Sem eletricidade, não haverá serviços de Internet altamente carregados que tanto gostamos. Curiosamente, os sistemas de controle para instalações de geração de eletricidade, como usinas nucleares, também são distribuídos, também sujeitos a altas cargas e também exigem muitas tecnologias. Além disso, a participação da energia nuclear no mundo aumentará, o gerenciamento dessas instalações e sua segurança é um tópico muito importante.
Portanto, vamos entender o que está lá, como está organizado, quais são as principais dificuldades arquitetônicas e onde na usina nuclear você pode aplicar as modernas tecnologias de ML e VR.
 Uma usina nuclear é:
Uma usina nuclear é:- Uma média de 3-4 unidades de energia com uma capacidade média de 1000 MW por NPP, porque é necessário fazer backup dos sistemas físicos, além de serviços na Internet.
- Cerca de 150 subsistemas especiais que garantem o funcionamento desta instalação. Por exemplo, este é um sistema interno de controle de reatores, um sistema de controle de turbinas, um sistema de controle químico de tratamento de água, etc. Cada um desses subsistemas é integrado a um enorme sistema de nível de bloco superior (SVBU) de um sistema de controle de processo automatizado (ACS TP).
- 200 a 300 mil tags, ou seja, fontes de sinal que mudam em tempo real. Você precisa entender o que é uma mudança, o que não é, se não perdemos algo e, se perdemos, o que fazer a respeito. Esses parâmetros são monitorados por dois operadores, um engenheiro líder de controle de reator (VIUR) e um engenheiro líder de controle de turbina (VIUT).
- Dois edifícios nos quais a maioria dos subsistemas está concentrada: um reator e um compartimento de turbina. Duas pessoas devem tomar uma decisão em tempo real, caso ocorram eventos não padrão ou padrão. Uma responsabilidade tão alta é imposta a apenas duas pessoas, porque se houver mais delas, elas precisarão concordar entre si.
Sobre o palestrante: Vadim Podolny (eletro-elétrico) representa a fábrica de Moscou Fizpribor. Esta não é apenas uma fábrica - é principalmente uma agência de engenharia na qual o hardware e o software são desenvolvidos. O nome é uma homenagem à história da empresa, que existe desde 1942. Isso não é muito elegante, mas muito confiável - era o que eles queriam dizer a eles.
IIoT em usinas nucleares
A empresa Fizpribor produz todo o complexo de equipamentos necessários para a interface de todo um grande número de subsistemas - sensores, controladores de automação a jusante, plataformas para a construção de controladores de automação a jusante, etc.
No design moderno, o controlador é apenas um servidor industrial com um número expandido de portas de entrada / saída para interface de equipamentos com subsistemas especiais. Estes são gabinetes enormes - o mesmo que os gabinetes de servidor, mas eles têm controladores especiais que fornecem computação, coleta, processamento e gerenciamento.
Desenvolvemos software instalado nesses controladores, em equipamentos de gateway. Além disso, como em outros lugares, temos data centers, uma nuvem local na qual ocorrem computação, processamento, tomada de decisão, previsão e tudo o que é necessário para o funcionamento do objeto de controle.
Deve-se notar que em nosso século, o equipamento está diminuindo, tornando-se mais inteligente. Muitos itens de equipamento já possuem microprocessadores - pequenos computadores que fornecem pré-processamento, como é chamado atualmente - cálculos de limites que são executados para não sobrecarregar o sistema em geral. Portanto, podemos dizer que o moderno sistema automatizado de controle de processos das NPPs já é algo como uma Internet industrial das coisas.
A plataforma que controla isso é a plataforma de IoT que muitos já ouviram falar. Há um número considerável deles agora, o nosso está muito rigidamente ligado ao tempo real.
Além disso, mecanismos de
verificação e validação de ponta a ponta são criados para fornecer verificações de compatibilidade e confiabilidade. Também inclui testes de estresse, testes de regressão, testes de unidade - tudo o que você sabe. Somente isso é feito com o hardware que projetamos e desenvolvemos, e o software que funciona com esse hardware. Problemas de segurança cibernética (seguros por design etc.) estão sendo abordados.

A figura mostra os módulos do processador que controlam os controladores. Esta é uma plataforma de 6 unidades com um chassi para a colocação de placas-mãe, nas quais montamos à superfície o equipamento de que precisamos, incluindo processadores. Agora temos uma onda de substituição de importações, estamos
tentando oferecer suporte a processadores domésticos . Alguém diz que, como resultado, a segurança dos sistemas industriais aumentará. Isso é verdade, um pouco mais tarde vou explicar o porquê.
Sistema de segurança
Qualquer sistema de controle de processo em uma usina nuclear é reservado como um sistema de segurança. A unidade de energia nuclear foi projetada para o avião cair sobre ele. O sistema de segurança deve fornecer um resfriamento de emergência do reator para que, devido ao calor residual gerado pelo decaimento beta, ele não derreta, como aconteceu na usina nuclear de Fukushima. Não havia sistema de segurança, os geradores a diesel de reserva foram levados pela onda e o que aconteceu aconteceu. Isso não é possível em nossas usinas nucleares, porque nossos sistemas de segurança estão localizados lá.
A base dos sistemas de segurança é lógica lógica.
De fato, estamos depurando um ou vários algoritmos de controle que podem ser combinados em um algoritmo de grupo funcional, e dessoldamos toda essa história diretamente para a placa sem um microprocessador, ou seja, obtemos uma lógica difícil. Se em algum momento uma peça de equipamento precisar ser substituída, suas configurações ou parâmetros serão alterados e será necessário fazer alterações no algoritmo de operação - sim, você precisará remover a placa na qual o algoritmo está soldado e colocar uma nova. Mas é seguro -
caro, mas seguro .

Abaixo está um exemplo de um sistema triplo de
proteção à sabotagem , no qual um algoritmo para resolver um problema do sistema de segurança na modalidade é de dois em três. Existem três em cada quatro - é como RAID.

Diversidade tecnológica
Em primeiro lugar, é importante usar diferentes processadores. Se criarmos um sistema multiplataforma e selecionarmos um sistema comum a partir de módulos executados em processadores diferentes, se um software mal-intencionado entrar no sistema em algum estágio do ciclo de vida (design, desenvolvimento, manutenção preventiva), ele não será atingiu imediatamente toda a variedade de sabotagem da tecnologia.

Há também uma
variedade quantitativa . A visão dos campos do satélite reflete bem o modelo quando cultivamos uma variedade de culturas, tanto quanto possível em termos de orçamento, espaço, entendimento e operação, ou seja, percebemos redundância, copiando os sistemas o máximo possível.
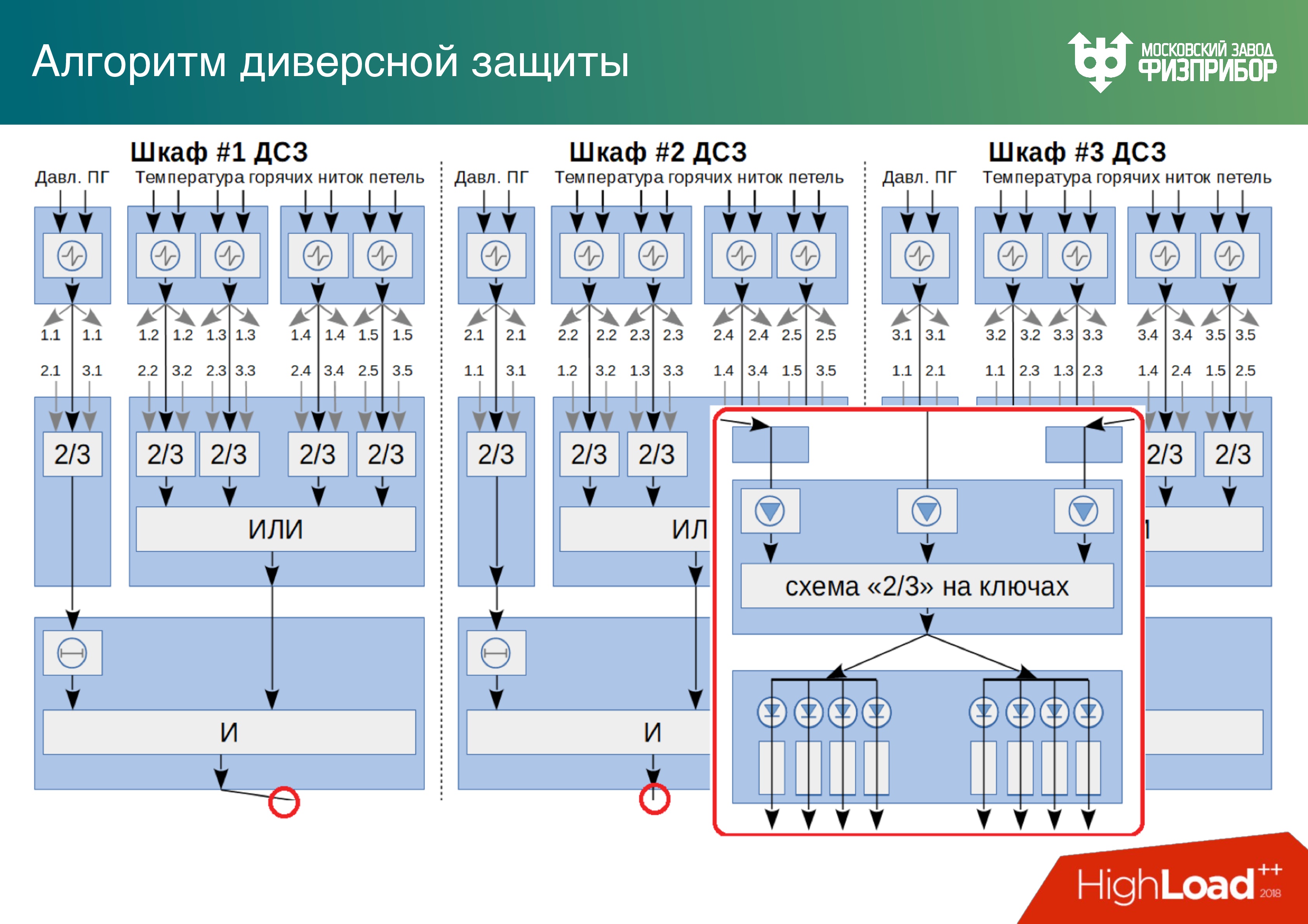
Abaixo está um exemplo de algoritmo para a escolha de uma solução baseada em um sistema triplo de proteção à sabotagem. O algoritmo é considerado correto com base em duas das três respostas. Acreditamos que, se um dos armários falhar, primeiro aprendemos sobre ele e, em segundo lugar, os outros dois funcionarão bem. Existem campos inteiros desses gabinetes em usinas nucleares.

Falamos sobre hardware, vamos passar para o que é mais interessante para todos - para software.
Software. Top e coluna
É assim que o sistema de monitoramento desses armários se parece.

O sistema de nível superior (após a automação de baixo nível) fornece coleta, processamento e entrega confiáveis de informações ao operador e outros serviços de seu interesse. Antes de tudo, ele deve resolver a tarefa principal - ser capaz de resolver tudo
no momento do pico de carga ; portanto, em operação normal, o sistema pode ser carregado de 5 a 10%. As capacidades restantes realmente funcionam ociosas e são projetadas para que, em caso de emergência, possamos equilibrar, distribuir e processar todas as sobrecargas.
O exemplo mais típico é uma turbina. Ele fornece o máximo de informações e, se começar a funcionar de maneira instável, o DDoS realmente acontece, porque todo o sistema de informações está entupido com as informações de diagnóstico dessa turbina. Se a
QoS não funcionar bem, problemas sérios podem surgir: o operador simplesmente não verá algumas das informações importantes.
De fato, nem tudo é tão assustador. Um operador pode trabalhar em um reatímetro físico por 2 horas, mas perde alguns equipamentos. Para evitar que isso aconteça, estamos desenvolvendo nossa nova plataforma de software. A versão anterior agora serve 15 unidades de energia, construídas na Rússia e no exterior.
 Uma plataforma de software é uma arquitetura de microsserviço multiplataforma
Uma plataforma de software é uma arquitetura de microsserviço multiplataforma que consiste em várias camadas:
- Uma camada de dados é um banco de dados em tempo real. É muito simples - algo como Key-value, mas o valor pode ser apenas o dobro. Não há mais objetos armazenados lá para remover completamente a possibilidade de estouro de buffer, pilha ou outra coisa.
- Um banco de dados separado para armazenar metadados. Utilizamos o PostgreSQL e outras tecnologias, em princípio, qualquer tecnologia está configurada, porque não há tempo real difícil.
- Camada de arquivamento. Este é um arquivo on-line (aproximadamente um dia) para processar informações atuais e, por exemplo, relatórios.
- Arquivo de longo prazo.
- Arquivo de emergência - uma caixa preta que será usada se ocorrer um acidente e o arquivo de longo prazo for danificado. Os principais indicadores, alarmes, o fato de reconhecer alarmes estão registrados ( reconhecimento significa que o operador viu o alarme e começou a fazer alguma coisa ).
- A camada lógica na qual a linguagem de script está localizada. O núcleo de computação é baseado nele e, depois do núcleo de computação, como um módulo, existe um gerador de relatórios. Nada de anormal: você pode imprimir um gráfico, fazer uma solicitação, ver como os parâmetros foram alterados.
- Camada de cliente - um nó que permite desenvolver serviços de cliente com base no código, contém uma API.
Existem várias opções para nós do cliente:
- Otimizado para gravação . Ele desenvolve drivers de dispositivo, mas não é um driver clássico. Este é um programa que coleta informações de controladores de automação a jusante, realiza pré-processamento, analisa todas as informações e quaisquer protocolos usados pelos equipamentos de automação a jusante - OPC, HART, UART, Profibus.
- Otimizado para leitura - para criar interfaces de usuário, manipuladores e tudo o que vai além.
Com base nesses nós, estamos construindo uma
nuvem . Ele consiste em servidores confiáveis clássicos que são gerenciados usando sistemas operacionais comuns. Usamos principalmente o Linux, às vezes QNX.
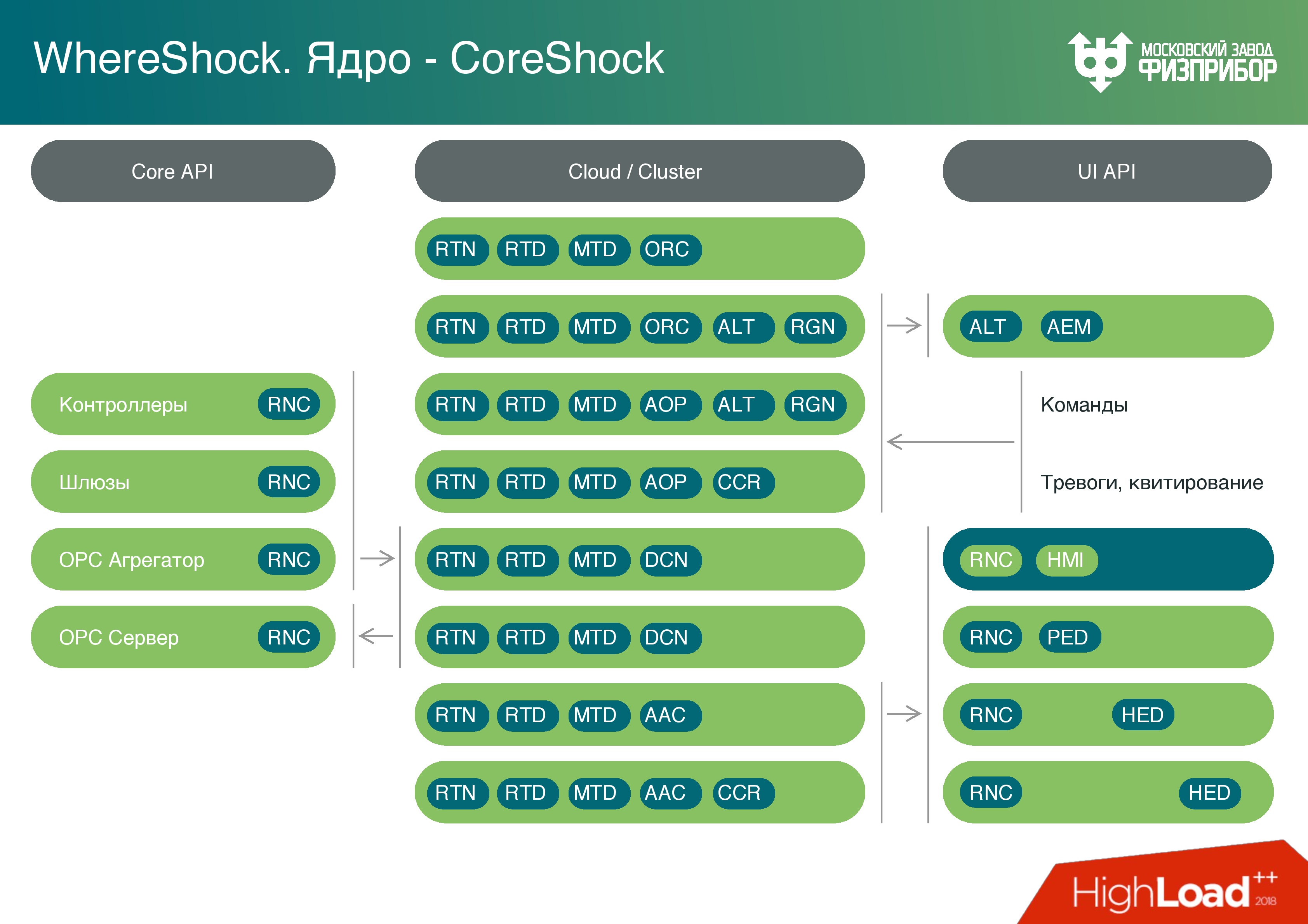
A nuvem é cortada em máquinas virtuais, os contêineres são lançados em algum lugar. Como parte da virtualização de contêiner, são iniciados vários tipos de nós que, se necessário, executam tarefas diferentes. Por exemplo, você pode executar o gerador de relatórios uma vez por dia, quando todos os materiais de relatório necessários para o dia estiverem prontos, as máquinas virtuais forem descarregadas e o sistema ficar pronto para outras tarefas.
Chamamos nosso sistema de
Vershok e o núcleo do sistema
Spine - está claro o porquê.

Tendo recursos de computação suficientemente poderosos nos controladores de gateway, pensamos - por que não usar a energia deles não apenas no pré-processamento? Podemos transformar essa nuvem e todos os nós de borda em neblina e carregar essas capacidades com tarefas, como, por exemplo, identificar erros.

Às vezes acontece que os sensores precisam ser calibrados. Com o tempo, as leituras são flutuantes, sabemos de acordo com o horário em que elas mudarão suas leituras e, em vez de alterar esses sensores, atualizamos os dados e fazemos as correções - isso é chamado de calibração do sensor.
Temos uma plataforma completa de nevoeiro. Sim, ele executa um número limitado de tarefas no meio do nevoeiro, mas aumentaremos gradualmente seu número e descarregaremos a nuvem total.
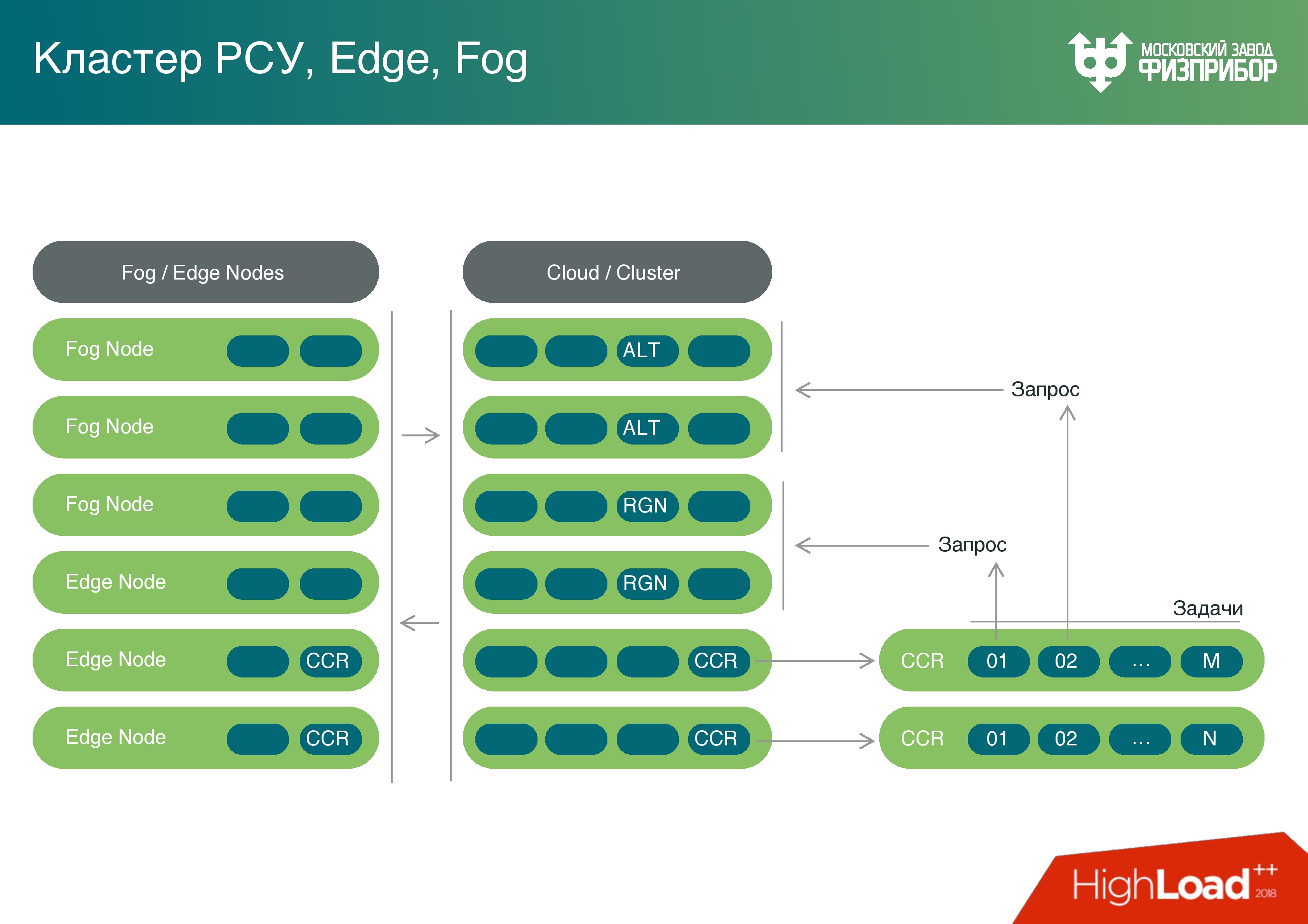
Além disso, temos um núcleo de computação. Incluímos uma linguagem de script, podemos trabalhar com Lua, com Python (por exemplo, biblioteca PyPy), com JavaScript e TypeScript para resolver problemas com interfaces de usuário. Podemos executar essas tarefas igualmente bem tanto na nuvem quanto nos nós de fronteira. Cada microsserviço pode ser iniciado no processador com absolutamente qualquer quantidade de memória e energia. Ele simplesmente processará a quantidade de informação possível nas capacidades atuais. Mas o sistema funciona da mesma maneira em absolutamente qualquer nó. Também é adequado para posicionamento em dispositivos IoT simples.
Agora, as informações de vários subsistemas chegam a essa plataforma: o nível de proteção física, sistemas de controle de controle de acesso, informações de câmeras, dados de segurança contra incêndio, sistemas de controle de processo, infraestrutura de TI, eventos de segurança da informação.
Com base nesses dados, o Behavior Analytics é construído - análise comportamental. Por exemplo, um operador não pode fazer login se a câmera não registrar que foi à sala do operador. Ou outro caso: vemos que algum canal de comunicação não está funcionando, enquanto corrigimos que, neste momento, a temperatura do rack mudou, a porta foi aberta. Alguém entrou, abriu a porta, puxou ou bateu no cabo. Obviamente, isso não deveria ser, mas o monitoramento ainda é necessário. É necessário descrever o maior número possível de casos, para que, quando algo de repente aconteça, tenhamos certeza disso.

Acima estão exemplos de equipamentos nos quais tudo isso funciona e seus parâmetros:
- À esquerda, há um servidor Supermicro comum. A escolha recaiu sobre a Supermicro, pois, com todas as possibilidades de ferro disponíveis imediatamente, é possível usar equipamentos domésticos.
- À direita está o controlador, produzido em nossa fábrica. Confiamos plenamente nele e entendemos o que está acontecendo lá. No slide, ele é totalmente carregado com módulos de computação.
Nosso
controlador trabalha com refrigeração passiva e, do nosso ponto de vista, é muito mais confiável, por isso tentamos transferir o número máximo de tarefas para sistemas com refrigeração passiva. Qualquer ventilador falhará em algum momento e a vida útil da usina nuclear é de 60 anos, com possibilidade de extensão para 80. É claro que durante esse período serão feitos reparos preventivos programados, o equipamento será substituído. Mas se você pegar um objeto que começou nos anos 90 ou 80, é impossível encontrar um computador para executar o software que funciona lá. Portanto, tudo precisa ser reescrito e alterado, incluindo algoritmos.
Nossos serviços operam no modo Multi-Master, não há um ponto único de falha, tudo isso é multiplataforma. Os nós são autodeterminados, você pode fazer Hot Swap, devido ao qual você pode adicionar e trocar de equipamento, e não há dependência da falha de um ou mais elementos.

Existe uma
degradação do sistema . Até certo ponto, o operador não deve perceber que algo está errado com o sistema: o módulo do processador está queimado ou a energia do servidor desapareceu e foi desligada; O canal de comunicação foi sobrecarregado porque o sistema não está funcionando. Esses problemas e similares podem ser resolvidos com o backup de todos os componentes e da rede. Agora temos uma topologia de estrela e malha dupla. Se algum nó falhar, a topologia do sistema permitirá que você continue a operação normal.

Estas são comparações dos parâmetros Supermicro (acima) e do nosso controlador (abaixo), que obtemos das atualizações com base em um banco de dados em tempo real. As figuras 4 e 8 são o número de réplicas, ou seja, o banco de dados mantém o estado atual de todos os nós em tempo real - estes são multicast e em tempo real. Na configuração de teste, existem aproximadamente 10 milhões de tags, ou seja, fontes de alterações de sinal.
Supermicro mostra uma média de 7 M / s ou 5 M / s, com um aumento no número de réplicas. Estamos lutando para não perder o poder do sistema, com um aumento no número de nós. Infelizmente, quando se torna necessário processar as configurações e outros parâmetros, perdemos velocidade com um aumento no número de nós, mas quanto mais nós, menos perdas.
No
nosso controlador (no Atom), os parâmetros são uma ordem de magnitude menor.
Para criar uma tendência, é mostrado ao usuário um conjunto de tags. Abaixo está uma interface orientada ao toque para o operador, na qual ele pode selecionar opções. Cada nó do cliente possui uma cópia do banco de dados. O desenvolvedor do aplicativo cliente trabalha com memória local e não pensa em sincronizar dados pela rede, apenas recebe, define por meio da API.
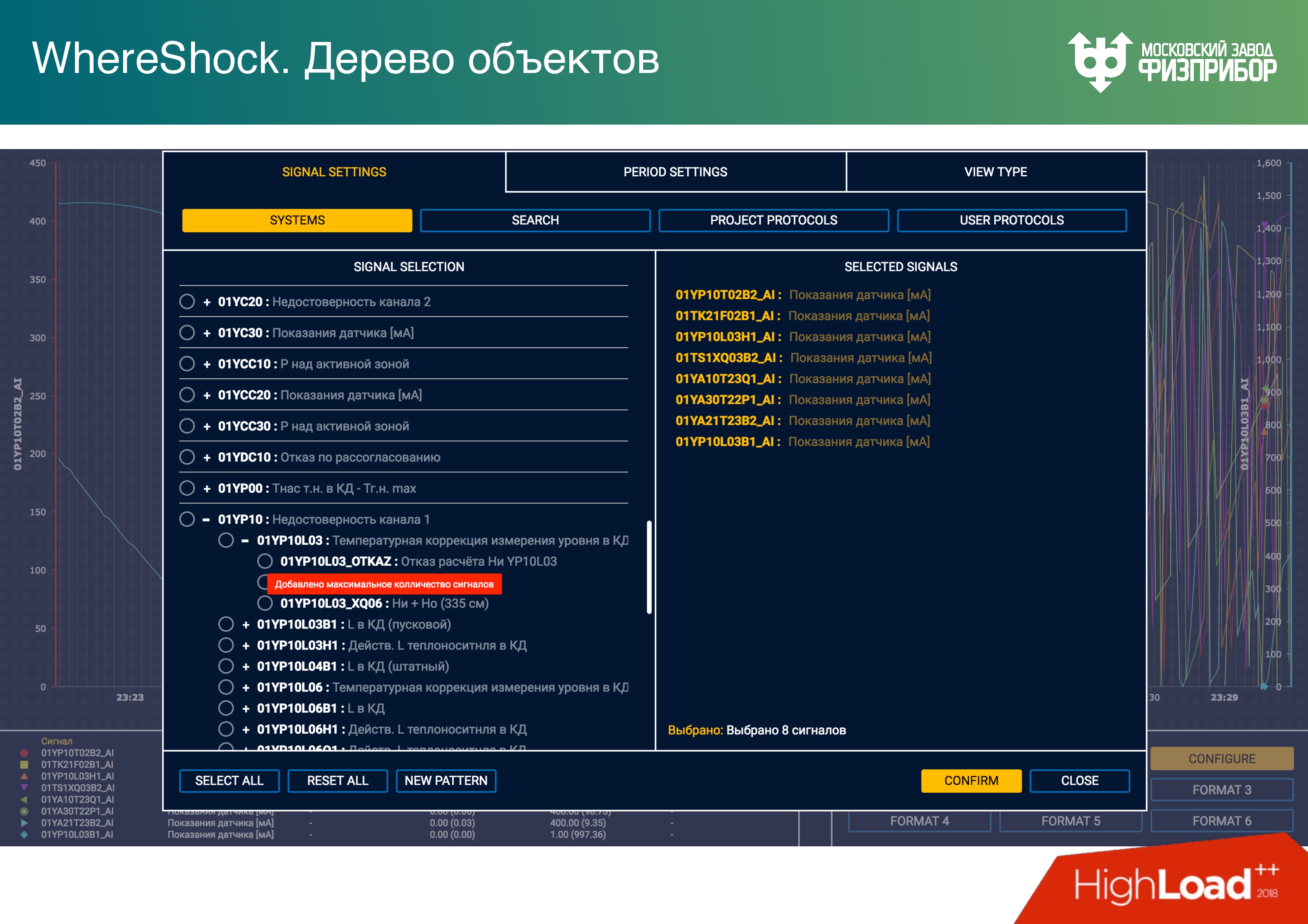
O desenvolvimento de uma interface do cliente para sistemas de controle de processos não é mais complicado do que o desenvolvimento de um site. Anteriormente, lutávamos em tempo real no cliente, usando C ++, Qt. Agora nós recusamos e fizemos tudo no Angular. Os processadores modernos permitem manter a confiabilidade de tais aplicativos. A web já é confiável o suficiente, embora a memória, é claro, esteja flutuando.
A tarefa de garantir a operação do aplicativo por um ano sem reiniciar não é mais relevante. Tudo isso é empacotado no
Electron e, de fato, oferece independência de plataforma, ou seja, a capacidade de executar a interface em tablets e painéis.
Ansiedade
Um alarme é o único objeto dinâmico que aparece no sistema. Após o início do sistema, toda a árvore de objetos é corrigida; nada pode ser excluído a partir daí. Ou seja, o modelo CRUD não funciona, você pode apenas marcar "marcar como excluído". Se você precisar excluir uma tag, ela é simplesmente marcada e oculta a todos, mas não é excluída, porque a operação de exclusão é complexa e pode danificar o estado do sistema e sua integridade.
Um alarme é um objeto que aparece quando um parâmetro de sinal de um equipamento específico vai além das configurações. As configurações são os limites inferior e superior de aviso dos valores: emergência, crítico, supercrítico, etc. Quando um parâmetro cai em um valor de escala específico, um alarme correspondente é exibido.
A primeira pergunta que surge quando ocorre um alarme é para quem mostrar uma mensagem sobre ele. Mostrar alarme para dois operadores? Mas nosso sistema é universal, pode haver mais operadores. Em uma usina nuclear, os bancos de dados do turbinista e do especialista em reatores diferem "um pouco", porque o equipamento é diferente. É claro, é claro, se o nível do sinal ultrapassou os limites no compartimento do reator, isso será visto pelo engenheiro líder de controle do reator, na turbina - pela turbina.
Mas suponha que haja muitos operadores.
Então você não pode mostrar o alarme para todos. Ou, se alguém aceitar o reconhecimento, ele deverá ser imediatamente bloqueado para reconhecimento em todos os outros nós. Esta é uma operação em tempo real e, quando dois operadores se comprometem a reconhecer o mesmo alarme, eles imediatamente começam a gerenciar equipamentos e algoritmos. Tudo isso está conectado à programação multithread de rede e pode levar a sérios conflitos no sistema. Portanto, qualquer objeto dinâmico deve ser mostrado, com a oportunidade de controlá-lo e "silenciar" o alarme apenas para um operador., . - “” – . , , , , “” . , . : , . , .
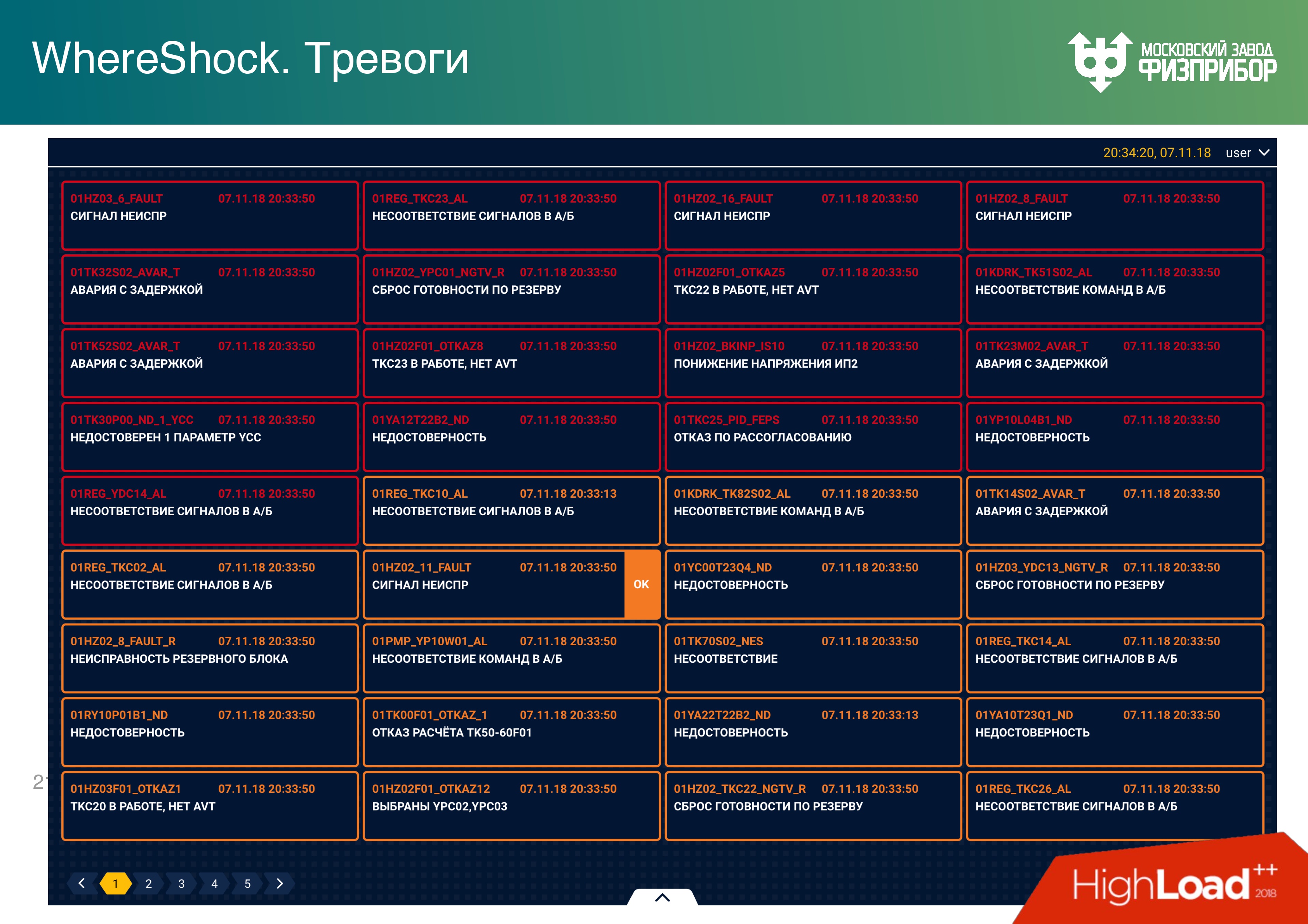
, , .

– .
. , .

.

, , , , .
– , . SCADA/HMI , , , – , , . , : «, ! Illustrator, Sketch – , SVG». SVG . , .
, . API, . , , , . , , . , , , , – . , , , , .
,
. , . Data Lake. ,
multitenancy (, ). .
, . , , ,
.
, : . , 10 100 , – .
, . , .
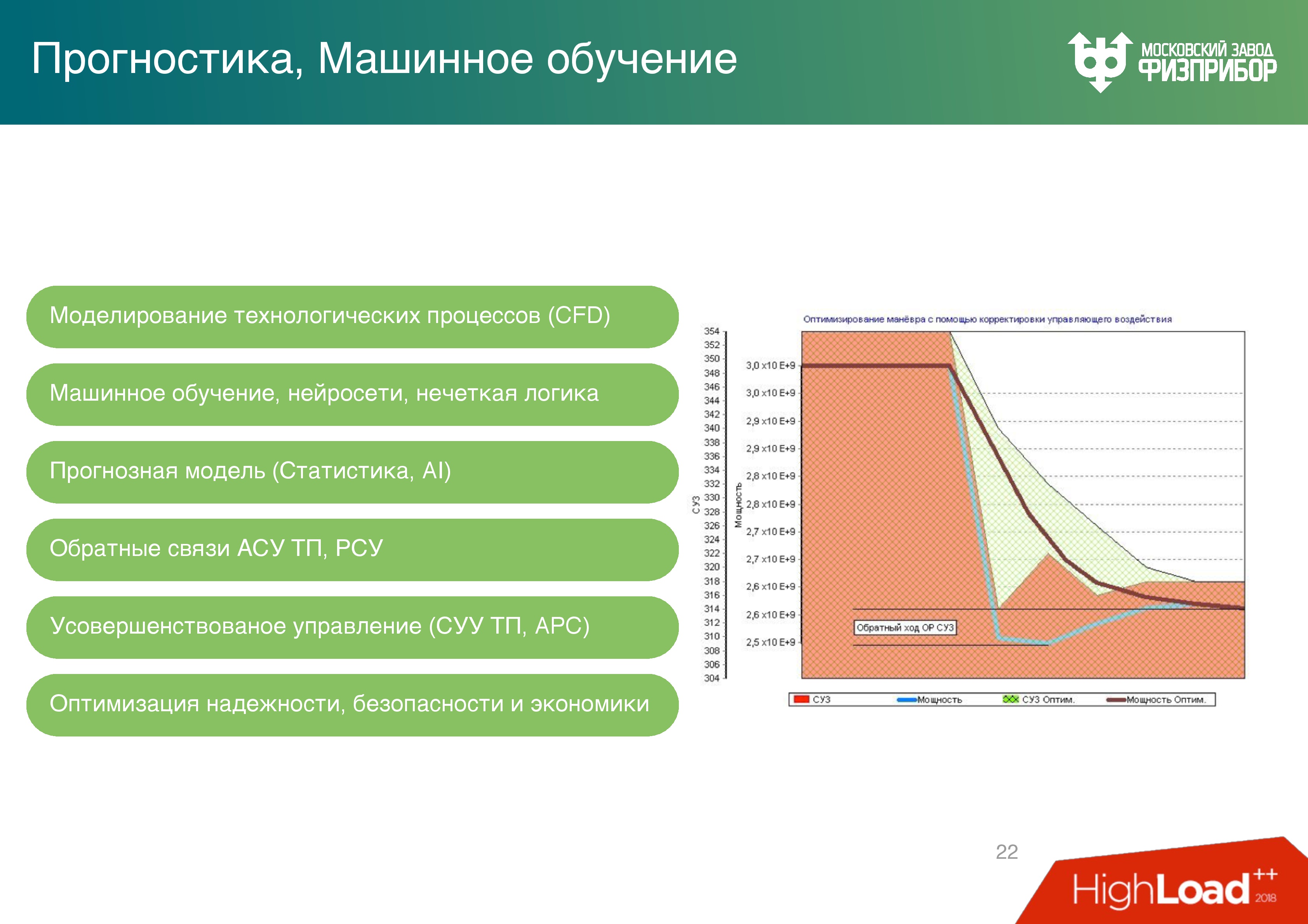
— . , , . – , : -1200 10 .
, , , , , - , , .… .
. . 5 : , , , . .
:
- - ( CPU);
- Computational Fluid Dynamics (CFD) ( GPU).
, . - , , ( ). .
60 , ( , ). KPI , .
.
 – , – .
– , – .. – . , , , – .
VR- , .

, , , . ( ) — , - . , , . — ( ), – ( ), .
, , — . . . .
ITER . , – . , , . , !
Faremos um viés maior no desenvolvimento de software e hardware para a Internet das coisas na InoThings Conf em 4 de abril. No ano passado, houve relatórios sobre IIoT e eletricidade . Este ano, planejamos tornar o programa ainda mais agitado. Escreva aplicativos se estiver pronto para nos ajudar com isso.