Detectar ataques tem sido uma tarefa importante em segurança da informação há décadas. Os primeiros exemplos conhecidos de implementação do IDS datam do início dos anos 80.
Após várias décadas, toda uma indústria de ferramentas de detecção de ataques foi formada. Atualmente, existem vários tipos de produtos, como IDS, IPS, WAF, firewalls, a maioria dos quais oferece detecção de ataques baseada em regras. A idéia de usar técnicas de detecção de anomalias para detectar ataques com base em estatísticas de produção não parece tão realista quanto no passado. Ou tudo a mesma coisa?
Detecção de anomalias em aplicativos da Web
Os primeiros firewalls projetados especificamente para detectar ataques a aplicativos da web começaram a aparecer no mercado no início dos anos 90. Desde então, os métodos de ataque e os mecanismos de defesa mudaram significativamente, e os atacantes podem estar um passo à frente a qualquer momento.
Atualmente, a maioria dos WAFs tenta detectar ataques da seguinte maneira: existem alguns mecanismos baseados em regras que estão embutidos no servidor proxy reverso. O exemplo mais impressionante é mod_security, o módulo WAF para o servidor da web Apache, desenvolvido em 2002. Identificar ataques usando regras tem várias desvantagens; por exemplo, as regras não podem detectar ataques de dia zero, enquanto os mesmos ataques podem ser facilmente detectados por um especialista, e isso não é surpreendente, porque o cérebro humano não funciona como um conjunto de expressões regulares.
Do ponto de vista do WAF, os ataques podem ser divididos naqueles que podemos detectar pela sequência de solicitações e naqueles em que uma solicitação HTTP (resposta) é suficiente para resolver. Nossa pesquisa se concentra na detecção dos últimos tipos de ataques - Injeção SQL, Cross Site Scripting, Injeção de Entidades Externas XML, Traversal de Caminho, Comando de SO, Comando de SO, Injeção de Objetos, etc.
Mas primeiro, vamos nos testar.
O que o especialista pensará quando vir as seguintes consultas?
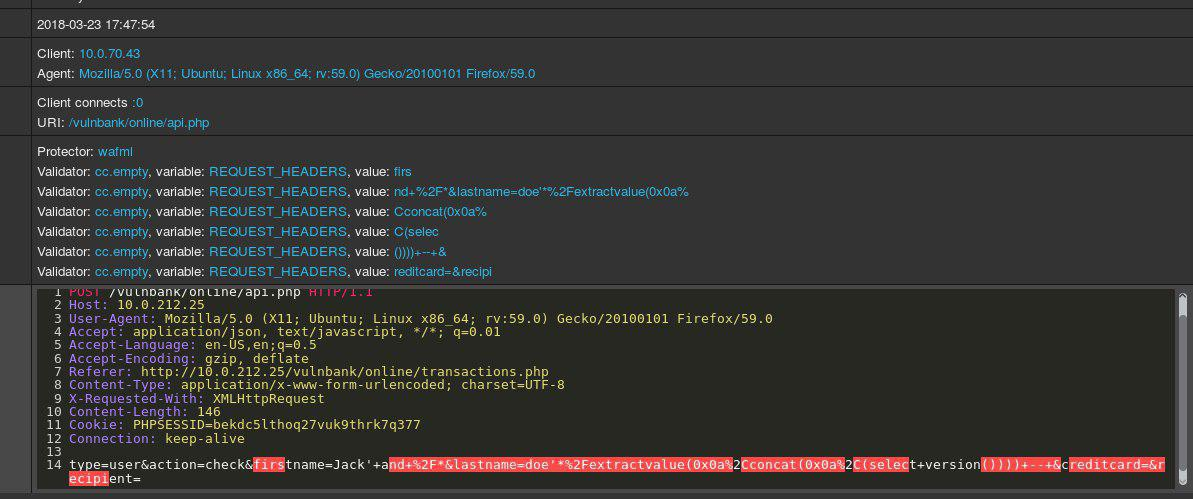
Veja um exemplo de solicitação HTTP para aplicativos:
Se você tivesse a tarefa de detectar solicitações maliciosas para um aplicativo, provavelmente gostaria de observar o comportamento usual do usuário por algum tempo. Examinando as consultas para vários pontos de extremidade do aplicativo, você pode ter uma idéia geral da estrutura e das funções de consultas não perigosas.
Agora você obtém a seguinte consulta para análise:

É imediatamente evidente que algo está errado aqui. Levará algum tempo para entender como é realmente o caso aqui e, depois de identificar a parte da solicitação que parece anormal, você poderá começar a pensar sobre que tipo de ataque é esse. Em essência, nosso objetivo é fazer com que nossa “inteligência artificial para detectar ataques” funcione da mesma maneira - para se parecer com o pensamento humano.
O óbvio é que algum tráfego, que à primeira vista parece malicioso, pode ser normal para um site específico.
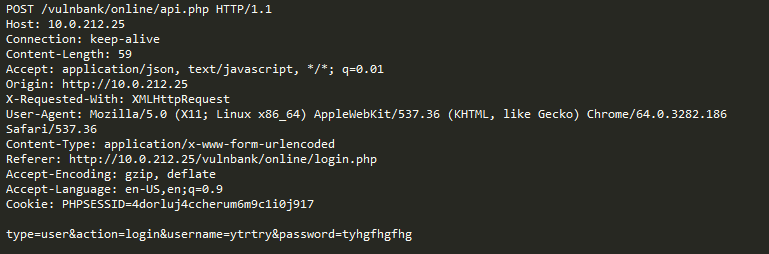
Por exemplo, vamos considerar as seguintes consultas:
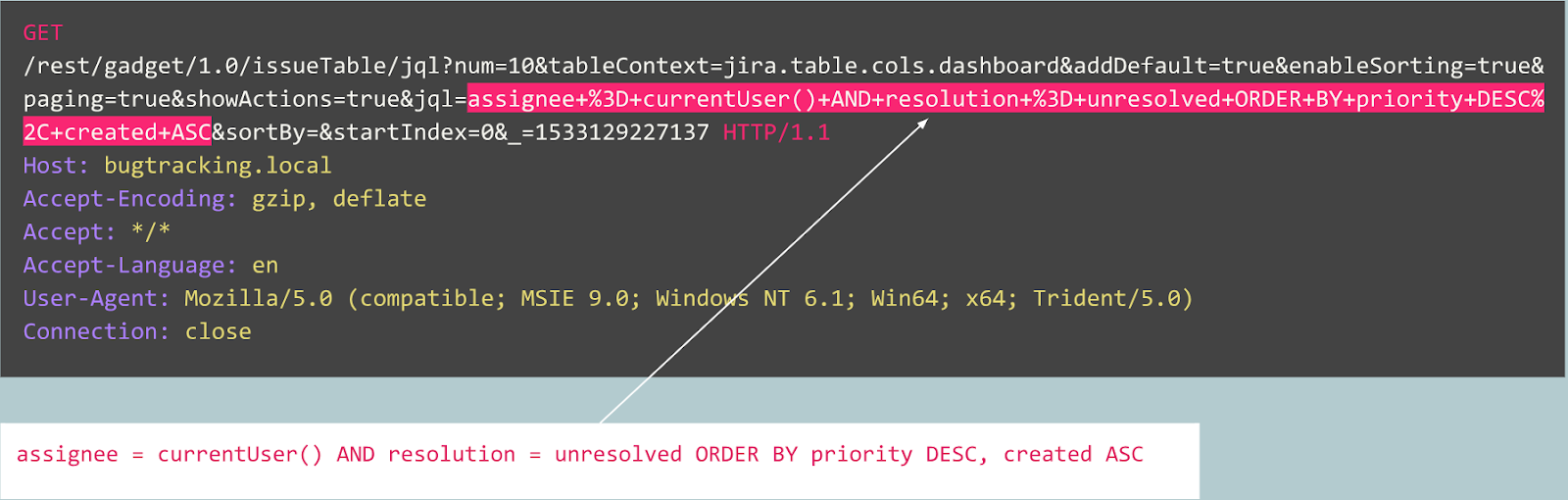
Esta consulta é anormal?
De fato, essa solicitação é uma publicação de um bug no rastreador Jira e é típica desse serviço, o que significa que a solicitação é esperada e normal.
Agora considere o seguinte exemplo:

À primeira vista, a solicitação parece um registro normal de usuário em um site baseado no Joomla CMS. No entanto, a operação solicitada é user.register em vez do usual registration.register. A primeira opção está desatualizada e contém uma vulnerabilidade que permite que qualquer pessoa se registre como administrador. Uma exploração para esta vulnerabilidade é conhecida como Joomla <3.6.4 Criação de conta / escalonamento de privilégios (CVE-2016-8869, CVE-2016-8870).

Por onde começamos
Obviamente, primeiro examinamos as soluções existentes para o problema. Várias tentativas de criar algoritmos de detecção de ataques com base em estatísticas ou aprendizado de máquina foram feitas há décadas. Uma das abordagens mais populares é resolver o problema de classificação, quando as classes são algo como "consultas esperadas", "injeções de SQL", XSS, CSRF, etc. Dessa forma, é possível obter uma boa precisão para o conjunto de dados usando o classificador no entanto, essa abordagem não resolve problemas muito importantes do nosso ponto de vista:
- A seleção de turmas é limitada e predeterminada . E se o seu modelo no processo de aprendizado for representado por três classes, digamos "consultas normais", SQLi e XSS, e durante a operação do sistema, encontrar CSRF ou um ataque de dia zero?
- O significado dessas classes . Suponha que você precise proteger dez clientes, cada um dos quais executando aplicativos da Web completamente diferentes. Para a maioria deles, você não tem idéia de como a injeção SQL realmente se parece com a aplicação deles. Isso significa que você precisa criar artificialmente conjuntos de dados de treinamento. Essa abordagem não é ótima, porque, em última análise, você aprenderá com dados que diferem na distribuição dos dados reais.
- Interpretabilidade dos resultados do modelo . Bem, o modelo produziu o resultado da injeção SQL, e agora o que? Você e, mais importante, seu cliente, que é o primeiro a receber um aviso e geralmente não é especialista em ataques na Web, devem adivinhar qual parte da solicitação que seu modelo considera maliciosa.
Mantendo todos esses problemas em mente, decidimos tentar treinar o modelo do classificador de qualquer maneira.
Como o protocolo HTTP é um protocolo de texto, era óbvio que precisávamos dar uma olhada nos classificadores de texto modernos. Um exemplo bem conhecido é a análise de sentimentos em um conjunto de dados de revisão de filmes IMDB. Algumas soluções usam a RNN para classificar revisões. Decidimos tentar um modelo semelhante com a arquitetura RNN com algumas pequenas diferenças. Por exemplo, a arquitetura RNN da linguagem natural usa uma representação vetorial de palavras, mas não está claro quais palavras ocorrem em uma linguagem não natural, como HTTP. Portanto, decidimos usar a representação vetorial de símbolos para nossa tarefa.
Representações prontas não resolvem nosso problema, por isso usamos mapeamentos simples de caracteres em códigos numéricos com vários marcadores internos, como
GO e
EOS .
Depois que o desenvolvimento e o teste do modelo foram concluídos, todos os problemas previstos anteriormente se tornaram aparentes, mas pelo menos nossa equipe passou de suposições inúteis para algum resultado.
O que vem a seguir?
Em seguida, decidimos dar alguns passos em direção à interpretabilidade dos resultados do modelo. Em algum momento, encontramos o mecanismo de atenção “Atenção” e começamos a implementá-lo em nosso modelo. E deu resultados promissores. Agora, nosso modelo começou a exibir não apenas rótulos de classe, mas também fatores de atenção para cada caractere que passamos para o modelo.
Agora, poderíamos visualizar e mostrar na interface da web o local exato em que o ataque de injeção SQL foi detectado. Este foi um bom resultado, mas outros problemas da lista ainda não foram resolvidos.
Era óbvio que deveríamos continuar a nos beneficiar do mecanismo de atenção e a nos afastar da tarefa de classificação. Depois de ler um grande número de estudos relacionados sobre modelos de sequência (sobre mecanismos de atenção [2], [3], [4], sobre a representação vetorial, sobre as arquiteturas de autoencodificadores) e sobre experiências com nossos dados, conseguimos criar um modelo de detecção de anomalias que, finalmente, funcionaria mais ou menos como um especialista.
Codificadores automáticos
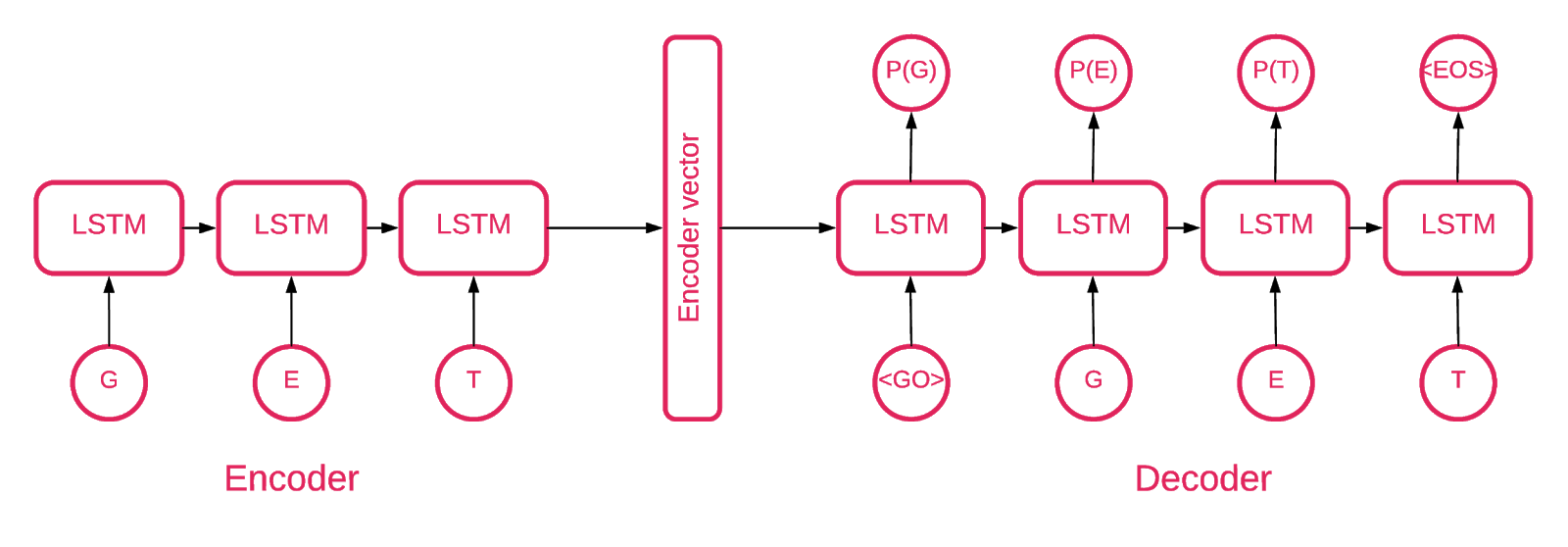
Em algum momento, ficou claro que a arquitetura do Seq2Seq [5] é mais adequada para a nossa tarefa.
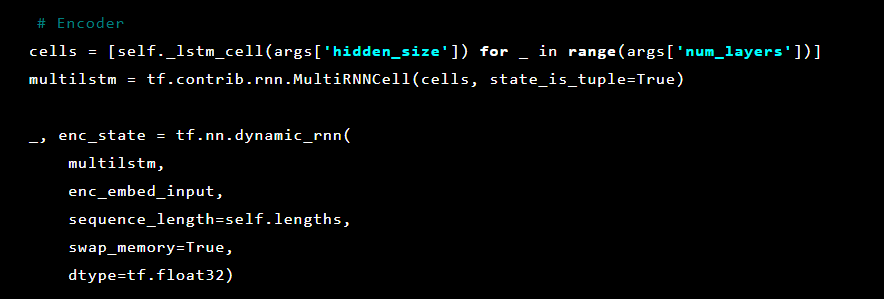
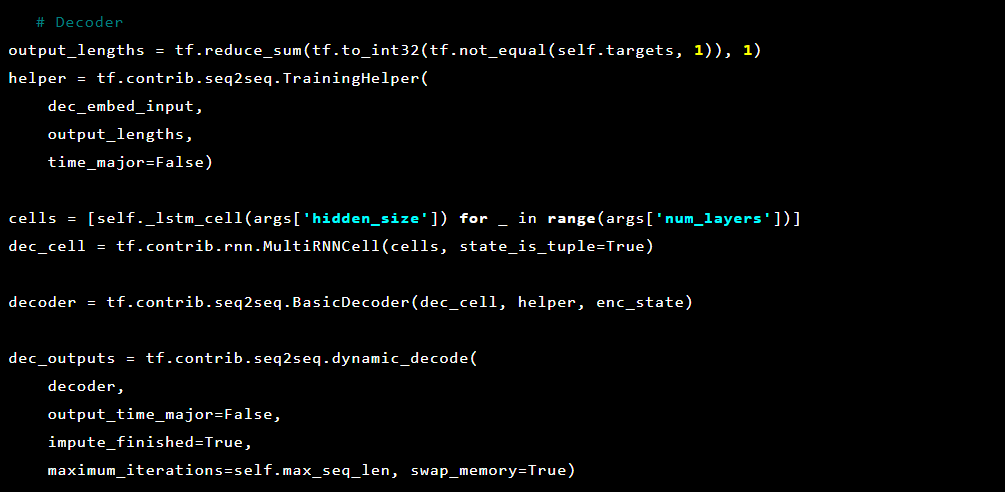
O modelo Seq2Seq [7] consiste em dois LSTMs multicamadas - um codificador e um decodificador. O codificador mapeia a sequência de entrada para um vetor de comprimento fixo. O decodificador decodifica o vetor alvo usando a saída do codificador. No treinamento, um codificador automático é um modelo no qual os valores-alvo são definidos como os valores de entrada.
A idéia é ensinar a rede a decodificar o que viu ou, em outras palavras, aproximar a identidade. Se um autoencodificador treinado recebe um padrão anormal, provavelmente o recria com um alto grau de erro, simplesmente porque nunca foi visto.
Solução
Nossa solução consiste em várias partes: inicialização do modelo, treinamento, previsão e verificação. Esperamos que a maior parte do código localizado no repositório não exija explicações, portanto, focaremos apenas as partes importantes.
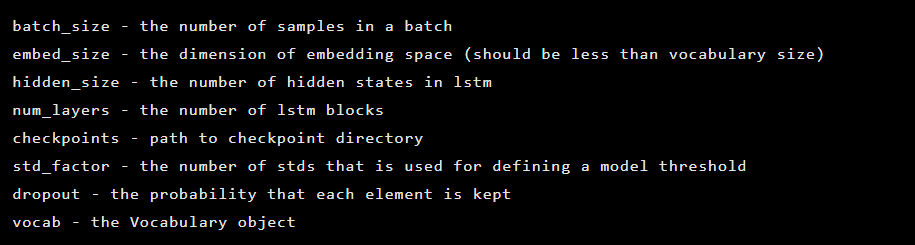
O modelo é criado como uma instância da classe Seq2Seq, que possui os seguintes argumentos do construtor:
Em seguida, as camadas do codificador automático são inicializadas. Primeiro codificador:
Então o decodificador:
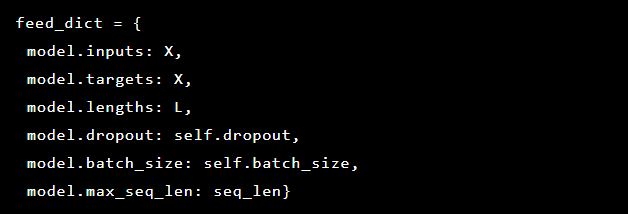
Como o problema que estamos resolvendo é detectar anomalias, os valores-alvo e a entrada são os mesmos. Portanto, nosso feed_dict fica assim:
Após cada época, o melhor modelo é salvo como um ponto de referência, que pode ser baixado. Para fins de teste, foi criada uma aplicação web que defendemos com um modelo para verificar se ataques reais foram bem-sucedidos.
Inspirados pelo mecanismo de atenção, tentamos aplicá-lo ao modelo do codificador automático para marcar as partes anormais dessa consulta, mas notamos que as probabilidades derivadas da última camada funcionam melhor.

No estágio de teste de nossa amostra atrasada, obtivemos resultados muito bons: a precisão e o recall são próximos de 0,99. E a curva ROC tende a 1. Parece incrível, não é?
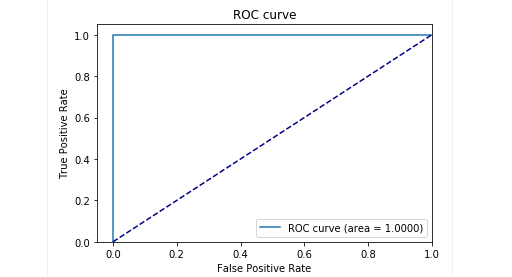
Resultados
O modelo proposto do auto-codificador Seq2Seq foi capaz de detectar anomalias em solicitações HTTP com precisão muito alta.
Esse modelo age como uma pessoa: apenas estuda as solicitações "normais" do usuário para um aplicativo da web. E quando detecta anomalias nas solicitações, seleciona a localização exata da solicitação, que considera anômala.
Testamos esse modelo em alguns ataques a um aplicativo de teste e os resultados foram promissores. Por exemplo, a imagem acima mostra como nosso modelo detectou uma injeção de SQL dividida em dois parâmetros em um formulário da web. Essas injeções de SQL são chamadas fragmentadas: partes da carga útil do ataque são entregues em vários parâmetros HTTP, o que dificulta a detecção de WAFs baseados em regras, pois eles geralmente testam cada parâmetro individualmente.
O código do modelo e os dados de treinamento e teste são publicados como um laptop Jupyter, para que todos possam reproduzir nossos resultados e sugerir melhorias.
Em conclusão
Acreditamos que nossa tarefa não foi trivial. Gostaríamos, com um mínimo de esforço (antes de tudo, de evitar erros devido à complexidade da solução), de encontrar uma maneira de detectar ataques que, como se por mágica, aprendessem a decidir o que é bom e o que é ruim. Em segundo lugar, eu queria evitar problemas com o fator humano, quando exatamente um especialista decide o que é sinal de ataque e o que não é. Resumindo, gostaria de observar que o codificador automático com a arquitetura Seq2Seq para o problema de procurar anomalias, em nossa opinião e para o nosso problema, fez um excelente trabalho.
Também queríamos resolver o problema com a interpretabilidade dos dados. Usar arquiteturas de redes neurais complexas geralmente é muito difícil. Em uma série de transformações, já é difícil dizer no final o que exatamente qual parte dos dados influenciou mais a decisão. No entanto, depois de repensar a abordagem da interpretação dos dados pelo modelo, foi suficiente obtermos as probabilidades de cada símbolo da última camada.
Note-se que esta não é uma versão de produção. Não podemos divulgar os detalhes da implementação dessa abordagem em um produto real e queremos alertar que simplesmente aceitar e incorporar essa solução em algum produto não funcionará.
Repositório do GitHub:
goo.gl/aNwq9UAutores : Alexandra Murzina (
murzina_a ), Irina Stepanyuk (
GitHub ), Fedor Sakharov (
GitHub ), Arseniy Reutov (
Raz0r )
Referências:
- Noções básicas sobre redes LSTM
- Atenção e redes neurais recorrentes aumentadas
- Atenção É Tudo Que Você Precisa
- Atenção é tudo o que você precisa (anotado)
- Tutorial de Tradução Automática Neural (seq2seq)
- Autoencoders
- Aprendizagem sequência a sequência com redes neurais
- Construindo Autoencoders em Keras