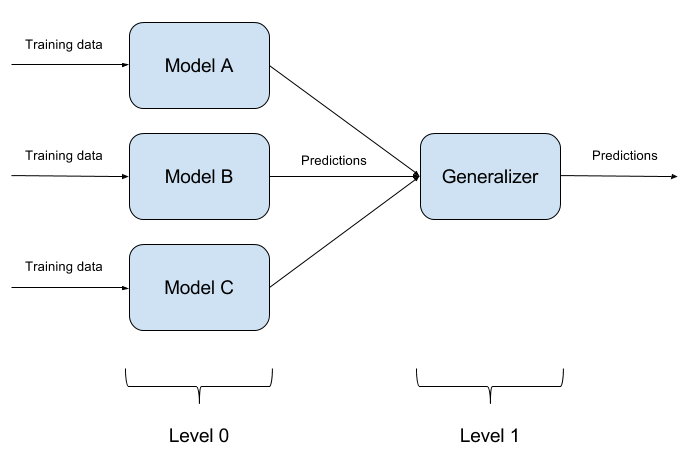
Não é difícil enganar um modelo treinado. Enganar dois modelos ao mesmo tempo com um objeto é ainda mais difícil. E se houver N tais modelos? É sobre isso que o método de conjunto de modelos se baseia. Simplesmente construímos N modelos diferentes e agregamos sua saída em uma única resposta. Se os modelos também são representados por algoritmos diferentes, é extremamente difícil enganar esse sistema, mas é extremamente difícil!
É bastante natural que a implementação de conjuntos de modelos seja uma abordagem puramente arquitetônica, com muitas perguntas (quais modelos básicos adotar? Como agregar as saídas de modelos básicos? Existe uma relação entre modelos? E assim por diante). Por esse motivo, essa abordagem não é implementada no ART-IBM
Aperto de recurso
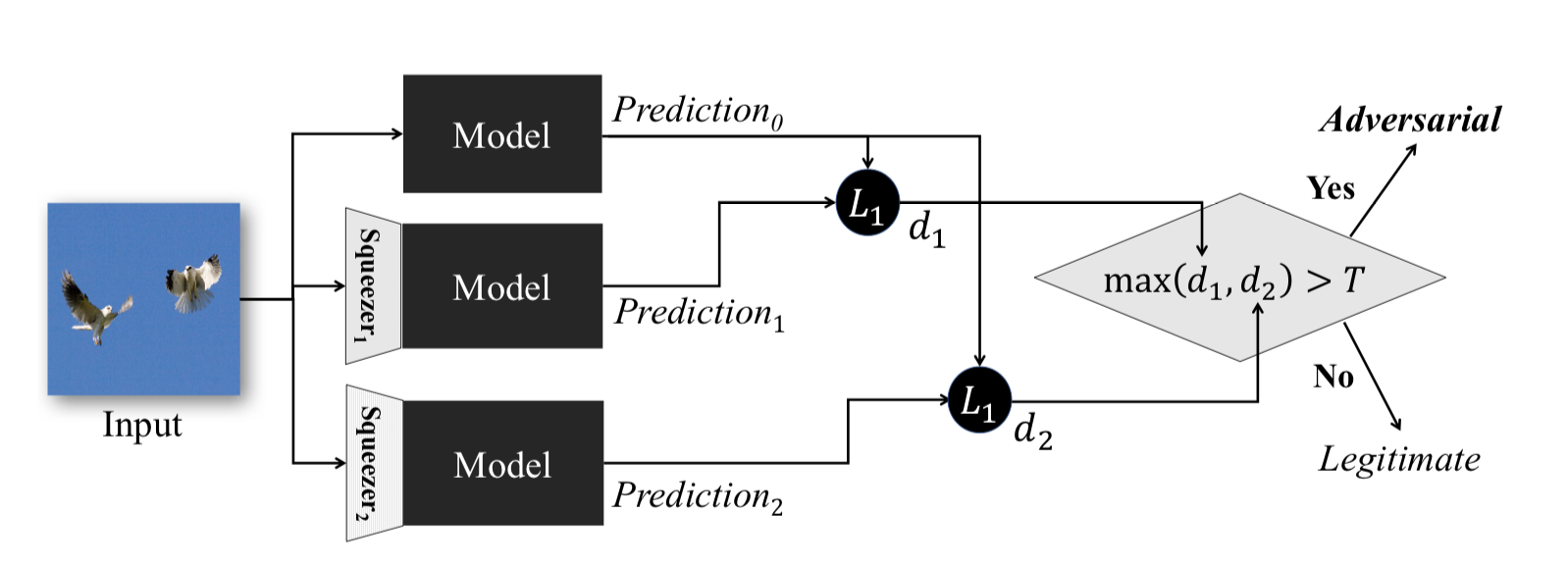
Este método, descrito em Aperto de recursos: detecção de exemplos adversos em redes neurais profundas , funciona durante a fase operacional do modelo. Permite detectar exemplos contraditórios.
A idéia por trás desse método é a seguinte: se você treinar n modelos nos mesmos dados, mas com taxas de compactação diferentes, os resultados do trabalho ainda serão semelhantes. Ao mesmo tempo, o exemplo Adversarial, que funciona na rede de origem, provavelmente falhará em redes adicionais. Assim, considerando a diferença de pares entre as saídas da rede neural inicial e as adicionais, escolhendo o máximo delas e comparando-a com um limiar pré-selecionado, podemos afirmar que o objeto de entrada é Adversarial ou absolutamente válido.
A seguir, é apresentado um método para obter objetos compactados usando ART-IBM
from art.defences.feature_squeezing import FeatureSqueezing FS = FeatureSqueezing() new_x = FS(train_x)
Terminaremos com métodos de proteção. Mas seria errado não entender um ponto importante. Se um invasor não tiver acesso às entradas e saídas do modelo, ele não entenderá como os dados brutos são processados dentro do seu sistema antes de entrar no modelo. Então, e somente então, todos os seus ataques serão reduzidos à classificação aleatória dos valores de entrada, o que é naturalmente improvável que leve ao resultado desejado.
Teste
Agora vamos falar sobre o teste de algoritmos para combater os exemplos contraditórios. Aqui, antes de tudo, é necessário entender como testaremos nosso modelo. Se assumirmos que, de alguma maneira, um invasor pode obter acesso total a todo o modelo, é necessário testar nosso modelo usando métodos de ataque WhiteBox.
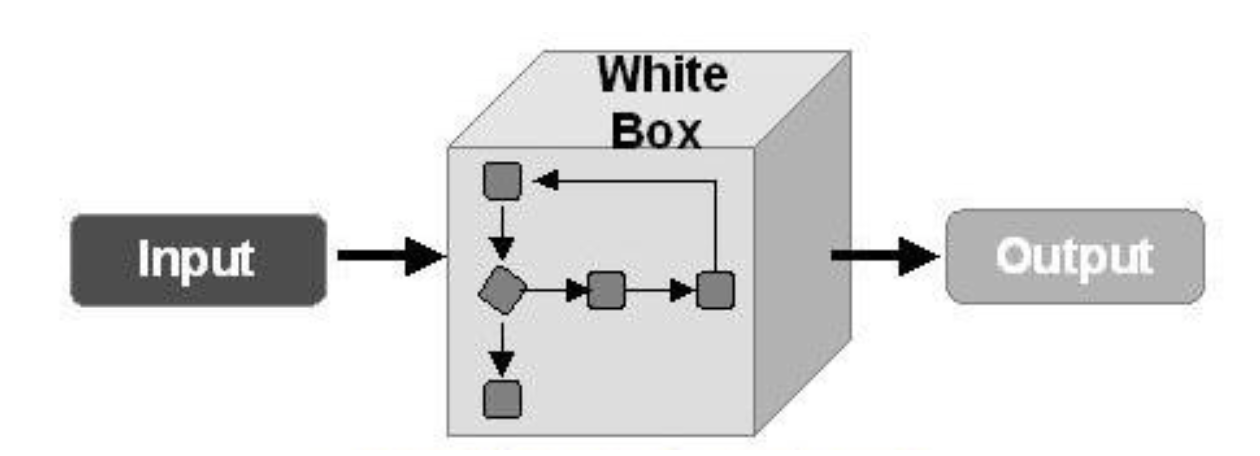
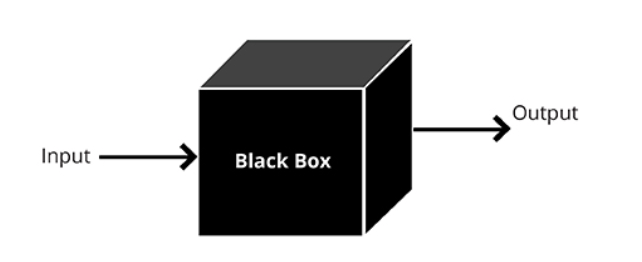
Em outro caso, assumimos que um invasor nunca terá acesso ao "interior" do nosso modelo, mas poderá, ainda que indiretamente, influenciar os dados de entrada e ver o resultado do modelo. Então você deve aplicar os métodos de ataques do BlackBox.
O algoritmo de teste geral pode ser descrito com o seguinte exemplo:
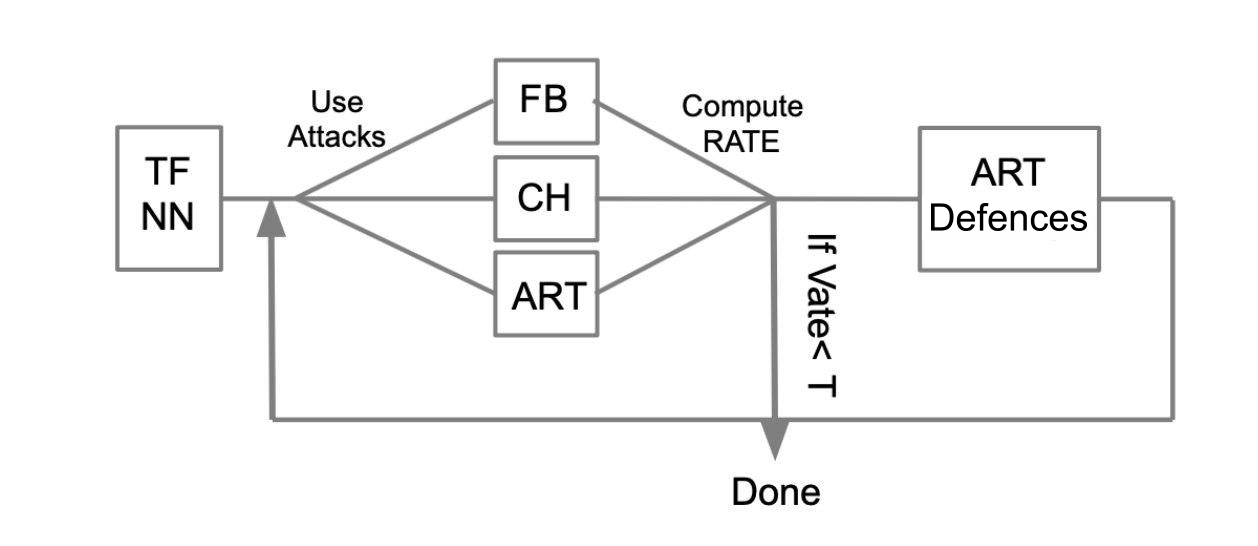
Que haja uma rede neural treinada escrita em TensorFlow (TF NN). Reivindicamos habilmente que nossa rede pode cair nas mãos de um invasor ao penetrar no sistema em que o modelo está localizado. Nesse caso, precisamos realizar ataques do WhiteBox. Para isso, definimos um pool de ataques e estruturas (FoolBox - FB, CleverHans - CH, Adversarial robustness toolbox - ART) que permitem a implementação desses ataques. Depois, contando quantos ataques foram bem-sucedidos, calculamos a taxa de sucesso (SR). Se o SR nos convém, terminamos o teste, caso contrário, usamos um dos métodos de proteção, por exemplo, implementado no ART-IBM. Então, novamente, realizamos ataques e consideramos SR. Fazemos essa operação ciclicamente, até que a SR nos convenha.
Conclusões
Gostaria de terminar aqui com informações gerais sobre ataques, defesas e modelos de aprendizado de máquina de teste. Resumindo os dois artigos, podemos concluir o seguinte:
- Não acredite no aprendizado de máquina como uma espécie de milagre que pode resolver todos os seus problemas.
- Ao aplicar algoritmos de aprendizado de máquina em suas tarefas, pense em quão resistente esse algoritmo é a uma ameaça como os exemplos adversos.
- Você pode proteger o algoritmo do lado do aprendizado de máquina e do lado do sistema em que este modelo é operado.
- Teste seus modelos, especialmente nos casos em que o resultado do modelo afeta diretamente a decisão
- Bibliotecas como FoolBox, CleverHans, ART-IBM fornecem uma interface conveniente para atacar e defender modelos de aprendizado de máquina.
Também neste artigo, gostaria de resumir o trabalho com as bibliotecas FoolBox, CleverHans e ART-IBM:
O FoolBox é uma biblioteca simples e compreensível para atacar redes neurais, suportando muitas estruturas diferentes.
O CleverHans é uma biblioteca que permite realizar ataques alterando muitos parâmetros do ataque, um pouco mais complicado que o FoolBox, suporta menos estruturas.
O ART-IBM é a única biblioteca acima, que permite trabalhar com métodos de segurança, até o momento suporta apenas o TensorFlow e o Keras, mas está se desenvolvendo mais rapidamente que outros.
Aqui, vale a pena dizer que existe outra biblioteca para trabalhar com exemplos adversos do Baidu, mas, infelizmente, é adequada apenas para pessoas que falam chinês.
No próximo artigo sobre este tópico, analisaremos parte da tarefa que foi proposta para ser resolvida durante o ZeroNights HackQuest 2018, enganando uma rede neural típica usando a biblioteca FoolBox.