Recentemente, eles estão falando cada vez mais sobre a análise estática como um dos meios importantes para garantir a qualidade dos produtos de software que estão sendo desenvolvidos, especialmente do ponto de vista da segurança. A análise estática permite encontrar vulnerabilidades e outros erros, podendo ser usada no processo de desenvolvimento, integrando-se a processos customizados. No entanto, em conexão com a sua aplicação, muitas questões surgem. Qual é a diferença entre ferramentas pagas e gratuitas? Por que não basta usar o linter? No final, o que a estatística tem a ver com isso? Vamos tentar descobrir.

Vamos responder à última pergunta imediatamente - as estatísticas não têm nada a ver com isso, embora a análise estática seja frequentemente chamada erroneamente de estatística. A análise é estática, porque o aplicativo não inicia durante a digitalização.
Primeiro, vamos descobrir o que queremos procurar no código do programa. A análise estática é frequentemente usada para procurar vulnerabilidades - seções de código, cuja presença pode levar a uma violação da confidencialidade, integridade ou disponibilidade do sistema de informações. No entanto, as mesmas tecnologias podem ser usadas para procurar outros erros ou recursos de código.
Fazemos uma reserva de que, em geral, o problema da análise estática é algoritmicamente insolúvel (por exemplo, pelo teorema de Rice). Portanto, você deve limitar as condições da tarefa ou permitir imprecisão nos resultados (ignorar vulnerabilidades, fornecer falsos positivos). Acontece que em programas reais, a segunda opção acaba funcionando.
Existem muitas ferramentas gratuitas e pagas que reivindicam a pesquisa de vulnerabilidades em aplicativos escritos em diferentes linguagens de programação. Vamos considerar como o analisador estático geralmente é organizado. Além disso, focaremos no núcleo e nos algoritmos do analisador. Obviamente, as ferramentas podem diferir na facilidade de uso da interface, no conjunto de funcionalidades, no conjunto de plug-ins para diferentes sistemas e na facilidade de uso da API. Este é provavelmente um tópico para um artigo separado.
Apresentação intermediária
Três etapas básicas podem ser distinguidas no esquema de operação de um analisador estático.
- Construindo uma representação intermediária (uma representação intermediária também é chamada de representação interna ou modelo de código).
- O uso de algoritmos de análise estática, como resultado do qual o modelo de código é complementado com novas informações.
- Aplicando regras de pesquisa de vulnerabilidades a um modelo de código aumentado.
Analisadores estáticos diferentes podem usar modelos de código diferentes, por exemplo, o código-fonte do programa, fluxo de token, árvore de análise, código de três endereços, gráfico de fluxo de controle, bytecode - padrão ou nativo - e assim por diante.

Como os compiladores, a análise lexical e sintática é usada para construir uma representação interna, na maioria das vezes uma árvore de análise (AST, Abstract Syntax Tree). A análise lexical divide o texto do programa em elementos semânticos mínimos, na saída que recebe um fluxo de tokens. A análise verifica se o fluxo de token corresponde à gramática da linguagem de programação, ou seja, o fluxo de token resultante está correto do ponto de vista do idioma. Como resultado da análise, uma árvore de análise é construída - uma estrutura que modela o código fonte do programa. Em seguida, é aplicada a análise semântica, que verifica o cumprimento de condições mais complexas, por exemplo, a correspondência dos tipos de dados nas instruções de atribuição.
A árvore de análise pode ser usada como uma representação interna. Você também pode obter outros modelos na árvore de análise. Por exemplo, você pode convertê-lo em um código de três endereços que, por sua vez, cria um gráfico de fluxo de controle (CFG). Normalmente, o CFG é o modelo principal para algoritmos de análise estática.

Na análise binária (análise estática do código binário ou executável), um modelo também é construído, mas as práticas de engenharia reversa já são usadas aqui: descompilação, desofuscação, tradução reversa. Como resultado, você pode obter os mesmos modelos do código fonte, incluindo o código fonte (usando a descompilação completa). Às vezes, o próprio código binário pode servir como uma representação intermediária.
Teoricamente, quanto mais próximo o modelo do código fonte, pior a qualidade da análise. No próprio código-fonte, você pode procurar apenas expressões regulares, o que não permitirá encontrar pelo menos qualquer vulnerabilidade complicada.
Análise de fluxo de dados
Um dos principais algoritmos de análise estática é a análise de fluxo de dados. A tarefa desta análise é determinar em cada ponto do programa algumas informações sobre os dados nos quais o código opera. As informações podem ser diferentes, por exemplo, tipo ou valor de dados. Dependendo de quais informações precisam ser determinadas, a tarefa de analisar o fluxo de dados pode ser formulada.

Por exemplo, se for necessário determinar se uma expressão é uma constante, bem como o valor dessa constante, o problema de constantes de propagação (propagação constante) é resolvido. Se for necessário determinar o tipo de uma variável, podemos falar sobre o problema da propagação de tipos. Se você precisa entender quais variáveis podem apontar para uma área específica da memória (armazenar os mesmos dados), então estamos falando da tarefa de análise de sinônimos (análise de alias). Existem muitas outras tarefas de análise de fluxo de dados que podem ser usadas em um analisador estático. Como as etapas de construção de um modelo de código, essas tarefas também são usadas em compiladores.
Na teoria da construção de compiladores, são descritas soluções para o problema de análise intra-processual de um fluxo de dados (é necessário rastrear dados em um único procedimento / função / método). As decisões são baseadas na teoria das redes algébricas e outros elementos das teorias matemáticas. O problema de analisar o fluxo de dados pode ser resolvido em tempo polinomial, ou seja, por um tempo aceitável para computadores, se as condições do problema satisfizerem as condições do teorema da solvabilidade, o que na prática nem sempre ocorre.
Falaremos mais sobre como resolver o problema da análise intra-processual do fluxo de dados. Para definir uma tarefa específica, além de determinar as informações necessárias, você precisa determinar as regras para alterar essas informações ao transmitir dados de acordo com as instruções no CFG. Lembre-se de que os nós no CFG são os blocos básicos - conjuntos de instruções, cuja execução é sempre seqüencial e os arcos indicam a possível transferência de controle entre os blocos básicos.
Para cada instrução
conjuntos são definidos:
- (informações geradas pela instrução ),
- (informações destruídas pela instrução ),
- (informações no ponto anterior à instrução ),
- (informações no ponto após a instrução )
O objetivo da análise de fluxo de dados é definir conjuntos
e
para cada instrução
programas. O sistema básico de equações com as quais as tarefas de análise do fluxo de dados são resolvidas é determinado pela seguinte relação (equações de fluxo de dados):
A segunda relação formula as regras pelas quais as informações são “combinadas” nos pontos de confluência dos arcos CFG (
- antecessores
em CFG). A operação de união, interseção e algumas outras podem ser usadas.
A informação desejada (o conjunto de valores das funções introduzidas acima) é formalizada como uma rede algébrica. Funções
e
são considerados mapeamentos monótonos em redes (funções de fluxo). Para equações de fluxo de dados, a solução é o ponto fixo desses mapeamentos.
Os algoritmos para resolver problemas de análise de fluxo de dados procuram pontos fixos máximos. Existem várias abordagens para a solução: algoritmos iterativos, análise de componentes fortemente conectados, análise T1-T2, análise de intervalo, análise estrutural e assim por diante. Existem teoremas sobre a correção desses algoritmos, que determinam o escopo de sua aplicabilidade a problemas reais. Repito, as condições dos teoremas podem não ser cumpridas, o que leva a algoritmos mais complicados e resultados imprecisos.
Análise interprocedural
Na prática, é necessário resolver os problemas da análise interprocedural do fluxo de dados, pois raramente a vulnerabilidade será completamente localizada em uma função. Existem vários algoritmos comuns.
Funções embutidas . No ponto de chamada da função, incorporamos a função chamada, reduzindo assim a tarefa de análise interprocedural à tarefa de análise intraprocedural. Esse método é facilmente implementado, mas, na prática, quando é aplicado, uma explosão combinatória é rapidamente alcançada.
Construir um gráfico geral do fluxo de controle do programa no qual as chamadas de função são substituídas por transições para o endereço inicial da função chamada e as instruções de retorno são substituídas por transições para todas as instruções, seguindo todas as instruções para chamar esta função. Essa abordagem adiciona um grande número de caminhos de execução irrealizáveis, o que reduz bastante a precisão da análise.
Um algoritmo semelhante ao anterior, mas ao alternar para uma função,
o contexto é
salvo - por exemplo, um quadro de pilha. Assim, o problema de criar caminhos irrealizáveis é resolvido. No entanto, o algoritmo é aplicável com profundidade de chamada limitada.
Informações da função de construção (resumo da função). O algoritmo de análise interprocedural mais aplicável. Ele se baseia na construção de um resumo para cada função: as regras pelas quais as informações sobre os dados são convertidas ao aplicar essa função, dependendo dos vários valores dos argumentos de entrada. O resumo pronto é usado na análise processual interna das funções. Uma dificuldade separada aqui é a determinação da ordem da passagem da função, pois na análise caso a caso, um resumo já deve ser construído para todas as funções chamadas. Geralmente, são criados algoritmos iterativos especiais para percorrer um gráfico de chamada.
A análise interprocedural do fluxo de dados é uma tarefa exponencialmente difícil, e é por isso que o analisador precisa realizar várias otimizações e suposições (é impossível encontrar a solução exata em tempo adequado para o poder da computação). Geralmente, ao desenvolver um analisador, é necessário encontrar um compromisso entre a quantidade de recursos consumidos, o tempo de análise, o número de falsos positivos e vulnerabilidades encontrados. Portanto, um analisador estático pode funcionar por muito tempo, consumir muitos recursos e fornecer falsos positivos. No entanto, sem isso, é impossível encontrar as vulnerabilidades mais importantes.
É nesse ponto que os analisadores estáticos sérios diferem de muitas ferramentas abertas, que, em particular, podem se posicionar na busca de vulnerabilidades. As verificações rápidas em tempo linear são boas quando você precisa obter o resultado rapidamente, por exemplo, durante a compilação. No entanto, essa abordagem não consegue encontrar as vulnerabilidades mais críticas - por exemplo, relacionadas à implementação de dados.
Análise de contaminação
Também devemos nos debruçar sobre uma das tarefas da análise de fluxo de dados - análise de mancha. A análise de contaminação permite distribuir sinalizadores por todo o programa. Essa tarefa é essencial para a segurança das informações, pois é com a ajuda delas que as vulnerabilidades são descobertas relacionadas à implementação dos dados (injeção SQL, scripts cruzados, redirecionamentos abertos, falsificação do caminho do arquivo etc.), além do vazamento de dados confidenciais (entrada de senha em registros de eventos, transferência insegura de dados).
Vamos tentar simular uma tarefa. Suponha que queremos rastrear n sinalizadores -
. Muitas informações aqui incluirão muitos subconjuntos
\ {f_1, ..., f_n \} , pois para cada variável em cada ponto do programa queremos definir seus sinalizadores.
Em seguida, precisamos definir as funções de fluxo. Nesse caso, as funções de fluxo podem ser determinadas pelas seguintes considerações.
- Muitas regras são dadas nas quais são definidas construções que levam ao aparecimento ou alteração de um conjunto de sinalizadores.
- A operação de atribuição vira as bandeiras da direita para a esquerda.
- Qualquer operação desconhecida para conjuntos de regras combina sinalizadores de todos os operandos e o conjunto final de sinalizadores é adicionado aos resultados da operação.
Por fim, você precisa definir as regras para mesclar informações nos pontos de junção dos arcos CFG. A mesclagem é determinada pela regra de união, ou seja, se diferentes conjuntos de sinalizadores para uma única variável vierem de diferentes blocos base, eles serão mesclados durante a mesclagem. A inclusão de falsos positivos vem daqui: o algoritmo não garante que o caminho para o CFG no qual o sinalizador apareceu possa ser executado.
Por exemplo, você precisa detectar vulnerabilidades como a Injeção SQL. Essa vulnerabilidade ocorre quando dados não verificados do usuário se enquadram nos métodos de trabalho com o banco de dados. É necessário determinar que os dados vieram do usuário e adicionar o sinalizador de contaminação a esses dados. Normalmente, a base de regras do analisador define as regras para definir o sinalizador de contaminação. Por exemplo, defina um sinalizador para o valor de retorno do método getParameter () da classe Request.
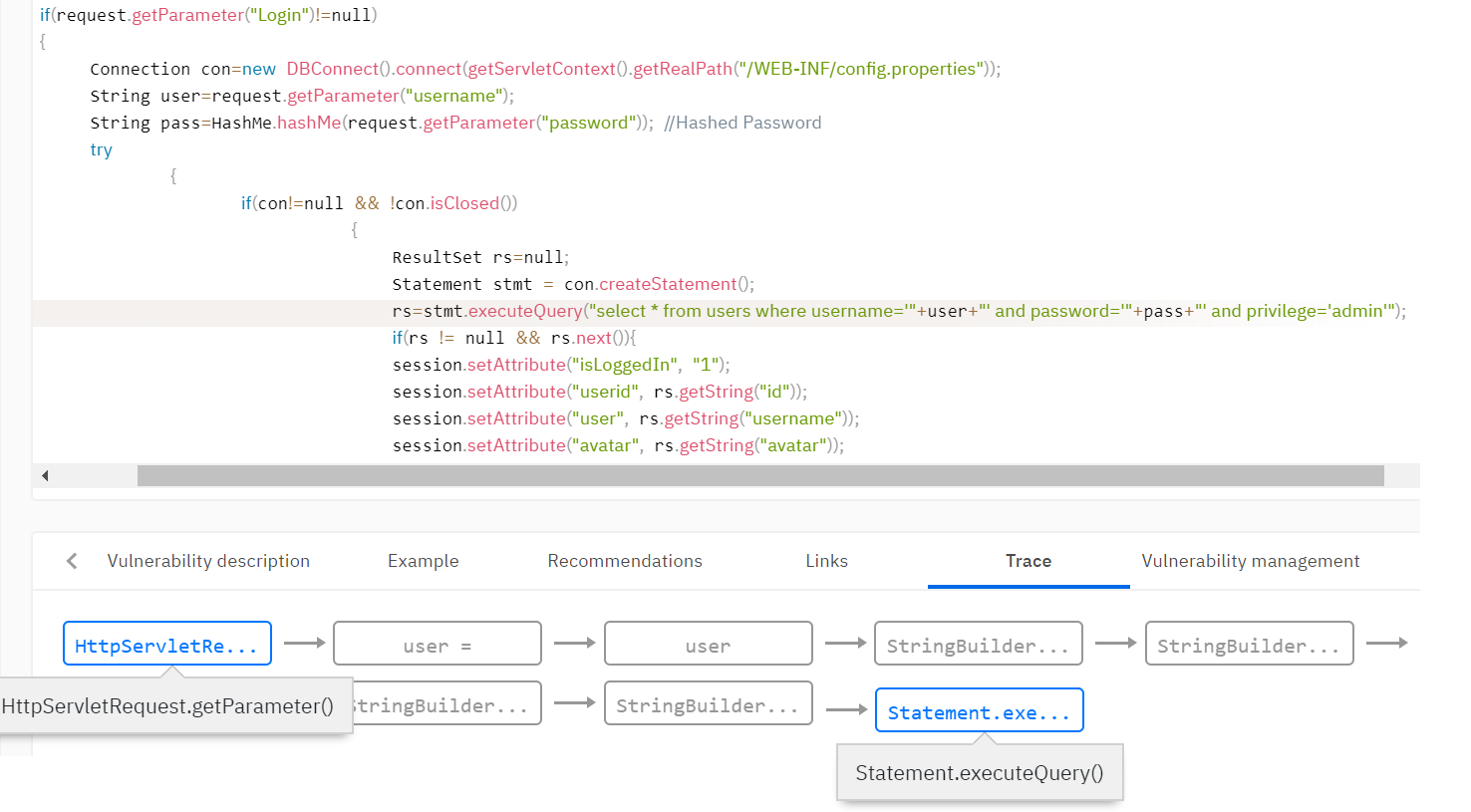
Em seguida, você precisa distribuir o sinalizador por todo o programa analisado usando a análise de contaminação, pois os dados podem ser validados e o sinalizador pode desaparecer em um dos caminhos de execução. O analisador define muitas funções que removem sinalizadores. Por exemplo, a função de validar dados de tags html pode limpar o sinalizador de vulnerabilidades de script entre sites (XSS). Ou, a função para vincular uma variável a uma expressão SQL remove o sinalizador para incorporação no SQL.
Regras de pesquisa de vulnerabilidade
Como resultado da aplicação dos algoritmos acima, a representação intermediária é complementada com as informações necessárias para procurar vulnerabilidades. Por exemplo, no modelo de código, são exibidas informações sobre quais variáveis pertencem a determinados sinalizadores, quais dados são constantes. As regras de pesquisa de vulnerabilidade são formuladas em termos de um modelo de código. As regras descrevem quais recursos na exibição intermediária final podem indicar uma vulnerabilidade.
Por exemplo, você pode aplicar uma regra de pesquisa de vulnerabilidade que define uma chamada de método com um parâmetro que possui o sinalizador de contaminação. Retornando ao exemplo de injeção SQL, verificamos que as variáveis com o sinalizador de contaminação não se enquadram na função de consulta ao banco de dados.
Acontece que uma parte importante do analisador estático, além da qualidade dos algoritmos, é a configuração e a base de regras: uma descrição de quais construções no código geram sinalizadores ou outras informações, quais construções validam esses dados e para quais construções o uso desses dados é fundamental.
Outras abordagens
Além da análise do fluxo de dados, existem outras abordagens. Um dos famosos é a execução simbólica ou a interpretação abstrata. Nessas abordagens, o programa é executado em domínios abstratos, o cálculo e a distribuição de restrições de dados no programa. Usando essa abordagem, é possível encontrar não apenas a vulnerabilidade, mas também calcular as condições nos dados de entrada sob os quais a vulnerabilidade é explorável. No entanto, essa abordagem apresenta sérias desvantagens - com soluções padrão em programas reais, os algoritmos explodem exponencialmente e as otimizações levam a sérias perdas na qualidade da análise.
Conclusões
No final, acho que vale a pena resumir, falando sobre os prós e contras da análise estática. É lógico que comparemos com a análise dinâmica, na qual a pesquisa de vulnerabilidades ocorre durante a execução do programa.

A vantagem indubitável da análise estática é a cobertura completa do código analisado. Além disso, as vantagens da análise estática incluem o fato de que para executá-la, não há necessidade de executar o aplicativo em um ambiente de combate. A análise estática pode ser implementada nos estágios iniciais do desenvolvimento, minimizando o custo das vulnerabilidades encontradas.
As desvantagens da análise estática são a presença inevitável de falsos positivos, o consumo de recursos e um longo tempo de varredura em grandes quantidades de código. No entanto, essas desvantagens são inevitáveis, com base nas especificidades dos algoritmos. Como vimos, um analisador rápido nunca encontrará uma vulnerabilidade real, como injeção de SQL e similares.
Escrevemos em
outro artigo sobre as dificuldades remanescentes do uso de ferramentas de análise estática, que, como se vê, podem ser superadas muito bem.