
Entre a data dos cientistas, existem muitos holivares, e um deles diz respeito ao aprendizado de máquina competitivo. O sucesso do Kaggle realmente mostra a capacidade de um especialista em resolver tarefas típicas de trabalho? Arseny
arseny_info (líder da equipe de pesquisa e desenvolvimento @
WANNABY ,
Kaggle Master , mais tarde em
A. ) e Arthur
n01z3 (chefe do grupo Computer Vision @
X5 Retail Group ,
Kaggle Grandmaster , mais tarde em
N. ) escalou o holivar para um novo nível: em vez de outra discussão em eles pegaram microfones na sala de bate-papo e realizaram uma
discussão pública na reunião , com base na qual este artigo nasceu.
Métricas, kernels, cabeçalho
A:Gostaria de começar com o argumento esperado de que Kaggle não ensina a coisa mais importante no trabalho de uma data típica de um cientista - a declaração do problema. Uma tarefa definida corretamente já contém metade da solução, e muitas vezes essa metade é a mais difícil, e codificar algum modelo e treiná-lo é muito mais fácil. O Kaggle oferece uma tarefa de um mundo ideal - os dados estão prontos, a métrica está pronta, pega e treina.
Surpreendentemente, mesmo com isso, surgem problemas. Não é difícil encontrar muitos exemplos quando os "entusiastas" ficam confusos quando veem uma métrica desconhecida / incompreensível.
N:Sim, essa é a essência do kaggle. Os organizadores pensaram, formalizaram a tarefa, coletaram o conjunto de dados e determinaram a métrica. Mas se uma pessoa tem o início do pensamento crítico, a primeira coisa em que ela pensa é por que decidiu que a métrica escolhida ou o alvo proposto é ideal.
Participantes fortes geralmente redefinem a tarefa por conta própria e apresentam um objetivo melhor.
E quando descobriram a métrica, determinaram o alvo e coletaram os dados, otimizar a métrica é o que os praticantes de kagglers fazem melhor. Após cada competição, o cliente pode com grande confiança acreditar que os participantes mostraram o "teto" para o algoritmo ideal com velocidade máxima. E, para conseguir isso, os participantes experimentam várias abordagens e idéias diferentes, validando-as com iterações rápidas.
Essa abordagem é convertida diretamente em trabalhos bem-sucedidos em tarefas reais. Além disso, malabaristas experientes podem imediatamente imediatamente, intuitivamente ou a partir de uma experiência passada, selecionar uma lista de idéias que vale a pena tentar em primeiro lugar para obter o máximo lucro. E aqui todo o arsenal da comunidade kaggle vem em socorro: artigos, folga, fórum, núcleos.
 A:
A:Você mencionou "kernels", e eu tenho uma reclamação separada para eles. Muitas competições se transformaram em desenvolvimento orientado ao kernel. Não vou me concentrar em casos degenerados quando uma medalha de ouro poderia ser alcançada devido ao lançamento bem-sucedido de um script público. No entanto, mesmo em competições de aprendizado profundo, agora você pode obter algum tipo de medalha, quase sem escrever código. Você pode tomar várias decisões públicas, principalmente sem entender a distorção de alguns parâmetros, testar-se na tabela de classificação, calcular a média dos resultados e obter uma boa métrica.
Anteriormente, até sucessos moderados em competições de “fotos” (por exemplo, uma medalha de bronze, ou seja, chegar aos 10% mais altos da classificação final) mostraram que uma pessoa é capaz de algo - você tinha que escrever um pipeline normal pelo menos do começo ao fim , evite erros críticos. Agora, esses sucessos foram desvalorizados: o Kaggle está promovendo sua plataforma principal com poder e principal, o que diminui o limiar de entrada e permite que você experimente de alguma forma sem perceber o que é o quê.
 N:
N:A medalha de bronze nunca foi citada. Este é o nível de "lancei algo lá e ele aprendeu". E não é tão ruim.
Diminuir o nível de entrada devido aos kernels e a presença de GPUs neles cria concorrência e aumenta o nível geral de conhecimento. Se há um ano era possível obter ouro usando a baunilha Unet, agora você não pode fazer isso sem mais de 5 modificações e truques. E esses truques funcionam não apenas no Kaggle, mas também além. Por exemplo, em
Aerial-Inria, nossos caras do ods.ai se levantaram e mostraram o estado da arte simplesmente com seus poderosos pipelines de segmentação desenvolvidos pela Kaggle. Isso mostra a aplicabilidade de tais abordagens no trabalho real.
 A:
A:O problema é que
em tarefas reais não há cabeçalho . Normalmente, não há um número único que mostre que tudo deu errado ou, inversamente, está tudo bem. Muitas vezes, existem vários números, eles se contradizem, vinculá-los a um sistema é outro desafio.
N:Mas as métricas são de alguma forma importantes. Eles mostram um desempenho objetivo do algoritmo. Sem algoritmos com métricas acima de algum limite utilizável, é impossível criar serviços baseados em ML.
A:Mas somente se eles refletirem honestamente o estado do produto, o que nem sempre é o caso. Acontece que você precisa arrastar a métrica para um mínimo de higiene, e
outras melhorias da métrica "técnica" não correspondem mais às melhorias do produto (o usuário não percebe essas +0,01 UI), a correlação entre a métrica e as sensações do usuário é perdida.
Além disso, os métodos clássicos de aumento da métrica não são aplicáveis no trabalho normal. Não é necessário procurar "rostos", não é necessário reproduzir a marcação e encontrar as respostas corretas através de hashes de arquivos.

Validação confiável e conjuntos de modelos ousados
N:O Kaggle ensina a validar corretamente, inclusive devido à presença de rostos. Você precisa ser muito claro sobre como a velocidade na tabela de classificação melhorou. Também é
necessário criar uma validação local representativa que reflita a parte privada do placar de líderes ou a distribuição de dados na produção, se estamos falando de trabalho real.
Outra coisa pela qual os Kagglers são frequentemente culpados é pelos conjuntos. Uma solução Kaggle geralmente consiste em vários modelos e é impossível arrastar o produto. No entanto, eles esquecem que é impossível fazer uma solução forte sem modelos únicos fortes. E para vencer, você precisa não apenas de um conjunto, mas de um conjunto de modelos únicos diversos e fortes.
A abordagem “misture tudo em uma fila” nunca fornece um resultado decente. A:
A:O conceito de "modelo único simples" na reunião do Kaggle e no ambiente de produção pode ser muito diferente. No âmbito da competição, essa será uma arquitetura treinada em 5/10 dobras, com um codificador espalhado, com o tempo em que você pode esperar o aumento do tempo de teste. Pelos padrões de concorrência, esta é uma solução realmente simples.
Porém, a produção geralmente
precisa de soluções com um número de ordens de magnitude mais fácil , especialmente quando se trata de aplicativos móveis ou IoT. Por exemplo, no meu caso, os modelos Kaggle geralmente ocupam mais de 100 megabytes e, no trabalho do modelo, mais de vários megabytes nem sempre são considerados; Existe uma lacuna semelhante nos requisitos para a taxa de inferência.
N:No entanto, se a data em que o cientista souber treinar uma grade pesada, todas as mesmas técnicas também serão adequadas para o treinamento de modelos leves. Em uma primeira aproximação, você pode usar apenas uma malha semelhante, uma versão mais fácil ou móvel da mesma arquitetura. Quantização de escalas e poda além da competência dos Kagglers - sem dúvida aqui. Mas essas já são habilidades muito específicas, que nem sempre são urgentemente necessárias no prod.
Mas uma situação muito mais frequente em problemas reais é que há um pequeno conjunto de dados rotulado
(como suas calças) e a maioria dos dados não alocados ou um fluxo contínuo de novos dados. E aqui a capacidade de soldar um conjunto grande e preciso é perfeitamente adequada. Com ele, você pode fazer pseudo-escurecimento ou destilação para treinar um modelo leve. Aumentar o conjunto de dados dessa maneira é garantido para melhorar o desempenho de qualquer modelo.
A:A pseudo-dabbing é útil, mas nas competições não é usada para uma vida boa - apenas porque é impossível redimensionar os dados. Os dados obtidos usando o pseudo-escurecimento, embora melhorando a métrica, não são tão úteis quanto a marcação manual dos dados ausentes.
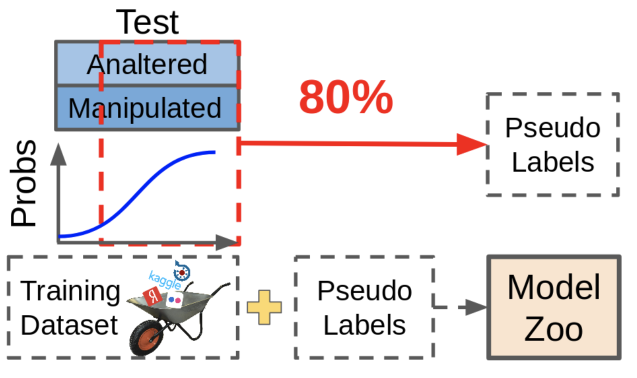
O que é pseudo-dabbing? Pegamos modelos existentes, observamos onde eles fornecem previsões confiáveis, jogamos essas amostras juntamente com previsões em nosso conjunto de dados. Nesse caso, amostras difíceis para o modelo permanecem sem rótulo, porque essas previsões não são boas o suficiente agora. Círculo vicioso!
Na prática, é muito mais útil encontrar as amostras que fazem com que a rede produza previsões incertas e redimensioná-las. Requer muito trabalho manual, mas o efeito vale a pena.
Sobre a beleza do código e do trabalho em equipe
A:Outra questão é a qualidade do código e a cultura de desenvolvimento. O Kaggle não apenas não ensina como escrever código, mas também fornece muitos exemplos ruins. A maioria dos kernels é um código mal estruturado, ilegível e ineficiente que é copiado sem pensar. Algumas personalidades populares do Kaggle até praticam o upload de seu código no Google Drive, e não no repositório.

As pessoas são boas em aprendizado não supervisionado. Se você olhar muito para um código incorreto, poderá se acostumar com a ideia de que deve ser assim. Isso é especialmente perigoso para iniciantes, que são bastante no Kaggle.
N:A qualidade do código é um ponto discutível na concha, concordo. No entanto, também conheci pessoas que escreveram pipelines muito valiosos que poderiam ser reutilizados para outras tarefas. Mas essa é a exceção: no calor da luta, a qualidade do código é sacrificada em favor de verificações rápidas de novas idéias, especialmente no final da competição.
Mas Kaggle ensina trabalho em equipe. E nada une as pessoas como uma causa comum, um objetivo comum e compreensível. Você pode tentar competir com várias pessoas diferentes, se envolver e desenvolver habilidades sociais.
 A:
A:As equipes no estilo Kaggle também são muito diferentes. É bom que haja realmente algum tipo de separação de tarefas por papéis, interação construtiva e todos contribuam. No entanto, as equipes nas quais todos fazem sua grande bola de barro e, nos últimos dias da competição, tudo isso é freneticamente misturado, também são suficientes, e isso também não ensina nada de bom - desenvolvimento de software real (incluindo ciência de dados) não feito por muito tempo.
Sumário
Vamos resumir.
Sem dúvida, a participação em competições concede bônus úteis no trabalho diário: primeiro, é a capacidade de iterar rapidamente, extrair tudo dos dados no âmbito da métrica e não hesitar em usar abordagens de última geração.
Por outro lado, o abuso das abordagens do Kaggle geralmente leva a códigos ilegíveis abaixo do ideal, prioridades de trabalho duvidosas e um pouco de confusão.
No entanto, em qualquer data em que o cientista saiba que, para criar um conjunto com sucesso, é necessário combinar uma variedade de modelos. Portanto, em uma equipe
, vale a pena combinar pessoas com diferentes conjuntos de habilidades , e um ou dois Kagglers experientes serão úteis para praticamente qualquer equipe.