
Materiais escandalosos, importantes e simplesmente muito legais não são publicados na mídia todos os dias, e nenhum editor se comprometerá a prever o sucesso de um artigo com 100% de precisão. O máximo que a equipe tem é no nível do instinto de dizer material "forte" ou "comum". Só isso. Em seguida, começa a mágica imprevisível da mídia, graças à qual o artigo pode chegar ao topo dos resultados de pesquisa com dezenas de links de outras publicações ou o material afundará no esquecimento. E apenas no caso da publicação de artigos interessantes, os sites de mídia periodicamente sofrem um influxo monstruoso de usuários, que modestamente chamamos de "efeito habitual".
Neste verão, o site de publicação da
República se tornou vítima do profissionalismo de seus próprios autores: artigos sobre reforma previdenciária, educação escolar e nutrição adequada reuniram uma audiência de vários milhões de leitores. A publicação de cada um dos materiais mencionados levou a cargas tão altas que, até a queda do site da República, havia "um pouco de espaço". A administração percebeu que algo precisava ser mudado: era necessário mudar a estrutura do projeto para que ele pudesse reagir vigorosamente às mudanças nas condições de trabalho (principalmente carga externa), mantendo-se totalmente funcional e acessível aos leitores, mesmo em momentos de saltos muito acentuados. E um grande bônus seria a intervenção manual mínima da equipe técnica da República nesses momentos.
Com base nos resultados de uma discussão conjunta com especialistas da República sobre várias opções para implementar a Lista de Desejos dublada, decidimos transferir o site da publicação para o Kubernetes *. Sobre o que tudo isso nos custou, e será a história de hoje.
* Durante a mudança, nenhum especialista técnico republicano ficou feridoComo parecia em termos gerais
Tudo começou, é claro, com negociações sobre como tudo vai acontecer "agora" e "depois". Infelizmente, o paradigma moderno no mercado de TI implica que, assim que uma empresa escolhe algum tipo de solução de infraestrutura, ela a coloca em uma lista de preços de serviços chave na mão. Parece que o trabalho é "chave na mão" - o que poderia ser melhor e mais agradável do que um diretor condicional ou proprietário de uma empresa? Paguei e minha cabeça não dói: planejamento, desenvolvimento, suporte - tudo está lá, do lado do contratante, a empresa só pode ganhar dinheiro para pagar por um serviço tão agradável.
No entanto, a transferência completa da infraestrutura de TI nem sempre é adequada para o cliente a longo prazo. É mais correto, de todos os pontos de vista, trabalhar como uma grande equipe, para que, após a conclusão do projeto, o cliente entenda como conviver mais com a nova infraestrutura, e os colegas da loja não tenham a pergunta "oh, o que aconteceu aqui?" após a assinatura do certificado de conclusão e demonstração dos resultados. Os caras da República eram da mesma opinião. Como resultado, por dois meses, desembarcamos quatro pessoas para o cliente, que não apenas perceberam nossa ideia, mas também especialistas tecnicamente treinados do lado da República para mais trabalho e existência nas realidades de Kubernetes.
E todos os lados se beneficiaram com isso: concluímos rapidamente o trabalho, mantemos nossos especialistas prontos para novas conquistas e obtivemos a Republic como cliente em suporte consultivo com nossos próprios engenheiros. A publicação, por outro lado, recebeu uma nova infraestrutura adaptada aos “habraeffects”, sua própria equipe de especialistas técnicos e a capacidade de procurar ajuda, se necessário.
Estamos preparando uma ponte
"Destrua - não construa." Este ditado se aplica a qualquer coisa. Obviamente, a solução mais simples parece ser o refém mencionado anteriormente, que captura a infraestrutura do cliente e o acorrenta, o cliente a si mesmo, ou faz um overclock da equipe existente e a exigência de contratar um guru em novas tecnologias. Fomos o terceiro, não o caminho mais popular hoje, e começamos com o treinamento de engenheiros da República.
No início, vimos uma solução desse tipo para garantir a operação do site:
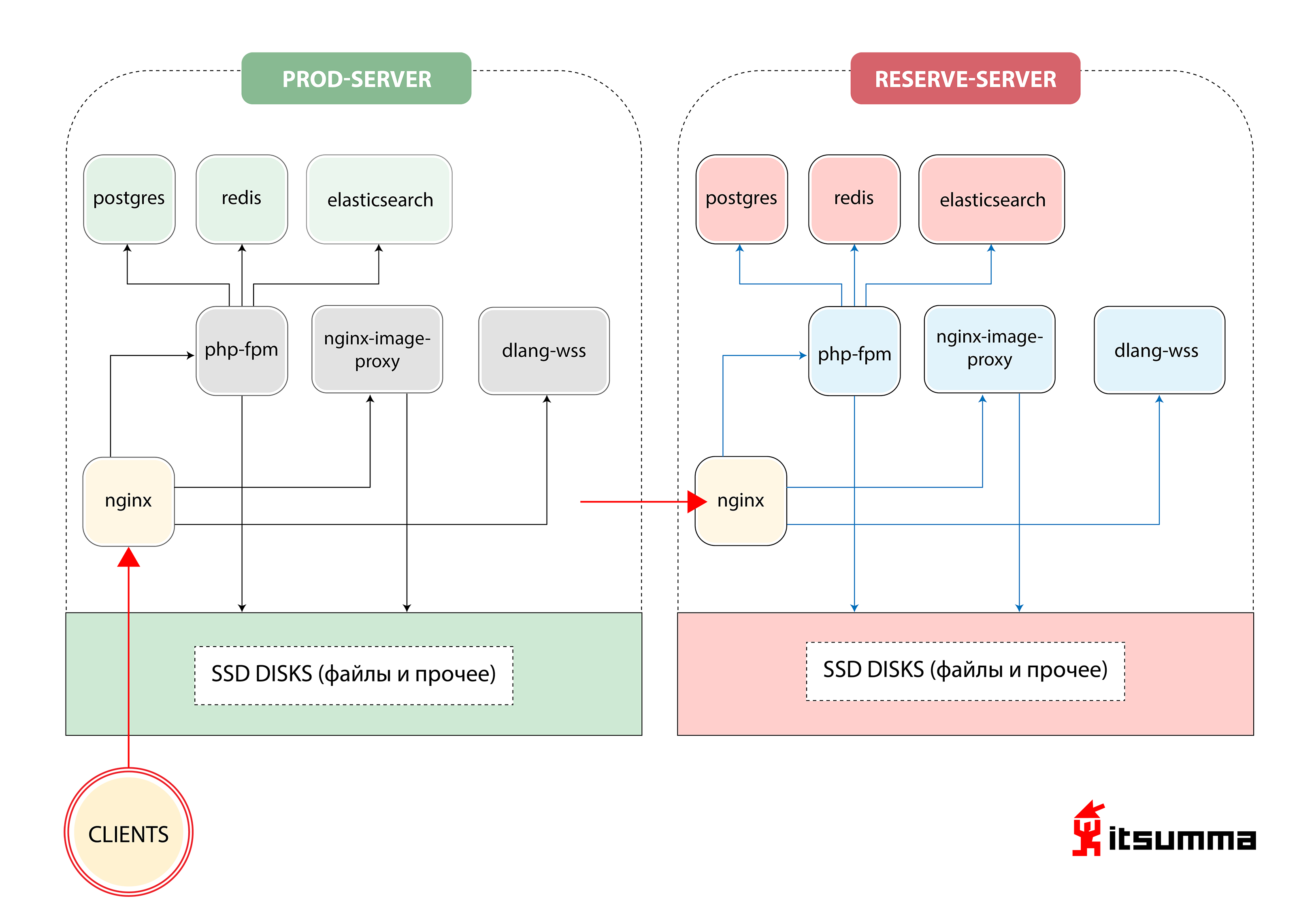
Ou seja, a Republic tinha apenas dois servidores de ferro - o principal e o backup, backup. O mais importante para nós foi conseguir uma mudança de paradigma no pensamento dos especialistas técnicos do cliente, porque antes eles lidavam com um grupo muito simples de NGINX, PHP-fpm e PostgreSQL. Agora eles enfrentavam a arquitetura de contêiner escalável do Kubernetes. Então, primeiro, mudamos o desenvolvimento da República local para o ambiente de composição de encaixe. E este foi apenas o primeiro passo.
Antes do desembarque, os desenvolvedores da Republic mantinham o ambiente de trabalho local em máquinas virtuais configuradas via Vagrant ou trabalhavam diretamente com o servidor de desenvolvimento via sftp. Com base na imagem básica geral de uma máquina virtual, cada desenvolvedor "pré-configurou" sua máquina "para si mesmo", o que deu origem a todo um conjunto de configurações diferentes. Como resultado dessa abordagem, a inclusão de novas pessoas na equipe aumentou exponencialmente o tempo em que entraram no projeto.
Nas novas realidades, oferecemos à equipe uma estrutura mais transparente do ambiente de trabalho. Descreveu declarativamente qual software e quais versões são necessárias para o projeto, a ordem das conexões e interações entre os serviços (aplicativos). Essa descrição foi carregada em um repositório git separado para que ele possa ser gerenciado centralmente de maneira conveniente.
Todos os aplicativos necessários começaram a ser executados em contêineres de docker separados - e este é um site php comum com nginx, muitas estatísticas, serviços para trabalhar com imagens (redimensionamento, otimização etc.) e ... um serviço separado para soquetes da Web, escrito em D Todos os arquivos de configuração (nginx-conf, php-conf ...) também se tornaram parte da base de código do projeto.
Consequentemente, o ambiente local foi completamente "recriado", completamente idêntico à infraestrutura atual do servidor. Assim, o tempo necessário para manter o mesmo ambiente nas máquinas locais dos desenvolvedores e no produto foi reduzido. O que, por sua vez, ajudou bastante a evitar problemas completamente desnecessários causados pelas configurações locais auto-escritas de cada desenvolvedor.
Como resultado, os seguintes serviços foram criados no ambiente de composição de encaixe:
- Web para aplicação php-fpm;
- nginx;
- impproxy e cairosvg (serviços para trabalhar com imagens);
- postgres
- redis;
- busca elástica;
- trompete (o mesmo serviço para os soquetes da web em D).
Do ponto de vista dos desenvolvedores, o trabalho com a base de código permaneceu inalterado - ele foi montado nos serviços necessários de um diretório separado (o repositório base com o código do site) nos serviços necessários: o diretório público no serviço nginx, todo o código do aplicativo php no serviço php-fpm. No diretório separado (que contém todas as configurações do ambiente de composição), os arquivos de configuração correspondentes são montados nos serviços nginx e php-fpm. Diretórios com postgres de dados, elasticsearch e redis também são montados na máquina local do desenvolvedor, de modo que, se todos os contêineres precisarem ser reconstruídos / excluídos, os dados nesses serviços não serão perdidos.
Para trabalhar com os logs de aplicativos - também no ambiente de docker-compose - os serviços da pilha ELK foram aumentados. Anteriormente, parte dos logs do aplicativo era gravada no padrão / var / log / ..., os logs e execuções do aplicativo php eram escritos no Sentry, e essa opção de armazenamento de logs "descentralizado" era extremamente inconveniente para trabalhar. Agora, aplicativos e serviços foram configurados e refinados para interagir com a pilha ELK. O uso de logs ficou muito mais fácil; os desenvolvedores agora têm uma interface conveniente para pesquisar e filtrar logs. No futuro (já no cubo) - você pode assistir os logs de uma versão específica do aplicativo (por exemplo, um kronzhoba lançado anteontem).
Além disso, a equipe da República iniciou um curto período de adaptação. A equipe precisava entender e aprender a trabalhar no novo paradigma de desenvolvimento, no qual o seguinte deve ser considerado:
- Os aplicativos ficam sem estado e podem perder dados a qualquer momento; portanto, o trabalho com bancos de dados, sessões e arquivos estáticos deve ser criado de maneira diferente. As sessões PHP devem ser armazenadas centralmente e compartilhadas entre todas as instâncias de aplicativos. Pode continuar a ser arquivos, mas o redis é usado com mais frequência para esses fins, devido à sua maior facilidade de gerenciamento. Os contêineres para bancos de dados devem "montar" um datadir ou o banco de dados deve ser executado fora da infraestrutura do contêiner.
- Um armazenamento de arquivos de cerca de 50 a 60 GB de imagens não deve estar "dentro do aplicativo da web". Para tais fins, é necessário usar algum armazenamento externo, sistemas cdn etc.
- Todos os aplicativos (bancos de dados, servidores de aplicativos ...) agora são "serviços" separados, e a interação entre eles deve ser configurada em relação ao novo espaço para nome.
Depois que a equipe de desenvolvimento da República se acostumou às inovações, começamos a transferir a infraestrutura de vendas da publicação para o Kubernetes.
E aqui está o Kubernetes
Com base no ambiente docker-compondo criado para o desenvolvimento local, começamos a traduzir o projeto em um "cubo". Todos os serviços em que o projeto é construído localmente, "empacotamos em contêineres": organizamos um procedimento linear e compreensível para a criação de aplicativos, armazenamento de configurações, compilação de estática. Do ponto de vista do desenvolvimento, eles removeram os parâmetros de configuração necessários em variáveis de ambiente, começaram a armazenar sessões não em arquivos, mas em rabanetes. Criamos o ambiente de teste, onde implantamos uma versão viável do site.
Como esse é um projeto monolítico anterior, é óbvio que havia um relacionamento difícil entre as versões front-end e back-end, respectivamente, e esses dois componentes foram implantados ao mesmo tempo. Portanto, decidimos criar os pods do aplicativo Web de forma que dois contêineres girassem em um pod: php-fpm e nginx.
Também construímos o dimensionamento automático para que os aplicativos da Web dimensionados para um máximo de 12 no pico do tráfego, definam certos testes de disponibilidade / disponibilidade, porque o aplicativo leva pelo menos 2 minutos para ser executado (já que você precisa aquecer o cache, gerar configurações ...)
Imediatamente, é claro, havia todos os tipos de cardumes e nuances. Por exemplo: a estatística estática compilada era necessária tanto para o servidor da web que a distribuiu quanto para o servidor de aplicativos no fpm, que em algum lugar em tempo real gerava algum tipo de imagem, em algum lugar o svg fornecia diretamente ao código. Percebemos que, para não se levantar duas vezes, precisamos criar um contêiner de construção intermediário e contornar a montagem final por meio de vários estágios. Para fazer isso, criamos vários contêineres intermediários, em cada um dos quais as dependências são extraídas separadamente, as estatísticas (css e js) são coletadas separadamente e, em seguida, em dois contêineres - no nginx e no fpm - elas são copiadas do contêiner de construção intermediário.
Começamos
Para trabalhar com arquivos na primeira iteração, criamos um diretório comum sincronizado com todas as máquinas em funcionamento. Com a palavra "sincronizado", quero dizer aqui exatamente o que você pode pensar com horror em primeiro lugar - sincronizar em círculo. Obviamente, uma má decisão. Como resultado, obtivemos todo o espaço em disco no GlusterFS, configuramos o trabalho com imagens para que elas estivessem sempre acessíveis em qualquer máquina e nada diminuísse a velocidade. Para a interação de nossos aplicativos com sistemas de armazenamento (postgres, elasticsearch, redis), os serviços externalName foram criados no k8s, de modo que, por exemplo, no caso de uma mudança urgente para o banco de dados de backup, atualize os parâmetros de conexão em um único local.
Todo o trabalho com crones foi levado para as novas entidades do k8s - cronjob, que podem ser executadas de acordo com uma programação específica.
Como resultado, obtivemos esta arquitetura:
 Clicável
ClicávelOh difícil
Este foi o lançamento da primeira versão, pois, paralelamente à completa reestruturação da infraestrutura, o site ainda estava passando por uma reformulação. Parte do site foi construída com alguns parâmetros - para estática e tudo mais, e parte - com outros. Lá era necessário ... para dizer o mínimo ... perverter com todos esses contêineres de vários estágios, copiar dados deles em uma ordem diferente, etc.
Também tivemos que dançar com pandeiros em todo o sistema CI \ CD para ensinar tudo isso a implantar e controlar de diferentes repositórios e de diferentes ambientes. Afinal, é necessário controle constante sobre as versões do aplicativo para que você possa entender quando um serviço ou outro serviço foi implantado e com qual versão do aplicativo um ou outro erro foi iniciado. Para fazer isso, configuramos o sistema de registro correto (bem como a própria cultura de registro) e implementamos o ELK. Os colegas aprenderam a definir certos seletores, ver qual cron gera quais erros, como geralmente é executado, porque no "cubo" após a execução do contêiner de cron, você não mais entrará nele.
Mas a coisa mais difícil para nós foi refazer e revisar toda a base de código.
Deixe-me lembrá-lo, Republic é um projeto que agora tem 10 anos. Começou com uma equipe, outra está se desenvolvendo agora e é realmente difícil colocar todos os códigos-fonte para possíveis bugs e erros. É claro que, neste momento, nossa equipe de desembarque de quatro homens conectou os recursos do restante da equipe: clicamos e testamos o site inteiro com testes, mesmo nas seções que vivem pessoas que não visitavam desde 2016.
Não falha em nenhum lugar
Na segunda-feira, de manhã cedo, quando as pessoas foram ao correio em massa com um resumo, todos nós temos uma estaca. O culpado foi encontrado rapidamente: o cronjob começou e começou a enviar cartas freneticamente a todos que queriam receber uma seleção de notícias na semana passada, devorando os recursos de todo o cluster ao longo do caminho. Como não suportamos esse comportamento, colocamos rapidamente limites rígidos em todos os recursos: quanto processador e memória um contêiner pode consumir e assim por diante.
Como lidou a equipe de desenvolvedores da República
Nossas atividades trouxeram muitas mudanças e nós entendemos isso. De fato, não apenas redesenhamos a infraestrutura da publicação, em vez do pacote habitual de "servidor de backup principal", implementamos uma solução de contêiner que conecta recursos adicionais conforme necessário, mas alteramos completamente a abordagem para desenvolvimento adicional.
Depois de algum tempo, os caras começaram a entender que isso não está funcionando diretamente com o código, mas com um aplicativo abstrato. Dado os processos de CI \ CD (criados no Jenkins), eles começaram a escrever testes, obtiveram ambientes completos para desenvolvedores de estágio em desenvolvimento, onde podem testar novas versões de seus aplicativos em tempo real, ver onde tudo cai e aprender a viver. novo mundo ideal.
O que o cliente recebeu
Primeiro de tudo, a Republic finalmente conseguiu um processo de implantação controlado! Costumava ser: na República, uma pessoa responsável foi ao servidor, iniciou tudo manualmente, depois coletou estática, verificou com as mãos que nada havia caído ... Agora, o processo de implantação é construído para que os desenvolvedores se envolvam no desenvolvimento e não percam tempo com mais nada . E a pessoa responsável agora tem uma tarefa - monitorar como foi o lançamento em geral.
Depois que ocorre um envio para a filial principal, automaticamente ou por uma implantação de "botão" (periodicamente, devido a certos requisitos de negócios, a implantação automática é desativada), Jenkins entra em conflito: a montagem do projeto começa. Primeiro, todos os contêineres do docker são montados: dependências (compositor, fio, npm) são instaladas nos contêineres preparatórios, o que permite acelerar o processo de construção se a lista de bibliotecas necessárias não tiver sido alterada durante a implantação; depois, os contêineres para php-fpm, nginx e outros serviços são coletados, nos quais, por analogia com o ambiente de composição de encaixe, apenas as partes necessárias da base de código são copiadas. Depois disso, os testes são iniciados e, no caso de aprovação bem-sucedida, há um envio de imagens para o armazenamento particular e, de fato, implementando implantações no cubador.
Graças à transferência da República para o k8s, obtivemos uma arquitetura usando um cluster de três máquinas reais nas quais até doze cópias do aplicativo da web podem "girar" ao mesmo tempo. Ao mesmo tempo, o próprio sistema, com base nas cargas atuais, decide quantas cópias ele precisa no momento. Tiramos a Republic da loteria “funciona - não funciona” com servidores estáticos e de backup e construímos um sistema flexível para eles, pronto para um aumento semelhante à avalanche na carga no site.
Nesse momento, pode surgir a pergunta: "pessoal, vocês trocaram dois pedaços de ferro pelos mesmos pedaços de ferro, mas com a virtualização, qual é o ganho, vocês estão bem aí?" E, claro, será lógico. Mas apenas em parte. Como resultado, não temos apenas peças de hardware com virtualização. Temos um ambiente de trabalho estável, o mesmo em alimentos e virgem. Um ambiente gerenciado centralmente para todos os participantes do projeto. Temos um mecanismo para montar o projeto inteiro e lançar lançamentos, novamente, o mesmo para todos. Temos um sistema de orquestração de projeto conveniente. Assim que a equipe da Republic percebe que geralmente deixa de ter recursos atuais suficientes e os riscos de cargas ultra-altas (ou quando isso já aconteceu e tudo se acalmou), eles apenas pegam outro servidor, em 10 minutos implementam a função de um nó de cluster e op-op tudo é lindo e bom de novo. A estrutura anterior do projeto não sugeria tal abordagem; não havia soluções lentas nem rápidas para esses problemas.
Em segundo lugar, uma implantação perfeita apareceu: o visitante acessará a versão antiga do aplicativo ou uma nova. E não como antes, quando o conteúdo poderia ser novo, mas os estilos são antigos.
Como resultado, os negócios estão satisfeitos: todo tipo de coisa nova agora pode ser feita mais rapidamente e com mais frequência.
No total, de "mas vamos tentar" a "pronto", o trabalho no projeto levou 2 meses. A equipe de nossa parte é um desembarque heróico de quatro pessoas + suporte para a "base" durante a verificação de código e testes.
O que os usuários obtiveram
E os visitantes, em princípio, não viram as mudanças. O processo de implantação da estratégia do RollingUpdate é construído "perfeitamente". A implantação de uma nova versão do site não prejudica os usuários, a nova versão do site, até que os testes sejam aprovados e os testes de disponibilidade / disponibilidade, não estarão disponíveis. Eles apenas veem que o site está funcionando e não vai cair depois de publicar artigos legais. Qual, em geral, é o que qualquer projeto precisa.