Parte 2/3 aqui
Parte 3/3 aqui
Olá pessoal! Neste artigo, quero otimizar as informações e compartilhar a experiência de criação e uso do cluster interno do Kubernetes.
Nos últimos anos, essa tecnologia de orquestração de contêineres deu um grande passo à frente e se tornou um tipo de padrão corporativo para milhares de empresas. Alguns o usam na produção, outros apenas o testam em projetos, mas as paixões em torno dele, não importa como você diz, brilham com seriedade. Se você nunca o usou antes, é hora de começar a namorar.
0. Introdução
O Kubernetes é uma tecnologia de orquestração escalável que pode começar com a instalação em um único nó e atingir o tamanho de grandes clusters de HA com base em várias centenas de nós no interior. Os provedores de nuvem mais populares fornecem diferentes tipos de implementações do Kubernetes - uso e uso. Mas as situações são diferentes e existem empresas que não usam nuvens e desejam obter todas as vantagens das modernas tecnologias de orquestração. E aqui vem a instalação do Kubernetes no bare metal.

1. Introdução
Neste exemplo, criaremos um cluster de HA do Kubernetes com a topologia para vários mestres, com um cluster externo etcd como a camada base e um balanceador de carga do MetalLB. Em todos os nós em funcionamento, implantaremos o GlusterFS como um simples armazenamento em cluster distribuído interno. Também tentaremos implantar vários projetos de teste usando nosso registro pessoal do Docker.
Em geral, existem várias maneiras de criar um cluster de alta disponibilidade do Kubernetes: o caminho difícil e detalhado descrito no popular documento kubernetes da maneira mais difícil , ou a maneira mais simples de usar o utilitário kubeadm .
O Kubeadm é uma ferramenta criada pela comunidade Kubernetes especificamente para simplificar a instalação do Kubernetes e facilitar o processo. Anteriormente, o Kubeadm era recomendado apenas para criar pequenos clusters de teste com um nó principal, para começar. Mas, no ano passado, muito foi aprimorado e agora podemos usá-lo para criar clusters de alta disponibilidade com vários nós principais. De acordo com as notícias da comunidade Kubernetes, no futuro, o Kubeadm será recomendado como uma ferramenta para instalar o Kubernetes.
A documentação do Kubeadm oferece duas maneiras básicas de implementar um cluster, com topologias de pilha e etcd externas. Escolherei o segundo caminho com os nós externos etcd devido à tolerância a falhas do cluster de alta disponibilidade.
Aqui está um diagrama da documentação do Kubeadm que descreve este caminho:
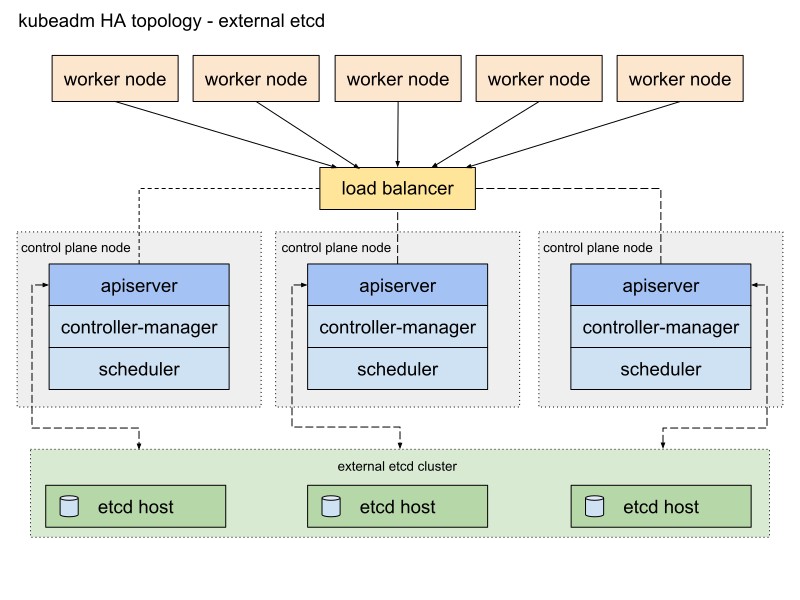
Vou mudar um pouco. Primeiro, usarei um par de servidores HAProxy como balanceadores de carga com o pacote Heartbeat, que compartilhará o endereço IP virtual. O Heartbeat e o HAProxy usam uma pequena quantidade de recursos do sistema, portanto, eu os colocarei em um par de nós etcd para reduzir um pouco o número de servidores para nosso cluster.
Para esse esquema de cluster do Kubernetes, são necessários oito nós. Três servidores para um cluster externo etcd (os serviços LB também usarão alguns), dois para nós do plano de controle (nós principais) e três para nós em funcionamento. Pode ser bare metal ou um servidor VM. Nesse caso, isso não importa. Você pode alterar facilmente o esquema adicionando mais nós principais e colocando o HAProxy com Heartbeat em nós separados, se houver muitos servidores gratuitos. Embora minha opção para a primeira implementação do cluster HA seja suficiente para os olhos.
Se desejar, adicione um servidor pequeno com o utilitário kubectl instalado para gerenciar este cluster ou use sua própria área de trabalho Linux.
O diagrama para este exemplo será parecido com este:
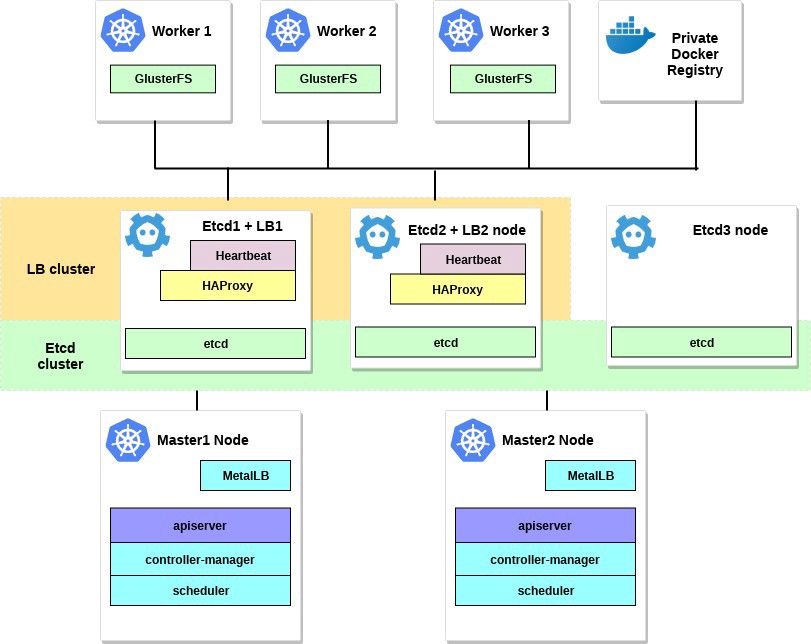
2. Requisitos
Você precisará de dois nós principais do Kubernetes com os requisitos mínimos de sistema recomendados: 2 CPUs e 2 GB de RAM, de acordo com a documentação do kubeadm . Para nós de trabalho, recomendo usar servidores mais poderosos, pois executaremos todos os nossos serviços de aplicativos neles. E para Etcd + LB, também podemos receber servidores com duas CPUs e pelo menos 2 GB de RAM.
Selecione uma rede pública ou rede privada para este cluster; Endereços IP não importam; É importante que todos os servidores estejam acessíveis um para o outro e, é claro, para você. Mais tarde, dentro do cluster Kubernetes, configuraremos uma rede de sobreposição.
Os requisitos mínimos para este exemplo são:
- 2 servidores com 2 processadores e 2 GB de RAM para o nó principal
- 3 servidores com 4 processadores e 4-8 GB de RAM para nós de trabalho
- 3 servidores com 2 processadores e 2 GB de RAM para Etcd e HAProxy
- 192.168.0.0/24 - a sub-rede.
192.168.0.1 - o endereço IP virtual do HAProxy, 192.168.0.2 - 4 endereços IP principais dos nós Etcd e HAProxy, 192.168.0.5 - 6 endereços IP principais do nó principal do Kubernetes, 192.168.0.7 - 9 endereços IP principais dos nós de trabalho do Kubernetes .
O banco de dados Debian 9 está instalado em todos os servidores.
Lembre-se também de que os requisitos do sistema dependem de quão grande e poderoso é o cluster. Para mais informações, consulte a documentação do Kubernetes.
3. Configure o HAProxy e a pulsação.
Temos mais de um nó mestre do Kubernetes e, portanto, você precisa configurar um balanceador de carga HAProxy na frente deles - para distribuir o tráfego. Este será um par de servidores HAProxy com um endereço IP virtual compartilhado. A tolerância a falhas é fornecida com o pacote de pulsação. Para implantação, usaremos os dois primeiros servidores etcd.
Instale e configure o HAProxy com Heartbeat no primeiro e no segundo servidores etcd (192.168.0.2–3 neste exemplo):
etcd1# apt-get update && apt-get upgrade && apt-get install -y haproxy etcd2# apt-get update && apt-get upgrade && apt-get install -y haproxy
Salve a configuração original e crie uma nova:
etcd1# mv /etc/haproxy/haproxy.cfg{,.back} etcd1# vi /etc/haproxy/haproxy.cfg etcd2# mv /etc/haproxy/haproxy.cfg{,.back} etcd2# vi /etc/haproxy/haproxy.cfg
Adicione estas opções de configuração para o HAProxy:
global user haproxy group haproxy defaults mode http log global retries 2 timeout connect 3000ms timeout server 5000ms timeout client 5000ms frontend kubernetes bind 192.168.0.1:6443 option tcplog mode tcp default_backend kubernetes-master-nodes backend kubernetes-master-nodes mode tcp balance roundrobin option tcp-check server k8s-master-0 192.168.0.5:6443 check fall 3 rise 2 server k8s-master-1 192.168.0.6:6443 check fall 3 rise 2
Como você pode ver, os dois serviços HAProxy compartilham o endereço IP - 192.168.0.1. Esse endereço IP virtual se moverá entre os servidores, portanto, seremos um pouco espertos e habilitaremos o parâmetro net.ipv4.ip_nonlocal_bind para permitir a ligação de serviços do sistema a um endereço IP não local.
Adicione esse recurso ao arquivo /etc/sysctl.conf :
etcd1# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1 etcd2# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1
Execute nos dois servidores:
sysctl -p
Execute também o HAProxy nos dois servidores:
etcd1# systemctl start haproxy etcd2# systemctl start haproxy
Verifique se o HAProxy está em execução e escutando o endereço IP virtual nos dois servidores:
etcd1# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy etcd2# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy
Hood! Agora instale o Heartbeat e configure esse IP virtual.
etcd1# apt-get -y install heartbeat && systemctl enable heartbeat etcd2# apt-get -y install heartbeat && systemctl enable heartbeat
Está na hora de criar vários arquivos de configuração: para o primeiro e o segundo servidores, eles serão basicamente os mesmos.
Primeiro, crie o arquivo /etc/ha.d/authkeys , neste arquivo o Heartbeat armazena dados para autenticação mútua. O arquivo deve ser o mesmo nos dois servidores:
# echo -n securepass | md5sum bb77d0d3b3f239fa5db73bdf27b8d29a etcd1# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a etcd2# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a
Este arquivo deve estar acessível apenas para a raiz:
etcd1# chmod 600 /etc/ha.d/authkeys etcd2# chmod 600 /etc/ha.d/authkeys
Agora crie o arquivo de configuração principal do Heartbeat nos dois servidores: para cada servidor, ele será um pouco diferente.
Crie /etc/ha.d/ha.cf :
etcd1
etcd1# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.3 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to log/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname
etcd2
etcd2# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.2 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to vlog/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname
Obtenha os parâmetros "node" para esta configuração executando uname -n nos dois servidores Etcd. Use também o nome da sua placa de rede em vez de ens18.
Por fim, você precisa criar o arquivo /etc/ha.d/haresources nesses servidores. Para os dois servidores, o arquivo deve ser o mesmo. Neste arquivo, definimos nosso endereço IP comum e determinamos qual nó é o mestre padrão:
etcd1# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1 etcd2# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1
Quando tudo estiver pronto, inicie os serviços de pulsação nos dois servidores e verifique se recebemos esse IP virtual declarado no nó etcd1:
etcd1# systemctl restart heartbeat etcd2# systemctl restart heartbeat etcd1# ip a ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff inet 192.168.0.2/24 brd 192.168.0.255 scope global ens18 valid_lft forever preferred_lft forever inet 192.168.0.1/24 brd 192.168.0.255 scope global secondary
Você pode verificar se o HAProxy está funcionando bem executando nc em 192.168.0.1 6443. Você deve ter expirado o tempo limite porque a API do Kubernetes ainda não está escutando no servidor. Mas isso significa que o HAProxy e o Heartbeat estão configurados corretamente.
# nc -v 192.168.0.1 6443 Connection to 93.158.95.90 6443 port [tcp/*] succeeded!
4. Preparação de nós para Kubernetes
O próximo passo é preparar todos os nós do Kubernetes. Você precisa instalar o Docker com alguns pacotes adicionais, adicionar o repositório Kubernetes e instalar os pacotes kubelet , kubeadm , kubectl . Essa configuração é a mesma para todos os nós do Kubernetes (mestre, trabalhadores, etc.)
A principal vantagem do Kubeadm é que não há muito software adicional necessário. Instale o kubeadm em todos os hosts - e use-o; pelo menos gere certificados de autoridade de certificação.
Instale o Docker em todos os nós:
Update the apt package index # apt-get update Install packages to allow apt to use a repository over HTTPS # apt-get -y install \ apt-transport-https \ ca-certificates \ curl \ gnupg2 \ software-properties-common Add Docker's official GPG key # curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add - Add docker apt repository # apt-add-repository \ "deb [arch=amd64] https://download.docker.com/linux/debian \ $(lsb_release -cs) \ stable" Install docker-ce. # apt-get update && apt-get -y install docker-ce Check docker version # docker -v Docker version 18.09.0, build 4d60db4
Depois disso, instale os pacotes Kubernetes em todos os nós:
kubeadm : comando para carregar o cluster.kubelet : um componente que é executado em todos os computadores do cluster e executa ações como iniciar fogões e contêineres.kubectl comando kubectl : util para se comunicar com o cluster.- kubectl - à vontade; Costumo instalá-lo em todos os nós para executar alguns comandos do Kubernetes para depuração.
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository # cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install packages # apt-get update && apt-get install -y kubelet kubeadm kubectl Hold back packages # apt-mark hold kubelet kubeadm kubectl Check kubeadm version # kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.1", GitCommit:"eec55b9dsfdfgdfgfgdfgdfgdf365bdd920", GitTreeState:"clean", BuildDate:"2018-12-13T10:36:44Z", GoVersion:"go1.11.2", Compiler:"gc", Platform:"linux/amd64"}
Após instalar o kubeadm e outros pacotes, não se esqueça de desativar o swap.
# swapoff -a # sed -i '/ swap / s/^/#/' /etc/fstab
Repita a instalação nos nós restantes. Os pacotes de software são os mesmos para todos os nós no cluster e apenas a seguinte configuração determinará as funções que eles receberão posteriormente.
5. Configure o HA Etcd Cluster
Assim, após concluir os preparativos, configuraremos o cluster Kubernetes. O primeiro bloco será o cluster HA Etcd, que também é configurado usando a ferramenta kubeadm.
Antes de começar, verifique se todos os nós etcd se comunicam pelas portas 2379 e 2380. Além disso, você precisa configurar o acesso ssh entre eles para usar o scp .
Vamos começar com o primeiro nó etcd e depois copiar todos os certificados e arquivos de configuração necessários para os outros servidores.
Em todos os nós etcd , você precisa adicionar um novo arquivo de configuração do systemd para a unidade kubelet com uma prioridade mais alta:
etcd-nodes# cat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf [Service] ExecStart= ExecStart=/usr/bin/kubelet --address=127.0.0.1 --pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true Restart=always EOF etcd-nodes# systemctl daemon-reload etcd-nodes# systemctl restart kubelet
Depois, passaremos o ssh para o primeiro nó etcd - vamos usá-lo para gerar todas as configurações necessárias do kubeadm para cada nó etcd e depois copiá-las.
# Export all our etcd nodes IP's as variables etcd1# export HOST0=192.168.0.2 etcd1# export HOST1=192.168.0.3 etcd1# export HOST2=192.168.0.4 # Create temp directories to store files for all nodes etcd1# mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/ etcd1# ETCDHOSTS=(${HOST0} ${HOST1} ${HOST2}) etcd1# NAMES=("infra0" "infra1" "infra2") etcd1# for i in "${!ETCDHOSTS[@]}"; do HOST=${ETCDHOSTS[$i]} NAME=${NAMES[$i]} cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml apiVersion: "kubeadm.k8s.io/v1beta1" kind: ClusterConfiguration etcd: local: serverCertSANs: - "${HOST}" peerCertSANs: - "${HOST}" extraArgs: initial-cluster: ${NAMES[0]}=https://${ETCDHOSTS[0]}:2380,${NAMES[1]}=https://${ETCDHOSTS[1]}:2380,${NAMES[2]}=https://${ETCDHOSTS[2]}:2380 initial-cluster-state: new name: ${NAME} listen-peer-urls: https://${HOST}:2380 listen-client-urls: https://${HOST}:2379 advertise-client-urls: https://${HOST}:2379 initial-advertise-peer-urls: https://${HOST}:2380 EOF done
Agora crie a autoridade de certificação principal usando o kubeadm
etcd1# kubeadm init phase certs etcd-ca
Este comando criará dois arquivos ca.crt e ca.key no diretório / etc / kubernetes / pki / etcd / .
etcd1# ls /etc/kubernetes/pki/etcd/ ca.crt ca.key
Agora vamos gerar certificados para todos os nós etcd :
### Create certificates for the etcd3 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST2}/ ### cleanup non-reusable certificates etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the etcd2 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST1}/ ### cleanup non-reusable certificates again etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the this local node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1 #kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml # No need to move the certs because they are for this node # clean up certs that should not be copied off this host etcd1# find /tmp/${HOST2} -name ca.key -type f -delete etcd1# find /tmp/${HOST1} -name ca.key -type f -delete
Em seguida, copie os certificados e configurações do kubeadm para os nós etcd2 e etcd3 .
Primeiro gere um par de chaves ssh no etcd1 e adicione a parte pública aos nós etcd2 e 3 . Neste exemplo, todos os comandos são executados em nome de um usuário que possui todos os direitos no sistema.
etcd1# scp -r /tmp/${HOST1}/* ${HOST1}: etcd1# scp -r /tmp/${HOST2}/* ${HOST2}: ### login to the etcd2 or run this command remotely by ssh etcd2# cd /root etcd2# mv pki /etc/kubernetes/ ### login to the etcd3 or run this command remotely by ssh etcd3# cd /root etcd3# mv pki /etc/kubernetes/
Antes de iniciar o cluster etcd, verifique se os arquivos existem em todos os nós:
Lista de arquivos necessários no etcd1 :
/tmp/192.168.0.2 └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── ca.key ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Para o nó etcd2, é o seguinte:
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
E o último nó é etcd3 :
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Quando todos os certificados e configurações estão em vigor, criamos manifestos. Em cada nó, execute o comando kubeadm - para gerar um manifesto estático para o cluster etcd :
etcd1# kubeadm init phase etcd local --config=/tmp/192.168.0.2/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml
Agora o cluster etcd - em teoria - está configurado e íntegro. Verifique executando o seguinte comando no nó etcd1:
etcd1# docker run --rm -it \ --net host \ -v /etc/kubernetes:/etc/kubernetes quay.io/coreos/etcd:v3.2.24 etcdctl \ --cert-file /etc/kubernetes/pki/etcd/peer.crt \ --key-file /etc/kubernetes/pki/etcd/peer.key \ --ca-file /etc/kubernetes/pki/etcd/ca.crt \ --endpoints https://192.168.0.2:2379 cluster-health ### status output member 37245675bd09ddf3 is healthy: got healthy result from https://192.168.0.3:2379 member 532d748291f0be51 is healthy: got healthy result from https://192.168.0.4:2379 member 59c53f494c20e8eb is healthy: got healthy result from https://192.168.0.2:2379 cluster is healthy
O cluster etcd aumentou, então siga em frente.
6. Configurando nós principais e de trabalho
Configure os nós principais do nosso cluster - copie esses arquivos do primeiro nó etcd para o primeiro nó principal:
etcd1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.key 192.168.0.5:
Em seguida, vá ssh para o nó principal master1 e crie o arquivo kubeadm-config.yaml com o seguinte conteúdo:
master1# cd /root && vi kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta1 kind: ClusterConfiguration kubernetesVersion: stable apiServer: certSANs: - "192.168.0.1" controlPlaneEndpoint: "192.168.0.1:6443" etcd: external: endpoints: - https://192.168.0.2:2379 - https://192.168.0.3:2379 - https://192.168.0.4:2379 caFile: /etc/kubernetes/pki/etcd/ca.crt certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
Mova os certificados e chaves copiados anteriormente para o diretório apropriado no nó master1, como na descrição da configuração.
master1# mkdir -p /etc/kubernetes/pki/etcd/ master1# cp /root/ca.crt /etc/kubernetes/pki/etcd/ master1# cp /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ master1# cp /root/apiserver-etcd-client.key /etc/kubernetes/pki/
Para criar o primeiro nó principal, faça:
master1# kubeadm init --config kubeadm-config.yaml
Se todas as etapas anteriores forem concluídas corretamente, você verá o seguinte:
You can now join any number of machines by running the following on each node as root: kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6
Copie esta saída de inicialização do kubeadm para qualquer arquivo de texto; usaremos esse token no futuro quando anexarmos o segundo nó principal e os nós de trabalho ao nosso cluster.
Eu já disse que o cluster Kubernetes usará algum tipo de rede de sobreposição para lareiras e outros serviços, portanto, neste ponto, você precisa instalar algum tipo de plugin CNI. Eu recomendo o plugin Weave CNI . A experiência demonstrou que é mais útil e menos problemática, mas você pode escolher outro, por exemplo, o Calico.
Instalando o plug-in de rede Weave no primeiro nó principal:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')" The connection to the server localhost:8080 was refused - did you specify the right host or port? serviceaccount/weave-net created clusterrole.rbac.authorization.k8s.io/weave-net created clusterrolebinding.rbac.authorization.k8s.io/weave-net created role.rbac.authorization.k8s.io/weave-net created rolebinding.rbac.authorization.k8s.io/weave-net created daemonset.extensions/weave-net created
Aguarde um momento e, em seguida, digite o seguinte comando para verificar se as lareiras dos componentes são iniciadas:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 6m25s coredns-86c58d9df4-xj98p 1/1 Running 0 6m25s kube-apiserver-master1 1/1 Running 0 5m22s kube-controller-manager-master1 1/1 Running 0 5m41s kube-proxy-8ncqw 1/1 Running 0 6m25s kube-scheduler-master1 1/1 Running 0 5m25s weave-net-lvwrp 2/2 Running 0 78s
- É recomendável anexar novos nós do plano de controle somente após a inicialização do primeiro nó.
Para verificar o status do cluster, faça:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 11m v1.13.1
Ótimo! O primeiro nó principal subiu. Agora está pronto e concluiremos a criação do cluster Kubernetes - adicionaremos um segundo nó mestre e os nós em funcionamento.
Para adicionar um segundo nó mestre, crie uma chave ssh em master1 e adicione a parte pública em master2 . Execute um logon de teste e copie alguns arquivos do primeiro nó mestre para o segundo:
master1# scp /etc/kubernetes/pki/ca.crt 192.168.0.6: master1# scp /etc/kubernetes/pki/ca.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.pub 192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.key @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.key @192.168.0.6: master1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.6:etcd-ca.crt master1# scp /etc/kubernetes/admin.conf 192.168.0.6: ### Check that files was copied well master2# ls /root admin.conf ca.crt ca.key etcd-ca.crt front-proxy-ca.crt front-proxy-ca.key sa.key sa.pub
No segundo nó principal, mova os certificados e chaves copiados anteriormente para os diretórios apropriados:
master2# mkdir -p /etc/kubernetes/pki/etcd mv /root/ca.crt /etc/kubernetes/pki/ mv /root/ca.key /etc/kubernetes/pki/ mv /root/sa.pub /etc/kubernetes/pki/ mv /root/sa.key /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.key /etc/kubernetes/pki/ mv /root/front-proxy-ca.crt /etc/kubernetes/pki/ mv /root/front-proxy-ca.key /etc/kubernetes/pki/ mv /root/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt mv /root/admin.conf /etc/kubernetes/admin.conf
Conecte o segundo nó principal ao cluster. Para fazer isso, você precisa da saída do comando connection, que anteriormente foi passado para nós pelo kubeadm init no primeiro nó.
Execute o nó principal master2 :
master2# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6 --experimental-control-plane
- Você precisa adicionar o
--experimental-control-plane . Ele automatiza a anexação de dados mestre a um cluster. Sem esse sinalizador, o nó de trabalho usual será simplesmente adicionado.
Aguarde um pouco até o nó ingressar no cluster e verifique o novo estado do cluster:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 32m v1.13.1 master2 Ready master 46s v1.13.1
Verifique também se todos os pods de todos os nós principais são iniciados normalmente:
master1# kubectl — kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 46m coredns-86c58d9df4-xj98p 1/1 Running 0 46m kube-apiserver-master1 1/1 Running 0 45m kube-apiserver-master2 1/1 Running 0 15m kube-controller-manager-master1 1/1 Running 0 45m kube-controller-manager-master2 1/1 Running 0 15m kube-proxy-8ncqw 1/1 Running 0 46m kube-proxy-px5dt 1/1 Running 0 15m kube-scheduler-master1 1/1 Running 0 45m kube-scheduler-master2 1/1 Running 0 15m weave-net-ksvxz 2/2 Running 1 15m weave-net-lvwrp 2/2 Running 0 41m
Ótimo! Estamos quase terminando a configuração de cluster do Kubernetes. E a última coisa a fazer é adicionar os três nós de trabalho que preparamos anteriormente.
Digite os nós de trabalho e execute o comando kubeadm join sem o --experimental-control-plane .
worker1-3# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6
Verifique o estado do cluster novamente:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 1h30m v1.13.1 master2 Ready master 1h59m v1.13.1 worker1 Ready <none> 1h8m v1.13.1 worker2 Ready <none> 1h8m v1.13.1 worker3 Ready <none> 1h7m v1.13.1
Como você pode ver, temos um cluster de alta disponibilidade do Kubernetes com dois nós principais e três nós de trabalho. Ele é construído com base no cluster etcd HA com um balanceador de carga à prova de falhas na frente dos nós principais. Parece muito bom para mim.
7. Configurando o gerenciamento de cluster remoto
Outra ação que ainda deve ser considerada nesta primeira parte do artigo é configurar o utilitário kubectl remoto para gerenciar o cluster. Anteriormente, executamos todos os comandos do nó mestre master1 , mas isso é adequado apenas pela primeira vez - ao configurar o cluster. Seria bom configurar um nó de controle externo. Você pode usar um laptop ou outro servidor para isso.
Efetue login neste servidor e execute:
Add the Google repository key control# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository control# cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install kubectl control# apt-get update && apt-get install -y kubectl In your user home dir create control# mkdir ~/.kube Take the Kubernetes admin.conf from the master1 node control# scp 192.168.0.5:/etc/kubernetes/admin.conf ~/.kube/config Check that we can send commands to our cluster control# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 6h58m v1.13.1 master2 Ready master 6h27m v1.13.1 worker1 Ready <none> 5h36m v1.13.1 worker2 Ready <none> 5h36m v1.13.1 worker3 Ready <none> 5h36m v1.13.1
Ok, agora vamos executar um teste em nosso cluster e verificar como ele funciona.
control# kubectl create deployment nginx --image=nginx deployment.apps/nginx created control# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-5c7588df-6pvgr 1/1 Running 0 52s
Parabéns! Você acabou de implantar o Kubernetes. E isso significa que seu novo cluster de alta disponibilidade está pronto. De fato, o processo de configuração de um cluster Kubernetes usando o kubeadm é bastante simples e rápido.
Na próxima parte do artigo, adicionaremos armazenamento interno configurando o GlusterFS em todos os nós em funcionamento, configurando um balanceador de carga interno para o cluster Kubernetes e executando também alguns testes de estresse, desconectando alguns nós e verificando a estabilidade do cluster.
Posfácio
Sim, trabalhando neste exemplo, você encontrará vários problemas. Não precisa se preocupar: para desfazer as alterações e retornar os nós ao seu estado original, basta executar a redefinição do kubeadm - as alterações feitas pelo kubeadm anteriormente serão redefinidas e você poderá configurar novamente. Além disso, não esqueça de verificar o status dos contêineres do Docker nos nós do cluster - verifique se todos eles iniciam e funcionam sem erros. Para obter mais informações sobre contêineres danificados, use o comando docker logs containerid .
Isso é tudo por hoje. Boa sorte