Oi, habrozhiteli!
Decidimos compartilhar a tradução do capítulo “Sistemas baseados em filas de tarefas”. Da novidade a seguir, “Sistemas distribuídos. Padrões de design ”(já na gráfica).
A forma mais simples de processamento em lote é a fila de tarefas. Em um sistema com uma fila de tarefas, há um conjunto de tarefas que devem ser concluídas. Cada tarefa é completamente independente das outras e pode ser processada sem nenhuma interação com elas. No caso geral, o objetivo de um sistema com uma fila de tarefas é garantir que cada estágio do trabalho seja concluído dentro de um determinado período de tempo. O número de fluxos de trabalho aumenta ou diminui de acordo com a alteração na carga. O esquema da fila de tarefas generalizadas é apresentado na Fig. 10.1
Um sistema baseado em uma fila de tarefas generalizada
A linha de tarefas é um exemplo ideal que demonstra todo o poder dos padrões de design de sistemas distribuídos. A maior parte da lógica da fila de tarefas não depende do tipo de trabalho executado. Em muitos casos, o mesmo se aplica à entrega das próprias tarefas.
Vamos ilustrar esta declaração usando a fila de tarefas mostrada na Fig. 10.1 Depois de examinar novamente, determine quais funções podem ser fornecidas por um conjunto compartilhado de contêineres. Torna-se aparente que a maior parte da implementação de uma fila de tarefas em contêiner pode ser usada por uma ampla variedade de usuários.
O enfileiramento de tarefas baseado em contêiner requer interfaces correspondentes entre os contêineres da biblioteca e os contêineres com a lógica do usuário. Na fila de tarefas em contêiner, são distinguidas duas interfaces: a interface do contêiner de origem, que fornece um fluxo de tarefas que requerem processamento, e a interface do contêiner em execução, que sabe como lidar com elas.
Interface do contêiner de origem
Qualquer fila de tarefas opera com base em um conjunto de tarefas que requerem processamento. Dependendo do aplicativo específico implementado com base na fila de tarefas, existem muitas fontes de tarefas que se enquadram nele. Porém, após receber um conjunto de tarefas, o esquema de operação da fila é bastante simples. Portanto, podemos separar a lógica específica do aplicativo da origem da tarefa do esquema generalizado de processamento da fila de tarefas. Recordando os padrões discutidos anteriormente de grupos de contêineres, aqui você pode ver a implementação do padrão Ambassador. O contêiner da fila de tarefas generalizada é o contêiner principal do aplicativo, e o contêiner de origem específico do aplicativo é um embaixador transmitindo solicitações do contêiner do despachante de fila para os executores de tarefas específicos. Este grupo de recipientes é mostrado na Fig. 10.2

A propósito, embora o embaixador de contêiner seja específico do aplicativo (o que é óbvio), também há várias implementações generalizadas da API de origem da tarefa. Por exemplo, a fonte pode ser uma lista de fotos localizadas em algum armazenamento na nuvem, um conjunto de arquivos em uma unidade de rede ou mesmo uma fila em sistemas operando com o princípio de "publicação / assinatura", como Kafka ou Redis. Apesar de os usuários poderem escolher os embaixadores de contêineres mais adequados para suas tarefas, eles devem usar uma implementação generalizada de “biblioteca” do próprio contêiner. Isso minimizará a quantidade de trabalho e maximizará a reutilização de código.
API da fila de tarefas Dado o mecanismo de interação entre a fila de tarefas e o embaixador de contêiner específico do aplicativo, devemos formular uma definição formal da interface entre os dois contêineres. Existem muitos protocolos diferentes, mas as APIs HTTP RESTful são fáceis de implementar e são o padrão de fato para essas interfaces. A fila de tarefas espera que os seguintes URLs sejam implementados no contêiner posterior:
Por que adicionar v1 à sua definição de API, você pergunta? Alguma vez haverá uma segunda versão da interface? Parece ilógico, mas o custo de versionamento da API quando definido inicialmente é mínimo. Realizar a refatoração apropriada posteriormente será extremamente caro. Estabeleça como regra adicionar versões a todas as APIs, mesmo se você não tiver certeza se elas serão alteradas. Deus salva o cofre.
URL / items / retorna uma lista de todas as tarefas:
{ kind: ItemList, apiVersion: v1, items: [ "item-1", "item-2", …. ] }
A URL / items / <item-name> fornece informações detalhadas sobre uma tarefa específica:
{ kind: Item, apiVersion: v1, data: { "some": "json", "object": "here", } }
Observe que a API não fornece nenhum mecanismo para corrigir o fato da tarefa. Pode-se desenvolver uma API mais complexa e transferir a maior parte da implementação para um embaixador de contêiner. Lembre-se, no entanto, que nosso objetivo é concentrar o máximo da implementação geral possível no gerenciador de filas de tarefas. Nesse sentido, o próprio gerenciador de filas de tarefas deve monitorar quais tarefas já foram processadas e quais ainda precisam ser processadas.
A partir dessa API, obtemos informações sobre uma tarefa específica e depois passamos o valor do campo item.data da interface do contêiner do executor.
Executando a interface do contêiner
Assim que o gerenciador de filas receber a próxima tarefa, ele deverá confiá-la a algum executor. Essa é a segunda interface na fila de tarefas generalizada. O próprio contêiner e sua interface são ligeiramente diferentes da interface do contêiner de origem por vários motivos. Em primeiro lugar, é uma API única. O trabalho do executor começa com uma única chamada e, durante o ciclo de vida do contêiner, nenhuma outra chamada é feita. Em segundo lugar, o contêiner em execução e o gerenciador de filas de tarefas estão em diferentes grupos de contêineres. O executor de contêiner é iniciado por meio da API do orquestrador de contêineres em seu próprio grupo. Isso significa que o gerenciador de filas de tarefas deve fazer uma chamada remota para iniciar o contêiner de execução. Isso também significa que você deve ter mais cuidado com problemas de segurança, pois um usuário mal-intencionado do cluster pode carregá-lo com trabalho desnecessário.
No contêiner de origem, usamos uma chamada HTTP simples para enviar a lista de tarefas ao gerenciador de tarefas. Isso foi feito no pressuposto de que essa chamada à API precisava ser feita várias vezes e os problemas de segurança não foram levados em consideração, pois tudo funcionava na estrutura do host local. A API do contêiner deve ser chamada apenas uma vez e é importante garantir que outros usuários do sistema não possam adicionar trabalho aos executores, mesmo por acidente ou por intenção maliciosa. Portanto, para o contêiner em execução, usaremos a API do arquivo. Após a criação, transmitiremos ao contêiner uma variável de ambiente chamada WORK_ITEM_FILE, cujo valor se refere a um arquivo no sistema de arquivos interno do contêiner. Este arquivo contém dados sobre a tarefa a ser concluída. Esse tipo de API, como mostrado abaixo, pode ser implementado pelo objeto ConfigMap Kubernetes. Pode ser montado em um grupo de contêineres como um arquivo (Fig. 10.3).
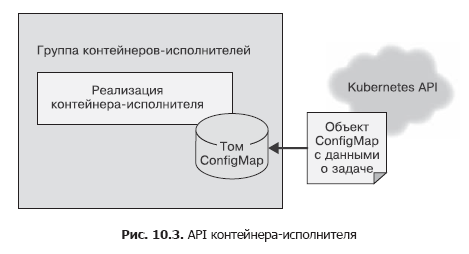
Esse mecanismo de API de arquivo é mais fácil de implementar usando um contêiner. Um executor dentro de uma fila de tarefas geralmente é um script de shell simples que acessa várias ferramentas. Não é prático criar um servidor Web inteiro para gerenciamento de tarefas - isso leva a uma complicação da arquitetura. Como no caso das fontes de tarefas, a maioria dos executores de contêineres será contêineres especializados para determinadas tarefas, mas também existem executores generalizados aplicáveis à resolução de várias tarefas diferentes.
Considere o exemplo de um contêiner em execução que baixa um arquivo do armazenamento em nuvem, executa um script de shell nele e copia o resultado novamente para o armazenamento em nuvem. Esse contêiner pode ser geralmente geral, mas um cenário específico pode ser passado a ele como parâmetro. Assim, a maior parte do código de manipulação de arquivos pode ser reutilizada por muitos usuários / filas de tarefas. O usuário final precisa apenas fornecer um script contendo as especificidades do processamento do arquivo.
Infraestrutura comum da fila de tarefas
O que resta a ser implementado em uma implementação de fila reutilizável se você já possui implementações das duas interfaces de contêiner descritas anteriormente? O algoritmo básico da fila de tarefas é bastante simples.
- Faça o download das tarefas atualmente disponíveis no contêiner de origem.
- Esclareça o status da fila de tarefas para quais tarefas já foram concluídas ou ainda estão sendo executadas.
- Para cada uma das tarefas não resolvidas, crie contêineres de contêiner com uma interface apropriada.
- Após a conclusão bem-sucedida do contêiner em execução, registre que a tarefa foi concluída.
Esse algoritmo é simples em palavras, mas na realidade não é tão fácil de implementar. Felizmente, a orquestra Kubernetes possui vários recursos que simplificam bastante sua implementação. A saber: o Kubernetes possui um objeto de trabalho que garante uma operação confiável da fila de tarefas. Você pode configurar o objeto Job para que ele inicie o contêiner em execução correspondente uma vez ou até que a tarefa seja concluída com êxito. Se você configurar o contêiner em execução para que seja executado antes que a tarefa seja concluída, mesmo quando a máquina no cluster falhar, a tarefa será concluída com êxito.
Assim, o enfileiramento de tarefas é bastante simplificado, pois a orquestra assume a responsabilidade pela execução confiável das tarefas.
Além disso, o Kubernetes permite que você anote tarefas, o que nos permite marcar cada objeto de tarefa com o nome do elemento da fila de tarefas processadas. Está se tornando mais fácil distinguir entre tarefas que são processadas e concluídas com êxito e com erro.
Isso significa que podemos implementar a fila de tarefas no topo do orquestrador Kubernetes sem usar nosso próprio repositório. Tudo isso simplifica bastante a tarefa de construir a infraestrutura da fila de tarefas.
Portanto, um algoritmo detalhado para a operação do contêiner, o gerenciador de filas de tarefas, é o seguinte.
Repita sem parar.
- Obtenha a lista de tarefas através da interface do contêiner - a origem das tarefas.
- Obtenha uma lista de tarefas que atendem a essa fila de tarefas.
- Com base nessas listas, selecione uma lista de tarefas não processadas.
- Para cada tarefa não processada, crie um objeto Job que gera o contêiner em execução correspondente.
Aqui está um script Python que implementa esta fila:
import requests import json from kubernetes import client, config import time namespace = "default" def make_container(item, obj): container = client.V1Container() container.image = "my/worker-image" container.name = "worker" return container def make_job(item): response = requests.get("http://localhost:8000/items/{}".format(item)) obj = json.loads(response.text) job = client.V1Job() job.metadata = client.V1ObjectMeta() job.metadata.name = item job.spec = client.V1JobSpec() job.spec.template = client.V1PodTemplate() job.spec.template.spec = client.V1PodTemplateSpec() job.spec.template.spec.restart_policy = "Never" job.spec.template.spec.containers = [ make_container(item, obj) ] return job def update_queue(batch): response = requests.get("http://localhost:8000/items") obj = json.loads(response.text) items = obj['items'] ret = batch.list_namespaced_job(namespace, watch=False) for item in items: found = False for i in ret.items: if i.metadata.name == item: found = True if not found: # Job, # job = make_job(item) batch.create_namespaced_job(namespace, job) config.load_kube_config() batch = client.BatchV1Api() while True: update_queue(batch) time.sleep(10)
Seminário Implementação de um gerador de miniaturas para arquivos de vídeo
Como exemplo de uso da fila de tarefas, considere a tarefa de gerar miniaturas de arquivos de vídeo. Com base nessas miniaturas, os usuários decidem quais vídeos eles querem assistir.
Para implementar as miniaturas, você precisa de dois contêineres. O primeiro é para a fonte das tarefas. Será mais fácil colocar tarefas em uma unidade de rede compartilhada conectada, por exemplo, via NFS (Sistema de arquivos de rede, sistema de arquivos de rede). A fonte da tarefa recebe uma lista de arquivos nesse diretório e os passa para o chamador.
Vou dar um programa simples no NodeJS:
const http = require('http'); const fs = require('fs'); const port = 8080; const path = process.env.MEDIA_PATH; const requestHandler = (request, response) => { console.log(request.url); fs.readdir(path + '/*.mp4', (err, items) => { var msg = { 'kind': 'ItemList', 'apiVersion': 'v1', 'items': [] }; if (!items) { return msg; } for (var i = 0; i < items.length; i++) { msg.items.push(items[i]); } response.end(JSON.stringify(msg)); }); } const server = http.createServer(requestHandler); server.listen(port, (err) => { if (err) { return console.log(' ', err); } console.log(` ${port}`) });
Esta fonte define a lista de filmes a serem processados. O utilitário ffmpeg é usado para extrair miniaturas.
Você pode criar um contêiner que execute o seguinte comando:
ffmpeg -i ${INPUT_FILE} -frames:v 100 thumb.png
O comando extrai um em cada 100 quadros (parâmetro -frames: v 100) e o salva no formato PNG (por exemplo, thumb1.png, thumb2.png, etc.).
Esse tipo de processamento pode ser implementado com base na imagem existente do ffmpeg Docker. A
imagem de jrottenberg / ffmpeg é popular.
Ao definir um contêiner de origem simples e um executor de contêiner ainda mais simples, é fácil ver os benefícios de um sistema de gerenciamento de filas genérico e orientado a contêiner. Reduz significativamente o tempo entre o design e a implementação da fila de tarefas.
Dimensionamento dinâmico de artistas
A fila de tarefas considerada anteriormente é bem adequada para processar tarefas à medida que se tornam disponíveis, mas pode levar a uma carga abrupta nos recursos do orquestrador de cluster de contêineres. Isso é bom quando você tem muitos tipos diferentes de tarefas que criam picos de carga em momentos diferentes e, assim, distribuem uniformemente a carga no cluster ao longo do tempo.
Mas se você não tiver tipos de carga suficientes, a abordagem "então espessa e vazia" para escalar a fila de tarefas pode exigir a reserva de recursos adicionais para suportar rajadas de carga. O resto do tempo, os recursos ficarão ociosos, esvaziando desnecessariamente sua carteira.
Para resolver esse problema, você pode limitar o número total de objetos de trabalho gerados pela fila de tarefas. Isso naturalmente limita o número de trabalhos processados em paralelo e, consequentemente, reduz o uso de recursos durante picos de carga. Por outro lado, a duração de cada tarefa individual aumentará com uma carga alta no cluster.
Se a carga for espasmódica, isso não será assustador, pois os intervalos de tempo de inatividade podem ser usados para concluir as tarefas acumuladas. No entanto, se a carga constante for muito alta, a fila de tarefas não terá tempo para processar as tarefas recebidas e cada vez mais será gasto em sua implementação.
Em tal situação, você precisará ajustar dinamicamente o número máximo de tarefas paralelas e, consequentemente, os recursos de computação disponíveis para manter o nível de desempenho necessário. Felizmente, existem fórmulas matemáticas que permitem determinar quando é necessário escalar a fila de tarefas para processar mais solicitações.
Considere uma fila de tarefas em que uma nova tarefa apareça em média uma vez por minuto, e sua conclusão leve em média 30 segundos. Essa fila é capaz de lidar com o fluxo de tarefas que entram nela. Mesmo que um grande pacote de tarefas chegue ao mesmo tempo, criando um engarrafamento, o engarrafamento será eliminado com o tempo, porque antes da próxima tarefa chegar, a fila consegue processar uma média de duas tarefas.
Se uma nova tarefa chegar a cada minuto e levar uma média de 1 minuto para processar uma tarefa, esse sistema será idealmente equilibrado, mas não responderá bem a alterações na carga. Ela é capaz de lidar com rajadas de carga, mas isso levará bastante tempo. O sistema não ficará ocioso, mas não haverá reserva de tempo no computador para compensar o aumento a longo prazo na velocidade de recebimento de novas tarefas. Para manter a estabilidade do sistema, é necessário ter uma reserva em caso de aumento de carga a longo prazo ou atrasos imprevistos nas tarefas de processamento.
Por fim, considere um sistema no qual uma tarefa por minuto chega e o processamento da tarefa leva dois minutos. Esse sistema constantemente perde desempenho. A duração da fila de tarefas aumentará junto com o atraso entre o recebimento e o processamento de tarefas (e o grau de irritação dos usuários).
Os valores desses dois indicadores devem ser constantemente monitorados. Ao calcular a média do tempo entre o recebimento de tarefas por um longo período, por exemplo, com base no número de tarefas por dia, obtemos uma estimativa do intervalo entre tarefas. Também é necessário monitorar o tempo médio de processamento da tarefa (excluindo o tempo gasto na fila). Em uma fila de tarefas estável, o tempo médio de processamento da tarefa deve ser menor que o intervalo entre tarefas. Para garantir que essa condição seja atendida, é necessário ajustar dinamicamente o número de filas disponíveis de recursos de computação. Se os trabalhos forem processados em paralelo, o tempo de processamento deverá ser dividido pelo número de trabalhos processados em paralelo. Por exemplo, se uma tarefa é processada por minuto, mas quatro são processadas em paralelo, o tempo efetivo de processamento de uma tarefa é de 15 segundos, o que significa que o intervalo entre tarefas deve ser de pelo menos 16 segundos.
Essa abordagem permite criar facilmente um módulo para escalar a fila de tarefas para cima. A redução é um pouco mais problemática. No entanto, é possível usar os mesmos cálculos de antes, estabelecendo adicionalmente a reserva de recursos computacionais determinados pela maneira heurística. Por exemplo, você pode reduzir o número de tarefas paralelas até que o tempo de processamento de uma tarefa seja 90% do intervalo entre tarefas.
Padrão Multi-Trabalhador
Um dos principais tópicos deste livro é o uso de contêineres para encapsular e reutilizar o código. Também é relevante para os padrões de enfileiramento de tarefas descritos neste capítulo. Além dos contêineres que gerenciam a fila, é possível reutilizar grupos de contêineres que compõem a implementação dos executores. Suponha que você precise processar cada tarefa em uma fila de três maneiras diferentes. Por exemplo, para detectar rostos em uma fotografia, combine-os com pessoas específicas e depois desfoque as partes correspondentes da imagem. Você pode colocar todo o processamento em um contêiner em execução, mas esta é uma solução única que não pode ser reutilizada. Para encobrir outra coisa, como carros, na foto, você precisará criar um artista de contêiner do zero.
A possibilidade desse tipo de reutilização pode ser alcançada aplicando o padrão Multi-Worker, que é realmente um caso especial do padrão Adapter descrito no início do livro. O padrão Multi-Worker converte um conjunto de contêineres em um contêiner comum com a interface do software do contêiner em execução. Esse contêiner compartilhado delega o processamento para vários contêineres reutilizáveis separados. Este processo é mostrado esquematicamente na Fig. 10.4
Ao reutilizar o código combinando a execução de contêineres, o trabalho das pessoas que projetam sistemas de processamento em lote distribuído é reduzido.
»Mais informações sobre o livro podem ser encontradas no
site do editor»
Conteúdo»
TrechoPara habrozhitelami desconto de 20% no cupom -
sistemas distribuídos .