No último comício interno da Pyrus, conversamos sobre armazenamento distribuído moderno, e Maxim Nalsky, CEO e fundador da Pyrus, compartilhou sua primeira impressão do FoundationDB. Neste artigo, falamos sobre as nuances técnicas que você enfrenta ao escolher uma tecnologia para dimensionar o armazenamento de dados estruturados.
Quando o serviço não está disponível para os usuários há algum tempo, é extremamente desagradável, mas ainda não é mortal. Mas perder dados de clientes é absolutamente inaceitável. Portanto, avaliamos escrupulosamente qualquer tecnologia para armazenar dados em duas a três dúzias de parâmetros.
Alguns deles determinam a carga atual no serviço.
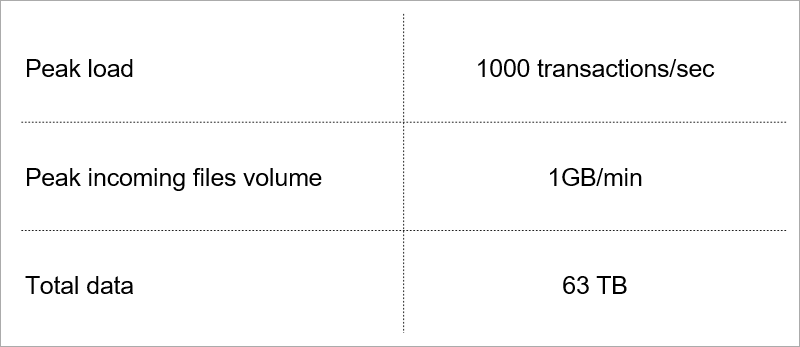 Carga atual. Selecionamos a tecnologia levando em consideração o crescimento desses indicadores.
Carga atual. Selecionamos a tecnologia levando em consideração o crescimento desses indicadores.Arquitetura do servidor cliente
O modelo cliente-servidor clássico é o exemplo mais simples de um sistema distribuído. Um servidor é um ponto de sincronização, pois permite que vários clientes façam algo juntos de maneira coordenada.
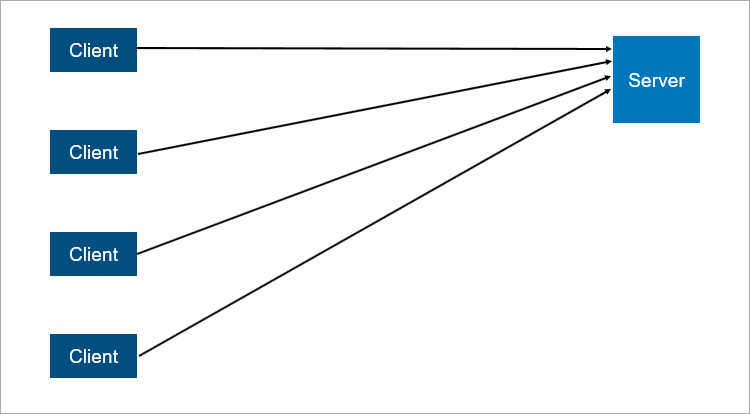 Um esquema muito simplificado de interação cliente-servidor.
Um esquema muito simplificado de interação cliente-servidor.O que não é confiável na arquitetura cliente-servidor? Obviamente, o servidor pode falhar. E quando o servidor falha, todos os clientes não podem funcionar. Para evitar isso, as pessoas criaram uma conexão mestre-escravo (que agora é
politicamente correta chamada seguidor de líder ). A conclusão é que existem dois servidores, todos os clientes se comunicam com o principal e, no segundo, todos os dados são simplesmente replicados.
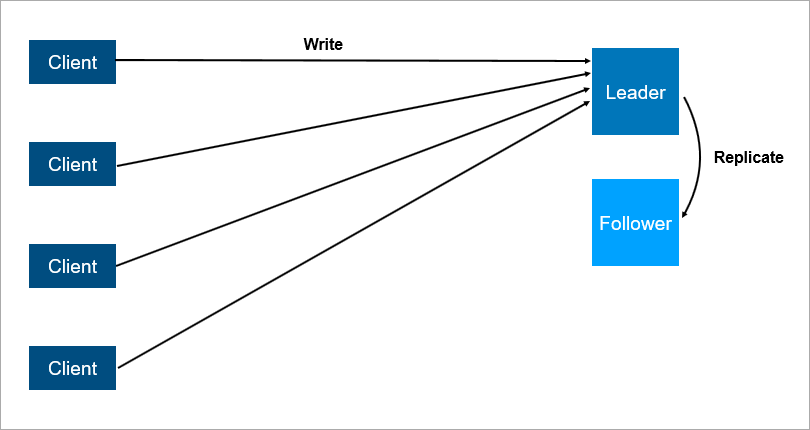 Arquitetura cliente-servidor com replicação de dados para seguidores.
Arquitetura cliente-servidor com replicação de dados para seguidores.Está claro que este é um sistema mais confiável: se o servidor principal travar, uma cópia de todos os dados estará no seguidor e poderá ser aumentada rapidamente.
É importante entender como a replicação funciona. Se for síncrona, a transação deve ser armazenada simultaneamente no líder e no seguidor, e isso pode ser lento. Se a replicação for assíncrona, você poderá perder alguns dados após um failover.
E o que acontecerá se o líder cair à noite quando todos estiverem dormindo? Existem dados sobre o seguidor, mas ninguém lhe disse que ele agora é um líder, e os clientes não se conectam a ele. OK, vamos dotar o seguidor com a lógica de que ele começa a se considerar a coisa principal quando a conexão com o líder é perdida. Então podemos facilmente ter um cérebro dividido - um conflito quando a conexão entre o líder e o seguidor é interrompida, e ambos pensam que eles são os principais. Isso realmente acontece em muitos sistemas,
como o RabbitMQ , a tecnologia de filas mais popular da atualidade.
Para resolver esses problemas, organize o failover automático - adicione um terceiro servidor (testemunha, testemunha). Isso garante que temos apenas um líder. E se o líder cair, o seguidor liga automaticamente com um tempo de inatividade mínimo, que pode ser reduzido para alguns segundos. Obviamente, os clientes nesse esquema devem conhecer antecipadamente os endereços do líder e seguidor e implementar a lógica da reconexão automática entre eles.
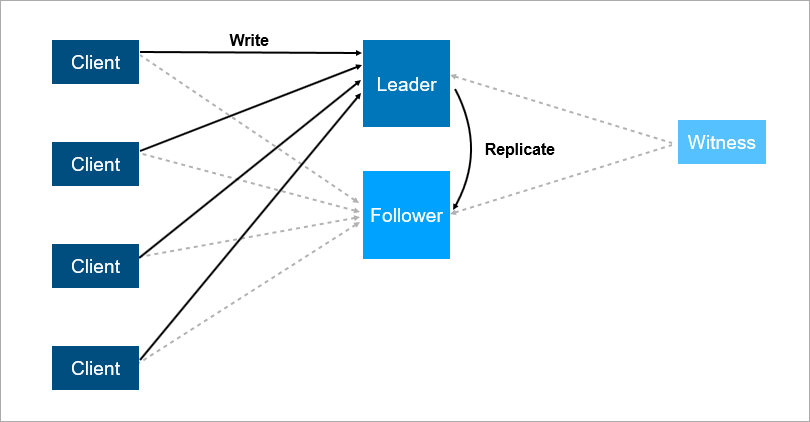 A testemunha garante que existe apenas um líder. Se o líder cair, o seguidor liga automaticamente.
A testemunha garante que existe apenas um líder. Se o líder cair, o seguidor liga automaticamente.Esse sistema agora funciona conosco. Há um banco de dados principal, um banco de dados sobressalente, há uma testemunha e sim - às vezes chegamos de manhã e vemos que a troca aconteceu à noite.
Mas esse esquema também tem desvantagens. Imagine que você está instalando service packs ou atualizando o sistema operacional em um servidor líder. Antes disso, você alternava manualmente a carga no seguidor e depois ... ela cai! Desastre, seu serviço está indisponível. O que fazer para se proteger disso? Adicione um terceiro servidor de backup - outro seguidor. Três é um tipo de número mágico. Se você deseja que o sistema funcione de maneira confiável, dois servidores não são suficientes, são necessários três. Um para manutenção, o segundo cai, o terceiro permanece.
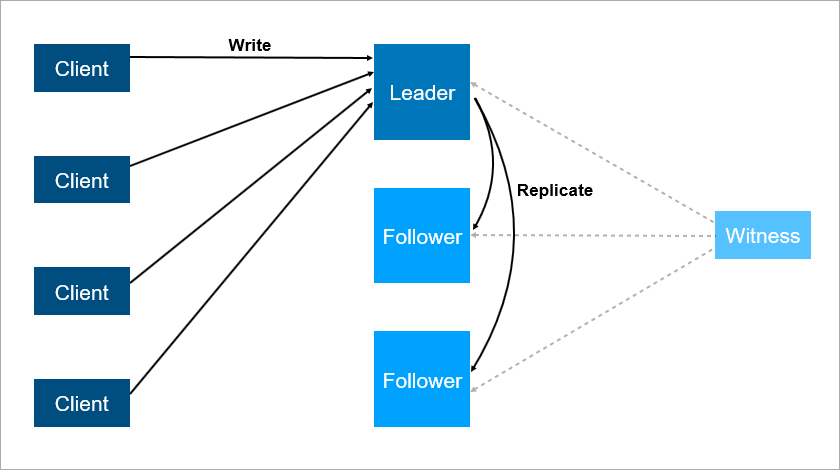 O terceiro servidor fornece operação confiável se os dois primeiros não estiverem disponíveis.
O terceiro servidor fornece operação confiável se os dois primeiros não estiverem disponíveis.Para resumir, a redundância deve ser igual a dois. Uma redundância de um não é suficiente. Por esse motivo, em matrizes de disco, as pessoas começaram a usar o esquema RAID6 em vez do RAID5, sobrevivendo à queda de dois discos ao mesmo tempo.
Transações
São conhecidos quatro requisitos básicos para transações: atomicidade, consistência, isolamento e durabilidade (Atomicidade, Consistência, Isolamento, Durabilidade - ACID).
Quando falamos de bancos de dados distribuídos, queremos dizer que os dados devem ser escalados. A leitura é muito boa - milhares de transações podem ler dados em paralelo sem problemas. Mas quando outras transações gravam dados ao mesmo tempo que a leitura, vários efeitos indesejáveis são possíveis. É muito fácil obter uma situação em que uma transação leia valores diferentes dos mesmos registros. Aqui estão alguns exemplos.
Leituras sujas. Na primeira transação, enviamos a mesma solicitação duas vezes: pegue todos os usuários cujo ID = 1. Se a segunda transação alterar essa linha e depois reverter, o banco de dados não verá nenhuma alteração por um lado, mas por outro a primeira transação lerá diferentes valores de idade para Joe.
 Leituras não repetíveis.
Leituras não repetíveis. Outro caso é se a transação de gravação foi concluída com êxito e a transação de leitura recebeu dados diferentes durante a execução da mesma solicitação.

No primeiro caso, o cliente leu dados que geralmente estavam ausentes no banco de dados. No segundo caso, o cliente lê os dados duas vezes no banco de dados, mas eles são diferentes, embora a leitura ocorra na mesma transação.
A leitura fantasma é quando relemos um intervalo dentro da mesma transação e obtemos um conjunto diferente de linhas. Em algum lugar no meio, outra transação entrou e inseriu ou excluiu registros.

Para evitar esses efeitos indesejáveis, os DBMSs modernos implementam mecanismos de bloqueio (uma transação restringe o acesso de outras transações aos dados com os quais estão trabalhando atualmente) ou o controle de versões em várias versões,
MVCC (uma transação nunca altera os dados gravados anteriormente e sempre cria uma nova versão).
O padrão ANSI / ISO SQL define 4 níveis de isolamento para transações que afetam seu grau de bloqueio mútuo. Quanto maior o nível de isolamento, menos efeitos indesejáveis. O preço para isso é desacelerar o aplicativo (já que as transações aguardam com mais frequência para desbloquear os dados necessários) e aumentar a probabilidade de conflitos.
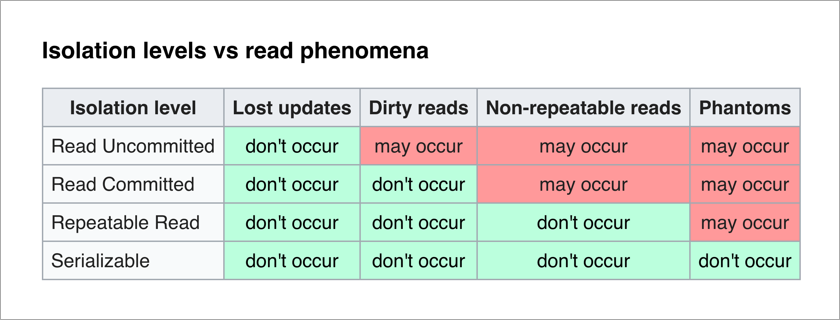
O mais agradável para um programador de aplicativos é o nível Serializable - não há efeitos indesejáveis e toda a complexidade de garantir a integridade dos dados é transferida para o DBMS.
Vamos pensar na implementação ingênua do nível Serializable - com cada transação, apenas bloqueamos todos os outros. Cada transação de gravação pode teoricamente ser executada em 50 µs (o tempo de uma operação de gravação em discos SSD modernos). E queremos salvar dados em três máquinas, lembra? Se eles estiverem no mesmo data center, a gravação levará de 1 a 3 ms. E, se eles, por confiabilidade, estiverem em cidades diferentes, a gravação poderá demorar de 10 a 12ms (o tempo de viagem de um pacote de rede de Moscou a São Petersburgo e vice-versa). Ou seja, com uma implementação ingênua do nível Serializable por gravação sequencial, não podemos realizar mais de 100 transações por segundo. Enquanto um SSD separado permite executar cerca de 20.000 operações de gravação por segundo!
Conclusão: as transações de gravação devem ser executadas em paralelo e, para escalá-las, é necessário um bom mecanismo de resolução de conflitos.
Sharding
O que fazer quando os dados param de entrar em um servidor? Existem dois mecanismos de zoom padrão:
- Vertical quando adicionamos memória e discos a este servidor. Isso tem seus limites - em termos de número de núcleos por processador, número de processadores e quantidade de memória.
- Horizontal, quando usamos muitas máquinas e distribuímos dados entre elas. Os conjuntos dessas máquinas são chamados de clusters. Para colocar dados em um cluster, eles precisam ser fragmentados - ou seja, para cada registro, determine em qual servidor ele estará localizado.
Uma chave de fragmentação é um parâmetro pelo qual os dados são distribuídos entre servidores, por exemplo, um identificador de cliente ou organização.
Imagine que você precisa registrar dados sobre todos os habitantes da Terra em um cluster. Como chave de fragmento, você pode usar, por exemplo, o ano de nascimento da pessoa. Então, 116 servidores serão suficientes (e a cada ano será necessário adicionar um novo servidor). Ou você pode tomar como chave o país em que a pessoa mora, e precisará de aproximadamente 250 servidores. Ainda, a primeira opção é preferível, porque a data de nascimento da pessoa não muda e você nunca precisará transferir dados sobre ela entre os servidores.
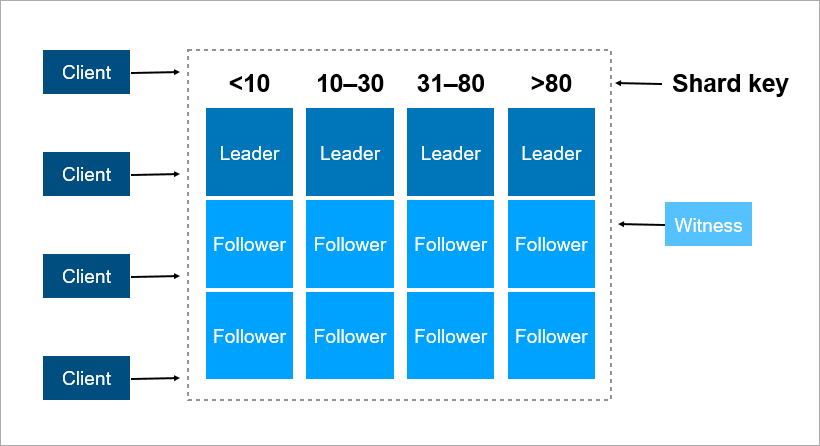
No Pyrus, você pode considerar uma organização como uma chave de fragmentação. Mas eles são muito diferentes em tamanho: existe um enorme Sovcombank (mais de 15 mil usuários) e milhares de pequenas empresas. Quando você atribui a uma organização um servidor específico, não sabe com antecedência como ela crescerá. Se a organização for grande e usar o serviço ativamente, mais cedo ou mais tarde seus dados deixarão de ser colocados em um servidor e você precisará compartilhar novamente. E isso não é fácil se os dados tiverem terabytes. Imagine: um sistema carregado, as transações acontecem a cada segundo e, nessas condições, você precisa mover dados de um lugar para outro. Você não pode interromper o sistema, esse volume pode ser bombeado por várias horas e os clientes comerciais não sobreviverão a um período de inatividade tão longo.
Como chave de compartilhamento, é melhor escolher dados que raramente mudam. No entanto, longe de sempre uma tarefa aplicada, é fácil fazer isso.
Consenso no cluster
Quando há muitas máquinas no cluster e algumas delas perdem contato com as outras, como decidir quem armazena a versão mais recente dos dados? Apenas atribuir um servidor testemunha não é suficiente, pois também pode perder o contato com todo o cluster. Além disso, em uma situação de cérebro dividido, várias máquinas podem gravar versões diferentes dos mesmos dados - e você precisa determinar de alguma forma qual é a mais relevante. Para resolver esse problema, as pessoas criaram algoritmos de consenso. Eles permitem que várias máquinas idênticas cheguem a um único resultado em qualquer questão, votando. Em 1989, o primeiro algoritmo desse tipo,
Paxos , foi publicado e, em 2014, os caras de Stanford criaram um
Raft mais simples de implementar. Estritamente falando, para que um cluster de servidores (2N + 1) alcance consenso, basta que ele tenha ao mesmo tempo não mais que N falhas. Para sobreviver a 2 falhas, o cluster deve ter pelo menos 5 servidores.
Escala relacional do DBMS
A maioria dos bancos de dados que os desenvolvedores estão acostumados a trabalhar com álgebra relacional de suporte. Os dados são armazenados em tabelas e, às vezes, você precisa unir os dados de diferentes tabelas usando a operação JOIN. Considere um exemplo de banco de dados e uma consulta simples.
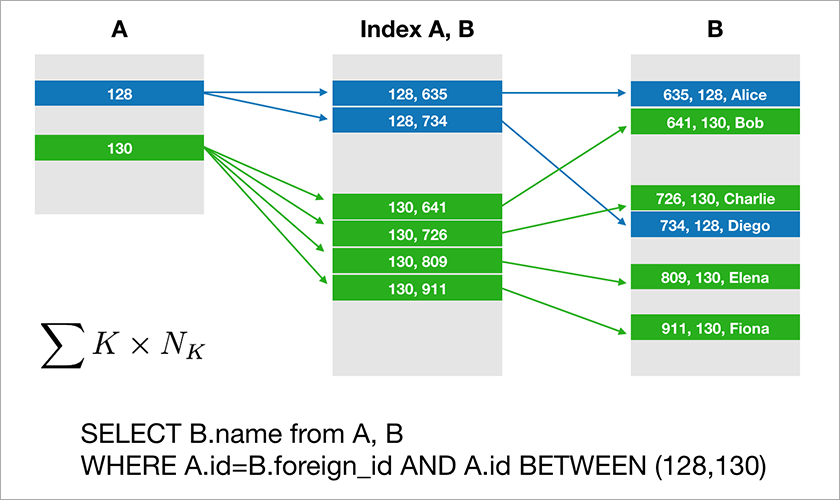
Suponha que A.id seja uma chave primária com um índice em cluster. Em seguida, o otimizador criará um plano que provavelmente primeiro selecionará os registros necessários da tabela A e, em seguida, obterá os links apropriados para os registros na tabela B a partir de um índice adequado (A, B). O tempo de execução dessa consulta aumenta logaritmicamente a partir do número de registros nas tabelas.
Agora imagine que os dados estão distribuídos por quatro servidores no cluster e você precisa executar a mesma consulta:
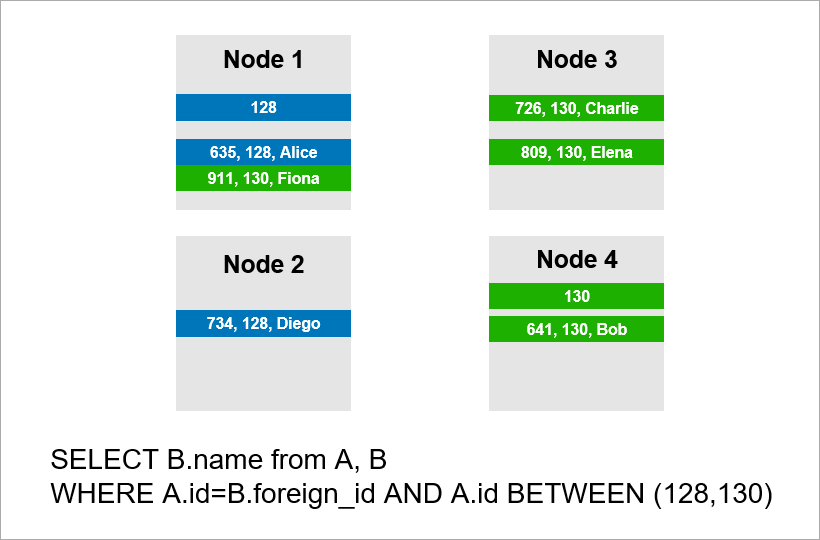
Se o DBMS não quiser exibir todos os registros de todo o cluster, provavelmente tentará encontrar registros com A.id iguais a 128, 129 ou 130 e encontrará os registros apropriados para eles na tabela B. Mas se A.id não for uma chave de fragmento, o DBMS antecipadamente não consigo saber em qual servidor estão os dados da tabela A. Precisarei entrar em contato com todos os servidores para descobrir se há registros A.id adequados para nossa condição. Cada servidor pode criar um JOIN dentro de si, mas isso não é suficiente. Veja bem, precisamos do registro no nó 2 da amostra, mas não há registro com A.id = 128? Se os nós 1 e 2 fizerem JOIN independentemente, o resultado da consulta estará incompleto - não receberemos parte dos dados.
Portanto, para atender a essa solicitação, cada servidor deve recorrer a todos os outros. O tempo de execução cresce quadraticamente com o número de servidores. (Você tem sorte se puder dividir todas as tabelas com a mesma chave e não precisar percorrer todos os servidores. No entanto, na prática isso não é realista - sempre haverá consultas em que a busca não se baseia na chave do fragmento).
Portanto, as operações do JOIN são muito escassas e esse é um problema fundamental da abordagem relacional.
Abordagem NoSQL
As dificuldades com o dimensionamento de DBMSs clássicos levaram as pessoas a criar bancos de dados NoSQL que não possuem operações JOIN. Sem junções - sem problemas. Mas não há propriedades ACID, mas elas não mencionaram isso nos materiais de marketing.
Artesãos rapidamente
encontrados que testam a força de vários sistemas distribuídos e
publicam os resultados publicamente . Verificou-se que existem cenários em que o
cluster Redis perde 45% dos dados armazenados, o cluster RabbitMQ - 35% das mensagens ,
MongoDB - 9% dos registros ,
Cassandra - até 5% . E estamos falando
sobre a perda depois que o cluster informou o cliente sobre o salvamento bem-sucedido. Normalmente, você espera um nível mais alto de confiabilidade da tecnologia escolhida.
O Google desenvolveu o banco de dados
Spanner , que opera globalmente em todo o mundo. A chave inglesa garante propriedades ACID, serialização e muito mais. Eles possuem relógios atômicos nos datacenters que fornecem tempo preciso, e isso permite que você crie uma ordem global de transações sem precisar encaminhar pacotes de rede entre continentes. A idéia do Spanner é que é melhor para os programadores lidar com problemas de desempenho que surgem com um grande número de transações do que muletas em torno da falta de transações. No entanto, o Spanner é uma tecnologia fechada, não lhe convém se, por algum motivo, você não quiser depender de um fornecedor.
Os nativos do Google desenvolveram um análogo de código aberto da Spanner e o chamaram CockroachDB ("barata" em inglês "barata", que deve simbolizar a capacidade de sobrevivência do banco de dados). Em Habré
já escreveu sobre a indisponibilidade do produto para produção, porque o cluster estava perdendo dados. Decidimos verificar a versão mais recente 2.0 e chegamos a uma conclusão semelhante. Não perdemos os dados, mas algumas das consultas mais simples foram executadas de maneira irracionalmente longa.
Como resultado, hoje existem bancos de dados relacionais que escalam bem apenas verticalmente, o que é caro. E existem soluções NoSQL sem transações e sem garantias ACID (se você quiser ACID, escreva muletas).
Como criar aplicativos de missão crítica nos quais os dados não cabem em um servidor? Novas soluções aparecem no mercado e, sobre uma delas -
FoundationDB -, contaremos mais no próximo artigo.