Olá% habrauser%!
Hoje, quero falar sobre um excelente, na minha opinião, estrutura de microsserviço
Moleculer .

Inicialmente, essa estrutura foi escrita em Node.js, mas posteriormente apareceu em portas em outras linguagens como Java, Go, Python e .NET e, provavelmente, outras implementações
aparecerão em um futuro próximo. Nós o usamos na produção de vários produtos há cerca de um ano e é difícil descrever com palavras como ele nos pareceu abençoado depois de usar o Seneca e nossas motos. Temos tudo o que precisamos imediatamente: coletando métricas, armazenamento em cache, balanceamento, tolerância a falhas, transportes selecionados, validação de parâmetros, registro em log, declarações concisas de métodos, várias formas de interação entre serviços, mixins e muito mais. E agora em ordem.
1. Introdução
A estrutura, de fato, consiste em três componentes (na verdade, não, mas você aprenderá mais sobre isso abaixo).
Transportador
Responsável pela descoberta de serviços e comunicação entre eles. Essa é uma interface que você pode implementar por conta própria, se desejar, ou pode usar implementações prontas que fazem parte da própria estrutura. 7 transportes estão disponíveis na caixa: TCP, Redis, AMQP, MQTT, NATS, NATS Streaming, Kafka.
Aqui você pode ver mais. Usamos o transporte Redis, mas planejamos mudar para o TCP com sua saída do estado experimental.
Na prática, ao escrever código, não interagimos com esse componente. Você só precisa saber o que ele é. O transporte usado é especificado na configuração. Assim, para mudar de um transporte para outro, basta alterar a configuração. Só isso. Algo assim:
Os dados, por padrão, são fornecidos no formato JSON. Mas você pode usar qualquer coisa: Avro, MsgPack, Notepack, ProtoBuf, Thrift, etc.
Serviço
A classe que herdamos ao escrever nossos microsserviços.
Aqui está o serviço mais simples sem métodos, que, no entanto, será detectado por outros serviços:
Corretor de serviços
O núcleo da estrutura.

Exagerando, podemos dizer que essa é uma camada entre transporte e serviço. Quando um serviço deseja interagir com outro serviço de alguma forma, ele o faz através de um broker (exemplos serão fornecidos abaixo). O broker está envolvido no balanceamento de carga (suporta várias estratégias, incluindo as personalizadas, por padrão - round-robin), levando em consideração os serviços ao vivo, os métodos disponíveis nesses serviços, etc. Para isso, o ServiceBroker usa outro componente sob o capô - o Registro, mas eu não vou me debruçar sobre ele, não precisamos dele para conhecimento.
Ter um corretor nos dá uma coisa extremamente conveniente. Agora vou tentar explicar, mas vou ter que me afastar um pouco. No contexto da estrutura, existe um nó. Em termos simples, um nó é um processo no sistema operacional (ou seja, o que acontece quando inserimos “node index.js” no console, por exemplo). Cada nó é um ServiceBroker com um conjunto de um ou mais microsserviços. Sim, você ouviu direito. Podemos construir nossa pilha de serviços como nosso coração desejar. Por que isso é conveniente? Para o desenvolvimento, iniciamos um nó no qual todos os microsserviços são iniciados ao mesmo tempo (1 cada), apenas um processo no sistema com a capacidade de conectar muito facilmente o hotreload, por exemplo. Em produção - um nó separado para cada instância do serviço. Bem, ou uma mistura, quando parte dos serviços em um nó, parte em outro e assim por diante (embora eu não saiba por que fazer isso, apenas para entender que você também pode fazer isso).
É assim que nosso index.js se parece const { resolve } = require('path'); const { ServiceBroker } = require('moleculer'); const config = require('./moleculer.config.js'); const { SERVICES, NODE_ENV, } = process.env; const broker = new ServiceBroker(config); broker.loadServices( resolve(__dirname, 'services'), SERVICES ? `*/@(${SERVICES.split(',').map(i => i.trim()).join('|')}).service.js` : '*/*.service.js', ); broker.start().then(() => { if (NODE_ENV === 'development') { broker.repl(); } });
Se não houver variável de ambiente, todos os serviços do diretório serão carregados, caso contrário, por máscara. A propósito, broker.repl () é outro recurso conveniente da estrutura. Ao iniciar no modo de desenvolvimento, ali mesmo, no console, temos uma interface para chamar métodos (o que você faria, por exemplo, através de carteiro em seu microsserviço que se comunica via http), só que aqui é muito mais conveniente: a interface está no mesmo console onde eles começaram a npm.
Interação entre serviços
É realizado de três maneiras:
ligar
Mais comumente usado. Fez uma solicitação, recebeu uma resposta (ou erro).
Como mencionado acima, as chamadas são automaticamente equilibradas. Apenas aumentamos o número necessário de instâncias de serviço, e a própria estrutura fará o balanceamento.

emitir
Usada quando queremos apenas notificar outros serviços sobre um evento, mas não precisamos do resultado.
Outros serviços podem se inscrever neste evento e responder de acordo. Opcionalmente, o terceiro argumento, você pode definir explicitamente os serviços que estão disponíveis para receber esse evento.
O ponto importante é que o evento receberá apenas uma instância de cada tipo de serviço, ou seja, se tivermos 10 serviços de "correio" e 5 de "assinatura" inscritos nesse evento, na verdade, apenas duas cópias o receberão - um "correio" e uma "assinatura". Esquematicamente aparece assim:
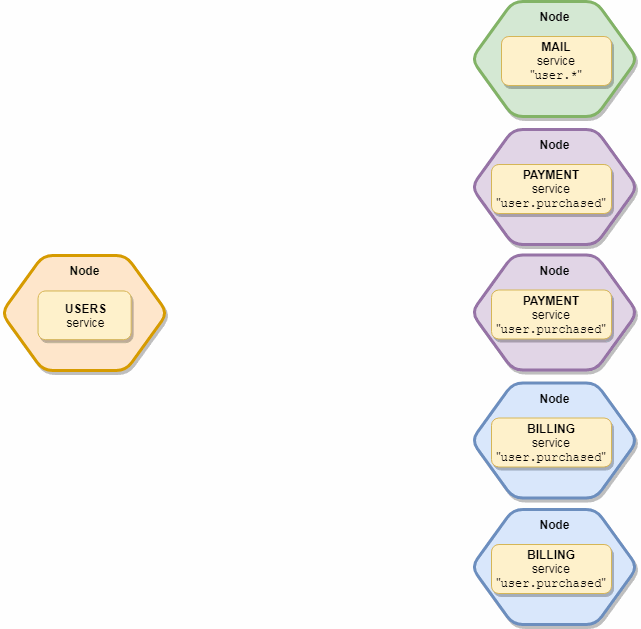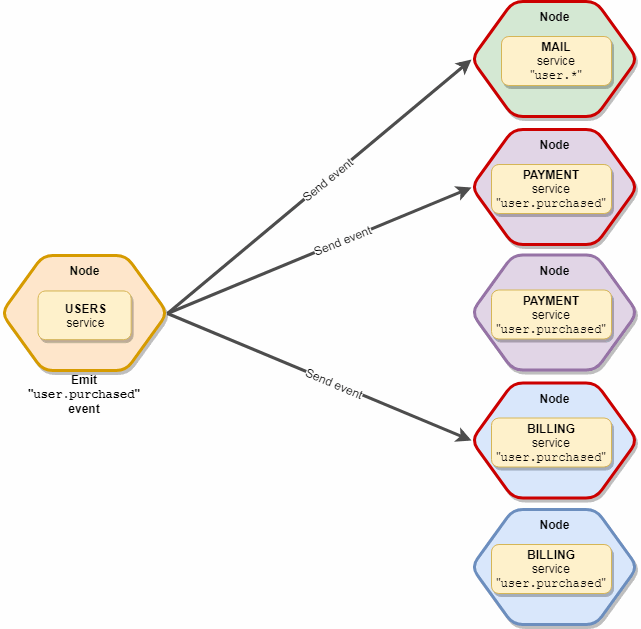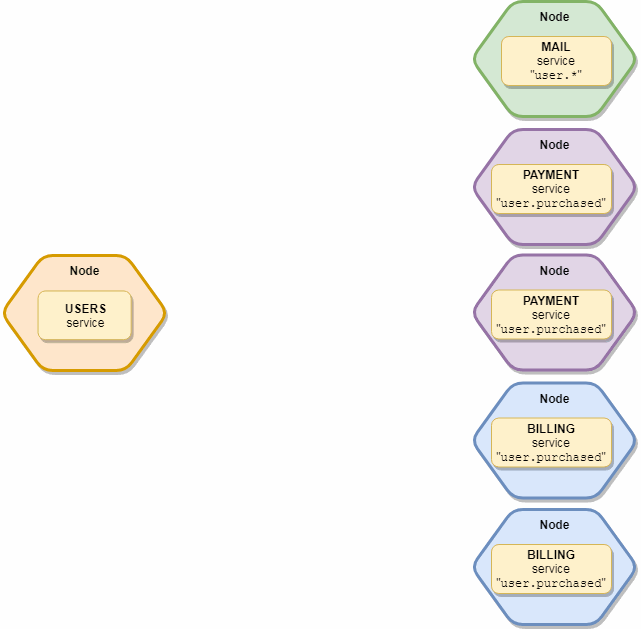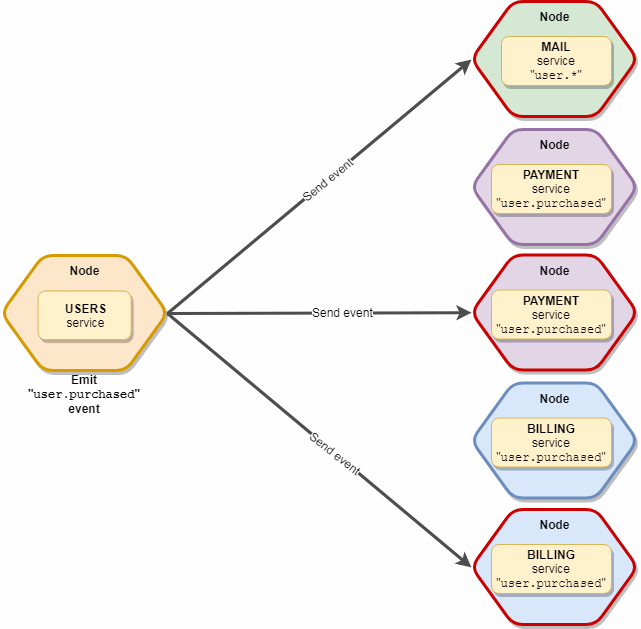
transmissão
O mesmo que emitir, mas sem restrições. Todos os 10 serviços de correio e 5 de assinatura participarão deste evento.
Validação de parâmetros
Por padrão, o
validador mais rápido é usado para validar os parâmetros, parece ser muito rápido. Mas nada impede o uso de outra, por exemplo, a mesma joi, se você precisar de uma validação mais avançada.
Quando escrevemos um serviço, herdamos da classe base Service, declaramos métodos com lógica de negócios, mas esses métodos são "privados", não podem ser chamados de fora (de outro serviço) até que desejemos explicitamente, declarando-os em seção de ações especiais durante a inicialização do serviço (métodos públicos de serviços no contexto da estrutura são chamados de ações).
Exemplo de uma declaração de método com validação module.exports = class JobService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'job', actions: { update: { params: { id: { type: 'number', convert: true }, name: { type: 'string', empty: false, optional: true }, data: { type: 'object', optional: true }, }, async handler(ctx) { return this.update(ctx.params); }, }, }, }); } async update({ id, name, data }) {
Mixins
Usado, por exemplo, para inicializar uma conexão com o banco de dados. Evite a duplicação de código de serviço para serviço.
Exemplo de mixin para inicializar uma conexão com Redis const Redis = require('ioredis'); module.exports = ({ key = 'redis', options } = {}) => ({ settings: { [key]: options, }, created() { this[key] = new Redis(this.settings[key]); }, async started() { await this[key].connect(); }, stopped() { this[key].disconnect(); }, });
Usando mixin no serviço const { Service, Errors } = require('moleculer'); const redis = require('../../mixins/redis'); const server = require('../../mixins/server'); const router = require('./router'); const { REDIS_HOST, REDIS_PORT, REDIS_PASSWORD, } = process.env; const redisOpts = { host: REDIS_HOST, port: REDIS_PORT, password: REDIS_PASSWORD, lazyConnect: true, }; module.exports = class AuthService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'auth', mixins: [redis({ options: redisOpts }), server({ router })], }); } }
Armazenamento em cache
As chamadas de método (ações) podem ser armazenadas em cache de várias maneiras: LRU, Memória, Redis. Opcionalmente, você pode especificar por quais chamadas de chave serão armazenadas em cache (por padrão, o hash do objeto é usado como uma chave de cache) e com o qual TTL.
Exemplo de declaração de método em cache module.exports = class InventoryService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'inventory', actions: { getInventory: { params: { steamId: { type: 'string', pattern: /^76\d{15}$/ }, appId: { type: 'number', integer: true }, contextId: { type: 'number', integer: true }, }, cache: { keys: ['steamId', 'appId', 'contextId'], ttl: 15, }, async handler(ctx) { return true; }, }, }, }); }
O método de armazenamento em cache é definido através da configuração do ServiceBroker.
Registo
Aqui, no entanto, tudo também é bastante simples. Há um bom logger interno que grava no console; é possível especificar a formatação personalizada. Nada impede o roubo de qualquer outro registrador popular, seja winston ou bunyan. Um manual detalhado está na
documentação . Pessoalmente, usamos o criador de logs incorporado, o formatador personalizado para algumas linhas de código que o spam no console JSON é simplesmente dividido no produto, após o qual eles entram no graylog usando o driver de log do docker.
Métricas
Se desejar, você pode coletar métricas para cada método e rastrear tudo em algum zipkin. Aqui
está a lista completa de exportadores disponíveis. Atualmente, existem cinco deles: Zipkin, Jaeger, Prometheus, Elastic, Console. Ele é configurado, como o cache, ao declarar um método (ação).
Exemplos de visualização do pacote elasticsearch + kibana usando o módulo
elastic-apm-node podem ser visualizados
neste link no Github.
A maneira mais fácil, é claro, é usar a opção de console. É assim:

Tolerância a falhas
A estrutura possui um disjuntor interno, controlado pelas configurações do ServiceBroker. Se algum serviço falhar e o número dessas falhas exceder um determinado limite, ele será marcado como não íntegro, as solicitações para ele serão severamente limitadas até que parem de cometer erros.
Como bônus, também existe um fallback ajustável individualmente para cada método (ação), caso presumamos que o método falhe e, por exemplo, envie dados em cache ou um stub.
Conclusão
A introdução dessa estrutura para mim tornou-se uma lufada de ar fresco, o que economizou uma enorme quantidade de estacas (exceto pelo fato de a arquitetura de microsserviços ser um grande problema) e o ciclismo, tornando a escrita do próximo microsserviço simples e transparente. Não há nada de supérfluo, é simples e muito flexível, e você pode escrever o primeiro serviço dentro de uma ou duas horas depois de ler a documentação. Ficarei feliz se este material for útil para você e em seu próximo projeto, você desejará experimentar esse milagre, como fizemos (e nunca o lamentamos ainda). Bom para todos!
Além disso, se você estiver interessado nessa estrutura, participe do bate-papo no Telegram -
@moleculerchat