Hardware e compiladores modernos estão prontos para virar nosso código de cabeça para baixo, se ele funcionar mais rápido. E seus fabricantes escondem cuidadosamente sua cozinha interna. E está tudo bem, desde que o código seja executado em um thread.
Em um ambiente multithread, você pode observar constantemente coisas interessantes. Por exemplo, a execução de instruções do programa não está na ordem que está escrita no código-fonte. Concordo, é desagradável perceber que executar o código fonte linha por linha é apenas nossa imaginação.
Mas todo mundo já percebeu, porque de alguma forma você tem que viver com isso. E os programadores Java até vivem bem. Como o Java possui um modelo de memória - o Java Memory Model (JMM), que fornece regras bastante simples para escrever o código multiencadeado correto.
E essas regras são suficientes para a maioria dos programas. Se você não os conhece, mas escreve ou deseja escrever programas multithread em Java, é melhor se familiarizar com
eles o mais rápido possível. E se você souber, mas você não tem contexto suficiente ou é interessante saber de onde as pernas da JMM crescem, este artigo pode ajudá-lo.
E perseguindo abstração
Na minha opinião, há uma torta, ou, mais adequado, um iceberg. JMM é a ponta do iceberg. O iceberg em si é uma teoria da programação multithread sob a água. Sob o iceberg está o inferno.

Um iceberg é uma abstração; se vazar, certamente veremos o inferno. Embora muitas coisas interessantes estejam acontecendo por lá, no artigo de revisão, não chegaremos a isso.
No artigo, estou mais interessado nos seguintes tópicos:
- Teoria e Terminologia
- Como a teoria da programação multithread é refletida no JMM
- Modelos de Programação Competitiva
A teoria da programação multithread permite que você se afaste da complexidade dos processadores e compiladores modernos, e simula a execução de programas multithread e estuda suas propriedades. Roman Elizarov fez um excelente
relatório , cujo objetivo é fornecer uma base teórica para a compreensão do JMM. Eu recomendo o relatório a todos os interessados neste tópico.
Por que é importante conhecer a teoria? Na minha opinião, espero apenas que, alguns programadores tenham uma opinião de que o JMM é uma complicação da linguagem e correção de alguns problemas de plataforma com multithreading. A teoria mostra que o Java não complicou, mas simplificou e tornou a programação multithread muito mais previsível e complexa.
Concorrência e Concorrência
Primeiro, vamos olhar para a terminologia. Infelizmente, não há consenso na terminologia - ao estudar diferentes materiais, você pode encontrar diferentes definições de concorrência e simultaneidade.
O problema é que, mesmo que cheguemos ao fundo da verdade e encontremos as definições exatas desses conceitos, ainda não vale a pena esperar que todos signifiquem a mesma coisa com esses conceitos. Você não
encontrará os fins aqui.
Roman Elizarov, em um relatório, a teoria da programação paralela para os profissionais sugere que às vezes esses conceitos são mistos. A programação paralela às vezes se distingue como um conceito geral dividido em competitivo e distribuído.
Parece-me que, no contexto do JMM, você ainda precisa separar concorrência e paralelismo, ou melhor, até entender que existem dois paradigmas diferentes, não importa como eles sejam chamados.
Muitas vezes citado por Rob Pike, que distingue os conceitos da seguinte maneira:
- A concorrência é uma maneira de resolver simultaneamente muitos problemas
- A simultaneidade é uma maneira de executar diferentes partes de uma única tarefa.
A opinião de Rob Pike não é um padrão, mas, na minha opinião, é conveniente desenvolvê-lo para aprofundar o estudo da questão. Leia mais sobre as diferenças
aqui .
Provavelmente, uma maior compreensão do problema aparecerá se destacarmos os principais recursos de um programa competitivo e paralelo. Existem muitos sinais, considere os mais significativos.
Sinais de competição.
- A presença de vários fluxos de controle (por exemplo, Thread em Java, corotina no Kotlin), se houver apenas um fluxo de controle, não haverá execução competitiva
- Resultado não determinístico. O resultado depende de eventos aleatórios, implementação e como a sincronização foi realizada. Mesmo que cada fluxo seja completamente determinístico, o resultado final será não determinístico
Um programa paralelo terá um conjunto diferente de recursos.
- Opcional possui vários fluxos de controle
- Isso pode levar a um resultado determinístico, por exemplo, o resultado da multiplicação de cada elemento da matriz por um número não será alterado se você o multiplicar em partes em paralelo
Curiosamente, a execução paralela é possível em um único fluxo de controle e até em uma arquitetura de núcleo único. O fato é que o paralelismo no nível de tarefas (ou fluxos de controle) aos quais estamos acostumados não é a única maneira de realizar cálculos em paralelo.
A simultaneidade é possível no nível de:
- bits (por exemplo, em máquinas de 32 bits, a adição ocorre em uma ação, processando todos os 4 bytes de um número de 32 bits em paralelo)
- instruções (em um núcleo, em um thread, o processador pode executar instruções em paralelo, apesar do código ser seqüencial)
- dados (existem arquiteturas com processamento paralelo de dados (dados múltiplos de instrução única) que podem executar uma instrução em um grande conjunto de dados)
- tarefas (implica a presença de vários processadores ou núcleos)
A simultaneidade no nível da instrução é um exemplo de otimizações que ocorrem com a execução de código ocultas do programador.
É garantido que o código otimizado será equivalente ao original dentro da estrutura de um thread, porque é impossível escrever um código adequado e previsível se ele não fizer o que o programador pretendia.
Nem tudo o que é executado em paralelo é importante para o JMM. A execução simultânea no nível da instrução em um único encadeamento não é considerada no JMM.
A terminologia é muito instável, com uma apresentação de Roman Elizarov chamada "Teoria da programação
paralela para profissionais", embora exista mais sobre programação competitiva, se você se ater ao que foi dito acima.
No contexto do JMM, no artigo vou me ater ao termo competição, uma vez que a competição é geralmente sobre o estado geral. Mas aqui você precisa ter cuidado para não se apegar a termos, mas entenda que existem paradigmas diferentes.
Modelos com um estado comum: "rotação de operações" e "aconteceu antes"
Em seu
artigo, Maurice Herlichi (autor da programação The Art Of Multiprocessor) escreve que um sistema competitivo contém uma coleção de processos seqüenciais (em trabalhos teóricos significa o mesmo que um encadeamento) que se comunicam através da memória compartilhada.
O modelo de estado geral inclui cálculos com mensagens, em que o estado compartilhado é uma fila de mensagens e cálculos com memória compartilhada, onde o estado comum são estruturas na memória.
Cada um dos cálculos pode ser simulado.
O modelo é baseado em uma máquina de estados finitos. O modelo se concentra exclusivamente no estado compartilhado e os dados locais de cada um dos fluxos são completamente ignorados. Cada ação dos fluxos sobre um estado compartilhado é uma função da transição para um novo estado.
Por exemplo, se 4 threads gravam dados em uma variável compartilhada, haverá 4 funções para a transição para um novo estado. Qual dessas funções será aplicada depende da cronologia dos eventos no sistema.
Os cálculos de passagem de mensagens são modelados de maneira semelhante, apenas as funções de estado e de transição dependem do envio ou recebimento de mensagens.
Se o modelo lhe pareceu complicado, no exemplo, vamos corrigi-lo. É realmente muito simples e intuitivo. Tanto é assim que, sem conhecer a existência desse modelo, a maioria das pessoas ainda analisará o programa como o modelo sugere.
Esse modelo é chamado de modelo de
desempenho por meio da alternância de operações (o nome foi ouvido em um relatório por Roman Elizarov).
Na intuição e na naturalidade, você pode escrever com segurança as vantagens do modelo. Você pode entrar no mundo selvagem com as palavras-chave
Consistência sequencial e o
trabalho de Leslie Lamport.
No entanto, há um esclarecimento importante sobre esse modelo. O modelo tem a limitação de que todas as ações em um estado compartilhado devem ser instantâneas e, ao mesmo tempo, as ações não podem ocorrer simultaneamente. Eles dizem que esse sistema tem uma
ordem linear - todas as ações no sistema são ordenadas.
Na prática, isso não acontece. A operação não ocorre instantaneamente, mas é executada em um intervalo; em sistemas com vários núcleos, esses intervalos podem se cruzar. Obviamente, isso não significa que o modelo seja inútil na prática, basta criar certas condições para seu uso.
Enquanto isso, considere outro
modelo - “aconteceu antes”, que não se concentra no estado, mas no conjunto de células de memória de leitura e gravação durante a execução (histórico) e seus relacionamentos.
O modelo diz que eventos em diferentes fluxos não são instantâneos e atômicos, mas em paralelo, e não é possível construir ordem entre eles. Eventos (gravação e leitura de dados compartilhados) em fluxos em uma arquitetura multiprocessador ou multinúcleo ocorrem realmente em paralelo. Não há conceito de tempo global no sistema, não podemos entender quando uma operação terminou e a outra começou.
Na prática, isso significa que podemos escrever um valor para uma variável em um segmento e fazê-lo, digamos de manhã, e ler o valor dessa variável em outro segmento à noite, e não podemos dizer que leremos o valor escrito de manhã com certeza. Em teoria, essas operações ocorrem paralelamente e não está claro quando uma terminará e outra operação começará.
É difícil imaginar como acontece que operações simples de leitura e gravação executadas em diferentes momentos do dia ocorrem simultaneamente. Mas se você pensar bem, realmente não nos importa quando os eventos de escrita e leitura ocorrem, se não podemos garantir que veremos o resultado da gravação.
E realmente não podemos ver o resultado da gravação, ou seja, em uma variável cujo valor é
0 no fluxo
P, escrevemos
1 e no fluxo
Q lemos essa variável. Não importa quanto tempo físico passe após a gravação, ainda podemos ler
0 .
É assim que os computadores funcionam e o modelo reflete isso.O modelo é completamente abstrato e precisa de visualização conveniente para um trabalho conveniente. Para visualização e somente para isso, é usado um modelo com tempo global, com reservas de que, para provar as propriedades dos programas, o tempo global não é usado. Na visualização, cada evento é representado como um intervalo com um começo e um fim.
Os eventos ocorrem em paralelo, como descobrimos. Mas, ainda assim, o sistema tem uma
ordem parcial , uma vez que existem pares especiais de eventos que têm uma ordem; nesse caso, eles dizem que esses eventos têm um relacionamento "aconteceu antes". Se você ouvir pela primeira vez sobre o relacionamento "aconteceu antes", provavelmente saber o fato de que esse tipo de organização organiza eventos não ajudará muito.
Tentando analisar um programa Java
Consideramos um mínimo teórico, vamos tentar seguir em frente e considerar um programa multithread em uma linguagem específica - Java, a partir de dois threads com um estado mutável comum.
Um exemplo clássico.
private static int x = 0, y = 0; private static int a = 0, b = 0; synchronized (this) { a = 0; b = 0; x = 0; y = 0; } Thread p = new Thread(() -> { a = 1; x = b; }); Thread q = new Thread(() -> { b = 1; y = a; }); p.start(); q.start(); p.join(); q.join(); System.out.println("x=" + x + ", y=" + y);
Precisamos simular a execução deste programa e obter todos os resultados possíveis - os valores das variáveis x e y. Haverá vários resultados, como lembramos da teoria, esse programa é não determinístico.
Como vamos modelar? Eu quero imediatamente usar o modelo de operações intercaladas. Mas o modelo "aconteceu antes" nos diz que os eventos em um encadeamento são paralelos aos eventos de outro encadeamento. Portanto, o modelo de operações alternadas aqui não é apropriado se não houver um relacionamento "aconteceu antes" entre as operações.
O resultado da execução de cada encadeamento é sempre determinado, uma vez que os eventos em um encadeamento são sempre ordenados, considere que eles recebem um relacionamento "aconteceu antes" gratuitamente. Mas como eventos em diferentes fluxos podem obter o relacionamento "aconteceu antes" não é totalmente óbvio. Obviamente, essa relação é formalizada no modelo, todo o modelo é escrito em linguagem matemática. Mas o que fazer com isso na prática, em um idioma específico, não é imediatamente entendido.
Quais são as opções?
Ignore restrições e simule intercalação. Você pode tentar, talvez nada de ruim aconteça.
Para entender que tipo de resultado pode ser obtido, simplesmente enumeramos todas as variantes possíveis de execução.
Todas as execuções possíveis de programas podem ser representadas como uma máquina de estados finitos.
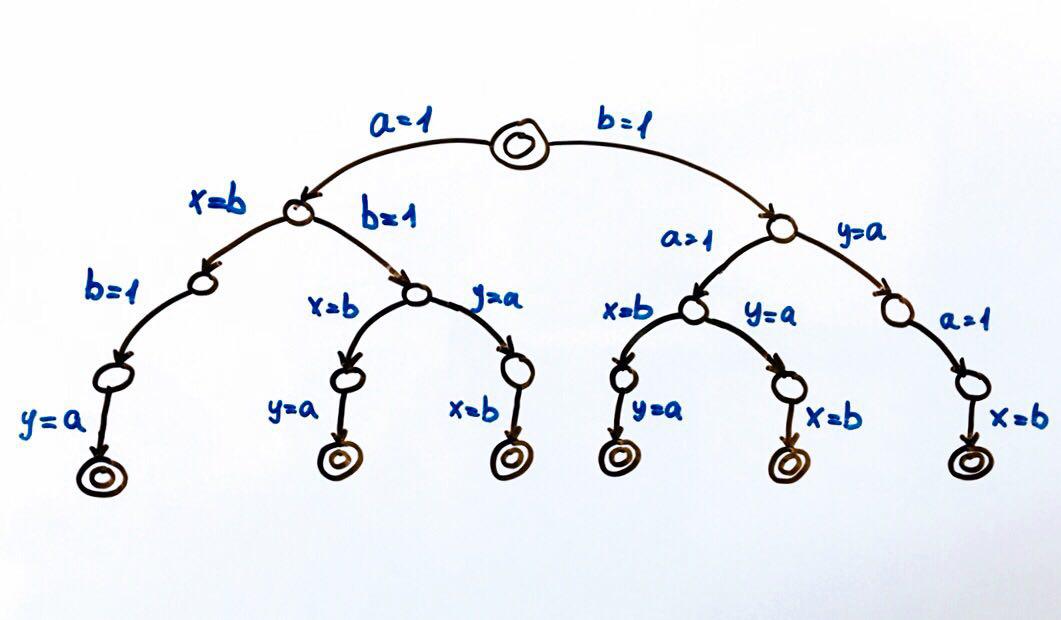
Cada círculo é um estado do sistema, no nosso caso as variáveis
a, b, x, y . Uma função de transição é uma ação em um estado que coloca o sistema em um novo estado. Como dois fluxos podem executar ações no estado geral, haverá duas transições de cada estado. Círculos duplos são os estados finais e iniciais do sistema.
No total, são possíveis 6 execuções diferentes, que resultam em pares de valores x, y:
(1, 1), (1, 0), (0, 1)
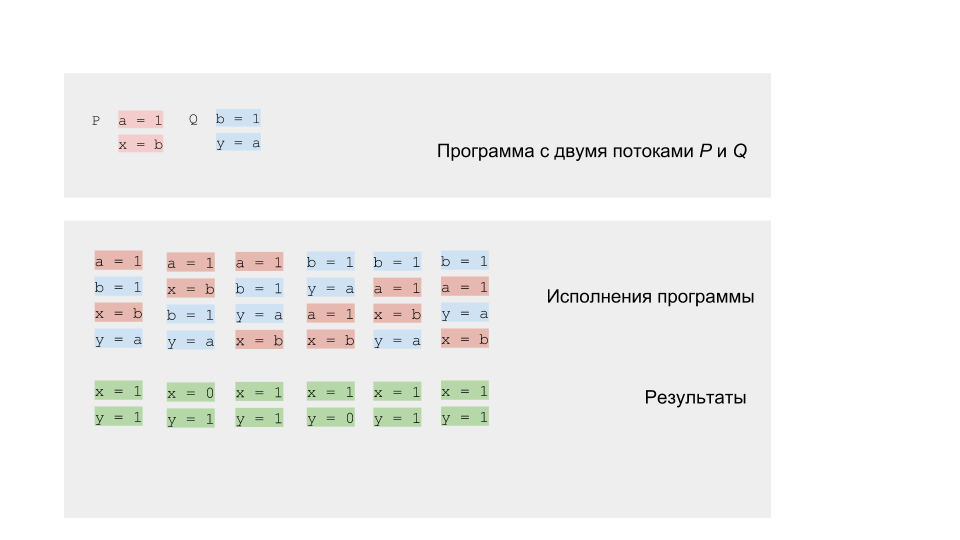
Podemos executar o programa e verificar os resultados. Como convém a um programa competitivo, ele terá um resultado não determinístico.
Para testar programas competitivos, é melhor usar ferramentas especiais (
ferramenta ,
relatório ).
Mas você pode tentar executar o programa vários milhões de vezes, ou melhor ainda, escrever um ciclo que fará isso por nós.
Se executarmos o código em uma arquitetura de núcleo único ou processador único, obteremos o resultado do conjunto que esperamos. O modelo de rotação funcionará bem. Na arquitetura multinúcleo, por exemplo, x86, podemos nos surpreender com o resultado - podemos obter o resultado (0,0), que não pode estar de acordo com a nossa modelagem.
A explicação para isso pode ser encontrada na Internet pela palavra-chave
reordenar . Agora é importante entender que a
modelagem intercalada não é realmente adequada em uma situação em que não podemos determinar a ordem de acesso ao estado compartilhado .
Teoria da Programação Competitiva e JMM
É hora de examinar mais de perto o relacionamento "aconteceu antes" e como ele faz amizade com a JMM. A definição original do relacionamento "aconteceu antes" pode ser encontrada em Horário, Relógios e Ordenação de eventos em um sistema distribuído.
O modelo de memória de linguagem ajuda a escrever um código competitivo, pois determina quais operações estão relacionadas ao “aconteceu antes”. Uma lista dessas operações é apresentada na
especificação na seção Acontece antes do pedido. De fato, esta seção responde à pergunta - sob quais condições veremos o resultado da gravação em outro fluxo.
Existem vários pedidos no JMM. Alexei Shipilev fala vigorosamente sobre as regras em um de seus
relatórios .
No modelo de tempo global, todas as operações no mesmo encadeamento estão em ordem. Por exemplo, os eventos de escrita e leitura de uma variável podem ser representados como dois intervalos; o modelo garante que esses intervalos nunca se cruzem na estrutura de um único fluxo. No JMM, esse pedido é chamado de Pedido de Programa (
PO ).
O PO vincula ações em um único encadeamento e não diz nada sobre a ordem de execução, apenas fala sobre a ordem no código-fonte. Isso é suficiente para garantir o
determinismo de cada fluxo separadamente .
O pedido pode ser considerado como dados brutos.
O PO é sempre fácil de organizar em um programa - todas as operações (ordem linear) no código-fonte em um único fluxo terão
PO .
No nosso exemplo, temos algo como o seguinte:
P: a = 1 PO x = b - escrevendo para a e lendo b tem ordem de PO
Q: b = 1 PO y = a - escreva em be leia a com a ordem dos PO
Eu espiei essa forma de escrever
w (a, 1) PO r (b): 0. Espero realmente que ninguém a tenha patenteado para relatórios. No entanto, a especificação tem uma forma semelhante.
Mas cada thread individualmente não é particularmente interessante para nós, uma vez que os threads têm um estado comum, estamos mais interessados na interação dos fluxos. Tudo o que queremos é ter certeza de que veremos um registro de variáveis em outros threads.
Deixe-me lembrá-lo de que isso não deu certo para nós, porque as operações de escrever e ler variáveis em diferentes fluxos não são instantâneas (são segmentos que se cruzam), respectivamente, é impossível analisar onde estão o início e o fim das operações.
A idéia é simples - no momento em que lemos a variável a no fluxo
Q , o registro dessa mesma variável no fluxo
P pode não terminar ainda. E não importa quanto tempo físico esses eventos compartilhem - um nanossegundo ou algumas horas.
Para solicitar eventos, precisamos do relacionamento "aconteceu antes". O JMM define esse relacionamento. A especificação corrige o pedido em um thread:
Se a operação xey estiver no mesmo encadeamento e no PO x ocorrer primeiro, e depois y, x ocorreu antes de y.
Olhando para o futuro, podemos dizer que podemos substituir todos os
pedidos por Happens-before (
HB ):
P: w(a, 1) HB r(b) Q: w(b, 1) HB r(a)
Mas, novamente, retornamos na estrutura de um fluxo.
O HB é possível entre operações que ocorrem em threads diferentes. Para lidar com esses casos, conheceremos outros pedidos.
Ordem de Sincronização (
SO ) - vincula Ações de Sincronização (
SA ), uma lista completa de
SA é fornecida na especificação, na seção 17.4.2. Acções Aqui estão alguns deles:
- Leitura de variável volátil
- Escrevendo variável volátil
- Bloqueio do monitor
- Desbloquear monitor
O SO é interessante para nós, porque possui a propriedade de que todas as leituras na ordem do
SO veem as últimas entradas no
SO . E eu lembro que estamos apenas conseguindo isso.
Neste local, repetirei o que estamos buscando. Temos um programa multithread, queremos simular todas as execuções possíveis e obter todos os resultados que ela pode fornecer. Existem modelos que permitem que isso seja feito de maneira simples. Mas eles exigem que todas as ações no estado compartilhado sejam ordenadas.
De acordo com a propriedade
SO - se todas as ações do programa forem
SA , alcançaremos nosso objetivo. I.e. podemos definir
modificador volátil para todas as variáveis e podemos usar o modelo de alternância. Se a intuição diz que isso não vale a pena, então você está absolutamente certo. Com essas ações, simplesmente proibimos otimizações sobre o código, é claro, às vezes essa é uma boa opção, mas esse definitivamente não é um caso geral.
Considere outra ordem de sincronização com (
SW ) - SO para pares voláteis específicos de desbloqueio / bloqueio, gravação / leitura. Não importa em que fluxo essas ações estarão, o principal é que elas estejam no mesmo monitor, variável volátil.
O SW fornece uma ponte entre os threads.
E agora chegamos à ordem mais interessante - acontece antes (
HB ).
HB é um fechamento transitivo da união de
SW e
PO .
O PO fornece uma ordem linear dentro do fluxo e o
SW fornece uma ponte entre os fluxos.
HB é transitivo, isto
é , se
x HB y y HB z, x HB z
A especificação possui uma lista de relacionamentos da
HB , você pode se familiarizar com ela com mais detalhes, aqui estão algumas da lista:
Dentro de um único encadeamento, qualquer operação acontece antes de qualquer operação seguinte no código-fonte.
A saída de um bloco / método sincronizado acontece antes de inserir um bloco / método sincronizado no mesmo monitor.
Escrever um campo
volátil acontece antes de ler o mesmo campo
volátil .
Vamos voltar ao nosso exemplo:
P: a = 1 PO x = b Q: b = 1 PO y = a
Vamos voltar ao nosso exemplo e tentar analisar o programa, levando em consideração os pedidos.
A análise do programa usando o JMM baseia-se em apresentar hipóteses e em confirmá-las ou refutá-las.
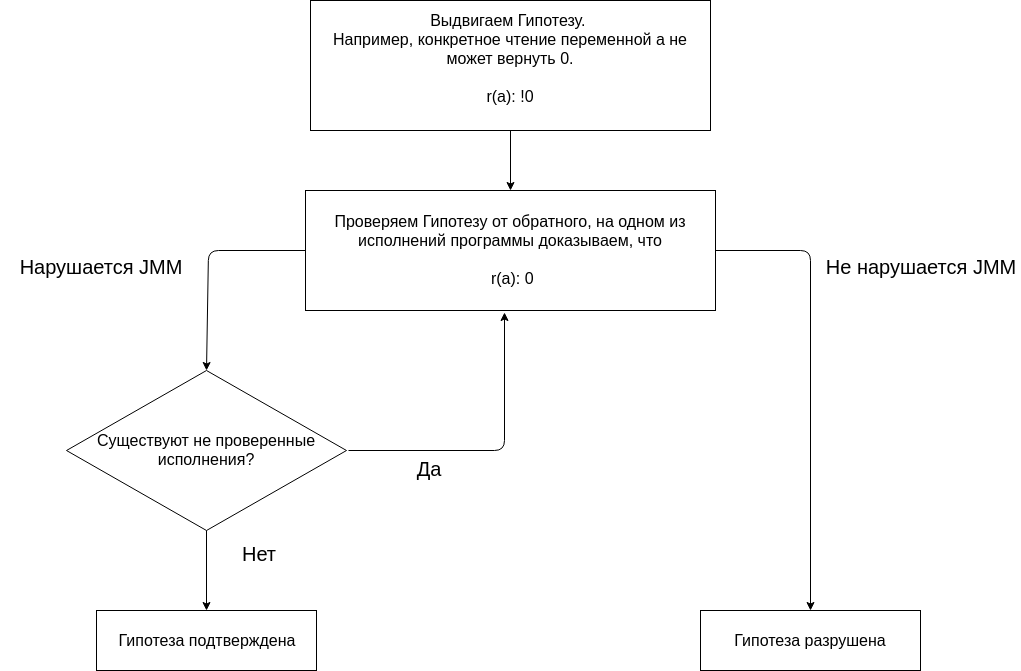
Começamos nossa análise com a hipótese de que nem uma única execução do programa fornece o resultado (0, 0). A ausência de um resultado (0, 0) em todas as execuções é uma propriedade suposta do programa.
Testamos a hipótese construindo diferentes execuções.
Vi a nomenclatura
aqui (às vezes aparece em vez de
… palavra
race com uma flecha, o próprio Alexey usa a seta e a palavra corrida em seus relatórios, mas avisa que essa ordem não existe no JMM e usa essa notação para maior clareza).
Fazemos uma pequena reserva.
Como todas as ações em variáveis comuns são importantes para nós, e no exemplo, as variáveis comuns são
a, b, x, y . Então, por exemplo, a operação x = b deve ser considerada como r (b) ew (x, b) e
r(b) HB w(x,b) (com base no
PO ). Mas como a variável x não é lida em nenhum lugar dos threads (a leitura impressa no final do código não é interessante, porque após a operação de junção no thread veremos o valor x), não podemos considerar a ação w (x, b).
Verifique a primeira apresentação.
w(a, 1) HB r(b): 0 … w(b, 1) HB r(a): 0
No fluxo
Q, lemos a variável a, escrevemos para essa variável no fluxo
P. Não há ordem entre escrever e ler
(PO, SW, HB) .
Se a variável for escrita em um segmento e a leitura estiver em outro segmento e não houver relação
HB entre operações, eles dizem que a variável é lida sob corrida. E, de acordo com a JMM, podemos ler o último valor registrado em
HB ou qualquer outro valor.
Tal desempenho é possível. A execução
não viola o JMM . Ao ler a variável a, você pode ver qualquer valor, pois a leitura ocorre sob a corrida e não há garantia de que veremos a ação w (a, 1). Isso não significa que o programa funcione corretamente, simplesmente significa que esse resultado é esperado.
Não faz sentido considerar o restante da execução, pois a
hipótese já está destruída .
O JMM diz que, se o programa não tiver corridas de dados, todas as execuções poderão ser consideradas como seqüenciais. Vamos nos livrar da corrida, para isso precisamos otimizar as operações de leitura e gravação em diferentes threads. É importante entender que um programa multithread, ao contrário de um seqüencial, possui várias execuções. E para dizer que um programa tem alguma propriedade, é necessário provar que o programa tem essa propriedade não em uma das execuções, mas em todas as execuções.
Para provar que o programa não é de corrida, você precisa fazer isso em todas as apresentações. Vamos tentar criar
SA e marcar a variável a com um
modificador volátil . Variáveis
voláteis serão prefixadas com v.
Propomos
uma nova hipótese . Se a variável a for tornada
volátil , nenhuma execução do programa fornecerá o resultado (0, 0).
w(va, 1) HB r(b): 0 … w(b, 1) HB r(va): 0
A execução
não viola o JMM . Ler va acontece sob a corrida. Qualquer raça destrói a transitividade da HB.
Apresentamos
outra hipótese . Se a variável b for tornada
volátil , nenhuma execução do programa fornecerá o resultado (0, 0).
w(a, 1) HB r(vb): 0 … w(vb, 1) HB r(a): 0
A execução não viola o JMM. A leitura de um ocorre sob a corrida.
Vamos
testar a hipótese de que, se as variáveis a e b são
voláteis , nenhuma execução do programa fornecerá o resultado (0, 0).
Verifique a primeira apresentação.
w(va, 1) SO r(vb): 0 SO w(vb, 1) SO r(va): 0
Como todas as ações no programa
SA (especificamente lendo ou gravando uma variável
volátil ), obtemos a ordem
SO completa entre todas as ações. Isso significa que r (va) deve ver w (va, 1). Esta
execução viola o JMM .
É necessário prosseguir para a próxima execução para confirmar a hipótese. Mas como haverá
SO para qualquer execução, você pode se desviar do formalismo - é óbvio que o resultado (0, 0) viola o JMM para qualquer execução.
Para usar o modelo de rotação, você precisa adicionar
voláteis para as variáveis a e b. Esse programa fornecerá os resultados (1,1), (1,0) ou (0,1).
No final, podemos dizer que programas muito simples são bastante simples de analisar.
Porém, programas complexos com um grande número de execuções e dados compartilhados são difíceis de analisar, pois você precisa verificar todas as execuções.
Outros modelos de execução competitivos
Por que considerar outros modelos de programação competitivos?
O uso de threads e primitivas de sincronização pode resolver todos os problemas. Tudo isso é verdade, mas o problema é que examinamos um exemplo de uma dúzia de linhas de código, em que quatro linhas de código funcionam de maneira útil.
E lá encontramos várias perguntas, até o ponto em que, sem a especificação, não conseguimos calcular corretamente todos os resultados possíveis. Threads e primitivas de sincronização são uma coisa muito difícil, cuja utilização é certamente justificada em alguns casos. Basicamente, esses casos estão relacionados ao desempenho.
Desculpe, me refiro muito a Elizarov, mas o que posso fazer se uma pessoa realmente tiver experiência nesse campo. Então, ele tem outro
relatório maravilhoso
, "Milhões de citações por segundo em Java puro", no qual ele diz que um estado imutável é bom, mas não copiarei meus milhões de citações para cada fluxo, desculpe. Mas nem todos têm milhões de citações; muitos, obviamente, têm tarefas mais modestas. Existem modelos de programação competitivos que permitem esquecer o JMM e ainda escrever códigos competitivos e seguros?
Se você está realmente interessado nesta questão, recomendo vivamente o livro de Paul Butcher, “Sete modelos de competição em sete semanas. Nós revelamos os segredos dos fluxos. ” Infelizmente, não foi possível encontrar informações suficientes sobre o autor, mas o livro deve abrir seus olhos para novos paradigmas. Infelizmente, não tenho experiência com muitos outros modelos de competição, por isso recebi a resenha deste livro.
Respondendo à pergunta acima. Tanto quanto eu entendo, existem modelos de programação competitivos que podem pelo menos reduzir bastante a necessidade de conhecimento das nuances do JMM. No entanto, se houver um estado e fluxos mutáveis, não estrague nenhuma abstração sobre eles, ainda haverá um local em que esses fluxos devem sincronizar o acesso ao estado. Outra pergunta é que você provavelmente não precisa sincronizar o acesso, por exemplo, uma estrutura pode responder por isso. Mas, como dissemos, mais cedo ou mais tarde, a abstração pode ocorrer.
Você pode excluir o estado mutável. No mundo da programação funcional, essa é uma prática normal. Se não houver estruturas mutáveis, provavelmente não haverá problemas com a memória compartilhada por definição. Existem representantes de linguagens funcionais na JVM, como Clojure. O Clojure é uma linguagem funcional híbrida, porque ainda permite alterar as estruturas de dados, mas fornece ferramentas mais eficientes e seguras para isso.
Linguagens funcionais são uma ótima ferramenta para trabalhar com código competitivo. Pessoalmente, eu não o uso, porque minha área de atividade é o desenvolvimento móvel e simplesmente não é popular. Embora certas abordagens possam ser adotadas.
Outra maneira de trabalhar com dados mutáveis é impedir o compartilhamento de dados. Os atores são um modelo de programação. Os atores simplificam a programação, não permitindo o acesso simultâneo aos dados. Isso é alcançado pelo fato de que uma função que executa trabalho em um momento no tempo pode funcionar em apenas um encadeamento.
No entanto, um ator pode alterar o estado interno. Dado que, no momento seguinte, o mesmo ator pode ser executado em outro encadeamento, isso pode ser um problema. O problema pode ser resolvido de diferentes maneiras, em linguagens de programação como Erlang ou Elixir, onde o modelo de ator é parte integrante da linguagem, você pode usar a recursão para chamar um ator com um novo estado.
Em Java, as recursões podem ser muito caras. No entanto, em Java, existem estruturas para um trabalho conveniente com este modelo, provavelmente o mais popular é o Akka. Os desenvolvedores da Akka cuidaram de tudo, você pode ir para a seção de documentação da
Akka e do Java Memory Model e ler sobre dois casos em que o acesso a um estado compartilhado pode ocorrer a partir de threads diferentes. Mais importante, porém, a documentação diz a quais eventos se relacionam "aconteceram antes". I.e. isso significa que podemos alterar o estado do ator o quanto quisermos, mas quando recebermos a próxima mensagem e possivelmente a processarmos em outro segmento, temos a garantia de ver todas as alterações feitas em outro segmento.
Por que o modelo de rosqueamento é tão popular?
Examinamos dois modelos de programação competitiva; na verdade, existem ainda mais deles que tornam a programação competitiva mais fácil e segura.
Mas por que então os fios e bloqueios ainda são tão populares?
Parece-me que o motivo é a simplicidade da abordagem, é claro, por um lado, é fácil cometer muitos erros não óbvios com fluxos, dar um tiro no pé etc. Mas, por outro lado
, não há nada complicado nos fluxos, especialmente se você não pensa nas consequências .
Em um determinado momento, o kernel pode executar uma instrução (na verdade não, a concorrência existe no nível da instrução, mas agora não importa), mas devido à multitarefa, mesmo em máquinas de núcleo único, vários programas podem ser executados simultaneamente (é claro, pseudo simultaneamente).
Para que a multitarefa funcione, você precisa de concorrência. Como já descobrimos, a concorrência é impossível sem vários fluxos de gerenciamento.
Quantas threads você acha que um programa que roda em um processador de celular com quatro núcleos precisa ser o mais rápido e responsivo possível?
Pode haver várias dezenas. Agora, a pergunta é: por que precisamos de tantos threads para um programa que roda em hardware que permite executar apenas 2-4 threads por vez?
Para tentar responder a essa pergunta, suponha que apenas nosso programa esteja sendo executado no dispositivo e nada mais. Como gerenciaríamos os recursos fornecidos a nós?
Você pode fornecer um núcleo para a interface do usuário, o restante do kernel para quaisquer outras tarefas.
Se um dos threads estiver bloqueado, por exemplo, o thread pode ir para o controlador de memória e aguardar uma resposta; então, obteremos um kernel bloqueado.Quais tecnologias existem para resolver o problema?Existem threads em Java, podemos criar muitos threads e outros threads poderão executar operações enquanto algum segmento estiver bloqueado. Com uma ferramenta como threads, podemos simplificar nossas vidas.A abordagem com threads não é livre, a criação de threads geralmente leva tempo (é decidido por conjuntos de threads), a memória é alocada para eles, alternar entre threads é uma operação cara. Mas é relativamente fácil programar com eles, portanto essa é uma tecnologia massiva que é tão amplamente usada em linguagens gerais, como Java.Java geralmente adora fluxos, não é necessário criar para cada ação um fluxo; existem coisas de nível superior, como Executors, que permitem trabalhar com pools e escrever códigos mais escaláveis e flexíveis. Os fluxos são realmente convenientes, você pode fazer uma solicitação de bloqueio para a rede e gravar o processamento de resultados na próxima linha. Mesmo se esperarmos o resultado por vários segundos, ainda podemos executar outras tarefas, pois o sistema operacional cuidará da distribuição do tempo do processador entre os threads.Os fluxos são populares não apenas no desenvolvimento de back-end; no desenvolvimento móvel, é considerado normal criar dezenas de fluxos para que você possa bloquear um fluxo por alguns segundos, aguardando o download dos dados pela rede ou do soquete.Idiomas como Erlang ou Clojure ainda são de nicho e, portanto, os modelos de programação competitivos que eles usam não são tão populares. No entanto, as previsões para eles são as mais otimistas.Conclusões
Se você estiver desenvolvendo na plataforma JVM, precisará aceitar as regras do jogo indicado pela plataforma. Essa é a única maneira de escrever código multithread normal. É muito desejável entender o contexto de tudo o que acontece, para que seja mais fácil aceitar as regras do jogo. É ainda melhor olhar em volta e se familiarizar com outros paradigmas, embora você não possa chegar a lugar algum do submarino, mas pode descobrir novas abordagens e ferramentas.Materiais adicionais
Tentei colocar no texto do artigo links para fontes das quais obtive informações.Em geral, o material JMM é fácil de encontrar na Internet. Aqui vou postar links para algum material adicional associado ao JMM e que pode não chamar minha atenção imediatamente.Leitura- Alexey Shipilev's blog - Eu sei o que é óbvio, mas é apenas um pecado para não mencionar
- Blog de Cheremin Ruslan - ele não escreveu ativamente recentemente, é preciso procurar as entradas antigas no blog, acredite em mim, vale a pena - existe uma fonte
- Habr Gleb Smirnov - existem excelentes artigos sobre multithreading e o modelo de memória
- O blog de Roman Elizarov é abandonado, mas escavações arqueológicas precisam ser realizadas. Em geral, Roman fez muito para educar as pessoas na teoria da programação multithread, procurá-la na mídia.
PodcastsProblemas que achei particularmente interessantes. Eles não são sobre JMM, são sobre o Inferno, o que está acontecendo na glândula. Mas depois de ouvi-los, quero beijar os criadores do JMM, que nos protegeram disso tudo.VídeoAlém dos discursos das pessoas acima mencionadas, preste atenção ao vídeo acadêmico.