O modelo de infraestrutura como código (IaC), às vezes chamado de "infraestrutura programável", é um modelo pelo qual o processo de configuração da infraestrutura é semelhante ao processo de programação de software. Essencialmente, marcou o início da remoção dos limites entre a criação de aplicativos e a criação de ambientes para esses aplicativos. Os aplicativos podem conter scripts que criam e gerenciam suas próprias máquinas virtuais. Essa é a base da computação em nuvem e parte integrante do DevOps.
A infraestrutura como um código permite gerenciar máquinas virtuais no nível do software. Isso elimina a necessidade de configuração manual e atualizações para componentes de equipamentos individuais. A infraestrutura se torna extremamente “resiliente”, ou seja, reproduzível e escalável. Um operador pode implantar e gerenciar tanto uma quanto 1000 máquinas usando o mesmo conjunto de códigos. Entre os benefícios garantidos da infraestrutura como código estão a velocidade, a relação custo-benefício e a redução de riscos.
É exatamente disso que trata a decodificação do relatório de Kirill Vetchinkin no DevOpsDays Moscow 2018. O relatório: reutilização de módulos Ansible, armazenamento no Git, revisão, reconstrução, benefícios financeiros, escala horizontal com um clique.
Quem se importa, por favor, debaixo do gato.
Olá pessoal. Como já foi dito, sou Vetchinkin Kirill. Eu trabalho na TYME e hoje falaremos sobre infraestrutura como um código. Também falaremos sobre como aprendemos a economizar nessa prática, porque é muito cara. Escrever muito código é muito caro para configurar a infraestrutura.
Vou falar brevemente sobre a empresa. Eu trabalho na TYME. Tivemos uma mudança de nome. Agora somos chamados PaySystem - como o nome indica, estamos envolvidos em sistemas de pagamento. Temos nossas próprias soluções - são processamentos e desenvolvimento personalizado. O desenvolvimento personalizado é serviços bancários eletrônicos, cobrança e afins. E como você sabe, se esse é um desenvolvimento personalizado, esse é um grande número de projetos a cada ano. O projeto segue o projeto. Quanto mais projetos, mais infraestrutura do mesmo tipo precisa ser aumentada. Como os projetos geralmente são muito carregados, usamos a arquitetura de microsserviço. Portanto, em um projeto, existem muitos, muitos subprojetos pequenos.

Portanto, gerenciar esse zoológico inteiro sem um DevOps completo é muito difícil. Portanto, nossa empresa implementou várias práticas de DevOps. Naturalmente, trabalhamos no Kanban, no SCRUM, armazenamos tudo no git. Após a confirmação, há uma integração contínua, os testes são executados. Os testadores escrevem testes de ponta a ponta no PyTest que começam todas as noites. O teste de unidade é iniciado após cada confirmação. Usamos um processo separado de criação e implantação: montado e implantado em vários ambientes várias vezes. Nós estávamos nas janelas. Nas janelas que implantamos usando o Octopus deploy, este ano estamos desenvolvendo no DotNet Core. Portanto, agora podemos executar software em sistemas Linux. Deixamos Octopus e chegamos a Ansible. Hoje falaremos sobre essa parte, que é uma nova prática que desenvolvemos este ano, algo que não tínhamos antes. Quando você faz testes, quando sabe como construir bem o aplicativo, é bom implantá-lo em algum lugar. Mas se você tiver dois ambientes configurados de maneira diferente, ainda cairá e cairá na produção. Portanto, gerenciar configurações é uma prática muito importante. É sobre isso que falaremos hoje.

Descreverei brevemente como a economia de trabalho do produto é construída: 60 % são gastos em desenvolvimento , a análise leva em torno de 10 %, o controle de qualidade (teste) leva em torno de 20 % e tudo o mais é atribuído à configuração. Quando os sistemas entram em pleno fluxo, eles têm muitos softwares de terceiros, os próprios sistemas operacionais são configurados quase da mesma maneira. Passamos um tempo extra fazendo isso, essencialmente fazendo a mesma coisa. Havia uma idéia para automatizar tudo e reduzir o custo de configuração da infraestrutura. Tarefas semelhantes são automatizadas, bem depuradas e não contêm operações manuais.

Cada aplicativo funciona em algum tipo de ambiente. Vamos ver no que tudo isso consiste. No mínimo, precisamos ter um sistema operacional , ele precisa ser configurado, existem alguns aplicativos de terceiros que também precisam ser configurados, o próprio aplicativo deve receber as configurações, mas, para que todo o produto funcione, é necessário iniciar o próprio aplicativo, que opera em todo o sistema. Também há uma rede que também precisa ser configurada, mas não falaremos sobre a rede hoje, porque temos clientes diferentes, dispositivos de rede diferentes. Também tentamos automatizar a configuração da rede, mas como os dispositivos são diferentes, não houve nenhum benefício em particular, gastamos mais recursos nisso. Mas automatizamos os sistemas operacionais, aplicativos de terceiros e a transferência de parâmetros de configuração para os próprios aplicativos.

Existem duas abordagens sobre como você pode configurar os servidores: manualmente - se você configurá-los manualmente, poderá obter uma situação que configurou a produção de uma maneira, o teste do outro, tudo é verde no teste, os testes são verdes. Você implanta na produção e não há estrutura - nada funciona para você. Outro exemplo: três servidores de aplicativos são configurados manualmente. Um servidor de aplicativos foi configurado de uma maneira, outro servidor de aplicativos de uma maneira diferente. Servidores podem trabalhar de maneiras diferentes. Outro exemplo: houve uma situação em que um servidor Stage parou de funcionar completamente para nós. Começamos a criar um novo servidor usando e após 30 o servidor estava pronto. Outro exemplo: o servidor parou de funcionar. Se você o configurar com as mãos, precisará procurar uma pessoa que saiba como configurá-lo, precisará levantar a documentação. Como sabemos, a documentação é pouco relevante. Estes são grandes problemas. E, o mais importante, é uma auditoria, ou seja, você tem dez administradores, cada um com algo em mãos, não está muito claro se o configuraram de maneira correta ou incorreta e como entender se então as configurações, eles poderiam colocar algo supérfluo, abrir algumas portas desnecessárias.

Existe uma opção alternativa - é exatamente disso que estamos falando hoje - essa é a configuração do código. Ou seja, temos um repositório git no qual toda a infraestrutura é armazenada. Todos os scripts são armazenados lá, com a ajuda da qual iremos configurá-lo. Como tudo isso está no git, obtemos todos os benefícios do gerenciamento de código, como no desenvolvimento, ou seja, podemos fazer revisões, auditorias, histórico de alterações, quem fez, por que fez, comentários, podemos reverter. Para trabalhar com o código, você precisa usar o pipeline de montagem contínuo - o pipeline de implantação. Para que um sistema específico faça alterações nos servidores, ou seja, nenhuma pessoa faria algo com as mãos, mas o sistema faria exclusivamente.

Como o sistema que faz as alterações, usamos o Ansible. Como não temos um grande número de servidores, é bastante adequado para nós. Se você tiver 100-200 servidores lá, terá pequenos problemas, porque (isto é, Ansible) ainda se conecta a cada um e os configura por sua vez - isso é um problema. É melhor usar outros meios que não empurram, mas puxam. Mas para a nossa história, quando temos muitos projetos, mas não mais que 20 servidores, isso é bastante adequado para nós. O Ansible tem uma grande vantagem - é um baixo limite de entrada. Ou seja, literalmente, qualquer especialista em TI em três semanas pode dominá-lo completamente. Ele tem muitos módulos. Ou seja, você pode gerenciar nuvens, redes, arquivos, instalar programas, implantar - absolutamente tudo. Se não houver módulos, você pode escrever o seu próprio, pode finalmente escrever algo usando o shell Ansible ou o módulo de comando.

Em geral, consideraremos brevemente como ela geralmente parece, essa ferramenta. Ansible tem módulos que eu já falei. Ou seja, eles podem ser entregues, escritos por eles mesmos, que estão fazendo algo. Existem inventários - é aqui que iremos fazer as alterações, ou seja, esses são os hosts, seus endereços IP, variáveis específicas para esses hosts. E, consequentemente, o papel. Funções é o que vamos lançar nesses servidores. E também nossos hosts são agrupados em grupos, ou seja, nesse caso, vemos que temos dois grupos: o servidor de banco de dados e o servidor de aplicativos. Em cada grupo, temos três carros. Eles estão conectados via ssh. Assim, resolvemos os problemas de que falamos anteriormente, que, em primeiro lugar, nossos servidores são configurados de forma idêntica, uma vez que a mesma função rola para os servidores. E da mesma maneira, se executarmos essa função em várias máquinas, para cada uma funcionará da mesma maneira.
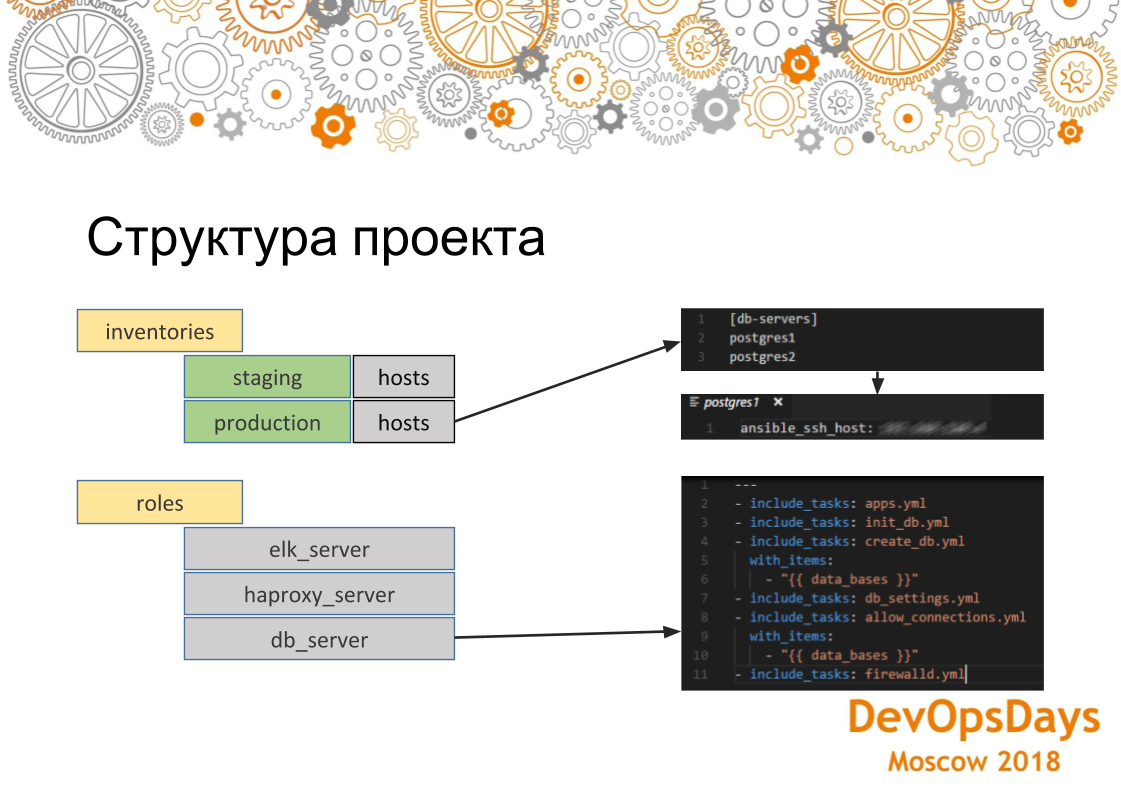
Se examinarmos mais detalhadamente como o projeto Ansible está estruturado, vemos aqui que os hosts são aceitáveis para os estoques de produção. Este grupo é indicado e há dois servidores nele. Se formos a um servidor específico, veremos que o endereço IP desta máquina está indicado aqui. Outros parâmetros também podem ser indicados lá - variáveis específicas para este ambiente. Se olharmos para os papéis. Essa função contém várias tarefas que serão executadas. Nesse caso, esse é o papel da instalação do PostgreSQL. Ou seja, instalamos o aplicativo necessário, criamos o banco de dados. Aqui usamos um loop. Eles (bancos de dados) serão criados um pouco. Em seguida, estabelecemos a conexão necessária - endereços IP que podem efetuar login neste banco de dados. E, consequentemente, configuramos no final do firewall. As configurações serão aplicadas a todos os servidores do grupo.

Basta abordar o problema em si: aprendemos a configurar o servidor usando o Ansible e tudo estava bem. Mas, como eu disse, temos muitos projetos. Eles são quase todos iguais. Alguns desses sistemas estão envolvidos em cada projeto (k8s, RabbitMQ, Vault, ELK, PostgreSQL, HAProxy). Para cada um, escrevemos um papel. Podemos rolar a partir do botão.

Mas temos muitos projetos, e em cada um eles se sobrepõem. Ou seja, em um desses conjuntos, no segundo, no terceiro. Temos pontos de interseção nos quais os mesmos papéis em diferentes projetos.

Temos um repositório com uma aplicação, temos um repositório com infraestrutura para o projeto. O segundo projeto tem exatamente o mesmo. Infraestrutura continuada. E o terceiro. Se implementarmos a mesma coisa, essencialmente copiar e colar será exibido. Faremos o mesmo papel em 10 lugares. Então, se houver algum erro, nós governaremos em 10 lugares.

O que fizemos: assumimos todas as funções comuns a todos os projetos e todas as suas configurações que vêm de fora para um repositório separado e as colocamos em um git em uma pasta separada - chamamos de Infraestrutura TYME. Lá, temos uma função para o PostgreSQL, para o ELK, para a implantação de clusters Kubernetes. Se precisarmos colocar algum projeto, digamos o mesmo PostgreSQL, basta ativá-lo como um submódulo, reescrever inventários, que é, grosso modo, a configuração em que desempenhar esse papel. Não reescrevemos o papel em si: ele já existe. E com o clique de um botão, o PostgreSQL aparece em todos os novos projetos. Se você precisar criar um cluster Kubernetes - a mesma coisa.

Assim, acabou por reduzir o custo de escrever papéis. Ou seja, eles escreveram uma vez - usaram 10 vezes. Quando o projeto segue o projeto - é muito conveniente. Mas como agora estamos trabalhando com a infraestrutura como um código, naturalmente precisamos dos pipelines sobre os quais falamos. As pessoas cometem erros no git, elas podem cometer algum tipo de erro - precisamos acompanhar tudo isso. Portanto, construímos exatamente esse pipeline. Ou seja, o desenvolvedor comete scripts Ansible no git. O Teamity os rastreia e os transfere para o Ansible. O Teamcity é necessário aqui por apenas um motivo: em primeiro lugar, ele possui uma interface visual (existe uma versão gratuita do Ansible Tower - AWX, que resolve o mesmo problema - aprox.). Diferentemente do Ansible free e, em princípio, temos o Teamcity como um único Ci. Então, em princípio, o Ansible tem um módulo que pode rastrear o git. Mas, neste caso, eles fizeram apenas à imagem e semelhança. E assim que ele o rastreia, ele transfere todo o código para Ansible e Ansible, respectivamente, executa-os no servidor de integração e altera a configuração. Se esse processo for violado, estamos analisando o que está errado, por que os scripts foram mal escritos.

O segundo ponto é que existe uma infraestrutura específica, aqui temos a infraestrutura implantada separadamente, o aplicativo é implantado separadamente. Porém, há uma infraestrutura específica para cada aplicativo, ou seja, que precisa ser implantada antes do lançamento. Aqui, portanto, é impossível transferi-lo para um pipeline diferente. Você deve implantá-lo no mesmo contêiner que o próprio aplicativo. Ou seja, digamos, estruturas são uma coisa popular quando você precisa instalar uma estrutura para um novo aplicativo e colocar outra estrutura para outra. Aqui está como com esta situação. Ou você precisa limpar os caches. Por exemplo, o Ansible também pode subir, limpar o cache.

Mas aqui usamos o docker em combinação com o Ansible. Ou seja, a infraestrutura específica de nós está na janela de encaixe, não específica na Ansible. E assim, compartilhamos esse pequeno delta no docker, tudo o mais, fundamental - no Ansible.

Um ponto muito importante - se você rolar a infraestrutura através de algum tipo de script, código, se ainda tiver manipulações manuais do servidor, essa será uma vulnerabilidade em potencial. Porque digamos que você coloque o java no servidor de teste, escreva a função ELK e faça a rolagem. A implantação no teste foi bem-sucedida. Implante na produção, mas não há java. E você não especificou java no script - a implantação na produção caiu. Portanto, você precisa tirar os direitos de todos os servidores dos administradores para que eles não entrem nele com suas mãos e façam todas as alterações através do git. Todo esse transportador pelo qual passamos. Há uma coisa, mas - não aperte muito as porcas. Ou seja, é necessário introduzir esse processo gradualmente. Porque ainda está sem cultivo. No nosso caso, deixamos o acesso a todos os sistemas na cabeça do administrador principal em caso de incidentes imprevistos. O acesso é concedido com a condição de que ele não configure nada manualmente.

Como o desenvolvimento funciona? Distribuição na preparação, a produção deve estar livre de erros. Algo poderia quebrar aqui. Se o lançamento no ambiente de integração cair constantemente em erros, será ruim. Isso é semelhante à depuração de aplicativos em uma máquina remota. Quando um desenvolvedor desenvolve tudo em uma máquina, compila-o. Se tudo compilar, envie-o para o repositório. Ele usa a mesma abordagem. Os desenvolvedores usam o Visual Studio Code com plug-ins Ansible, Vagrant, Docker, etc. Os desenvolvedores testam seu código de infraestrutura em um vagrant local. Surge um sistema operacional limpo. Os scripts para elevar essa máquina também estão neste repositório com a infraestrutura de que falamos. O desenvolvedor começa a instalar um servidor FTP nele. Se algo der errado, ele simplesmente a exclui, recarrega e tenta instalar o software necessário usando scripts de implantação. Depois de depurar os scripts de implantação, ele faz uma Solicitação de Mesclagem na ramificação principal. Após mesclar a solicitação de mesclagem, o IC reverte essas alterações para o servidor de integração.

Como todos os scripts são código, podemos escrever testes. Digamos que instalamos o PostgreSQL. Queremos verificar se funciona ou não. Para fazer isso, use o módulo de declaração Ansible. Compare a versão instalada do PostgreSQL com a versão nos scripts. Assim, entendemos que ele está instalado, geralmente está em execução, é a própria versão que esperávamos.

Vemos que o teste passou. Portanto, nosso manual de instruções funcionou corretamente. Você pode escrever quantos testes quiser. Eles são idempotentes. Idempotência (uma operação que, se aplicada a qualquer valor várias vezes, sempre resulta no mesmo valor que em um único aplicativo). Se você escrever scripts gratuitos para instalação e configuração, certifique-se de que seus scripts sempre obtenham o mesmo valor se forem executados várias vezes.

Há outro tipo de teste que não se relaciona diretamente ao teste de infraestrutura. Mas eles parecem afetá-lo indiretamente. Estes são testes de ponta a ponta. Temos a infraestrutura e os próprios aplicativos são instalados no mesmo servidor, testado pelos testadores. Se rolamos algum tipo de infraestrutura incorreta, apenas testes complexos não serão aprovados. Ou seja, nosso aplicativo funcionará de alguma maneira incorretamente. Neste exemplo, instalamos uma nova versão na produção - o aplicativo funciona. Em seguida, um commit foi feito nos testes git e de ponta a ponta, que ocorrem à noite, rastreando que aqui não temos um arquivo no ftp. Desmontamos esse caso e vemos que o problema está nas configurações de ftp. Corrigimos os scripts no código, implantamos novamente e tudo fica verde. A mesma história com o código. O código de infraestrutura e a infraestrutura são indiretamente testados de uma maneira ou de outra. Em seguida, podemos implantá-lo na produção.

Quando introduzimos essa abordagem, o CI (Teamcity), que implementou alterações no servidor de integração, caiu 8 vezes em 10. Ninguém prestou atenção a ela porque não havia feedback. Para os desenvolvedores, esses processos foram implementados por um longo tempo, mas as mensagens não chegaram ao OPS (administradores de sistema). Portanto, adicionamos um painel com as montagens deste projeto a um monitor grande em um local de destaque no escritório. Nele, vários projetos são destacados em verde - isso significa que tudo está em ordem com ele. Se destacado em vermelho, significa que tudo está ruim com ele. Vimos que alguns testes falharam. Na apresentação, no lado esquerdo da segunda, de cima, vemos o resultado das implantações de implantação . , , , . : - . . Slack , - - - .

Ok, , , - , . trunk based . Master — . Master CI (Teamcity) integration . CI , integration . release candidate. . . , end-to-end , staging . production. , staging .

. ? , PostgreSQL. 5 . , . 1-2 . . , PostgreSQL . PostgreSQL , staging, production 4 . , , . , . - .

git submodule Ansible . , . git submodule Ansible . inventories , . 30 . git submodule .

: , . , , , staging , . , , , , , , staging. — , , - .

6 . — 10 . . . , . - git submodule, . . , , , . , , .

.
-, , : , Ansible git , : “ , - ”. ? git . , . 100% . . .
, . . , RabbitMQ, ELK, . , ELK . , , ELK. ELK, , ELK .
, , , , . , , , , . , . .
. , , , , , , . git. , — git, , : , - . .
, , , code review. , , . , . , , , , , . , : . . . , - - .
, .
: , git submodule, . - , latest . inventories. — , . , , .. . — . .
: - Ansible ( A B, B C A, )? , ?
: . . , - IP , , , , . . , , , , , . , - , , , RabbitMQ RabbitMQ, . - , .
PS: Sugiro que todos os interessados em conjunto no github traduzam relatórios interessantes de conferências para o texto. Você pode formar um grupo no github para tradução. Até agora, estou traduzindo para texto na minha conta do github - você também pode enviar uma solicitação Pull para corrigir um artigo lá.