Graças à análise em tempo real, nós, funcionários da Uber, temos uma idéia do estado das coisas e da eficiência do trabalho e, com base nos dados, decidimos como melhorar a qualidade do trabalho na plataforma Uber. Por exemplo, a equipe do projeto monitora o estado do mercado e identifica possíveis problemas em nossa plataforma; software baseado em modelos de aprendizado de máquina prevê ofertas e demanda de passageiros por motoristas; especialistas em processamento de dados estão melhorando os modelos de aprendizado de máquina - por sua vez, para melhorar a qualidade da previsão.

No passado, para análise em tempo real, usamos soluções de banco de dados de outras empresas, mas nenhuma atendia a todos os nossos critérios de funcionalidade, escalabilidade, eficiência, custo e requisitos operacionais.
Lançado em novembro de 2018, o AresDB é uma ferramenta de análise em tempo real de código aberto. Ele usa uma fonte de alimentação não convencional, processadores gráficos (GPU), que permite aumentar a escala da análise. A tecnologia GPU, uma promissora ferramenta de análise em tempo real, avançou significativamente nos últimos anos, tornando-a ideal para computação paralela em tempo real e processamento de dados.
Nas seções a seguir, descrevemos a estrutura do AresDB e como essa solução interessante para análise em tempo real nos permitiu unificar, simplificar e melhorar de maneira mais eficiente e racional as soluções de banco de dados Uber para análise em tempo real. Esperamos que, depois de ler este artigo, você experimente o AresDB como parte de seus próprios projetos e também verifique sua utilidade!
Aplicativos de análise em tempo real Uber
A análise dos dados é fundamental para o sucesso do Uber. Entre outras funções, ferramentas analíticas são usadas para resolver as seguintes tarefas:
- Construindo painéis para monitorar métricas de negócios.
- Tomar decisões automáticas (por exemplo, determinar o custo de uma viagem e identificar casos de fraude ) com base nas métricas de resumo coletadas.
- Crie consultas aleatórias para diagnosticar, solucionar problemas e solucionar problemas de operações comerciais.
Categorizamos essas funções com requisitos diferentes da seguinte maneira:

Os painéis e os sistemas de tomada de decisão usam sistemas de análise em tempo real para criar consultas semelhantes em subconjuntos de dados relativamente pequenos, mas altamente importantes (com o mais alto nível de relevância dos dados) com QPS alto e baixa latência.
Necessidade de outro módulo analítico
O problema mais comum que o Uber usa ferramentas de análise em tempo real para resolver é calcular populações de séries temporais. Esses cálculos dão uma idéia das interações do usuário, para que possamos melhorar a qualidade dos serviços de acordo. Com base neles, solicitamos indicadores para determinados parâmetros (por exemplo, dia, hora, identificador da cidade e status da viagem) por um determinado período de tempo para dados filtrados aleatoriamente (ou às vezes combinados). Ao longo dos anos, o Uber implantou vários sistemas projetados para resolver esse problema de várias maneiras.
Aqui estão algumas soluções de terceiros que usamos para resolver esse tipo de problema:
- O Apache Pinot , um banco de dados analítico de código aberto distribuído escrito em Java, é adequado para análise de dados em larga escala. O Pinot usa uma arquitetura lambda interna para consultar dados de pacotes e dados em tempo real no armazenamento de colunas, um índice de bits invertido para filtragem e uma árvore em estrela para armazenar em cache os resultados agregados. No entanto, ele não oferece suporte a deduplicação com base em chave, atualização ou inserção, mesclagem ou recursos avançados de consulta, como filtragem geoespacial. Além disso, como o Pinot é um banco de dados baseado em JVM, a consulta é muito cara em termos de uso de memória.
- O Elasticsearch é usado pelo Uber para resolver várias tarefas de análise de streaming. Ele é construído com base na biblioteca Apache Lucene , que armazena documentos para pesquisa de palavras-chave em texto completo e um índice invertido. O sistema é amplo e expandido para suportar dados agregados. Um índice invertido fornece filtragem, mas não é otimizado para armazenar e filtrar dados com base em intervalos de tempo. Os registros são armazenados na forma de documentos JSON, o que impõe custos adicionais para fornecer acesso ao repositório e solicitações. Como o Pinot, o Elasticsearch é um banco de dados baseado em JVM e, consequentemente, não suporta a função de junção, e a execução da consulta ocupa uma grande quantidade de memória.
Embora essas tecnologias tenham seus pontos fortes, eles não possuíam alguns dos recursos necessários para o nosso caso de uso. Precisávamos de uma solução unificada, simplificada e otimizada e, em sua pesquisa, trabalhamos em uma direção fora do padrão (mais precisamente, dentro da GPU).
Usando GPU para análise em tempo real
Para renderização realista de imagens com alta taxa de quadros, as GPUs processam simultaneamente um grande número de formas e pixels em alta velocidade. Embora a tendência de aumentar a frequência de clock das unidades de processamento de dados nos últimos anos tenha começado a diminuir, o número de transistores no chip aumentou apenas de acordo com a lei de Moore . Como resultado, a velocidade de computação da GPU, medida em gigaflops por segundo (Gflops / s), está aumentando rapidamente. A Figura 1 abaixo mostra uma comparação da tendência teórica de velocidade (Gflops / s) da GPU NVIDIA e da CPU Intel ao longo dos anos:
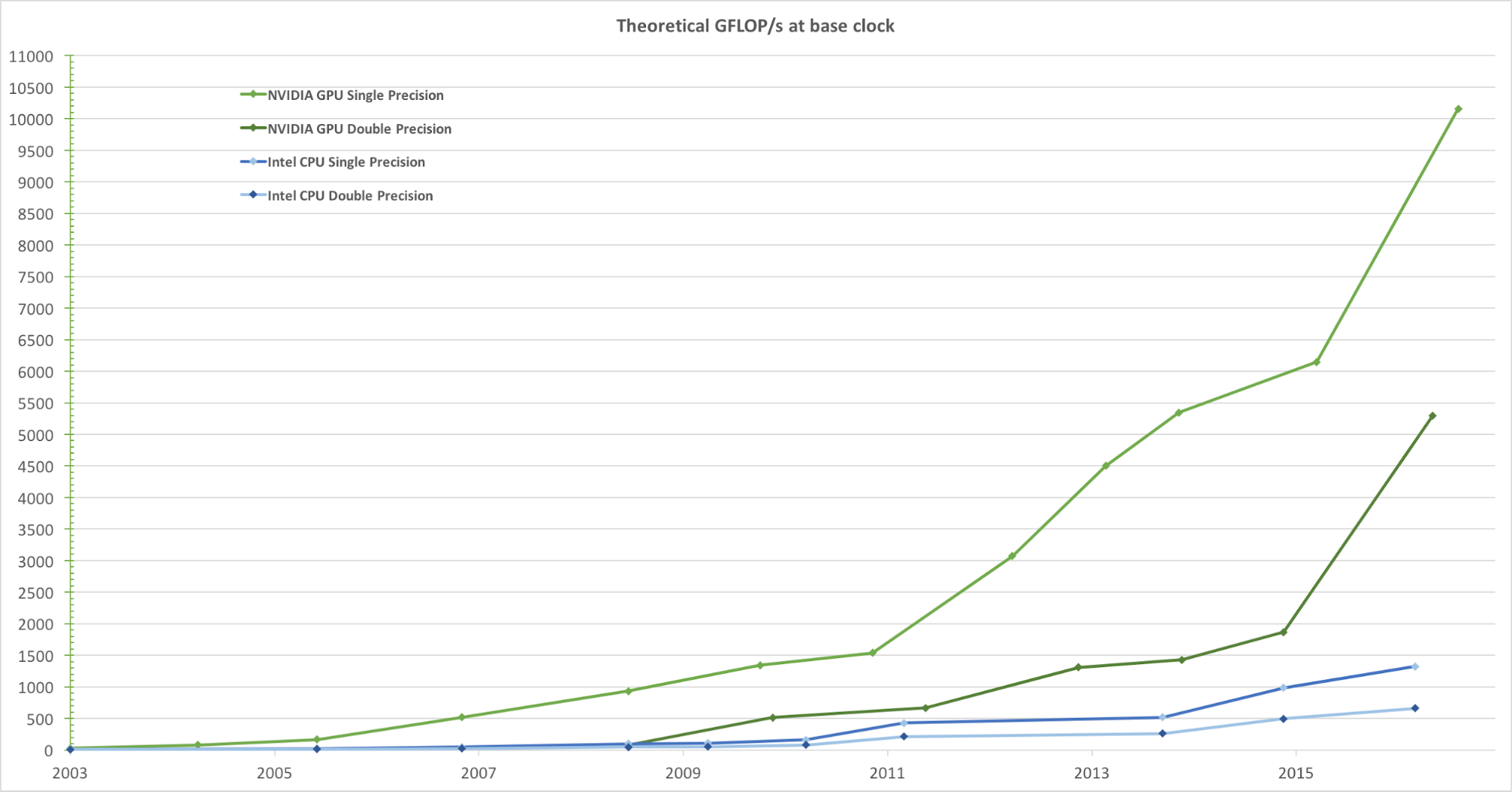
Figura 1. Comparação do desempenho da CPU e GPU de ponto flutuante de precisão única ao longo de vários anos. Imagem tirada do Guia de Programação CUDA C da Nvidia.
Ao desenvolver o mecanismo de solicitação de análise em tempo real, a decisão de integrar a GPU foi natural. No Uber, uma solicitação típica de análise em tempo real exige o processamento de dados em alguns dias com milhões ou até bilhões de registros, filtrando-os e resumindo-os em um curto período de tempo. Essa tarefa computacional se encaixa perfeitamente no modelo de processamento paralelo da GPU de uso geral, porque eles:
- Eles processam dados em paralelo com uma velocidade muito alta.
- Eles fornecem uma velocidade computacional mais alta (Gflops / s), o que os torna excelentes para executar tarefas computacionais complexas (em blocos de dados) que podem ser paralelizadas.
- Eles oferecem maior desempenho (sem demora) na troca de dados entre a unidade de computação e o armazenamento (ALU e GPU de memória global) em comparação com as unidades de processamento central (CPUs), tornando-os ideais para o processamento de tarefas de E / S de memória paralela, que requer uma quantidade significativa de dados.
Focando no uso de um banco de dados analítico baseado em GPU, nós - do ponto de vista de nossas necessidades - avaliamos várias soluções analíticas existentes que usam GPUs:
- O Kinetica , uma ferramenta analítica baseada em GPU, chegou ao mercado em 2009, inicialmente para uso no Exército dos EUA e em agências de inteligência. Embora demonstre o alto potencial da tecnologia GPU na análise, descobrimos que, para nossas condições de uso, muitas funções importantes estão ausentes, incluindo alteração do esquema, inserção ou atualização parcial, compactação de dados, configuração de disco e memória no nível da coluna e conexão por relações geoespaciais.
- O OmniSci , um módulo de consulta SQL de código aberto, parecia uma opção promissora, mas ao avaliar o produto, percebemos que faltava alguns recursos importantes para uso no Uber, como a desduplicação. Embora o OminiSci tenha introduzido o código-fonte aberto de seu projeto em 2017, após analisar sua solução com base em C ++, chegamos à conclusão de que nem alterar nem ramificar sua base de código é praticamente viável.
- As ferramentas de análise em tempo real baseadas em GPU, incluindo GPUQP , CoGaDB , GPUDB , Ocelot , OmniDB e Virginian , são frequentemente usadas em instituições educacionais e de pesquisa. No entanto, considerando seus objetivos acadêmicos, essas decisões se concentram no desenvolvimento de algoritmos e conceitos de teste, em vez de resolver problemas do mundo real. Por esse motivo, não os levamos em consideração - nas condições de nosso volume e escala.
No geral, esses sistemas demonstram a enorme vantagem e o potencial de processamento de dados usando a tecnologia GPU e nos inspiraram a criar nossa própria solução de análise em tempo real da GPU, adaptada às necessidades do Uber. Com base nesses conceitos, desenvolvemos e abrimos o código fonte do AresDB.
Visão geral da arquitetura do AresDB
Em um nível alto, o AresDB armazena a maioria dos dados na memória do host (RAM, que está conectada à CPU), usa a CPU para processar dados e discos recebidos para recuperar dados. Durante o período de solicitação, o AresDB transfere dados da memória do host para a memória da GPU para processamento paralelo na GPU. Conforme mostrado na Figura 2 abaixo, o AresDB inclui armazenamento de memória, armazenamento de metadados e disco:

Figura 2. A arquitetura exclusiva do AresDB inclui armazenamento de memória, disco e armazenamento de metadados.
Tabelas
Diferentemente da maioria dos sistemas de gerenciamento de banco de dados relacional (RDBMS), o AresDB não possui um escopo de banco de dados ou esquema. Todas as tabelas pertencem ao mesmo escopo em um cluster / instância do AresDB, que permite aos usuários acessá-las diretamente. Os usuários armazenam seus dados na forma de tabelas de fatos e tabelas de dimensões.
Tabela de fatos
A tabela de fatos armazena um fluxo interminável de eventos de séries temporais. Os usuários usam uma tabela de fatos para armazenar eventos / fatos que ocorrem em tempo real, e cada evento é associado à hora do evento, e a tabela é frequentemente consultada pela hora do evento. Como exemplo do tipo de informação armazenada na tabela de fatos, podemos nomear viagens, onde cada viagem é um evento, e a hora de uma solicitação de viagem é frequentemente indicada como a hora do evento. Se vários registros de data e hora estiverem associados a um evento, apenas um registro de data e hora será indicado como a hora do evento e será exibido na tabela de fatos.
Tabela de medição
A tabela de medidas armazena as características atuais das instalações (incluindo cidades, clientes e motoristas). Por exemplo, os usuários podem armazenar informações sobre a cidade, em particular o nome da cidade, fuso horário e país, na tabela de medidas. Diferentemente das tabelas de fatos, que estão em constante crescimento, as tabelas de dimensões são sempre limitadas em tamanho (por exemplo, para Uber, a tabela de cidades é limitada pelo número real de cidades no mundo). As tabelas de medidas não requerem uma coluna de tempo especial.
Tipos de dados
A tabela abaixo mostra os tipos de dados atuais suportados pelo AresDB:
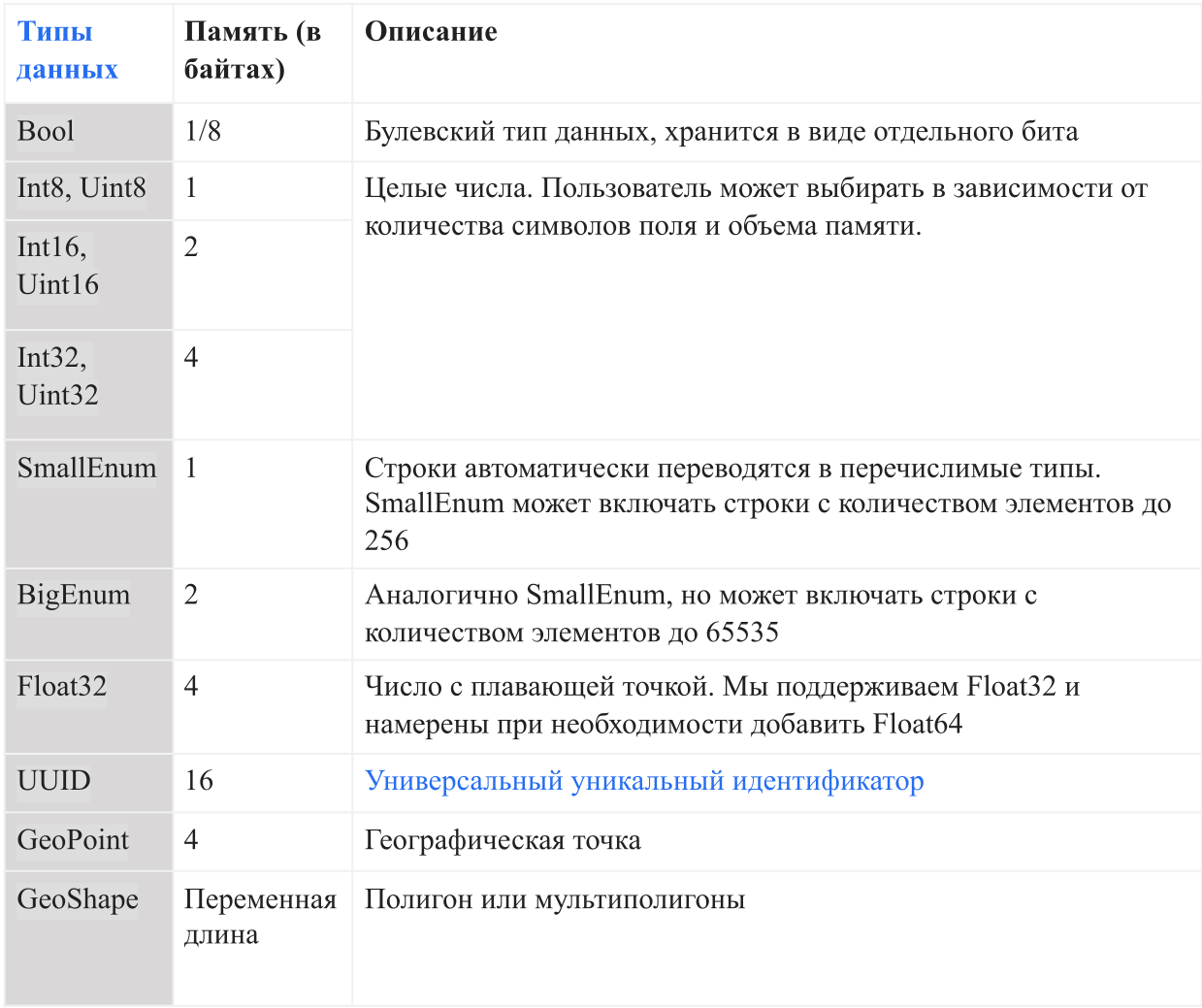
No AresDB, as seqüências de caracteres são convertidas em enumerações automaticamente antes de entrarem no banco de dados para aumentar a conveniência de armazenamento e eficiência da consulta. Isso permite verificações de igualdade com distinção entre maiúsculas e minúsculas, mas não suporta operações avançadas, como concatenação, substrings, máscaras e correspondência de expressão regular. No futuro, pretendemos adicionar a opção de suporte de linha completa.
Funções principais
A arquitetura do AresDB suporta os seguintes recursos:
- Armazenamento baseado em coluna com compactação para aumentar a eficiência do armazenamento (menos memória em bytes para armazenamento de dados) e eficiência da consulta (menos troca de dados entre a memória da CPU e a memória da GPU ao processar uma solicitação)
- Atualização ou inserção em tempo real com desduplicação da chave primária para melhorar a precisão dos dados e atualizar os dados em tempo real em alguns segundos
- Processamento de solicitação de GPU para processamento de dados de GPU altamente paralelo com baixa latência de solicitação (de frações de segundo a vários segundos)
Armazenamento da coluna
Vetor
O AresDB armazena todos os dados em um formato de coluna. Os valores de cada coluna são armazenados como um vetor de valor da coluna. O marcador de confiança / incerteza dos valores em cada coluna é armazenado em um vetor zero separado, enquanto o marcador de confiança de cada valor é apresentado como um bit.
Armazenamento ativo
O AresDB armazena dados da coluna não compactados e não classificados (vetores ativos) no armazenamento ativo. Os registros de dados no armazenamento ativo são divididos em pacotes (ativos) de um determinado volume. Novos pacotes são criados quando os dados são recebidos, enquanto pacotes antigos são excluídos após o arquivamento de registros. O índice de chave primária é usado para localizar registros de desduplicação e atualização. A Figura 3 abaixo mostra como organizamos os registros ativos e usamos o valor da chave primária para determinar sua localização:
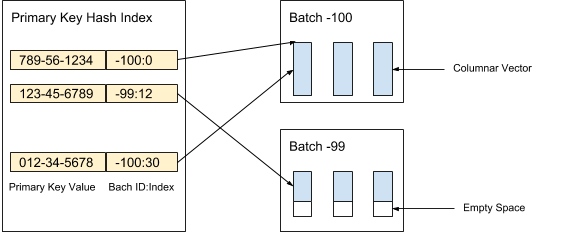
Figura 3. Usamos o valor da chave primária para determinar a localização do pacote e a posição de cada registro dentro do pacote.
Os valores de cada coluna no pacote são armazenados como um vetor de coluna. O marcador de confiabilidade / incerteza dos valores em cada vetor de valor é armazenado como um vetor zero separado, e o marcador de confiabilidade de cada valor é apresentado como um bit. Na Figura 4 abaixo, oferecemos um exemplo com cinco valores para a coluna city_id :
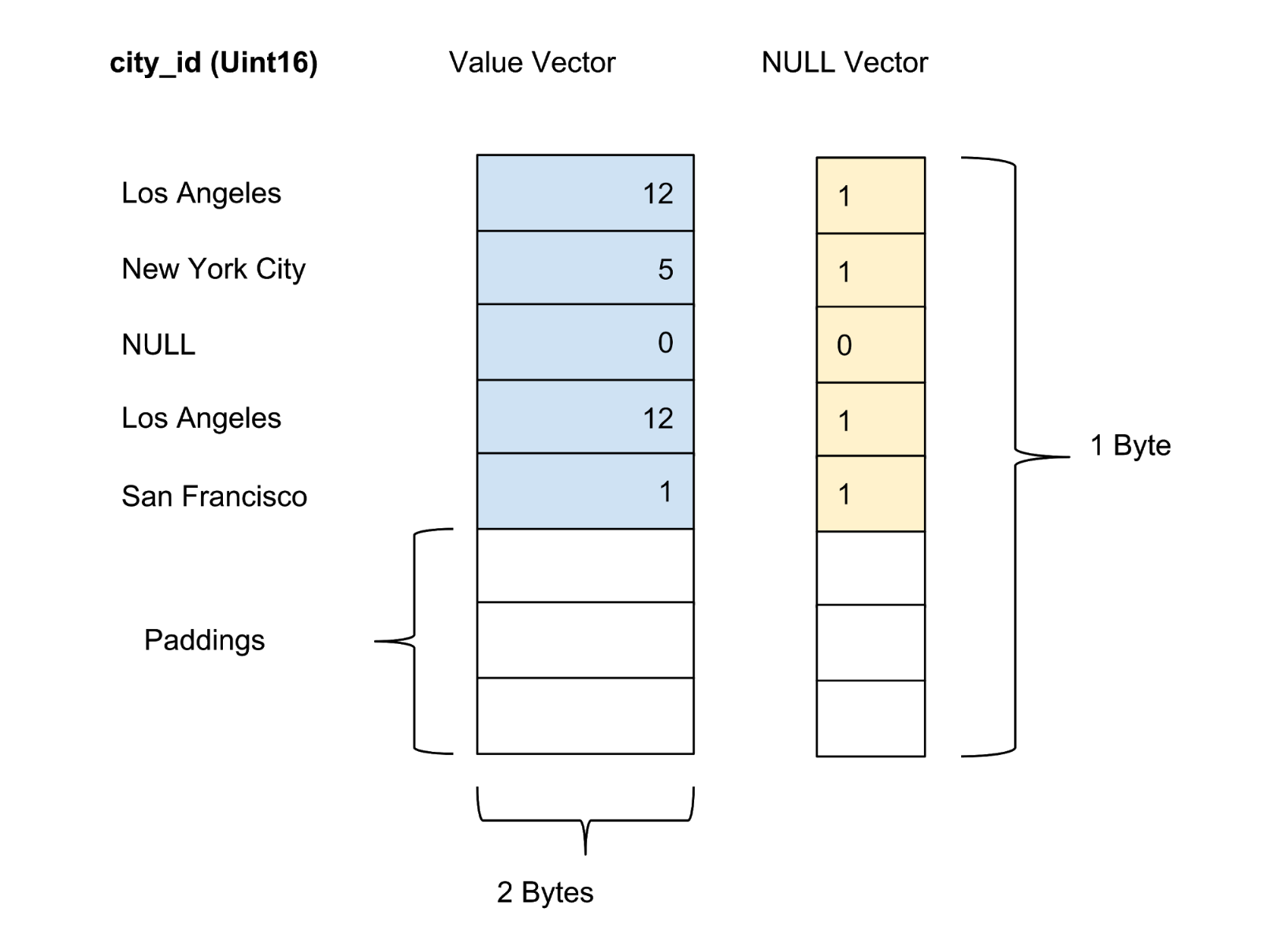
Figura 4. Armazenamos valores (valor real) e vetores zero (marcador de confiança) de colunas não compactadas na tabela de dados.
Armazenamento de arquivo
O AresDB também armazena dados de coluna concluídos, classificados e compactados (vetores de archive) no armazenamento de archive através de tabelas de fatos. Os registros no armazenamento do arquivo morto também são distribuídos em lotes. Diferentemente dos pacotes ativos, o pacote de archive armazena registros por dia, de acordo com o Tempo Universal Coordenado (UTC). Um pacote de archive usa o número de dias como identificador de pacote desde o Unix Epoch.
Os registros são armazenados na forma classificada de acordo com uma ordem de classificação da coluna definida pelo usuário. Como mostra a Figura 5 abaixo, classificamos primeiro pela coluna city_id e depois pela coluna status:
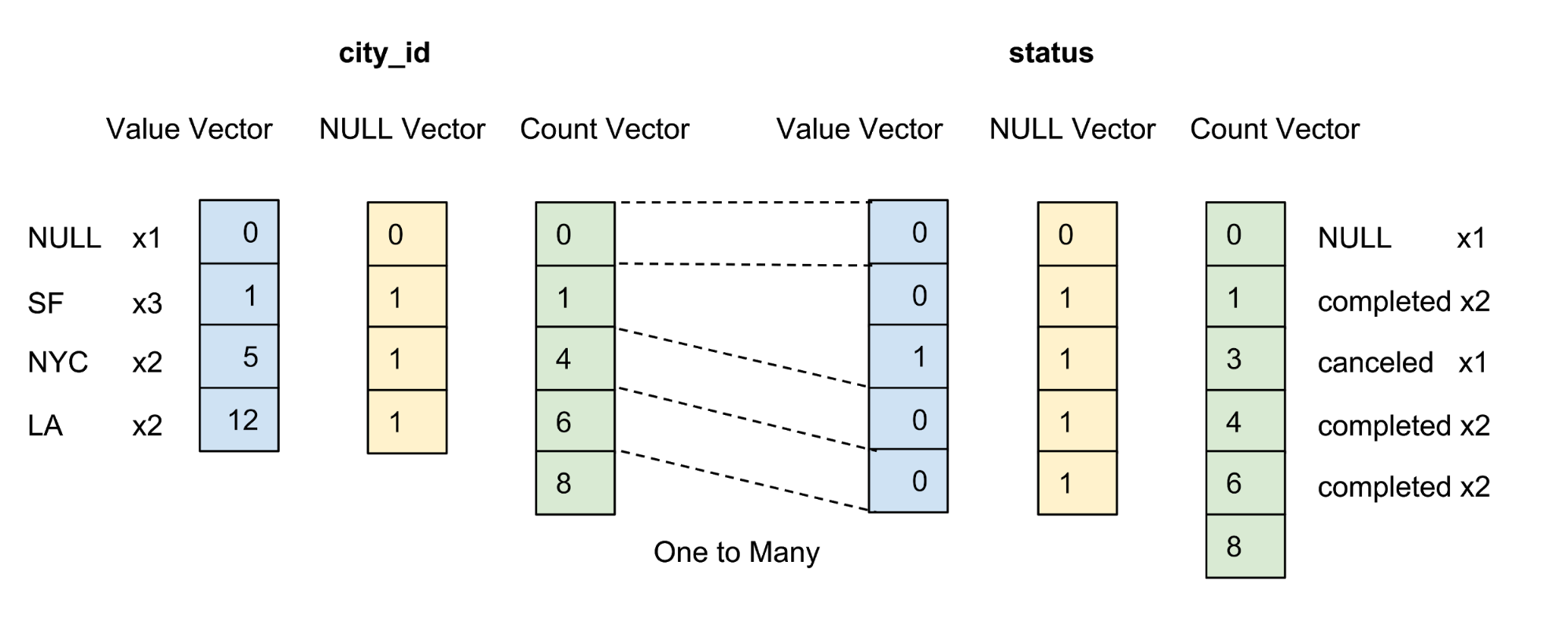
Figura 5. Classificamos todas as linhas por city_id, depois por estado e, em seguida, compactamos cada coluna por codificação de grupo. Após a classificação e compactação, cada coluna receberá um vetor contábil.
O objetivo de definir a ordem de classificação do usuário para as colunas é o seguinte:
- Maximizando o efeito de compactação classificando colunas com um pequeno número de elementos em primeiro lugar. A compactação máxima melhora a eficiência do armazenamento (menos bytes são necessários para armazenar dados) e a eficiência da consulta (menos bytes são transferidos entre a memória da CPU e a memória da GPU).
- Fornecendo uma pré-filtragem conveniente baseada em intervalo para filtros equivalentes comuns, por exemplo, city_id = 12. A pré-filtragem minimiza o número de bytes necessários para transferir dados entre a memória da CPU e a memória da GPU, o que maximiza a eficiência da consulta.
Uma coluna é compactada apenas se estiver presente na ordem de classificação especificada pelo usuário. Não estamos tentando compactar colunas com um grande número de elementos, pois isso economiza pouca memória.
Após a classificação, os dados para cada coluna qualificada são compactados usando uma opção de codificação de grupo específica. Além do vetor de valor e do vetor zero, introduzimos um vetor de contabilidade para representar novamente o mesmo valor.
Recepção de dados em tempo real com suporte para funções de atualização e inserção
Os clientes recebem dados através da API HTTP publicando um service pack. Um service pack é um formato binário ordenado especial que minimiza o uso de espaço enquanto mantém o acesso aleatório aos dados.
Quando o AresDB recebe o service pack, ele primeiro grava o service pack no log da operação de recuperação. Quando um service pack é adicionado ao final do log de eventos, o AresDB identifica e ignora as entradas atrasadas nas tabelas de fatos para uso no armazenamento ativo. Um registro é considerado "atrasado" se o horário do evento for anterior ao horário do arquivo desconectado. Para registros que não são considerados "atrasados", o AresDB usa o índice de chave primária para localizar o pacote dentro do armazenamento ativo onde você deseja inseri-los. Conforme mostrado na Figura 6 abaixo, novos registros (não encontrados anteriormente com base no valor da chave primária) são inseridos no espaço vazio e os registros existentes são atualizados diretamente:
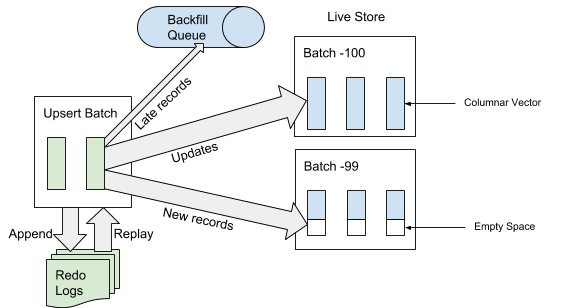
Figura 6. Quando os dados são recebidos, após adicionar o service pack ao log de eventos, as entradas "atrasadas" são adicionadas à fila reversa e outras entradas ao armazenamento ativo.
Arquivamento
Quando os dados são recebidos, os registros são adicionados / atualizados no armazenamento ativo ou adicionados à fila reversa, aguardando a colocação no armazenamento do arquivo morto.
Periodicamente, iniciamos um processo agendado, chamado de arquivamento, em relação aos registros do armazenamento ativo para anexar novos registros (registros que nunca foram arquivados antes) ao armazenamento do arquivo morto. O processo de arquivamento processa apenas registros no armazenamento ativo com o tempo do evento no intervalo entre o tempo de desligamento antigo (tempo de desligamento do último processo de arquivamento) e o novo tempo de desligamento (novo tempo de desligamento com base no parâmetro de atraso de arquivamento no esquema da tabela).
O horário do evento de registro é usado para determinar em quais registros do pacote de archive devem ser combinados ao compactar dados do archive em pacotes diários. O arquivamento não requer deduplicação do índice do valor da chave primária durante a mesclagem, pois apenas os registros no intervalo entre o antigo e o novo tempo de desligamento são arquivados.
A Figura 7 abaixo mostra um gráfico de acordo com a hora do evento de um registro específico.
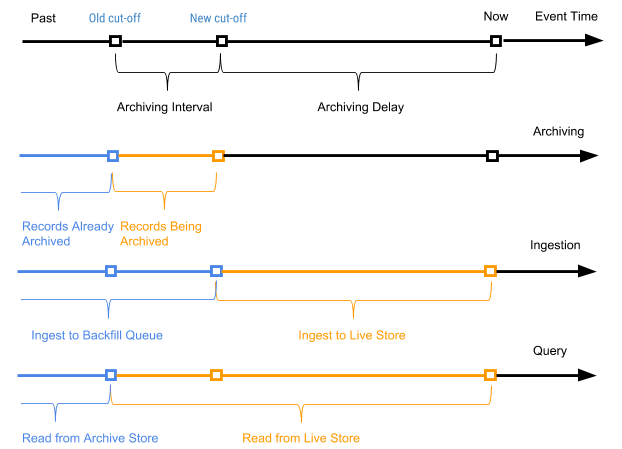
Figura 7. Usamos o tempo do evento e o tempo da viagem para definir os registros como novos (ativos) e antigos (a hora do evento é anterior ao tempo arquivado do evento da viagem).
Nesse caso, o intervalo de arquivamento é o intervalo de tempo entre os dois processos de arquivamento, e o atraso no arquivamento é o período após o horário do evento, mas até que o evento seja arquivado. Ambos os parâmetros são definidos nas configurações do esquema da tabela AresDB.
Preenchimento
Conforme mostrado na Figura 7 acima, os registros antigos (cuja hora do evento é anterior à hora do arquivamento do evento de desligamento) das tabelas de fatos são adicionados à fila reversa e, finalmente, são processados como parte do processo de aterramento. Os gatilhos desse processo também são o tempo ou o tamanho da fila reversa, se atingir um nível limite. Comparado ao processo de adicionar dados ao armazenamento ativo, o preenchimento é assíncrono e relativamente mais caro em termos de CPU e recursos de memória. O preenchimento é usado nos seguintes cenários:
- Processando dados aleatórios e muito atrasados
- Captura manual de dados históricos de um fluxo de dados upstream
- Inserindo dados históricos em colunas adicionadas recentemente
Diferentemente do arquivamento, o processo de preenchimento é idempotente e requer desduplicação com base no valor da chave primária. Os dados preenchíveis ficarão visíveis para as consultas.
A fila reversa é mantida na memória com um tamanho predefinido e, com uma grande carga de aterro, o processo será bloqueado para o cliente até que a fila seja limpa iniciando o processo de aterro.
Processamento de solicitação
Na implementação atual, o usuário precisa usar a Ares Query Language (AQL) criada pelo Uber para executar consultas no AresDB. O AQL é uma linguagem eficaz para consultas analíticas de séries temporais e não segue a sintaxe padrão do SQL, como “SELECT FROM WHERE GROUP BY”, como outras linguagens semelhantes ao SQL. Em vez disso, o AQL é usado em campos estruturados e pode ser incluído nos objetos JSON, YAML e Go. Por exemplo, em vez da /SELECT (*) /FROM /GROUP BY city_id, /WHERE = «» /AND request_at >= 1512000000 , a variante AQL equivalente em JSON é escrita da seguinte maneira:
{ “table”: “trips”, “dimensions”: [ {“sqlExpression”: “city_id”} ], “measures”: [ {“sqlExpression”: “count(*)”} ], ;”> “rowFilters”: [ “status = 'completed'” ], “timeFilter”: { “column”: “request_at”, “from”: “2 days ago” } }
No formato JSON, o AQL oferece aos desenvolvedores de um painel e sistema de tomada de decisão um algoritmo de consulta de programa mais conveniente que o SQL, permitindo que eles possam compor consultas e manipulá-las facilmente usando o código sem se preocupar com coisas como a injeção de SQL. Ele atua como um formato de consulta universal para arquiteturas típicas de navegadores da web, servidores externos e internos até o banco de dados (AresDB). Além disso, o AQL fornece uma sintaxe conveniente para filtragem por hora e lote, com suporte para seu próprio fuso horário. Além disso, o idioma suporta várias funções, como subconsultas implícitas, para evitar erros comuns em consultas e facilita o processo de análise e reescrita de consultas para desenvolvedores da interface interna.
Apesar dos muitos benefícios que o AQL oferece, sabemos que a maioria dos engenheiros está mais familiarizada com o SQL. O fornecimento de uma interface SQL para execução de consultas é uma das próximas etapas que consideraremos como parte de nossos esforços para melhorar a interação com os usuários do AresDB.
O fluxograma de execução da consulta AQL é mostrado na Figura 8 abaixo:
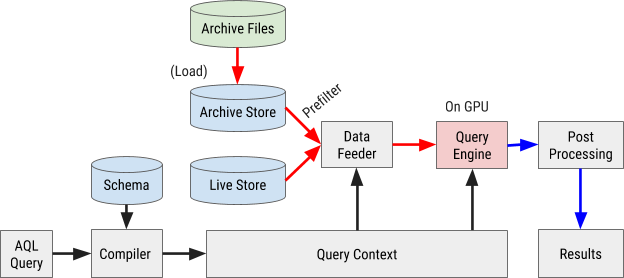
Figura 8. O fluxograma de consulta do AresDB usa nossa própria linguagem de consulta AQL para processar e recuperar dados de maneira rápida e eficiente.
Compilação de consultas
Uma consulta AQL é compilada no contexto interno da consulta. Expressões em filtros, medidas e parâmetros são analisados em árvores de sintaxe abstrata (AST) para processamento adicional através de um processador gráfico (GPU).
Carregamento de dados
O AresDB usa pré-filtros para filtrar dados de arquivamento mais baratos antes de enviá-los à GPU para processamento paralelo. Como os dados arquivados são classificados de acordo com a ordem das colunas configuradas, alguns filtros podem usar essa ordem de classificação e o método de pesquisa binária para determinar o intervalo apropriado de correspondência. Em particular, filtros equivalentes para todas as colunas X classificadas inicialmente e um filtro de intervalo opcional para as colunas classificadas X + 1 podem ser usados como filtros preliminares, conforme mostrado na Figura 9 abaixo.

Figura 9. O AresDB pré-filtra os dados da coluna antes de enviá-los à GPU para processamento.
Após a pré-filtragem, somente os valores verdes (que atendem às condições do filtro) devem ser enviados à GPU para processamento paralelo. Os dados de entrada são carregados na GPU e processados um pacote por vez. Isso inclui pacotes ativos e pacotes de arquivamento.
O AresDB usa fluxos CUDA para pipelining e processamento de dados. Para cada solicitação, dois fluxos são aplicados alternadamente para processamento em dois estágios sobrepostos. Na Figura 10 abaixo, oferecemos um gráfico que ilustra esse processo.
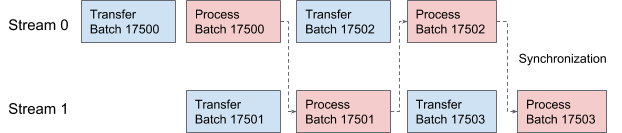
Figura 10. No AresDB, dois threads CUDA transmitem e processam dados alternadamente.
Execução de consulta
Por uma questão de simplicidade, o AresDB usa a biblioteca Thrust para implementar procedimentos de execução de consultas, que oferecem blocos de um algoritmo paralelo ajustado para uma rápida implementação de consultas na ferramenta atual.
No Thrust, os dados vetoriais de entrada e saída são avaliados usando iteradores de acesso aleatório. Cada encadeamento da GPU procura por iteradores de entrada em sua posição de trabalho, lê os valores e executa cálculos e depois grava o resultado na posição correspondente no iterador de saída.
Para avaliar expressões do AresDB, segue o modelo "um operador por núcleo" (OOPK).
Na Figura 11 abaixo, esse procedimento é demonstrado usando o exemplo AST gerado a partir da expressão de dimensão request_at – request_at % 86400 no estágio de compilação do pedido:
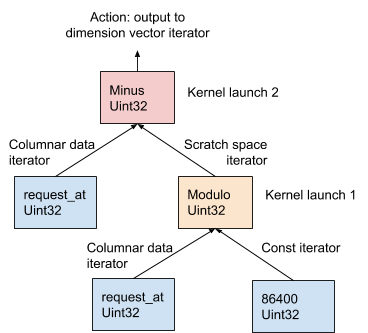
Figura 11. O AresDB usa o modelo OOPK para avaliar expressões.
No modelo OOPK, o mecanismo de consulta AresDB ignora cada nó folha da árvore AST e retorna um iterador para o nó de origem. Se o nó raiz também for finito, a ação raiz será executada diretamente no iterador de entrada.
Para cada nó não-raiz não-raiz ( operação de módulo neste exemplo), um vetor de espaço de trabalho temporário é alocado para armazenar o resultado intermediário obtido da expressão request_at% 86400 . Usando o Thrust, uma função do kernel é iniciada para calcular o resultado dessa instrução na GPU. Os resultados são armazenados no iterador da área de trabalho.
Para um nó raiz, a função kernel é executada da mesma maneira que para um nó não raiz e não finito. Várias ações de saída são executadas com base no tipo de expressão, descrito em detalhes abaixo:
- Filtragem para reduzir o número de elementos do vetor de entrada
- Gravando dados de saída de medição em um vetor de medição para mesclagem de dados subsequente
- Registre a saída dos parâmetros no vetor de parâmetros para mesclagem de dados subsequente
Após avaliar a expressão, a classificação e a transformação são executadas para finalmente combinar os dados. Nas operações de classificação e transformação, usamos os valores do vetor de dimensão como valores-chave para classificação e transformação, e os valores do vetor de parâmetro como valores para combinar dados. Assim, linhas com valores de dimensão semelhantes são agrupadas e combinadas. A Figura 12 abaixo mostra esse processo de classificação e conversão.
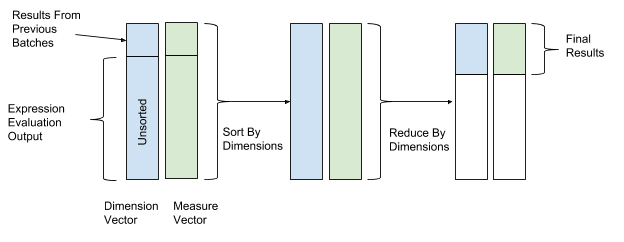
Figura 12. Após avaliar a expressão, o AresDB classifica e converte os dados de acordo com os valores-chave dos vetores de medição (valor-chave) e parâmetros (valor).
O AresDB também suporta as seguintes funções avançadas de consulta:
- Associação: o AresDB atualmente suporta uma opção de associação de hash entre a tabela de fatos e a tabela de dimensões
- Estimando o número de itens do Hyperloglog : O AresDB usa o algoritmo Hyperloglog
- Geo Intersect : atualmente, o AresDB suporta apenas operações interconectadas entre o GeoPoint e o GeoShape
Gerenciamento de recursos
Como um banco de dados baseado na memória interna, o AresDB deve gerenciar os seguintes tipos de uso de memória:
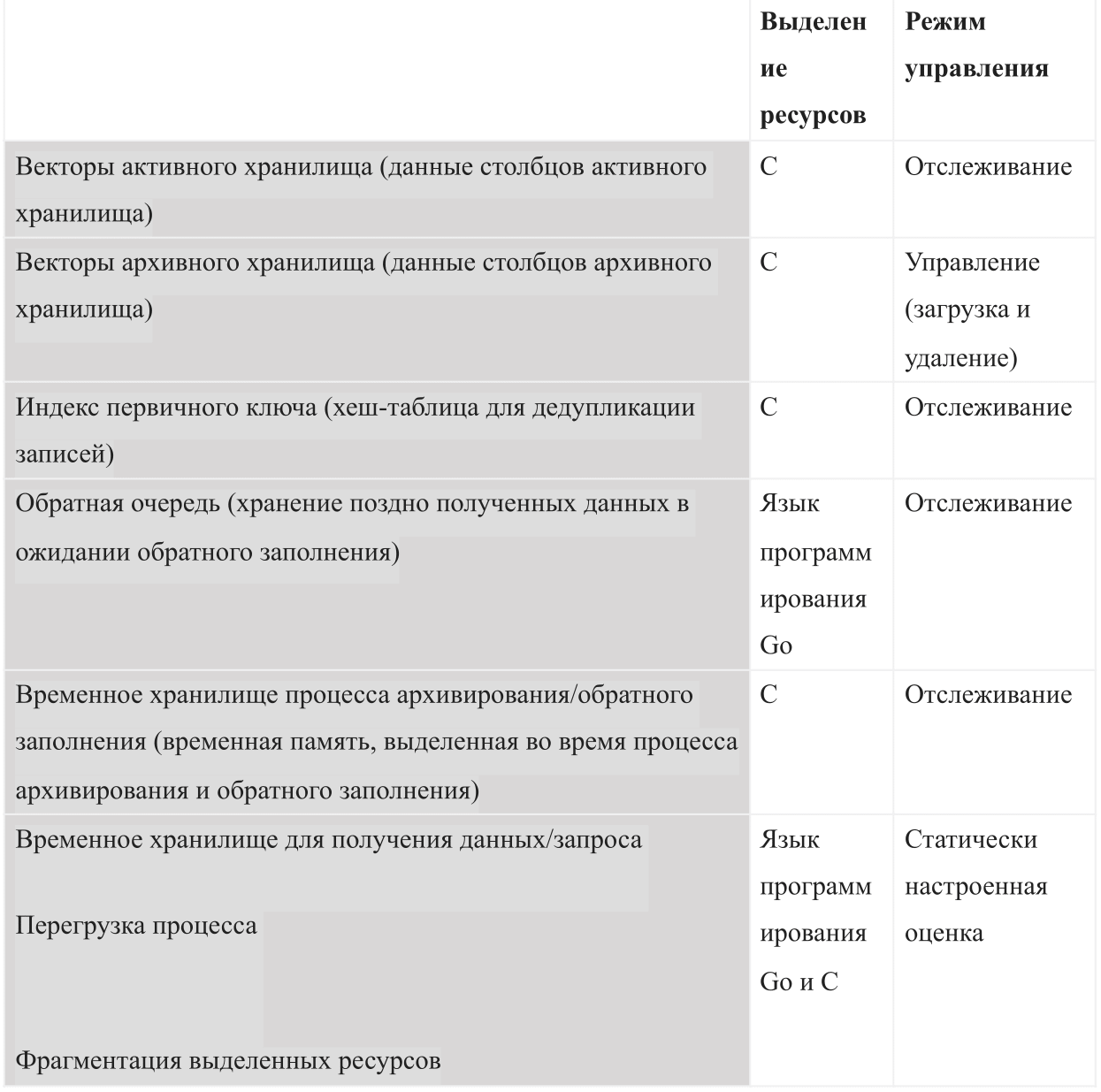
Quando o AresDB é inicializado, ele usa o orçamento de memória compartilhada configurado. O orçamento é dividido em todos os seis tipos de memória e também deve deixar espaço suficiente para o sistema operacional e outros processos. Esse orçamento também inclui uma estimativa de congestionamento configurada estaticamente, um armazenamento de dados ativo monitorado pelo servidor e dados arquivados que o servidor pode decidir baixar e excluir, dependendo do orçamento de memória restante.
A Figura 13 abaixo mostra o modelo de memória do host do AresDB.
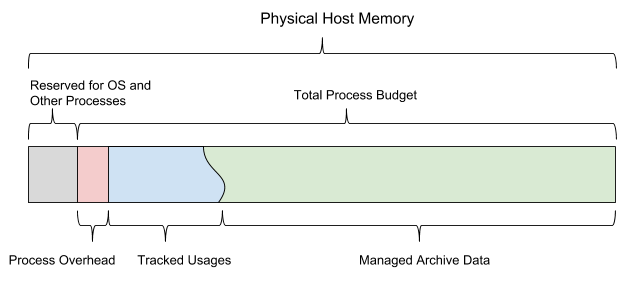
Figura 13. O AresDB gerencia seu próprio uso de memória para que não exceda o orçamento total do processo configurado.
O AresDB permite que os usuários definam dias de pré-carregamento e prioridades no nível da coluna para tabelas de fatos e pré-carregam dados arquivados apenas nos dias de pré-carregamento. Os dados que não foram baixados anteriormente são carregados na memória a partir do disco sob demanda. Quando preenchido, o AresDB também exclui dados arquivados da memória do host. Os princípios da remoção do AresDB são baseados nos seguintes parâmetros: número de dias de pré-carregamento, prioridades das colunas, dia da compilação do pacote e tamanho da coluna.
O AresDB também gerencia vários dispositivos da GPU e simula os recursos do dispositivo como threads da GPU e memória do dispositivo, rastreando o uso da memória da GPU para processar solicitações. O AresDB gerencia dispositivos da GPU por meio de um gerenciador de dispositivos que modela os recursos do dispositivo em duas dimensões (threads da GPU e memória do dispositivo) e rastreia o uso da memória ao processar solicitações. Após compilar a solicitação, o AresDB permite aos usuários estimar a quantidade de recursos necessários para concluir a solicitação. Os requisitos de memória do dispositivo devem ser atendidos antes que a solicitação seja resolvida; se atualmente houver memória insuficiente em qualquer dispositivo, a solicitação deverá aguardar. Atualmente, o AresDB pode executar uma ou mais solicitações no mesmo dispositivo GPU ao mesmo tempo, se o dispositivo atender a todos os requisitos de recursos.
Na implementação atual, o AresDB não armazena em cache a entrada na memória do dispositivo para reutilização em várias solicitações. O AresDB visa dar suporte a consultas em conjuntos de dados que são constantemente atualizados em tempo real e mal armazenados em cache corretamente. Nas versões futuras do AresDB, pretendemos implementar funções para armazenar dados em cache na memória da GPU, o que ajudará a otimizar o desempenho da consulta.
No Uber, usamos o AresDB para criar painéis para obter informações comerciais em tempo real. O AresDB é responsável por armazenar eventos primários com atualizações constantes e calcular métricas críticas para eles em uma fração de segundo, graças aos recursos da GPU a baixo custo, para que os usuários possam usar os painéis interativamente. Por exemplo, dados de viagem anonimizados com um longo período de validade no data warehouse são atualizados por vários serviços, incluindo nosso sistema de despacho, sistemas de pagamento e preços. Para fazer uso eficiente dos dados de viagem, os usuários dividem e dividem dados em diferentes dimensões para obter informações sobre soluções em tempo real.
Ao usar o AresDB, o painel do Uber é um painel de análise generalizado usado pelas equipes da empresa para produzir métricas relevantes e respostas em tempo real para melhorar a experiência do usuário.
14. Uber AresDB .
, , :
( )

( )

AresDB
, , AresDB :

, , , , , .
AresDB , Apache Kafka , , Apache Flink Apache Spark .
AresDB
, « » « ». , -. 24 AQL:

:
, , .

, AresDB , , . AresDB , , .
Próximas etapas
AresDB Uber , . , , AresDB .
:
- : AresDB, , , .
- : AresDB 2018 , , AresDB .
- : , , , .
- : , (LLVM) GPU.
AresDB Apache. AresDB .
, .
Agradecimentos
(Kate Zhang), (Jennifer Anderson), (Nikhil Joshi), (Abhi Khune), (Shengyue Ji), (Chinmay Soman), (Xiang Fu), (David Chen) (Li Ning) , !