Olá Habr! Nesta postagem, escreveremos um aplicativo no Spring Boot 2 usando o Apache Kafka no Linux, da instalação do JRE a um aplicativo de microsserviço em funcionamento.
Colegas do departamento de desenvolvimento front-end que viram o artigo reclamam que eu não estou explicando o que são Apache Kafka e Spring Boot. Acredito que quem precisa montar um projeto finalizado usando as tecnologias acima sabe o que é e por que precisa. Se para o leitor a pergunta não está ociosa, aqui estão excelentes artigos sobre Habré, o que são
Apache Kafka e
Spring Boot .
Podemos fazer sem longas explicações sobre o que são Kafka, Spring Boot e Linux e, em vez disso, executar o servidor Kafka do zero em uma máquina Linux, escrever dois microsserviços e fazer com que um deles envie mensagens para o outro - em geral, configure arquitetura completa de microsserviços.

A postagem será composta de duas seções. No primeiro, configuramos e executamos o Apache Kafka em uma máquina Linux; no segundo, escrevemos dois microsserviços em Java.
Na inicialização, na qual iniciei minha carreira profissional como programador, havia microsserviços no Kafka, e um dos meus microsserviços também trabalhava com outros através do Kafka, mas eu não sabia como o próprio servidor funcionava, se ele estava escrito como um aplicativo ou se já está completamente encaixotado produto. Qual foi minha surpresa e decepção quando o Kafka ainda era um produto in a box, e minha tarefa seria não apenas escrever um cliente em Java (o que eu amo fazer), como também implantar e configurar o aplicativo finalizado como devOps (que eu odeio fazer). No entanto, mesmo que eu possa aumentá-lo no servidor virtual Kafka em menos de um dia, é realmente muito simples fazer isso. Então
Nossa aplicação terá a seguinte estrutura de interação:
No final da postagem, como de costume, haverá links para o git com o código ativo.
Implantar o Apache Kafka + Zookeeper em uma máquina virtual
Tentei criar o Kafka no Linux local, em uma papoula e no Linux remoto. Em dois casos (Linux), consegui rapidamente. Com papoula ainda nada aconteceu. Portanto, criaremos o Kafka no Linux. Eu escolhi o Ubuntu 18.04.
Para que Kafka trabalhe, ela precisa de um tratador. Para fazer isso, você deve fazer o download e executá-lo antes de iniciar o Kafka.
Então
0. Instale o JRE
Isso é feito pelos seguintes comandos:
sudo apt-get update sudo apt-get install default-jre
Se tudo der certo, você poderá inserir o comando
java -version
e verifique se o Java está instalado.
1. Baixe o Zookeeper
Eu não gosto de equipes mágicas no Linux, especialmente quando eles dão apenas alguns comandos e não está claro o que estão fazendo. Portanto, descreverei cada ação - o que exatamente ela faz. Portanto, precisamos baixar o Zookeeper e descompactá-lo em uma pasta conveniente. É aconselhável que todos os aplicativos sejam armazenados na pasta / opt, ou seja, no nosso caso, será / opt / zookeeper.
Eu usei o comando abaixo. Se você conhece outros comandos do Linux que, na sua opinião, permitirão que você faça isso de maneira mais racial, use-os. Sou desenvolvedor, não devoto, e me comunico com servidores no nível da "própria cabra". Então, baixe o aplicativo:
wget -P /home/xpendence/downloads/ "http://apache-mirror.rbc.ru/pub/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz"
O aplicativo é baixado para a pasta que você especificar, criei a pasta / home / xpendence / downloads para baixar todos os aplicativos de que preciso.
2. Desembale o Zookeeper
Eu usei o comando:
tar -xvzf /home/xpendence/downloads/zookeeper-3.4.12.tar.gz
Este comando descompacta o arquivo morto na pasta em que você está localizado. Pode ser necessário transferir o aplicativo para / opt / zookeeper. E você pode entrar imediatamente nele e a partir daí já descompactar o arquivo.
3. Editar configurações
Na pasta / zookeeper / conf / há um arquivo zoo-sample.cfg, sugiro renomeá-lo para zoo.conf; é esse arquivo que a JVM procurará na inicialização. O seguinte deve ser adicionado a este arquivo no final:
tickTime=2000 dataDir=/var/zookeeper clientPort=2181
Além disso, crie o diretório / var / zookeeper.
4. Inicie o Zookeeper
Vá para a pasta / opt / zookeeper e inicie o servidor com o comando:
bin/zkServer.sh start
“INICIADO” deve aparecer.
Depois disso, proponho verificar se o servidor está funcionando. Escrevemos:
telnet localhost 2181
Uma mensagem deve aparecer dizendo que a conexão foi um sucesso. Se você tiver um servidor fraco e a mensagem não aparecer, tente novamente - mesmo quando STARTED aparecer, o aplicativo começará a escutar a porta muito mais tarde. Quando tentei tudo isso em um servidor fraco, isso aconteceu comigo todas as vezes. Se tudo estiver conectado, digite o comando
ruok
O que significa: "Você está bem?" O servidor deve responder:
imok ( !)
e desconecte. Então, tudo está de acordo com o plano. Prosseguimos com o lançamento do Apache Kafka.
5. Crie um usuário no Kafka
Para trabalhar com o Kafka, precisamos de um usuário separado.
sudo adduser --system --no-create-home --disabled-password --disabled-login kafka
6. Faça o download do Apache Kafka
Existem duas distribuições - binária e fontes. Nós precisamos de um binário. Na aparência, o arquivo com o binário é diferente em tamanho. O binário pesa 59 MB e 6,5 MB pesam.
Faça o download do binário no diretório lá, usando o link abaixo:
wget -P /home/xpendence/downloads/ "http://mirror.linux-ia64.org/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz"
7. Descompacte o Apache Kafka
O procedimento de desembalagem não é diferente do mesmo para o Zookeeper. Também descompactamos o arquivo morto no diretório / opt e o renomeamos para kafka, para que o caminho para a pasta / bin seja / opt / kafka / bin
tar -xvzf /home/xpendence/downloads/kafka_2.11-2.1.0.tgz
8. Editar configurações
As configurações estão em /opt/kafka/config/server.properties. Adicione uma linha:
delete.topic.enable = true
Essa configuração parece ser opcional, funciona sem ela. Essa configuração permite excluir tópicos. Caso contrário, você simplesmente não poderá excluir tópicos através da linha de comando.
9. Damos acesso aos diretórios do usuário kafka Kafka
chown -R kafka:nogroup /opt/kafka chown -R kafka:nogroup /var/lib/kafka
10. O tão esperado lançamento do Apache Kafka
Nós inserimos o comando, após o qual o Kafka deve iniciar:
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
Se as ações usuais (Kafka estão escritas em Java e Scala) não se espalharam no log, tudo funcionou e você pode testar nosso serviço.
10.1 Problemas fracos no servidor
Para experimentos no Apache Kafka, peguei um servidor fraco com um núcleo e 512 MB de RAM (por apenas 99 rublos), o que resultou em vários problemas para mim.
Falta de memória. Obviamente, você não pode fazer overclock com 512 MB e o servidor não pôde implantar o Kafka devido à falta de memória. O fato é que, por padrão, o Kafka consome 1 GB de memória. Não é à toa que ele estava desaparecido :)
Vamos para kafka-server-start.sh, zookeeper-server-start.sh. Já existe uma linha que regula a memória:
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
Altere para:
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
Isso reduzirá o apetite do Kafka e permitirá que você inicie o servidor.
O segundo problema com um computador fraco é a falta de tempo para se conectar ao Zookeeper. Por padrão, isso é dado 6 segundos. Se o ferro é fraco, é claro que isso não é suficiente. Em server.properties, aumentamos o tempo de conexão com o zukipper:
zookeeper.connection.timeout.ms=30000
Coloquei meio minuto.
11. Teste o Kafka-server
Para isso, abriremos dois terminais, em um lançaremos o produtor, por outro - o consumidor.
No primeiro console, insira uma linha:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Este ícone deve aparecer, indicando que o produtor está pronto para enviar mensagens de spam:
>
No segundo console, digite o comando:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
Agora, digitando no console do produtor, quando você pressionar Enter, ele aparecerá no console do consumidor.
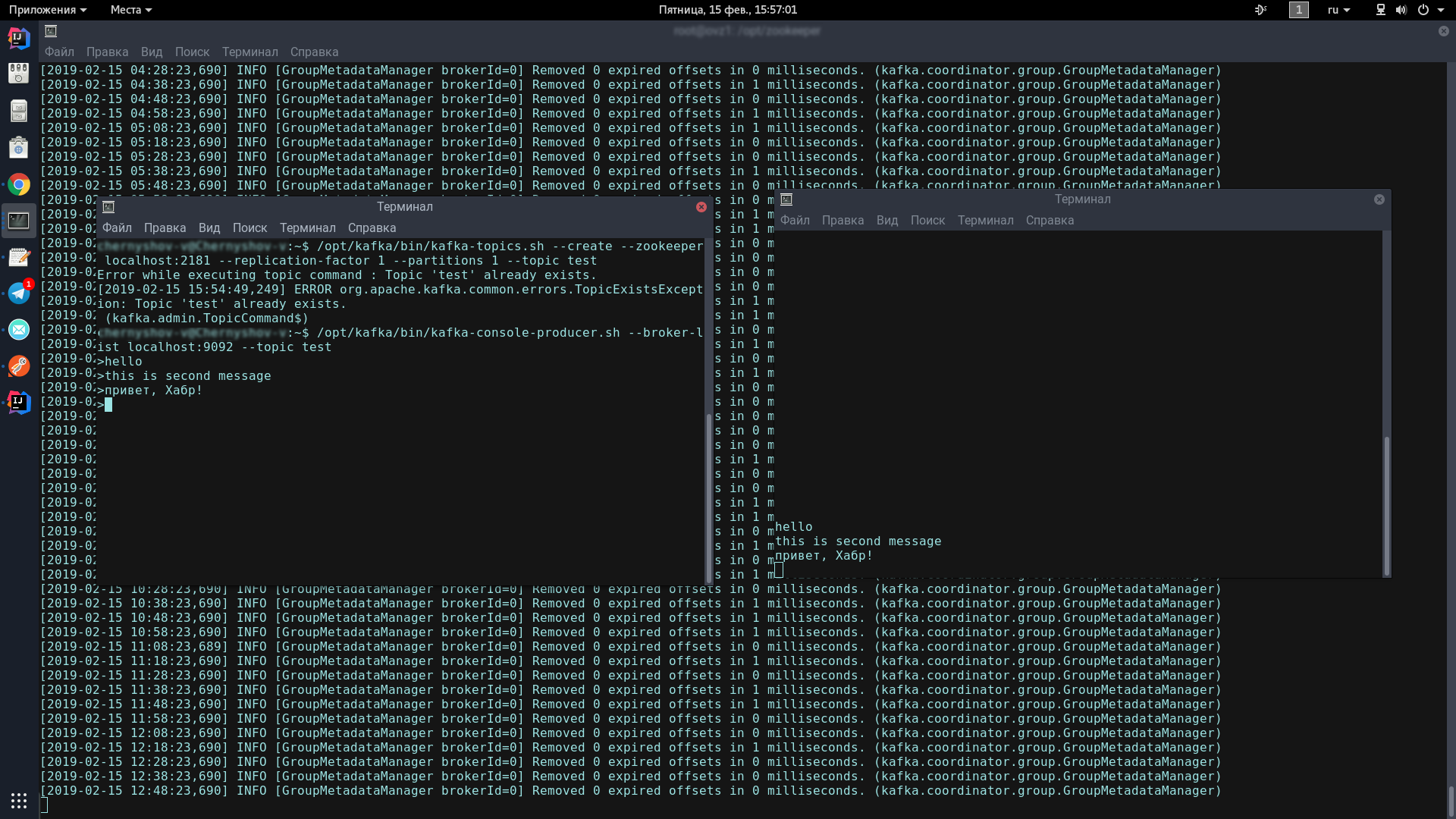
Se você vê na tela aproximadamente o mesmo que eu - parabéns, o pior já passou!
Agora, apenas precisamos escrever alguns clientes no Spring Boot que se comunicarão através do Apache Kafka.
Escrevendo um aplicativo no Spring Boot
Escreveremos dois aplicativos que trocarão mensagens através do Apache Kafka. A primeira mensagem será chamada kafka-server e conterá o produtor e o consumidor. O segundo será chamado kafka-tester, e foi projetado para termos uma arquitetura de microsserviço.
kafka-server
Para nossos projetos criados por meio do Spring Initializr, precisamos do módulo Kafka. Adicionei Lombok e Web, mas isso é uma questão de gosto.
O cliente Kafka consiste em dois componentes - o produtor (ele envia mensagens para o servidor Kafka) e o consumidor (ele escuta o servidor Kafka e recebe novas mensagens a partir daí sobre os tópicos nos quais está inscrito). Nossa tarefa é escrever os dois componentes e fazê-los funcionar.
Consumidor:
@Configuration public class KafkaConsumerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.group.id}") private String kafkaGroupId; @Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; } @Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } @Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); } @Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); } }
Precisamos de 2 campos inicializados com dados estáticos do kafka.properties.
kafka.server=localhost:9092 kafka.group.id=server.broadcast
kafka.server é o endereço no qual nosso servidor trava, nesse caso, local. Por padrão, Kafka escuta na porta 9092.
kafka.group.id é um grupo de consumidores, dentro do qual uma instância da mensagem é entregue. Por exemplo, você tem três correios em um grupo e todos ouvem o mesmo tópico. Assim que uma nova mensagem aparecer no servidor com este tópico, ela será entregue a alguém do grupo. Os dois consumidores restantes não estão recebendo a mensagem.
Em seguida, estamos criando uma fábrica para os consumidores - ConsumerFactory.
@Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); }
Inicializado com as propriedades de que precisamos, servirá como uma fábrica padrão para os consumidores no futuro.
@Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; }
consumerConfigs são apenas configurações de mapa. Nós fornecemos o endereço do servidor, grupo e desserializadores.
Além disso, um dos pontos mais importantes para um consumidor. O consumidor pode receber objetos únicos e coleções - por exemplo, StarshipDto e List. E se obtivermos StarshipDto como JSON, obteremos List como, grosso modo, como uma matriz JSON. Portanto, temos pelo menos duas fábricas de mensagens - para mensagens únicas e para matrizes.
@Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; }
Instanciamos ConcurrentKafkaListenerContainerFactory, digitamos Long (chave da mensagem) e AbstractDto (valor da mensagem abstrata) e inicializamos seus campos com propriedades. Obviamente, inicializamos a fábrica com nossa fábrica padrão (que já contém configurações de mapa), depois marcamos que não ouvimos pacotes (as mesmas matrizes) e especificamos um conversor JSON simples como conversor.
Quando criamos uma fábrica para pacotes / matrizes (lote), a principal diferença (além do fato de marcarmos que ouvimos pacotes) é que especificamos como conversor um conversor de pacote especial que converterá pacotes que consistem em de cadeias JSON.
@Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); }
E mais uma coisa. Ao inicializar os beans Spring, a lixeira com o nome kafkaListenerContainerFactory pode não ser contada e o aplicativo fica arruinado. Certamente existem opções mais elegantes para resolver o problema, escreva sobre elas nos comentários, por enquanto acabei de criar uma lixeira descarregada com funcionalidade com o mesmo nome:
@Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); }
O consumidor está configurado. Passamos para o produtor.
@Configuration public class KafkaProducerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.producer.id}") private String kafkaProducerId; @Bean public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, LongSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); props.put(ProducerConfig.CLIENT_ID_CONFIG, kafkaProducerId); return props; } @Bean public ProducerFactory<Long, StarshipDto> producerStarshipFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } @Bean public KafkaTemplate<Long, StarshipDto> kafkaTemplate() { KafkaTemplate<Long, StarshipDto> template = new KafkaTemplate<>(producerStarshipFactory()); template.setMessageConverter(new StringJsonMessageConverter()); return template; } }
Das variáveis estáticas, precisamos do endereço do servidor kafka e do ID do produtor. Ele pode ser qualquer coisa.
Nas configurações, como vemos, não há nada de especial. Quase a mesma coisa. Mas com relação às fábricas, há uma diferença significativa. Devemos registrar um modelo para cada classe, cujos objetos enviaremos para o servidor, bem como uma fábrica para ele. Temos um par desse tipo, mas pode haver dezenas deles.
No modelo, marcamos que serializaremos objetos em JSON, e isso, talvez, seja suficiente.
Temos um consumidor e um produtor, resta escrever um serviço que envie e receba mensagens.
@Service @Slf4j public class StarshipServiceImpl implements StarshipService { private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate; private final ObjectMapper objectMapper; @Autowired public StarshipServiceImpl(KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate, ObjectMapper objectMapper) { this.kafkaStarshipTemplate = kafkaStarshipTemplate; this.objectMapper = objectMapper; } @Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); } @Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); } private String writeValueAsString(StarshipDto dto) { try { return objectMapper.writeValueAsString(dto); } catch (JsonProcessingException e) { e.printStackTrace(); throw new RuntimeException("Writing value to JSON failed: " + dto.toString()); } } }
Existem apenas dois métodos em nosso serviço, eles são suficientes para explicar o trabalho do cliente. Autowire os padrões que precisamos:
private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate;
Método do produtor:
@Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); }
Tudo o que é necessário para enviar uma mensagem ao servidor é chamar o método send no modelo e transferir o tópico (assunto) e nosso objeto para lá. O objeto será serializado em JSON e voará para o servidor sob o tópico especificado.
O método de escuta é assim:
@Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); }
Marcamos esse método com a anotação @KafkaListener, onde indicamos qualquer ID que gostamos, ouvimos tópicos e uma fábrica que converterá a mensagem recebida no que precisamos. Nesse caso, como aceitamos um objeto, precisamos de uma única fábrica. Para Lista <?>, Especifique batchFactory. Como resultado, enviamos o objeto ao servidor kafka usando o método send e o obtemos usando o método consumir.
Você pode escrever um teste em 5 minutos que demonstrará toda a força do Kafka, mas iremos além - dedique 10 minutos e escreva outro aplicativo que enviará mensagens ao servidor que nosso primeiro aplicativo ouvirá.
kafka-tester
Tendo a experiência de escrever o primeiro aplicativo, podemos escrever facilmente o segundo, especialmente se copiarmos a pasta e o pacote dto, registrar apenas o produtor (enviaremos apenas mensagens) e adicionar o único método de envio ao serviço. Usando o link abaixo, você pode facilmente fazer o download do código do projeto e garantir que não haja nada complicado lá.
@Scheduled(initialDelay = 10000, fixedDelay = 5000) @Override public void produce() { StarshipDto dto = createDto(); log.info("<= sending {}", writeValueAsString(dto)); kafkaStarshipTemplate.send("server.starship", dto); } private StarshipDto createDto() { return new StarshipDto("Starship " + (LocalTime.now().toNanoOfDay() / 1000000)); }
Após os primeiros 10 segundos, o kafka-tester começa a enviar mensagens com os nomes de naves estelares para o servidor Kafka a cada 5 segundos (a imagem é clicável).
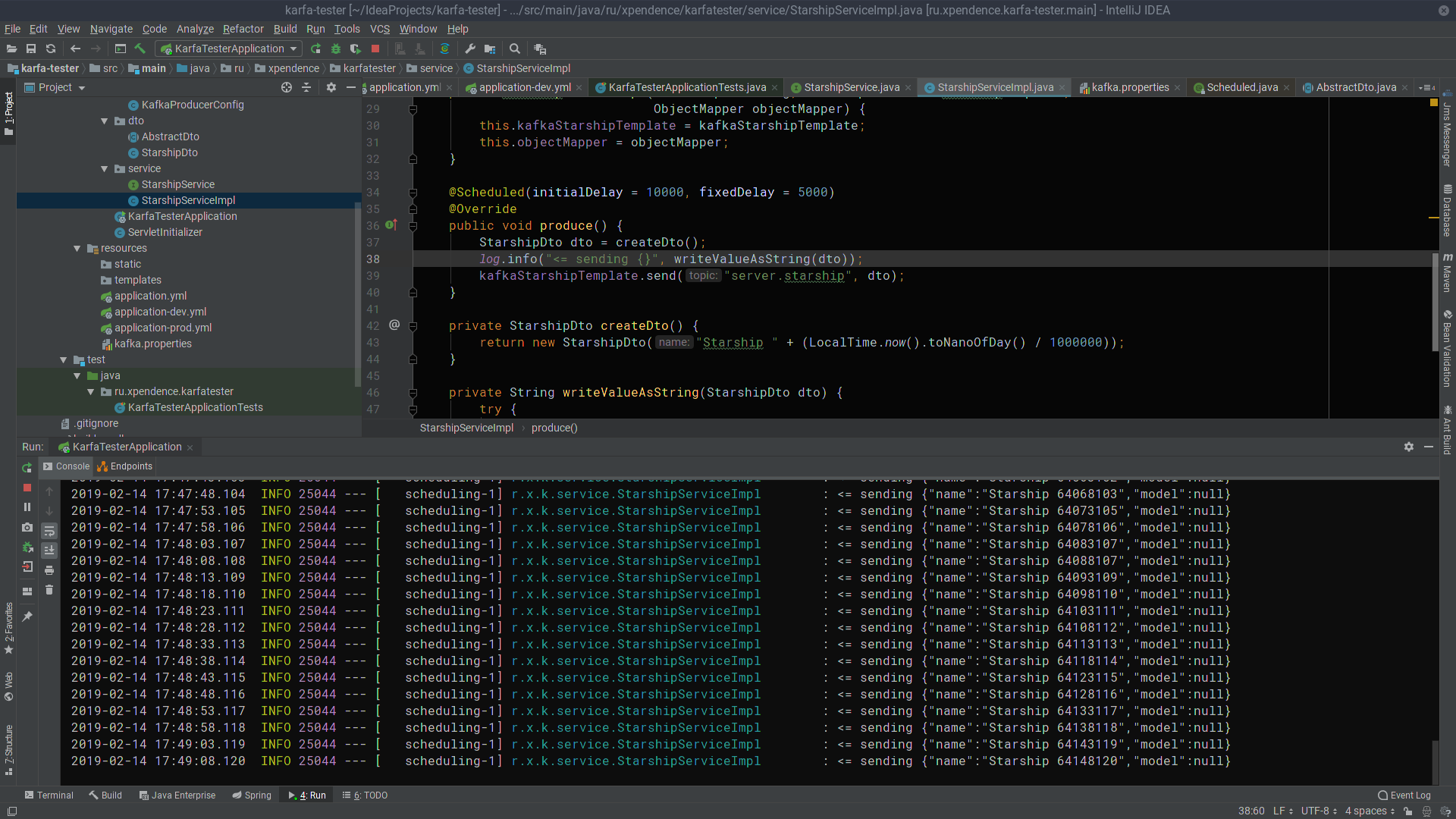
Lá, eles são ouvidos e recebidos pelo kafka-server (a imagem também é clicável).

Espero que aqueles que sonham em começar a escrever microsserviços na Kafka tenham sucesso tão facilmente quanto eu. E aqui estão os links para os projetos:
→
kafka-server→
kafka-tester