Recentemente, o Jupyter Notebook se tornou muito popular entre os especialistas em ciência de dados, tornando-se o padrão de fato para prototipagem rápida e análise de dados. Na Netflix, tentamos ampliar ainda mais os limites de seus recursos, repensando o que o Notebook pode ser, quem pode ser usado e o que eles podem fazer com ele. Nós nos esforçamos muito para traduzir nossa visão em realidade.
Neste artigo, queremos dizer por que achamos que os notebooks Jupyter são tão atraentes e que nos inspiram ao longo do caminho. Além disso, descrevemos os componentes de nossa infraestrutura e analisamos novas maneiras de usar o Jupyter Notebook na Netflix.

Nota do tradutor: cuidado, muito texto e poucas fotos
Se você não tiver muito tempo, sugerimos que você vá imediatamente para a seção Casos de uso .
Por que tudo isso?
Os dados são o poder da Netflix. Eles permeiam nossos pensamentos, influenciam nossas decisões e desafiam nossas hipóteses . Eles cobram experimentos e o surgimento de um novo em uma escala sem precedentes . Os dados nos permitem descobrir significados inesperados e experimentar uma experiência personalizada incrível para 130 milhões de nossos usuários em todo o mundo .
Tornar tudo isso realidade é uma conquista considerável, exigindo impressionante suporte de engenharia e infraestrutura. Todos os dias, mais de 1 trilhão de eventos são recebidos em um fluxo (pipeline de ingestão de streaming) que é processado e registrado em um armazenamento em nuvem de 100PB. Todos os dias, nossos usuários realizam mais de 150.000 tarefas nesses dados, cobrindo tudo, desde relatórios a aprendizado de máquina e algoritmos de recomendação.
Para suportar esses cenários de uso em tal escala, criamos um dos melhores do setor, uma plataforma de processamento de dados flexível, poderosa e, se necessário, complexa (Netflix Data Platform). Também desenvolvemos ferramentas e serviços adicionais, como Genie (serviço de execução de tarefas) e Metacat (meta-armazenamento). Essas ferramentas reduzem a complexidade, possibilitando o suporte a uma ampla gama de usuários em toda a empresa.

A variedade de usuários é impressionante, mas você precisa pagar por isso: a Netflix Data Platform e seu ecossistema de ferramentas e serviços devem ser escalados para oferecer suporte a cenários de uso adicionais, idiomas, esquemas de acesso e muito mais. Para uma melhor compreensão do problema, consideramos três posições comuns: um engenheiro analista, um engenheiro de dados e um cientista de dados.
 A diferença na preferência de idiomas e ferramentas para diferentes posições
A diferença na preferência de idiomas e ferramentas para diferentes posiçõesComo regra, cada posição prefere usar seu próprio conjunto de ferramentas e idiomas. Por exemplo, um engenheiro de dados pode criar um novo conjunto de dados contendo trilhões de fluxos de eventos usando o Scala no IntelliJ. O analista pode usá-los em um novo relatório global de qualidade de streaming usando SQL e Tableau. Este relatório pode ser enviado a um cientista de dados que criará um novo modelo de compressão de streaming usando o R e o RStudio. À primeira vista, esses processos parecem fragmentados, embora complementares, mas se você olhar mais profundamente, cada um desses processos possui várias tarefas sobrepostas:
exploração de dados - ocorre no estágio inicial do projeto; pode incluir uma visão geral dos dados de amostra, consultas para análise estatística e visualização de dados
preparação de dados - uma tarefa repetitiva, pode incluir limpeza, padronização, transformação, desnormalização e agregação de dados; geralmente a parte mais demorada do projeto
validação de dados - uma tarefa que ocorre regularmente; pode incluir uma pesquisa de dados amostrados, análise estatística, análise agregada e visualização de dados; geralmente ocorre como parte da exploração, preparação, desenvolvimento, pré-implantação e pós-implantação de dados
produção - ocorre na fase final do projeto; pode incluir implantação de código, adições de amostra, treinamento de modelo, validação de dados e programação de fluxos de trabalho
Para expandir os recursos de nossos usuários, queremos tornar essas tarefas o mais fácil possível.
Para expandir os recursos de nossa plataforma, queremos minimizar o número de ferramentas que precisam ser suportadas. Mas como Nenhuma ferramenta única pode cobrir todas essas tarefas. Além disso, muitas vezes uma tarefa requer o uso de várias ferramentas. No entanto, se desativarmos, surge um padrão comum para todas as ferramentas e linguagens: executar código, examinar dados, apresentar o resultado.
Aconteceu que um projeto de código aberto foi desenvolvido especificamente para isso: Projeto Jupyter .
Cadernos Jupyter

O notebook Jupyter no nteract exibe Vega e Altair
O projeto Jupyter foi lançado em 2014 com o objetivo de criar um conjunto consistente de ferramentas de código aberto para pesquisa, fluxo de trabalho reproduzível e análise de dados. Essas ferramentas foram altamente elogiadas pelo setor e hoje o Jupyter se tornou parte integrante do kit de ferramentas de qualquer cientista de dados. Para entender a extensão de sua influência, observamos que Jupyter recebeu o 2017 ACM Software Systems Award - um prêmio de prestígio que ele compartilha com Java, Unix e the_Web.
Para entender por que o Notebook Jupyter é tão atraente para nós, considere suas principais características:
- protocolo de mensagens para analisar e executar código, independentemente do idioma
- formato de arquivo com a capacidade de editar, para descrição, exibição e execução de código, saída e notas de remarcação
- interface da web para gravação interativa, execução de código e visualização de resultados
O protocolo Jupyter fornece uma API de mensagens padronizada com kernels que atuam como módulos de computação e fornece uma arquitetura composível, compartilhando assim onde o código (UI) é armazenado e onde é executado (o kernel). Assim, separando a interface e o núcleo, os Notebooks podem funcionar em vários idiomas, mantendo a flexibilidade de configurar o tempo de execução. Se existir um idioma para um idioma que possa trocar mensagens usando o protocolo Jupyter, o Notebook poderá executar o código enviando e recebendo mensagens para esse kernel.
Além de tudo, tudo isso é suportado por um formato de arquivo que permite armazenar o próprio código e os resultados de sua execução em um único local. Isso significa que você pode visualizar os resultados da execução posteriormente sem precisar reiniciar o próprio código. Os notebooks também podem armazenar uma descrição detalhada do contexto e o que exatamente acontece dentro dele. Isso o torna um formato ideal para transmitir um contexto comercial, corrigir suposições, comentar códigos, descrever conclusões e muito mais.
Casos de uso
Entre os muitos cenários, os casos de uso mais populares são: acesso a dados, modelos de blocos de anotações e blocos de anotações de agendamento.
Acesso a dados
O Jupyter Notebook apareceu originalmente na Netflix para suportar fluxos de trabalho de ciência de dados. À medida que seu uso entre os especialistas em ciência de dados aumentou, vimos o potencial de expandir os recursos de nossas ferramentas. Percebemos que poderíamos usar a versatilidade e a arquitetura do Notebook Jupyter e expandir seus recursos para compartilhamento de dados. No terceiro trimestre de 2017, começamos a trabalhar seriamente para tornar o Notebook uma ferramenta para um círculo restrito de especialistas em um representante de primeira classe da Netflix Data Platform.
Do ponto de vista de nossos usuários, os Notebooks oferecem uma interface conveniente para execução interativa de comandos, pesquisa de saída e visualização de dados - tudo em um ambiente de desenvolvimento em nuvem. Também oferecemos suporte à biblioteca Python, que combina acesso à API da plataforma. Isso significa que os usuários têm acesso programático a praticamente toda a plataforma Netflix via Notebook. Graças a essa combinação de flexibilidade, potência e facilidade de uso, a empresa experimentou um aumento acentuado no uso por todos os tipos de usuários da plataforma.
Hoje, o notebook é a ferramenta de dados mais popular da Netflix.
Modelos de caderno
À medida que o suporte para os notebooks Jupyter se expandia dentro da plataforma, começamos a introduzir novos recursos para usá-lo para atender a novos cenários de uso. A partir daqui vieram os laptops parametrizados. Laptops parametrizados representam exatamente o que o nome diz: um notebook que permite definir parâmetros no código e receber entrada em tempo de execução. Isso fornece um bom mecanismo para os usuários definirem o notebook como modelos reutilizáveis.
Nossos usuários encontraram muitas maneiras de usar esses padrões. Listamos alguns dos mais usados:
- Data Scientist : experimente diferentes coeficientes e resuma os resultados
- Engenheiro de dados : execute uma coleção de auditorias de qualidade de dados como parte do processo de implantação.
- Analista de dados : compartilhe consultas e visualizações preparadas para que as partes interessadas possam explorar os dados mais profundamente do que o Tableau permite
- Engenheiro de software : envie os resultados de um script para solucionar problemas de falha
Agendamento de notebooks (Agendador)
Uma das maneiras originais de usar o Notebook é criar uma camada de mesclagem para agendar fluxos de trabalho.
Como cada laptop pode ser executado em um kernel arbitrário, podemos oferecer suporte a qualquer ambiente de tempo de execução definido pelo usuário. E como os notebooks descrevem um fluxo de execução linear dividido em células, podemos relacionar a falha a uma célula específica. Isso permite que os usuários descrevam a execução e as visualizações de uma forma mais narrativa, que pode ser capturada com precisão na inicialização em um momento posterior.
Esse paradigma permite que você use um laptop para trabalho interativo e alterne suavemente para várias execuções e uso do agendador. O que acabou sendo muito conveniente para os usuários. Muitos usuários criam fluxos de trabalho inteiros no bloco de anotações apenas para duplicá-los em arquivos separados e executá-los no momento certo. Ao tratar o notebook como uma descrição seqüencial do processo, podemos agendá-lo facilmente para execução como qualquer outro fluxo de trabalho.
Podemos planejar a execução de outros tipos de trabalho através de notebooks. Quando um trabalho Spark ou Presto é executado a partir do agendador, o código-fonte é inserido no bloco de notas recém-criado e executado. Este notebook se torna um repositório de histórico contendo código-fonte, parâmetros, configurações, logs de execução, mensagens de erro, etc. Ao solucionar problemas, isso fornece um ponto de partida rápido para a investigação, pois todas as informações relevantes estão dentro e o notebook pode ser executado para depuração interativa.
Infraestrutura de notebook
O suporte aos cenários descritos acima na escala Netflix requer uma extensa infraestrutura de suporte. Apresente brevemente vários projetos que serão discutidos nas seguintes seções:
O nteract é a nova geração de UI baseada em React para notebooks Jupyter. Ele fornece uma interface simples e intuitiva e oferece vários aprimoramentos para a interface do usuário clássica do Jupyter, como barras de ferramentas de células em linha, células de arrastar e soltar e um explorador integrado.
Biblioteca Papermill para parametrização, execução e análise de notebooks Jupyter. Com a ajuda dos quais você pode propagar vários notebooks com vários parâmetros e executá-los simultaneamente. O Papermill também permite coletar e resumir métricas para uma coleção inteira de cadernos.
O Commuter é um serviço leve e verticalmente escalável para visualizar e compartilhar notebooks. Ele fornece uma versão da API compatível com Jupyter para conteúdo e facilita a leitura de notebooks armazenados localmente no Amazon S3. Também oferece um explorador para pesquisar e compartilhar arquivos.
Titus é uma plataforma de gerenciamento de contêineres que fornece lançamento de contêiner escalável e confiável e integração nativa da nuvem com o Amazon AWS. O Titus foi desenvolvido na Netflix e é usado em combate para oferecer suporte aos sistemas de streaming, recomendação e conteúdo da Netflix.
Uma descrição mais detalhada da arquitetura pode ser encontrada no artigo Agendamento de cadernos na Netflix . Para os fins deste post, nos restringimos aos três componentes fundamentais do sistema: armazenamento, execução e interface.
 Infraestrutura de notebooks na Netflix
Infraestrutura de notebooks na NetflixArmazenamento
A Netflix Data Platform usa armazenamento em nuvem Amazon S3 e EFS, que os notebooks tratam como sistemas de arquivos virtuais. Isso significa que cada usuário possui um diretório inicial do EFS contendo um espaço de trabalho pessoal para notebooks. Nesse espaço, armazenamos qualquer notebook criado ou carregado pelo usuário. Este também é o local em que a leitura e a gravação ocorrem quando o usuário inicia o laptop de forma interativa. Usamos a combinação [espaço de trabalho + nome do arquivo] para o espaço para nome, ou seja, /efs/users/kylek/notebooks/MySparkJob.ipynb para visualizar, compartilhar e no agendador de execução. Esse acordo evita colisões e facilita a identificação do usuário e da localização do notebook no EFS.
O caminho para a área de trabalho permite ignorar a complexidade do armazenamento em nuvem para o usuário. Por exemplo, apenas os nomes dos arquivos do notebook são exibidos no diretório, ou seja, MySparkJob.ipynb. O mesmo arquivo está disponível no terminal: ~ / notebooks / MySparkJob.ipynb.

Armazenamento de notebook vs. acesso
Quando o usuário define a tarefa de iniciar o bloco de anotações, o agendador copia o bloco de anotações do usuário do EFS para o diretório compartilhado no S3. O notebook no S3 se torna a fonte da verdade para o agendador ou o notebook de origem. Sempre que o agendador (expedidor) inicia o bloco de notas, ele cria um novo bloco de notas a partir da origem. Esse novo bloco de anotações é o que realmente inicia e se torna um registro invariável de uma execução específica, contendo o código executável, a saída e os logs de cada célula. Nós o chamamos de notebook de saída (saída).
A cocriação é uma característica fundamental da Netflix. Portanto, não foi surpreendente quando os usuários começaram a trocar links de URL para notebook. Com o crescimento dessa prática, somos confrontados com o problema de reescrita acidental causada pelo acesso simultâneo de vários usuários ao mesmo notebook. Nossos usuários queriam uma maneira de compartilhar seu notebook ativo no modo somente leitura. Isso levou à criação do viajante de bilhete mensal . Sob o capô, o Commuter exibe a API do Jupyter para listar / arquivos e / api / contents em uma lista de diretórios, para exibir o conteúdo dos arquivos e acessar os metadados do arquivo. Isso significa que os usuários podem visualizar blocos de anotações sem consequências para tarefas de combate ou blocos de anotações em execução.
Computar
Gerenciar recursos de computação é uma das partes mais difíceis de trabalhar com dados. Isso é especialmente verdade no Netflix, onde usamos a arquitetura de contêiner altamente escalável na AWS. Todas as tarefas na plataforma de dados são executadas em contêineres, incluindo consultas, pipelines e notebook. Naturalmente, queríamos abstrair o máximo possível dessa complexidade.
Um contêiner é fornecido quando o usuário inicia o servidor do notebook. Fornecemos padrões racionais para recursos de contêiner que funcionam para ~ 87,3% dos padrões de execução. Quando isso não é suficiente, os usuários podem solicitar mais recursos usando uma interface simples.

Os usuários podem selecionar o máximo ou o mínimo de memória + computação que precisarem
Também fornecemos um tempo de execução unificado com uma imagem de contêiner concluída. A imagem possui bibliotecas compartilhadas e um conjunto predefinido de kernels padrão. Nem tudo na imagem é estático - nossos kernels usam as versões mais recentes do Spark e as últimas configurações de cluster para nossa plataforma. Isso reduz o tempo de desorganização e ajuste de novos laptops e geralmente nos mantém em um único ambiente de tempo de execução.
Sob o capô, gerenciamos a orquestração e os ambientes com o Titus , nosso serviço de gerenciamento de contêiner Docker. Além disso, criamos um wrapper sobre esse serviço, gerenciando configurações e imagens específicas do servidor do usuário. A imagem também inclui grupos e funções de segurança do usuário, bem como variáveis de ambiente comuns para identificação nas bibliotecas incluídas. Isso significa que nossos usuários podem gastar menos tempo em infraestrutura e mais tempo em dados.
Interface
Anteriormente, descrevemos nossa visão de que os notebooks deveriam ser a ferramenta mais eficaz e ideal para trabalhar com dados. Mas isso apresenta um desafio interessante: como uma interface pode suportar todos os usuários? Não sabemos a resposta exata, mas temos algumas idéias.
Sabemos que a simplicidade é necessária. Significa uma interface de usuário intuitiva com um estilo minimalista e também requer um UX atencioso que facilita a execução de coisas complexas. Essa filosofia se encaixa bem nos objetivos do nteract , escritos no frontend do React para o notebook Jupyter. Ele enfatiza a composição como princípios fundamentais do design, tornando-o uma parte ideal da nossa visão.
A reclamação mais comum de nossos usuários é a falta de visualização nativa para todos os idiomas, especialmente para idiomas não-Python. Data Explorer nteract — , .
Data Explorer MyBinder. ( )

Visualizing the World Happiness Report dataset with nteract's Data Explorer
, notebook, .
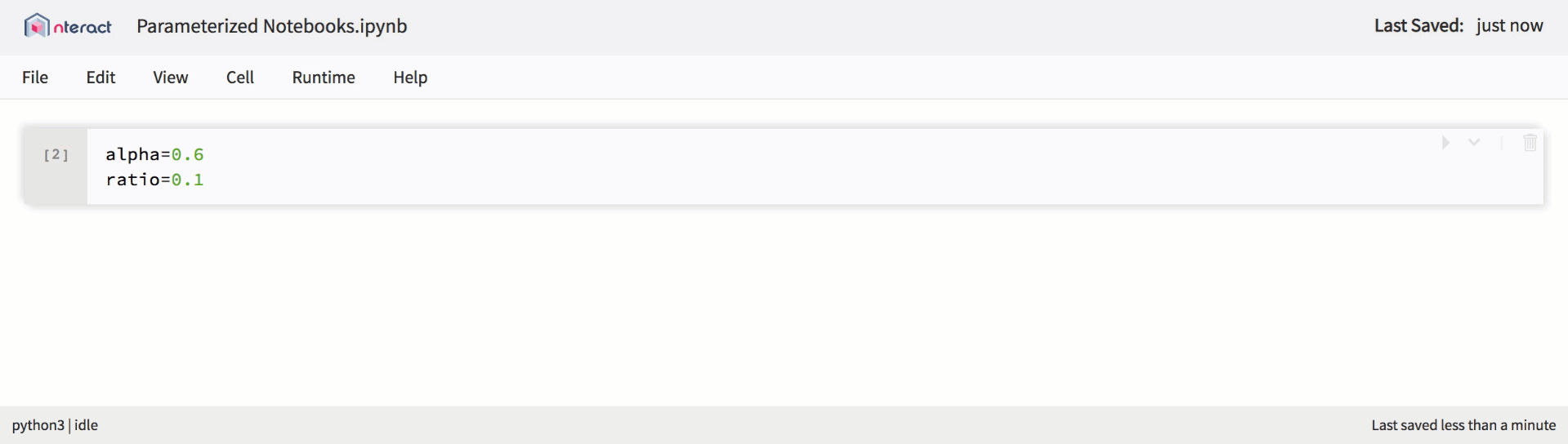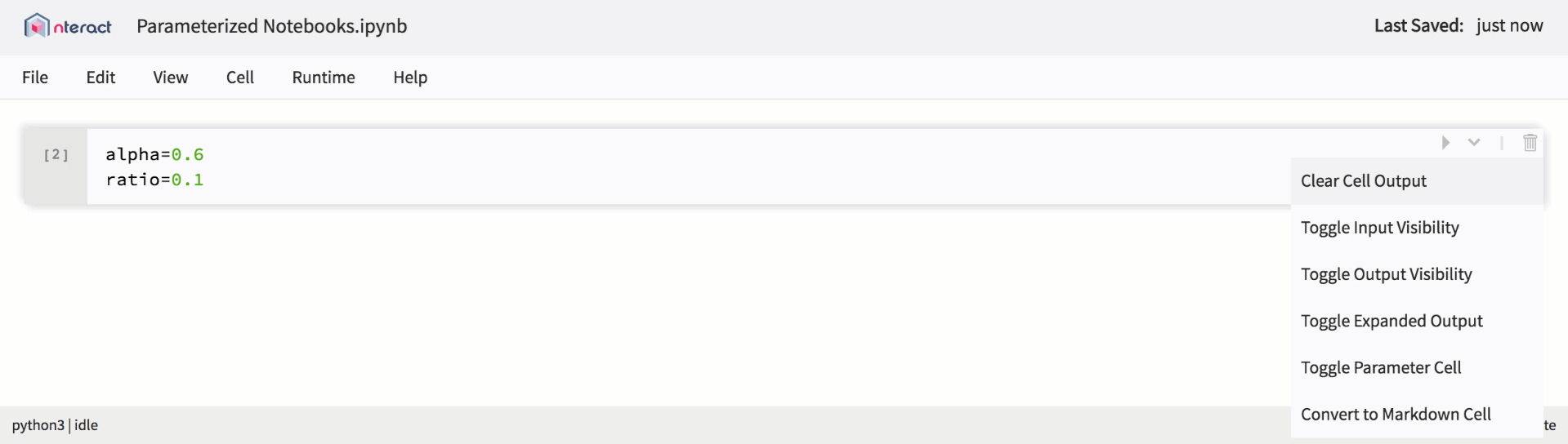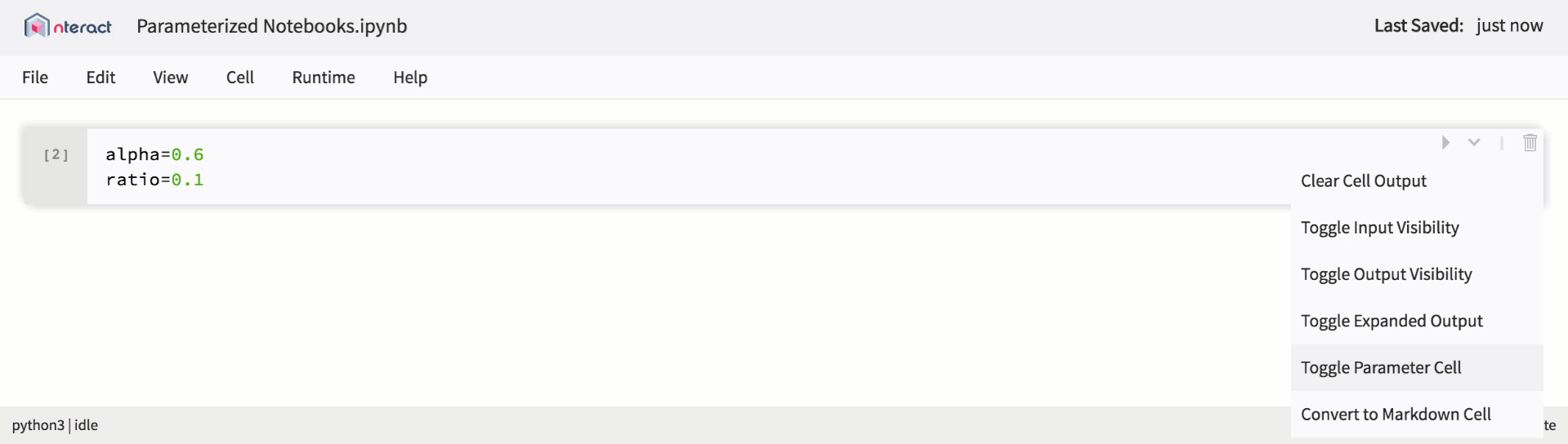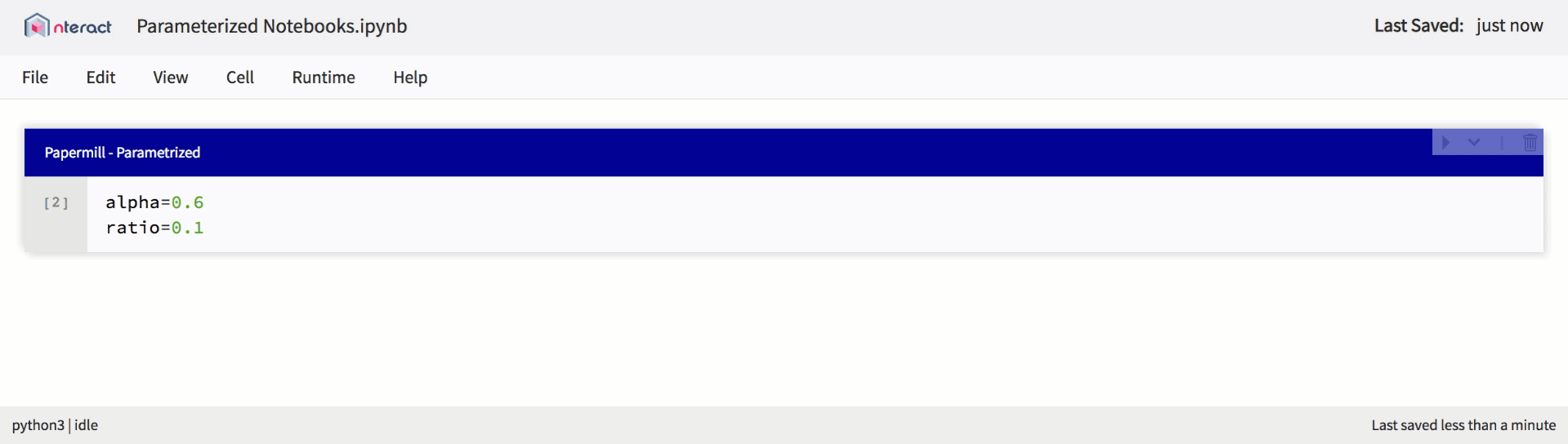
Native support for parameterized notebooks in nteract
Jupyter notebook , . , notebook. 12 , . , , , . , , Spark DataFrames, Scala. .
Open Source Projects
Netflix . , , . Netflix Data Platform Netflix OSS . “Not Invented Here”. Spark , Jupyter pandas .
, , Jupyter Project, . , nteract notebook UI Netflix. , . , Jupyter Notebook, , , . nteract.
, Netflix, . , , , , . , Papermill, .
What's Next ( )
, – (Netflixers) . Notebook Netflix. , . , .
! . , notebook. notebook Netflix, . :
I: Notebook Innovation ( )
II: Scheduling Notebooks
:
Scheduling workflows , — .