Aconteceu a você que você se envolve em algum tipo de jogo simples, pensando que a inteligência artificial pode lidar com isso? Eu costumava e decidi tentar criar um bot player desse tipo. Além disso, agora existem muitas ferramentas para visão computacional e aprendizado de máquina que permitem criar modelos sem uma compreensão profunda dos detalhes da implementação. Os mortais comuns podem fazer um protótipo sem construir redes neurais por meses a partir do zero.

Abaixo do corte, você encontrará o processo de criação de um bot de prova de conceito para o jogo Clash Royale, no qual eu usei as bibliotecas Scala, Python e CV. Usando visão computacional e aprendizado de máquina, tentei criar um bot para um jogo que interage como um jogador ao vivo.
Meu nome é Sergey Tolmachev, sou desenvolvedor líder do Scala na plataforma Waves e ensino
um curso Scala no distrito binário, e no meu tempo livre estudo outras tecnologias, como a IA. E eu queria reforçar as habilidades adquiridas com alguma experiência prática. Ao contrário das competições de IA, em que seu bot joga contra bots de outros usuários, o Clash Royale pode jogar contra pessoas, o que parece engraçado. Seu bot pode aprender a derrotar jogadores reais!
Mecânica de jogo em Clash Royale
A mecânica do jogo é bastante simples. Você e seu oponente têm três edifícios: uma fortaleza e duas torres. Os jogadores antes do jogo coletam baralhos - 8 unidades disponíveis, que são usadas na batalha. Eles têm níveis diferentes e podem ser bombeados, coletando mais cards dessas unidades e comprando atualizações.
Após o início do jogo, você pode colocar as unidades disponíveis a uma distância segura das torres inimigas, enquanto gasta unidades de mana, que são restauradas lentamente durante o jogo. As unidades são enviadas para os edifícios inimigos e distraídas pelos inimigos encontrados ao longo do caminho. O jogador só pode controlar a posição inicial das unidades - ele pode afetar o movimento adicional e os danos apenas definindo outras unidades.
Ainda existem feitiços que podem ser jogados em qualquer lugar do campo, pois geralmente causam danos às unidades de maneiras diferentes. Magias podem clonar, congelar ou acelerar unidades em uma área.
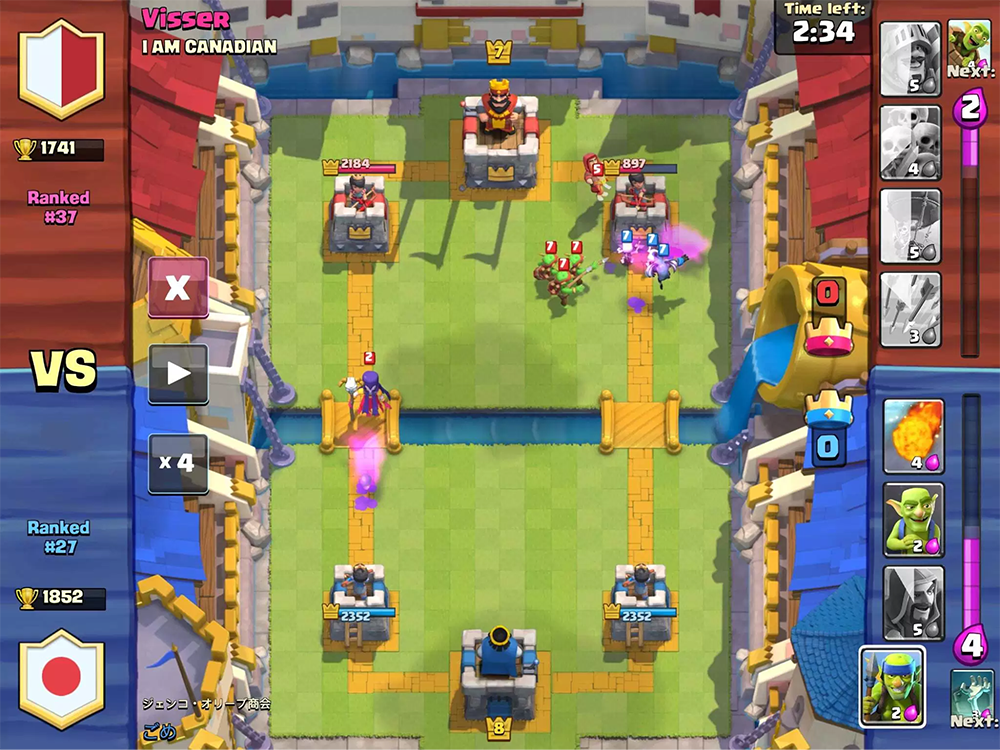
O objetivo do jogo é destruir os edifícios inimigos. Para uma vitória completa, você deve destruir a fortaleza ou, após dois minutos do jogo, destruir mais prédios (as regras dependem dos modos de jogo, mas, em geral, são assim).
Durante o jogo, você precisa levar em consideração o movimento das unidades, o número possível de mana e as cartas inimigas atuais. Você também precisa considerar como a instalação da unidade afeta o campo de jogo.
Construindo uma solução
O Clash Royale é um jogo para celular, então decidi executá-lo no Android e interagir com ele através do ADB. Isso daria suporte ao trabalho com o simulador ou com um dispositivo real.
Decidi que o bot, como muitas outras IAs de jogos, deveria funcionar no algoritmo Perception-Analysis-Action. Todo o ambiente do jogo é exibido na tela e a interação ocorre clicando na tela. Portanto, o bot deve ser um programa cuja entrada descreve o estado atual do jogo: a localização e as características das unidades e edifícios, as cartas possíveis atuais e a quantidade de mana. Na saída, o bot deve fornecer uma matriz de coordenadas onde a unidade deve ser gravada.
Mas antes de criar o bot em si, era necessário resolver o problema de extrair informações sobre o estado atual do jogo a partir da captura de tela. De um modo geral, o conteúdo adicional do artigo é dedicado a esta tarefa.
Para resolver esse problema, decidi usar o Computer Vision. Talvez essa não seja a melhor solução: um currículo sem muita experiência e recursos tem claramente limitações e não pode reconhecer tudo no nível humano.
Seria mais preciso coletar dados da memória, mas eu não tinha essa experiência. A raiz é necessária e, em geral, essa solução parece mais complicada. Também não está claro se a velocidade em torno do tempo real pode ser alcançada aqui se você procurar objetos com uma JVM de pilha dentro do dispositivo. Além disso, eu queria resolver o problema do CV mais do que isso.
Em teoria, alguém poderia criar um servidor proxy e obter informações de lá. Mas o protocolo de rede do jogo geralmente muda, os proxies na Internet aparecem, mas rapidamente se tornam desatualizados e não são suportados.
Recursos disponíveis do jogo
Para começar, decidi me familiarizar com os materiais disponíveis no jogo. Eu encontrei um
clube de artesãos retirando recursos empacotados de jogos
[1] [2] . Antes de tudo, eu estava interessado em imagens de unidades, mas no pacote de jogos descompactado elas são apresentadas na forma de um mapa de peças (das quais uma unidade consiste).
Também achei scripts colados (embora não perfeitos) de quadros de animação de unidade - eles foram úteis para treinar o modelo de reconhecimento.

Além disso, nos recursos, você pode encontrar csv com vários dados do jogo - a quantidade de HP, danos a unidades de diferentes níveis etc. Isso é útil ao criar lógica de bot. Por exemplo, a partir dos dados, ficou claro que o campo foi dividido em 18 x 29 células, e as unidades só podem ser colocadas nelas. Havia também todas as imagens de mapas de unidades, que serão úteis para nós mais tarde.
Visão computacional para os preguiçosos
Depois de procurar soluções CV disponíveis, ficou claro que, em qualquer caso, elas precisariam ser treinadas em um conjunto de dados rotulado. Tirei screenshots e já estava pronto para marcar um certo número de screenshots com as mãos. Isso provou ser uma tarefa assustadora.
Encontrar programas de reconhecimento disponíveis levou algum tempo. Eu
decidi por
labelImg . Todos os aplicativos de anotação que encontrei eram bastante primitivos: muitos não suportavam atalhos de teclado, a seleção de objetos e seus tipos era muito menos conveniente do que no labelImg.
Durante a marcação, mostrou-se útil ter o código-fonte do aplicativo. Tirei screenshots a cada dois segundos da partida. Existem muitos objetos nas capturas de tela (por exemplo, um exército de esqueletos), e eu fiz uma modificação no labelImg - por padrão, ao marcar a próxima imagem, as etiquetas da anterior foram tiradas. Muitas vezes, eles simplesmente precisavam ser movidos para uma nova posição das unidades, remover as unidades mortas e adicionar algumas aparecidas, e não marcar do zero.

O processo acabou consumindo muitos recursos - em dois dias no modo silencioso, publiquei cerca de 200 capturas de tela. A amostra parece muito pequena, mas decidi começar a experimentar. Você sempre pode adicionar mais exemplos e melhorar a qualidade do modelo.
No momento da marcação, eu não sabia qual ferramenta de treinamento eu usaria, então decidi salvar os resultados da marcação no formato VOC - um dos mais conservadores e aparentemente universais.
A questão pode surgir: por que não procurar imagens pixel-a-pixel de unidades por completa coincidência? O problema é que, para isso, seria necessário procurar um grande número de quadros diferentes de animação de unidades diferentes. Dificilmente funcionaria. Eu queria criar uma solução universal que suporte permissões diferentes. Além disso, as unidades podem ter uma cor diferente, dependendo do efeito aplicado a elas - congelamento, aceleração.
Por que eu escolhi YOLO
Comecei a explorar possíveis soluções de reconhecimento de imagem. Eu olhei para a aplicação de vários algoritmos: OpenCV, TensorFlow, Torch. Eu queria fazer o reconhecimento o mais rápido possível, sacrificando a precisão e obtendo o POC o mais rápido possível.
Depois de ler os
artigos , percebi que minha tarefa não se encaixa nos classificadores HOG / LBP / SVM / HAAR / .... Embora sejam rápidos, teriam que ser aplicados várias vezes - de acordo com o classificador de cada unidade - e depois um por um para aplicá-los à imagem para pesquisa. Além disso, seu princípio de operação em teoria daria resultados ruins: as unidades podem ter uma forma diferente, por exemplo, ao mover para a esquerda e para cima.
Teoricamente, usando uma rede neural, você pode aplicá-la uma vez a uma imagem e obter todas as unidades de tipos diferentes com suas posições, então comecei a procurar redes neurais. O TensorFlow encontrou suporte para Redes Neurais Convolucionais (CNN). Descobriu-se que não é necessário treinar redes neurais do zero - você pode
treinar novamente a poderosa rede existente .
Então eu encontrei um algoritmo YOLO mais prático que promete menos complexidade e, portanto, tinha que fornecer um algoritmo de busca em alta velocidade sem sacrificar muita precisão (e, em alguns casos, superando outros modelos).
O site da YOLO promete uma enorme diferença de velocidade usando o modelo minúsculo e uma rede menor e otimizada. O YOLO também permite que você treine novamente a rede neural pronta para sua tarefa, e o
darknet - uma estrutura de código
aberto para usar vários neurônios cujos criadores desenvolveram o YOLO - é um aplicativo C nativo simples, e todo o trabalho com ele ocorre através de suas chamadas de parâmetros.
O TensorFlow, escrito em Python, é de fato uma biblioteca Python e é usado usando scripts auto-escritos que você precisa descobrir ou refinar para atender às suas necessidades. Provavelmente, para alguns, a flexibilidade do TensorFlow é uma vantagem, mas sem entrar em detalhes, dificilmente é possível pegá-lo e usá-lo rapidamente. Portanto, no meu projeto, a escolha recaiu no YOLO.
Construção de modelo
Para trabalhar no treinamento de modelos, instalei o Ubuntu 18.10, entreguei pacotes de montagem, pacote OpenCL da NVIDIA e outras dependências e construí darknet.
O Github possui uma
seção com etapas simples para treinar novamente o modelo YOLO : você precisa fazer o download do modelo e das configurações, alterá-los e iniciar a reciclagem.
Primeiro, eu queria tentar treinar um modelo YOLO simples, depois Tiny e compará-los. Entretanto, para o treinamento de modelos simples, você precisa de 4 GB de memória da placa de vídeo e eu só tinha uma placa gráfica NVIDIA GeForce GTX 1060 de 3 GB comprada para jogos. Portanto, pude treinar imediatamente apenas o modelo Tiny.
A marcação das unidades nas imagens que eu tinha estava no formato VOC e o YOLO trabalhava com seu próprio formato, então usei o utilitário
convert2Yolo para converter arquivos de anotação.
Depois de uma noite de treinamento nas minhas 200 capturas de tela, obtive os primeiros resultados e eles me surpreenderam - o modelo realmente conseguiu reconhecer algo corretamente! Percebi que estava indo na direção certa e decidi dar mais exemplos de ensino.

Eu não queria continuar exibindo capturas de tela e lembrei-me dos quadros das animações de unidade. Marquei todas as imagens pequenas com suas aulas e tentei treinar a rede nesse set. O resultado foi muito ruim. Suponho que o modelo não possa selecionar os padrões corretos em imagens pequenas para uso em imagens grandes.
Depois disso, decidi colocá-los em cenários prontos de arenas de batalha e criar programaticamente um arquivo de marcação VOC. O resultado foi uma captura de tela sintética com layout 100% preciso automático.
Eu escrevi um script em Scala que divide a captura de tela em 16 quadrados 4x4 e coloca as unidades no centro delas, para que elas não se cruzem. O script também me permitiu personalizar a criação de exemplos de treinamento - ao sofrer danos, as unidades são pintadas na cor de sua equipe (vermelho / azul) e, durante a classificação, reconheço unidades de cores diferentes. Além da mancha, unidades de diferentes equipes que receberam danos apresentam pequenas diferenças nas roupas. Além disso, aumentei e diminuí um pouco aleatoriamente as unidades, para que o modelo aprendesse a não depender muito do tamanho da unidade. Como resultado, aprendi como criar dezenas de milhares de exemplos de treinamento que são aproximadamente semelhantes às capturas de tela reais.
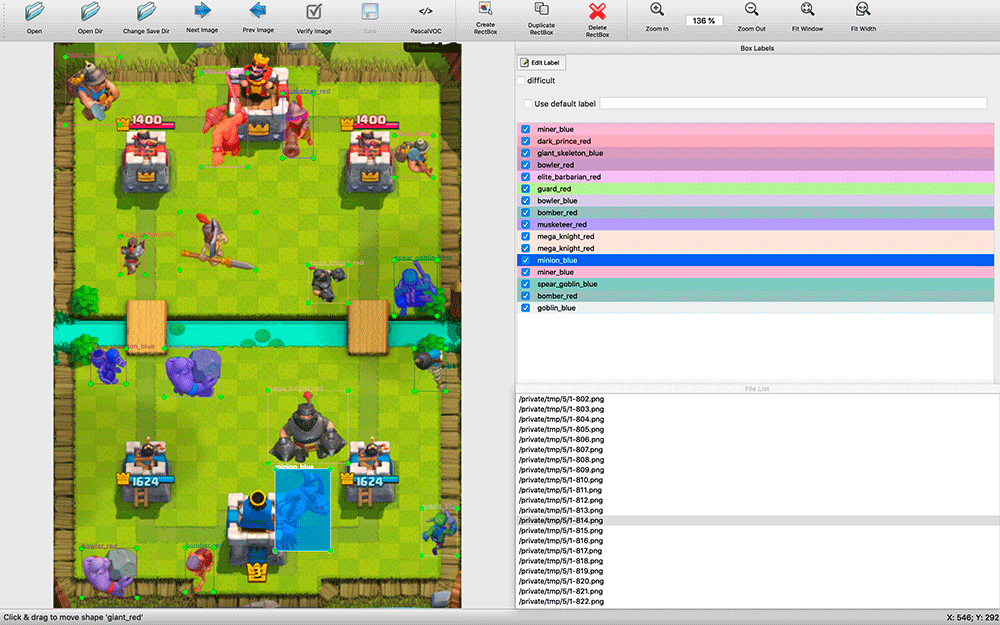
A geração não foi perfeita. Muitas vezes, as unidades eram colocadas no topo de edifícios, embora no jogo estivessem atrás deles; não houve exemplos de partes sobrepostas da unidade, embora essa não seja uma situação rara no jogo. Mas até agora decidi negligenciá-lo.

O modelo obtido após várias noites de treinamento com uma mistura de 200 capturas de tela reais e 5.000 imagens geradas que foram recriadas durante o processo de treinamento uma vez por dia, quando testadas nessas capturas de tela, deu maus resultados. Não é surpreendente, porque as imagens geradas têm muitas diferenças em relação às reais.
Portanto, coloquei o modelo resultante para treinar novamente em uma amostra média, na qual havia apenas 200 das minhas capturas de tela. Depois disso, ela começou a trabalhar muito melhor.
VergonhaPeço desculpas por lidar com medidas não científicas como "muito melhores", mas não sei como validar imagens cruzadas rapidamente, então tentei várias capturas de tela de um conjunto sem treinamento e verifiquei se os resultados me satisfaziam. Esta é a coisa mais importante. Nós somos preguiçosos e estamos fazendo um protótipo, certo?
Os próximos passos para melhorar o modelo foram compreensíveis - marque com as mãos mais capturas de tela reais e treine-as no modelo, pré-treinadas nas capturas de tela geradas.
Vamos ao que interessa
Decidi escrever um bot em Python - ele tem muitas ferramentas disponíveis para o ML. Decidi usar meu modelo com o OpenCV, que do
3.5 aprendeu a usar modelos de redes neurais , e até encontrei um
exemplo simples . Tendo experimentado várias bibliotecas para trabalhar com o ADB, escolhi o
pure-python-adb - tudo o que preciso é simplesmente implementado lá: a função de captura de tela e a operação no dispositivo shell; Eu bato usando o 'toque de entrada'.
Então, tendo recebido uma captura de tela do jogo, reconhecendo as unidades e cutucando-a na tela, continuei trabalhando no reconhecimento do estado do jogo. Além das unidades, eu precisava reconhecer o nível atual de mana e as cartas disponíveis para o jogador.
O nível de mana no jogo é exibido como uma barra de progresso e números. Sem pensar duas vezes, comecei a cortar o número, inverter e reconhecer usando
pytesseract .
Para determinar os cartões disponíveis e sua posição, usei o
detector de ponto -
chave KAZE da OpenCV . Até agora, eu não queria voltar a aprender a rede neural novamente e escolhi um método que fosse mais rápido e fácil, embora, no final, tenha a precisão mínima necessária no caso em que você precisa procurar muitos objetos.
Ao iniciar o bot, contei os pontos-chave de todas as imagens do mapa (existem várias dúzias no total) e, durante o jogo, procurei correspondências de todas as cartas com a área de cartas do jogador para reduzir o número de erros e aumentar a velocidade. Eles foram classificados pela precisão e pela coordenada
x para obter a ordem dos mapas - informações sobre como eles estão localizados na tela.
Tendo brincado um pouco com os parâmetros, na prática eu cometi muitos erros, embora algumas imagens complexas de cartões, que às vezes eram confundidas com outras pelo algoritmo, fossem reconhecidas com grande precisão. Eu tive que adicionar um buffer de três elementos: se três forem reconhecidos em uma linha, obtemos os mesmos valores, então acreditamos condicionalmente que podemos confiar neles.

Depois de receber todas as informações necessárias (unidades e sua posição aproximada, mana e cards disponíveis), você pode tomar algumas decisões.
Para começar, decidi usar algo simples: por exemplo, se houver mana suficiente em uma carta acessível, jogue-a no campo. Mas o bot ainda não sabe "jogar" as cartas - sabe quais as cartas que temos, onde fica o campo, é necessário clicar no cartão desejado e depois na célula desejada no campo.
Conhecendo a resolução da captura de tela, você pode entender as coordenadas do mapa e a célula de campo desejada. Agora, vinculei à resolução exata da tela, mas, se necessário, posso ignorar isso. A função de decisão retornará uma matriz de torneiras que precisam ser feitas em um futuro próximo. Em geral, nosso bot será um loop infinito (simplificado):
: = : ( ) : = () = () = () += (, , , )
Até agora, o bot só pode colocar unidades em um ponto, mas já possui informações suficientes para construir uma estratégia mais complexa.
Primeiros problemas
Na realidade, encontrei um problema inesperado e muito desagradável. Criar uma captura de tela através do ADB leva cerca de 100 ms, o que gera um atraso significativo - eu esperava um atraso máximo, levando em consideração todos os cálculos e a opção de ação, mas não em uma etapa da criação de uma captura de tela. Não foi possível encontrar uma solução simples e rápida. Em teoria, usando o emulador Android, você pode tirar capturas de tela diretamente da janela do aplicativo ou criar um utilitário para transmitir imagens de um telefone com compressão via UDP e conectar o bot a ele, mas também não encontrei soluções rápidas aqui.
Então
Depois de avaliar com seriedade o estado do meu projeto, decidi me concentrar neste modelo por enquanto. Passei várias semanas do meu tempo livre fazendo isso, e o reconhecimento da unidade é apenas parte da jogabilidade.
Decidi desenvolver partes do bot gradualmente - para criar a lógica básica da percepção, depois uma lógica simples do jogo e a interação com o jogo, e então será possível melhorar partes individuais do bot. Quando o nível do modelo de reconhecimento de unidade se torna suficiente, adicionar informações sobre a HP e o nível de unidades pode levar o desenvolvimento do bot do jogo a um estágio totalmente novo. Talvez esse seja o próximo objetivo, mas, no momento, não vale a pena focar nessa tarefa.
Repositório do projeto GithubPassei muito tempo no projeto e, francamente, estou cansado disso, mas não me arrependo nem um pouco - tenho uma nova experiência em ML / CV.
Talvez eu volte mais tarde para ele - ficarei feliz se alguém se juntar a mim. Se você estiver interessado, participe do grupo no
Telegram e também participe do meu
curso Scala .