Quão complexo é o tópico do aprendizado de máquina? Se você é bom em matemática, mas a quantidade de conhecimento sobre aprendizado de máquina tende a zero, até onde você pode ir em uma competição séria na plataforma
Kaggle ?

Sobre o site e a concorrência
Kaggle é uma comunidade de pessoas interessadas em ML (de iniciantes a profissionais legais) e um local para competições (geralmente com uma premiação impressionante).
Para mergulhar imediatamente em todos os encantos da ML, decidi escolher imediatamente uma competição séria. Tal estava disponível:
Two Sigma: Using News para prever movimentos de estoque . Em resumo, a essência do concurso é prever o preço das ações de várias empresas com base no status do ativo e nas notícias relacionadas a esse ativo. O fundo do prêmio é de US $ 100.000, que serão distribuídos entre os participantes que conquistaram os 7 primeiros lugares.
A competição é especial por dois motivos:
- este é um concurso exclusivo do Kernels: você pode treinar modelos apenas na nuvem do Kaggle Kernels;
- a distribuição final dos assentos será conhecida apenas seis meses após a conclusão da tomada de decisão; durante esse período, as decisões preverão os preços na data atual.
Sobre a tarefa
Por condição, devemos prever a confiança
na medida em que o retorno do ativo aumentará. O retorno de um ativo é considerado relativo ao retorno do mercado como um todo. A métrica de destino é personalizada - não é o
RMSE ou o
MAE mais familiar, mas
a taxa de Sharpe , que neste caso é considerada da seguinte maneira:
onde
,
- o retorno do ativo i em relação ao mercado para o dia t no horizonte de 10 dias,
- uma variável booleana indicando se o i-ésimo ativo está incluído na avaliação para o dia t,
- valor médio
,
- desvio padrão
.
O índice de Sharpe é o retorno ajustado ao risco, os valores do coeficiente mostram a eficácia do trader:
- menos de 1: desempenho ruim
- 1 - 2: médio, eficiência normal,
- 2 - 3: excelente desempenho,
- mais de 3: perfeito.
Dados de movimentação de mercado- time (datetime64 [ns, UTC]) - hora atual (nos dados de movimento do mercado em todas as linhas às 22:00 UTC)
- assetCode (object) - identificador de ativo
- assetName (categoria) - um identificador de um grupo de ativos para comunicação com dados de notícias
- universe (float64) - um valor booleano que indica se esse ativo será levado em consideração no cálculo da pontuação
- volume (float64) - volume diário de negociação
- close (float64) - preço de fechamento para este dia
- open (float64) - preço da abertura para este dia
- ReturnsClosePrevRaw1 (float64) - rendimento de fechamento a fechamento no dia anterior
- retornosOpenPrevRaw1 (float64) - rentabilidade de abertura em abertura para o dia anterior
- retornosClosePrevMktres1 (float64) - lucratividade do fechamento ao fechamento do dia anterior, ajustada em relação ao movimento do mercado como um todo
- retornosOpenPrevMktres1 (float64) - lucratividade de abertura em abertura para o dia anterior, ajustado em relação ao movimento do mercado como um todo
- ReturnsClosePrevRaw10 (float64) - rendimento de quase a fechar nos 10 dias anteriores
- retornosOpenPrevRaw10 (float64) - rentabilidade de abertura em abertura nos 10 dias anteriores
- retornosClosePrevMktres10 (float64) - rendimento próximo ao fechamento dos 10 dias anteriores, ajustado em relação ao movimento do mercado como um todo
- returnOpenPrevMktres10 (float64) - rendimento de abertura a abertura nos 10 dias anteriores, ajustado em relação ao movimento do mercado como um todo
- ReturnsOpenNextMktres10 (float64) - rendimento de aberto a aberto nos próximos 10 dias, ajustado pelo movimento do mercado como um todo. Vamos prever esse valor.
Dados de notícias- time (datetime64 [ns, UTC]) - tempo na disponibilidade de dados UTC
- sourceTimestamp (datetime64 [ns, UTC]) - hora em Notícias da publicação UTC
- firstCreated (datetime64 [ns, UTC]) - hora em UTC da primeira versão dos dados
- sourceId (object) - identificador de registro
- título (objeto) - título
- urgency (int8) - tipos de notícias (1: alerta, 3: artigo)
- takeSequence (int16) - parâmetro não muito claro, número em alguma sequência
- provider (category) - identificador do provedor de notícias
- assuntos (categoria) - uma lista de códigos de tópicos de notícias (pode ser um sinal geográfico, evento, setor industrial etc.)
- públicos-alvo (categoria) - lista de códigos de audiência
- bodySize (int32) - número de caracteres no corpo da notícia
- companyCount (int8) - número de empresas mencionadas explicitamente nas notícias
- headlineTag (objeto) - uma certa etiqueta de título da Thomson Reuters
- marketCommentary (bool) - um sinal de que as notícias estão relacionadas às condições gerais de mercado
- fraseCount (int16) - número de ofertas nas notícias
- wordCount (int32) - número de palavras e sinais de pontuação nas notícias
- assetCodes (categoria) - lista de ativos mencionados nas notícias
- assetName (categoria) - código do grupo de ativos
- firstMentionSentence (int16) - uma frase que menciona primeiro um ativo:
- relevância (float32) - um número de 0 a 1, mostrando a relevância das notícias sobre o ativo
- sentimentClass (int8) - classe de tonalidade de notícias
- sentimentNegative (float32) - probabilidade de a tonalidade ser negativa
- sentimentNeutral (float32) - probabilidade de o tom ser neutro
- sentimentPositive (float32) - probabilidade de a chave ser positiva
- sentimentWordCount (int32) - o número de palavras no texto que estão relacionadas ao ativo
- noveltyCount12H (int16) - notícias "novidades" em 12 horas, calculadas em relação às notícias anteriores sobre este ativo
- noveltyCount24H (int16) - o mesmo, em 24 horas
- noveltyCount3D (int16) - o mesmo, em 3 dias
- noveltyCount5D (int16) - o mesmo, em 5 dias
- noveltyCount7D (int16) - o mesmo em 7 dias
- volumeCounts12H (int16) - a quantidade de notícias sobre esse ativo em 12 horas
- volumeCounts24H (int16) - o mesmo, em 24 horas
- volumeCounts3D (int16) - o mesmo em 3 dias
- volumeCounts5D (int16) - o mesmo por 5 dias
- volumeCounts7D (int16) - o mesmo em 7 dias
A tarefa é essencialmente a tarefa de classificação binária, ou seja, prevemos um sinal binário, produzirá aumento (1 classe) ou diminuição (0 classe).
Sobre ferramentas
Kaggle Kernels é uma plataforma de computação em nuvem que suporta colaboração. Os seguintes tipos de kernels são suportados:
- Script Python
- Script R
- Caderno Jupyter
- RMarkdowndown
Cada kernel é executado em seu contêiner de janela de encaixe. Um grande número de pacotes está instalado no contêiner, uma lista para python pode ser encontrada
aqui . As especificações técnicas são as seguintes:
- CPU: 4 núcleos,
- RAM: 17 GB,
- unidade: 5 GB permanente e 16 GB temporário,
- tempo máximo de execução do script: 9 horas (no início do concurso, eram 6 horas).
As GPUs também estão disponíveis no Kernels, no entanto, a GPU foi proibida neste concurso.
O Keras é uma estrutura de rede neural de alto nível executada sobre o
TensorFlow ,
CNTK ou
Theano . É uma API muito conveniente e compreensível, e é possível adicionar topologias de rede, funções de perda e muito mais usando a API de back-end.
O Scikit-learn é uma grande biblioteca de algoritmos de aprendizado de máquina. Uma fonte útil de algoritmos de pré-processamento e análise de dados para uso com estruturas mais especializadas.
Validação de modelo
Antes de enviar um modelo para avaliação, você precisa verificar de alguma forma localmente o quão bem ele funciona - ou seja, apresentar um caminho para a validação local. Eu tentei as seguintes abordagens:
- validação cruzada vs simples divisão proporcional em conjuntos de treinamento / teste;
- cálculo local da razão Sharpe vs ROC AUC .
Como resultado, os resultados mais próximos da avaliação competitiva, curiosamente, mostraram uma combinação da partição proporcional (selecionada empiricamente a partição 0,85 / 0,15) e AUC. A validação cruzada provavelmente não é muito adequada, pois o comportamento do mercado é muito diferente nos estágios iniciais dos dados de treinamento e no período de avaliação. Por que a CUA funcionou melhor do que a proporção Sharpe - não posso dizer nada.
Primeiras tentativas
Como a tarefa é prever a série temporal, a primeira foi testada com a solução clássica - uma rede neural recorrente (
RNN ), ou melhor, suas variantes
LSTM e
GRU .
O principal princípio das redes recorrentes é que, para cada valor de saída, não é inserida uma amostra, mas uma sequência inteira. Daqui resulta que:
- precisamos de algum pré-processamento dos dados iniciais - a geração dessas mesmas sequências de duração t dias para cada ativo;
- um modelo baseado em uma rede recorrente não pode prever o valor de saída se não houver dados para os t dias anteriores.
Eu gerava seqüências para cada dia, começando com t, então, para t relativamente grande (de 20), o conjunto completo de amostras de treinamento deixou de caber na memória. O problema foi resolvido usando geradores, pois o Keras pode usar geradores como conjuntos de dados de entrada e saída para treinamento e previsão.
A preparação inicial dos dados foi a mais ingênua possível: coletamos todos os dados do mercado e adicionamos alguns recursos (dia da semana, mês, número da semana do ano) e não tocamos nos dados das notícias.
O primeiro modelo usou t = 10 e ficou assim:
model = Sequential() model.add(LSTM(256, activation=act.tanh, return_sequences=True, input_shape=(data.timesteps, data.features))) model.add(LSTM(256, activation=act.relu)) model.add(Dense(data.assets, activation=act.relu)) model.add(Dense(data.assets))
Nada adequado foi extraído deste modelo, a pontuação foi próxima de zero (mesmo um pouco no vermelho).
Redes Convolucionais Temporais
Uma solução de rede neural mais moderna para previsão de séries temporais é a TCN. A essência dessa topologia é muito simples: pegamos uma rede convolucional unidimensional e a aplicamos à nossa sequência de comprimento t. Opções mais avançadas usam várias camadas convolucionais com diferentes dilatações. A implementação da TCN foi parcialmente copiada (às vezes no nível da ideia)
daqui (visualização da pilha da TCN retirada do
artigo da Wavenet ).
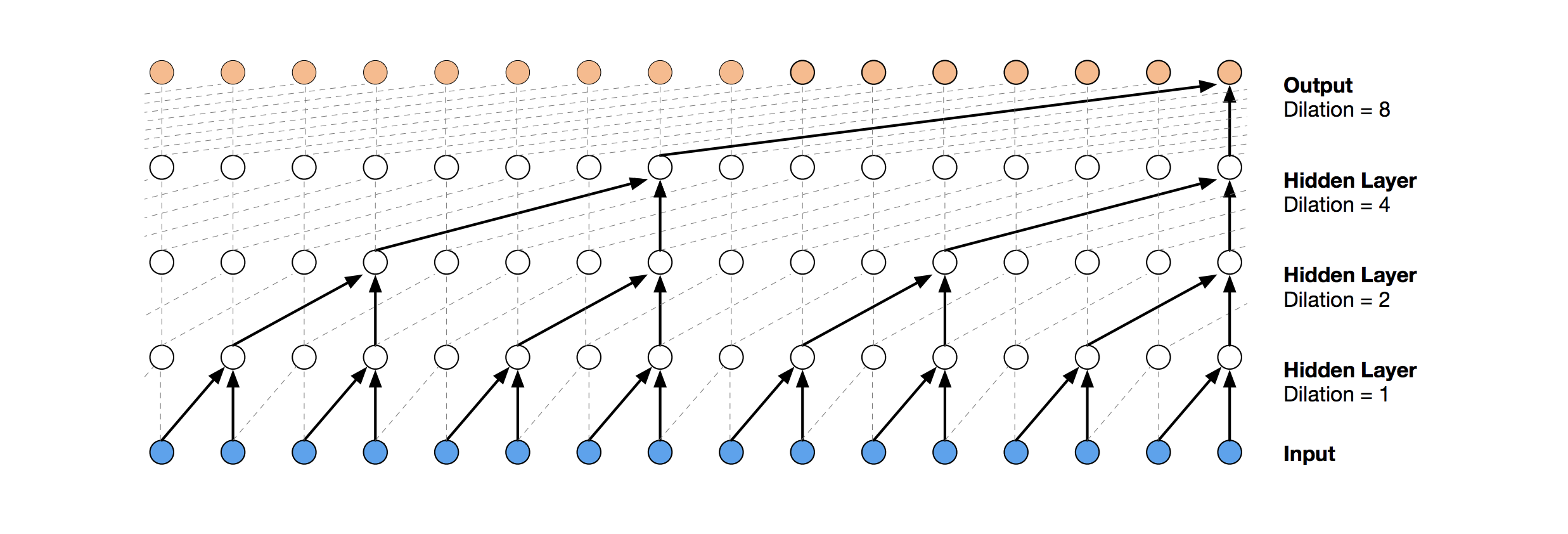
A primeira solução relativamente bem-sucedida foi esse modelo, que inclui uma camada GRU sobre a TCN:
model = Sequential() model.add(Conv1D(512,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(256)) model.add(Dense(data.assets, activation=act.relu))
Esse modelo produz pontuação = 0,27668. Com um pequeno ajuste (número de filtros TCN, tamanho do lote) e um aumento de t para 100, obtemos 0,41092:
batch_size = 512 model = Sequential() model.add(Conv1D(8,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(16)) model.add(Dense(1, activation=act.sigmoid))
Em seguida, adicionamos normalização e abandono:
Código batch_size = 512 dropout_rate = 0.05 def channel_normalization(x): max_values = K.max(K.abs(x), 2, keepdims=True) + 1e-5 out = x / max_values return out model = Sequential() if(data.timesteps > 1): model.add(Conv1D(16,2, activation=act.relu, padding='valid', input_shape=(data.timesteps, data.features))) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) for i in range(1, 6): model.add(Conv1D(16,2, activation=act.relu, padding='valid', dilation_rate=2**i)) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) model.add(Flatten()) else: model.add(Flatten(input_shape=(data.timesteps, data.features))) model.add(Dense(256, activation=act.relu)) model.add(Dense(1, activation=act.sigmoid))
Aplicando esse modelo, inclusive nas etapas iniciais (com t = 1), obtemos pontuação = 0,53578.
Máquinas de reforço de gradiente
Nesse estágio, as idéias terminaram, e eu decidi fazer o que precisava ser feito desde o início: ver as decisões públicas de outros participantes. A maioria das boas soluções não usava redes neurais, preferindo o GBM.
O aumento de gradiente é um método ML, cuja saída obtemos um conjunto de modelos simples (na maioria das vezes, árvores de decisão). Devido ao grande número de modelos simples, a função de perda é otimizada. Você pode ler mais sobre o Gradient Boosting, por exemplo,
aqui .
Como a implementação do GBM usou o
lightgbm - uma estrutura bastante conhecida da Microsoft.
O pré-processamento de modelo e dados retirado
daqui imediatamente fornece uma pontuação de cerca de 0,64:
Código def prepare_data(marketdf, newsdf):
O pré-processamento aqui já inclui dados de notícias, combinando-os com dados de mercado (no entanto, de maneira bastante ingênua, apenas um código de ativo dentre todos os mencionados nas notícias é levado em consideração). Tomei essa opção de pré-processamento como base para todas as decisões subseqüentes.
Adicionando um pequeno recurso (firstMentionSentence, marketCommentary, sentimentClass) e também substituindo a métrica pela
ROC AUC , obtemos uma pontuação de 0,65389.
Ensemble
A próxima decisão bem-sucedida foi usar um conjunto constituído por um modelo de rede neural e GBM (embora "conjunto" seja um grande nome para dois modelos). A previsão resultante é obtida calculando a média das previsões dos dois modelos, aplicando o mecanismo de votação branda. Esta decisão permitiu obter pontuação 0,66879.
Análise Exploratória de Dados e Engenharia de Recursos
Outra coisa para começar foi a EDA. Depois de ler que é importante entender a correlação entre os recursos, construímos uma imagem (as imagens nesta seção são clicáveis):
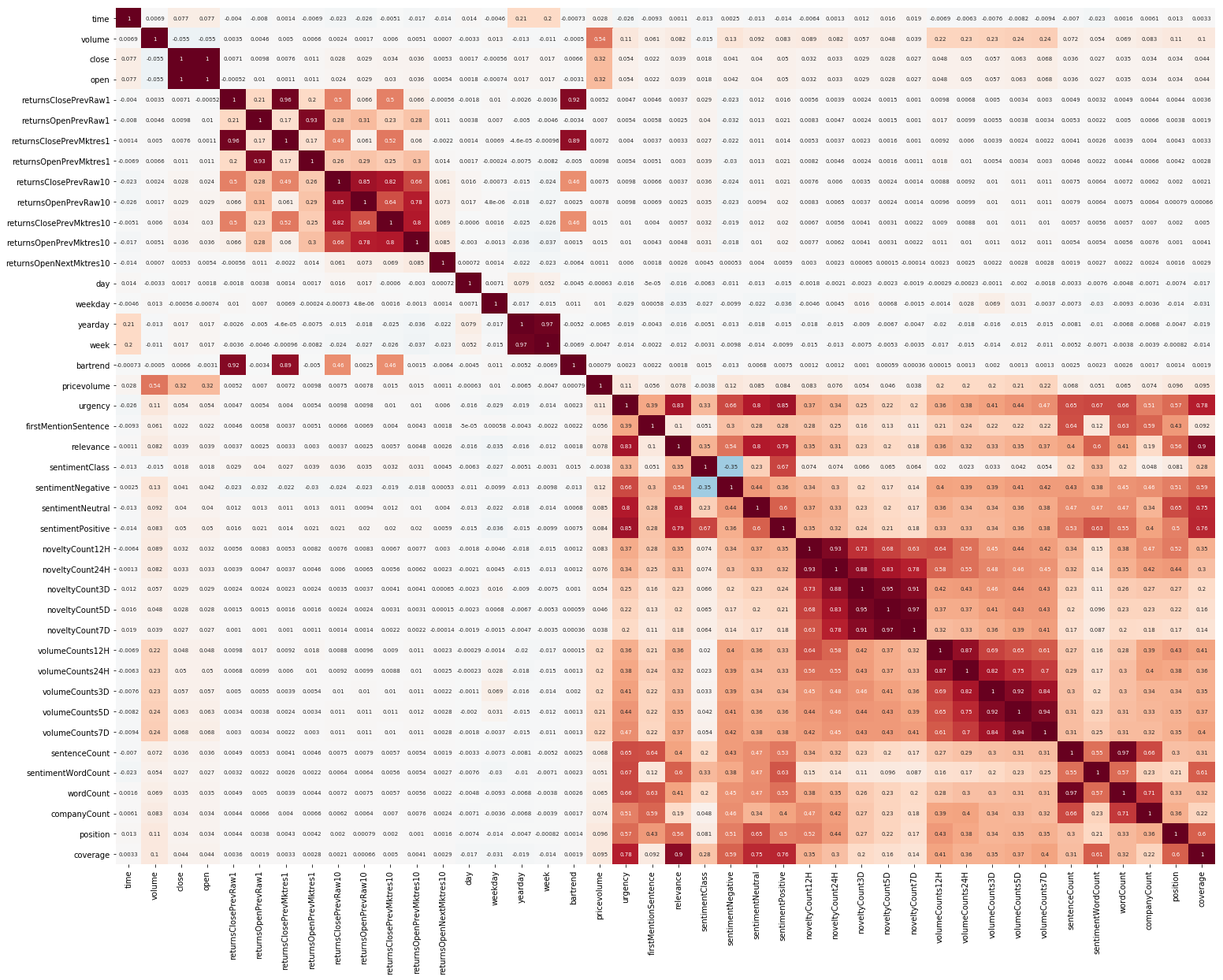
É claramente visto aqui que a correlação separadamente nos dados de mercado e de notícias é bastante alta; no entanto, apenas os valores dos retornos se correlacionam com o valor alvo, pelo menos de alguma forma. Como os dados representam uma série temporal, faz sentido examinar também a autocorrelação do valor de destino:
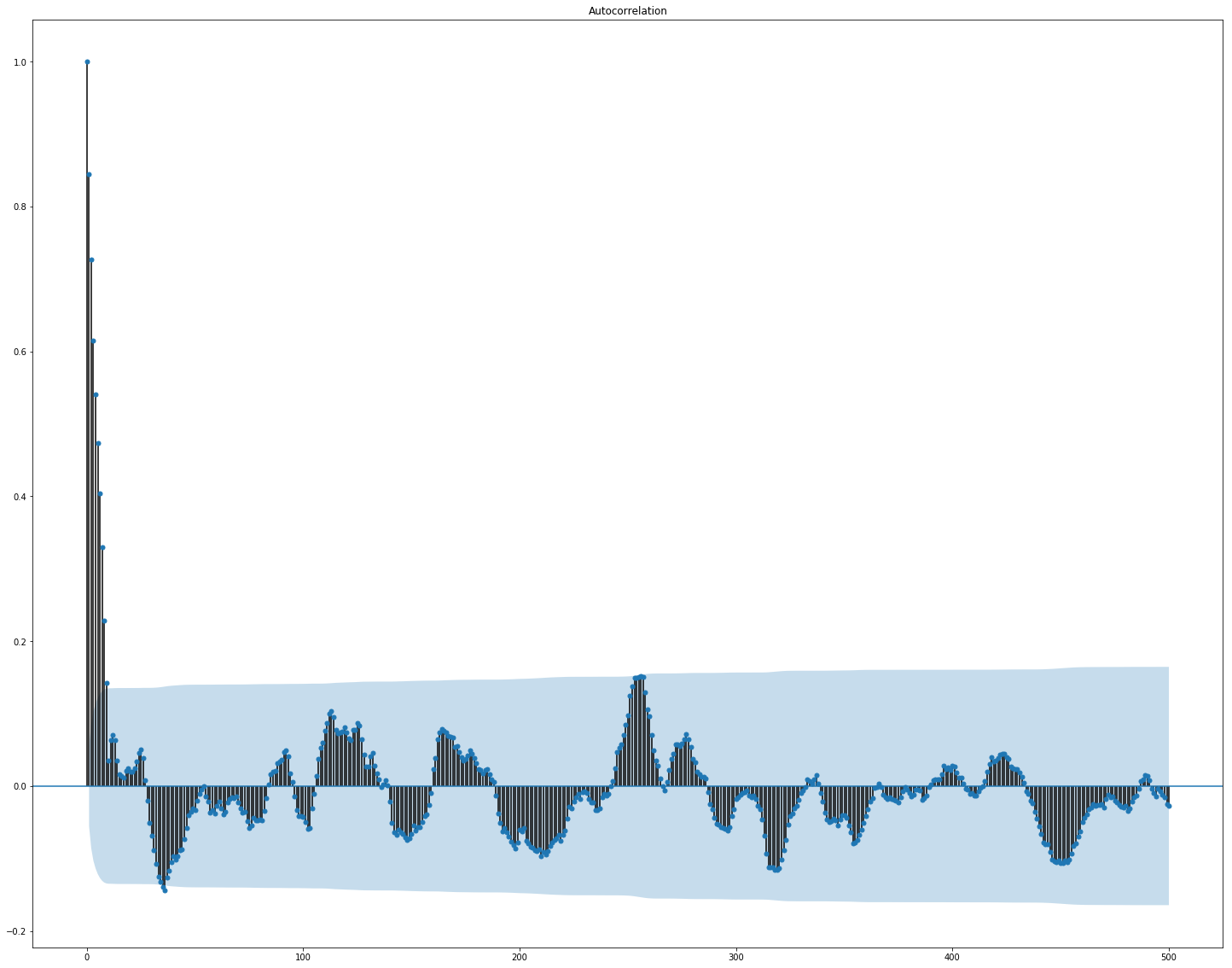
Pode-se observar que, após um período de 10 dias, a dependência diminui significativamente. Provavelmente, é isso que faz com que o GBM funcione bem, levando em consideração apenas os recursos com um atraso de 10 dias (que já estão no conjunto de dados original).
A seleção e o pré-processamento de recursos são cruciais para todos os algoritmos de ML. Vamos tentar usar maneiras automáticas de extrair recursos, a saber,
a análise de componentes principais (
PCA ):
from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler market_x = market_data.loc[:,features] scaler = StandardScaler() scaler.fit(market_x) market_x = scaler.transform(market_x) pca = PCA(.95) pca.fit(market_x) market_pca = pca.transform(market_x)
Vamos ver quais recursos o PCA gera:

Vemos que o método não funciona muito bem em nossos dados, pois a correlação final de novos recursos com o valor-alvo é pequena.
Ajuste fino e se é necessário
Muitos modelos de ML têm um número bastante grande de hiperparâmetros, ou seja, as “configurações” do próprio algoritmo. Eles podem ser selecionados manualmente, mas também existem mecanismos de seleção automática. Para o último, existe uma biblioteca de
hiperoperação que implementa dois algoritmos correspondentes - pesquisa aleatória e
Estimador de Parzen estruturado em árvore (TPE) . Eu tentei otimizar:
- parâmetros lightgbm (tipo de algoritmo, número de folhas, taxa de aprendizado e outros),
- parâmetros de modelos de redes neurais (número de filtros TCN , número de blocos de memória GRU , taxa de abandono, taxa de aprendizado, tipo de solucionador).
Como resultado, todas as soluções encontradas usando essa otimização apresentaram uma pontuação mais baixa, embora funcionassem melhor nos dados do teste. Provavelmente, o motivo está no fato de que os dados para os quais a pontuação é considerada não são muito semelhantes aos dados de validação selecionados no treinamento. Portanto, para esta tarefa, o ajuste fino não é muito adequado, pois leva à reciclagem do modelo.
Decisão final
De acordo com as regras da competição, os participantes podem escolher duas soluções para a etapa final. Minhas decisões finais são quase as mesmas e contêm um conjunto de dois modelos -
GBM e
GRU multicamada. A única diferença é que uma solução não usa dados de notícias e a outra os usa, mas apenas para o modelo de rede neural.
Solução de dados de notícias:
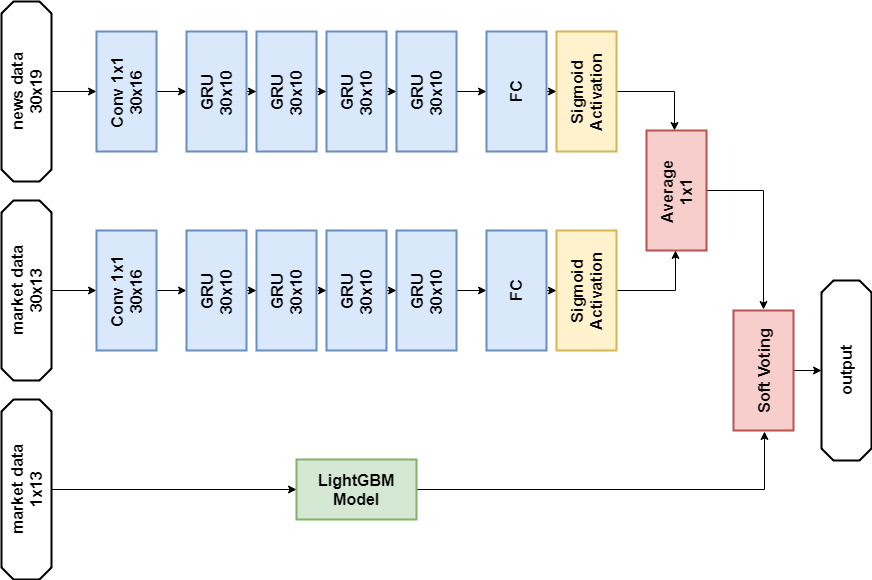
Importações import numpy as np import pandas as p import itertools import functools from kaggle.competitions import twosigmanews from sklearn.preprocessing import StandardScaler, LabelEncoder import tensorflow as tf from keras.models import Sequential, Model from keras.layers import Dense, GRU, LSTM, Conv1D, Reshape, Flatten, SpatialDropout1D, Lambda, Input, Average from keras.optimizers import Adam, SGD, RMSprop from keras import losses as ls from keras import activations as act import keras.backend as K import lightgbm as lgb
Pré-processamento de dados Modelo de rede neural def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) x2 = Lambda(lambda x: x[:,:,13:])(i) x2 = Conv1D(16,1, padding='valid')(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10)(x2) x2 = Dense(1, activation=act.sigmoid)(x2) x = Average()([x1, x2]) model = Model(inputs=i, outputs=x) return model def train_model_time_series(model, data, val_data=None): print('Building model...') batch_size = 4096 optimizer = RMSprop()
Modelo GBM def train_model(data, val_data=None): print('Building model...') params = { "objective" : "binary", "metric" : "auc", "num_leaves" : 60, "max_depth": -1, "learning_rate" : 0.01, "bagging_fraction" : 0.9,
Treinamento n_timesteps = 30 market_data, news_data = cleanData(market_train_df, news_train_df) dates = market_data['time'].unique() train = range(len(dates))[:int(0.85*len(dates))] val = range(len(dates))[int(0.85*len(dates)):] train_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[train])], news_data.loc[news_data['time'] <= max(dates[train])]) val_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[val])], news_data.loc[news_data['time'] > max(dates[train])], scaler=train_data_prepared.scaler) model_gbm = train_model(train_data_prepared, val_data_prepared) train_data_ts = generateTimeSeries(train_data_prepared, n_timesteps=n_timesteps) val_data_ts = generateTimeSeries(val_data_prepared, n_timesteps=n_timesteps) rnn = buildRNN(train_data_ts.timesteps, train_data_ts.features) model_rnn = train_model_time_series(rnn, train_data_ts, val_data_ts)
Previsão def make_predictions(data, template, model): if(hasattr(data, 'gen')): prediction = (model.predict(data.gen(data.samples)) * 2 - 1)[:,-1] else: prediction = model.predict(data.x) * 2 - 1 predsdf = p.DataFrame({'ast':data.assets,'conf':prediction}) template['confidenceValue'][template['assetCode'].isin(predsdf.ast)] = predsdf['conf'].values return template day = 1 days_data = p.DataFrame({}) days_data_len = [] days_data_n = p.DataFrame({}) days_data_n_len = [] for (market_obs_df, news_obs_df, predictions_template_df) in env.get_prediction_days(): print(f'Predicting day {day}') days_data = p.concat([days_data, market_obs_df], ignore_index=True, copy=False, sort=False) days_data_len.append(len(market_obs_df)) days_data_n = p.concat([days_data_n, news_obs_df], ignore_index=True, copy=False, sort=False) days_data_n_len.append(len(news_obs_df)) data = prepareData(market_obs_df, news_obs_df, scaler=train_data_prepared.scaler) predictions_df = make_predictions(data, predictions_template_df.copy(), model_gbm) if(day >= n_timesteps): data = prepareData(days_data, days_data_n, scaler=train_data_prepared.scaler) data = generateTimeSeries(data, n_timesteps=n_timesteps) predictions_df_s = make_predictions(data, predictions_template_df.copy(), model_rnn) predictions_df['confidenceValue'] = (predictions_df['confidenceValue'] + predictions_df_s['confidenceValue']) / 2 days_data = days_data[days_data_len[0]:] days_data_n = days_data_n[days_data_n_len[0]:] days_data_len = days_data_len[1:] days_data_n_len = days_data_n_len[1:] env.predict(predictions_df) day += 1 env.write_submission_file()
Solução sem dados de notícias:

Código (apenas um método diferente) def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
Ambas as decisões deram um resultado semelhante (cerca de 0,69) na primeira etapa da competição, que correspondeu a 566 dos 2.927 lugares. Após o primeiro mês de novos dados, as posições na lista de participantes foram confundidas e a solução com dados de notícias ficou em 65º lugar das 697 equipes restantes com o resultado de 3.19251, e o que acontecerá nos próximos cinco meses, ninguém sabe.
O que mais eu tentei
Métricas personalizadas
Como as decisões são avaliadas usando a razão Sharpe, é lógico tentar usá-la como uma métrica para o término precoce do treinamento.
Métrica para lightgbm:
def sharpe_metric(y_pred, train_data): y_true = train_data.get_label() * 2 - 1 std = np.std(y_true * y_pred) mean = np.mean(y_true * y_pred) sharpe = np.divide(mean, std, out=np.zeros_like(mean), where=std!=0) return "sharpe", sharpe, True
A verificação mostrou que essa métrica funciona pior nesse problema do que a AUC.
Mecanismo de atenção
O mecanismo de atenção permite que a rede neural se concentre nos recursos “mais importantes” nos dados de origem. Tecnicamente, a atenção é representada por um vetor de pesos (geralmente obtido por meio de uma camada totalmente conectada com ativação
softmax ), que é multiplicada pela saída de outra camada. Eu usei uma implementação na qual a atenção é aplicada ao eixo do tempo:
def buildRNN(timesteps, features): def attention_3d_block(inputs): a = Permute((2, 1))(inputs) a = Dense(timesteps, activation=act.softmax)(a) a = Permute((2, 1))(a) mul = Multiply()([inputs, a]) return mul i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
Esse modelo parece bastante bonito, mas essa abordagem não deu um aumento de pontuação, mas foi de cerca de 0,67.
O que não teve tempo de fazer
Várias áreas que parecem promissoras:
Conclusões
Nossa aventura chegou ao fim, você pode tentar resumir. A competição acabou sendo difícil, mas não conseguimos enfrentar a sujeira. Isso sugere que o limiar para entrar no ML não é tão alto, mas, como em qualquer negócio, a mágica real (e há muito disso no aprendizado de máquina) já está disponível para profissionais.
Resultados em números:
- A pontuação máxima no primeiro estágio: ~ 0,69 contra ~ 1,5 em primeiro lugar. Algo parecido com a média do hospital, um valor de 0,7 foi superado por alguns, a pontuação máxima da decisão pública também foi de ~ 0,69, um pouco mais que a minha.
- Lugar na primeira etapa: 566 de 2927.
- Pontuação na segunda etapa: 3.19251 após o primeiro mês.
- Lugar na segunda etapa: 65 de 697 após o primeiro mês.
Chamo a atenção para o fato de que os números no segundo estágio não estão falando particularmente de nada, pois ainda há muito poucos dados para uma avaliação qualitativa das decisões.
Referências
A solução final usando notíciasTwo Sigma: Usando Notícias para Predizer Movimentos de Ações - Página do Concurso
Keras -
Estrutura de rede neural
LightGBM - estrutura GBM
Scikit-learn - biblioteca de algoritmos de aprendizado de máquina
Hyperopt - biblioteca para otimização de hiperparâmetros
Artigo sobre WaveNet