
Hoje, o desenvolvimento rápido e eficiente de software é impensável sem fluxos de trabalho aprimorados: cada componente é transferido para a montagem no momento da instalação, o produto não fica ocioso. Há dois anos, juntamente com a M.Video, começamos a introduzir essa abordagem no processo de desenvolvimento no varejista e hoje continuamos a desenvolvê-la. Quais são os subtotais? O resultado foi totalmente recompensado: graças às alterações implementadas, foi possível acelerar o lançamento de lançamentos em 20 a 30%. Quer alguns detalhes? Welcom em nossos bastidores.
De Scrum para Kanban
Antes de tudo, uma mudança na metodologia foi implementada - a transição do Scrum, ou seja, o modelo de sprint, para o Kanban. Anteriormente, o processo de desenvolvimento era assim:

Há um ramo de desenvolvimento, há sprints para cinco equipes. Eles codificam em seus próprios ramos de desenvolvimento, os sprints terminam no mesmo dia e todas as equipes combinam os resultados de seu trabalho com o ramo mestre no mesmo dia. Depois disso, os testes de regressão são executados por cinco dias, depois a ramificação é dada ao ambiente piloto e depois ao produtivo. Porém, antes de iniciar os testes de regressão, demorou de dois a três dias para estabilizar a ramificação principal, removendo conflitos após a fusão com as ramificações de comando.
Qual é a vantagem do Kanban? As equipes não esperam o final do sprint, mas combinam suas alterações locais com a ramificação principal após a conclusão da tarefa, sempre verificando conflitos de colisão. No dia marcado, todas as associações com o mestre são bloqueadas e os testes de regressão são iniciados.
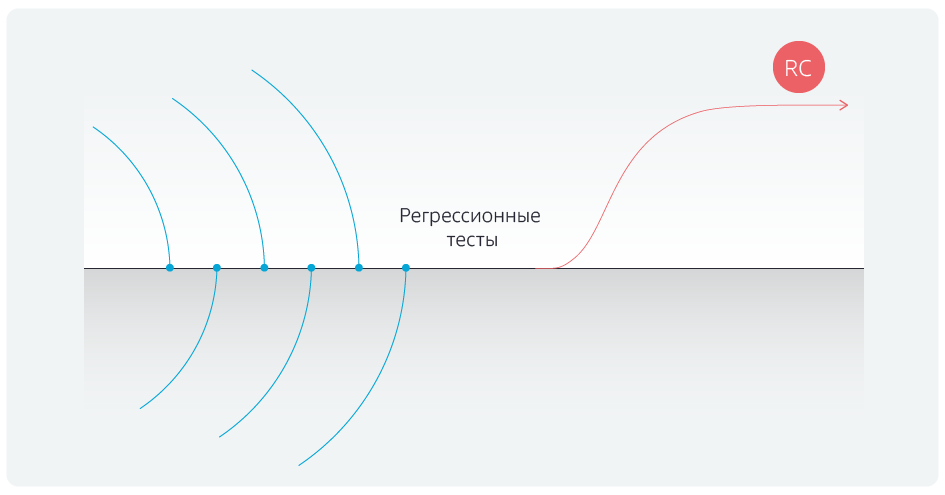
Como resultado, conseguimos nos livrar de constantes mudanças de termos para a direita, regressões
sem atraso, o candidato a liberação é enviado no prazo.
Automação onipresente
Obviamente, apenas mudar a metodologia não foi suficiente. A segunda etapa, nós, juntamente com o varejista, automatizamos os testes. No total, são testados cerca de 900 cenários, divididos em grupos por prioridade.
Cerca de 100 cenários são os chamados bloqueadores. Eles devem trabalhar no site - a loja online M.Video - mesmo durante uma guerra atômica. Se um dos bloqueadores não funcionar, existem grandes problemas no site. Por exemplo, os bloqueadores incluem um mecanismo para comprar mercadorias, aplicar descontos, autorização, registrar usuários, fazer um pedido de crédito, etc.
Cerca de 300 outros cenários são críticos. Isso inclui, por exemplo, a capacidade de selecionar produtos usando filtros. Se esse recurso quebrar, é improvável que os usuários comprem mercadorias, mesmo que os mecanismos de compra e pesquisa direta no catálogo funcionem.
Outros cenários são maiores e menores. Se eles não funcionarem, as pessoas ganharão experiência negativa usando o site. Isso inclui muitos problemas de importância e visibilidade variadas para o usuário. Por exemplo, o layout (principal) foi, a descrição do estoque (menor) não é exibida, a sugestão automática de senhas na conta pessoal (menor) não funciona, a recuperação (principal) não funciona.
Juntamente com a M.Video, automatizamos o teste de bloqueadores em 95%, dos demais cenários - em cerca de 50%. Por que metade não é automatizada? Existem muitas razões, e diferentes. Existem cenários a priori não passíveis de automação. Existem casos complexos de integração, cuja preparação requer trabalho manual, por exemplo, ligar para o banco e cancelar um pedido de empréstimo, entrar em contato com o departamento de vendas e cancelar pedidos em um ambiente produtivo.
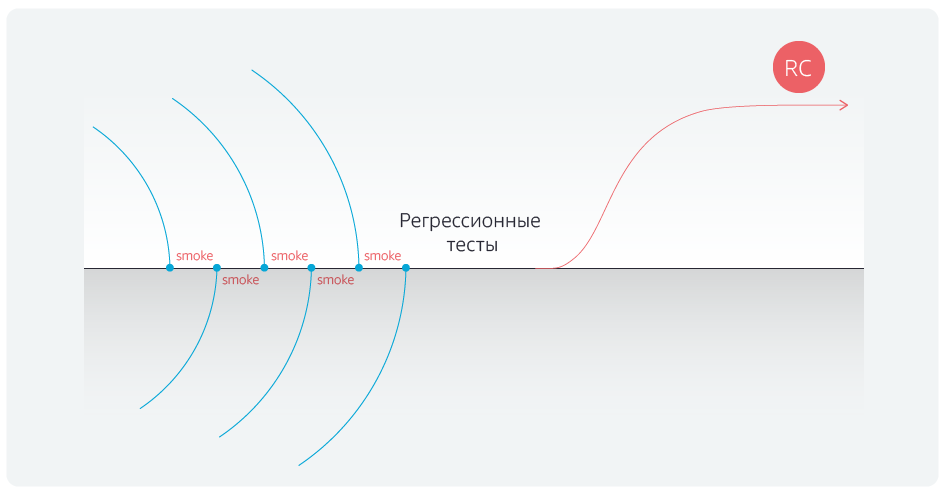
A automação dos testes de regressão reduziu sua duração. Mas fomos mais longe e automatizamos testes de fumaça para bloqueadores após cada mesclagem das ramificações de comando com a ramificação mestre.
Depois de automatizar os testes, finalmente nos livramos dos atrasos após concluir as associações com a ramificação principal.
Maxixe para o resgate
Para consolidar o sucesso, nossa equipe reformulou os testes eles mesmos. Anteriormente, eram tabelas: ação → resultado esperado → resultado real. Por exemplo, entrei no site com esse nome de usuário e senha; resultado esperado: tudo está em ordem; o resultado real também está bom, vou para outras páginas. Foram cenários complicados.
Nós os traduzimos para a notação Gherkin e automatizamos algumas das etapas. Vamos
usar a mesma autorização no site, o script agora está formulado da seguinte forma: "
como usuário do site, entrei com os dados da autorização e o procedimento foi bem-sucedido ". Além disso, o “
usuário do site ” e o “
logado com os dados da autorização ” são listados em tabelas separadas. Agora podemos executar rapidamente casos de teste, independentemente dos dados.
Qual é o valor desta etapa? Digamos que um testador esteja envolvido no teste de um projeto. Ele não dá a mínima para como ele escreve testes, ele pode fazer verificações mesmo na forma de uma lista de verificação: "a autorização é verificada, o registro é verificado, a compra é verificada por cartão, a compra por Yandex. O dinheiro é verificado - eu sou bonito". Uma nova pessoa chega e pergunta: você fez login por email ou pelo Facebook? Como resultado, a lista de verificação se transforma em um script.
Cinco equipes trabalham no projeto e cada equipe tem pelo menos dois testadores. Anteriormente, cada um deles escrevia testes como quisesse e, como resultado, os testes só podiam ser suportados por seus autores. Com a automação, tudo ficou sem graça: você precisa recrutar engenheiros de automação separados que traduzem todo o zoológico de testes em uma linguagem de script ou esquecer a automação como um fenômeno. A Gherkin ajudou a mudar tudo: com a ajuda dessa linguagem de script, criamos "cubos" - autorização, cesta, pagamento etc. - a partir dos quais os testadores agora coletam vários scripts. Quando você precisa criar um novo script, uma pessoa não o escreve do zero, mas simplesmente puxa os blocos necessários na forma de autotestes. As notações Gherkin treinaram todos os testadores funcionais e agora podem interagir independentemente com a automação, scripts de suporte e analisar resultados.
Nós não paramos por aí.
Blocos funcionais
Digamos que o release 1 seja a funcionalidade que já está no site. No release 2, queríamos fazer algumas alterações nos cenários de usuário e de negócios e, como resultado, parte dos testes parou de funcionar porque a funcionalidade foi alterada.
Estruturamos o sistema de armazenamento de teste: o dividimos em blocos funcionais, por exemplo, "conta pessoal", "compra" etc. Agora, quando um novo script de usuário é introduzido, os blocos funcionais necessários já estão marcados com marcações.
Graças a isso, depois de combinar com a ramificação principal, os desenvolvedores podem verificar o trabalho não apenas dos bloqueadores, mas também dos scripts relacionados à área de assunto em que as alterações feitas afetam.
A segunda consequência é que ficou muito mais fácil manter os testes eles mesmos. Por exemplo, se algo mudou em sua conta pessoal, ao fazer um pedido e entrega, não precisamos agitar todo o modelo de regressão, porque os blocos funcionais alterados ficam imediatamente visíveis. Ou seja, manter o conjunto de testes atualizado se tornou mais rápido e, portanto, mais barato.
O problema com as arquibancadas
Ninguém costumava testar o desempenho dos estandes antes do teste de aceitação. Por exemplo, eles nos fornecem um banco de testes, realizamos testes de regressão por várias horas. Eles caem, entendem, consertam, executam testes novamente. Ou seja, perdemos tempo na depuração e execuções repetidas.
O problema foi resolvido de maneira simples: eles escreveram um total de 15 testes de API que verificam a configuração dos estandes, que não estão relacionados à funcionalidade. Os testes são independentes da versão de compilação; eles apenas verificam todos os pontos de integração críticos para a passagem de scripts.
Isso ajudou a economizar muito tempo. De fato, antes da automação, tínhamos 14 testadores, as verificações eram complicadas e demoradas, havia scripts para quase todo o dia de trabalho, consistindo em 150 etapas. E aqui você está testando e, em algum ponto da etapa 30–40–110, você percebe que o suporte não está funcionando. Multiplicamos o tempo de trabalho perdido por 14 pessoas e ficamos horrorizados. Após a introdução da automação e teste dos estandes, conseguimos reduzir pela metade o número de testadores e eliminar o tempo de inatividade, o que trouxe muita alegria ao contador-chefe.
Cerejas no bolo
A primeira cereja é o fluxo de erros. Formalmente, esse é o ciclo de vida de qualquer bug, mas de fato de qualquer entidade. Por exemplo, operamos nesse conceito em Jira. Um status adicional nos permitiu acelerar os lançamentos.
Em geral, o processo se parece com o seguinte: eles encontraram um incidente, o levaram ao trabalho, o concluíram, o entregaram ao teste, o testaram e o fecharam.

Entendemos que o defeito foi fechado, o problema foi resolvido. E eles adicionaram outro status: "para teste de regressão". Isso significa que após a análise, os cenários que detectam erros críticos são adicionados ao conjunto de regressão de 900 cenários. Se eles não estavam lá, ou se tinham detalhes insuficientes, temos um feedback instantâneo sobre o estado do produtivo ou piloto.

Ou seja, entendemos que há um problema e, por algum motivo, não o levamos em consideração. E agora, adicionar um script de verificação de bug economiza muito tempo.
Também introduzimos uma retrospectiva no nível dos testes. É assim: eles compilaram um tablet “número da versão, número de bugs, número de bloqueadores e outros scripts e número de resoluções”. Ao mesmo tempo, estimamos o número de resoluções inválidas. Por exemplo, se você obtiver 15 bugs inválidos em 40 bugs, esse é um indicador muito ruim; os testadores estão perdendo não apenas seu tempo, mas também o tempo dos desenvolvedores que trabalham nesses bugs. Os caras começaram a refletir, lidar com isso, introduziram o procedimento para revisar bugs por testadores mais experientes antes de enviá-los para o desenvolvimento. E eles fizeram isso muito bem.
Assim, há constante reflexão e trabalho para melhorar a qualidade. Todos os erros do produto são analisados: um teste é criado para cada erro, que é imediatamente incluído no conjunto de regressão. Se possível, esse teste é automatizado e é executado regularmente.
Resultados
Inicialmente, foi planejado aumentar a frequência de lançamentos e reduzir o número de erros, mas o resultado excedeu um pouco as expectativas. Um processo de automação razoavelmente construído tornou possível aumentar o número de testes automatizados em um curto espaço de tempo, e a análise de erros perdidos permitiu que a equipe de desenvolvimento e teste priorizasse os scripts de maneira otimizada e se concentrasse nos mais importantes.
Resultados da automação:
- até 4 dias (em vez dos 10 anteriores) reduziram a duração dos testes de regressão;
- equipe de teste manual diminuiu 50%;
- de 30 a 35 para 25 dias, o tempo de duração do mercado foi reduzido - desde o momento em que um recurso entrou no backlog da equipe até entrar no piloto.
Equipe de automação de teste, Jet Infosystems