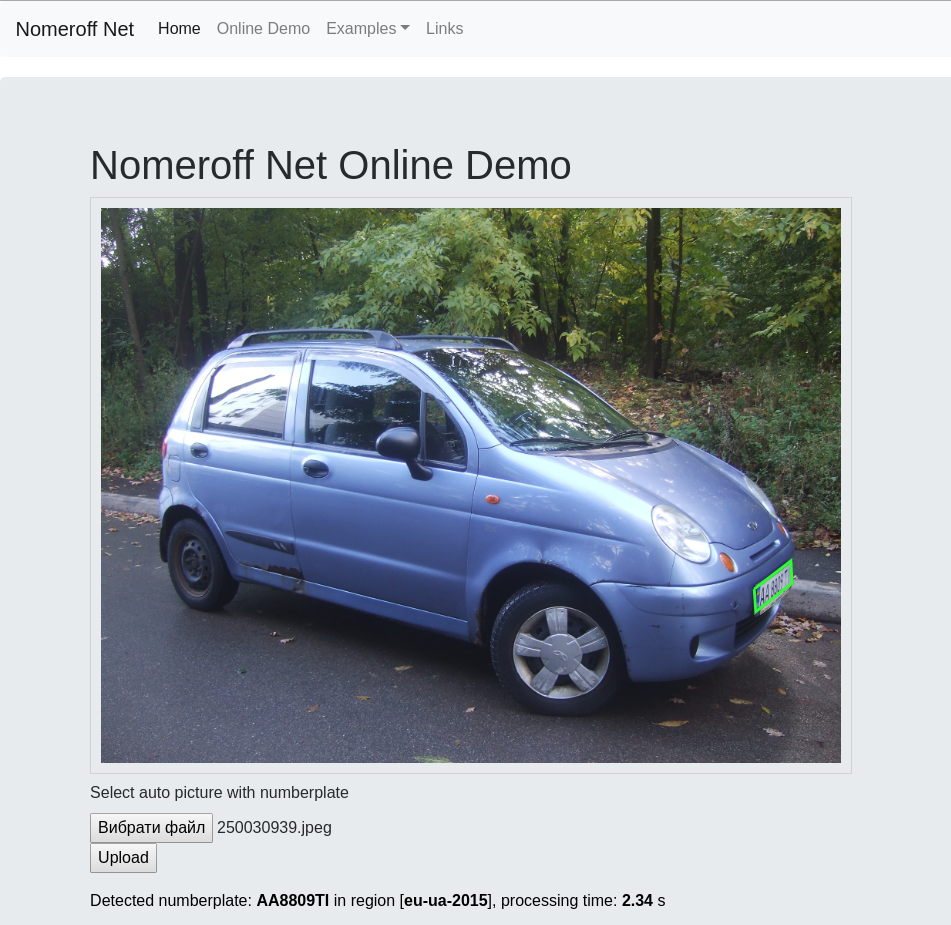
Continuamos a história de como reconhecer placas de carros para quem pode escrever o aplicativo hello world em python! Nesta parte, aprenderemos como treinar modelos que estão procurando uma região de um determinado objeto e também como escrever uma rede RNN simples que lida melhor com números de leitura do que alguns colegas comerciais.
Nesta parte, mostrarei como treinar o Nomeroff Net para seus dados, como obter alta qualidade de reconhecimento, como configurar o suporte à GPU e acelerar tudo por uma ordem de magnitude ...
Treinamos Mask RCNN para encontrar a área com o número
Obviamente, você pode encontrar não apenas um número, mas qualquer outro objeto que precise encontrar. Por exemplo, você pode, por analogia, procurar um cartão de crédito e ler seus detalhes. Em geral, encontrar a máscara na qual o objeto está inscrito na imagem é chamada de tarefa "Segmentação de Instância" (eu já escrevi sobre isso na primeira parte).
Agora vamos descobrir como treinar a rede para resolver esse problema. De fato, há pouca programação aqui, tudo se resume a uma marcação de dados monótona, tediosa e uniforme. Sim, sim, depois de marcar seus primeiros cem, você entenderá o que quero dizer :)
Portanto, o algoritmo de preparação de dados é o seguinte:
- Tiramos imagens de pelo menos 300 x 300, despejamos tudo em uma pasta
- Faça o download da ferramenta de marcação VGG Image Annotator (VIA) , você pode marcá- la on-line , a saída será um diretório com uma foto e o arquivo json que você criou com a marcação. Existem duas pastas, no chamado trem, coloque a parte principal dos exemplos; no segundo, cerca de 20 a 30% do número de exemplos do primeiro pacote (é claro que essas pastas não devem ter as mesmas fotos). Você pode ver um exemplo de dados marcados para o projeto Nomeroff Net . Pela quantidade - quanto mais, melhor. Alguns especialistas recomendam 5.000 exemplos, somos preguiçosos, digitando um pouco mais de 1.000, pois o resultado foi muito bom conosco.

- Para iniciar o treinamento, você precisa fazer o download do projeto Nomeroff Net no Github, instalar o Mask RCNN com todas as dependências e tentar executar o script de treinamento train / mrcnn.ipynb em nossos dados
- Eu imediatamente te aviso, isso não funciona rápido. Se você não possui uma GPU, isso pode levar dias. Para acelerar significativamente o processo de aprendizado, é aconselhável instalar o tensorflow com o suporte da GPU .
- Se o treinamento em nosso conjunto de dados foi bem-sucedido, agora você pode mudar com segurança para o seu próprio país.
Observe: nós não treinamos tudo do zero, treinamos o modelo treinado nos dados do conjunto de dados COCO , que o Mask RCNN baixa na primeira execução
- Você pode treinar não coco, mas nosso modelo mask_rcnn_numberplate_0700.h5 e especificar o caminho para esse modelo no parâmetro de configuração WEIGHTS (por padrão, "WEIGHTS": "coco")
- Dos parâmetros que podem ser estendidos são: EPOCH, STEPS_PER_EPOCH
- O resultado após cada era será despejado na pasta ./logs/numberplate<date of launch> /
Para testar o modelo treinado na prática, nos
exemplos de projeto, substitua
MASK_RCNN_MODEL_PATH pelo caminho para o seu modelo.
Aprimorando o classificador de matrícula para seus requisitos
Depois que as áreas com placas são encontradas, você precisa tentar determinar qual estado / tipo de número que reconhecemos. Aqui a universalização trabalha contra a qualidade do reconhecimento. Portanto, idealmente, você precisa treinar um classificador que não apenas determine em qual país o número é, mas também o tipo de design desse número (local dos caracteres, opções de símbolos para um determinado tipo de número).
Em nosso projeto, implementamos o apoio ao reconhecimento dos números da Ucrânia, da Federação Russa e dos números europeus em geral. A qualidade do reconhecimento dos números europeus é um pouco pior, pois existem números com desenhos diferentes e um número maior de caracteres encontrados. Talvez, com o tempo, existam módulos de reconhecimento separados para "eu-ee", "eu-pl", "eu-nl", ...
Antes de classificar uma placa, você precisa "cortá-la" da imagem e normalizá-la; em outras palavras, remova todas as distorções ao máximo e obtenha um retângulo puro que será submetido a análises adicionais. Essa tarefa acabou não sendo trivial, eu até precisei me lembrar da matemática da escola e escrever uma implementação especializada do algoritmo de agrupamento k-means :). O módulo que processa isso é chamado RectDetector, é assim que os números normalizados se parecem, que iremos classificar e reconhecer ainda mais.

Para de alguma forma automatizar o processo de criação de um conjunto de dados para classificação de números, desenvolvemos um
pequeno painel de administração no nodejs . Usando este painel de administração, você pode marcar a inscrição na placa do veículo e a classe à qual ela pertence.
Pode haver vários classificadores. No nosso caso, por tipo de número e por ser esboçado / pintado na foto.
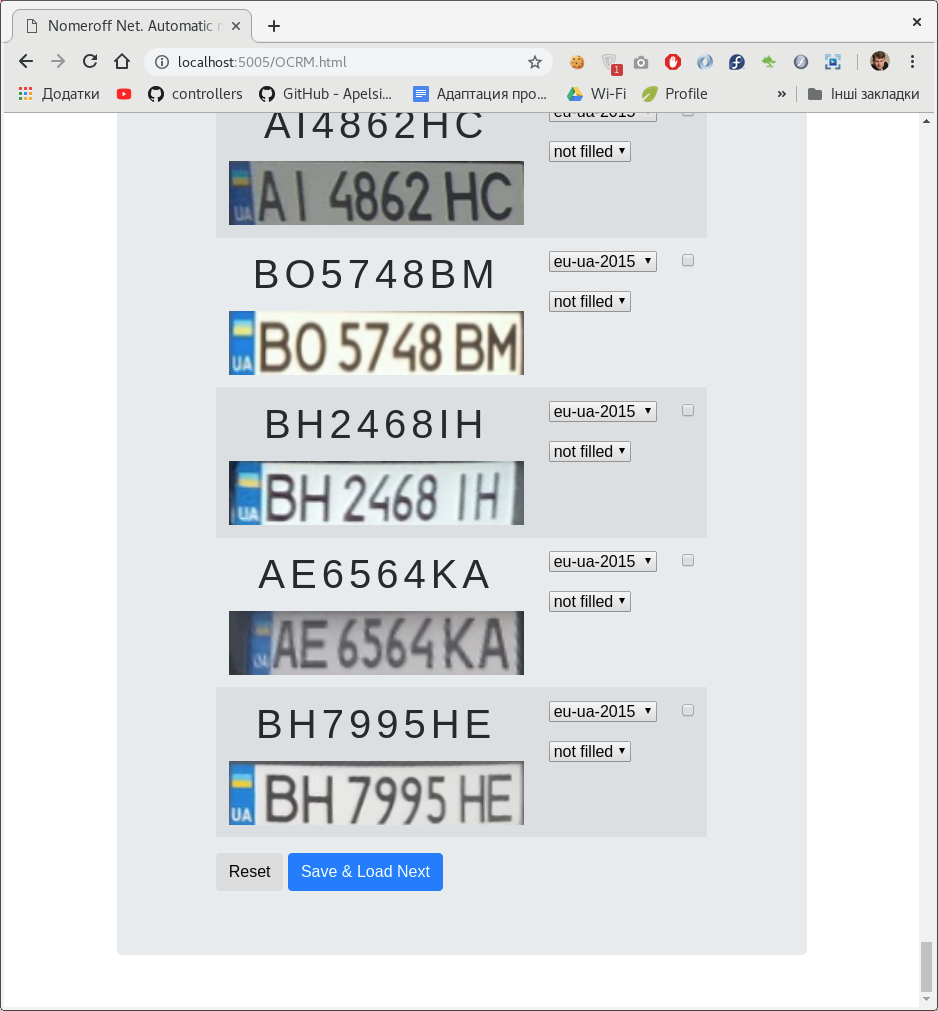
Depois de marcarmos o conjunto de dados, o dividimos em amostras de treinamento, validação e teste. Como exemplo, faça o download do nosso
conjunto de
dados autoriaNumberplateOptions3Dataset-2019-05-20-20.zip para ver como tudo
funciona lá.
Como a seleção já foi marcada (moderada), é necessário alterar “isModerated”: 1 para “isModerated”: 0 nos arquivos json aleatórios e, em seguida, iniciar o painel de administração .
Nós treinamos o classificador:
O script de treinamento
train / options.ipynb ajudará você a obter sua versão do modelo. Nosso exemplo mostra que, para a classificação de regiões / tipos de placas, obtivemos uma precisão de
98,8% , para a classificação de "O número está pintado?"
99,4% em nosso conjunto de dados. Concordo, acabou bem.
Treine seu OCR (reconhecimento de texto)
Bem, encontramos a área com o número e a normalizamos em um retângulo que contém a inscrição com o número. Como lemos o texto? A maneira mais fácil é executá-lo através do FineReader ou Tesseract. A qualidade será "não muito", mas com uma boa resolução da área com o número, você poderá obter uma precisão de 80%. Na verdade, isso não é uma precisão ruim, mas se eu lhe disser que você pode obter
97% e ao mesmo tempo gastar significativamente menos recursos do computador? Parece bom - vamos tentar. Uma arquitetura um pouco incomum é adequada para esses fins, na qual são utilizadas as camadas convolucionais e recorrentes. A arquitetura desta rede é mais ou menos assim:
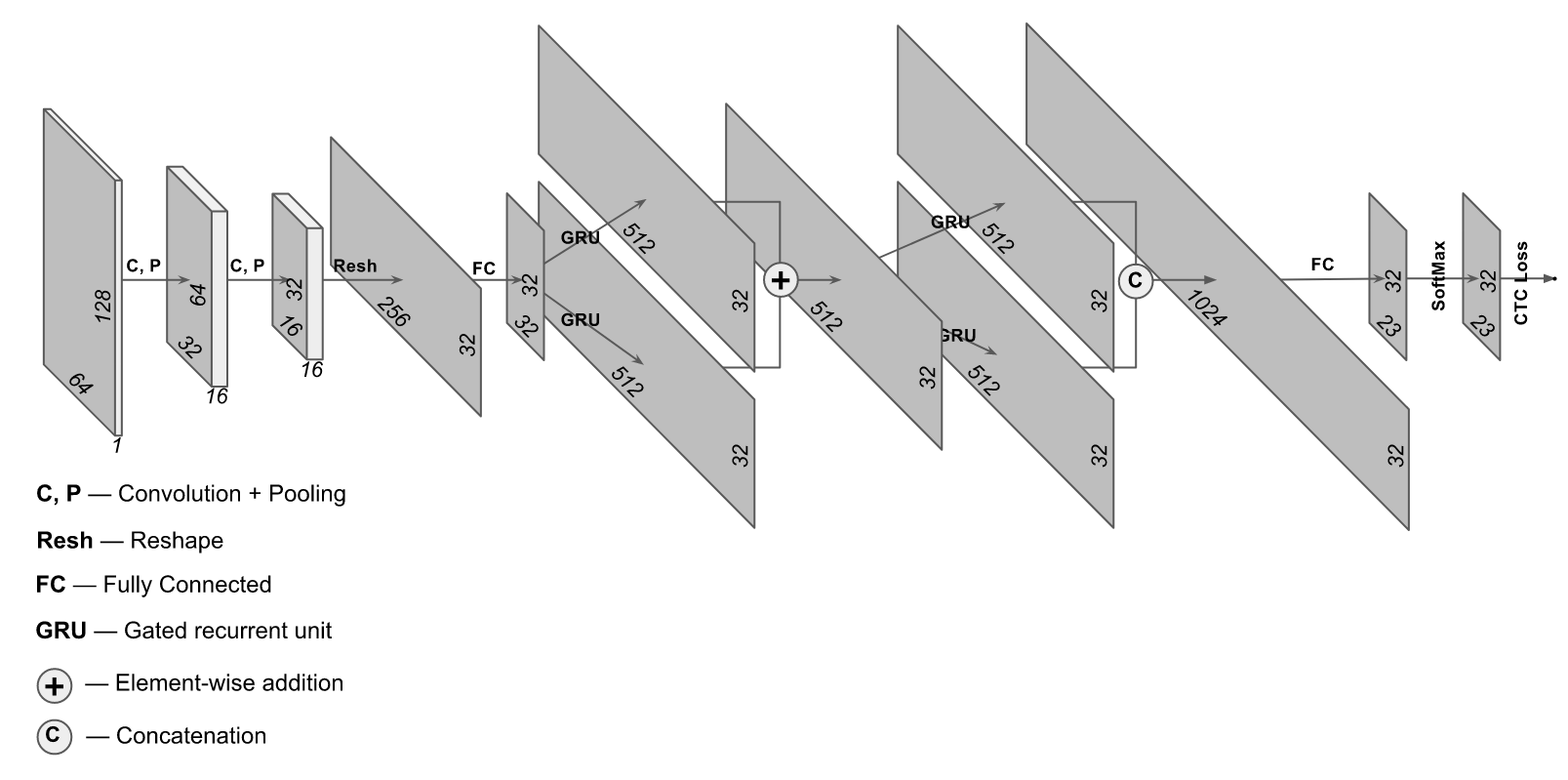
A implementação foi retirada do site
https://supervise.ly/ , modificamos um pouco para treinamento em fotos reais (no site de supervisão, uma opção foi feita para amostragem sintética)
Agora começa a parte divertida, marque pelo menos 5.000 números :). Marcamos cerca de
100.000 ucranianos ,
~ 50.000 ucranianos com o design "antigo" ,
~ 6.500 europeus ,
~ 10.000 RF . Esta foi a parte mais difícil do desenvolvimento. Você nem imagina quantas vezes adormeci em uma cadeira de computador moderando várias horas por dia para a próxima parte dos números. Mas o verdadeiro herói da marcação é
dimabendera - ele marcou 2/3 de todo o conteúdo (dê-lhe uma vantagem se você entender como é chato fazer todo esse trabalho :))
Você pode tentar de alguma forma automatizar esse processo, por exemplo, tendo reconhecido anteriormente cada imagem com o Tesseract e corrigindo os erros usando
nosso painel de administração .
Observe: o mesmo painel de administração é usado para marcar o classificador e o OCR no número. Você pode carregar os mesmos dados lá e ali, exceto os números esboçados, é claro.
Se você marcar pelo menos 5.000 números e puder treinar seu OCR - fique à vontade para organizar um prêmio para si mesmo com seus superiores, tenho certeza de que esse teste não é para os fracos!
Treinamento de introdução
O
script train / ocr-ru.ipynb treina o modelo para números russos; existem exemplos para a
Ucrânia e a
Europa .
Observe que nas configurações de treinamento há apenas uma era (uma passagem).
Um recurso do treinamento desse conjunto de dados será um resultado muito diferente para cada tentativa. Antes de cada sessão de treinamento, os dados são misturados em ordem aleatória; às vezes, é mais "não muito bom" para o treinamento. Eu recomendo que você tente pelo menos 5 vezes, enquanto controla a precisão dos dados de teste. Com diferentes tentativas de lançamento, nossa precisão pode "pular" de
87% para 97% .
Algumas recomendações :
- Não há necessidade de inicializar tudo de uma nova maneira, basta reiniciar a linha model = ocrTextDetector.train (mode = MODE) até obter o resultado esperado
- Um dos motivos da baixa precisão são os dados insuficientes. Se você não gostar, marcamos uma e outra vez, em algum momento a qualidade para de crescer, para cada conjunto de dados é diferente, você pode se concentrar no número de 10.000 exemplos rotulados
- O treinamento será mais rápido se você tiver o driver NVIDIA CuDNN instalado, altere o valor MODE = "gpu" no script de treinamento e o CuDNNGRU será conectado em vez da camada GRU, o que levará a uma aceleração tríplice.
Um pouco sobre a configuração do tensorflow para as GPUs NVIDIA
Se você é um feliz proprietário de uma GPU da NVIDIA, às vezes pode acelerar as coisas: números de treinamento de modelo e inferência (modo de reconhecimento). O problema é instalar e compilar tudo corretamente.
Nós usamos o Fedora Linux em nossos servidores ML (isso aconteceu historicamente).
A sequência aproximada de ações para quem usa este sistema operacional é a seguinte:
- Colocamos o driver da GPU para a sua versão do sistema operacional, aqui para o Fedora
- Conectamos o repositório NVIDIA e instalamos o pacote CUDA a partir daí, aqui para o CentOS / Fedora
- Colocamos o bazel e coletamos o fluxo tensor das fontes nesta doca
- Também é aconselhável instalar a versão antiga do compilador gcc, chamada cuda-gcc, tudo estava indo bem para mim no cuda-gcc 6.4. Ao configurar a montagem, especifique o caminho para cuda-gcc
Se você não conseguir construir o tensorflow com suporte à gpu, poderá iniciar tudo por meio do docker e, além do docker, precisará instalar o pacote nvidia-docker2. Dentro do contêiner do docker, você pode executar o notebook jupyter e, em seguida, executar tudo lá.
jupyter notebook --ip=0.0.0.0 --port=8888 --allow-root
Links úteis
Também quero agradecer aos 2expres,
habrausers glassofkvass, por fornecerem às fotos números e
dimabendera por escrever a maior parte do código e marcar a maioria dos dados do projeto Nomeroff Net.
UPD1: Como eu e Dmitri somos enviados às perguntas padrão da PM sobre reconhecimento de números, uma combinação de fluxo tensor com gpu, etc. e Dmitry e eu damos as mesmas respostas, quero de alguma forma otimizar esse processo.
Sugerimos tornar a correspondência nos comentários mais estruturada, dividida por tópico. Há uma funcionalidade conveniente no GitHub para isso. No futuro, faça perguntas não nos comentários, mas na
edição temática no github Nomeroff NetUPD2: Com o tempo, também apareceram conjuntos de dados:
números do Cazaquistão ,
números da Geórgia