Somos Big Data no MTS e este é o nosso primeiro post. Hoje, falaremos sobre quais tecnologias nos permitem armazenar e processar grandes dados, para que sempre haja recursos suficientes para análises, e o custo da compra de ferro não ultrapasse as alturas.
Eles pensaram em criar o centro de Big Data no MTS em 2014: era necessário escalar o armazenamento analítico clássico e os relatórios de BI sobre ele. Naquela época, o mecanismo de processamento de dados e BI era SAS - isso acontecia historicamente. E, embora as necessidades comerciais de armazenamento estivessem fechadas, com o tempo, a funcionalidade do BI e da análise ad-hoc sobre o armazenamento analítico cresceu tanto que foi necessário resolver o problema do aumento da produtividade, pois, ao longo dos anos, o número de usuários aumentou dez vezes e continuou a crescer.
Como resultado do concurso, o sistema Teradata MPP apareceu no MTS, cobrindo as necessidades das telecomunicações naquele momento. Este foi o ímpeto para tentar algo mais popular e de código aberto.
 Na foto - a equipe do Big Data MTS no novo escritório da Descartes em Moscou
Na foto - a equipe do Big Data MTS no novo escritório da Descartes em Moscou O primeiro cluster era de 7 nós. Isso foi suficiente para testar várias hipóteses de negócios e preencher os primeiros inchaços. Os esforços não foram em vão: o Big Data existe no MTS há três anos e agora a análise de dados está envolvida em quase todas as áreas funcionais. A equipe cresceu de trezentos para duzentos.
Queríamos ter processos de desenvolvimento fáceis, testar rapidamente hipóteses. Para fazer isso, são necessárias três coisas: uma equipe com pensamento de inicialização, processos de desenvolvimento leves e infraestrutura desenvolvida. Existem muitos lugares onde você pode ler e ouvir sobre o primeiro e o segundo, mas vale a pena falar sobre a infraestrutura desenvolvida separadamente, porque o legado e as fontes de dados que estão nas telecomunicações são importantes aqui. Uma infraestrutura de dados desenvolvida não está apenas construindo um data lake, uma camada de dados detalhada e uma camada de loja. Também inclui ferramentas e interfaces de acesso a dados, isolamento de recursos de computação para produtos e comandos, mecanismos para entrega de dados aos consumidores - tanto em tempo real quanto em lote. E muito, muito mais.
Todo esse trabalho se destacou em uma área separada, que se dedica ao desenvolvimento de utilitários e ferramentas de dados. Essa área é chamada de plataforma de TI Big Data.
De onde vem o Big Data no MTS
O MTS possui muitas fontes de dados. Uma das principais são as estações base; atendemos a base de assinantes de mais de 78 milhões de assinantes na Rússia. Também temos muitos serviços que não estão relacionados à telecomunicação e permitem que você receba dados mais versáteis (comércio eletrônico, integração de sistemas, Internet das coisas, serviços em nuvem etc.) - toda a "não telecomunicação" já traz cerca de 20% de toda a receita).
Resumidamente, nossa arquitetura pode ser representada como um gráfico:
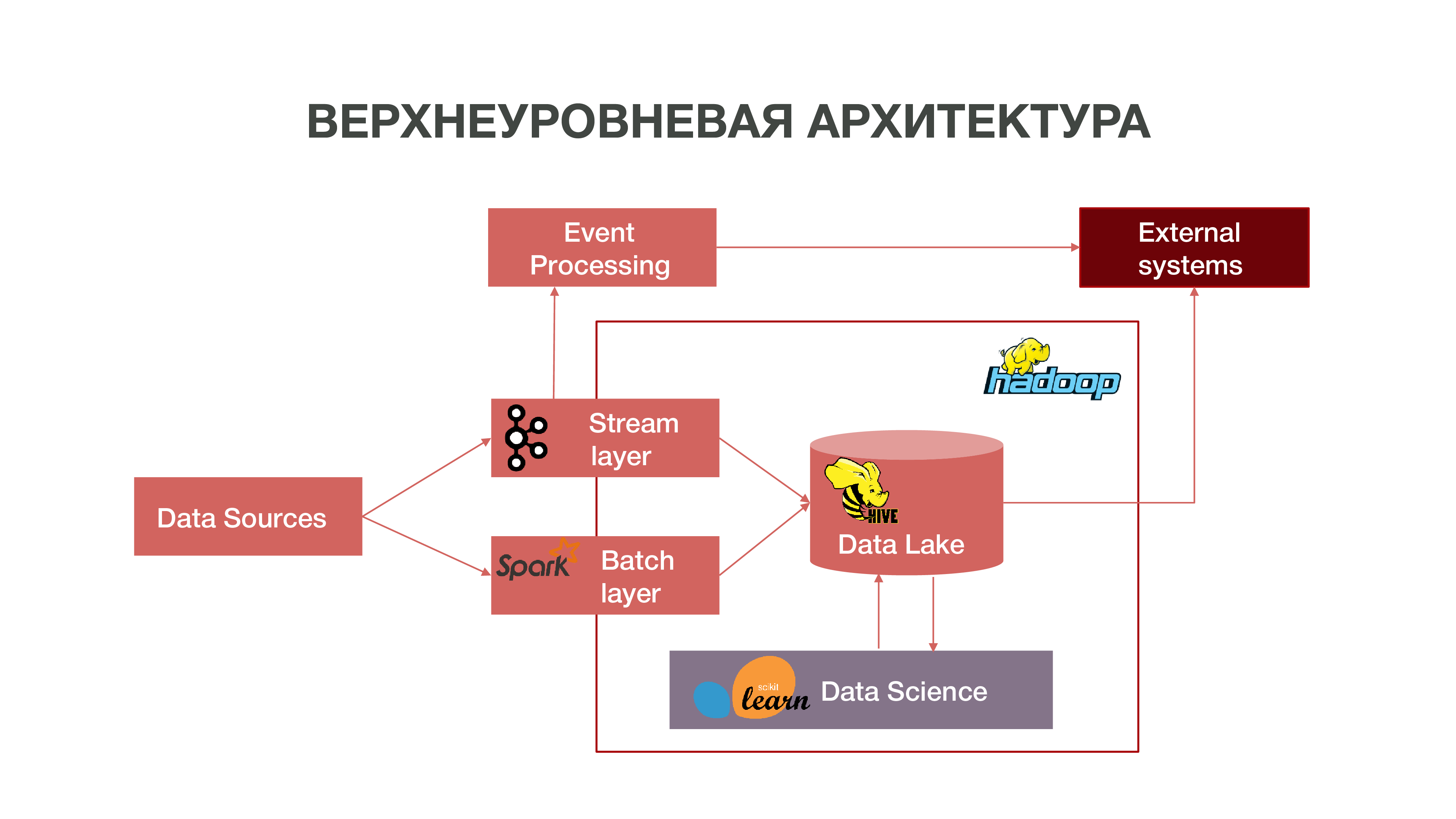
Como você pode ver no gráfico, as fontes de dados podem fornecer informações em tempo real. Usamos a camada de fluxo - podemos processar informações em tempo real, extrair dela alguns eventos que são do nosso interesse e criar análises sobre isso. Para fornecer esse processamento de eventos, desenvolvemos uma implementação bastante padrão (do ponto de vista da arquitetura) usando Apache Kafka, Apache Spark e código na linguagem Scala. As informações obtidas como resultado dessa análise podem ser consumidas tanto no MTS quanto no exterior: as empresas geralmente se interessam pelo fato de certas ações dos assinantes.
Há também um modo de carregar dados em lotes - camada de lote. Geralmente, o download ocorre uma vez por hora em uma programação, usamos o Apache Airflow como agendador e os próprios processos de download em lote são implementados em python. Nesse caso, uma quantidade significativamente maior de dados é carregada no Data Lake, o que é necessário para preencher o Big Data com dados históricos, nos quais nossos modelos de ciência de dados devem ser treinados. Como resultado, um perfil de assinante é formado no contexto histórico com base nos dados de sua atividade de rede. Isso nos permite obter estatísticas preditivas e construir modelos de comportamento humano, até criar um retrato psicológico dele - temos um produto tão separado. Esta informação é muito útil, por exemplo, para empresas de marketing.
Também temos uma grande quantidade de dados que compõem o repositório clássico. Ou seja, agregamos informações sobre vários eventos - usuário e rede. Todos esses dados anônimos também ajudam a prever com mais precisão os interesses e eventos do usuário que são importantes para a empresa - por exemplo, para prever possíveis falhas no equipamento e solucionar problemas a tempo.
Hadoop
Se você olhar para o passado e se lembrar de como o big data apareceu em geral, deve-se notar que basicamente o acúmulo de dados foi realizado para fins de marketing. Não existe uma definição clara do que é big data - são gigabytes, terabytes, petabytes. Impossível desenhar uma linha. Para alguns, o big data é dezenas de gigabytes, para outros, petabytes.
Aconteceu que, com o tempo, muitos dados foram acumulados em todo o mundo. E, para realizar algum tipo de análise mais ou menos significativa desses dados, os repositórios usuais que vêm sendo desenvolvidos desde os anos 70 do século passado não eram mais suficientes. Quando o fluxo de informações começou nos anos 2000, 10 e quando havia muitos dispositivos que tinham acesso à Internet, quando a Internet das coisas apareceu, esses repositórios simplesmente não conseguiam lidar conceitualmente. A base desses repositórios foi a teoria relacional. Ou seja, havia relações de diferentes formas que interagiam entre si. Havia um sistema para descrever como construir e projetar repositórios.
Quando tecnologias antigas falham, novas aparecem. No mundo moderno, o problema da análise de big data é resolvido de duas maneiras:
Criando sua própria estrutura que permite processar grandes quantidades de informações. Geralmente, esse é um aplicativo distribuído de muitas centenas de milhares de servidores - como o Google, Yandex, que criaram seus próprios bancos de dados distribuídos que permitem trabalhar com um volume de informações tão grande.
O desenvolvimento da tecnologia Hadoop é uma estrutura de computação distribuída, um sistema de arquivos distribuídos que pode armazenar e processar uma quantidade muito grande de informações. As ferramentas de ciência de dados são principalmente compatíveis com o Hadoop e essa compatibilidade abre muitas possibilidades para análises avançadas de dados. Muitas empresas, incluindo nós, estão se movendo em direção ao ecossistema Hadoop de código aberto.
O cluster central do Hadoop está localizado em Nizhny Novgorod. Ele acumula informações de quase todas as regiões do país. Em termos de volume, agora podem ser baixados cerca de 8,5 petabytes de dados lá. Também em Moscou, temos clusters de RND separados, onde realizamos experimentos.
Como temos cerca de mil servidores em diferentes regiões, onde realizamos análises e planejamos expansão, surge a questão da escolha certa de equipamentos para sistemas analíticos distribuídos. Você pode comprar equipamentos suficientes para armazenamento de dados, mas que não são adequados para análises - simplesmente porque não haverá recursos suficientes, o número de núcleos da CPU e a RAM livre nos nós. É importante encontrar um equilíbrio para obter boas oportunidades de análise e custos de equipamento não muito altos.
A Intel nos ofereceu diferentes opções sobre como otimizar o trabalho com um sistema distribuído, para que as análises em nosso volume de dados possam ser obtidas por um preço razoável. Intel avança na tecnologia de unidade de estado sólido SSD NAND É centenas de vezes mais rápido que um HDD comum. Do que é bom para nós: o SSD, especialmente com a interface NVMe, fornece acesso rápido aos dados.
Além disso, a Intel lançou os SSDs do servidor Intel Optane SSD com base no novo tipo de memória não volátil Intel 3D XPoint. Eles lidam com cargas mistas intensivas no sistema de armazenamento e têm um recurso mais longo que os SSDs NAND regulares. Por que é bom para nós: o Intel Optane SSD permite que você trabalhe de forma estável em cargas pesadas e com baixa latência. Inicialmente, vimos o NAND SSD como um substituto para os discos rígidos tradicionais, porque temos uma quantidade muito grande de dados movendo-se entre o disco rígido e a RAM - e precisávamos otimizar esses processos.
Primeiro teste
O primeiro teste que realizamos em 2016. Acabamos de pegar e tentar substituir o HDD por um rápido NAND SSD. Para isso, solicitamos amostras do novo drive Intel - na época era o DC P3700. E eles executaram o teste padrão do Hadoop - um ecossistema que permite avaliar como o desempenho muda em diferentes condições. Estes são testes padronizados TeraGen, TeraSort, TeraValidate.

O TeraGen permite "gerar" dados artificiais de um determinado volume. Por exemplo, pegamos 1 GB e 1 TB. Com o TeraSort, classificamos essa quantidade de dados no Hadoop. Esta é uma operação bastante intensiva em recursos. E o último teste - TeraValidate - permite garantir que os dados sejam classificados na ordem correta. Ou seja, passamos por eles uma segunda vez.

Como experiência, pegamos carros apenas com SSDs - ou seja, o Hadoop instalou apenas em SSDs sem usar discos rígidos. Na segunda versão, usamos o SSD para armazenar arquivos temporários, HDD - para armazenar dados básicos. E na terceira versão, os discos rígidos foram usados para ambos.
Os resultados desses experimentos não foram muito agradáveis para nós, porque a diferença nos indicadores de desempenho não excedeu 10-20%. Ou seja, percebemos que o Hadoop não é muito amigável com SSDs em termos de armazenamento, porque inicialmente o sistema foi criado para armazenar grandes dados no HDD, e ninguém o otimizou especialmente para SSDs rápidos e caros. E como o custo do SSD naquela época era bastante alto, decidimos até agora não entrar nessa história e nos dar bem com os discos rígidos.
Segundo teste
Em seguida, a Intel lançou novos SSDs Intel Optane do lado do servidor com base na memória 3D XPoint. Eles foram lançados no final de 2017, mas as amostras estavam disponíveis para nós anteriormente. Os recursos de memória do 3D XPoint possibilitam o uso do Intel Optane SSD como uma extensão da RAM nos servidores. Como já percebemos que não seria fácil resolver o problema de desempenho do IO Hadoop no nível dos dispositivos de armazenamento em bloco, decidimos tentar uma nova opção - expandir a RAM usando a Intel Memory Drive Technology (IMDT). E no início deste ano, fomos um dos primeiros no mundo a testá-lo.
Isso é bom para nós: é mais barato que a RAM, o que permite coletar servidores com terabytes de RAM. E como a RAM é rápida o suficiente, você pode carregar grandes conjuntos de dados e analisá-los. Deixe-me lembrá-lo de que a peculiaridade de nosso processo analítico é que acessamos os dados várias vezes. Para fazer algum tipo de análise, precisamos carregar o máximo de dados possível na memória e "rolar" algum tipo de análise desses dados várias vezes.
O laboratório de inglês da Intel em Swindon nos alocou um cluster de três servidores, que durante os testes comparamos com nosso cluster de teste localizado no MTS.

Como pode ser visto no gráfico, de acordo com os resultados do teste, obtivemos resultados bastante bons.
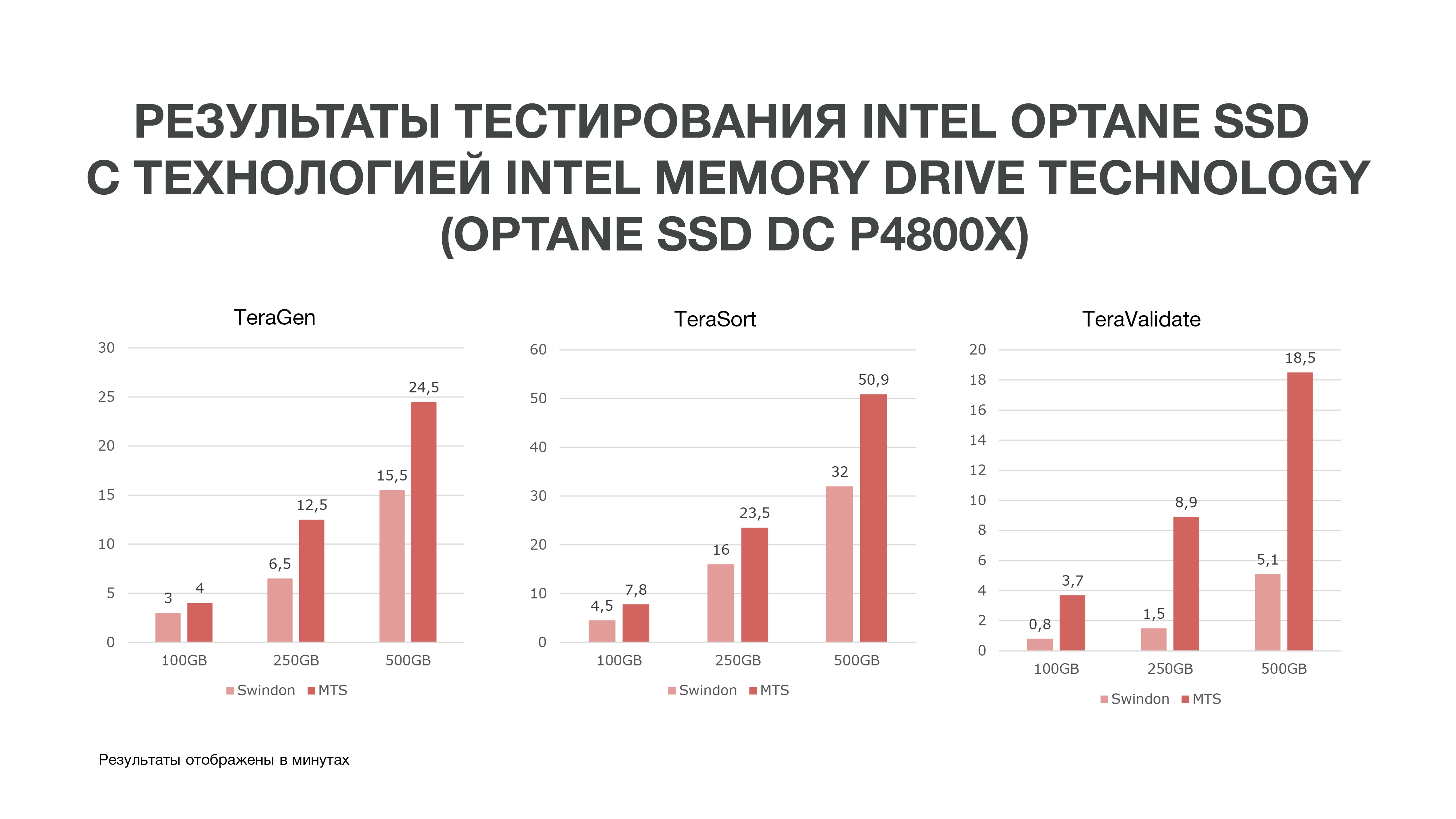
O mesmo TeraGen mostrou um aumento quase duplo na produtividade, o TeraValidate - em 75%. Isso é muito bom para nós, porque, como eu disse, acessamos os dados que temos em nossa memória várias vezes. Consequentemente, se obtivermos tal ganho de desempenho, ele nos ajudará especialmente na análise de dados, especialmente em tempo real.
Realizamos três testes sob diferentes condições. 100 GB, 250 GB e 500 GB. E quanto mais usamos a memória, o Intel Optane SSD com Intel Memory Drive Technology teve melhor desempenho. Ou seja, quanto mais dados analisamos, mais obtemos eficiência. As análises que ocorreram em mais nós podem ocorrer em menos deles. E também temos uma quantidade bastante grande de memória em nossas máquinas, o que é muito bom para as tarefas de ciência de dados. Com base nos resultados do teste, decidimos comprar essas unidades para trabalhar no MTS.
Se você também tiver que escolher e testar o hardware para armazenar e processar uma grande quantidade de dados, será interessante para nós ler quais dificuldades você encontrou e quais resultados teve: escreva nos comentários.
Autores:
Grigory Koval, chefe do Centro de Competência em Arquitetura Aplicada do Departamento de Big Data do MTS grigory_koval
Chefe da tribo de gerenciamento de dados do Departamento de Big Data MTS Dmitry Shostko zloi_diman