Oi Habr!
Muitos leitores e autores regulares do site provavelmente pensaram em que tipo de ciclo de vida os artigos publicados aqui têm. E embora isso seja intuitivamente mais ou menos claro (é óbvio, por exemplo, que o artigo na primeira página tenha o número máximo de visualizações), mas quanto especificamente?
Para coletar estatísticas, usaremos Python, Pandas, Matplotlib e Raspberry Pi.
Aqueles que estão interessados no que aconteceu, por favor, abaixo de gato.
Coleta de dados
Primeiro, vamos decidir sobre as métricas - o que queremos saber. Tudo é simples, cada artigo possui 4 parâmetros principais exibidos na página - este é o número de visualizações, curtidas, favoritos e comentários. Vamos analisá-los.
Quem quiser ver imediatamente os resultados, pode ir para a terceira parte, mas, por enquanto, será sobre programação.
Plano geral: analisaremos os dados necessários da página da web, salvá-los em CSV e ver o que obtemos por um período de vários dias. Primeiro, carregue o texto do artigo (tratamento de exceção omitido para maior clareza):
link = "https://habr.com/ru/post/000001/" f = urllib.urlopen(link) data_str = f.read()
Agora precisamos extrair dados da linha data_str (é claro, em HTML). Abra o código-fonte no navegador (elementos sem princípios removidos):
<ul class="post-stats post-stats_post js-user_" id="infopanel_post_438514"> <li class="post-stats__item post-stats__item_voting-wjt"> <span class="voting-wjt__counter voting-wjt__counter_positive js-score" title=" 448: ↑434 ↓14">+420</span> </li> <span class="btn_inner"><svg class="icon-svg_bookmark" width="10" height="16"><use xlink:href="https://habr.com/images/1550155671/common-svg-sprite.svg#book" /></svg><span class="bookmark__counter js-favs_count" title=" , ">320</span></span> <li class="post-stats__item post-stats__item_views"> <div class="post-stats__views" title=" "> <span class="post-stats__views-count">219k</span> </div> </li> <li class="post-stats__item post-stats__item_comments"> <a href="https://habr.com/ru/post/438514/#comments" class="post-stats__comments-link" <span class="post-stats__comments-count" title=" ">577</span> </a> </li> <li class="post-stats__item"> <span class="icon-svg_report"><svg class="icon-svg" width="32" height="32" viewBox="0 0 32 32" aria-hidden="true" version="1.1" role="img"><path d="M0 0h32v32h-32v-32zm14 6v12h4v-12h-4zm0 16v4h4v-4h-4z"/></svg> </span> </li> </ul>
É fácil ver que o texto que precisamos está dentro do bloco '<ul class = "post-stats post-stats_post js-user_>', e os elementos necessários estão em blocos com os nomes vote-wjt__counter, bookmark__counter, bookmark__counter, post-stats__views-count e post- stats__comments-count. Pelo nome, tudo é bastante óbvio.
Herdaremos a classe str e adicionaremos a ele o método de extrair a substring localizada entre as duas tags:
class Str(str): def find_between(self, first, last): try: start = self.index(first) + len(first) end = self.index(last, start) return Str(self[start:end]) except ValueError: return Str("")
Você poderia ficar sem herança, mas isso permitirá que você escreva um código mais conciso. Com ele, toda extração de dados se encaixa em 4 linhas:
votes = data_str.find_between('span class="voting-wjt__counter voting-wjt__counter_positive js-score"', 'span').find_between('>', '<') bookmarks = data_str.find_between('span class="bookmark__counter js-favs_count"', 'span').find_between('>', '<') views = data_str.find_between('span class="post-stats__views-count"', 'span').find_between('>', '<') comments = data_str.find_between('span class="post-stats__comments-count"', 'span').find_between('>', '<')
Mas isso não é tudo. Como você pode ver, o número de comentários ou visualizações pode ser armazenado como uma sequência como "12,1k", que não é diretamente traduzida para int.
Adicione uma função para converter essa sequência em um número:
def to_int(self): s = self.lower().replace(",", ".") if s[-1:] == "k":
Resta apenas adicionar o registro de data e hora e você pode salvar os dados no csv:
timestamp = strftime("%Y-%m-%dT%H:%M:%S.000", gmtime()) str_out = "{},votes:{},bookmarks:{},views:{},comments:{};".format(timestamp, votes.to_int(), bookmarks.to_int(), views.to_int(), comments.to_int())
Como estamos interessados em analisar vários artigos, adicionamos a capacidade de especificar um link através da linha de comando. Também geraremos o nome do arquivo de log pelo ID do artigo:
link = sys.argv[1]
E o último passo. Pegamos o código na função, no loop, pesquisamos os dados e gravamos os resultados no log.
delay_s = 5*60 while True:
Como você pode ver, os dados foram atualizados a cada 5 minutos para não criar uma carga no servidor. Salvei o arquivo do programa com o nome habr_parse.py; quando ele iniciar, ele salvará os dados até que o programa seja fechado.
Além disso, é desejável salvar os dados, pelo menos por alguns dias. Porque Relutamos em manter o computador ligado por vários dias, pegamos o Raspberry Pi - ele terá energia suficiente para tal tarefa e, diferentemente de um PC, o Raspberry Pi não faz barulho e consome quase nenhuma eletricidade. Examinamos o SSH e executamos nosso script:
nohup python habr_parse.py https://habr.com/ru/post/0000001/ &
O comando nohup deixa o script em segundo plano depois de fechar o console.
Como bônus, você pode executar um servidor http em segundo plano digitando o comando “nuhup python -m SimpleHTTPServer 8000 &”. Isso permitirá que você assista os resultados diretamente no navegador a qualquer momento, abrindo um link no formulário
http://192.168.1.101:8000 (o endereço, é claro, pode ser diferente).
Agora você pode deixar o Raspberry Pi ativado e retornar ao projeto em alguns dias.
Análise de dados
Se tudo foi feito corretamente, a saída deve ser algo como este log:
2019-02-12T22:26:28.000,votes:12,bookmarks:0,views:448,comments:1; 2019-02-12T22:31:29.000,votes:12,bookmarks:0,views:467,comments:1; 2019-02-12T22:36:30.000,votes:14,bookmarks:1,views:482,comments:1; 2019-02-12T22:41:30.000,votes:14,bookmarks:2,views:497,comments:1; 2019-02-12T22:46:31.000,votes:14,bookmarks:2,views:513,comments:1; 2019-02-12T22:51:32.000,votes:14,bookmarks:2,views:527,comments:1; 2019-02-12T22:56:32.000,votes:14,bookmarks:2,views:543,comments:1; 2019-02-12T23:01:33.000,votes:14,bookmarks:2,views:557,comments:2; 2019-02-12T23:06:34.000,votes:14,bookmarks:2,views:567,comments:3; 2019-02-12T23:11:35.000,votes:13,bookmarks:2,views:590,comments:4; ... 2019-02-13T02:47:03.000,votes:15,bookmarks:3,views:1100,comments:20; 2019-02-13T02:52:04.000,votes:15,bookmarks:3,views:1200,comments:20;
Vamos ver como isso pode ser processado. Para começar, carregue o csv em um dataframe do pandas:
import pandas as pd import numpy as np import datetime log_path = "habr_data.txt" df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
Adicione funções para conversão e média e extraia os dados necessários:
def to_float(s):
A média é necessária porque o número de visualizações no site é exibido em incrementos de 100, o que leva a uma programação "rasgada". Em princípio, isso não é necessário, mas com a média parece melhor. O fuso horário de Moscou também é adicionado ao código (a hora no Raspberry Pi acabou sendo GMT).
Finalmente, você pode exibir os gráficos e ver o que aconteceu.
import matplotlib.pyplot as plt
Resultados
No início de cada gráfico, há um espaço vazio, que é explicado com simplicidade - quando o script foi lançado, os artigos já estavam publicados, para que os dados não fossem coletados do zero. O ponto "zero" foi adicionado manualmente a partir da descrição do tempo de publicação do artigo.
Todos os gráficos apresentados são gerados pelo matplotlib e pelo código acima.
De acordo com os resultados, dividi os artigos investigados em 3 grupos. A divisão é condicional, embora ainda tenha algum sentido.
Artigo quente
Este artigo trata de algum tópico popular e relevante, com um título como "Como o MTS deduz dinheiro" ou "Roskomnadzor bloqueou o
porn git hub".
Esses artigos têm um grande número de visualizações e comentários, mas o "hype" dura no máximo vários dias. Você também pode ver uma pequena diferença no crescimento do número de visualizações durante o dia e a noite (mas não tão significativo quanto o esperado - aparentemente, Habr é lido em quase todos os fusos horários).
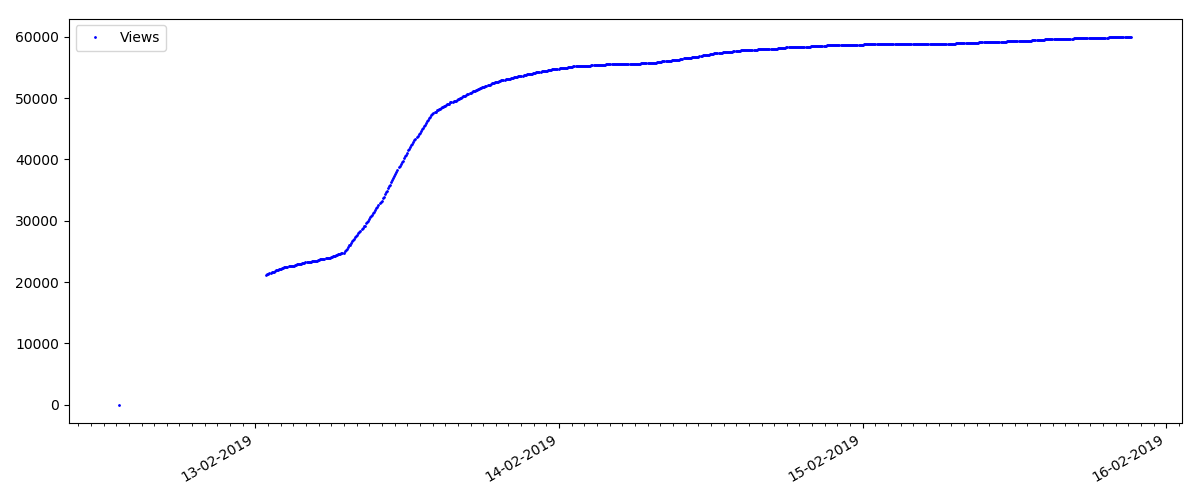
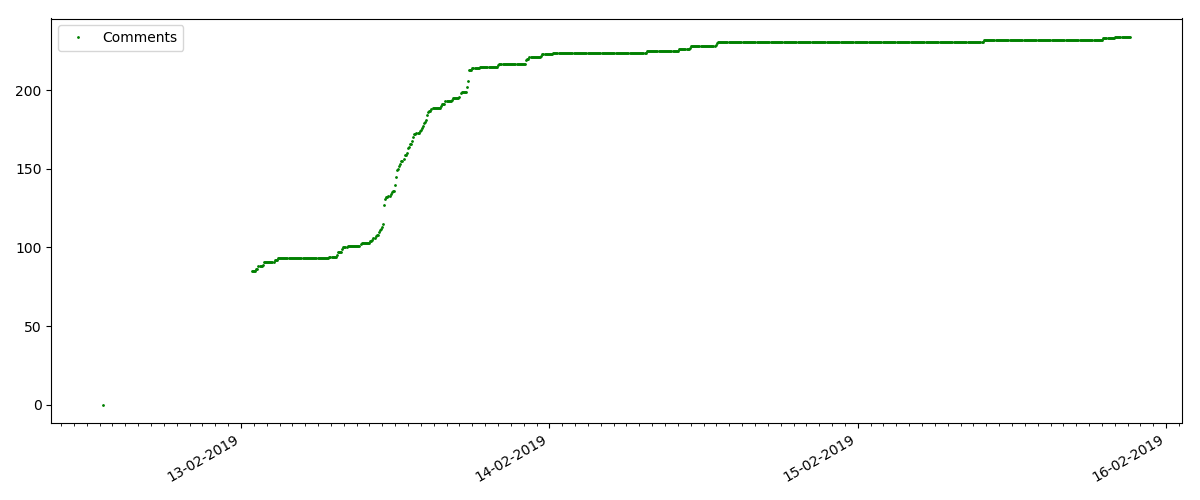
O número de "curtidas" está crescendo bastante, enquanto o número de marcadores está crescendo notavelmente mais devagar. Isso é lógico, porque Alguém pode gostar do artigo, mas a especificidade do texto é tal que simplesmente não é necessário marcá-lo.
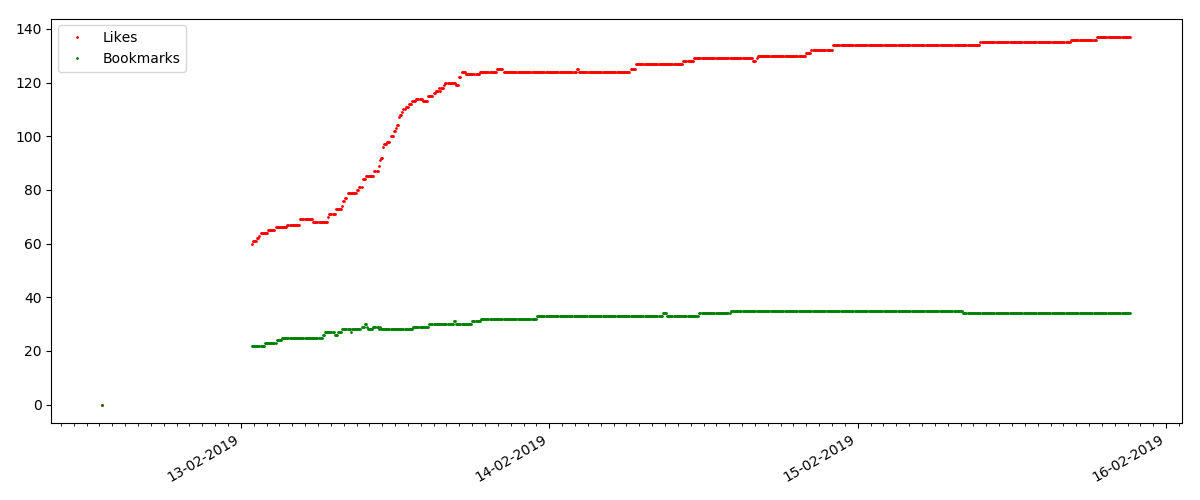
A proporção de visualizações e curtidas permanece aproximadamente a mesma e é aproximadamente 400: 1:
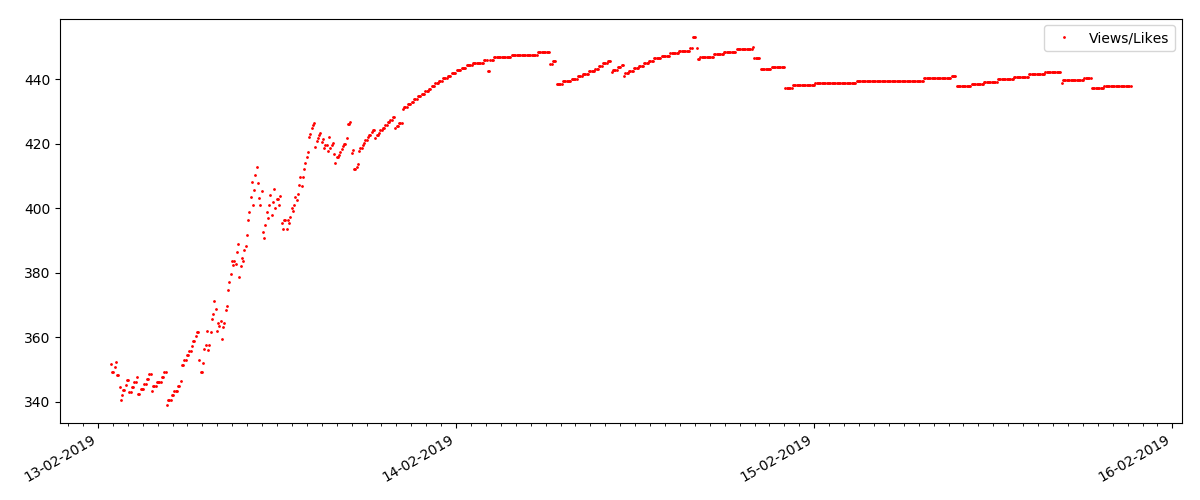
Artigo "Técnico"
Este é um artigo mais especializado, como “Configurando scripts para o nó JS”. Obviamente, um artigo desse tipo obtém muitas vezes menos visualizações do que o artigo “quente”, o número de comentários também é visivelmente menor (neste caso, havia apenas 4).
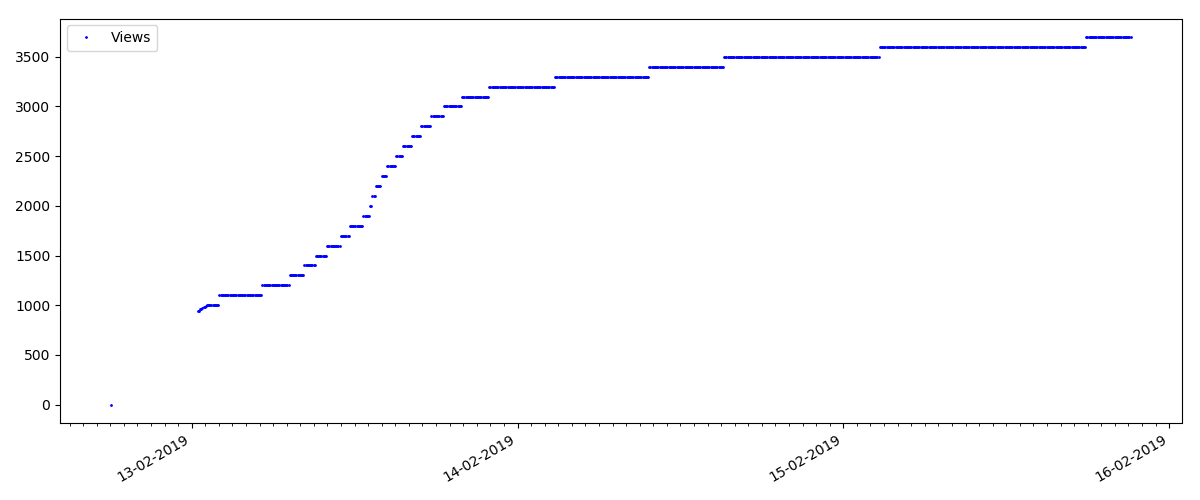
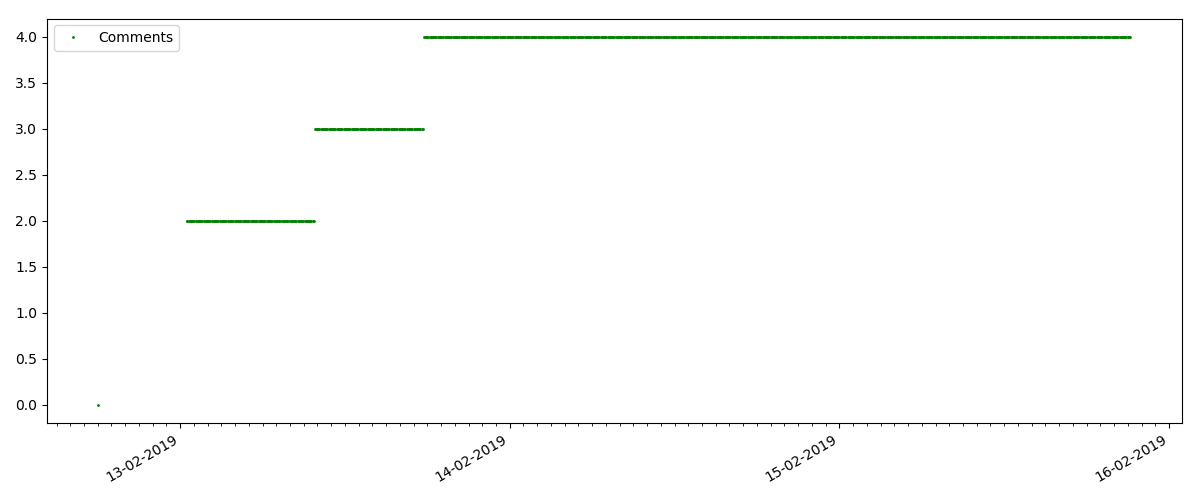
Mas o próximo ponto é mais interessante: o número de "curtidas" para esses artigos está crescendo notavelmente mais lento que o número de "marcadores". Aqui está o contrário, em comparação com a versão anterior - muitos acham o artigo útil para salvar para o futuro, mas o leitor não precisa clicar em "curtir".
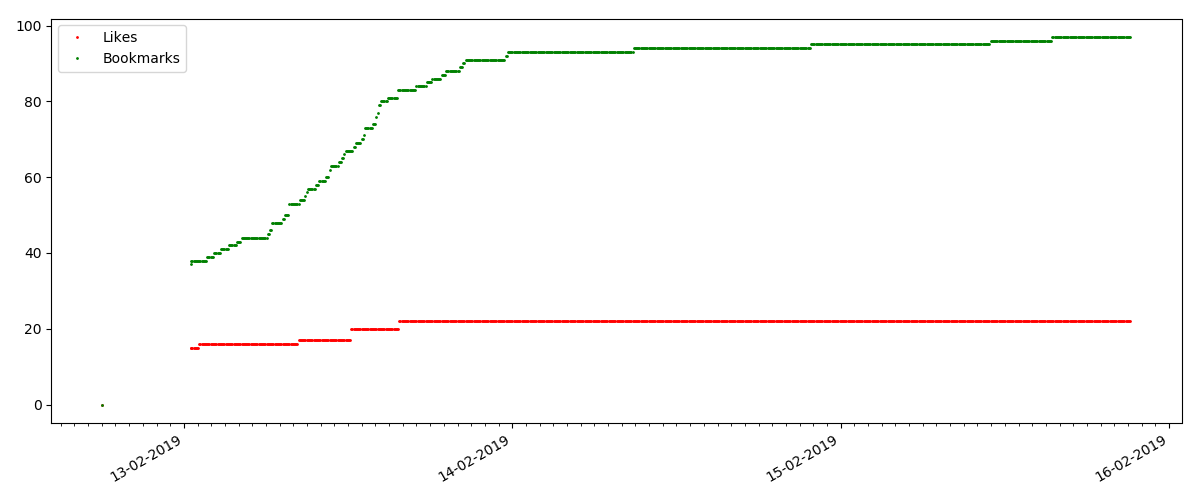
A propósito, neste momento, gostaria de chamar a atenção dos administradores do site - ao calcular as classificações dos artigos, você deve contar os marcadores em paralelo com os gostos (por exemplo, combinar conjuntos por OR). Caso contrário, isso leva a um viés na classificação, quando um artigo conhecido tem muitos favoritos (isto é, os leitores definitivamente gostaram), mas essas pessoas se esqueceram ou ficaram com preguiça de clicar em "curtir".
E, finalmente, a proporção de visualizações e gostos: você pode ver que é visivelmente mais alto do que na primeira modalidade e é aproximadamente 150: 1, ou seja, a qualidade do conteúdo indiretamente também pode ser considerada mais alta.
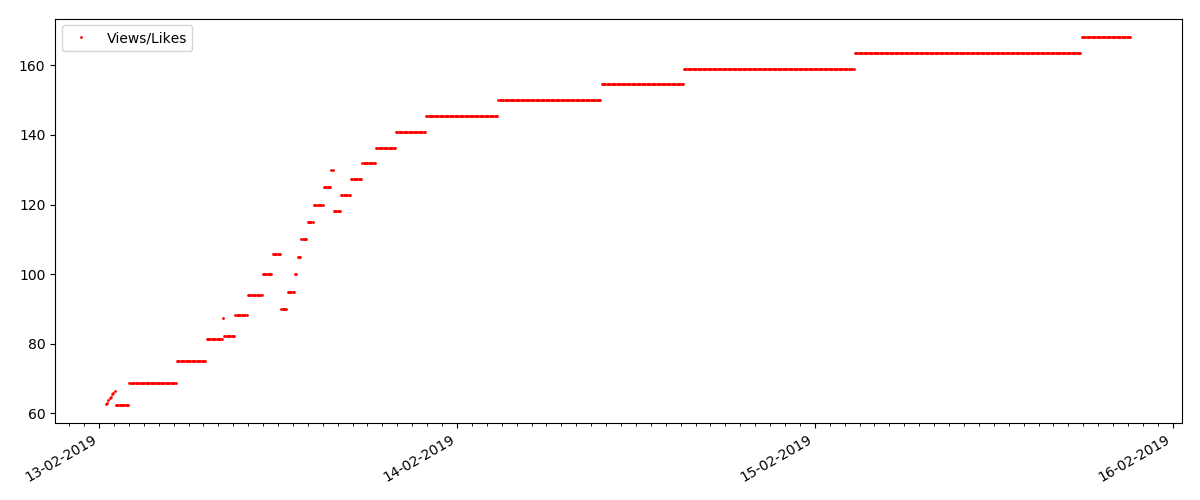
Artigo "Suspeito" (mas isso não é exato)
Para o próximo artigo examinado, o número de "curtidas" aumentou em um terço em um intervalo de 5 minutos (imediatamente em 10, com um total de 30 marcados nos vários dias).
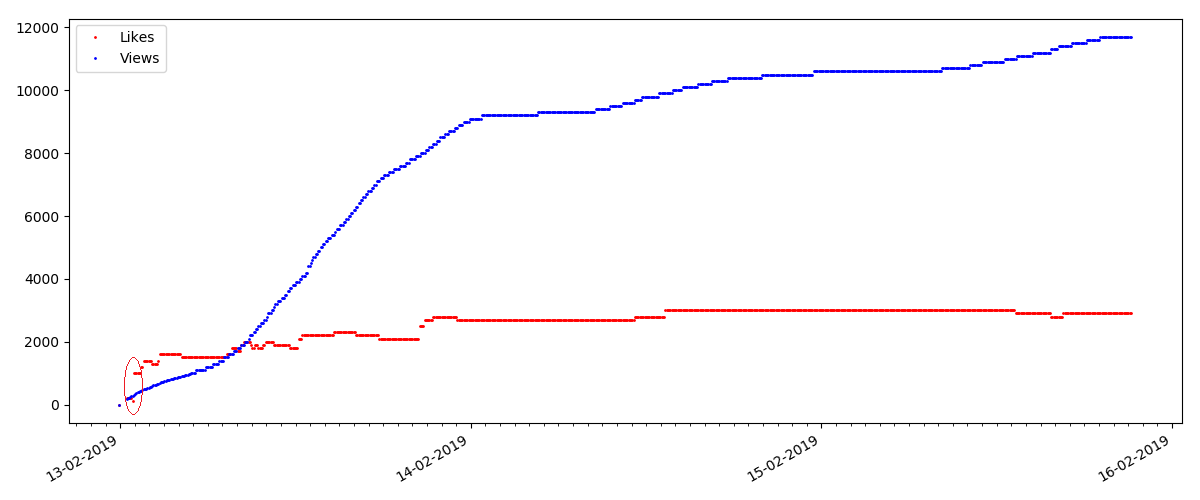
Pode-se suspeitar de uma trapaça, mas a "teoria das filas", em princípio, permite tais surtos. Ou talvez o autor tenha enviado o link para todos os seus 10 amigos, o que, é claro, não é proibido pelas regras.
Conclusões
A principal conclusão é que tudo é decadência e maya. Até o material mais popular, com milhares de visualizações, ficará "no passado" em apenas 3-4 dias. Tais, infelizmente, as especificidades da Internet moderna e, provavelmente, toda a indústria de mídia moderna como um todo. E tenho certeza de que os números mostrados são específicos não apenas para Habr, mas também para qualquer recurso similar da Internet.
Caso contrário, é mais provável que essa análise tenha natureza "sexta-feira" e, é claro, não pretende ser um estudo sério. Também espero que alguém tenha encontrado algo novo ao usar o Pandas e o Matplotlib.
Obrigado pela atenção.