Durante o ano passado, o tópico de inteligência cibernética ou Inteligência de Ameaças ganhou popularidade crescente na corrida por armas cibernéticas entre atacantes e defensores. Obviamente, a obtenção proativa de informações sobre ameaças cibernéticas é uma coisa muito útil, mas não protege a infraestrutura por si só. É necessário criar um processo que ajude a gerenciar corretamente as informações sobre o método de um possível ataque e o tempo disponível para prepará-lo. E a principal condição para a formação de um processo desse tipo é a integridade das informações sobre ameaças cibernéticas.

Os dados primários da Inteligência contra ameaças podem ser obtidos em uma ampla variedade de fontes. Podem ser
assinaturas gratuitas , informações de parceiros, uma equipe de investigação técnica da empresa etc.
Há três estágios principais no trabalho com as informações obtidas através do processo de Inteligência contra Ameaças (embora, como centro de monitoramento e resposta a ataques cibernéticos, tenhamos um quarto estágio - notificar os clientes sobre a ameaça):
- Obtendo informações, processamento primário.
- Detecção de indicadores de comprometimento (indicador de compromisso, COI).
- Verificação retrospectiva.
Aquisição de informações, processamento primário
O primeiro estágio pode ser chamado de mais criativo. Compreender corretamente a descrição de uma nova ameaça, destacar indicadores relevantes, determinar sua aplicabilidade a uma organização específica, filtrar informações desnecessárias sobre ataques (por exemplo, direcionados para determinadas regiões) - tudo isso costuma ser uma tarefa difícil. Ao mesmo tempo, existem fontes que fornecem dados exclusivamente verificados e relevantes que podem ser adicionados ao banco de dados automaticamente.
Para uma abordagem sistemática ao processamento de informações, recomendamos dividir os indicadores obtidos na estrutura do Threat Intelligence em dois grandes grupos - host e rede. A detecção de indicadores de rede não significa um comprometimento inequívoco do sistema, mas a detecção de indicadores de host, como regra, sinaliza de maneira confiável o sucesso de um ataque.
Os indicadores de rede incluem domínios, URLs, endereços de email, um conjunto de endereços IP e portas. Os indicadores do host estão executando processos, alterações nas ramificações e arquivos do registro, valores de hash.
Indicadores recebidos como parte de um único alerta de ameaça, faz sentido combinar em um grupo. No caso da detecção de indicadores, isso facilita muito a determinação do tipo de ataque e também facilita a verificação do sistema potencialmente comprometido para todos os indicadores possíveis de um relatório de ameaças específico.
No entanto, muitas vezes é preciso lidar com indicadores, cuja detecção não nos permite falar inequivocamente sobre um sistema comprometido. Podem ser endereços IP pertencentes a grandes empresas e redes de hospedagem, domínios de correio de serviços de correio de publicidade, nomes e somas de hash de arquivos executáveis legítimos. Os exemplos mais simples são os endereços IP da Microsoft, Amazon, CloudFlare, que geralmente são listados, ou processos legítimos que aparecem no sistema após a instalação de pacotes de software, por exemplo, pageant.exe, um agente para armazenar chaves. Para evitar um grande número de falsos positivos, é melhor filtrar esses indicadores, mas, digamos, não os jogue fora - a maioria deles não é totalmente inútil. Se houver suspeita de um sistema comprometido, uma verificação completa é realizada em todos os indicadores, e a detecção de um indicador indireto pode confirmar essas suspeitas.
Como nem todos os indicadores são igualmente úteis, no Solar JSOC usamos o chamado peso do indicador. Por convenção, a detecção de um lançamento de arquivo, cuja soma de hash coincide com o hash do arquivo executável malicioso, tem um peso limite. A detecção de um indicador desse tipo leva instantaneamente à ocorrência de um evento de segurança da informação. Um único acesso ao endereço IP de um host potencialmente perigoso em uma porta não específica não levará a um evento de IB, mas entrará em um perfil especial que acumula estatísticas, e a detecção de novas chamadas também levará a uma investigação.
Ao mesmo tempo, existem mecanismos que nos pareciam razoáveis no momento da criação, mas que acabaram sendo reconhecidos como ineficazes. Por exemplo, foi inicialmente estabelecido que certos tipos de indicadores terão uma vida útil limitada, após o que serão desativados. No entanto, como a prática demonstrou, ao conectar-se a uma nova infraestrutura, às vezes são encontrados hosts que foram infectados por vários tipos de malware há anos. Por exemplo, uma vez ao conectar um cliente, o vírus Corkow foi detectado na máquina do chefe de SI (na época, os indicadores tinham mais de cinco anos) e outras investigações revelaram um backdoor e keylogger explorados no host.
Detecção de indicadores de compromisso
Trabalhamos com muitas instalações de vários sistemas SIEM, no entanto, a estrutura geral dos registros que se enquadram no banco de dados de indicadores é padronizada e tem a seguinte aparência:
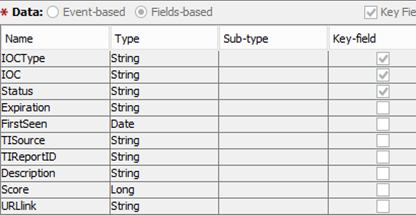
Por exemplo, classificando os indicadores por TIReportID, você pode encontrar todos os indicadores que apareceram na descrição de uma ameaça específica e, clicando no link URL, você pode obter uma descrição detalhada dela.
Ao criar o processo de Inteligência de Ameaças, é muito importante analisar os sistemas de informações conectados ao SIEM em termos de utilidade para identificar indicadores de comprometimento.
O fato é que a descrição do ataque geralmente inclui vários tipos de indicadores de comprometimento - por exemplo, a quantidade de hash do malware, o endereço IP do servidor SS no qual ele está batendo e assim por diante. Mas se os endereços IP acessados pelo host forem monitorados por vários meios de proteção, é muito mais difícil obter informações sobre os valores de hash. Portanto, consideramos todos os sistemas que podem servir como fonte de qualquer log do ponto de vista de quais indicadores eles podem rastrear:
Tipo de indicador
| Tipo de fonte
|
Domínio
| Servidores proxy, NGFW, servidores DNS
|
URL
|
Soquete
| Proxies, NGFW, FW
|
Mail
| Servidores de Correio, Antispam, DLP
|
Processo
| Logs do host, DB AVPO, Sysmon
|
Registo
| Logs do host
|
Soma de hash
| Logs do host, DB AVPO, Sysmon, Sandboxes CMDB
|
Esquematicamente, o processo de detecção de indicadores de comprometimento pode ser representado da seguinte forma:

Eu já falei sobre os dois primeiros pontos acima, agora um pouco mais sobre a verificação do COI. Por exemplo, pegaremos os eventos que contêm informações sobre endereços IP. A regra de correlação para cada evento realiza quatro verificações possíveis com base em indicadores:

A pesquisa é realizada por indicadores relevantes do tipo Socket, enquanto o design geral do endereço IP e a porta correspondente são verificados quanto à conformidade com o indicador. Porque a porta específica nem sempre é indicada nas informações de ameaça, o IP: qualquer construção verifica se o endereço no banco de dados tem uma porta indefinida.
Um design semelhante é implementado em uma regra que detecta indicadores de comprometimento em eventos de alteração do registro. Nas informações recebidas geralmente não há dados sobre uma chave ou valor específico; portanto, quando um indicador é inserido no banco de dados, os dados desconhecidos ou sem um valor exato são substituídos por 'any'. As opções finais de pesquisa são as seguintes:

Tendo encontrado o indicador de comprometimento nos logs, a regra de correlação cria um evento de correlação marcado com a categoria que a regra de incidente processa (discutimos isso em detalhes no artigo “
Cozinha DIREITA ”).
Além da categoria, o evento de correlação será complementado com informações em que alerta ou relatório esse indicador apareceu, seu peso, dados de ameaças e um link para a fonte. O processamento adicional de eventos de detecção de indicadores de todos os tipos é realizado pela regra do incidente. Seu trabalho pode ser apresentado esquematicamente da seguinte maneira:

Mas, é claro, você deve ter em mente as exceções: em quase qualquer infraestrutura, existem dispositivos cujas ações são legítimas, apesar do fato de que elas contêm formalmente sinais de um sistema comprometido. Esses dispositivos geralmente incluem caixas de areia, vários scanners etc.
A necessidade de correlacionar os eventos de detecção de indicadores de diferentes tipos também se deve ao fato de indicadores heterogêneos estarem frequentemente presentes em informações sobre ameaças.
Consequentemente, um agrupamento de eventos de detecção de indicadores pode permitir que você veja toda a cadeia de ataques desde o momento da penetração até a operação.
Propomos considerar a implementação de um dos seguintes cenários como um evento de segurança da informação:
- Detecção de um indicador de compromisso altamente relevante.
- Detecção de dois indicadores diferentes em um relatório.
- Atingindo o limite.
Com as duas primeiras opções, tudo fica claro, e a terceira é necessária quando não temos dados além da atividade de rede do sistema.
Verificação retrospectiva dos indicadores de comprometimento
Depois de receber informações sobre a ameaça, identificar indicadores e organizar sua identificação, é necessária uma verificação retrospectiva que permita detectar um comprometimento que já ocorreu.
Se eu me aprofundar um pouco mais sobre como isso funciona no SOC, posso dizer que esse processo requer uma quantidade verdadeiramente colossal de tempo e recursos. A busca por indicadores de comprometimento nos registros por meio ano nos obriga a manter uma quantidade impressionante deles disponível para verificações on-line. Além disso, o resultado da verificação deve ser não apenas informações sobre a presença de indicadores, mas também dados gerais sobre o desenvolvimento do ataque. Ao conectar novos sistemas de informações do cliente, os dados deles também devem ser verificados quanto a indicadores. Para isso, é necessário refinar constantemente o chamado "conteúdo" do SOC - regras de correlação e indicadores de comprometimento.
Para o sistema ArcSight SIEM, mesmo essa pesquisa nas últimas semanas pode levar muito tempo. Por isso, foi decidido aproveitar as tendências.
"Uma tendência é um recurso do ESM que define como e em que período os dados serão agregados e avaliados quanto às tendências ou correntes prevalecentes. Uma tendência executa uma consulta especificada em um horário definido e duração. ”
ESM_101_Guide
Após vários testes em sistemas carregados, o seguinte algoritmo para o uso de tendências foi desenvolvido:

As regras de criação de perfil que preenchem as folhas ativas correspondentes com dados úteis permitem distribuir a carga total no SIEM. Após o recebimento dos indicadores, as solicitações são criadas nas planilhas e tendências correspondentes, com base em quais relatórios serão feitos, que por sua vez serão distribuídos por todas as instalações. De fato, resta apenas executar relatórios e processar os resultados.
Vale ressaltar que o processo de processamento pode ser continuamente aprimorado e automatizado. Por exemplo, introduzimos uma plataforma para armazenar e processar indicadores de comprometimento MISP, que atualmente atendem aos nossos requisitos de flexibilidade e funcionalidade. Seus análogos estão amplamente representados no mercado de código aberto - YETI, estrangeiro - Anomali ThreatStream, ThreatConnect, ThreatQuotinet, EclecticIQ, russo - TI.Platform, R-Vision Threat Intelligence Platform. Agora, estamos realizando testes finais do descarregamento automatizado de eventos diretamente do banco de dados SIEM. Isso agilizará bastante o relatório de indicadores de comprometimento.
O principal elemento da inteligência cibernética
No entanto, o elo final no processamento dos próprios indicadores e dos relatórios são engenheiros e analistas, e as ferramentas listadas acima apenas ajudam na tomada de decisões. Em nosso país, o grupo de resposta é responsável por adicionar indicadores, e o grupo de monitoramento é responsável pela exatidão dos relatórios.
Sem pessoas, o sistema não funcionará adequadamente o suficiente; você não pode prever todas as pequenas coisas e exceções. Por exemplo, observamos chamadas para os endereços IP dos nós TOR, mas nos relatórios para o cliente compartilhamos a atividade do host comprometido e do host no qual o Navegador TOR foi simplesmente instalado. É possível automatizá-lo, mas é bastante difícil pensar em todos esses pontos com antecedência ao definir as regras. Portanto, o grupo de resposta, de acordo com vários critérios, elimina indicadores que criarão um grande número de falsos positivos. E vice-versa - pode ser adicionado um indicador específico que é altamente relevante para alguns clientes (por exemplo, o setor financeiro).
O grupo de monitoramento pode remover a atividade da área restrita do relatório final, verificar os administradores quanto ao bloqueio bem-sucedido de um recurso malicioso, mas adicionar atividades sobre a verificação externa sem êxito, mostrando ao cliente que sua infraestrutura está sendo verificada pelos invasores. A máquina não tomará essas decisões.

Em vez de saída
Por que recomendamos esse método de trabalho com a Threat Intelligence? Primeiro de tudo, ele permite que você se afaste do esquema, quando, para cada novo ataque, é necessário criar uma regra de correlação separada. Isso leva um tempo inaceitavelmente longo e revela apenas o ataque em andamento.
O método descrito aproveita ao máximo os recursos de TI - você só precisa adicionar indicadores, e isso leva no máximo 20 minutos a partir do momento em que eles aparecem e, em seguida, realiza uma verificação retrospectiva completa dos logs. Assim, você reduzirá o tempo de resposta e obterá resultados de teste mais completos.
Se você tiver alguma dúvida, bem-vindo ao comentar.