
Entro na equipe do Tarantool Core e participo do desenvolvimento de um mecanismo de banco de dados, comunicação interna dos componentes do servidor e replicação. E hoje eu vou lhe dizer como a replicação funciona.
Sobre replicação
Replicação é o processo de fazer cópias de dados de um armazenamento para outro. Cada cópia é chamada de réplica. A replicação pode ser usada se você precisar obter um backup, implementar o hot standby ou escalar o sistema horizontalmente. E para isso é necessário poder usar os mesmos dados em diferentes nós da rede de computadores do cluster.
Classificamos a replicação de duas maneiras principais:
- Direção: mestre-mestre ou mestre-escravo . A replicação mestre-escravo é a opção mais fácil. Você tem um nó no qual está alterando dados. Você traduz essas alterações para os outros nós em que são aplicadas. Com a replicação mestre-mestre, são feitas alterações em vários nós de uma só vez. Nesse caso, cada nó altera seus dados e aplica as alterações feitas em outros nós.
- Modo de operação: assíncrono ou síncrono . A replicação síncrona implica que os dados não serão confirmados e a replicação não será confirmada para o usuário até que as alterações sejam propagadas por pelo menos o número mínimo de nós do cluster. Na replicação assíncrona, confirmar uma transação (confirmar) e interagir com um usuário são dois processos independentes. Para confirmar dados, é necessário apenas que eles caiam no log local e somente então essas alterações são transmitidas de alguma forma para outros nós. Obviamente, a replicação assíncrona tem vários efeitos colaterais por causa disso.
Como funciona a replicação no Tarantool?
A replicação no Tarantool possui vários recursos:
- Ele é construído a partir de tijolos básicos, com os quais você pode criar um cluster de qualquer topologia. Cada um desses itens de configuração básica é unidirecional, ou seja, você sempre tem mestre e escravo. O mestre executa algumas ações e gera um log de operações, que é usado na réplica.
- A replicação do Tarantool é assíncrona. Ou seja, o sistema confirma a confirmação para você, independentemente de quantas réplicas essa transação viu, quanto foi aplicada a si mesma e se acabou sendo feita.
- Outra propriedade de replicação no Tarantool é que ela é baseada em linhas. Tarantool mantém um log de operações (WAL). A operação chega lá linha por linha, ou seja, quando algumas alterações do espaço são alteradas, essa operação é gravada no log como uma linha. Depois disso, o processo em segundo plano lê essa linha do log e a envia para a réplica. Quantas réplicas o mestre possui, tantos processos em segundo plano. Ou seja, cada processo de replicação para diferentes nós do cluster é executado de forma assíncrona a partir de outros.
- Cada nó do cluster possui seu próprio identificador exclusivo, que é gerado quando o nó é criado. Além disso, o nó também possui um identificador no cluster (número do membro). Essa é uma constante numérica atribuída a uma réplica quando conectada a um cluster e permanece com a réplica durante toda a sua vida útil no cluster.
Devido à assincronia, os dados são entregues às réplicas atrasadas. Ou seja, você fez alguma alteração, o sistema confirmou a confirmação, a operação já foi aplicada no mestre, mas nas réplicas ela será aplicada com algum atraso, que é determinado pela velocidade com que o processo de replicação em segundo plano lê a operação, a envia para a réplica e aplica-a .
Por esse motivo, há uma chance de dados fora de sincronia. Suponha que tenhamos vários mestres que alteram dados interconectados. Pode acontecer que as operações usadas não sejam comutativas e se refiram aos mesmos dados, então dois membros diferentes do cluster terão versões diferentes dos dados.
Se a replicação no Tarantool é mestre-escravo unidirecional, como fazer mestre-mestre? Muito simples: crie outro canal de replicação, mas na outra direção. Você precisa entender que, no Tarantool, a replicação mestre-mestre é apenas uma combinação de dois fluxos de dados que são independentes um do outro.
Usando o mesmo princípio, podemos conectar o terceiro mestre e, como resultado, criar uma rede de malha completa na qual cada réplica é mestre e escravo para todas as outras réplicas.
Observe que não apenas as operações iniciadas localmente neste mestre são replicadas, mas também aquelas que ele recebeu externamente por meio de protocolos de replicação. Nesse caso, as alterações criadas na réplica número 1 chegarão à réplica número 3 duas vezes: diretamente e através da réplica número 2. Essa propriedade nos permite criar topologias mais complexas sem usar uma malha completa. Digamos este.
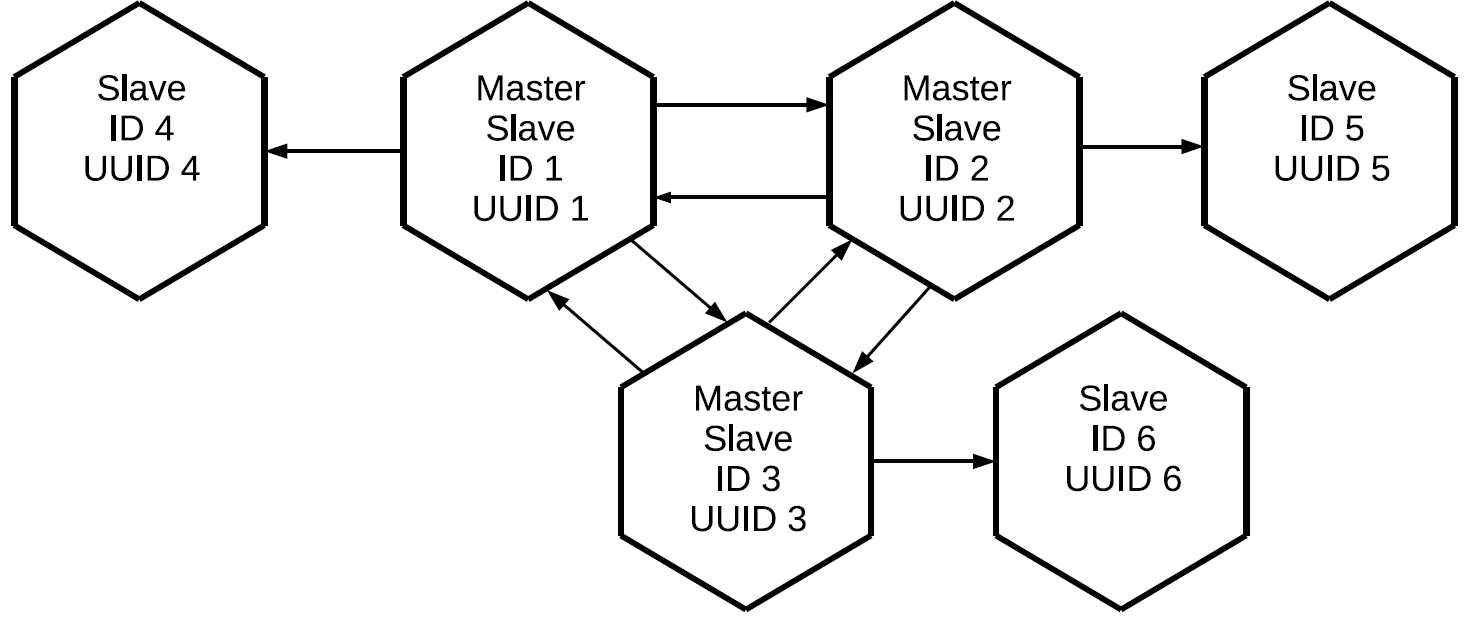
Todos os três mestres, que juntos formam o núcleo de malha completa do cluster, têm uma réplica individual anexada. Como o proxy dos logs é executado em cada um dos mestres, todos os três escravos “limpos” conterão todas as operações que foram executadas em qualquer um dos nós do cluster.
Essa configuração pode ser usada para uma variedade de tarefas. Você não pode criar links redundantes entre todos os nós do cluster e, se as réplicas forem colocadas nas proximidades, elas terão uma cópia exata do mestre com um atraso mínimo. E tudo isso é feito usando o elemento básico de replicação mestre-escravo.
Operações de cluster de rotulagem
Surge a pergunta:
se as operações tiverem proxy entre todos os membros do cluster e chegarem a cada réplica várias vezes, como entenderemos qual operação precisa ser executada e quais não? Isso requer um mecanismo de filtragem. Cada operação lida no log recebe dois atributos:
- O identificador do servidor no qual esta operação foi iniciada.
- O número de sequência da operação no servidor, lsn, que é seu iniciador. Cada servidor, ao executar uma operação, atribui um número crescente a cada linha de log recebida: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ... Portanto, se sabemos que para um servidor com um determinado identificador, aplicamos a operação com LS 10, as operações com LS 9, 8, 7, 10 que vieram através de outros canais de replicação não são necessárias. Em vez disso, aplicamos o seguinte: 11, 12 e assim por diante.
Status da réplica
E como o Tarantool armazena informações sobre as operações que já foram aplicadas? Para fazer isso, há um relógio Vclock - este é o vetor do último lsn aplicado a cada nó no cluster.
[lsn 1 , lsn 2 , lsn n ]onde
lsn i é o número da última operação conhecida do servidor com o identificador i.
O Vclock também pode ser chamado de um determinado instantâneo de todo o estado do cluster conhecido por esta réplica. Conhecendo o ID do servidor da operação que chegou, isolamos o componente do Vclock local necessário, comparamos o lsn recebido com a operação lsn e decidimos se deve usar essa operação. Como resultado, as operações iniciadas por um mestre específico serão enviadas e aplicadas sequencialmente. Ao mesmo tempo, os fluxos de trabalho criados em diferentes mestres podem ser misturados entre si devido à replicação assíncrona.
Criação de Cluster
Suponha que tenhamos um cluster composto por dois elementos mestre e escravo, e desejemos conectar uma terceira instância a ele. Ele possui um UUID exclusivo, mas ainda não há identificador de cluster. Se o Tarantool, que ainda não foi inicializado, deseja ingressar no cluster, ele deve enviar uma operação JOIN para um dos mestres que pode executá-lo, ou seja, está no modo de leitura / gravação. Em resposta a JOIN, o mestre envia seu instantâneo local para a réplica de conexão. A réplica rola em casa, embora ainda não tenha um identificador. Agora a réplica com um ligeiro atraso está sincronizada com o cluster. Depois disso, o mestre no qual o JOIN foi executado atribui um identificador a essa réplica, que é registrada e enviada à réplica. Quando um identificador é atribuído a uma réplica, ele se torna um nó completo e, depois disso, pode iniciar a replicação de log para o lado.
As linhas do diário são enviadas a partir do estado desta réplica no momento da solicitação do log de replicação do mestre - ou seja, do vclock recebido durante o processo JOIN ou do local em que a réplica parou anteriormente. Se a réplica cair por algum motivo, na próxima vez em que se conectar ao cluster, ela não executará JOIN, porque já possui uma captura instantânea local. Ela apenas pede todas as operações que ocorreram durante sua ausência no cluster.
Registrar uma réplica em um cluster
Para armazenar o estado sobre a estrutura do cluster, é usado um espaço especial - cluster. Ele contém os identificadores do servidor no cluster, seus números de série e identificadores exclusivos.
[1, 'c35b285c-c5b1-4bbe-83b1-b825eb594aa4']
[2, '37b12cb7-d324-4d75-b428-cde92c18e708']
[3, 'b72b1aa6-42a0-4d73-a611-900e44cdd465']Os identificadores não precisam seguir em ordem, porque os nós podem ser eliminados e adicionados.
Aqui está a primeira armadilha. Como regra, os clusters não são coletados por um nó: você executa um determinado aplicativo e ele implementa todo o cluster de uma só vez. Mas a replicação no Tarantool é assíncrona. E se dois mestres conectarem simultaneamente novos nós e atribuírem identificadores idênticos a eles? Haverá um conflito.
Aqui está um exemplo de um JOIN errado e correto:

Temos dois mestres e duas réplicas que desejam se conectar. Eles fazem JOINs em diferentes mestres. Suponha que as réplicas obtenham os mesmos identificadores. Em seguida, a replicação entre os mestres e aqueles que conseguem replicar seus logs desmoronará, o cluster desmoronará.
Para impedir que isso aconteça, você precisa iniciar réplicas estritamente em um mestre a qualquer momento. Para esse fim, Tarantool introduziu esse conceito como líder de inicialização e implementou um algoritmo para escolher esse líder. Uma réplica que deseja se conectar ao cluster primeiro estabelece uma conexão com todos os mestres conhecidos na configuração transferida. Em seguida, a réplica seleciona aqueles que já foram iniciados (ao implantar o cluster, nem todos os nós conseguem ganhar dinheiro cheio). E a partir deles são selecionados os mestres disponíveis para gravação. No Tarantool, há leitura e gravação e somente leitura, não podemos registrar no nó somente leitura. Depois disso, na lista de nós filtrados, selecionamos o que possui o UUID mais baixo.
Se usarmos a mesma configuração e a mesma lista de servidores em instâncias não inicializadas conectadas ao cluster, eles selecionarão o mesmo mestre, o que significa que JOIN provavelmente terá êxito.
A partir daqui, derivamos uma regra: ao conectar réplicas a um cluster em paralelo, todas essas réplicas devem ter a mesma configuração de replicação. Se omitirmos algo em algum lugar, existe a possibilidade de que instâncias com uma configuração diferente sejam iniciadas em mestres diferentes e o cluster não consiga montar.
Suponha que estivéssemos enganados, ou o administrador esqueceu de corrigir a configuração, ou o Ansible quebrou, e o cluster ainda se desfez. O que pode testemunhar isso? Primeiro, as réplicas conectáveis não poderão criar seus instantâneos locais: as réplicas não iniciam e relatam erros. Em segundo lugar, nos mestres nos logs, veremos erros relacionados a conflitos no cluster de espaço.
Como resolvemos essa situação? É simples:
- Antes de tudo, precisamos validar a configuração que definimos para as réplicas de conexão, porque se não a corrigirmos, todo o resto será inútil.
- Depois disso, limpamos os conflitos no cluster e tiramos uma foto.
Agora você pode tentar inicializar as réplicas novamente.
Resolução de Conflitos
Então, criamos um cluster e nos conectamos. Todos os nós funcionam no modo de assinatura, ou seja, recebem as alterações geradas por diferentes mestres. Como a replicação é assíncrona, são possíveis conflitos. Quando você altera dados simultaneamente em diferentes mestres, réplicas diferentes obtêm cópias diferentes dos dados, porque as operações podem ser aplicadas em uma ordem diferente.
Aqui está um exemplo de cluster após a execução de JOIN:
Temos três escravos-mestre, os logs são transmitidos entre eles, que são procurados em direções diferentes e são aplicados nos escravos. Dados fora de sincronia significa que cada réplica terá seu próprio histórico de alterações no vclock, porque fluxos de diferentes mestres podem ser misturados. Porém, a ordem das operações nas instâncias pode variar. Se nossas operações não forem comutativas, como a operação REPLACE, os dados que recebermos nessas réplicas serão diferentes.
Um pequeno exemplo. Suponha que tenhamos dois mestres com vclock = {0,0}. E ambos realizarão duas operações, designadas como op1,1, op1,2, op2,1, op2,2. Este é o segundo intervalo de tempo em que cada um dos mestres executou uma operação local:

Verde indica uma alteração no componente vclock correspondente. Primeiro, os dois mestres alteram seu vclock e, em seguida, o segundo mestre executa outra operação local e aumenta novamente o vclock. O primeiro mestre recebe a operação de replicação do segundo mestre, isso é indicado pelo número vermelho 1 no vclock do primeiro nó do cluster.

Então o segundo mestre recebe a operação do primeiro e do primeiro - a segunda operação do segundo. E no final, o primeiro mestre executa sua última operação e o segundo mestre a recebe.

Vclock no quantum de tempo zero, temos o mesmo - {0,0}. No último quantum de tempo, também temos o mesmo vclock {2,2}, parece que os dados devem ser os mesmos. Mas a ordem das operações executadas em cada mestre é diferente. E se esta é uma operação REPLACE com valores diferentes para as mesmas chaves? Então, apesar do mesmo vclock no final, obteremos versões diferentes dos dados nas duas réplicas.
Também somos capazes de resolver esta situação.
- Registros de sharding . Primeiro, podemos executar operações de gravação não em réplicas selecionadas aleatoriamente, mas de alguma forma fragmentá-las. Eles simplesmente quebraram as operações de gravação em diferentes mestres e obtiveram um sistema de consistência eventual. Por exemplo, as chaves foram alteradas de 1 para 10 em um mestre e de 11 para 20 em outro - os nós trocarão seus logs e obterão exatamente os mesmos dados.
Sharding implica que temos um certo roteador. Ele não precisa ser uma entidade separada, o roteador pode fazer parte do aplicativo. Pode ser um shard que aplica operações de gravação a si mesmo ou as transfere para outro mestre de uma maneira ou de outra. Mas passa de tal maneira que as alterações nos valores associados vão para algum mestre específico: um bloco de valor foi para um mestre, outro bloco para outro mestre. Nesse caso, as operações de leitura podem ser enviadas para qualquer nó no cluster. E não se esqueça da replicação assíncrona: se você gravou no mesmo mestre, também poderá precisar ler a mesma.
- Ordenação lógica de operações . Suponha que, de acordo com as condições do problema, você possa determinar de alguma forma a prioridade da operação. Digamos, coloque um carimbo de data / hora, ou versão ou algum outro rótulo que nos permita entender qual operação ocorreu fisicamente anteriormente. Ou seja, estamos falando de uma fonte externa de pedidos.
O Tarantool possui um gatilho before_replace que pode ser executado durante a replicação. Nesse caso, não estamos limitados pela necessidade de rotear solicitações, podemos enviá-las para onde quisermos. Mas, ao executar a replicação na entrada do fluxo de dados, temos um gatilho. Ele lê a linha enviada, a compara com a linha que já está armazenada e decide qual das linhas tem maior prioridade. Ou seja, o gatilho ignora a solicitação de replicação ou a aplica, possivelmente com as modificações necessárias. Já aplicamos essa abordagem, embora ela também tenha suas desvantagens. Primeiro, você precisa de uma fonte de relógio externa. Suponha que uma operadora de um salão de telefonia móvel faça alterações em um assinante. Para essas operações, você pode usar o tempo no computador do operador, pois é improvável que vários operadores façam alterações em um assinante ao mesmo tempo. As operações podem vir de maneiras diferentes, mas se cada uma delas puder ser atribuída a uma determinada versão, ao passar pelos gatilhos, apenas os relevantes permanecerão.
A segunda desvantagem do método: como o gatilho é aplicado a cada delta que veio pela replicação para cada solicitação, isso cria uma carga computacional extra. Mas teremos uma cópia consistente dos dados em uma escala de cluster.
Sincronizar
Nossa replicação é assíncrona, ou seja, pela execução da confirmação, você não sabe se esses dados já estão em algum outro nó do cluster. Se você fez uma confirmação no mestre, ela foi confirmada e, por algum motivo, o mestre parou imediatamente de funcionar, então você não pode ter certeza de que os dados foram salvos em outro lugar. Para resolver esse problema, o protocolo de replicação do Tarantool possui um ACK. Cada mestre detém o conhecimento de qual último ACK veio de cada escravo.
O que é um ACK? Quando o slave recebe o delta, marcado pelo mestre lsn e seu identificador, em resposta, envia um pacote ACK especial, no qual empacota seu vclock local após aplicar esta operação. Vamos ver como isso pode funcionar.
Temos um mestre que realizou 4 operações em si mesmo. Suponha que em algum momento o escravo escravo tenha recebido as três primeiras linhas e seu vclock aumentado para {3,0}.
O ACK ainda não chegou. Após receber essas três linhas, o slave envia o pacote ACK ao qual costurou seu vclock no momento em que o pacote foi enviado. Deixe o mestre escravo enviar outra linha no mesmo intervalo de tempo, ou seja, o vclock do escravo aumentou. Com base nisso, o mestre n ° 1 sabe com certeza que as três primeiras operações que ele executou já foram aplicadas a esse escravo. Esses estados são armazenados para todos os escravos com os quais o mestre trabalha; eles são completamente independentes.
E, no final, o escravo responde com um quarto pacote ACK. Depois disso, o mestre sabe que o escravo está sincronizado com ele.
Este mecanismo pode ser usado no código do aplicativo. Quando você confirma uma operação, não reconhece imediatamente o usuário, mas primeiro chama uma função especial. Espera que o escravo lsn conhecido pelo mestre seja igual ao lsn do seu mestre no momento em que a confirmação é concluída. Portanto, você não precisa esperar pela sincronização completa, apenas pelo momento mencionado.
Suponha que a nossa primeira chamada tenha mudado três linhas e a segunda tenha mudado uma. Após a primeira chamada, você deseja garantir que os dados estejam sincronizados. O estado mostrado acima já significa que a primeira chamada foi sincronizada em pelo menos um escravo.
Onde exatamente procurar informações sobre isso, consideraremos na próxima seção.
Monitoramento
Quando a replicação é síncrona, o monitoramento é muito simples: se desmoronar, serão emitidos erros nas suas operações. E se a replicação é assíncrona, a situação se torna confusa. O Mestre responde que tudo está bem, funciona, é aceito, anotado. Mas, ao mesmo tempo, todas as réplicas estão inoperantes, os dados não têm redundância e, se você perder o mestre, os dados serão perdidos. Portanto, eu realmente quero monitorar o cluster, entender o que está acontecendo com a replicação assíncrona, onde estão as réplicas e em que estado elas estão.
Para monitoramento básico, o Tarantool possui uma entidade box.info. Vale a pena chamá-lo no console, pois você verá dados interessantes.
id: 1 uuid: c35b285c-c5b1-4bbe-83b1-b825eb594aa4 lsn : 5 vclock : {2: 1, 1: 5} replication : 1: id: 1 uuid : c35b285c -c5b1 -4 bbe -83b1 - b825eb594aa4 lsn : 5 2: id: 2 uuid : 37 b12cb7 -d324 -4 d75 -b428 - cde92c18e708 lsn : 1 upstream : status : follow idle : 0.30358312401222 peer : lag: 3.6001205444336 e -05 downstream : vclock : {2: 1, 1: 5}
A métrica mais importante é o ID do
id . Nesse caso, 1 significa que o lsn desse mestre será armazenado na primeira posição em todo o vclock. Uma coisa muito útil. Se você tiver um conflito com JOIN, poderá distinguir um mestre do outro apenas por identificadores exclusivos. Além disso, quantidades locais incluem quantidades como lsn. Este é o número da última linha que esse mestre executou e gravou em seu log. No nosso exemplo, o primeiro mestre executou cinco operações. Vclock é o estado de operações que ele sabe que se aplicou a si mesmo. E, finalmente, para o mestre número 2, ele executou uma de suas operações de replicação.
Após os indicadores do estado local, você pode ver o que esta instância sabe sobre o estado da replicação de cluster; para isso, há uma seção de
replication . Ele lista todos os nós do cluster conhecidos pela instância, incluindo ele próprio. O primeiro nó possui o identificador 1, id corresponde à instância atual. O segundo nó tem o identificador 2, seu lsn 1 corresponde ao lsn que é gravado no vclock. Nesse caso, consideramos a replicação mestre-mestre, quando o mestre nº 1 é o mestre do segundo nó do cluster e seu escravo, ou seja, segue-o.
- A essência do
upstream . O atributo status follow significa que o mestre 1 segue o mestre 2. Ocioso é o tempo que passou localmente desde a última interação com esse mestre. Não enviamos um fluxo continuamente, o mestre envia um delta somente quando ocorrem alterações nele. Quando enviamos algum tipo de confirmação, também nos comunicamos. Obviamente, se o tempo ocioso aumentar (segundos, minutos, horas), algo está errado. - Atributo
lag . Nós conversamos sobre lag. Além do lsn e da server id cada operação no log também é marcada com um carimbo de data / hora - horário local durante o qual essa operação foi registrada no vclock no mestre que a executou. Ao mesmo tempo, Slave compara seu registro de data e hora local com o registro de data e hora do delta que ele recebeu. O último registro de data e hora atual recebido para a última linha, o escravo é exibido no monitoramento. - Atributo a
downstream . Mostra o que o mestre sabe sobre seu escravo em particular. Este é o ACK que o escravo envia para ele. A downstream apresentada acima significa que a última vez que seu escravo, também conhecido como mestre no número 2, enviou a ele seu vclock, que era 5,1. Esse mestre sabe que todas as cinco linhas, que ele completou em seu lugar, foram para outro nó.
Perda de XLOG
Considere a situação com a queda do mestre.
lsn : 0 id: 3 replication : 1: <...> upstream : status: disconnected peer : lag: 3.9100646972656 e -05 idle: 1602.836148153 message: connect, called on fd 13, aka [::1]:37960 2: <...> upstream : status : follow idle : 0.65611373598222 peer : lag: 1.9550323486328 e -05 3: <...> vclock : {2: 2, 1: 5}
Primeiro de tudo, o status mudará.
Lag não muda porque a linha que aplicamos permanece a mesma, não recebemos nenhuma nova. Ao mesmo tempo,
idle crescendo, nesse caso já é igual a 1602 segundos, tanto tempo que o mestre estava morto. E vemos uma mensagem de erro: não há conexão de rede.
O que fazer em uma situação semelhante? Nós descobrimos o que aconteceu com o nosso mestre, atraímos o administrador, reiniciamos o servidor, aumentamos o nó. A replicação repetida é executada e, quando o mestre entra no sistema, nos conectamos a ele, assinamos seu XLOG, obtemos para nós mesmos e o cluster se estabiliza.
Mas há um pequeno problema. Imagine que tínhamos um escravo, que por algum motivo se desligou e ficou ausente por um longo tempo. Durante esse período, o mestre que o serviu excluiu o XLOG. Por exemplo, o disco está cheio, o coletor de lixo coletou logs. Como um escravo que retorna pode continuar? De jeito nenhum. Como os logs que ele precisa aplicar para se sincronizar com o cluster desapareceram e não há para onde retirá-los. Nesse caso, veremos um erro interessante: o status não é mais
disconnected , mas
stopped . E uma mensagem específica: não há arquivo de log correspondente a esse lsn.
id: 3 replication : 1: <...> upstream : peer : status: stopped lag : 0.0001683235168457 idle : 9.4331328970147 message: 'Missing .xlog file between LSN 7 1: 5, 2: 2 and 8 1: 6, 2: 2' 2: <...> 3: <...> vclock : {2: 2, 1: 5}
De fato, a situação nem sempre é fatal. Suponha que temos mais de dois mestres e, em alguns deles, esses logs ainda são preservados. Nós os derramamos a todos os mestres de uma só vez, e não os armazenamos em apenas um. Acontece que essa réplica, conectando-se a todos os mestres que ela conhece, em alguns deles encontrará os logs de que ela precisa. Ela executará todas essas operações em casa, seu vclock aumentará e alcançará o estado atual do cluster. Depois disso, você pode tentar se reconectar.
Se não houver nenhum registro, não podemos continuar a réplica. Resta apenas reinicializá-lo. Lembre-se de seu identificador exclusivo, você pode escrevê-lo em um pedaço de papel ou em um arquivo. Em seguida, limpamos a réplica localmente: exclua suas imagens, logs e assim por diante. Depois disso, reconecte a réplica com o mesmo UUID que ela possuía.
Remova o cluster ou reutilize o UUID para a nova réplica:
box.cfg{instance_uuid = uuid} .
, . UUID space cluster, . , . UUID, master, JOIN, , UUID, , .
, UUID , space cluster , . . , , .
, - . , . , , .
Tarantool .
replication_connect_quorum: 2
replication_connect_timeout: 30
replication_sync_lag: 0.1, , , , , , master' 0,1 . 30 . , . 0,1 . , .
Keep alive
, ip tables drop. , - 30 30 , , . , keep alive-.
keep alive- :
box.cfg.replication_timeout .
master' , keep alive-, , . 4 master slave keep alive- , . master'.
, . 6 , 5 . 10 , 9 . .
, , . , master', . - . .
6 , 3. , . , 5 , 3 .
, :
, Telegram-, . , GitHub, .