Quando escolhemos uma ferramenta para processar big data, consideramos opções diferentes - proprietárias e de código aberto. Avaliamos as possibilidades de rápida adaptação, acessibilidade e flexibilidade de tecnologias. Incluindo a migração entre versões. Como resultado, escolhemos a solução Greenplum de código aberto, que melhor cumpria nossos requisitos, mas exigia a solução de um problema importante.

O fato é que os arquivos de banco de dados Greenplum versões 4 e 5 não são compatíveis entre si e, portanto, uma simples atualização de uma versão para outra é impossível. A migração de dados só pode ser feita através do upload e download de dados. Neste post, falarei sobre as opções possíveis para essa migração.
Avaliando opções de migração
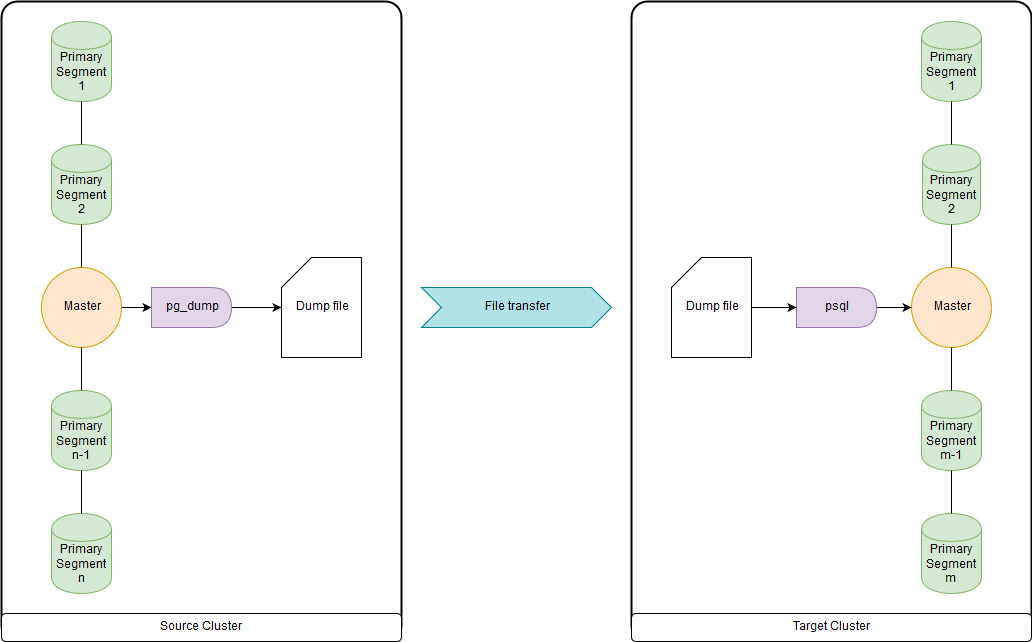
pg_dump & psql (ou pg_restore)
Isso é muito lento quando se trata de dezenas de terabytes, pois todos os dados são carregados e baixados através dos nós principais. Mas rápido o suficiente para migrar DDL e pequenas tabelas. Você pode fazer upload de ambos para um arquivo e executar pg_dump e psql ao mesmo tempo através de um canal em um cluster de origem e um cluster de destino. O pg_dump simplesmente carrega em um único arquivo contendo os comandos DDL e COPY data. Os dados obtidos podem ser convenientemente processados, como será mostrado abaixo.
gptransfer
Requer a versão Greenplum 4.2 ou posterior. É necessário que o cluster de origem e o cluster de destino trabalhem simultaneamente. A maneira mais rápida de migrar grandes tabelas de dados para a versão de código aberto. Mas esse método é muito lento para transferir tabelas vazias e pequenas devido à alta sobrecarga.
O gptransfer usa pg_dump para transferir DDL e gpfdist para transferir dados. O número de segmentos primários no cluster de destino não deve ser menor que o segmento host no cluster de origem. É importante considerar ao criar clusters “sandbox”, se os dados dos principais clusters serão transferidos para eles, e o uso do utilitário gptransfer é planejado. Mesmo se os hosts de segmento forem poucos, você poderá implantar o número necessário de segmentos em cada um deles. O número de segmentos no cluster de destino pode ser menor que no cluster de origem; no entanto, isso
afetará negativamente a velocidade de transferência de dados. Entre os clusters, a autenticação ssh nos certificados deve ser configurada.
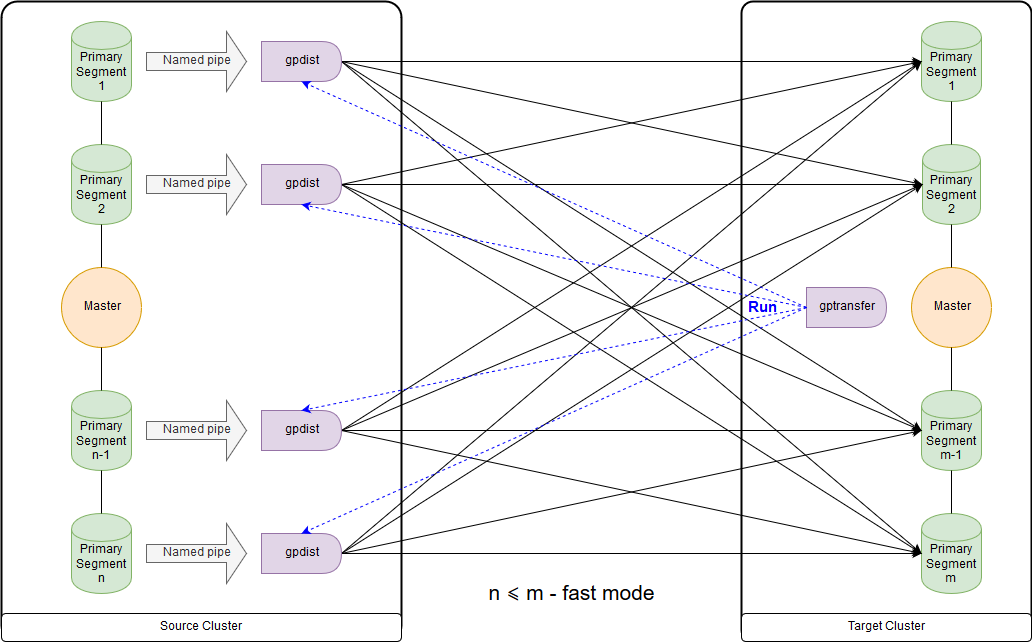
Esse é o esquema para o modo rápido quando o número de segmentos no cluster de destino é maior ou igual ao número no cluster de origem. O lançamento do próprio utilitário é mostrado no diagrama no nó principal do cluster receptor. Nesse modo, uma tabela de gravação externa é criada no cluster de origem, que grava dados em cada segmento no canal nomeado. O comando INSERT INTO writable_external_table SELECT * FROM source_table é executado. Os dados do pipe nomeado são lidos pelo gpfdist. Uma tabela externa também é criada no cluster de destino, apenas para leitura. A tabela indica os dados que o gpfdist fornece sobre
o protocolo com o mesmo nome . O comando INSERT INTO target_table SELECT * FROM external_gpfdist_table é executado. Os dados são redistribuídos automaticamente entre os segmentos do cluster de destino.
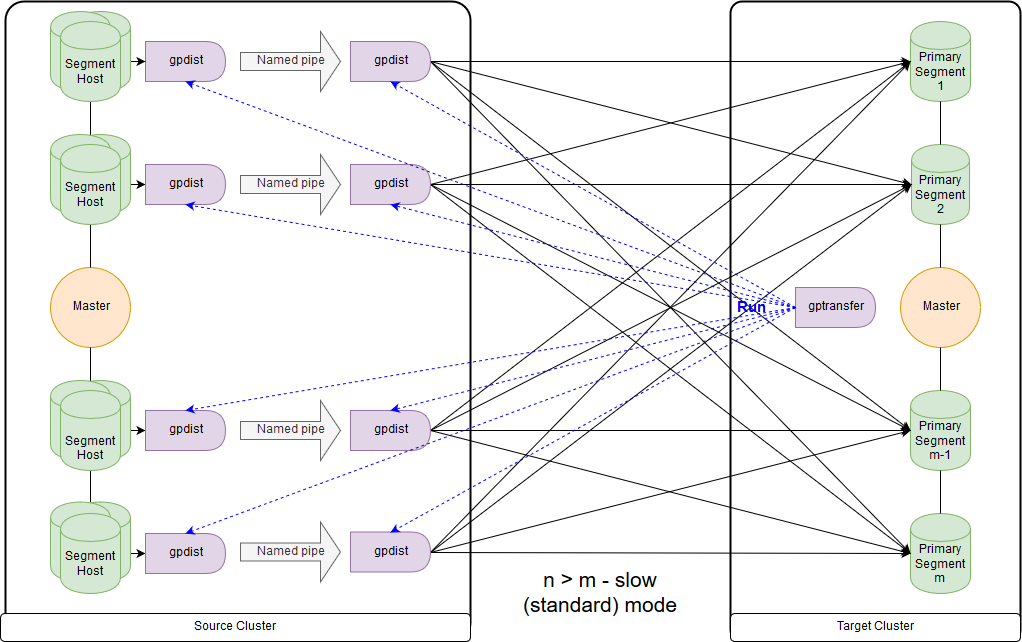
E este é o esquema para o modo lento, ou, como o próprio gptransfer divulga, modo padrão. A principal diferença é que, em cada host de segmento do cluster de origem, um par gpfdist é iniciado para todos os segmentos desse host de segmento. Uma tabela de registro externo refere-se ao gpfdist atuando como um receptor de dados. Além disso, se vários valores forem indicados para gravação no parâmetro LOCATION da tabela externa, os segmentos serão distribuídos igualmente pelo gpfdist ao gravar dados. Os dados entre gpfdist no segmento de host são passados através do pipe nomeado. Por esse motivo, a velocidade de transferência de dados é mais baixa, mas ainda é mais rápida do que quando os dados são transferidos apenas através do nó principal.
Ao migrar dados do Greenplum 4 para o Greenplum 5, o gptransfer deve ser executado no nó principal do cluster de destino. Se executarmos o gptransfer no cluster de origem, obteremos o erro da ausência do campo
san_mounts na tabela
pg_catalog.gp_segment_configuration :
gptransfer -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Validating options... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190109:12:46:14:010893 gptransfer:gpdb-source-master.local:gpadmin-[CRITICAL]:-gptransfer failed. (Reason='error 'ERROR: column "san_mounts" does not exist LINE 2: ... SELECT dbid, content, status, unnest(san_mounts... ^ ' in ' SELECT dbid, content, status, unnest(san_mounts) FROM pg_catalog.gp_segment_configuration WHERE content >= 0 ORDER BY content, dbid '') exiting...
Você também precisa verificar as variáveis GPHOME para que elas correspondam entre o cluster de origem e o cluster de destino. Caso contrário, obteremos um
erro bastante estranho (o utilitário gptransfer falha quando a origem e o destino têm um caminho GPHOME diferente).
gptransfer -t big_db.public.test_table --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --source-host=gpdb-spurce-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[ERROR]:-gptransfer: error: GPHOME directory does not exist on gpdb-source-master.local
Você pode simplesmente criar o link simbólico correspondente e substituir a variável GPHOME na sessão em que o gptransfer é iniciado.
Quando o gptransfer é iniciado no cluster de destino, a opção “--source-map-file” deve apontar para um arquivo que contém uma lista de hosts e seus endereços IP com segmentos principais do cluster de origem. Por exemplo:
sdw1,192.0.2.1 sdw2,192.0.2.2 sdw3,192.0.2.3 sdw4,192.0.2.4
Com a opção “--full”, é possível transferir não apenas tabelas, mas todo o banco de dados, no entanto, os bancos de dados do usuário não devem ser criados no cluster de destino. Você também deve se lembrar de que existem problemas devido a alterações de sintaxe ao mover tabelas externas.
Vamos avaliar a sobrecarga extra, por exemplo, copiando 10 tabelas vazias (tabelas de big_db.public.test_table_2 para big_db.public.test_table_11) usando gptarnsfer:
gptransfer -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-ba tch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-batch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190118:06:14:09:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving source tables... 20190118:06:14:12:031521 gptransfer:mdw:gpadmin-[INFO]:-Checking for gptransfer schemas... 20190118:06:14:22:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving list of destination tables... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Reading source host map file... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Building list of source tables to transfer... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Number of tables to transfer: 10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-gptransfer will use "standard" mode for transfer. 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating source host map... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating transfer table set... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-The following tables on the destination system will be truncated: 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_2 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_3 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_4 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_5 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_6 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_7 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_8 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_9 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_11 … 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using batch size of 10 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using sub-batch size of 16 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating work directory '/home/gpadmin/gptransfer_31521' 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating schema public in database edw_prod... 20190118:06:14:40:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting transfer of big_db.public.test_table_5 to big_db.public.test_table_5... … 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Validation of big_db.public.test_table_4 successful 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Removing work directories... 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Finished.
Como resultado, a transferência de 10 tabelas vazias levou cerca de 16 segundos (14: 40-15: 02), ou seja, uma tabela - 1,6 segundos. Durante esse período, no nosso caso, cerca de 100 MB de dados podem ser baixados usando pg_dump & psql.
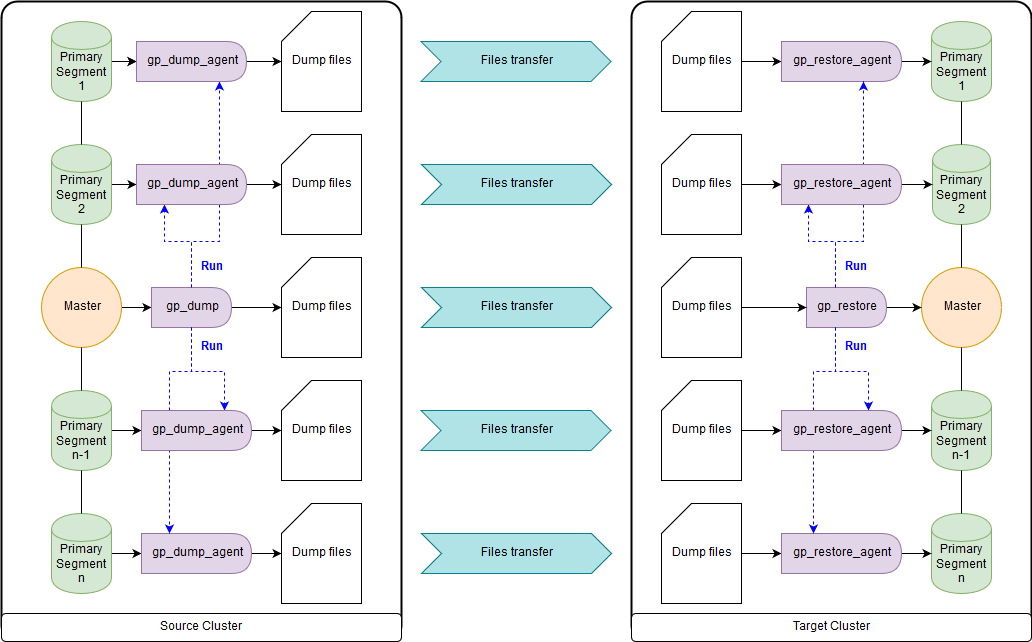
gp_dump & gp_restore
Como opção: use complementos sobre eles, gpcrondump & gpdbrestore, pois gp_dump & gp_restore são declarados obsoletos. Embora gpcrondump e gpdbrestore usem gp_dump & gp_restore no processo. Esta é a maneira mais universal, mas não a mais rápida. Os arquivos de backup criados com gp_dump representam um conjunto de comandos DDL no nó principal e nos segmentos primários, principalmente conjuntos de comandos e dados COPY. Adequado para casos em que não é possível fornecer operação simultânea do cluster de destino e do cluster de origem. Existem nas versões antigas do Greenplum e nas novas:
gp_dump ,
gp_restore .
Utilitários gpbackup e gprestore
Criado como um substituto para gp_dump e gp_restore. Para seu trabalho, é necessária a versão mínima 4.3.17 do Greenplum (
const MINIMUM_GPDB4_VERSION = "4.3.17" ). O esquema de trabalho é semelhante ao gpbackup & gprestore, enquanto a velocidade do trabalho é muito mais rápida. A maneira mais rápida de obter comandos DDL para grandes bancos de dados. Por padrão, ele transfere objetos globais, para a recuperação você precisa especificar "gprestore --with-globals". O parâmetro opcional “--jobs” pode definir o número de trabalhos (e sessões no banco de dados) ao criar um backup. Devido ao fato de várias sessões serem criadas, é importante garantir a consistência dos dados até que todos os bloqueios sejam recebidos. Há também uma opção útil “--with-stats”, que permite transferir estatísticas sobre objetos usados para criar planos de execução. Mais informações
aqui .
Utilitário Gpcopy
Para copiar bancos de dados, existe um utilitário gpcopy - um substituto para o gptansfer. Mas ele está incluído apenas na versão proprietária do Greenplum da Pivotal, a partir de 4.3.26 - na versão de código aberto
esse utilitário não . Em operação, o cluster de origem executa o comando COPY source_table TO PROGRAM 'gpcopy_helper ...' NO SEGMENTO CSV IGNORANDO PARTIÇÕES EXTERNAS. No lado do cluster de recebimento, uma tabela externa temporária CREATE EXTERNAL WEB TEMP TABLE external_temp_table (LIKE target_table) EXECUTE '... gpcopy_helper –listen ...' é criada e o comando INSERT INTO target_table SELECT * FROM external_temp_table é executado. Como resultado, gpcopy_helper com o parâmetro –listen é iniciado em cada segmento do cluster de destino, que recebe dados de gpcopy_helper dos segmentos do cluster de origem. Devido a esse esquema de transmissão de dados e à compressão, a velocidade de transmissão é muito maior. Entre os clusters, a autenticação ssh nos certificados também deve ser configurada. Também quero observar que o gpcopy tem uma opção conveniente “--truncate-source-after” (e “--validate”) para casos em que os clusters de origem e destino estão localizados nos mesmos servidores.
Estratégia de Transferência de Dados
Para determinar a estratégia de transferência, precisamos determinar o que é mais importante para nós: transferir dados rapidamente, mas com mais trabalho e possivelmente com menos confiabilidade (gpbackup, gptransfer ou uma combinação dos mesmos) ou com menos trabalho, mas mais lento (gpbackup ou gptransfer sem combinação).
A maneira mais rápida de transferir dados - quando há um cluster de origem e um cluster de destino - é o seguinte:
- Obtenha DDL usando gpbackup - somente metadados, converta e carregue através do pipeline usando psql
- Excluir índices
- Transfira tabelas com um tamanho de 100 MB ou mais usando gptransfer
- Transfira tabelas com tamanho menor que 100 MB usando pg_dump | psql como no primeiro parágrafo
- Criar índices excluídos de volta
Esse método acabou sendo em nossas medições pelo menos duas vezes mais rápido que gp_dump & gp_restore. Métodos alternativos: transferência de todos os bancos de dados usando gptransfer –full, gpbackup & gprestore ou gp_dump & gp_restore.
Os tamanhos das tabelas podem ser obtidos pela seguinte consulta:
SELECT nspname AS "schema", coalesce(tablename, relname) AS "name", SUM(pg_total_relation_size(class.oid)) AS "size" FROM pg_class class JOIN pg_namespace namespace ON namespace.oid = class.relnamespace LEFT JOIN pg_partitions parts ON class.relname = parts.partitiontablename AND namespace.nspname = parts.schemaname WHERE nspname NOT IN ('pg_catalog', 'information_schema', 'pg_toast', 'pg_bitmapindex', 'pg_aoseg', 'gp_toolkit') GROUP BY nspname, relkind, coalesce(tablename, relname), pg_get_userbyid(class.relowner) ORDER BY 1,2;
Conversões necessárias
Os arquivos de backup nas versões 4 e 5 do Greenplum também não são totalmente compatíveis. Portanto, no Greenplum 5, devido a uma alteração na sintaxe, os comandos CREATE EXTERNAL TABLE e COPY não possuem o parâmetro INTO ERROR TABLE e é necessário definir o parâmetro SET gp_ignore_error_table como true para que a restauração do backup não falhe por engano. Com o conjunto de parâmetros, apenas recebemos um aviso.
Além disso, a quinta versão introduziu um protocolo diferente para interagir com tabelas pxf externas e, para usá-lo, é necessário alterar o parâmetro LOCATION e configurar o serviço pxf.
Também é importante notar que nos arquivos de backup gp_dump e gp_restore no nó mestre e em cada segmento primário, o parâmetro SET gp_strict_xml_parse está definido como false. Não existe esse parâmetro no Greenplum 5 e, como resultado, recebemos uma mensagem de erro.
Se o protocolo gphdfs foi usado para tabelas externas, é necessário verificar nos arquivos de backup a lista de fontes no parâmetro LOCATION para tabelas externas na linha 'gphdfs: //'. Por exemplo, deve haver apenas 'gphdfs: //hadoop.local: 8020'. Se houver outras linhas, elas deverão ser adicionadas ao script de substituição no nó principal por analogia.
grep -o gphdfs\:\/\/.*\/ /data1/master/gpseg-1/db_dumps/20181206/gp_dump_-1_1_20181206122002.gz | cut -d/ -f1-3 | sort | uniq gphdfs://hadoop.local:8020
Fazemos substituições no nó principal (usando o arquivo de dados gp_dump como exemplo):
mv /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz gunzip -c /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz | sed "s#'gphdfs://hadoop.local:8020#'pxf:/#g" | sed "s/\(^.*pxf\:\/\/.*'\)/\1\\&\&\?PROFILE=HdfsTextSimple'/" |sed "s#'&#g" | sed 's/SET gp_strict_xml_parse = false;/SET gp_ignore_error_table = true;/g' | gzip -1 > /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz nets
Nas versões recentes, o nome do perfil HdfsTextSimple é
declarado obsoleto , o novo nome é hdfs: text.
Sumário
Fora do artigo, permanecia a necessidade de conversão explícita em texto (
Implicit Text Casting ), um novo mecanismo de gerenciamento de recursos de cluster de
Grupos de Recursos que substituiu Filas de Recursos, otimizador
GPORCA , incluído por padrão no Greenplum 5, pequenos problemas com os clientes.
Estou ansioso pelo lançamento da sexta versão do Greenplum, que está programada para a primavera de 2019: nível de compatibilidade com o PostgreSQL 9.4, pesquisa de texto completo, suporte ao índice GIN, tipos de intervalo, JSONB e compactação zStd. Além disso, os planos preliminares para o Greenplum 7 tornaram-se conhecidos: nível de compatibilidade com o PostgreSQL mínimo 9.6, segurança no nível de linha, failover mestre automatizado. Os desenvolvedores também prometem a disponibilidade de utilitários de atualização de banco de dados para atualização entre as principais versões, para que seja mais fácil viver.
Este artigo foi preparado pela equipe de gerenciamento de dados Rostelecom