Este artigo é uma transcrição do relatório em vídeo de Alexei Vakhov de Uchi.ru “Nuvens nas nuvens”
Uchi.ru é uma plataforma on-line para educação escolar, mais de 2 milhões de estudantes, aulas interativas regularmente decidem conosco. Todos os nossos projetos são hospedados inteiramente em nuvens públicas, 100% dos aplicativos funcionam em contêineres, começando pelo menor, para uso interno, e terminando com grandes produções com 1k + solicitações por segundo. Aconteceu que temos 15 clusters de docker isolados (não Kubernetes, sic!) Em cinco provedores de nuvem. Mil e quinhentos aplicativos de usuário, cujo número está em constante crescimento.
Vou falar sobre coisas muito específicas: como mudamos para contêineres, como gerenciamos a infraestrutura, os problemas que encontramos, o que funcionou e o que não funcionou.
Durante o relatório, discutiremos:
- Motivação para seleção de tecnologia e recursos de negócios
- Ferramentas: Ansible, Terraform, Docker, Github Flow, Consul, Nomad, Prometheus, Shaman - uma interface da Web para o Nomad.
- Usando a Federação de Cluster para Gerenciar Infra-Estrutura Distribuída
- Lançamentos de NoOps, ambientes de teste, circuitos de aplicativos (os desenvolvedores fazem suas próprias alterações praticamente por conta própria)
- Histórias divertidas da prática
Quem se importa, por favor, debaixo do gato.
Meu nome é Alexey Vakhov. Eu trabalho como diretor técnico em Uchi.ru. Hospedamos em nuvens públicas. Nós ativamente usamos Terraform, Ansible. Desde então, mudamos completamente para o Docker. Muito satisfeito. Quão felizes, quão felizes estamos - eu direi.

A empresa Uchi.ru está envolvida na produção de produtos para educação escolar. Temos uma plataforma principal na qual as crianças resolvem problemas interativos em vários assuntos na Rússia, Brasil e EUA. Realizamos olimpíadas online, concursos, clubes, acampamentos. Todos os anos essa atividade está crescendo.

Do ponto de vista da engenharia, a pilha da Web clássica (Ruby, Python, NodeJS, Nginx, Redis, ELK, PostgreSQL). A principal característica é que muitas aplicações. Os aplicativos estão hospedados em todo o mundo. Todos os dias há lançamentos em produção.
A segunda característica é que nossos esquemas mudam com muita frequência. Eles pedem para criar um novo aplicativo, interromper o antigo, adicionar cron para trabalhos em segundo plano. A cada 2 semanas, há uma nova Olimpíada - esta é uma nova aplicação. É tudo necessário para acompanhar, monitorar, fazer backup. Portanto, o ambiente é superdinâmico. Dinamismo é a nossa principal dificuldade.
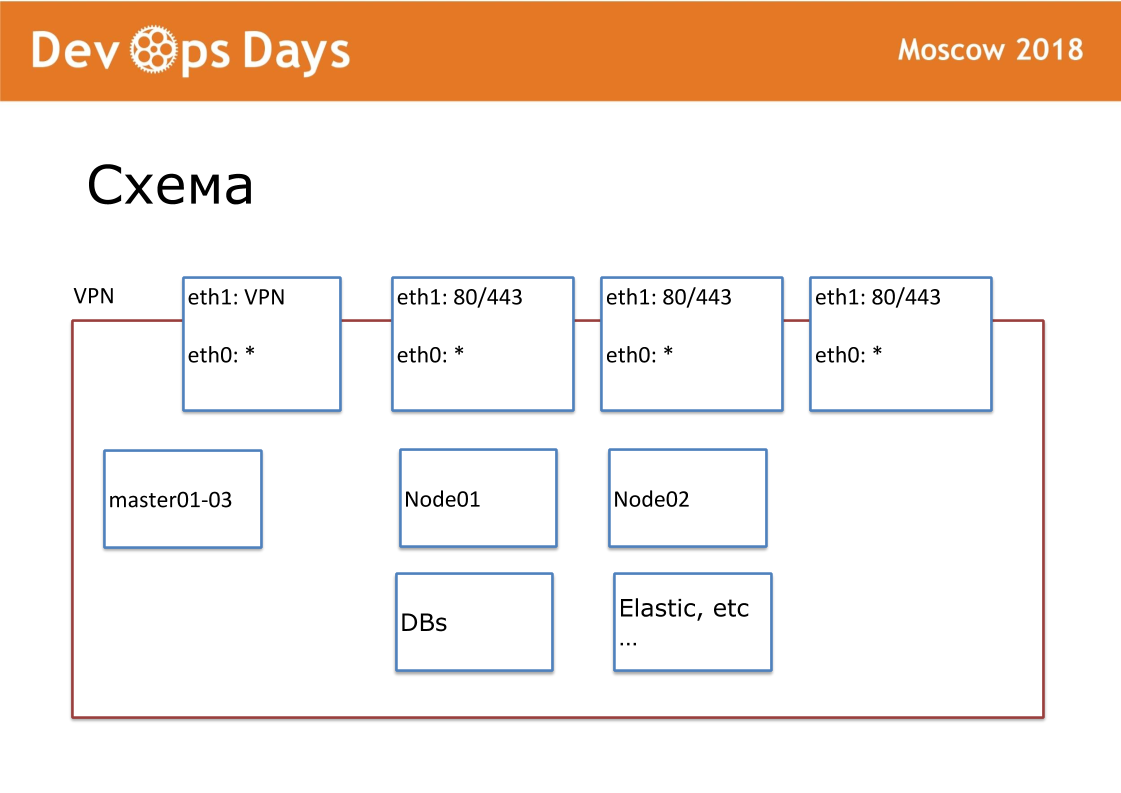
Nossa unidade de trabalho é o site. Em termos de provedores de nuvem, este é o Projeto. Nosso site é uma entidade completamente isolada, com uma API e uma sub-rede privada. Quando entramos no país, procuramos provedores de nuvem locais. Em todo lugar não há Google e Amazon. Às vezes acontece que não há API para o provedor de nuvem. Externamente, publicamos VPN e HTTP, HTTPS para balanceadores. Todos os outros serviços se comunicam dentro da nuvem.

Para cada site, criamos nosso próprio repositório Ansible. O repositório possui hosts.yml, playbook, papéis e 3 pastas secretas, sobre as quais falarei mais adiante. Isto é terraform, provisão, roteamento. Somos fãs da padronização. Nosso repositório sempre deve ser chamado de "nome ansible do site". Nós padronizamos cada nome de arquivo, estrutura interna. Isso é muito importante para maior automação.

Montamos o Terraform há um ano e meio, então o usamos. Terraform sem módulos, sem estrutura de arquivos (estrutura plana é usada). Estrutura do arquivo Terraform: 1 servidor - 1 arquivo, configurações de rede e outras configurações. Usando terraform, descrevemos servidores, unidades, domínios, s3-buckets, redes e assim por diante. Terraform no local está preparando totalmente o ferro.

Terraform cria o servidor, então o conjunto rola esses servidores. Devido ao fato de usarmos a mesma versão do sistema operacional em todos os lugares, escrevemos todas as funções do zero. As funções possíveis geralmente são publicadas na Internet para todos os sistemas operacionais que não funcionam em nenhum lugar. Todos nós assumimos papéis Ansible e deixamos apenas o que precisávamos. Papéis Ansible Padronizados. Temos 6 cartilhas básicas. Quando lançado, o Ansible instala uma lista padrão de software: OpenVPN, PostgreSQL, Nginx, Docker. Kubernetes que não usamos.

Usamos Consul + Nomad. Estes são programas muito simples. Execute 2 programas escritos em Golang em cada servidor. O Consul é responsável pela descoberta de serviços, verificação de integridade e valor-chave para armazenar a configuração. Nomad é responsável pelo agendamento, pela implantação. O Nomad lança contêineres, fornece lançamentos, incluindo atualizações contínuas na verificação de integridade, permite executar contêineres laterais. O cluster é fácil de expandir ou vice-versa para reduzir. Nomad suporta cron distribuído.
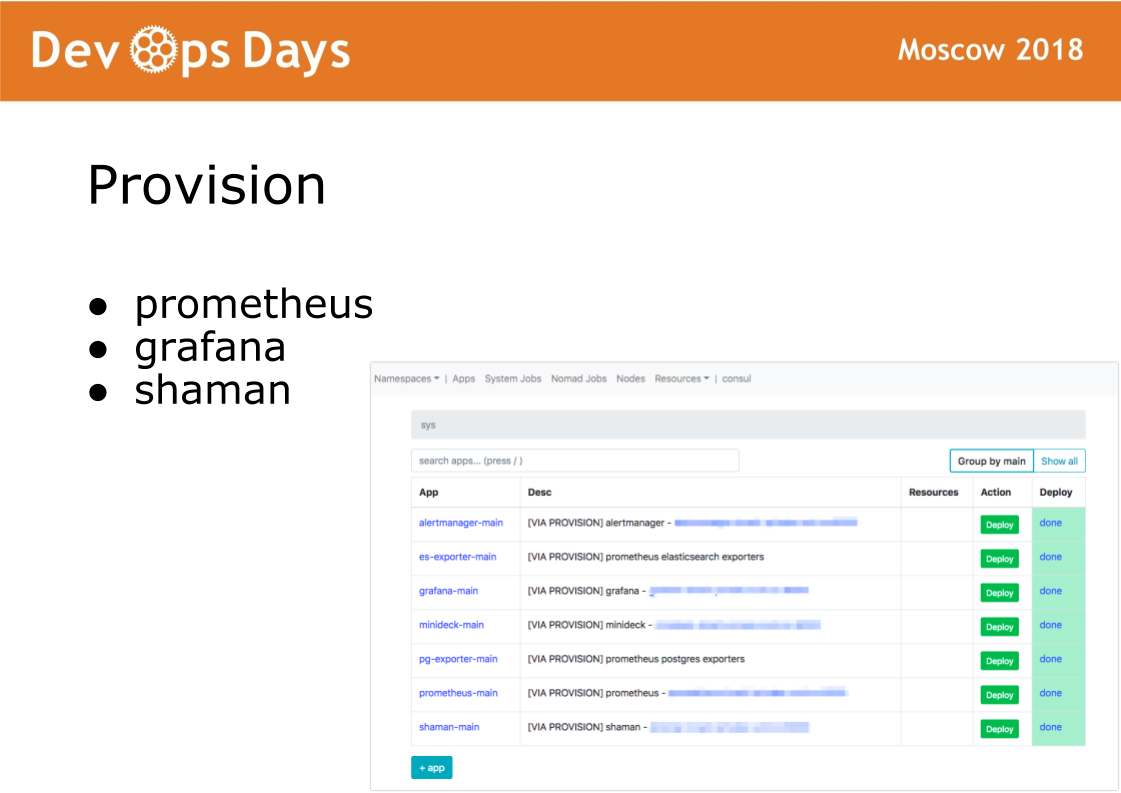
Depois de entrar no site, o Ansible executa o manual localizado no diretório de provisão. O manual deste diretório é responsável pela instalação do software no cluster de docker usado pelos administradores. Instale o software prometheus, grafana e secret shaman.
Shaman é um painel da web para nômades. O Nomad é de nível baixo e eu realmente não quero deixar desenvolvedores. No shaman, vemos uma lista de aplicativos, fornecemos aos desenvolvedores um botão de implantação de aplicativos. Os desenvolvedores podem alterar as configurações: adicionar contêineres, variáveis de ambiente, iniciar serviços.
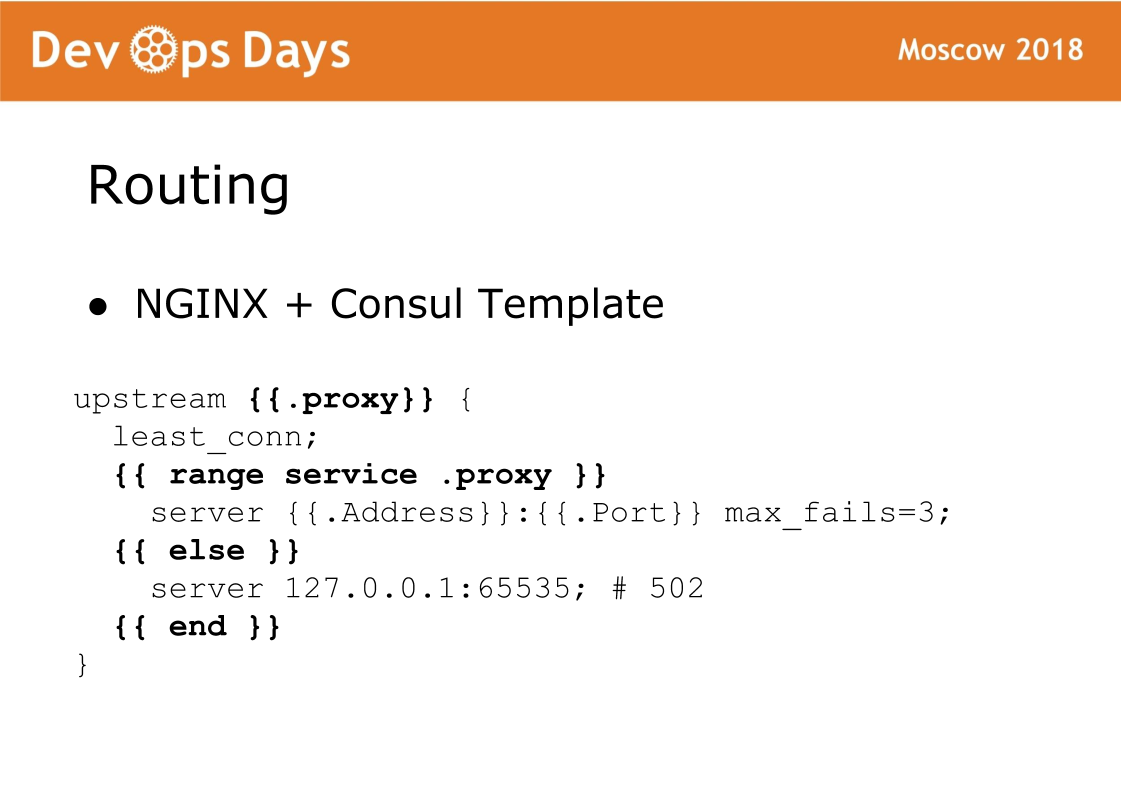
E, finalmente, o componente final do site é roteamento. O roteamento é armazenado no armazenamento K / V do cônsul, ou seja, existe um link entre upstream, serviço, URL, etc. Em cada balanceador, há um modelo Consul que gera uma configuração nginx e a recarrega. Uma coisa muito confiável, nunca tivemos problemas com isso. A característica desse esquema é que o tráfego aceita o nginx padrão e você sempre pode ver qual configuração foi gerada e trabalhar como no nginx padrão.

Assim, cada site consiste em 5 camadas. Com terraform, personalizamos o hardware. Ansible realizamos a configuração básica dos servidores, coloque o docker-cluster. A provisão acumula o software do sistema. O roteamento direciona o tráfego no site. Aplicativos contém aplicativos de usuário e aplicativos de administrador.
Depuramos essas camadas por um longo tempo para que fossem tão idênticas quanto possível. Provisão, roteamento corresponde a 100% entre sites. Portanto, para desenvolvedores, cada site é absolutamente o mesmo.
Se os profissionais de TI mudarem de um projeto para outro, eles cairão em um ambiente completamente típico. Em geral, não foi possível tornar as configurações de firewall e VPN idênticas para diferentes provedores de nuvem. Com uma rede, todos os provedores de nuvem funcionam de maneira diferente. O Terraform está em toda parte, porque contém designs específicos para cada provedor de nuvem.
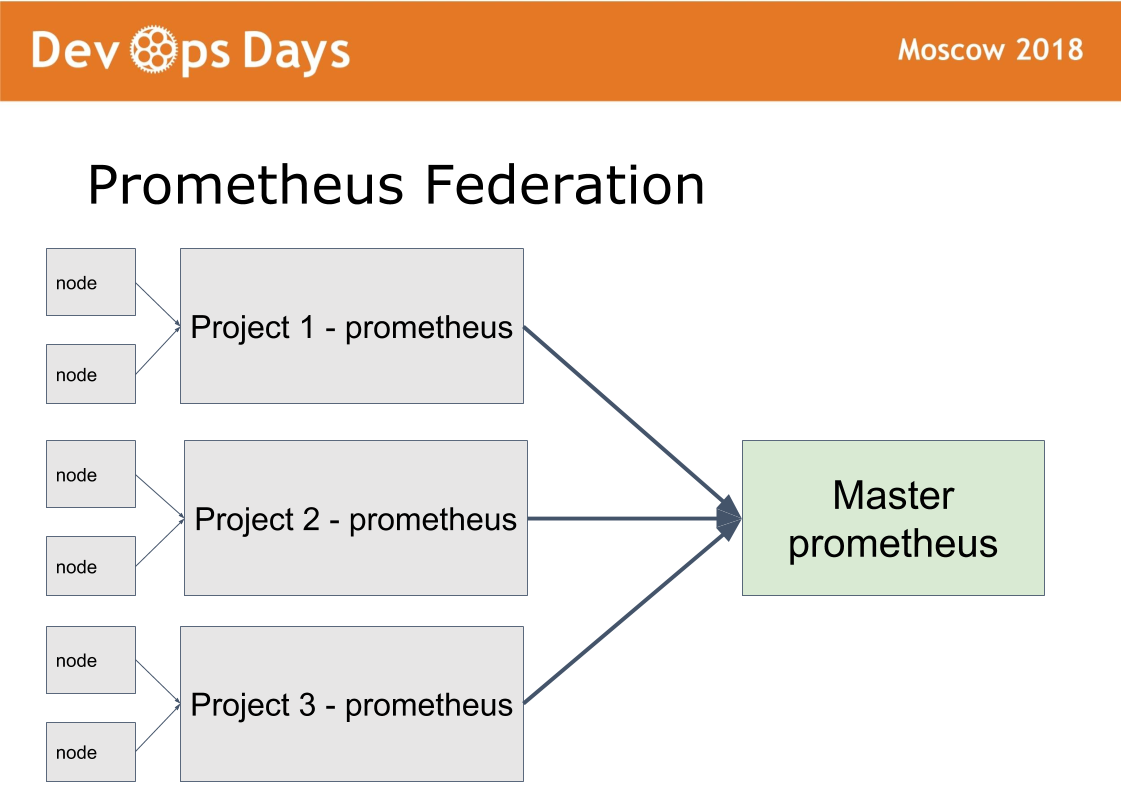
Temos 14 locais de produção. Surge a pergunta: como gerenciá-los? Criamos o 15º site mestre, no qual permitimos apenas administradores. Ela trabalha em um esquema de federação.
A idéia foi tirada de Prometeu. Há um modo no prometheus quando instalamos o prometheus em cada site. Publicamos o Prometheus por meio da autorização de autenticação básica HTTPS. O mestre do Prometheus coleta apenas as métricas necessárias do prometheus remoto. Isso possibilita comparar métricas de aplicativos em diferentes nuvens, encontrar os aplicativos mais baixados ou descarregados. A notificação centralizada (alerta) passa pelo mestre do prometheus para administradores. Os desenvolvedores recebem alertas do prometheus local.

O xamã é configurado da mesma maneira. Por meio do site principal, os administradores podem implantar, configurar em qualquer site por meio de uma única interface. Resolvemos uma classe de problemas suficientemente grande sem sair deste site mestre.

Vou te contar como mudamos para o docker. Este processo é muito lento. Passamos cerca de 10 meses. No verão de 2017, tínhamos 0 contêineres de produção. Em abril de 2018, fizemos a dockerização e lançamos nosso aplicativo mais recente em produção.

Nós somos do mundo do rubi nos trilhos. Costumava haver 99% das aplicações Ruby on Rails. O Rails passa por Capistrano. Tecnicamente, o Capistrano funciona da seguinte maneira: o desenvolvedor inicia o deploy do cap, o capistrano acessa todos os servidores de aplicativos via ssh, pega a versão mais recente do código, coleta ativos, migrações de bancos de dados. Capistrano faz um link simbólico para a nova versão do código e envia um sinal USR2 para o aplicativo da web. Nesse sinal, o servidor da web pega um novo código.
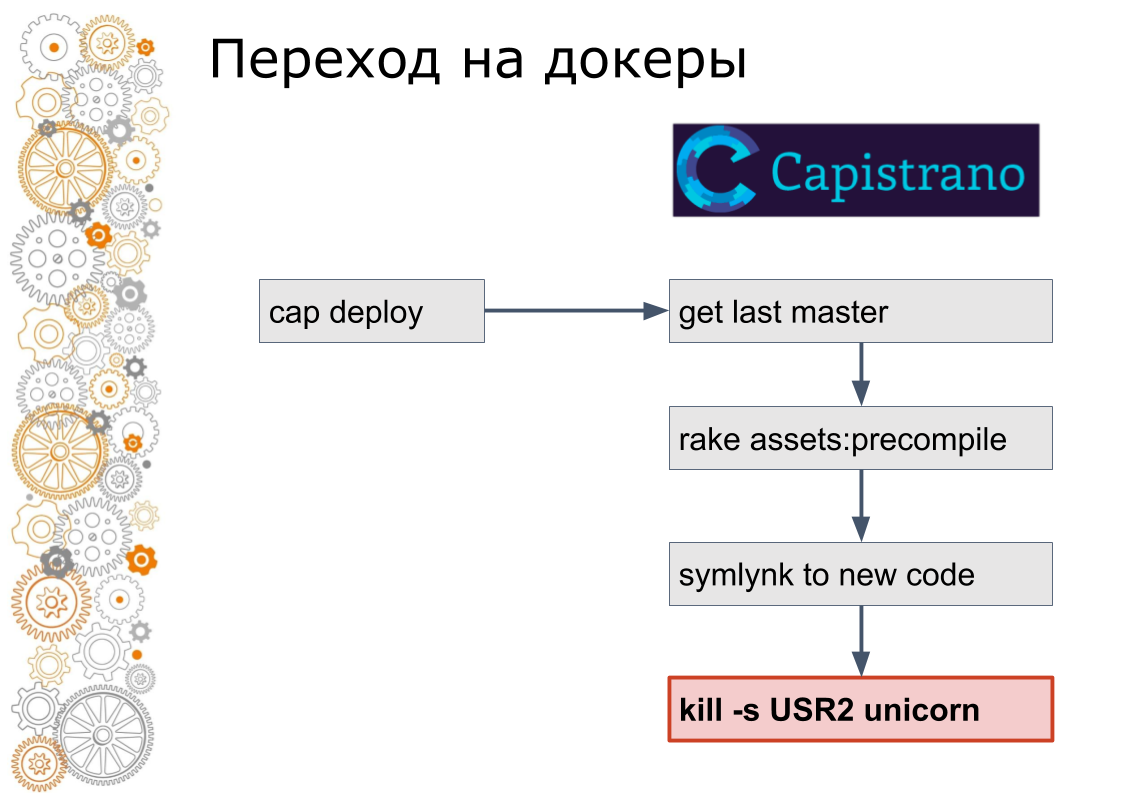
O último passo na janela de encaixe não é feito assim. Na janela de encaixe, é necessário parar o contêiner antigo e elevar o novo contêiner. Isso levanta a questão: como mudar o tráfego? No mundo da nuvem, a descoberta de serviços é responsável por isso.

Portanto, adicionamos o consul em cada site. O Consul foi adicionado porque eles usaram o Terraform. Envolvemos todas as configurações do nginx em um modelo de consul. Formalmente, a mesma coisa, mas já estávamos prontos para gerenciar dinamicamente o tráfego dentro dos sites.

Em seguida, escrevemos um script ruby que coletava uma imagem em um dos servidores, a enviava para o registro, passava o ssh para cada servidor, pegava novos e interrompia os contêineres antigos, registrando-os no consul. Os desenvolvedores também continuaram executando a implementação de limite, mas os serviços já estavam em execução no docker.
Lembro-me de que havia duas versões do script, a segunda era bastante avançada, houve uma atualização contínua, quando um pequeno número de contêineres parou, novos surgiram, o cônsul Helfcheki esperou e seguiu em frente.

Então eles perceberam que este é um método sem saída. O script aumentou para 600 linhas. O próximo passo na programação manual substituímos o Nomad. Escondendo os detalhes do trabalho do desenvolvedor. Ou seja, eles ainda chamavam cap deploy, mas por dentro já havia uma tecnologia completamente diferente.
E, no final, movemos a implantação para a interface do usuário e tiramos o acesso ao servidor, deixando o botão verde de implantação e a interface de controle.
Em princípio, essa transição acabou sendo obviamente longa, mas evitamos o problema que encontrei algumas vezes.
Existe algum tipo de pilha, sistema ou algo parecido. Khachennaya já apenas em retalhos. O desenvolvimento de uma nova versão começa. Após alguns meses ou alguns anos, dependendo do tamanho da empresa, na nova versão menos da metade da funcionalidade necessária é implementada, e a versão antiga ainda escapou. E esse novo também se tornou muito legado. E é hora de começar uma nova terceira versão do zero. Em geral, este é um processo sem fim.
Portanto, sempre movemos a pilha inteira como um todo. Em pequenos passos, tortos, com muletas, mas inteiramente. Não podemos atualizar, por exemplo, o mecanismo do docker em um site. É necessário atualizar em qualquer lugar, se houver um desejo.

Implementações. Todas as instruções da janela de encaixe lançam 10 contêineres nginx ou 10 contêineres redis na doca. Este é um mau exemplo, porque as imagens já estão montadas, as imagens são claras. Empacotamos nossos aplicativos de trilhos na janela de encaixe. O tamanho das imagens da janela de encaixe era de 2 a 3 gigabytes. Eles aparecerão não tão rápido.
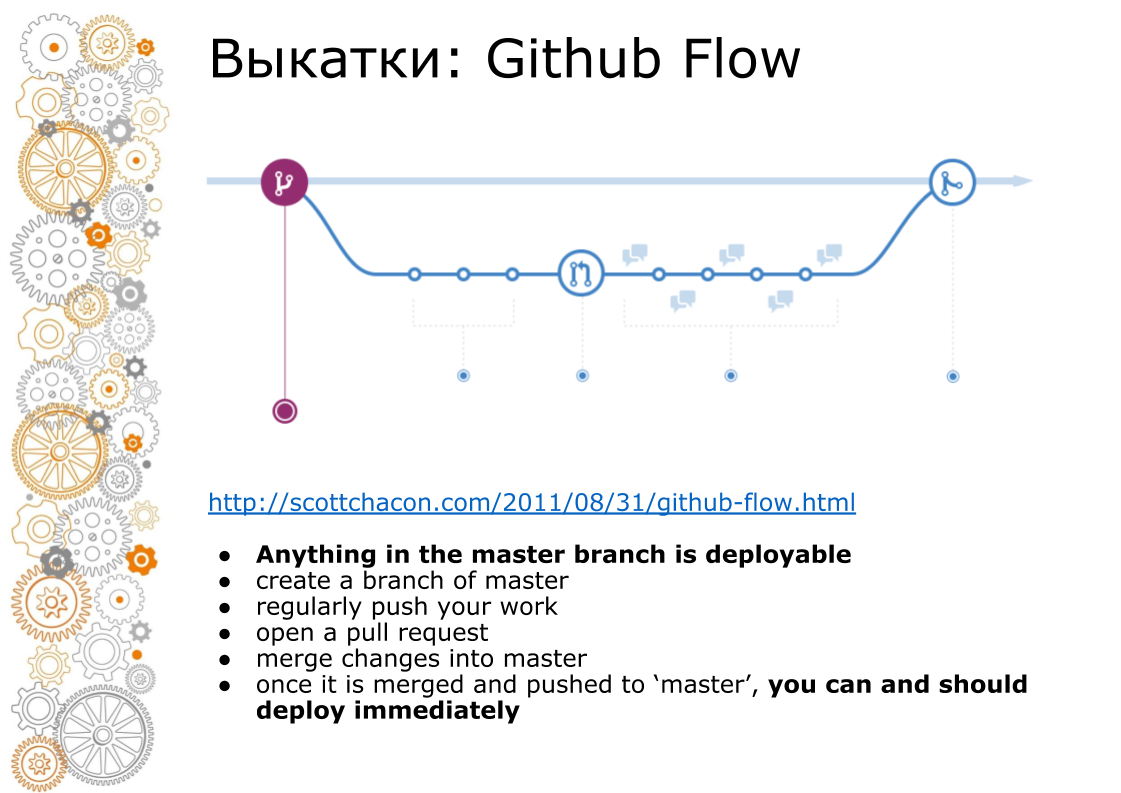
O segundo problema veio da web hipster. Uma web moderna é sempre o Github Flow. Em 2011, houve um post de época que o Github Flow dirige, de modo que toda a web rola. Como é isso? O ramo mestre é sempre produção. Ao adicionar novas funcionalidades, fazemos uma ramificação. Quando fazemos fusão, revisamos o código, executamos testes, aumentamos o ambiente de teste. Negócios que procuram um ambiente de preparação. No momento X, se tudo der certo, mesclaremos o ramo no master e iniciaremos a produção.
No capistrano, isso funcionou bem, porque foi criado para isso. O Docker sempre nos vende um pipeline. Montou o recipiente. O contêiner pode ser transferido para o desenvolvedor, testador, transferido para produção. Mas no momento da mesclagem no mestre, o código já é diferente. Todas as imagens da janela de encaixe que foram coletadas da ramificação do recurso, elas não foram coletadas do mestre.

Como fizemos isso? Coletamos a imagem e a colocamos no registro da janela de encaixe local. Depois disso, fazemos o restante das operações: migração, implantação na produção.

Para montar rapidamente esta imagem, usamos o Docker-in-Docker. Na Internet, todo mundo escreve que isso é um antipadrão, ele trava. Não tínhamos nada disso. Quantos já trabalham com ele nunca tiveram problemas. Encaminhamos o diretório / var / lib / docker para o servidor principal usando o volume Persistent. Todas as imagens intermediárias estão no servidor principal. A montagem de uma nova imagem cabe em alguns minutos.

Para cada aplicativo, criamos um registro da janela de encaixe interna local e nosso volume de compilação. Porque o docker salva todas as camadas no disco e é difícil de limpar. Agora sabemos a utilização do disco de cada registro da janela de encaixe local. Sabemos a quantidade de disco necessária. Você pode receber alertas através do Grafana centralizado e limpo. Enquanto limpamos as mãos deles. Mas vamos automatizar isso.

Outro ponto. Imagem do Docker coletada. Agora, essa imagem precisa ser decomposta em servidores. Ao copiar uma imagem grande do Docker, a rede não suporta. Na nuvem, temos 1 Gbit / s. Há um desligamento global na nuvem. Agora, estamos implantando uma imagem do docker em 4 servidores de produção pesada. No gráfico, você pode ver o disco trabalhado em 1 pacote de servidores. Em seguida, o segundo pacote de servidores é implantado. Abaixo você pode ver a utilização do canal. Cerca de 1 Gbit / s, quase puxamos. Não há mais aceleração lá.

Minha produção favorita é a África do Sul. Há ferro muito caro e lento. Quatro vezes mais caro que na Rússia. Existe uma internet muito ruim. Internet no nível do modem, mas não com bugs. Lá, lançamos aplicativos em 40 minutos, levando em consideração o ajuste de caches, parâmetros de tempo limite.

O último problema que me preocupou antes do docker entrar em contato foi a carga. De fato, a carga é a mesma que sem uma docker com ferro idêntico. A única nuance que encontramos em apenas um ponto. Se você coletar logs do mecanismo do Docker por meio do driver fluentd interno, a uma carga de cerca de 1000 rps, o buffer interno do fluentd começa a ficar desarrumado e as solicitações começam a ficar mais lentas. Tiramos o registro em contêineres laterais. No nómada, isso é chamado de log-shipper. Um contêiner pequeno fica ao lado de um contêiner de aplicativo grande. A única tarefa é buscá-lo e enviá-lo para um repositório centralizado.

Quais foram os problemas / soluções / desafios. Eu tentei analisar qual era a tarefa. As características de nossos problemas são:
- muitas aplicações independentes
- mudanças contínuas na infraestrutura
- Fluxo do Github e imagens grandes de janela de encaixe

Nossas soluções
- Federação de clusters de docker. Do ponto de vista do manuseio, é difícil. Mas o docker é bom em implementar a funcionalidade comercial na produção. Trabalhamos com dados pessoais e temos certificação em todos os países. Em um site isolado, essa certificação é fácil de passar. Durante a certificação, surgem todas as perguntas: onde você está hospedando, como possui um provedor de nuvem, onde armazena dados pessoais, onde faz backup e quem tem acesso aos dados. Quando tudo está isolado, é muito mais fácil descrever o círculo de suspeitos e monitorar tudo isso é muito mais fácil.
- Orquestração. É claro que os kubernetes. Ele está em todo lugar. Mas quero dizer que o Consul + Nomad é uma solução completamente de produção.
- Montagem de imagens. Você pode criar rapidamente imagens no Docker-in-Docker.
- Ao usar o Docker, também é possível manter uma carga de 1000 rps.
Vetor de direção de desenvolvimento
Agora, um dos grandes problemas é a dessincronização de versões de software nos sites. Anteriormente, configuramos o servidor manualmente. Então nos tornamos engenheiros de devops. Agora configure o servidor usando ansible. Agora temos unificação total, padronização. Introduzimos o pensamento comum na cabeça. Não podemos consertar o PostgreSQL com as mãos no servidor. Se você precisar de algum tipo de ajuste fino em apenas 1 servidor, pensamos em como espalhar essa configuração em todos os lugares. Se você não padronizar, haverá um zoológico de configurações.
Estou encantado e muito feliz por termos saído da caixa gratuitamente de uma infraestrutura de trabalho realmente muito boa.

Você pode me adicionar no facebook. Se fizermos algo de bom, vou escrever sobre isso.
Perguntas:
Qual é a vantagem do modelo Consul em relação ao modelo Ansible, por exemplo, para configurar regras de firewall e muito mais?
Resposta: Agora temos tráfego de balanceadores externos indo diretamente para contêineres. Não há ninguém no meio. Uma configuração é formada lá que encaminha os endereços IP e as portas do cluster. Além disso, temos todas as configurações de saldo em K / V no Consul. Temos a ideia de fornecer configurações de roteamento aos desenvolvedores por meio de uma interface segura, para que eles não quebrem nada.
Pergunta: Em relação à homogeneidade de todos os sites. Realmente, não há solicitações de empresas ou de desenvolvedores que você precise implementar algo fora do padrão neste site? Por exemplo, tarantool com cassandra.
Resposta: Isso acontece, mas é muito raro. Assim, elaboramos um artefato separado interno. Existe um problema, mas é raro.
Pergunta: A solução para o problema de entrega é usar um registro do docker privado em cada site e, a partir daí, já é rápido obter imagens do docker.
Resposta: De qualquer forma, a implantação será executada na rede, pois estamos implantando a imagem do docker em 15 servidores simultaneamente. Descansamos contra a rede. Dentro da rede, 1 Gbit / s.
Pergunta: Muitos contêineres de docker são baseados na mesma pilha de tecnologia?
Resposta: Ruby, Python, NodeJS.
Pergunta: Com que frequência você testa ou verifica as imagens do docker em busca de atualizações? Como você resolve problemas de atualização, por exemplo, quando o glibc, openssl precisa ser corrigido em todas as janelas de encaixe?
Resposta: Se você encontrar esse erro, vulnerabilidade, nos sentaremos por uma semana e o repararemos. Se você precisar implantar, podemos implantar a nuvem inteira (todos os aplicativos) do zero até a federação. Podemos clicar em todos os botões verdes para a implantação de aplicativos e sair para beber chá.
Pergunta: Você vai lançar seu xamã no código-fonte aberto?
Resposta: Aqui, Andrei (aponta para a pessoa da platéia) promete que deixemos o xamã no outono. Mas aí você precisa adicionar suporte ao kubernetes. O opensource sempre deve ser melhor.