No ano passado, uma onda de artigos sobre festas no Vale do Silício, com alguma atmosfera de Hollywood, mas sem especificar nomes específicos, fotografias e sem descrever o desenvolvimento de hardware e as tecnologias de escrita de software associadas a esses nomes, passou uma onda de artigos na imprensa russa e ucraniana. Este artigo é diferente! Também terá bilionários, gênios e meninas, mas com fotos, slides, diagramas e fragmentos do código do programa. Então:
Outro dia, o prefeito de Campbell, com o nome russo Paul Resnikoff, cortou a fita na abertura do novo escritório de startups da Wave Computing, que, juntamente com a Broadcom, está desenvolvendo um chip de 7 nanômetros para acelerar o cálculo das redes neurais. O escritório está localizado no edifício da histórica fábrica de frutas e conservas do final do século XIX e início do século XX, quando o Vale do Silício era o maior pomar do mundo. Mesmo assim, o escritório se dedicou à inovação, introduzindo o primeiro motor elétrico para transportadores da indústria da ameixa-damasco, para o qual trabalhavam cerca de 200 funcionários, principalmente mulheres.
Na festa que se seguiu ao corte da fita, muitas pessoas famosas da indústria foram destacadas, incluindo o camarada de armas de Kernigan-Richey e autor do compilador C mais popular do final dos anos 70 e início dos anos 80, Stephen Johnson, um dos autores do padrão para números de ponto flutuante Jerome Kunen, inventor conceitos de barramento local e o primeiro desenvolvedor de chipset PC AT Diosdado Banatao, ex-desenvolvedores dos processadores Sun, DEC, Cyrix, Intel, AMD e Silicon Graphics, chips Qualcomm, Xilinx e Cypress, analistas industriais, uma garota de cabelos ruivos e outros habitantes da Califórnia empresa deste tipo.
No final do post, falaremos sobre os livros a serem lidos e os exercícios a serem feitos para ingressar nesta comunidade.
Vamos começar com Jerome Kunen, um inovador em aritmética de ponto flutuante e gerente da Apple desde o primeiro Macintosh.
As dissertações de candidatos não são tão comuns que afetam a computação em bilhões de dispositivos. Diser, de Jerome Kunen (à esquerda), contribuiu para uma proposta de norma para aritmética binária de ponto flutuante, cujos resultados foram incluídos nos números de ponto flutuante da norma IEEE 754. Depois de se formar na escola de Berkeley em 1982, Jerome foi trabalhar na Apple, onde introduziu a biblioteca de ponto flutuante no primeiro Macintosh.
Após 10 anos de gerenciamento na Apple, Kunen aconselhou a Hewlett-Packard e a Microsoft e, em 2000, otimizou a aritmética de 128 bits para a nova versão x86 de 64 bits da AMD. Recentemente, Jerome voltou sua atenção para a pesquisa de padrões de ponto flutuante para redes neurais, em particular disputas sobre Unum e Posit. Unum é o novo padrão proposto, promovido pelo cientista da Caltech John Gustafson, autor do agora barulhento livro The End of Error, "The End of Error". O Posit é uma versão do Unum que pode ser implementada com mais eficiência (*) que o Unum no hardware.
(*) Mais eficiente na combinação de parâmetros: freqüência do relógio, número de ciclos por operação, taxa de transferência do transportador, área relativa no chip e consumo de energia relativo.

Imagens de artigos (não de Jerome)
Tornando a matemática de ponto flutuante altamente eficiente para hardware de IA e
Vencendo o ponto flutuante no seu próprio jogo: Posit Aritmetic de John L. Gustafson e Isaac Yonemoto :

Mas na festa Stephen / Steve Johnson é a pessoa em cujo compilador a linguagem de programação C se tornou popular. O primeiro compilador C foi escrito por Denis Ritchie, mas o compilador Richie estava fortemente vinculado à arquitetura PDP-11. Steve Johnson, baseado no trabalho de Alan Snyder, escreveu em meados da década de 1970 o Portable C Compiler (PCC), que era fácil de refazer para gerar código para diferentes arquiteturas. Ao mesmo tempo, o compilador Johnson foi rápido e otimizador. Como ele conseguiu isso?
Na entrada do PCC, Steve Johnson usou o analisador LALR (1) gerado pelo YACC (Yet Another Compiler Compiler), também de autoria de Steve Johnson. Depois disso, a tarefa de compilação foi reduzida para manipular árvores em funções recursivas e gerar código a partir da tabela de modelos. Algumas dessas funções recursivas eram independentes da máquina, a outra parte foi escrita por pessoas que transferiram o PCC para outra máquina. A tabela de modelos consistia em entradas de regra do tipo "se um registro do tipo A e dois registros do tipo B estiverem livres, reconstrua a árvore em um nó do tipo C e gere código com uma sequência D". A mesa era dependente da máquina.
Devido à combinação de elegância, flexibilidade e eficiência, o compilador PCC foi transportado para mais de 200 arquiteturas - de PDP, VAX, IBM / 370, x86 ao BESM-6 soviético e Orbit 20-700 (um computador de bordo nas versões anteriores do MiG-29). Segundo Denis Ritchie, quase todos os compiladores C do início dos anos 80 eram baseados no PCC. No mundo BSD Unix, o PCC foi substituído como o compilador GNU GCC somente padrão em 1994.
Além do PCC e da Yacc, Steve Johnson também é o autor do programa de verificação do programa Lint original (consulte, por exemplo, o
artigo de 1978 ). Os nomes dos programas Yacc e Lint tornaram-se substantivos comuns. Nos anos 2000, Steve reescreveu o front end do MATLAB e escreveu o MLint. Agora, Steve Johnson está ocupado com a tarefa de paralelizar os algoritmos para calcular redes neurais em dispositivos como CGRA (Coarse-Grained Reconfigurable Architecture), com dezenas de milhares de elementos semelhantes a processadores que são distribuídos por tensores através de uma rede de dezenas de milhares de comutadores dentro de um chip massivo com bilhões de transistores:

Mas com um copo de vinho, o bilionário Diosdado Banatao, fundador da Chips & Technologies, S3 Graphics e investidor na Marvell. Se você programou um PC IBM em 1985-1988, quando ele apareceu pela primeira vez na URSS, talvez saiba que na maioria dos AT-sheks com gráficos EGA e VGA havia chipsets da Chips & Technologies, lançados simultaneamente com os da IBM. Os primeiros chipsets da C&T foram projetados por Banatao, que havia aprendido a ser engenheiro eletrônico em Stanford, e antes de Stanford trabalhar como engenheiro na Boeing. Em 1987, a Intel adquiriu a Chips & Technologies.


À esquerda, na imagem abaixo, está John Bourgoin, presidente da MIPS Technologies desde seu pico nos anos 2000, quando chips com núcleos MIPS estavam dentro da maioria dos aparelhos de DVD, câmeras digitais e TVs, com chipsets da Zoran, Sigma Design, Realtek, Broadcom e outras empresas. Antes disso, John era presidente da MIPS Silicon Graphics desde 1996, quando os processadores MIPS estavam dentro das estações de trabalho da Silicon Graphics que Hollywood usava para gravar os primeiros filmes realistas em 3D do Jurassic Park. Antes da Silicon Graphics, John era um dos vice-presidentes da AMD desde 1976.
Art Swift, à direita, foi vice-presidente de marketing da MIPS na década de 2000 e, antes disso, na década de 1980, trabalhou como engenheiro na Fairchild Semiconductor (sim, essa), depois vice-presidente de marketing da Sun, DEC, Cirrus Logic e Presidente da Transmet. Recentemente, Art foi vice-presidente do comitê de marketing do RISC-V e familiarizou-se com Syntacore e CloudBear na Rússia nessa posição. E agora ele se tornou o presidente do MIPS IP da Wave:

Os slides da
apresentação sobre a história do MIPS estão relacionados ao período em que o MIPS foi controlado por John Bourgoin, na figura acima, à esquerda:

A empresa Transmet, cujo presidente foi Art Swift por algum tempo, na foto acima, à direita, lançou o processador Crusoe no final dos anos 90, que podia seguir as instruções x86 e chegou ao mercado em sub-laptops Toshiba Libretto L, NEC e Sharp , thin client da Compaq. Sua vantagem competitiva sobre a Intel e a AMD estava definida para controlar o baixo consumo de energia.
A implementação e a verificação diretas do pacote x86 completo são uma tarefa muito cara, por isso a Transmeta seguiu o caminho contrário, que se assemelha ao caminho da empresa russa MTsST com o processador Elbrus (a linha que começou com Elbrus 2000 e agora é apresentada como Elbrus 8C). Transmeta e Elbrus foram baseados em um processador estruturalmente simples com uma microarquitetura VLIW, e o nível de emulação x86 funcionou sobre ele usando a tecnologia que Transmeta chamou de morphing de código.
A idéia do VLIW (Very Long Instruction Word) é bastante simples - várias instruções do processador são declaradas explicitamente como uma super instrução e são executadas em paralelo. Diferentemente dos processadores superescalares, em particular a Intel começando com o PentiumPro (1996), no qual o processador seleciona várias instruções da memória e decide o que executar em paralelo e o que sequencialmente, com base em uma análise automática das dependências entre as instruções.
Um processador superescalar é muito mais complicado que o VLIW, porque um superescalar precisa gastar a lógica em manter a ilusão de um programador de que todas as instruções selecionadas são executadas uma após a outra, embora na realidade possa haver dezenas delas dentro do processador, em diferentes estágios de execução. No caso do VLIW, o ônus de manter essa ilusão recai sobre o compilador de uma linguagem de alto nível. Por fim, o circuito VLIW é interrompido quando o processador precisa trabalhar com um cache de vários níveis, com atrasos imprevisíveis que dificultam o compilador agendar instruções de relógio. Mas para cálculos matemáticos (por exemplo, colocar Elbrus no radar e calcular o movimento do alvo) é esse, especialmente em condições de escassez de pessoal de engenharia qualificado (mais pessoas precisam verificar a superescalar).
Ilustração da ideia VLIW, processador Crusoe e sub-laptop Toshiba Libretto L1:

E aqui no centro da foto abaixo, Derek Meyer, Derek Meyer, atual CEO da Wave Computing. Antes da Wave, Derek era CEO da ARC, desenvolvedora de núcleos de processadores ARC usados em chips de áudio. Esses núcleos foram
licenciados ao mesmo tempo pela
empresa russa NIIMA Progress , que posteriormente licenciou os núcleos MIPS e
mostrou chips baseados neles em uma exposição em Kazan Innopolis . Derek Meyer viajou várias vezes para a Rússia, para São Petersburgo, onde estava localizada a equipe de desenvolvimento da Virage Logic. Em 2009, a ARC adquiriu a Virage Logic e, em 2010, a Synopsys, empresa líder mundial em design de chips, adquiriu a ARC.
À direita na foto -
Sergey Vakulenko , que no início de sua carreira estava nas origens de Runet, trabalhou na cooperativa Demos e no Instituto Kurchatov, que trouxe a Internet para a URSS. Agora, Sergey está escrevendo um modelo com precisão de ciclo do elemento processador Wave para computação em redes neurais e, anteriormente, ele escreveu modelos com precisão de instrução de núcleos MIPS que eram usados para verificar os núcleos do processador MIPS I6400 Samurai, I7200 Shaolin e outros.

Aqui estão Vadim Antonov e Sergey Vakulenko em 1990, com o primeiro computador na URSS conectado à Internet:

E aqui está Larry Hudepohl à direita (Hüdepol está escrito em russo?). Larry começou sua carreira na Digital Equipment Corporation (DEC) como designer de processadores para o MicroVAX. Então Larry trabalhou para uma pequena empresa Cyrix, que no final dos anos 80 desafiou a Intel e fabricou um coprocessador FPU compatível com Intel 80387 e 50% mais rápido. Então Larry projetou chips MIPS na Silicon Graphics. Quando a MIPS Technologies se separou da Silicon Graphics, Larry e Ryan Quinter lançaram juntos o primeiro produto MIPS independente, o MIPS 4K, que se tornou a espinha dorsal da linha que dominava os eletrônicos domésticos dos anos 2000 (DVD players, câmeras, TVs digitais). Então o MIPS 5K voou para o espaço - foi usado pela agência espacial japonesa JAXA. Larry, como vice-presidente de engenharia de hardware, liderou o desenvolvimento das seguintes linhas e agora está trabalhando nas novas arquiteturas de aceleradores Wave.

A sonda japonesa, orgulhosamente chamada Hayabusa-2 (Sapsan-2), que
pousou na superfície do asteróide Ryugu no ano passado , é controlada pelo processador HR5000, baseado no núcleo do processador MIPS 5Kf, que é licenciado há muito tempo pela MIPS Technologies.
Aqui está um pipeline serial simples do núcleo do processador MIPS 5Kf de 64 bits da sua
folha de dados :

Bem na foto - Darren Jones, Darren Jones. Ele foi o diretor de engenharia de hardware do MIPS, que liderou o desenvolvimento de núcleos complexos, com multithreading de hardware e superescalares com execução extraordinária de instruções. Depois, Darren foi para a Xilinx, onde estava envolvido nos chips Xilinx Zynq, nos quais havia uma combinação de FPGAs e processadores ARM. Darren é agora vice-presidente de engenharia da Wave.
No MIPS, Darren era o líder de um grupo cujos membros mais tarde foram trabalhar para Apple e Samsung. A designer Monica, que foi para a Samsung, certa vez me disse uma frase que me lembrava bem: “Design RTL: alguns princípios simples e o resto é trapaça” (design de hardware no nível do registro: alguns princípios simples, tudo o mais é muhlezh ") Um exemplo canônico de um muhlezh é um cache (o programa gravou dados e os leu, mas só será lembrado mais tarde), mas esse é apenas um caso muito especial do que Monica foi capaz de fazer.

Multithreading de hardware e uma superescalar extraordinária são duas abordagens diferentes para melhorar o desempenho do processador. O multithreading de hardware permite aumentar a taxa de transferência sem muito consumo de energia, mas com programação não trivial. A superescalar permite executar programas de thread único aproximadamente o dobro da velocidade, mas também gasta o dobro de watts. Mas sem truques na programação.
Finalmente, o multithreading de hardware foi bem explicado na Wikipedia russa, aqui está o
multithreading temporário (implementado no MIPS interAptiv e no MIPS I7200 Shaolin), mas o
multithreading simultâneo (foi feito nos processadores DEC Alpha nos anos 90, depois no SPARC e, em seguida, no MIPS I6400 Samurai / I6500 Daimyo).
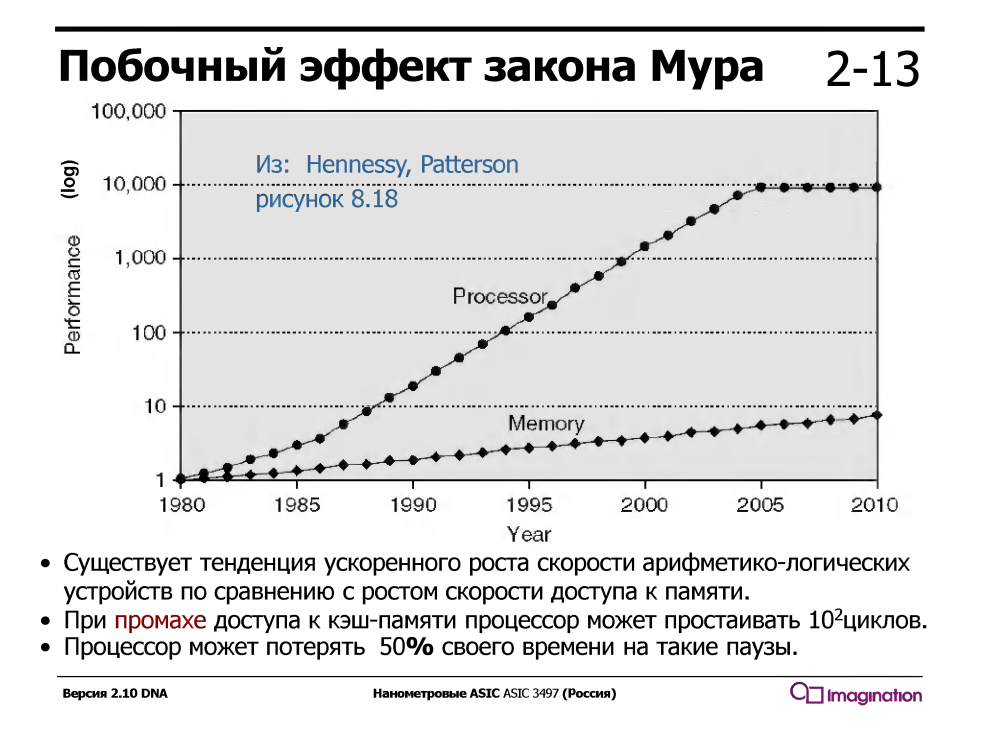
O multithreading temporário explora o fato de que um processador com um pipeline serial convencional está ocioso / aguardando metade do tempo de execução. O que ele está esperando? Dados que passam por caches da memória. E aguarda muito tempo - enquanto aguarda uma falha no cache, o processador pode executar dezenas ou até cem ou duas instruções aritméticas simples, como adição.
Esse nem sempre foi o caso - na década de 1960, os dispositivos aritméticos eram muito mais lentos que a memória. Mas desde 1980, a velocidade dos núcleos dos processadores cresceu muito mais rapidamente que a velocidade da memória, e até a aparência de caches de vários níveis nos processadores resolveu o problema apenas parcialmente.
Os processadores com multithreading temporário suportam vários conjuntos de registros, um para cada thread, e quando o thread atual aguarda dados da memória durante uma falta de cache, o processador alterna para outro thread. Isso acontece instantaneamente, em um ciclo, sem interrupções e milhares de ciclos do manipulador de interrupções, que é ativado durante a multithreading de software (não de hardware).
Aqui está a idéia do multi-threading
nos slides das oficinas de Charles Danchek , professor da Universidade da Califórnia em Santa Cruz, Silicon Valley Extension. Por que em russo? Porque Charles Danchek deu palestras no Moscow MISiS e, depois, no ITMO de São Petersburgo e no KPI de Kiev:


Curiosamente, o hardware multiencadeado pode ser programado simplesmente em C. Aqui está o que parece:
#include "mips/m32c0.h" #include "mips/mt.h" #include "mips/mips34k.h"
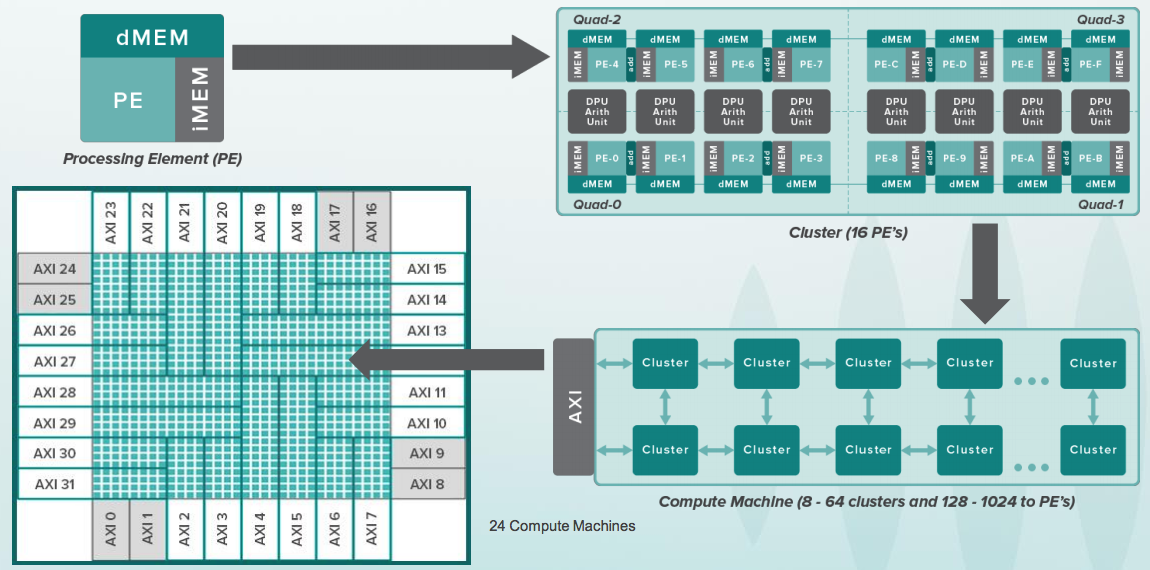
Aqui do lado da festa está o dispositivo Wave para data centers. Ainda não funciona totalmente, embora os chips estejam disponíveis para alguns clientes como parte do programa beta:

O que este dispositivo faz? Você sabe programar em Python? Aqui no Python, você pode criar usando a biblioteca TensorFlow, chamada DFG (Data Flow Graph). As redes neurais são essencialmente gráficos especializados com operações em matrizes. No grupo de software Wave, parte do qual é liderado por Steve Johnson, há um compilador com um subconjunto da representação do Google TensorFlow nos arquivos de configuração dos chips deste dispositivo. Após a configuração, ele pode fazer o cálculo desses gráficos muito rapidamente. O dispositivo foi projetado para data centers, mas o mesmo princípio pode ser aplicado a chips pequenos, mesmo dentro de dispositivos móveis, por exemplo, para reconhecimento de rosto:

Chijioke Anyanwu (esquerda) - Por muitos anos ele é o guardião de todo o sistema de teste do núcleo do processador MIPS. Baldwyn Chieh (centro) é o designer da nova geração de elementos semelhantes a processadores no Wave. Baldwin costumava ser designer sênior da Qualcomm. Aqui estão os
slides sobre o dispositivo Wave da conferência HotChips :


A inovação digital em nanômetros de toda empresa do Vale do Silício deve ter sua própria garota com cabelos brilhantes. Aqui está uma garota no Wave. O nome dela é Athena, ela é socióloga por educação e atua no escritório:

E aqui está a aparência do escritório do lado de fora e sua história de mais de um século da época em que era uma fábrica de conservas inovadora:


E agora a pergunta é: como entender arquitetura, microarquitetura, circuitos digitais, princípios de design de chips de IA e participar de tais festas? A maneira mais fácil é estudar o livro “Digital Circuitry and Computer Architecture” de David Harris e Sarah Harris, e ir para a Wave Computing para estagiário de verão (está planejado contratar 15 estagiários para o verão). Espero que isso também possa ser feito em empresas microeletrônicas russas envolvidas em desenvolvimentos semelhantes - ELVIS, Milander, Baikal Electronics, IVA Technologies e várias outras. Em Kiev, isso pode ser feito teoricamente na empresa Melexis, que coopera com o KPI.
No outro dia, foi lançada uma nova versão finalmente corrigida do livro Harris & Harris, que deveria ser gratuita aqui
www.mips.com/downloads/digital-design-and-computer-architecture-russian-edition-second-edition-ver3 , mas esse link não funciona para mim e, quando funcionar, escreverei uma postagem separada sobre ele. Com perguntas feitas durante entrevistas na Apple, Intel, AMD e em quais páginas deste livro (e outras fontes), você pode ver as respostas.