
Olá Habr! Meu nome é Stanislav Semenov, estou trabalhando em tecnologias para extrair dados de documentos em P&D ABBYY. Neste artigo, falarei sobre as abordagens básicas para o processamento de documentos semiestruturados (faturas, recebimentos de caixa etc.) que usamos recentemente e que estamos usando agora. E falaremos sobre como os métodos de aprendizado de máquina são aplicáveis para resolver esse problema.
Consideraremos as faturas como documentos, porque no mundo, eles são muito difundidos e mais demandados em termos de extração de dados. A propósito, o processamento automático de faturas é um dos cenários mais populares entre nossos clientes estrangeiros. Por exemplo, com o ABBYY FlexiCapture, a American PepsiCo Imaging Technology
reduziu o tempo de processamento de faturas e o número de erros devido à entrada manual, enquanto o varejista European Sportina
começou a inserir dados das contas nos sistemas de contabilidade
duas vezes mais rápido .
As faturas são documentos que são utilizados na prática comercial internacional e são de grande importância para os negócios. Algo semelhante a uma fatura na Rússia é, por exemplo, uma carta de porte. Os dados de tais documentos se enquadram em vários sistemas contábeis, e os erros ali, para dizer o mínimo, não são bem-vindos.
Uma fatura comum pode ser considerada bastante estruturada; contém duas classes principais de objetos:
- vários campos do cabeçalho (número do documento, data, remetente, destinatário, total etc.),
- dados tabulares é uma lista de bens e serviços (quantidade, preço, descrição etc.).
É assim que se parece:
Milhões de horas-homem são gastas anualmente no processamento de faturas. E é muito caro. De acordo com várias estimativas, para uma empresa o processamento de uma fatura em papel custa de US $ 10 a US $ 40, onde uma parte significativa desses custos é de trabalho manual para inserir e reconciliar dados.
Existem empresas que processam milhões de faturas por mês. Para fazer isso, eles contêm uma equipe inteira de centenas e, às vezes, milhares de pessoas. É fácil estimar que um aumento na precisão do reconhecimento ou na eficiência da extração de dados de apenas 1% pode reduzir os custos das grandes empresas em centenas de milhares e até milhões de dólares anualmente.
Por outro lado, há uma quantidade catastrófica de documentos. Em 2017, Billentis
estimou o número total de faturas / faturas geradas por ano no mundo em 400 bilhões. Destes, apenas 10% eram eletrônicos, e o restante exige entrada totalmente manual ou participação humana intensiva. Se você imprimir 400 bilhões de documentos em papel A4 padrão, haverá milhares de caminhões de papel por dia ou uma pilha de papel com a altura humana a cada segundo!
Algumas palavras sobre como a tecnologia se desenvolveu

Muitas empresas estão desenvolvendo software especializado que pode reconhecer documentos e extrair dados deles. Mas a qualidade do processamento da fatura ainda não é perfeita. "Qual é o problema?" - você pergunta.
É tudo sobre uma enorme variedade de faturas. Não há padrões para faturas, e cada empresa é livre para criar sua própria versão do documento: o tipo, a estrutura e a localização dos campos.
Encontre campos por palavras-chave
As primeiras tentativas de extrair dados chegaram a encontrar palavras-chave especiais entre todas as palavras reconhecidas, como, por exemplo, Número da fatura ou Total e, em seguida, na pequena vizinhança dessas palavras, por exemplo, à direita ou na parte inferior, para encontrar os significados.
Localização do número da fatura em diferentes faturas (clicáveis):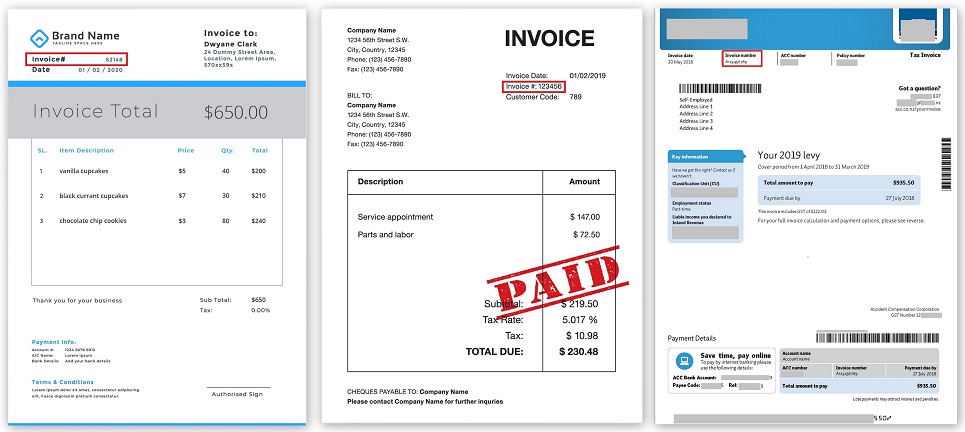
Toda a lógica foi programada, de que existem tais e tais campos, eles estão em tal e qual lugar do documento, ao redor deles existem outros campos a algumas distâncias. E isso funcionou de alguma forma até aparecer outra empresa, que começou a enviar seus documentos de uma forma completamente diferente. Ou a empresa anterior mudou de repente o formato e tudo parou de funcionar.
Padrões
Lutar contra isso, sempre que reprogramar algo, era irracional. Portanto, um novo paradigma veio em socorro - o uso de modelos.
Um modelo é um conjunto de campos que precisam ser encontrados em um documento e um conjunto de regras sobre como encontrar esses campos. A principal vantagem aqui é que os modelos são criados visualmente. Por exemplo, queremos procurar o número da fatura e o total, selecionar esses campos e configurar os parâmetros que esse e aquele campo vem imediatamente após tal e tal palavra-chave, que está localizado na parte superior do documento e contém números e sinais de pontuação.
Foram desenvolvidas ferramentas especializadas, os chamados editores de modelos, onde usuários já avançados, sem a ajuda de programadores, podiam rapidamente definir manualmente algum tipo de lógica. Assim que um documento de um novo formulário chegou, um modelo foi criado para ele e tudo começou a funcionar mais ou menos.
Modelo de amostra (clicável):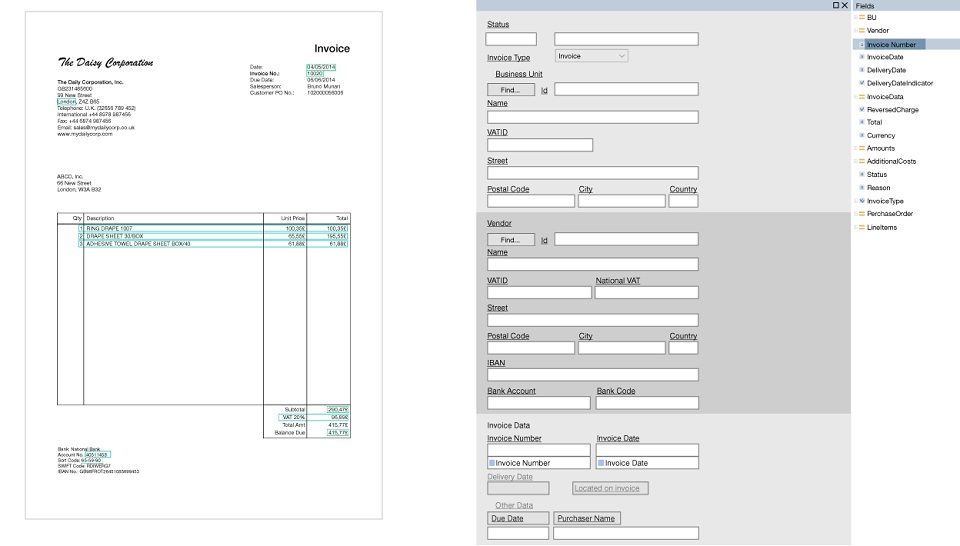
Mas para fazer um modelo não basta, eles precisam ser feitos centenas e até milhares. E, portanto, configurar um produto para cada cliente pode levar muito tempo. É impossível criar modelos "universais" com antecedência, que abrangerão toda a variedade de faturas.
Usando modelos, você pode melhorar significativamente a qualidade da recuperação da tabela. Porém, muitas vezes são encontradas estruturas de tabela complexas, com representação de dados não padrão, vários níveis de aninhamento e modelos nesses casos nem sempre funcionam bem. Então, novamente, você deve escrever alguns scripts que contenham muitos parâmetros, condições, exceções, etc. selecionados manualmente
Usando o Machine Learning
Hoje, a tecnologia não fica parada e, com o desenvolvimento do aprendizado de máquina, tornou-se possível transferir a tarefa de extrair dados de documentos para redes neurais.
Hoje, existem várias abordagens básicas usadas na prática:
- A primeira abordagem é trabalhar diretamente com a imagem de entrada do documento. Ou seja, uma imagem (imagem) ou fragmento é alimentada na entrada da rede, e a rede aprende a encontrar pequenas áreas em que os campos necessários estão localizados e, em seguida, o texto nessas áreas é reconhecido usando as tecnologias clássicas de OCR (Optical Character Recognition). Esta é uma solução de ponta a ponta que pode ser implementada rapidamente. Você pode usar uma rede pronta para pesquisar objetos em imagens, por exemplo, YOLO ou Faster R-CNN e treiná-la em imagens marcadas de documentos.
A desvantagem dessa abordagem não é a melhor qualidade dos dados extraídos e a dificuldade de extrair tabelas. De fato, essa abordagem é de alguma forma semelhante à tarefa de encontrar as palavras certas na imagem (localização de palavras), um problema fundamental do campo da visão computacional; somente aqui estamos procurando não as palavras, mas os campos necessários. - A segunda abordagem é processar o texto extraído do documento. Pode ser texto de um PDF ou um documento OCR de página inteira. Ele usa a tecnologia de processamento de linguagem natural (PNL) . As linhas são montadas a partir de palavras individuais, vários fragmentos de texto, parágrafos ou colunas são formados a partir de linhas, e nelas a rede já está aprendendo a distinguir várias entidades nomeadas NER (Reconhecimento de Entidades Nomeadas).
São possíveis várias maneiras de formar fragmentos de texto. Você pode combinar a primeira e a segunda abordagens, treinar uma rede para encontrar blocos grandes com determinadas informações nas imagens, por exemplo, dados sobre o remetente ou dados sobre o destinatário, que contêm imediatamente o nome, endereço, detalhes etc., e depois transferir o texto de cada bloco. para a segunda rede NER.
A qualidade dessa abordagem pode se tornar mais alta do que apenas na primeira, mas é bastante difícil construir um modelo eficaz. Hoje, existem modelos bastante avançados, por exemplo, LSTM-CRF para NER, que podem marcar palavras no texto e definir entidades. - A terceira abordagem é criar uma representação semântica do documento sem referência ao tipo de documento, ou seja, quando não sabemos o que o documento está à nossa frente, mas tentamos entendê-lo durante o processamento. Um conjunto de palavras do documento com seus vários atributos (por exemplo, a palavra contém apenas letras ou é um número), o arranjo geométrico de palavras (coordenadas, recuos) e com vários delimitadores e conexões identificados durante a análise de imagem é alimentado à entrada da rede e a saída é obtida para Cada palavra tem seu próprio conjunto específico de características. Com base nas características obtidas, vários conjuntos de hipóteses de possíveis campos ou tabelas são formados, os quais são posteriormente classificados e avaliados por um classificador adicional. Em seguida, é selecionada a hipótese mais confiável da estrutura e do conteúdo do documento.
Essa já é tecnicamente a solução mais difícil, mas você pode resolver o problema de extrair dados de documentos de uma maneira geral.
Como usamos redes neurais
Na ABBYY, não apenas monitoramos de perto as realizações da ciência e da tecnologia, mas também criamos nossas próprias tecnologias avançadas e as implementamos em vários produtos.
A figura abaixo mostra a arquitetura geral da nossa solução usando redes neurais.
Imagem clicável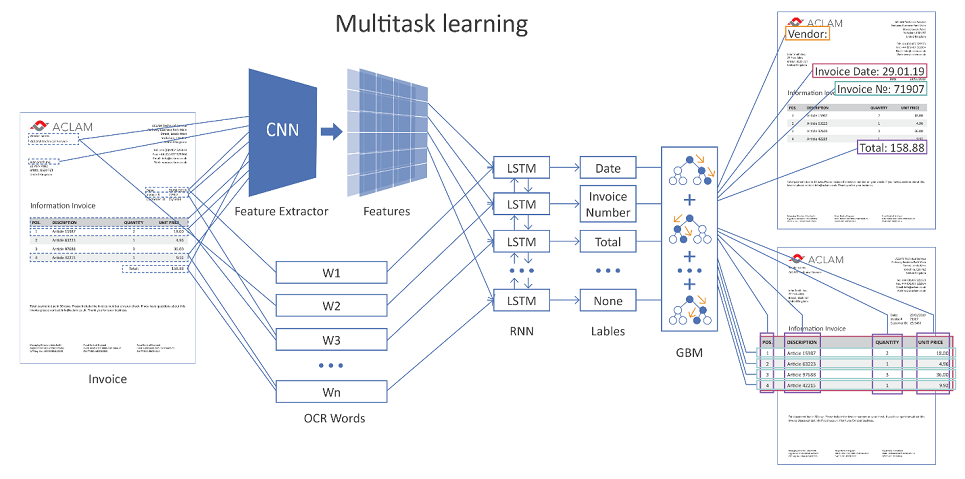
A página inteira do documento é alimentada na entrada da rede. Usando camadas convolucionais (CNN), várias características geométricas são formadas, por exemplo, a posição relativa das palavras em relação uma à outra. Além disso, esses sinais são combinados com a representação vetorial de palavras reconhecidas (incorporação de palavras) e veiculados em camadas recorrentes (LSTM) e totalmente conectadas. Existem várias camadas de saída diferentes (aprendizado de várias tarefas), cada saída resolve seu próprio problema:
- determinar o tipo de campo ao qual uma palavra pode corresponder,
- hipóteses de limites da tabela,
- hipóteses de linhas da tabela, limites da coluna etc.
Se o documento tiver várias páginas, a rede fará sua previsão para cada página individual e os resultados serão combinados.
Em seguida, são formadas hipóteses do possível arranjo de campos e tabelas, com a ajuda de uma função de regressão treinada separadamente, elas são avaliadas e a hipótese mais confiante vence.
Para aumentar a precisão da extração de dados, além de separar os documentos por tipo (cheque, fatura, contrato, etc.), um cluster adicional ocorre dentro do seu tipo, de acordo com características adicionais.
Por exemplo, para faturas, pode ser um fornecedor ou apenas uma aparência (de acordo com o grau de similaridade da localização dos campos). E então, dependendo de um grupo específico (cluster), configurações específicas de algoritmos são aplicadas. Tecnicamente, com exemplos de faturas marcadas corretamente para diferentes grupos, é possível do lado do usuário treinar novamente os mecanismos de avaliação e escolha das hipóteses corretas.
Para configurar todos os tipos de parâmetros de nossos algoritmos e redes neurais, usamos o método de evolução diferencial, que se provou muito bem na prática.
Nossos Resultados de Aprendizado de Máquina

- O método desenvolvido para extrair dados de documentos estruturados usando o aprendizado de máquina em muitos casos mostra melhores resultados do que as soluções programadas baseadas em heurísticas. O ganho de qualidade em várias métricas varia de várias unidades a dezenas de por cento em várias entidades extraíveis.
- Há uma vantagem inegável sobre a abordagem clássica - a capacidade de treinar novamente a rede com novos dados. No caso de uma variedade de formas de documentos, agora isso não é um problema, mas uma necessidade. Quanto mais deles, melhor; quanto maior a capacidade de generalização da rede e maior a qualidade.
- Houve uma oportunidade de lançar a solução denominada “pronta para uso”, quando o usuário simplesmente instala o produto (de fato, uma rede treinada) e tudo começa imediatamente a trabalhar com um resultado aceitável. Não há necessidade de programar nada, personalizar os modelos de maneira extensa e dolorosa, selecionar todos os tipos de parâmetros.
Um detalhe importante que eu também gostaria de mencionar são os dados. Nenhum aprendizado de máquina pode acontecer sem dados de qualidade. O aprendizado de máquina fornece melhores resultados do que a engenharia do conhecimento, apenas se houver uma quantidade suficiente de dados marcados. No caso das faturas, são dezenas de milhares de documentos rotulados manualmente e esse número está em constante crescimento.
Além disso, usamos mecanismos avançados de aumento de dados, alteramos os nomes das organizações, endereços, listas de bens e tipos de serviços em tabelas, datas, várias características quantitativas, como preço, quantidade, custo, etc. Também alteramos a sequência de várias entidades nos documentos, o que nos permite gerar milhões de documentos completamente diferentes para treinamento.
Em vez de uma conclusão
Em conclusão, podemos dizer que a programação, é claro, não desapareceu, mas está gradualmente mudando seu papel. A cada novo dia, o aprendizado de máquina começa a lidar com as tarefas que lhe são atribuídas cada vez melhor em uma variedade de setores, excluindo abordagens clássicas. A vantagem inegável do aprendizado de máquina em eficiência: dezenas de homens-ano de trabalho intelectual agora custam dezenas de horas-máquina de aprendizado. Portanto, em um futuro próximo, vemos ainda maior desenvolvimento e aplicabilidade de redes em todos os nossos desenvolvimentos. E se você estiver interessado, estamos sempre abertos a sugestões e
cooperação .