Olá pessoal.
Eu decidi compartilhar uma solução simples e espaçosa na minha opinião de uma rede neural em C ++.
Por que essa informação deve ser interessante?Resposta: Tentei programar o trabalho do perceptron multicamada em um conjunto mínimo, para que ele pudesse ser configurado como eu gosto em apenas algumas linhas de código, e a implementação dos algoritmos básicos para trabalhar em “C” permitirá transferir facilmente as linguagens orientadas para “C” (em e para qualquer outro)
sem usar bibliotecas de terceiros!Por favor, dê uma olhada no que veio dele
Não vou falar sobre o
objetivo das redes neurais , espero que você não tenha sido banido do
Google e encontre as informações de seu interesse (objetivo, recursos, aplicativos e assim por diante).
Você encontrará o
código fonte no final do artigo, mas por enquanto, em ordem.
Vamos começar a análise
1) Arquitetura e detalhes técnicos
-
perceptron multicamada com a capacidade de configurar qualquer número de camadas com uma determinada largura. Abaixo é apresentado
exemplo de configuraçãomyNeuero.cppinputNeurons = 100;
Observe que a configuração da largura da entrada e saída de cada camada é realizada de acordo com uma determinada regra - a entrada da camada atual = a saída da anterior. Uma exceção é a camada de entrada.
Portanto, você tem a oportunidade de definir qualquer configuração manualmente ou de acordo com uma regra especificada antes de compilar ou após a compilação para ler dados dos arquivos de origem.
- implementação do mecanismo de
propagação traseira de erros com a capacidade de definir a velocidade de aprendizado
myNeuero.h #define learnRate 0.1
- instalação de
pesos iniciaismyNeuero.h #define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5))
Nota : se houver mais de três camadas (nlCount> 4), é necessário aumentar o pow (saída, -0,5) para que, quando o sinal passa diretamente, sua energia não se reduz a 0. Exemplo de pow (saída, -0,2)
- a
base do código em C. Os algoritmos básicos e o armazenamento dos coeficientes de ponderação são implementados como uma estrutura em C; todo o resto é a concha da função de chamada dessa estrutura; também é um reflexo de qualquer uma das camadas tiradas separadamente.
Estrutura de camadamyNeuero.h struct nnLay{ int in; int out; float** matrix; float* hidden; float* errors; int getInCount(){return in;} int getOutCount(){return out;} float **getMatrix(){return matrix;} void updMatrix(float *enteredVal) { for(int ou =0; ou < out; ou++) { for(int hid =0; hid < in; hid++) { matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); } matrix[in][ou] += (learnRate * errors[ou]); } }; void setIO(int inputs, int outputs) { in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) { matrix[inp] = (float*) malloc(out*sizeof(float)); } for(int inp =0; inp < in+1; inp++) { for(int outp =0; outp < out; outp++) { matrix[inp][outp] = randWeight; } } } void makeHidden(float *inputs) { for(int hid =0; hid < out; hid++) { float tmpS = 0.0; for(int inp =0; inp < in; inp++) { tmpS += inputs[inp] * matrix[inp][hid]; } tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); } }; float* getHidden() { return hidden; }; void calcOutError(float *targets) { errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) { errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); } }; void calcHidError(float *targets,float **outWeights,int inS, int outS) { errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) { errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) { errors[hid] += targets[ou] * outWeights[hid][ou]; } errors[hid] *= sigmoidasDerivate(hidden[hid]); } }; float* getErrors() { return errors; }; float sigmoida(float val) { return (1.0 / (1.0 + exp(-val))); } float sigmoidasDerivate(float val) { return (val * (1.0 - val)); }; };
2) Aplicação
Testando o projeto com o conjunto mnist foi bem-sucedido, conseguimos obter uma probabilidade condicional de reconhecimento de manuscrito de 0,9795 (nlCount = 4, learnRate = 0,03 e várias épocas). O principal objetivo do teste era testar o desempenho da rede neural com a qual ela lidava.
Abaixo, consideramos o trabalho sobre a
"tarefa condicional" .
Dados de origem:-2 vetores de entrada aleatórios de 100 valores
rede neural com geração aleatória de pesos
-2 estabelecer metas
O código na função main ()
{
O resultado da rede neural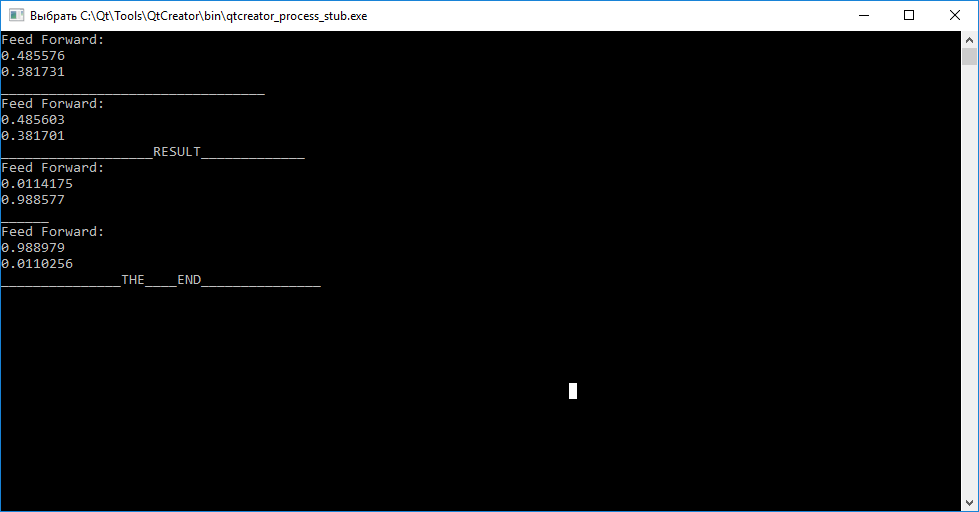
Sumário
Como você pode ver, chamar a função de consulta (entradas) antes do treinamento para cada um dos vetores não nos permite julgar suas diferenças. Além disso, chamando a função train (input, target), para treinamento com o objetivo de organizar coeficientes de peso para que a rede neural possa subsequentemente distinguir entre vetores de entrada.
Após concluir o treinamento, observamos que a tentativa de mapear o vetor “abc” para “tar1” e “cba” para “tar2” falhou.
Você tem a oportunidade, usando o código-fonte, de testar independentemente o desempenho e experimentar a configuração!PS: este código foi escrito a partir do QtCreator, espero que você possa substituir facilmente a saída, deixar seus comentários e comentários.
PPS: se alguém estiver interessado em uma análise detalhada do trabalho de struct nnLay {} write, haverá uma nova postagem.
PPPS: Espero que alguém possa usar o código orientado a "C" para portar para outras ferramentas.
Código fontemain.cpp #include <QCoreApplication> #include <QDebug> #include <QTime> #include "myneuro.h" int main(int argc, char *argv[]) { QCoreApplication a(argc, argv); myNeuro *bb = new myNeuro(); //----------------------------------INPUTS----GENERATOR------------- qsrand((QTime::currentTime().second())); float *abc = new float[100]; for(int i=0; i<100;i++) { abc[i] =(qrand()%98)*0.01+0.01; } float *cba = new float[100]; for(int i=0; i<100;i++) { cba[i] =(qrand()%98)*0.01+0.01; } //---------------------------------TARGETS----GENERATOR------------- float *tar1 = new float[2]; tar1[0] =0.01; tar1[1] =0.99; float *tar2 = new float[2]; tar2[0] =0.99; tar2[1] =0.01; //--------------------------------NN---------WORKING--------------- bb->query(abc); qDebug()<<"_________________________________"; bb->query(cba); int i=0; while(i<100000) { bb->train(abc,tar1); bb->train(cba,tar2); i++; } qDebug()<<"___________________RESULT_____________"; bb->query(abc); qDebug()<<"______"; bb->query(cba); qDebug()<<"_______________THE____END_______________"; return a.exec(); }
myNeuro.cpp #include "myneuro.h" #include <QDebug> myNeuro::myNeuro() { //-------- inputNeurons = 100; outputNeurons =2; nlCount = 4; list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); inputs = (float*) malloc((inputNeurons)*sizeof(float)); targets = (float*) malloc((outputNeurons)*sizeof(float)); list[0].setIO(100,20); list[1].setIO(20,6); list[2].setIO(6,3); list[3].setIO(3,2); //----------------- // inputNeurons = 100; // outputNeurons =2; // nlCount = 2; // list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); // inputs = (float*) malloc((inputNeurons)*sizeof(float)); // targets = (float*) malloc((outputNeurons)*sizeof(float)); // list[0].setIO(100,10); // list[1].setIO(10,2); } void myNeuro::feedForwarding(bool ok) { list[0].makeHidden(inputs); for (int i =1; i<nlCount; i++) list[i].makeHidden(list[i-1].getHidden()); if (!ok) { qDebug()<<"Feed Forward: "; for(int out =0; out < outputNeurons; out++) { qDebug()<<list[nlCount-1].hidden[out]; } return; } else { // printArray(list[3].getErrors(),list[3].getOutCount()); backPropagate(); } } void myNeuro::backPropagate() { //-------------------------------ERRORS-----CALC--------- list[nlCount-1].calcOutError(targets); for (int i =nlCount-2; i>=0; i--) list[i].calcHidError(list[i+1].getErrors(),list[i+1].getMatrix(), list[i+1].getInCount(),list[i+1].getOutCount()); //-------------------------------UPD-----WEIGHT--------- for (int i =nlCount-1; i>0; i--) list[i].updMatrix(list[i-1].getHidden()); list[0].updMatrix(inputs); } void myNeuro::train(float *in, float *targ) { inputs = in; targets = targ; feedForwarding(true); } void myNeuro::query(float *in) { inputs=in; feedForwarding(false); } void myNeuro::printArray(float *arr, int s) { qDebug()<<"__"; for(int inp =0; inp < s; inp++) { qDebug()<<arr[inp]; } }
myNeuro.h #ifndef MYNEURO_H #define MYNEURO_H #include <iostream> #include <math.h> #include <QtGlobal> #include <QDebug> #define learnRate 0.1 #define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5)) class myNeuro { public: myNeuro(); struct nnLay{ int in; int out; float** matrix; float* hidden; float* errors; int getInCount(){return in;} int getOutCount(){return out;} float **getMatrix(){return matrix;} void updMatrix(float *enteredVal) { for(int ou =0; ou < out; ou++) { for(int hid =0; hid < in; hid++) { matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); } matrix[in][ou] += (learnRate * errors[ou]); } }; void setIO(int inputs, int outputs) { in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) { matrix[inp] = (float*) malloc(out*sizeof(float)); } for(int inp =0; inp < in+1; inp++) { for(int outp =0; outp < out; outp++) { matrix[inp][outp] = randWeight; } } } void makeHidden(float *inputs) { for(int hid =0; hid < out; hid++) { float tmpS = 0.0; for(int inp =0; inp < in; inp++) { tmpS += inputs[inp] * matrix[inp][hid]; } tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); } }; float* getHidden() { return hidden; }; void calcOutError(float *targets) { errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) { errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); } }; void calcHidError(float *targets,float **outWeights,int inS, int outS) { errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) { errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) { errors[hid] += targets[ou] * outWeights[hid][ou]; } errors[hid] *= sigmoidasDerivate(hidden[hid]); } }; float* getErrors() { return errors; }; float sigmoida(float val) { return (1.0 / (1.0 + exp(-val))); } float sigmoidasDerivate(float val) { return (val * (1.0 - val)); }; }; void feedForwarding(bool ok); void backPropagate(); void train(float *in, float *targ); void query(float *in); void printArray(float *arr,int s); private: struct nnLay *list; int inputNeurons; int outputNeurons; int nlCount; float *inputs; float *targets; }; #endif // MYNEURO_H
UPD:
As fontes para checar o mnist são:
o link1) Projeto
"
Github.com/mamkin-itshnik/simple-neuro-network "
Há também uma descrição gráfica do trabalho. Resumidamente, ao pesquisar dados de teste na rede, você recebe o valor de cada um dos neurônios de saída (10 neurônios correspondem a números de 0 a 9). Para tomar uma decisão sobre a figura representada, você precisa conhecer o índice do neurônio máximo. Dígito = índice + 1 (não esqueça de onde são numerados os números nas matrizes))
2) MNIST
“
Www.kaggle.com/oddrationale/mnist-in-csv ” (se você precisar usar um conjunto de dados menor, basta limitar o contador while ao ler o arquivo CSV do PS: existe um exemplo para o git)