Há algum tempo, sob a marca VTB, três grandes bancos se fundiram: VTB, ex-VTB24 e ex-Bank of Moscow. Para observadores externos, o banco VTB combinado agora está funcionando como um todo, mas, por dentro, tudo parece muito mais complicado. Neste post, falaremos sobre planos para criar uma rede unificada do banco VTB integrado, compartilhar hacks para organizar a interação de firewalls, conectar e combinar segmentos de rede sem interromper os serviços.
Dificuldades na interação de infraestruturas díspares
Atualmente, as operações da VTB são suportadas por três infra-estruturas herdadas: ex-Bank of Moscow, ex-VTB24 e o próprio VTB. As infraestruturas de cada um deles têm seu próprio conjunto de perímetros de rede, na fronteira com a qual existem equipamentos de proteção. Uma das condições para integrar infra-estruturas no nível da rede é a existência de uma estrutura consistente de endereçamento IP.
Imediatamente após a mesclagem, começamos a alinhar os espaços de endereço e agora ele está quase completo. Mas o processo é demorado e rápido, e os prazos para organizar o acesso cruzado entre infra-estruturas eram muito apertados. Portanto, no primeiro estágio, conectamos as infraestruturas de diferentes bancos na forma em que estão - por meio do firewall para várias zonas de segurança principais. De acordo com esse esquema, para organizar o acesso de um perímetro de rede para outro, é necessário rotear o tráfego através de muitos firewalls e outros meios de proteção, transmitidos nos endereços de articulação de recursos e usuários usando as tecnologias NAT e PAT. Além disso, todos os firewalls nas junções são reservados local e geograficamente, e isso sempre deve ser levado em consideração ao organizar interações e criar cadeias de serviços.
Esse esquema é bastante funcional, mas você certamente não pode chamá-lo de ideal. Existem questões técnicas e organizacionais. É necessário coordenar e documentar as interações de muitos sistemas cujos componentes estão espalhados por diferentes infraestruturas e zonas de segurança. Ao mesmo tempo, no processo de transformação de infra-estruturas, é necessário atualizar rapidamente essa documentação para cada sistema. A condução desse processo carrega muito nosso recurso mais valioso - especialistas altamente qualificados.
Problemas técnicos são expressos na multiplicação de tráfego nos links, alta carga de ferramentas de segurança, complexidade da organização de interações de rede, incapacidade de criar algumas interações sem tradução de endereço.
O problema da multiplicação de tráfego surge principalmente devido às muitas zonas de segurança que interagem entre si por meio de firewalls em sites diferentes. Independentemente da localização geográfica dos próprios servidores, se o tráfego ultrapassar o perímetro da zona de segurança, ele passará por uma cadeia de recursos de segurança que podem estar em outros locais. Por exemplo, temos dois servidores em um datacenter, mas um no perímetro do VTB e outro no perímetro da rede ex-VTB24. O tráfego entre eles não é direto, mas passa por 3-4 firewalls que podem estar ativos em outros data centers, e o tráfego será entregue ao firewall e retornado várias vezes pela rede de tronco.
Para garantir alta confiabilidade, precisamos de cada firewall em 3 a 4 cópias - dois em um site na forma de um cluster de alta disponibilidade e um ou dois firewalls em outro site, para o qual o tráfego será alternado se o cluster de firewall principal ou o site como um todo for interrompido.
Resumimos. Três redes independentes são um
monte de problemas : complexidade excessiva, necessidade de equipamentos caros adicionais, gargalos, dificuldades de redundância e, como resultado, altos custos de operação da infraestrutura.
Abordagem geral de integração
Desde que decidimos assumir a transformação da arquitetura de rede, começaremos com as coisas básicas. Vamos de cima para baixo, começaremos analisando os requisitos de negócios, candidatos, engenheiros de sistema e equipe de segurança.
- Com base em suas necessidades, projetamos a estrutura de destino das zonas de segurança e os princípios de interconexão entre essas zonas.
- Nós impomos essa estrutura de zonas na geografia de nossos principais consumidores - data centers e grandes escritórios.
- Em seguida, formamos a rede MPLS de transporte.
- Sob ela, já trazemos a rede principal que fornece serviços para a camada física.
- Selecionamos locais para a colocação de módulos de borda e de firewall.
- Depois que a imagem de destino é esclarecida, elaboramos e aprovamos a metodologia de migração da infraestrutura existente para a de destino, para que o processo seja transparente aos sistemas em funcionamento.
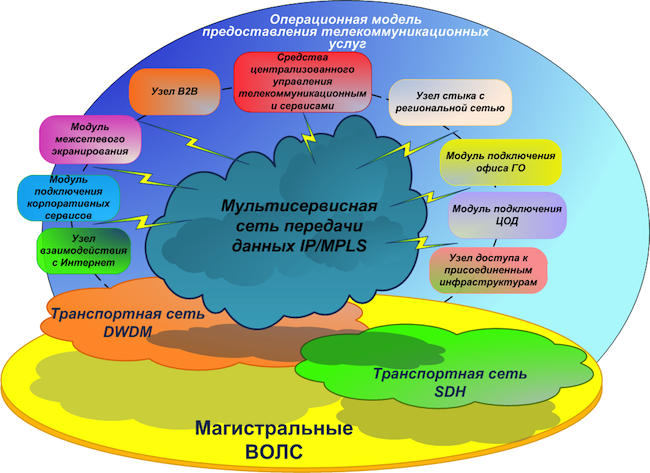
Conceito de rede alvoTeremos uma rede principal de backbone - essa é uma infraestrutura de transporte de telecomunicações baseada em linhas de comunicação de fibra ótica (FOCL), equipamentos passivos e ativos de formação de canais. Também pode usar o subsistema de densificação de canal óptico xWDM e, possivelmente, uma rede SDH.
Com base na rede primária, estamos construindo a chamada
rede principal . Ele terá um único plano de endereço e um único conjunto de protocolos de roteamento. A rede principal inclui:
- MPLS - rede multisserviço;
- DCI - links entre data centers;
- Módulos EDGE - vários módulos de conexão: firewall, organizações parceiras, canais da Internet, data centers, LANs, redes regionais.
Criamos
uma rede multisserviço de
acordo com um princípio hierárquico com a alocação de nós de trânsito (P) e final (PE) . Durante uma análise preliminar do equipamento atualmente disponível no mercado, ficou claro que seria mais economicamente viável transferir o nível de nós P para separar equipamentos do que combinar a funcionalidade P / PE em um dispositivo.
Uma rede multisserviço terá alta disponibilidade, tolerância a falhas, tempo mínimo de convergência, escalabilidade, alto desempenho e funcionalidade, em particular suporte a IPv6 e multicast.
Durante a construção da rede de backbone, pretendemos
abandonar as tecnologias proprietárias (sempre que possível, sem comprometer a qualidade), enquanto nos esforçamos para tornar a solução flexível e não vinculada a um fornecedor específico. Mas, ao mesmo tempo, não queremos criar um "vinagrete" a partir do equipamento de vários fornecedores. Nosso princípio de design fundamental é fornecer o número máximo de serviços ao usar equipamentos que sejam minimamente suficientes para esse número de fornecedores. Isso permitirá, entre outras coisas, organizar a manutenção da infraestrutura de rede, usando um número limitado de pessoas. Também é importante que o novo equipamento seja compatível com o equipamento existente para garantir um processo de migração contínuo.
A estrutura das zonas de segurança das redes VTB, ex-VTB24 e ex-Bank of Moscow dentro da estrutura do projeto está planejada para ser completamente redesenhada com o objetivo de combinar segmentos funcionalmente duplicados. É planejada uma estrutura unificada de zonas de segurança com regras de roteamento comuns e um conceito unificado de acesso a redes. Planejamos realizar firewalls entre zonas de segurança usando firewalls de hardware separados, espaçados em dois locais principais. Também planejamos implementar todos os módulos de borda de forma independente em dois sites diferentes, com redundância automática entre eles com base em protocolos de roteamento dinâmico padronizados.
Organizamos o gerenciamento dos equipamentos da rede principal por meio de uma rede física separada (fora de banda). O acesso administrativo a todos os equipamentos de rede será fornecido através de um único serviço de autenticação, autorização e contabilidade (AAA).
Para encontrar rapidamente problemas na rede, é muito importante poder copiar o tráfego de qualquer ponto da rede para análise e entregá-lo ao analisador por meio de um canal de comunicação independente. Para fazer isso, criaremos uma rede isolada para o tráfego SPAN, com a ajuda da qual coletaremos, filtraremos e transmitiremos fluxos de tráfego para servidores de análise.
Para padronizar os serviços fornecidos pela rede e a possibilidade de alocar custos, apresentaremos um único catálogo com indicadores de SLA. Passamos ao modelo de serviço, no qual levamos em conta a interconexão da infraestrutura de rede com as tarefas aplicadas, a interconexão de elementos dos aplicativos de controle e seu impacto nos serviços. E esse modelo de serviço é suportado por um sistema de monitoramento de rede para que possamos alocar corretamente os custos de TI.
Da teoria à prática
Agora, desceremos um nível e falaremos sobre as soluções mais interessantes em nossa nova infraestrutura que podem ser úteis para você.
Floresta de recursos: detalhes
Já
familiarizamos os residentes de Khabrovsk com a floresta de recursos do VTB. Agora tente dar uma descrição técnica mais detalhada.
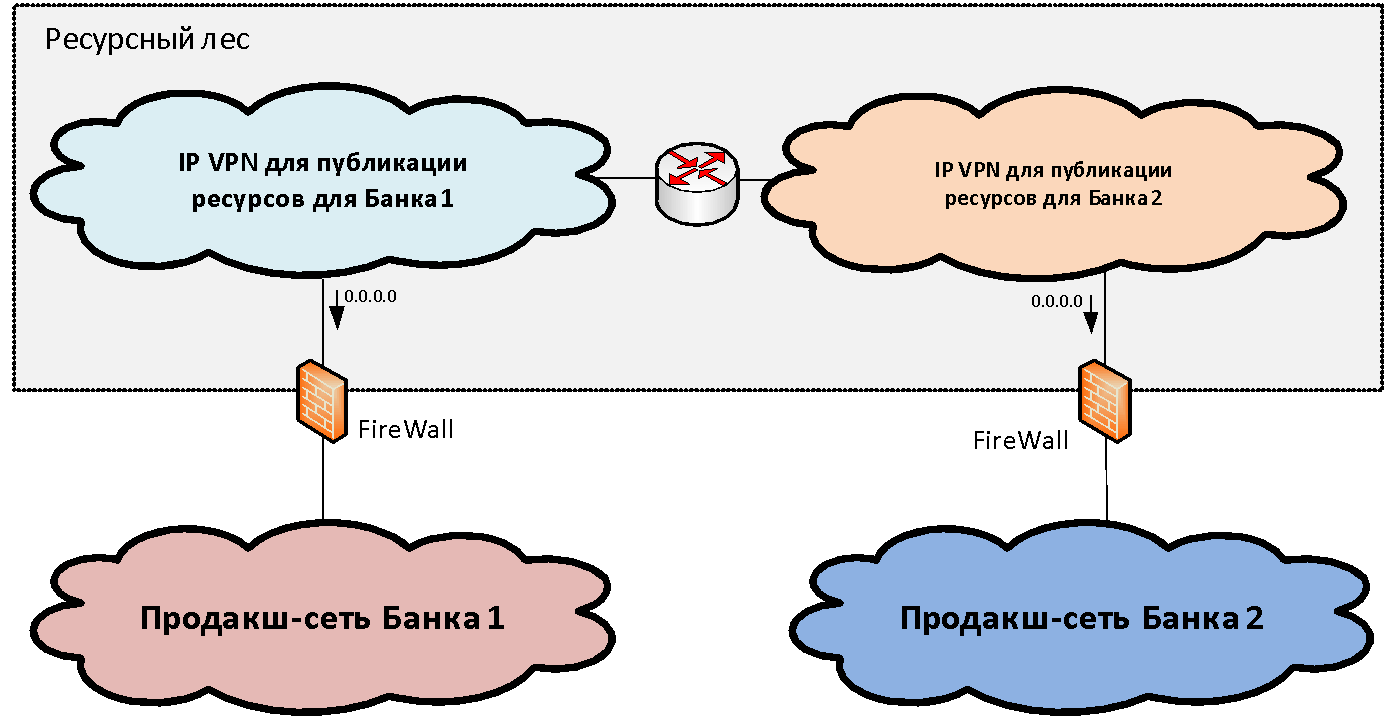
Suponha que tenhamos duas infra-estruturas de rede (para simplificar) de diferentes organizações que precisam ser combinadas. Dentro de cada infraestrutura, via de regra, entre o conjunto de segmentos de rede funcional (zonas de segurança), é possível distinguir o principal segmento de rede produtivo, onde estão localizados os principais sistemas industriais. Conectamos essas zonas produtivas a uma certa estrutura de segmentos de bloqueio, que chamamos de
"floresta de recursos" . Esses segmentos de gateway publicam os recursos compartilhados disponíveis nas duas infra-estruturas.
O conceito de uma floresta de recursos, do ponto de vista da rede, é criar uma zona de segurança de gateway consistindo em duas VPNs IP (no caso de dois bancos). Essas VPNs IP são roteadas livremente entre si e conectadas por firewalls a segmentos produtivos. O endereçamento IP para esses segmentos é selecionado em um intervalo separado de endereços IP. Assim, o roteamento para a floresta de recursos se torna possível a partir das redes de ambas as organizações.
Porém, com o roteamento da floresta de recursos para os segmentos industriais, a situação é um pouco pior, pois o endereçamento neles geralmente se cruza e é impossível formar uma única tabela. Para resolver esse problema, precisamos apenas de dois segmentos na floresta de recursos. Em cada um dos segmentos da floresta de recursos, uma rota padrão é gravada em direção à rede industrial da organização "deles". Ou seja, os usuários podem acessar sem traduzir endereços para o segmento "próprio" da floresta de recursos e para outro segmento via PAT.
Portanto, dois segmentos da floresta de recursos representam uma zona de segurança de gateway único, se você desenhar a borda ao longo dos firewalls. Cada um deles tem seu próprio roteamento: o gateway padrão olha para o banco "its". Se colocarmos um recurso em algum segmento da floresta de recursos, os usuários do banco correspondente poderão interagir com ele sem o NAT.
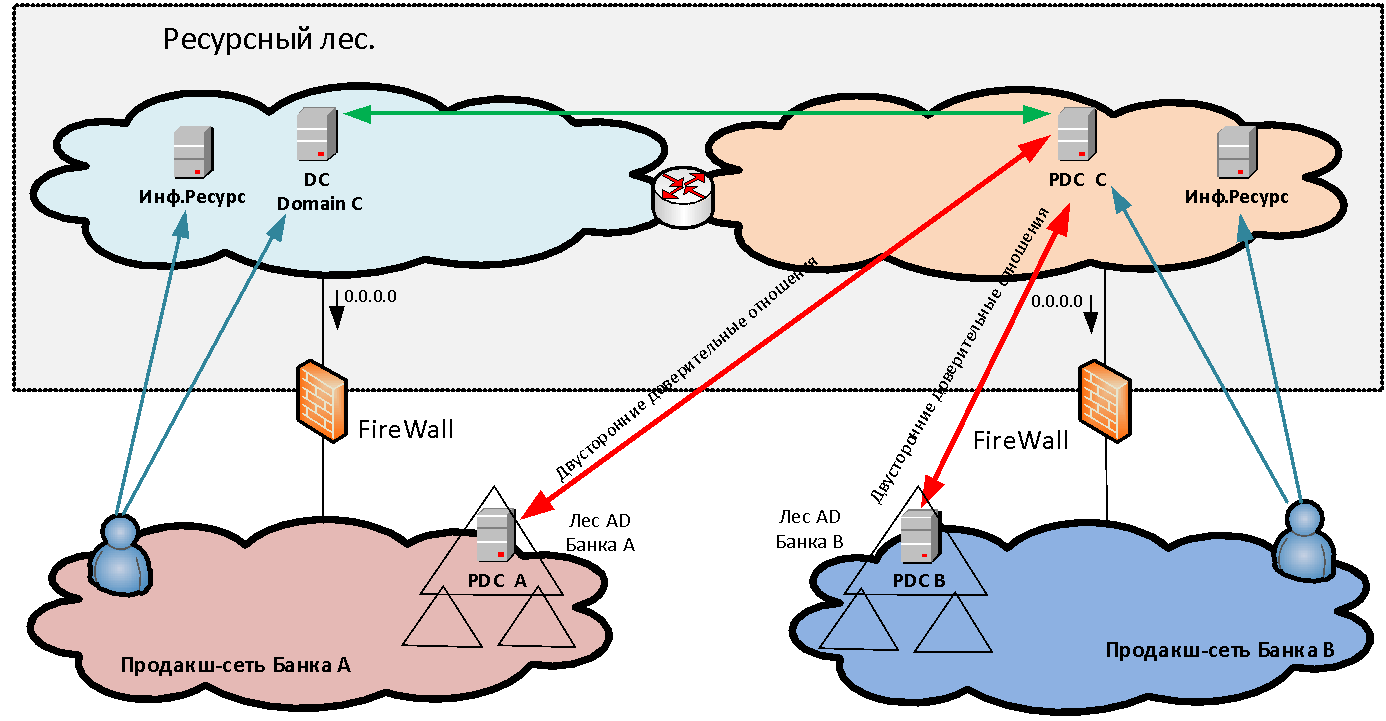
Interação sem NAT é muito importante para muitos sistemas e, primeiro, para interações de domínio da Microsoft - afinal, na floresta de recursos, temos servidores do Active Directory para o novo domínio comum, com os quais as relações de confiança são estabelecidas pelas duas organizações. Além disso, sem a interação NAT, são necessários sistemas como Skype for Business, ABS "MBANK" e muitos outros aplicativos diversos, nos quais o servidor retorna ao endereço do cliente. E se o cliente estiver atrás do PAT, a conexão reversa não será mais estabelecida.
Os servidores que instalamos nos segmentos da floresta de recursos são divididos em duas categorias: infraestrutura (por exemplo, servidores MS AD) e fornecimento de acesso a alguns sistemas de informações. O último tipo de servidor que chamamos de data marts. As fachadas de lojas geralmente são servidores Web, cujo back-end já está atrás do firewall na rede de produção da organização que criou essa fachada na floresta de recursos.
E como os
usuários são
autenticados ao acessar recursos publicados? Se simplesmente fornecermos acesso a alguns aplicativos para um ou dois usuários em outro domínio, poderemos criar contas separadas para autenticação em nosso domínio para eles. Mas quando falamos sobre a fusão em massa de infraestruturas - digamos, 50 mil usuários - é completamente irrealista iniciar e manter contas cruzadas separadas para eles. Também não é sempre possível criar relações de confiança diretas entre florestas de diferentes organizações, por motivos de segurança e devido à necessidade de criar usuários PAT nas condições de cruzamento de espaços de endereço. Portanto, para resolver o problema da autenticação unificada de usuários, uma nova floresta do MS AD que consiste em um domínio é criada no perímetro da floresta de recursos. Nesse novo domínio, os usuários se autenticam ao acessar serviços. Para tornar isso possível, são estabelecidas relações de confiança bilaterais no nível da floresta entre a nova floresta e as florestas de domínio de cada organização. Portanto, o usuário de qualquer organização pode se autenticar em qualquer recurso publicado.
Obtendo integração de rede
Depois que estabelecemos a interação dos sistemas através da infraestrutura da floresta de recursos e, assim, eliminamos os sintomas agudos, era hora de começar a integração direta das redes.
Para fazer isso, no primeiro estágio, conectamos os segmentos de produtos de três bancos a um único firewall poderoso (logicamente unificado, mas fisicamente muitas vezes reservado em sites diferentes). O firewall fornece interação direta entre os sistemas de diferentes bancos.
Com o ex-VTB24, antes de organizar qualquer interação direta entre os sistemas, já conseguimos alinhar os espaços de endereço. Depois de formar as tabelas de roteamento no firewall e abrir os acessos adequados, conseguimos garantir a interação entre os sistemas em duas infraestruturas diferentes.
Com o ex-Banco de Moscou, os espaços de endereço no momento da organização das interações aplicadas não estavam alinhados, e tivemos que usar o NAT mútuo para organizar a interação dos sistemas. O uso do NAT criou vários problemas de resolução de DNS que foram resolvidos pela manutenção de zonas DNS duplicadas. Além disso, devido ao NAT, houve dificuldades com a operação de vários sistemas de aplicativos. Agora, quase eliminamos as interseções dos espaços de endereço, mas estamos confrontados com o fato de que muitos sistemas VTB e ex-Bank of Moscow estão fortemente ligados para interagir nos endereços traduzidos. Agora, precisamos migrar essas interações para endereços IP reais, mantendo a continuidade dos negócios.
Abolição do NAT
Aqui, nosso objetivo é garantir a operação dos sistemas em um único espaço de endereço para maior integração dos serviços de infraestrutura (MS AD, DNS) e aplicativos (Skype for Business, MBANK). Infelizmente, como alguns dos sistemas de aplicativos já estão vinculados entre si nos endereços traduzidos, é necessário um trabalho individual com cada sistema de aplicativo para eliminar o NAT para interações específicas.
Às vezes, você pode
adotar esse truque : configure o mesmo servidor ao mesmo tempo, tanto no endereço traduzido como no endereço real. Portanto, os administradores de aplicativos podem testar o trabalho em um endereço real antes da migração, tentar alternar para a interação não-NAT por conta própria e reverter, se necessário. Ao mesmo tempo, monitoramos o firewall usando a função de captura de pacotes para ver se alguém está se comunicando com o servidor através do endereço traduzido. Assim que essa comunicação é interrompida, nós, de acordo com o proprietário do recurso, paramos de transmitir: o servidor tem apenas um endereço real.
Após analisar o NAT, infelizmente, por algum tempo, será necessário manter o firewall entre segmentos funcionalmente idênticos, porque nem todas as zonas cumprem os mesmos padrões de segurança. Após padronizar os segmentos, o firewall entre os segmentos é substituído pelo roteamento e as zonas de segurança funcionalmente idênticas se fundem.
Firewall
Vamos para o problema do firewall de rede. Em princípio, é relevante para qualquer grande organização na qual é necessário fornecer tolerância a falhas local e global de equipamentos de proteção.
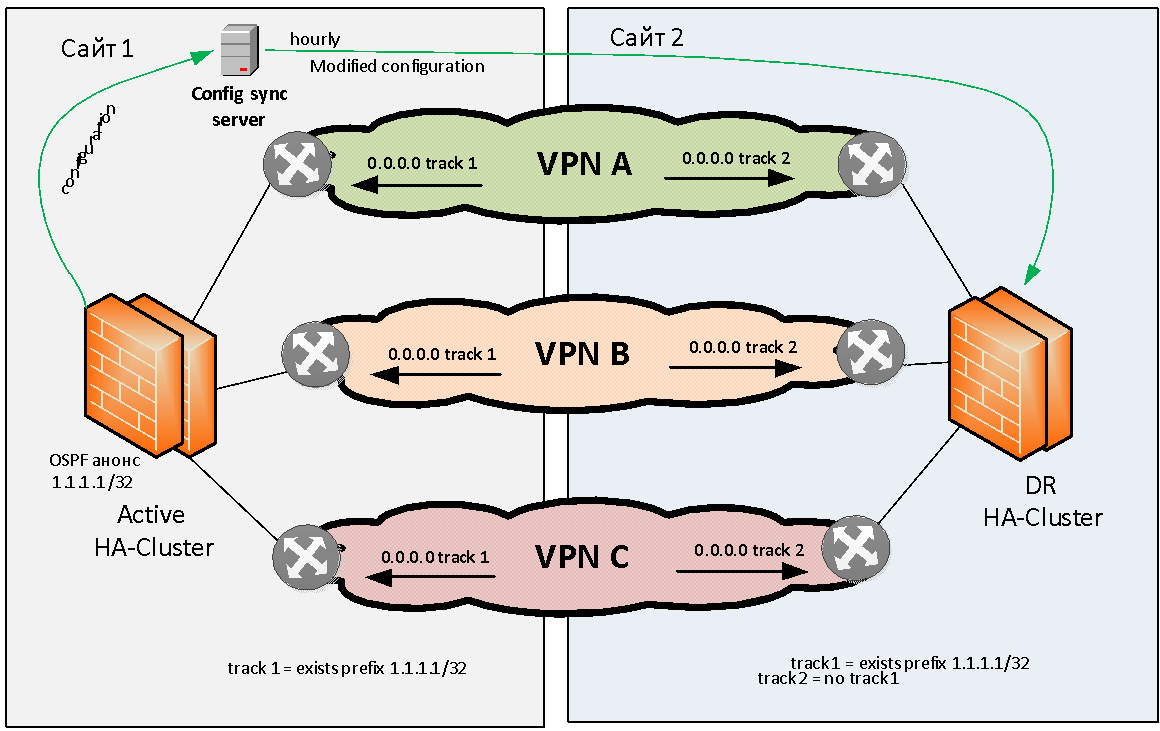
Vamos tentar formular o problema da reserva de firewall em geral. Temos dois sites: site 1 e site 2. Existem várias (por exemplo, três) VPNs MPLS IP que se comunicam por meio de um firewall stateful. Esse firewall precisa ser reservado local e geograficamente.
Não consideraremos o problema do backup local de firewalls; quase qualquer fabricante oferece a capacidade de montar firewalls em um cluster local de alta disponibilidade. Quanto à reserva geográfica de firewalls, praticamente nenhum fornecedor tem essa tarefa pronta para uso.
Obviamente, você pode "esticar" um cluster de firewall em vários sites ao longo de L2, mas esse cluster representará um único ponto de falha e a confiabilidade da nossa solução não será muito alta. Às vezes, os clusters congelam completamente devido a erros de software ou caem em um estado cerebral dividido devido a uma quebra de link L2 entre sites. Por isso, recusamos imediatamente esticar os clusters de firewall sobre L2.
Precisávamos criar um esquema no qual, se um módulo de firewall falhasse em um site, ocorreria uma transição automática para outro site. Aqui está como fizemos.
Decidiu-se manter o modelo de reserva geográfica ativa / em espera quando o cluster ativo está localizado no mesmo site. Caso contrário, encontraremos imediatamente problemas com o roteamento assimétrico, o que é difícil de resolver com um grande número de VPNs L3.
O cluster de firewall ativo deve, de alguma forma, sinalizar sua operação correta. Como método de sinalização, escolhemos o anúncio OSPF do firewall para a rede da rota de teste (sinalizador) com a máscara / 32. O equipamento de rede no site 1 monitora a presença dessa rota do firewall e, se disponível, ativa o roteamento estático (por exemplo, 0.0.0.0 / 0), em direção ao cluster de firewall especificado. Essa rota padrão estática é então colocada (através da redistribuição) na tabela de protocolo BGP MP e distribuída pela rede de backbone. , OSPF , , IP VPN.
, , , .
1 - , , 1 , 2 — . , , VPN' . , , , .
, active/standby. active-. , . , (, IP- ). . . .
L3 , . .
. , , — , , . L3-, .
, IP-. MPLS VPN. MPLS VPN «IN» VPN «OUT». VPN HUB-and-spoke VPN. Spoke HUB' VPN, .
«IN»
- Spoke VPN' VPN. «OUT»
Spoke VPN' .
MPLS VPN «IN». VPN . VPN HUB-VPN «IN» . . , Policy Based Routing. VPN «OUT», VPN «OUT» Spoke-VPN.
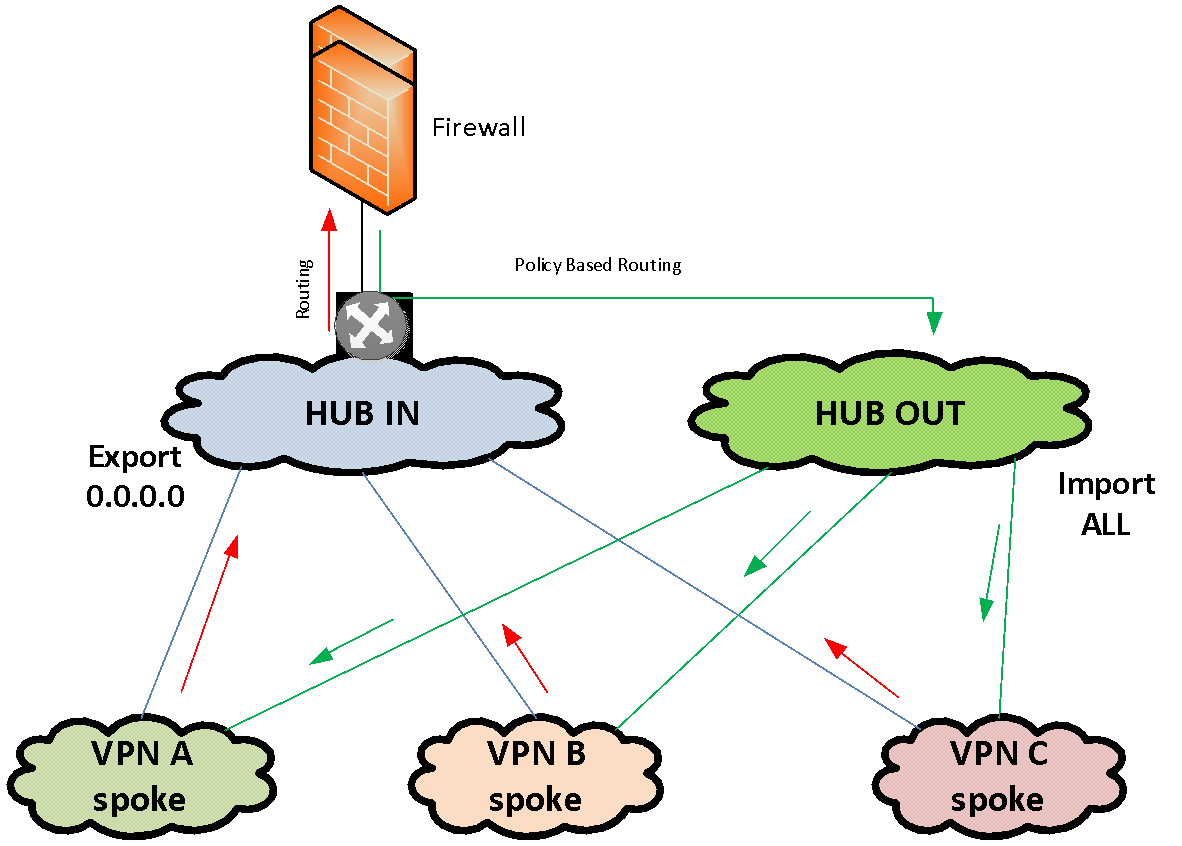
VPN, . MPLS import / export HUB VPN.
VPN , — , VLAN, ..
Conclusão
, , . , , , . .