O objetivo era criar um aplicativo para Mac que reconheça o código de imagens e vídeos.
Eu queria ter certeza de que, mesmo com uma grande quantidade de código, o texto fosse reconhecido em menos de um segundo.
O problema é facilitado pelo fato de que o idioma no qual o código é escrito é sempre inglês e a largura entre todas as letras é a mesma (fonte monoespaçada) - elas são usadas para programação e nessas fontes é fácil ver a diferença entre 1 e I, 0 e O, etc.
Em suma, a tarefa se resume a duas partes:
1. Encontrar a própria letra com suas bordas
E a Vision, a nova estrutura da Apple, fez um ótimo trabalho.
Aqui está uma captura de tela de como funciona. 2. Reconhecimento da letra nos limites indicados
Decidi não seguir de maneira complicada e verificar certos pixels do quadrado, dentro dos limites dos quais existem letras (digamos: centro, cantos, lados) e, a partir da presença ou ausência de uma letra, classifico qual é a letra.
Exemplo ilustrativo:

E aqui está a aparência da árvoreEsta é uma parte, pois tudo não caberia e não é necessário.
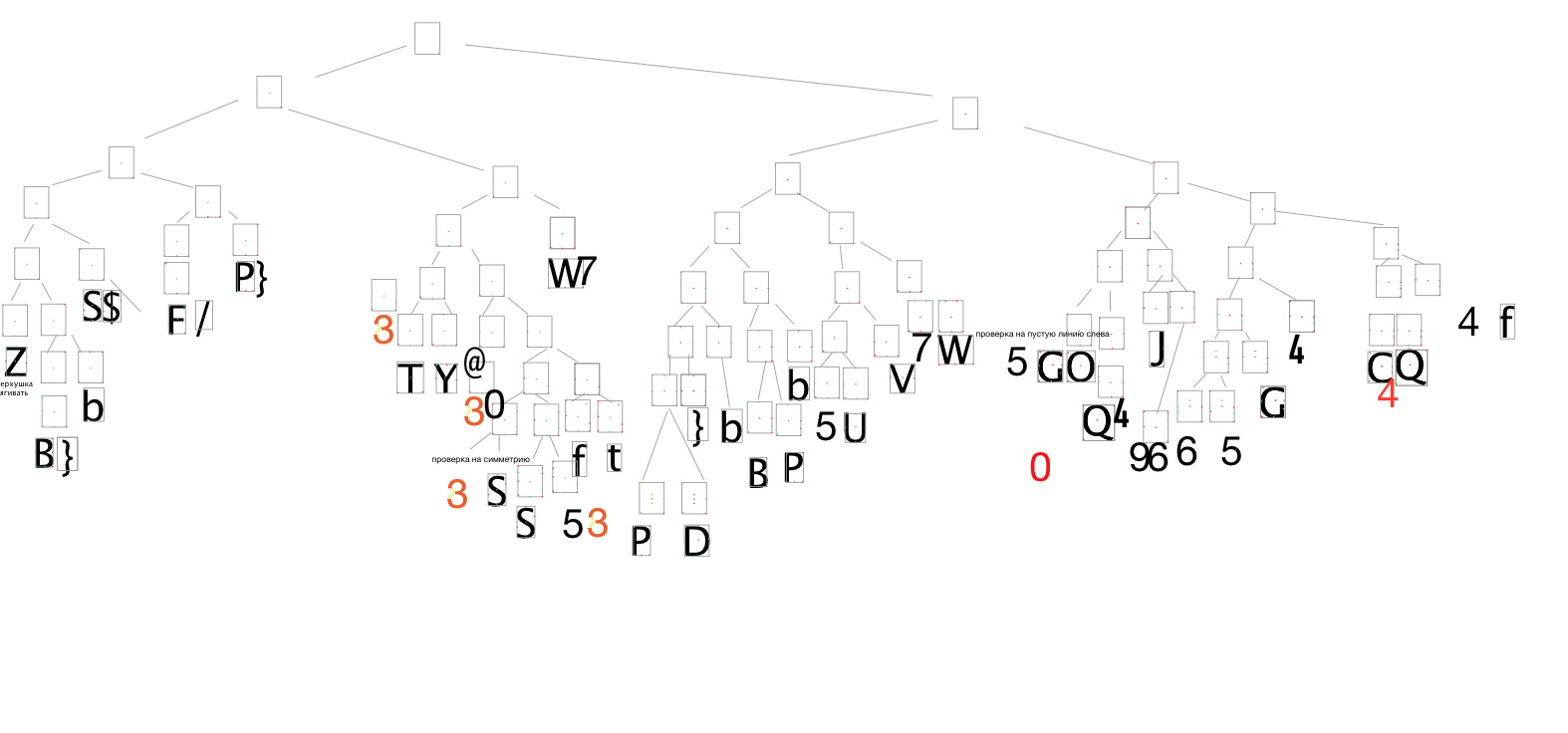
Como transferir esse desenho esquemático para o código, para não se enterrar nele e para que seja tão óbvio?
É aqui que uma árvore binária vem em socorro. Aqui está o seu quadro.
enum Tree<Node, Result> {
Agora, com base nisso, podemos transferir todo o desenho para o código.
É assim que um pedaço de madeira pareceria maior.

Você pode decompor tudo de maneira muito esquemática e encontrar facilmente a letra de que precisa.
E no último momento, é assim que o modelo se parece, no qual todo o trabalho ocorre.
extension Tree where Node == OCROperations, Result == String { func find(_ colorChecker: LetterExistenceChecker, with frame: CGRect) -> String? { switch self { case .empty: return nil case .r(let element): return element case let .n(operation, left, right): let exist = operation.action(colorChecker, frame) return (exist ? left : right).find(colorChecker, with: frame) } } }
Nesta árvore, passamos a classe LetterExistenceChecker, responsável por verificar a presença de um pixel de uma letra em um ponto específico dentro dos limites do quadrado desejado. Obviamente, omiti muitos detalhes, caso contrário, o artigo seria muito complicado. E aqui, não apenas essas duas etapas mencionadas no artigo, mas muito mais, mas foram omitidas, porque o objetivo era mostrar como usar a árvore binária e a enumeração.
Aqui está uma demonstração de como o programa funciona. Observe que, como o objetivo era reconhecer apenas texto com código, decidi ignorar todo o resto do texto que não é código, para que o programa só procurasse texto com código.
Ficarei feliz em ouvir seus comentários, críticas.