Nota perev. : Os funcionários do Tinder recentemente compartilharam alguns dos detalhes técnicos da migração de sua infraestrutura para o Kubernetes. O processo levou quase dois anos e resultou no lançamento nos K8s de uma plataforma de grande escala, composta por 200 serviços hospedados em 48 mil contêineres. Que dificuldades interessantes os engenheiros do Tinder enfrentaram e que resultados chegaram - leia esta tradução.
Porque
Há quase dois anos, o Tinder decidiu mudar sua plataforma para o Kubernetes. O Kubernetes permitiria à equipe do Tinder contêiner e mudar para a operação com o mínimo de esforço por meio de uma
implantação imutável . Nesse caso, o conjunto de aplicativos, sua implantação e a própria infraestrutura seriam determinados exclusivamente pelo código.
Também procuramos uma solução para o problema de escalabilidade e estabilidade. Quando o dimensionamento se tornou crítico, muitas vezes tivemos que esperar vários minutos para iniciar novas instâncias do EC2. Portanto, a ideia de lançar contêineres e começar a servir o tráfego em segundos, em vez de minutos, se tornou muito atraente para nós.
O processo não foi fácil. Durante a migração, no início de 2019, o cluster Kubernetes atingiu uma massa crítica e começamos a enfrentar vários problemas devido à quantidade de tráfego, tamanho do cluster e DNS. Nesta jornada, resolvemos muitos problemas interessantes relacionados à transferência de 200 serviços e manutenção do cluster Kubernetes, que consiste em 1000 nós, 15.000 pods e 48.000 contêineres em funcionamento.
Como
Desde janeiro de 2018, passamos por vários estágios de migração. Começamos contendo todos os nossos serviços e implantando-os nos ambientes de teste do Kubernetes. Em outubro, iniciou o processo de transferência metódica de todos os serviços existentes para o Kubernetes. Em março do ano seguinte, a "realocação" foi concluída e agora a plataforma Tinder roda exclusivamente no Kubernetes.
Crie imagens para o Kubernetes
Temos mais de 30 repositórios de código-fonte para microsserviços em execução em um cluster Kubernetes. O código nesses repositórios é escrito em diferentes idiomas (por exemplo, Node.js, Java, Scala, Go) com muitos ambientes de tempo de execução para o mesmo idioma.
O sistema de compilação foi projetado para fornecer um "contexto de compilação" totalmente personalizável para cada microsserviço. Geralmente consiste em um Dockerfile e uma lista de comandos do shell. Seu conteúdo é totalmente personalizável e, ao mesmo tempo, todos esses contextos de compilação são gravados de acordo com um formato padronizado. A padronização de contextos de construção permite que um único sistema de construção lide com todos os microsserviços.
 Figura 1-1. Processo de construção padronizado por meio do construtor de contêiner (Construtor)
Figura 1-1. Processo de construção padronizado por meio do construtor de contêiner (Construtor)Para obter a máxima consistência entre os tempos de execução, o mesmo processo de construção é usado durante o desenvolvimento e o teste. Enfrentamos um problema muito interessante: tivemos que desenvolver uma maneira de garantir a consistência do ambiente de montagem em toda a plataforma. Para fazer isso, todos os processos de montagem são realizados dentro de um contêiner
Builder especial.
Sua implementação exigiu técnicas avançadas para trabalhar com o Docker. O Builder herda o ID do usuário local e os segredos (como a chave SSH, credenciais da AWS, etc.) necessários para acessar os repositórios privados do Tinder. Ele monta diretórios locais que contêm a fonte para armazenar naturalmente artefatos de montagem. Essa abordagem aprimora o desempenho, eliminando a necessidade de copiar artefatos de montagem entre o contêiner do Builder e o host. Os artefatos de montagem armazenados podem ser reutilizados sem configuração adicional.
Para alguns serviços, tivemos que criar outro contêiner para combinar o ambiente de compilação com o tempo de execução (por exemplo, durante o processo de instalação, a biblioteca bode do Node.js. gera artefatos binários específicos da plataforma). Durante a compilação, os requisitos podem variar para diferentes serviços, e o Dockerfile final é compilado em tempo real.
Arquitetura e migração de cluster Kubernetes
Gerenciamento de tamanho de cluster
Decidimos usar o
kube-aws para implantar automaticamente o cluster nas instâncias do Amazon EC2. No início, tudo funcionava em um conjunto comum de nós. Rapidamente percebemos a necessidade de separar as cargas de trabalho por tamanho e tipo de instâncias para um uso mais eficiente dos recursos. A lógica era que o lançamento de vários pods multiencadeados carregados se mostrou mais previsível no desempenho do que sua coexistência com um grande número de pods de encadeamento único.
Como resultado, decidimos:
- m5.4xlarge - para monitoramento (Prometheus);
- c5.4xlarge - para carga de trabalho do Node.js. (carga de trabalho de thread único);
- c5.2xlarge - para Java e Go (carga de trabalho multiencadeada);
- c5.4xlarge - para o painel de controle (3 nós).
A migração
Uma das etapas preparatórias para migrar da infraestrutura antiga para o Kubernetes foi redirecionar a interação direta existente entre os serviços para os novos balanceadores de carga (ELB, Elastic Load Balancers). Eles foram criados em uma sub-rede específica da nuvem privada virtual (VPC). Essa sub-rede foi conectada ao Kubernetes VPC. Isso nos permitiu migrar os módulos gradualmente, sem levar em conta a ordem específica das dependências de serviço.
Esses pontos de extremidade foram criados usando conjuntos ponderados de registros DNS com CNAMEs apontando para cada novo ELB. Para alternar, adicionamos um novo registro apontando para um novo ELB de serviço Kubernetes com um peso de 0. Em seguida, definimos o Time To Live (TTL) do conjunto de registros como 0. Depois disso, os pesos novos e antigos foram ajustados lentamente e, eventualmente, 100% da carga foi perdida. para o novo servidor. Após a conclusão da troca, o valor TTL retornou a um nível mais adequado.
Nossos módulos Java existentes lidavam com DNS TTL baixo, mas os aplicativos Node não. Um dos engenheiros reescreveu parte do código do conjunto de conexões, agrupando-o em um gerente que atualizava os conjuntos a cada 60 segundos. A abordagem escolhida funcionou muito bem e sem uma redução perceptível no desempenho.
As lições
Restrições de dispositivo de rede
Nas primeiras horas da manhã de 8 de janeiro de 2019, a plataforma Tinder caiu de repente. Em resposta a um aumento não relacionado na latência da plataforma no início da manhã, o número de pods e nós no cluster aumentou. Isso levou à exaustão do cache ARP em todos os nossos nós.
Existem três opções do Linux associadas ao cache do ARP:

(
fonte )
gc_thresh3 é um limite rígido. A aparência no log de entradas do formulário “estouro de tabela vizinho” significava que, mesmo após a coleta de lixo síncrona (GC) no cache do ARP, não havia espaço suficiente para armazenar o registro vizinho. Nesse caso, o kernel simplesmente eliminou completamente o pacote.
Usamos a
Flanela como uma
malha de rede no Kubernetes. Pacotes são transmitidos por VXLAN. VXLAN é um túnel L2, erguido sobre uma rede L3. A tecnologia usa o encapsulamento MAC-in-UDP (Protocolo de datagrama de endereço MAC no usuário) e permite expandir os segmentos de rede do 2º nível. O protocolo de transporte na rede física do data center é IP mais UDP.
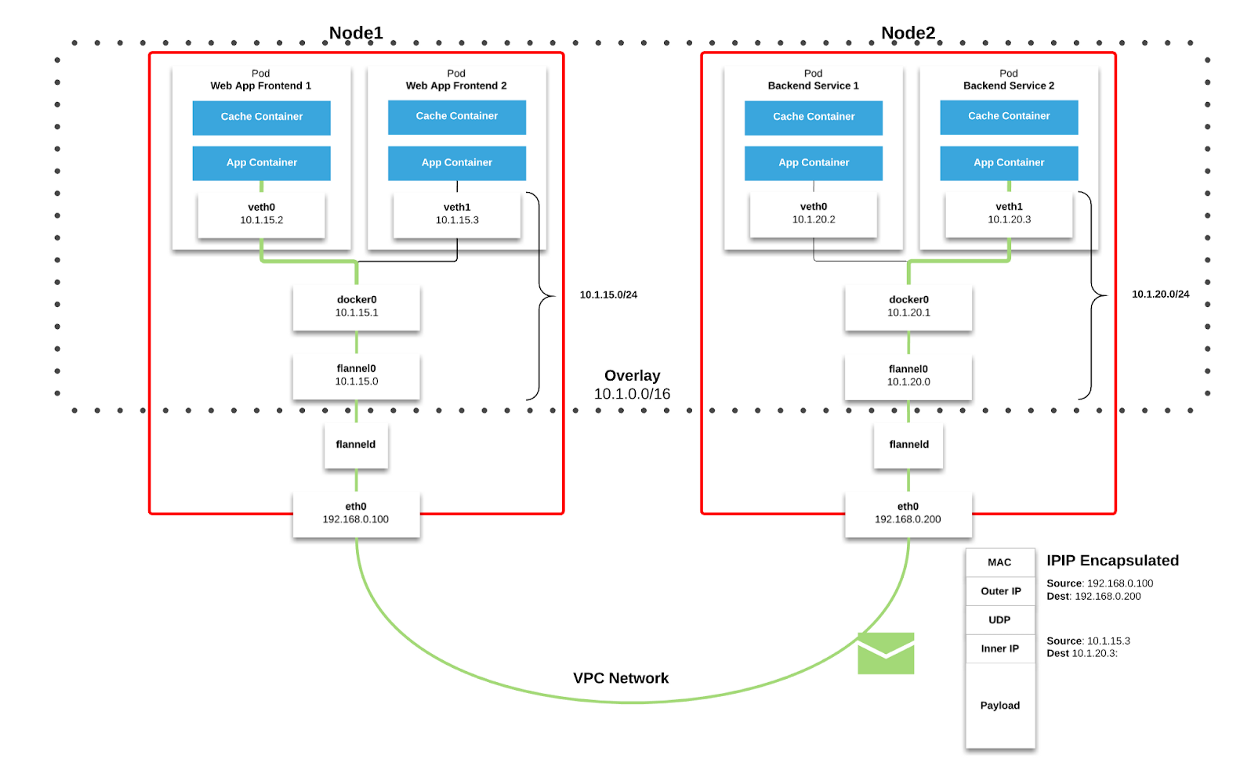 Figura 2-1. Gráfico de flanela ( origem )
Figura 2-1. Gráfico de flanela ( origem ) Figura 2–2. Pacote VXLAN ( origem )
Figura 2–2. Pacote VXLAN ( origem )Cada nó de trabalho do Kubernetes aloca um espaço de endereço virtual com mask / 24 do bloco maior / 9. Para cada nó, isso
significa uma entrada na tabela de roteamento, uma entrada na tabela ARP (na interface
flannel.1 ) e uma entrada na tabela de comutação (FDB). Eles são adicionados quando o nó de trabalho é iniciado pela primeira vez ou quando cada novo nó é detectado.
Além disso, a conexão nó-pod (ou pod-pod) passa pela interface
eth0 (como mostrado no diagrama de flanela acima). Isso resulta em uma entrada adicional na tabela ARP para cada origem e destino correspondente do nó.
Em nosso ambiente, esse tipo de comunicação é muito comum. Para objetos do tipo de serviço no Kubernetes, um ELB é criado e o Kubernetes registra cada nó no ELB. O ELB não sabe nada sobre os pods e o nó selecionado pode não ser o destino final do pacote. O fato é que, quando um nó recebe um pacote do ELB, ele leva em consideração as regras do
iptables para um serviço específico e seleciona aleatoriamente o pod em outro nó.
No momento da falha, o cluster tinha 605 nós. Pelas razões
expostas acima, isso foi suficiente para superar o valor
padrão de gc_thresh3 . Quando isso acontece, não apenas os pacotes começam a ser descartados, mas todo o espaço de endereço virtual da Flanela com a máscara / 24 desaparece da tabela ARP. As comunicações de pod de nó e as consultas DNS são interrompidas (o DNS está hospedado em um cluster; consulte o restante deste artigo para obter detalhes).
Para resolver esse problema, aumente os valores de
gc_thresh1 ,
gc_thresh2 e
gc_thresh3 e reinicie o Flannel para registrar novamente as redes ausentes.
Escala de DNS inesperada
Durante o processo de migração, usamos o DNS ativamente para gerenciar o tráfego e gradualmente transferir serviços da infraestrutura antiga para o Kubernetes. Definimos valores TTL relativamente baixos para RecordSets relacionados no Route53. Quando a infraestrutura antiga estava sendo executada em instâncias do EC2, nossa configuração de resolvedor apontou para o DNS da Amazon. Tomamos isso como garantido e o impacto do baixo TTL em nossos serviços da Amazon (como o DynamoDB) passou quase despercebido.
Como os serviços foram migrados para o Kubernetes, descobrimos que o DNS lida com 250.000 consultas por segundo. Como resultado, os aplicativos começaram a experimentar tempos limites constantes e sérios para consultas de DNS. Isso aconteceu apesar dos esforços incríveis para otimizar e alternar o provedor de DNS para o CoreDNS (que atingiu 1.000 pods rodando em 120 núcleos em pico de carga).
Explorando outras causas e soluções possíveis, encontramos
um artigo descrevendo as condições de corrida que afetam a estrutura de filtragem de pacotes
netfilter no Linux. Os tempos limite observados, juntamente com o crescente contador
insert_failed na interface Flannel, corresponderam às conclusões do artigo.
O problema surge no estágio de conversão de endereço de rede de origem e destino (SNAT e DNAT) e entrada subseqüente na tabela
conntrack . Uma das soluções alternativas discutidas na empresa e propostas pela comunidade foi a transferência do DNS para o próprio nó de trabalho. Nesse caso:
- O SNAT não é necessário porque o tráfego permanece dentro do nó. Ele não precisa ser roteado através da interface eth0 .
- O DNAT não é necessário, porque o IP de destino é local para o host e não um pod selecionado aleatoriamente de acordo com as regras do iptables .
Decidimos seguir essa abordagem. O CoreDNS foi implantado como DaemonSet no Kubernetes e implementamos um servidor DNS local no
resolv.conf de cada pod, configurando o
sinalizador --cluster-dns do comando
kubelet . Esta solução provou ser eficaz para tempos limite de DNS.
No entanto, ainda observamos a perda de pacotes e um aumento no contador
insert_failed na interface Flannel. Essa situação continuou após a introdução da solução alternativa, pois conseguimos excluir o SNAT e / ou DNAT apenas para o tráfego DNS. As condições de corrida persistiram para outros tipos de tráfego. Felizmente, a maioria dos nossos pacotes é TCP e, quando ocorre um problema, eles são simplesmente retransmitidos. Ainda estamos tentando encontrar uma solução adequada para todos os tipos de tráfego.
Usando o enviado para um melhor equilíbrio de carga
Ao migrar os serviços de back-end para o Kubernetes, começamos a sofrer uma carga desequilibrada entre os pods. Descobrimos que, devido ao HTTP Keepalive, as conexões ELB permaneciam nos primeiros pods prontos para cada implantação de lançamento. Assim, a maior parte do tráfego passou por uma pequena porcentagem dos pods disponíveis. A primeira solução que testamos foi definir o parâmetro MaxSurge para 100% em novas implantações para os piores casos. O efeito foi insignificante e pouco promissor em termos de implantações maiores.
Outra solução que usamos foi aumentar artificialmente as solicitações de recursos para serviços de missão crítica. Nesse caso, os pods adjacentes teriam mais espaço de manobra do que outros pods pesados. A longo prazo, também não funcionaria devido ao desperdício de recursos. Além disso, nossos aplicativos Node eram de thread único e, portanto, podiam usar apenas um núcleo. A única solução real era usar um melhor balanceamento de carga.
Há muito que desejamos apreciar plenamente o
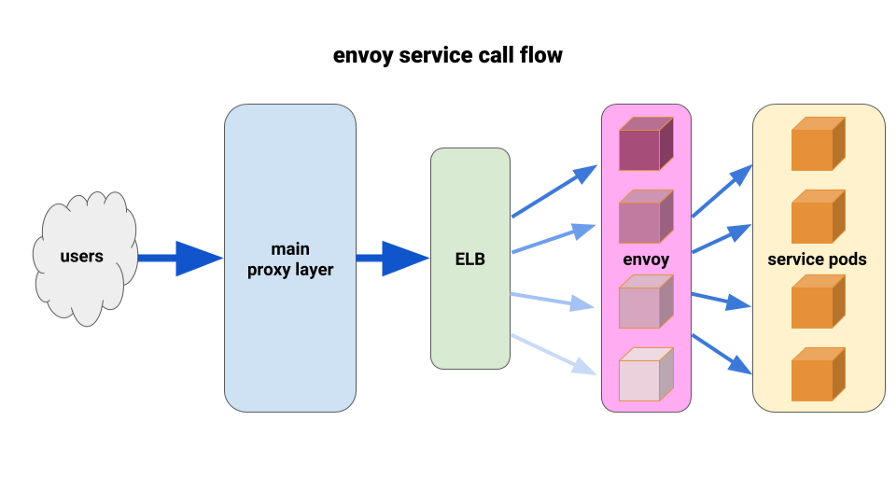
enviado . A situação atual nos permitiu implantá-lo de uma maneira muito limitada e obter resultados imediatos. O Envoy é um proxy de sétimo nível de código aberto e alto desempenho, projetado para aplicativos SOA grandes. Ele é capaz de aplicar técnicas avançadas de balanceamento de carga, incluindo novas tentativas automáticas, disjuntores e limites globais de velocidade.
( Nota : tradução : para obter mais detalhes, consulte o artigo recente sobre o Istio - a malha de serviço, baseada no Envoy.)Criamos a seguinte configuração: envie o side-car Envoy para cada pod e uma única rota e o cluster - conecte-se ao contêiner localmente por porta. Para minimizar o potencial de cascata e manter um pequeno raio de "dano", usamos o pod park de proxy frontal da Envoy, um para cada Zona de Disponibilidade (AZ) para cada serviço. Eles se voltaram para um mecanismo simples de descoberta de serviço escrito por um de nossos engenheiros, que simplesmente retornava uma lista de pods em cada AZ para um determinado serviço.
Em seguida, os representantes da frente de serviço usaram esse mecanismo de descoberta de serviço com um cluster e rota upstream. Definimos tempos limites adequados, aumentamos todas as configurações do disjuntor e adicionamos uma configuração mínima de repetição para ajudar com falhas únicas e garantir implantações perfeitas. Antes de cada um desses serviços, enviamos um TCP ELB. Mesmo que o keepalive de nossa camada principal de proxy permanecesse em alguns pods do Envoy, eles ainda poderiam lidar com a carga muito melhor e estavam prontos para equilibrar através de pelo menos_request no backend.
Para a implantação, usamos o gancho preStop nos pods de aplicativos e nos side-cars. O gancho iniciou um erro ao verificar o status do terminal administrativo localizado no contêiner lateral e "dormiu" por um tempo para permitir a conclusão de conexões ativas.
Um dos motivos pelos quais conseguimos avançar tão rapidamente na solução de problemas está relacionado a métricas detalhadas que conseguimos integrar facilmente em uma instalação padrão do Prometheus. Com eles, foi possível ver exatamente o que estava acontecendo enquanto selecionamos os parâmetros de configuração e redistribuímos o tráfego.
Os resultados foram imediatos e óbvios. Começamos com os serviços mais desequilibrados e, no momento, ele já funciona antes dos 12 serviços mais importantes do cluster. Este ano, planejamos mudar para uma malha de serviço completa com descoberta de serviço mais avançada, quebra de circuito, detecção de outlier, limitação de velocidade e rastreamento.
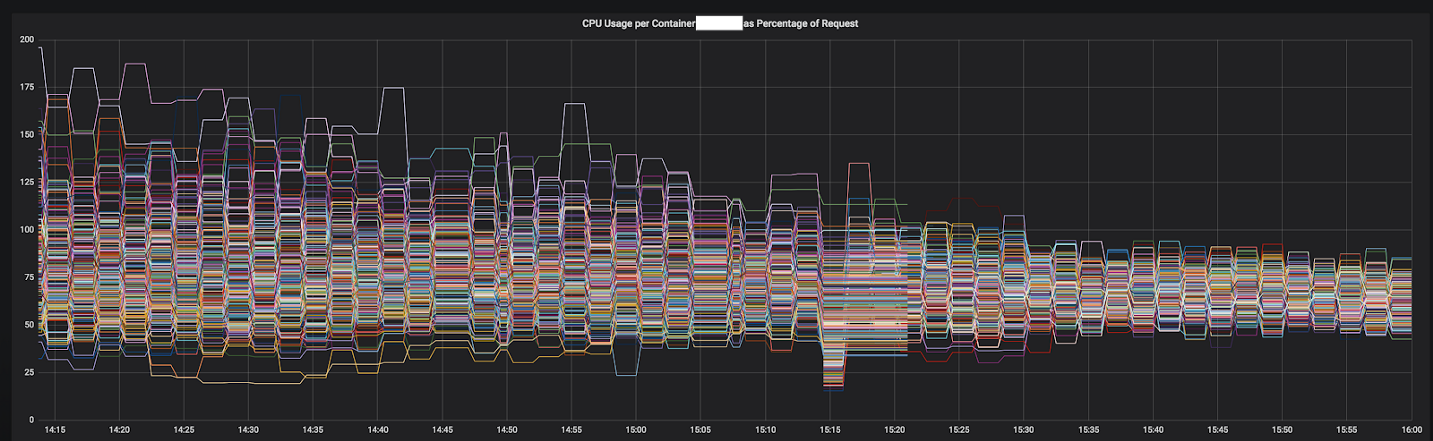 Figura 3-1. Convergência da CPU de um serviço durante a transição para o Envoy
Figura 3-1. Convergência da CPU de um serviço durante a transição para o Envoy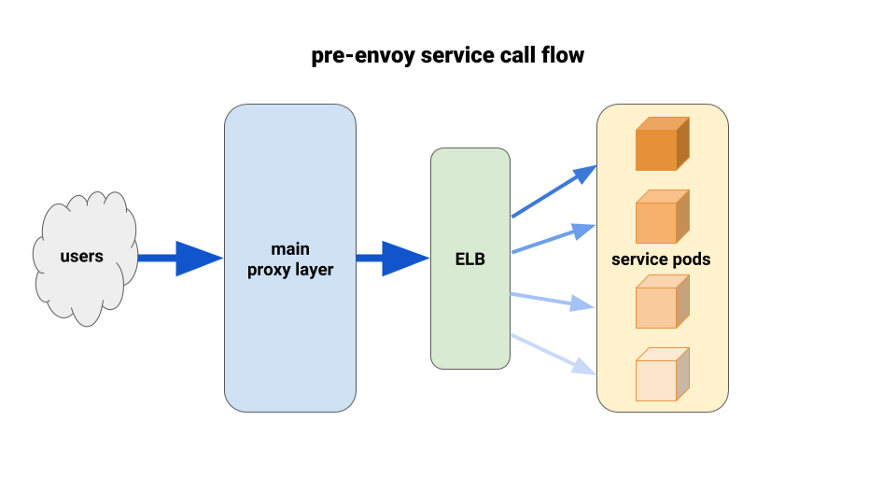
Resultado final
Graças à nossa experiência e pesquisas adicionais, construímos uma equipe de infraestrutura forte, com boas habilidades em projetar, implantar e operar grandes clusters Kubernetes. Agora, todos os engenheiros do Tinder têm o conhecimento e a experiência em como empacotar contêineres e implantar aplicativos no Kubernetes.
Quando surgiu a necessidade de capacidades adicionais na infraestrutura antiga, tivemos que esperar alguns minutos para lançar novas instâncias do EC2. Agora, os contêineres iniciam e começam a processar o tráfego por vários segundos, em vez de minutos. Planejar vários contêineres em uma única instância do EC2 também fornece uma concentração horizontal aprimorada. Como resultado, em 2019, prevemos uma redução significativa nos custos de EC2 em comparação com o ano passado.
Demorou quase dois anos para migrar, mas a concluímos em março de 2019. Atualmente, a plataforma Tinder é executada exclusivamente no cluster Kubernetes, que consiste em 200 serviços, 1000 nós, 15.000 pods e 48.000 contêineres em execução. A infraestrutura não é mais da exclusiva responsabilidade das equipes operacionais. Todos os nossos engenheiros compartilham essa responsabilidade e controlam o processo de criação e implantação de seus aplicativos usando apenas código.
PS do tradutor
Leia também nossa série de artigos em nosso blog: