Todos sabemos como a pátria começa e o aprendizado profundo começa com os dados. Sem eles, é impossível treinar um modelo, avaliá-lo e usá-lo. Envolvidos em pesquisas, aumentando o índice Hirsch com artigos sobre novas arquiteturas de redes neurais e experiências, contamos com as fontes de dados locais mais simples; geralmente arquivos em vários formatos. Funciona, mas seria bom lembrar de um sistema de combate contendo terabytes de dados em constante mudança. E isso significa que você precisa simplificar e acelerar a transferência de dados na produção, além de poder trabalhar com big data. É aqui que o Apache Ignite entra.
O Apache Ignite é um banco de dados distribuído centralizado na memória, bem como uma plataforma para operações de armazenamento em cache e processamento relacionadas a transações, análises e cargas de fluxo. O sistema é capaz de moer petabytes de dados na velocidade da RAM. O artigo focará na integração entre o Apache Ignite e o TensorFlow, que permite usar o Apache Ignite como uma fonte de dados para treinar a rede neural e a inferência, além de um repositório de modelos treinados e um sistema de gerenciamento de cluster para aprendizado distribuído.
Fonte de dados RAM distribuída
O Apache Ignite permite armazenar e processar quantos dados forem necessários em um cluster distribuído. Para aproveitar esse Apache Ignite ao treinar redes neurais no TensorFlow, use o
Ignite Dataset .
Nota: O Apache Ignite não é apenas um dos links no pipeline ETL entre um banco de dados ou armazém de dados e o TensorFlow. O Apache Ignite em si é o
HTAP (um sistema híbrido para processamento de dados transacionais / analíticos). Ao escolher o Apache Ignite e o TensorFlow, você obtém um sistema único para processamento transacional e analítico e, ao mesmo tempo, a capacidade de usar dados operacionais e históricos para treinar a rede neural e a inferência.
Os seguintes benchmarks demonstram que o Apache Ignite é adequado para cenários em que os dados são armazenados em um único host. Esse sistema permite atingir uma taxa de transferência superior a 850 Mb / s, se o armazém de dados e o cliente estiverem localizados no mesmo nó. Se o armazenamento estiver localizado em um host remoto, a taxa de transferência será de cerca de 800 Mb / s.
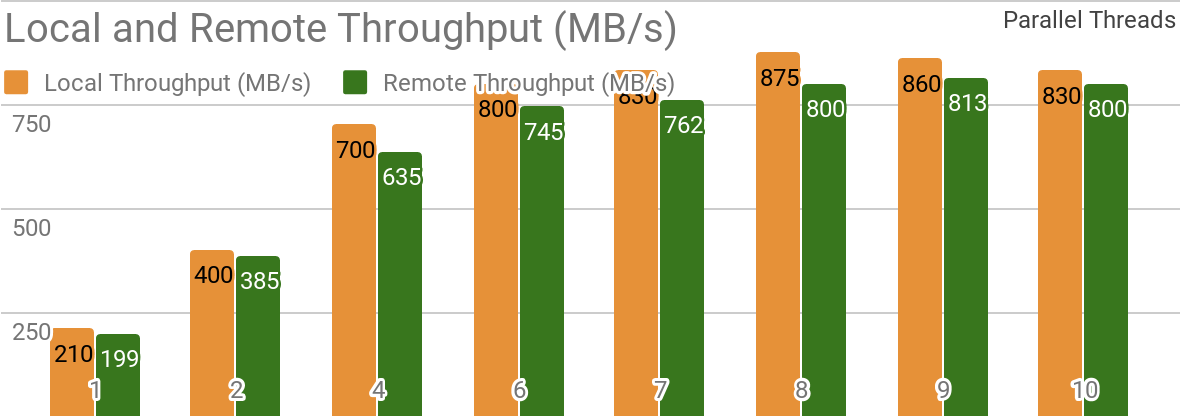
O gráfico mostra a largura de banda do Ignite Dataset para um único nó local do Apache Ignite. Esses resultados foram obtidos em um processador 2x Xeon E5-2609 v4 1.7GHz com 16 GB de RAM e em uma rede com uma largura de banda de 10 GB / s (cada registro tem tamanho de 1 MB, tamanho da página - 20 MB).
Outro benchmark demonstra como o Ignite Dataset funciona com um cluster Apache Ignite distribuído. Essa configuração é selecionada por padrão ao usar o Apache Ignite como um sistema HTAP e permite obter largura de banda para um único cliente com mais de 1 GB / s em um cluster com largura de banda de 10 Gb / s.
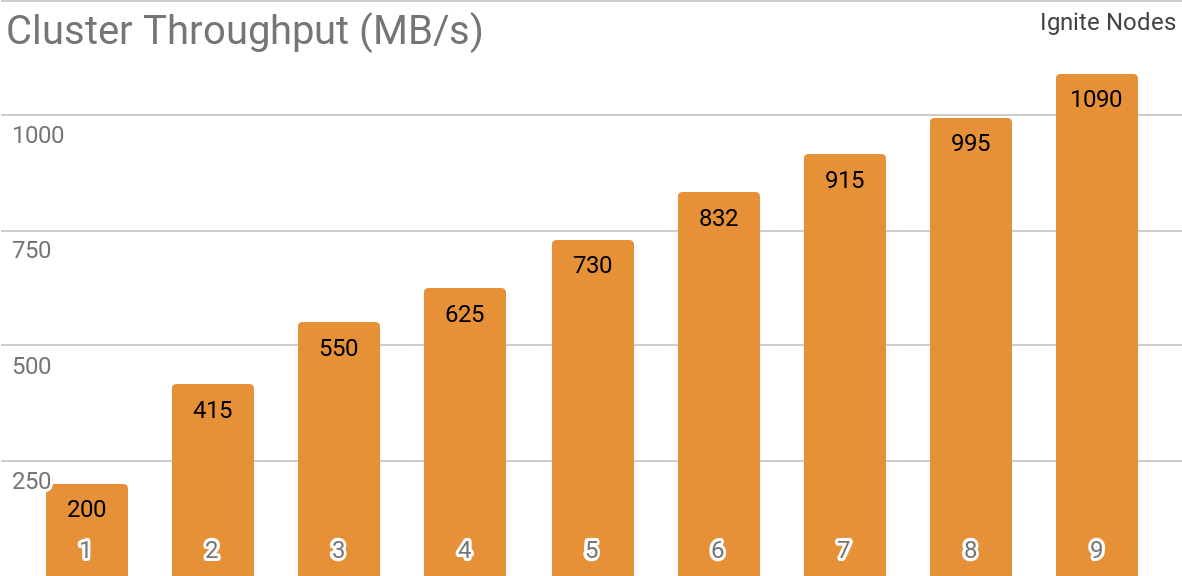
O gráfico mostra a taxa de transferência do Ignite Dataset para um cluster distribuído do Apache Ignite com um número diferente de nós (de 1 a 9). Esses resultados foram obtidos em um processador 2x Xeon E5-2609 v4 1.7GHz com 16 GB de RAM e em uma rede com uma largura de banda de 10 GB / s (cada registro tem tamanho de 1 MB, tamanho da página - 20 MB).
O cenário a seguir foi testado: o cache do Apache Ignite (com um número variável de partições no primeiro conjunto de testes e com 2048 no segundo) é preenchido com 10K linhas de 1 MB cada, após as quais o cliente TensorFlow lê dados usando o Ignite Dataset. O cluster foi construído a partir de máquinas com 2x Xeon E5-2609 v4 a 1,7 GHz, 16 GB de memória e conectado através de uma rede que opera a uma velocidade de 10 GB / s. Em cada nó, o Apache Ignite trabalhou na
configuração padrão .
O Apache Ignite é fácil de usar como um banco de dados clássico com interface SQL e ao mesmo tempo como fonte de dados para o TensorFlow.
$ apache-ignite/bin/ignite.sh $ apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR); INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY'); INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY'); INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE") for element in dataset: print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}} {'key': 2, 'val': {'NAME': b'SOFT KITTY'}} {'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
Objetos estruturados
O Apache Ignite permite armazenar objetos de qualquer tipo que possam ser construídos em qualquer hierarquia. Você pode trabalhar com ele através do Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES") for element in dataset.take(1): print(element)
{ 'key': 'kitten.png', 'val': { 'metadata': { 'file_name': b'kitten.png', 'label': b'little ball of fur', 'width': 800, 'height': 600 }, 'pixels': [0, 0, 0, 0, ..., 0] } }
O treinamento em rede neural e outros cálculos requerem pré-processamento, o que pode ser feito como parte do pipeline
tf.data se você usar o Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels']) for element in dataset: print(element)
[0, 0, 0, 0, ..., 0]
Treinamento distribuído
O TensorFlow é uma estrutura de aprendizado de máquina que
suporta aprendizado de rede neural distribuída, inferência e outra computação. Como você sabe, o treinamento da rede neural é baseado no cálculo dos gradientes da função de perda. No caso de treinamento distribuído, podemos calcular esses gradientes em cada partição e agregá-los. É esse método que permite calcular gradientes para nós individuais nos quais os dados são armazenados, resumi-los e, finalmente, atualizar os parâmetros do modelo. E, como nos livramos da transmissão de dados de amostra de treinamento entre nós, a rede não se torna o "gargalo" do sistema.
O Apache Ignite usa particionamento horizontal (sharding) para armazenar dados em um cluster distribuído. Ao criar o cache do Apache Ignite (ou uma tabela, em termos de SQL), você pode especificar o número de partições entre as quais os dados serão distribuídos. Por exemplo, se um cluster do Apache Ignite consistir em 100 máquinas e criarmos um cache com 1000 partições, cada máquina será responsável por cerca de 10 partições com dados.
O Ignite Dataset permite usar esses dois aspectos para o treinamento distribuído de redes neurais. Ignite Dataset é o nó do
gráfico de computação que forma a base da arquitetura TensorFlow. E, como qualquer nó em um gráfico, ele pode ser executado em um nó remoto no cluster. Esse nó remoto é capaz de substituir os parâmetros Ignite Dataset (por exemplo,
host ,
port ou
part ), configurando as variáveis de ambiente apropriadas para o fluxo de trabalho (por exemplo,
IGNITE_DATASET_HOST ,
IGNITE_DATASET_PORT ou
IGNITE_DATASET_PART ). Usando essa substituição, você pode atribuir uma partição específica a cada nó do cluster. Em seguida, um nó é responsável por uma partição e, ao mesmo tempo, o usuário recebe uma única fachada de trabalho com o conjunto de dados.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset dataset = IgniteDataset("IMAGES")
O Apache Ignite também permite aprendizado distribuído usando a biblioteca
API de alto nível do
Estimador TensorFlow. Essa funcionalidade é baseada no modo
cliente autônomo de aprendizado distribuído no TensorFlow, onde o Apache Ignite atua como uma fonte de dados e sistema de gerenciamento de cluster. O próximo artigo será inteiramente dedicado a este tópico.
Aprendendo o armazenamento do ponto de controle
Além dos recursos de banco de dados, o Apache Ignite também possui um sistema de arquivos
IGFS distribuído. Funcionalmente, ele se assemelha ao sistema de arquivos Hadoop HDFS, mas apenas na RAM. Juntamente com suas próprias APIs, o sistema de arquivos IGFS implementa a API do Hadoop FileSystem e pode se conectar de forma transparente ao Hadoop ou Spark implantado. A biblioteca TensorFlow no Apache Ignite fornece integração entre IGFS e TensorFlow. A integração é baseada no plug-in do
sistema de arquivos do TensorFlow e na API IGFS nativa do Apache Ignite. Existem vários cenários para seu uso, por exemplo:
- Os pontos de verificação de status são armazenados no IGFS para confiabilidade e tolerância a falhas.
- Os processos de aprendizado interagem com o TensorBoard gravando arquivos de eventos em um diretório monitorado pelo TensorBoard. O IGFS garante que essas comunicações estejam operacionais, mesmo quando o TensorBoard estiver sendo executado em outro processo ou em outra máquina.
Essa funcionalidade apareceu no lançamento do TensorFlow 1.13.0.rc0 e também fará parte do
tensorflow / io no lançamento do TensorFlow 2.0.
Conexão SSL
O Apache Ignite permite proteger canais de dados usando
SSL e autenticação. O Ignite Dataset suporta conexões SSL com e sem autenticação. Consulte a documentação do
Apache Ignite SSL / TLS para obter mais detalhes.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES", certfile="client.pem", cert_password="password", username="ignite", password="ignite")
Suporte do Windows
O Ignite Dataset é totalmente compatível com o Windows. Ele pode ser usado como parte do TensorFlow em uma estação de trabalho Windows, bem como em sistemas Linux / MacOS.
Experimente você mesmo
Os exemplos abaixo ajudarão você a iniciar o módulo.
Ignorar conjunto de dados
A maneira mais fácil de iniciar o Ignite Dataset é iniciar o contêiner do
Docker com o Apache Ignite e os dados do
MNIST baixados e, em seguida, trabalhar com ele usando o Ignite Dataset. Esse contêiner está disponível no Docker Hub:
dmitrievanthony / ignite-with-mnist . Você precisa executar o contêiner em sua máquina:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
Depois disso, você pode trabalhar com ele da seguinte maneira:
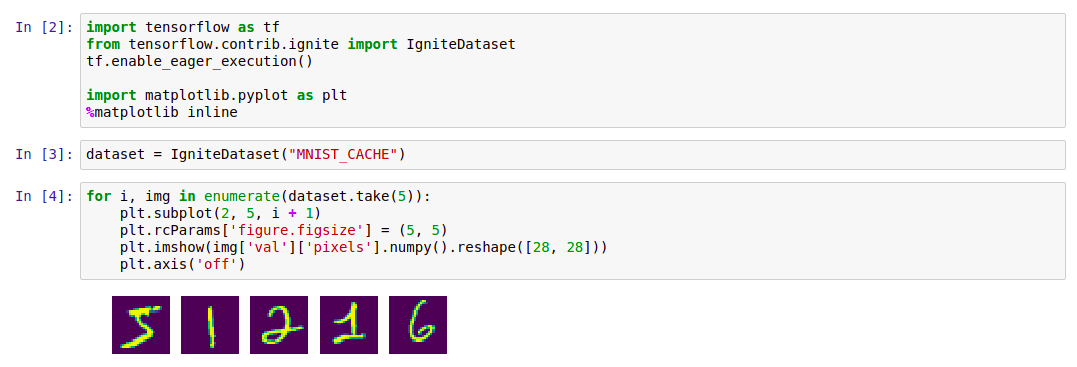
Código import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() import matplotlib.pyplot as plt %matplotlib inline dataset = IgniteDataset("MNIST_CACHE") for i, img in enumerate(dataset.take(5)): plt.subplot(2, 5, i + 1) plt.rcParams['figure.figsize'] = (5, 5) plt.imshow(img['val']['pixels'].numpy().reshape([28, 28])) plt.axis('off')
IGFS
O suporte ao TensorFlow IGFS apareceu na versão 1.13.0rc0 do TensorFlow e também fará parte da versão
io / tensorflow no TensorFlow 2.0. Para experimentar o IGFS com o TensorFlow, a maneira mais fácil de iniciar um contêiner do
Docker é com o Apache Ignite + IGFS e trabalhe com ele usando o TensorFlow
tf.gfile . Esse contêiner está disponível no Docker Hub:
dmitrievanthony / ignite-with-igfs . Este contêiner pode ser executado em sua máquina:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
Então você pode trabalhar assim:
import tensorflow as tf import tensorflow.contrib.ignite.python.ops.igfs_ops with tf.gfile.Open("igfs:///hello.txt", mode='w') as w: w.write("Hello, world!") with tf.gfile.Open("igfs:///hello.txt", mode='r') as r: print(r.read())
Hello, world!
Limitações
Atualmente, ao trabalhar com o Ignite Dataset, presume-se que todos os objetos no cache tenham a mesma estrutura (objetos homogêneos) e que o cache contenha pelo menos um objeto necessário para recuperar o esquema. Outra limitação diz respeito aos objetos estruturados: o Ignite Dataset não suporta UUIDs, Mapas e matrizes de Objetos, que podem fazer parte de um objeto. A remoção dessas restrições, bem como a estabilização e sincronização de versões do TensorFlow e Apache Ignite, é uma das tarefas do desenvolvimento em andamento.
Versão esperada do TensorFlow 2.0
As próximas alterações no TensorFlow 2.0 destacarão esses recursos no módulo
tensorflow / io . Depois disso, o trabalho com eles pode ser construído com mais flexibilidade. Os exemplos mudarão um pouco, e isso será refletido no gihab e na documentação.