Olá pessoal! Apresento a você uma tradução de um artigo do Analytics Vidhya com uma visão geral dos eventos de AI / ML nas tendências de 2018 e 2019. O material é bastante grande, por isso é dividido em 2 partes. Espero que o artigo interesse não apenas especialistas especializados, mas também os interessados no tópico da IA. Boa leitura!
1. Introdução
Nos últimos anos, os entusiastas da IA e os profissionais de aprendizado de máquina passaram em busca de um sonho. Essas tecnologias deixaram de ser nicho, tornaram-se populares e já estão afetando a vida de milhões de pessoas no momento. Os ministérios da IA foram criados em diferentes países [
mais detalhes aqui - aprox. por.] e orçamentos são alocados para acompanhar esta corrida.
O mesmo vale para profissionais de ciência de dados. Há alguns anos, você pode se sentir à vontade conhecendo algumas ferramentas e truques, mas esse tempo já passou. O número de eventos recentes em ciência de dados e a quantidade de conhecimento necessária para acompanhar os tempos nessa área são surpreendentes.
Decidi dar um passo atrás e analisar os desenvolvimentos em algumas áreas-chave no campo da inteligência artificial do ponto de vista dos especialistas em ciência de dados. Quais fugas ocorreram? O que aconteceu em 2018 e o que esperar em 2019? Leia este artigo para obter respostas!
PS Como em qualquer previsão, abaixo estão minhas conclusões pessoais baseadas em tentativas de combinar fragmentos individuais em todo o cenário. Se o seu ponto de vista for diferente do meu, ficarei feliz em saber sua opinião sobre o que mais pode mudar na ciência de dados em 2019.
As áreas que abordaremos neste artigo são:
- Processo de linguagem natural (PNL)
- Visão computacional
- Ferramentas e bibliotecas
- Aprendizado por Reforço
- Questões éticas em IA
Processamento de linguagem natural (PNL)
Forçar máquinas a analisar palavras e frases sempre parecia um sonho. Existem muitas nuances e recursos em idiomas que às vezes são difíceis de entender, mesmo para as pessoas, mas 2018 foi um verdadeiro ponto de virada para a PNL.
Assistimos a um grande avanço após o outro: ULMFiT, ELMO, OpenAl Transformer, Google BERT, e esta não é uma lista completa. A aplicação bem-sucedida do aprendizado de transferência (a arte de aplicar modelos pré-treinados aos dados) abriu as portas para a PNL em uma variedade de tarefas.
Transferir aprendizado - permite adaptar um modelo / sistema pré-treinado à sua tarefa específica usando uma quantidade relativamente pequena de dados.
Vejamos alguns desses principais desenvolvimentos com mais detalhes.
ULMFiT
Desenvolvido por Sebastian Ruder e Jeremy Howard (fast.ai), o ULMFiT foi a primeira estrutura a receber transferência de aprendizado este ano. Para os não iniciados, o acrônimo ULMFiT significa "Universal Language Model Fine-Tuning". Jeremy e Sebastian adicionaram, com razão, a palavra "universal" ao ULMFiT - essa estrutura pode ser aplicada a quase todas as tarefas da PNL!
O melhor de ULMFiT é que você não precisa treinar modelos do zero! Os pesquisadores já fizeram o mais difícil para você - participe e inscreva-se em seus projetos. O ULMFiT superou outros métodos em seis tarefas de classificação de texto.
Você pode
ler o tutorial de Pratek Joshi [Pateek Joshi - aprox. trad.] sobre como começar a usar o ULMFiT para qualquer tarefa de classificação de texto.
ELMo
Adivinha o que significa a abreviação ELMo? Acrônimo para Casamentos de modelos de idiomas [anexos de modelos de idiomas - aprox. trans.]. E o ELMo chamou a atenção da comunidade de ML logo após o lançamento.
O ELMo usa modelos de linguagem para receber anexos para cada palavra e também leva em consideração o contexto em que a palavra se encaixa em uma frase ou parágrafo. O contexto é um aspecto crítico da PNL, no qual a maioria dos desenvolvedores falhou anteriormente. O ELMo usa LSTMs bidirecionais para criar anexos.
A memória de longo prazo (LSTM) é um tipo de arquitetura de redes neurais recorrentes proposta em 1997 por Sepp Hochreiter e Jürgen Schmidhuber. Como a maioria das redes neurais recorrentes, uma rede LSTM é universal no sentido de que, com um número suficiente de elementos de rede, pode realizar qualquer cálculo de que um computador comum é capaz, o que requer uma matriz de peso apropriada que possa ser considerada como um programa. Diferentemente das redes neurais recorrentes tradicionais, a rede LSTM é bem adaptada para o treinamento nos problemas de classificação, processamento e previsão de séries temporais nos casos em que eventos importantes são separados por intervalos de tempo com duração e limites indefinidos.
- fonte. Wikipedia
Como o ULMFiT, o ELMo melhora significativamente a produtividade na solução de um grande número de tarefas de PNL, como analisar o humor do texto ou responder a perguntas.
BERT do Google
Muitos especialistas observam que o lançamento do BERT marcou o início de uma nova era na PNL. Após o ULMFiT e o ELMo, o BERT assumiu a liderança, demonstrando alto desempenho. Como o anúncio original afirma: "O BERT é conceitualmente simples e empiricamente poderoso".
O BERT mostrou excelentes resultados em 11 tarefas de PNL! Veja os resultados nos testes do SQuAD:
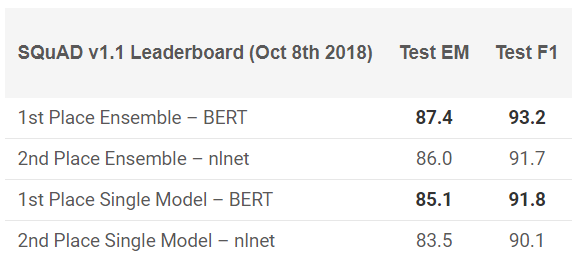
Quer experimentar? Você pode usar a reimplementação no código PyTorch ou TensorFlow do Google e tentar repetir o resultado em sua máquina.
Facebook PyText
Como o Facebook pode ficar longe desta corrida? A empresa oferece sua própria estrutura de NLP de código aberto chamada PyText. De acordo com um estudo publicado pelo Facebook, o PyText aumentou a precisão dos modelos de conversação em 10% e reduziu o tempo de treinamento.
O PyText está na verdade por trás de vários produtos do Facebook, como o Messenger. Portanto, trabalhar com ele adicionará um bom ponto ao seu portfólio e um conhecimento inestimável que você certamente obterá.
Você pode tentar você mesmo,
baixar o código do GitHub .
Google duplex
É difícil acreditar que você nunca ouviu falar do Google Duplex. Aqui está uma demonstração que por muito tempo brilhou nas manchetes:
Como este é um produto do Google, há poucas chances de que mais cedo ou mais tarde o código seja publicado para todos. Obviamente, essa demonstração levanta muitas questões: de questões éticas a questões de privacidade, mas falaremos sobre isso mais tarde. Por enquanto, apenas aproveite o quão longe chegamos com a ML nos últimos anos.
Tendências da PNL em 2019
Quem melhor que o próprio Sebastian Ruder pode dar uma idéia de para onde a PNL está indo em 2019? Aqui estão suas descobertas:
- O uso de modelos de investimento em idiomas pré-treinados será generalizado; modelos avançados sem suporte serão muito raros.
- Aparecerão visualizações pré-treinadas que podem codificar informações especializadas que complementam os anexos do modelo de idioma. Poderemos agrupar diferentes tipos de apresentações pré-treinadas, dependendo dos requisitos da tarefa.
- Mais trabalhos aparecerão no campo de aplicativos multilíngues e modelos multilíngues. Em particular, contando com a incorporação de palavras entre idiomas, veremos o surgimento de representações interlínguas pré-treinadas e profundas.
Visão computacional

Hoje, a visão computacional é a área mais popular no campo da aprendizagem profunda. Parece que os primeiros frutos da tecnologia já foram obtidos e estamos no estágio de desenvolvimento ativo. Independentemente da imagem ou do vídeo, vemos o surgimento de muitas estruturas e bibliotecas que resolvem facilmente os problemas da visão computacional.
Aqui está minha lista das melhores soluções que podem ser vistas este ano.
BigGANs Out
Ian Goodfellow projetou as GANs em 2014, e o conceito gerou uma ampla variedade de aplicações. Ano após ano, observamos como o conceito original foi finalizado para uso em casos reais. Mas uma coisa permaneceu inalterada até este ano - as imagens geradas por computador eram facilmente distinguíveis. Uma certa inconsistência sempre aparecia no quadro, o que tornava a diferença muito óbvia.
Nos últimos meses, surgiram mudanças nessa direção e, com a
criação do BigGAN , esses problemas podem ser resolvidos de uma vez por todas. Veja as imagens geradas por este método:

Sem um microscópio, é difícil dizer o que há de errado com essas imagens. É claro que todos decidirão por si mesmos, mas não há dúvida de que o GAN muda a maneira como percebemos as imagens digitais (e o vídeo).
Para referência: esses modelos foram treinados primeiro no conjunto de dados ImageNet e depois no JFT-300M para demonstrar que esses modelos são bem transferidos de um conjunto de dados para outro. Aqui está um
link para uma página da lista de correspondência da GAN explicando como visualizar e entender a GAN.
Model Fast.ai treinado no ImageNet em 18 minutos
Esta é uma implementação muito legal. Existe uma crença generalizada de que, para executar tarefas de aprendizado profundo, você precisará de terabytes de dados e grandes recursos de computação. O mesmo vale para o treinamento do modelo a partir do zero nos dados do ImageNet. Muitos de nós pensamos da mesma maneira antes de algumas pessoas no fast.ai não conseguirem provar o contrário de todos.
O modelo deles deu 93% de precisão com impressionantes 18 minutos. O hardware usado,
descrito em detalhes
em seu blog , consistia em 16 instâncias públicas da nuvem da AWS, cada uma com 8 GPUs NVIDIA V100. Eles criaram um algoritmo usando as bibliotecas fast.ai e PyTorch.
O custo total da montagem foi de apenas US $ 40! Jeremy descreveu suas
abordagens e métodos em mais detalhes
aqui . Esta é uma vitória comum!
vid2vid da NVIDIA
Nos últimos 5 anos, o processamento de imagens fez grandes progressos, mas e o vídeo? Os métodos de conversão de um quadro estático para um dinâmico se mostraram um pouco mais complicados do que o esperado. Você pode tirar uma sequência de quadros de um vídeo e prever o que acontecerá no próximo quadro? Tais estudos foram feitos antes, mas as publicações eram vagas, na melhor das hipóteses.

A NVIDIA decidiu tornar sua decisão publicamente disponível no início deste ano [2018 - aprox. por.], que foi avaliada positivamente pela sociedade. O objetivo do vid2vid é derivar uma função de exibição de um determinado vídeo de entrada para criar um vídeo de saída que transmita o conteúdo do vídeo de entrada com uma precisão incrível.
Você pode tentar a implementação no PyTorch, leve-o
ao GitHub aqui .
Tendências de visão de máquina para 2019
Como mencionei anteriormente, em 2019 é mais provável que vejamos o desenvolvimento das tendências de 2018, em vez de novos avanços: carros autônomos, algoritmos de reconhecimento de rosto, realidade virtual e muito mais. Você pode discordar de mim se tiver um ponto de vista ou acréscimo diferente, compartilhá-lo conosco, o que mais podemos esperar em 2019?
A questão dos drones, na pendência da aprovação de políticos e do governo, pode finalmente ter um sinal verde nos Estados Unidos (a Índia está muito atrasada nesse assunto). Pessoalmente, eu gostaria que mais pesquisas fossem feitas em cenários do mundo real. Conferências como
CVPR e
ICML fornecem uma boa cobertura dos últimos desenvolvimentos nesta área, mas a proximidade dos projetos da realidade não é muito clara.
“Resposta visual às perguntas” e “sistemas de diálogo visual” podem finalmente sair com uma estreia muito esperada. Esses sistemas não têm capacidade de generalização, mas espera-se que em breve veremos uma abordagem multimodal integrada.
O autotreinamento veio à tona este ano. Aposto que no próximo ano ele será aplicado em um número muito maior de estudos. Essa é uma direção muito legal: os sinais são determinados diretamente a partir dos dados de entrada, em vez de perder tempo marcando manualmente as imagens. Vamos manter os dedos cruzados!