Este artigo é uma tradução autorizada da postagem original . A tradução foi feita com a ajuda gentil dos caras do PVS-Studio. Obrigado pessoal!O que me incentivou a escrever este artigo é uma quantidade significativa de materiais sobre análise estática, que vem surgindo cada vez mais. Primeiro, este é um
blog do PVS-Studio , que se promove ativamente no Habr postando análises de erros, encontradas por sua ferramenta em projetos de código aberto. O PVS-Studio implementou recentemente o
suporte a Java e, é claro, os desenvolvedores do IntelliJ IDEA, cujo analisador embutido é provavelmente o mais avançado para Java atualmente,
não puderam ficar de fora .
Ao ler essas resenhas, sinto que estamos falando de um elixir mágico: clique no botão e aqui está - a lista de defeitos bem na frente dos seus olhos. Parece que, à medida que os analisadores se tornam mais avançados, mais e mais bugs serão encontrados e os produtos verificados por esses robôs se tornarão cada vez melhores sem nenhum esforço de nossa parte.
Bem, mas não há elixires mágicos. Eu gostaria de falar sobre o que geralmente não é falado em posts como "aqui estão as coisas que o nosso robô pode encontrar": o que os analisadores não conseguem fazer, qual é a verdadeira parte e o lugar deles no processo de entrega de software e como implementar a análise corretamente.
 Catraca (fonte: Wikipedia ).
Catraca (fonte: Wikipedia ).O que os analisadores estáticos nunca serão capazes de fazer
Qual é a análise do código fonte do ponto de vista prático? Pegamos os arquivos de origem e obtemos algumas informações sobre a qualidade do sistema em um curto espaço de tempo (muito mais curto que uma execução de testes). A limitação principal e matematicamente intransponível é que dessa forma podemos responder apenas a um subconjunto muito limitado de perguntas sobre o sistema analisado.
O exemplo mais famoso de uma tarefa, não solucionável usando a análise estática, é um
problema de parada : este é um teorema, que prova que não se pode elaborar um algoritmo geral, que definiria se um programa com um determinado código-fonte repetia para sempre ou era concluído. o tempo final. A extensão desse teorema é um
teorema de Rice , afirmando que, para qualquer propriedade não trivial de funções computáveis, a questão de determinar se um determinado programa calcula uma função com essa propriedade é uma tarefa algoritmicamente insolúvel. Por exemplo, você não pode escrever um analisador, que determina com base no código-fonte se o programa analisado é uma implementação de um algoritmo específico, por exemplo, um que calcula o quadrado de um número inteiro.
Assim, a funcionalidade dos analisadores estáticos tem limitações intransponíveis. O analisador estático nunca será capaz de detectar todos os casos de, por exemplo, erro "exceção de ponteiro nulo" em idiomas sem a
segurança nula . Ou detecte todas as ocorrências de "atributo não encontrado" em idiomas digitados dinamicamente. Tudo o que o analisador estático mais perfeito pode fazer é capturar casos específicos. O número deles entre todos os possíveis problemas com o seu código fonte, sem exageros, é uma gota no oceano.
A análise estática não é uma pesquisa de erros
Aqui está uma conclusão que se segue: a análise estática não é a maneira de diminuir o número de defeitos em um programa. Atrevo-me a reivindicar o seguinte: sendo aplicado pela primeira vez ao seu projeto, ele encontrará lugares "divertidos" no código, mas provavelmente não encontrará defeitos que afetem a qualidade do seu programa.
Exemplos de defeitos encontrados automaticamente pelos analisadores são impressionantes, mas não devemos esquecer que esses exemplos foram encontrados ao escanear um enorme conjunto de bases de código contra o conjunto de regras relativamente simples. Da mesma forma, os hackers, tendo a oportunidade de tentar várias senhas simples em um grande número de contas, acabam encontrando as contas com uma senha simples.
Isso significa que não é necessário aplicar a análise estática? Claro que não! Ele deve ser aplicado pelo mesmo motivo em que você pode querer verificar todas as novas senhas na lista de parada de senhas não seguras.
A análise estática é mais do que procurar bugs
De fato, as tarefas que podem ser resolvidas pela análise na prática são muito mais amplas. Porque, de um modo geral, a análise estática representa qualquer verificação do código fonte, realizada antes da execução. Aqui estão algumas coisas que você pode fazer:
- Uma verificação do estilo de codificação no sentido mais amplo desta palavra. Ele inclui uma verificação de formatação e uma pesquisa de uso de parênteses vazios / desnecessários, configuração de valores limite para métricas, como várias linhas / complexidade ciclomática de um método e assim por diante - tudo isso que complica a legibilidade e a manutenção do código. Em Java, o Checkstyle representa uma ferramenta com essa funcionalidade, em Python -
flake8 . Esses programas são geralmente chamados de "linters". - Não apenas o código executável pode ser analisado. Recursos como arquivos JSON, YAML, XML e
.properties podem (e devem!) Ser verificados automaticamente quanto à validade. O motivo disso é que é melhor descobrir que, digamos, a estrutura JSON está quebrada devido às cotações não emparelhadas no estágio inicial da verificação automática de uma solicitação pull do que durante a execução de testes ou em tempo de execução, não é isso? Existem algumas ferramentas relevantes, por exemplo, YAMLlint , JSONLint e xmllint . - A compilação (ou análise de linguagens de programação dinâmicas) também é um tipo de análise estática. Geralmente, os compiladores podem emitir avisos que sinalizam sobre problemas com a qualidade do código-fonte e não devem ser ignorados.
- Às vezes, a compilação é aplicada não apenas ao código executável. Por exemplo, se você possui documentação no formato AsciiDoctor , no processo de compilação em HTML / PDF, o AsciiDoctor ( plug-in Maven ) pode emitir avisos, por exemplo, em links internos quebrados. Esse é um motivo significativo para não aceitar uma solicitação de recebimento com alterações na documentação.
- A verificação ortográfica também é um tipo de análise estática. O utilitário aspell é capaz de verificar a ortografia não apenas na documentação, mas também no código-fonte dos programas (comentários e literais) em várias linguagens de programação, incluindo C / C ++, Java e Python. Erro de ortografia na interface do usuário ou na documentação também é um defeito!
- Na verdade, os testes de configuração representam uma forma de análise estática, pois eles não executam o código-fonte durante o processo de execução, mesmo que os testes de configuração sejam executados como testes de unidade
pytest .
Como podemos ver, a pesquisa de bugs tem o papel menos significativo nesta lista e tudo o mais está disponível ao usar ferramentas gratuitas de código aberto.
Qual desses tipos de análise estática deve ser usado no seu projeto? Claro, quanto mais, melhor! O importante aqui é uma implementação adequada, que será discutida mais adiante.
Um pipeline de entrega como filtro de vários estágios e análise estática como seu primeiro estágio
Um pipeline com um fluxo de alterações (começando das alterações do código-fonte até a entrega na produção) é uma metáfora clássica da integração contínua. A sequência padrão de estágios deste pipeline é a seguinte:
- análise estática
- compilação
- testes de unidade
- testes de integração
- Testes de interface do usuário
- verificação manual
As alterações rejeitadas no N-ésimo estágio do pipeline não são passadas no estágio N + 1.
Por que não e de outra forma? Na parte do pipeline, que lida com testes, os testadores reconhecem a bem conhecida pirâmide de teste:
 Pirâmide de teste. Fonte: o artigo de Martin Fowler.
Pirâmide de teste. Fonte: o artigo de Martin Fowler.No final desta pirâmide, existem testes mais fáceis de escrever, que são executados mais rapidamente e não tendem a produzir falsos positivos. Portanto, deve haver mais deles, eles devem cobrir a maior parte do código e devem ser executados primeiro. No topo da pirâmide, a situação é bastante oposta; portanto, o número de testes de integração e interface do usuário deve ser reduzido ao mínimo necessário. As pessoas nesta cadeia são os recursos mais caros, lentos e não confiáveis; portanto, elas estão localizadas no final e só funcionam se as etapas anteriores não detectaram nenhum defeito. Nas partes não relacionadas ao teste, o pipeline é construído com os mesmos princípios!
Eu gostaria de sugerir a analogia na forma de um sistema de vários estágios de filtragem de água. Água suja (alterações com defeitos) é fornecida na entrada e, como saída, precisamos obter água limpa, que não conterá todas as contaminações indesejadas.
 Filtro de vários estágios. Fonte: Wikimedia Commons
Filtro de vários estágios. Fonte: Wikimedia CommonsComo você deve saber, os filtros de purificação são projetados para que cada estágio subsequente possa remover partículas contaminantes de tamanho menor. Os estágios de entrada da purificação aproximada têm maior rendimento e menor custo. Em nossa analogia, isso significa que os portões de qualidade de entrada têm maior desempenho, exigem menos esforço para iniciar e têm menos custos operacionais. O papel da análise estática, que (como agora entendemos) é capaz de eliminar apenas os defeitos mais sérios, é o papel do filtro do depósito como o primeiro estágio dos purificadores de vários estágios.
A análise estática não melhora a qualidade do produto final por si só, o mesmo que o "poço" não torna a água potável. No entanto, em conjunto com outros elementos do pipeline, sua importância é óbvia. Mesmo que em um filtro de vários estágios, os estágios de saída possam remover potencialmente tudo o que os de entrada podem - estamos cientes das consequências que se seguirão ao tentar sobreviver apenas com estágios de purificação fina, sem estágios de entrada.
O objetivo do "poço" é descarregar as etapas subsequentes da captura de defeitos muito graves. Por exemplo, uma pessoa que executa uma revisão de código não deve se distrair com a violação incorreta de código e de código de código formatado incorretamente (como parênteses redundantes ou ramificação aninhada muito profundamente). Erros como o NPE devem ser detectados pelos testes de unidade, mas, se antes disso, o analisador indicar que um erro deve aparecer inevitavelmente - isso acelerará significativamente sua correção.
Suponho que agora esteja claro por que a análise estática não melhora a qualidade do produto quando aplicada ocasionalmente e deve ser aplicada continuamente para filtrar alterações com defeitos graves. A questão de saber se a aplicação de um analisador estático melhora a qualidade do seu produto equivale aproximadamente à pergunta "se tirarmos água de lagoas sujas, sua qualidade de bebida será melhorada quando passarmos por uma peneira?"
Introdução em um projeto herdado
Uma questão prática importante: como implementar a análise estática no processo de integração contínua, como uma "porta da qualidade"? No caso de testes automatizados, tudo fica claro: há um conjunto de testes, uma falha em qualquer um deles é uma razão suficiente para acreditar que uma construção não passou por um portão de qualidade. Uma tentativa de configurar o portão da mesma maneira pelos resultados da análise estática falha: há muitos avisos de análise no código legado, você não deseja ignorá-los todos; por outro lado, é impossível interromper a entrega do produto apenas porque existem avisos do analisador.
Para qualquer projeto, o analisador emite um grande número de avisos sendo aplicados pela primeira vez. A maioria dos avisos não tem nada a ver com o bom funcionamento do produto. Será impossível consertar todos eles e muitos deles não precisam ser consertados. No final, sabemos que nosso produto realmente funciona mesmo antes da introdução da análise estática!
Como resultado, muitos desenvolvedores se limitam ao uso ocasional de análise estática ou apenas no modo informativo, que envolve a obtenção de um relatório do analisador ao criar um projeto. Isso é equivalente à ausência de qualquer análise, porque, se já temos muitos avisos, o surgimento de outro (por mais grave) permanece despercebido ao alterar o código.
Aqui estão as formas conhecidas de introdução dos portões de qualidade:
- Definir o limite do número total de avisos ou do número de avisos, dividido pelo número de linhas de código. Funciona mal, pois essa porta permite alterações com novos defeitos até que seu limite seja excedido.
- A marcação de todos os avisos antigos no código é ignorada em um determinado momento e cria falhas quando novos avisos aparecem. Essa funcionalidade pode ser fornecida pelo PVS-Studio e algumas outras ferramentas, por exemplo, Codacy. Não trabalhei com o PVS-Studio. Quanto à minha experiência com o Codacy, o principal problema deles é que a distinção entre um erro antigo e um novo é um algoritmo complicado e nem sempre funciona, principalmente se os arquivos mudam significativamente ou são renomeados. Que eu saiba, o Codacy pode ignorar novos avisos em uma solicitação de recebimento e, ao mesmo tempo, impedir uma solicitação de recebimento devido a avisos, não relacionados a alterações no código deste PR.
- Na minha opinião, a solução mais eficaz é o método de "catraca" descrito no livro " Entrega contínua ". A idéia básica é que o número de avisos de análise estática seja uma propriedade de cada release e somente essas alterações sejam permitidas, o que não aumenta o número total de avisos.
Catraca
Funciona da seguinte maneira:
- Na fase inicial, uma entrada sobre vários avisos encontrados pelos analisadores de código é adicionada aos metadados do release. Portanto, ao criar a ramificação principal, não apenas a "release 7.0.2" é gravada em seu gerenciador de repositório, mas a "release 7.0.2, contendo 100500 Checkstyle-warnings". Se você estiver usando o gerenciador de repositórios avançado (como o Artifactory), é fácil manter esses metadados sobre o seu lançamento.
- Ao criar, cada solicitação pull compara o número de avisos resultantes com seu número em uma liberação atual. Se um PR levar a um crescimento desse número, o código não passará pela qualidade da análise estática. Se o número de avisos for reduzido ou não for alterado - ele será aprovado.
- Durante a próxima versão, o número recalculado será gravado nos metadados novamente.
Assim, lenta mas seguramente, o número de avisos estará convergindo para zero. Obviamente, o sistema pode ser enganado introduzindo um novo aviso e corrigindo o de outra pessoa. Isso é normal, porque, a longo prazo, dá o resultado: os avisos são corrigidos, geralmente não um por um, mas por grupos de um determinado tipo, e todos os avisos facilmente resolvidos são resolvidos rapidamente.
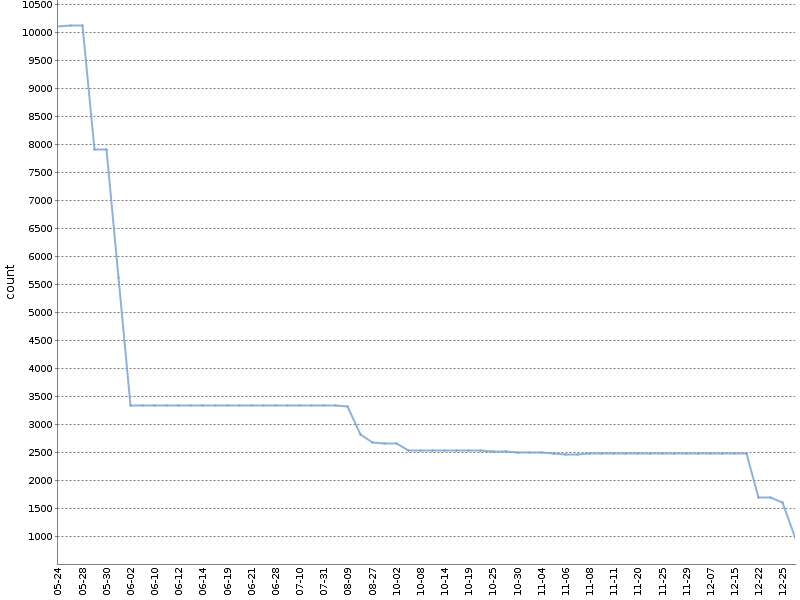
Este gráfico mostra o número total de avisos do Checkstyle por seis meses dessa "catraca" em
um dos nossos projetos OpenSource . O número de avisos foi reduzido significativamente e ocorreu naturalmente, paralelamente ao desenvolvimento do produto!
Eu aplico a versão modificada deste método. Eu conto os avisos separadamente para diferentes módulos de projeto e ferramentas de análise. O arquivo YAML com metadados sobre a construção, formado ao fazê-lo, tem a seguinte aparência:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
Em qualquer sistema avançado de CI, uma "catraca" pode ser implementada para qualquer ferramenta de análise estática, sem depender de plug-ins e ferramentas de terceiros. Cada um dos analisadores emite seu relatório em um formato simples de texto ou XML, que será analisado facilmente. A única coisa a fazer depois é escrever a lógica necessária em um script de IC. Você pode espiar e ver
aqui ou
aqui como ele é implementado em nossos projetos de origem baseados em Jenkins e Artifactory. Ambos os exemplos dependem da biblioteca
ratchetlib : o método
countWarnings() da maneira usual conta as tags xml nos arquivos gerados pelo Checkstyle e Spotbugs, e
compareWarningMaps() implementa essa própria catraca,
compareWarningMaps() um erro no caso, se o número de avisos em qualquer um dos as categorias estão aumentando.
Uma maneira interessante de implementação de "catraca" é possível para analisar a ortografia dos comentários, literais de texto e documentação usando o aspell. Como você deve saber, ao verificar a ortografia, nem todas as palavras desconhecidas no dicionário padrão estão incorretas, elas podem ser adicionadas ao dicionário personalizado. Se você tornar um dicionário personalizado parte do projeto de código-fonte, a porta de qualidade para ortografia poderá ser formulada da seguinte maneira: executar o aspell com o dicionário padrão e personalizado
não deve encontrar nenhum erro de ortografia.
A importância de corrigir a versão do analisador
Em conclusão, é necessário observar o seguinte: qualquer maneira que você escolher para introduzir a análise em seu pipeline de entrega, a versão do analisador deve ser corrigida. Se você deixar o analisador se atualizar espontaneamente, ao criar outra solicitação de recebimento, poderão surgir novos defeitos, que não estão relacionados ao código alterado, mas ao fato de que o novo analisador é capaz de detectar mais defeitos. Isso interromperá seu processo de verificação de solicitação de recebimento. A atualização do analisador deve ser uma ação consciente. De qualquer forma, a fixação rígida da versão de cada componente de construção é um requisito geral e um assunto para outro tópico.
Conclusões
- A análise estática não encontrará bugs e não melhorará a qualidade do seu produto como resultado de uma única execução. Somente sua execução contínua no processo de entrega produzirá um efeito positivo.
- A caça a insetos não é o principal objetivo da análise. A grande maioria dos recursos úteis está disponível nas ferramentas de código-fonte aberto.
- Introduzir portas de qualidade pelos resultados da análise estática no primeiro estágio do pipeline de entrega, usando o "catraca" para o código legado.
Referências
- Entrega contínua
- Alexey Kudryavtsev: Análise do programa: você é um bom desenvolvedor? Relate sobre diferentes métodos de análise de código, não apenas estático!
Trechos da discussão do artigo original
Evgeniy RyzhkovIvan, obrigado pelo artigo e por nos ajudar a fazer nosso trabalho, que é popularizar a tecnologia da análise de código estático. Você está absolutamente certo de que os artigos do blog PVS-Studio, no caso de mentes imaturas, podem afetá-los e levar a conclusões como "Vou verificar o código apenas uma vez, corrigir os erros e isso funcionará". Essa é a minha dor pessoal, que não sei superar há já vários anos. O fato é que os artigos sobre o projeto verificam:
- Causar efeito uau nas pessoas. As pessoas gostam de ler como os desenvolvedores de empresas como Google, Epic Games, Microsoft e outras empresas às vezes falham. As pessoas gostam de pensar que alguém pode estar errado, até os líderes da indústria cometem erros. As pessoas gostam de ler esses artigos.
- Além disso, os autores podem escrever artigos sobre o fluxo, sem ter que pensar muito. Claro, não quero ofender nossos colegas que escrevem esses artigos. Mas chegar a cada momento com um novo artigo é muito mais difícil do que escrever um artigo sobre uma verificação do projeto (uma dúzia de bugs, algumas piadas, misture com fotos de unicórnios).
Você escreveu um artigo muito bom. Eu também tenho alguns artigos sobre esse tópico. Então, tenha outros colegas. Além disso, visito várias empresas com um relatório sobre o tema "Filosofia da análise estática de código", no qual falo sobre o processo em si, mas não sobre erros específicos.
Mas não é possível escrever 10 artigos sobre o processo. Bem, para promover nosso produto, precisamos escrever muito regularmente. Gostaria de comentar mais alguns pontos do artigo com um comentário separado para facilitar a discussão.
Este pequeno
artigo é sobre “Filosofia da análise de código estático”, que é o meu tópico ao visitar diferentes empresas.
Ivan PonomarevEvgeniy, muito obrigado pela revisão informativa sobre o artigo! Sim, você recebeu minha preocupação no post sobre o impacto nas "mentes imaturas" absolutamente corretamente!
Não há ninguém para culpar aqui, pois os autores dos artigos / relatórios sobre
analisadores não pretendem fazer artigos / relatórios sobre a
análise . Mas, depois de algumas postagens recentes de
Andrey2008 e
lany , decidi que não poderia mais ficar em silêncio.
Evgeniy RyzhkovIvan, como escrevi acima, comentarei três pontos do artigo. Significa que eu concordo com os que não comento.
1.
A sequência padrão de estágios deste pipeline é a seguinte ...Não concordo que o primeiro passo seja a análise estática e apenas o segundo é a compilação. Acredito que, em média, a verificação de compilação é mais rápida e lógica do que uma execução imediata de análise estática "mais pesada". Podemos discutir se você pensa o contrário.
2.
Não trabalhei com o PVS-Studio. Quanto à minha experiência com o Codacy, o principal problema deles é que a distinção entre um erro antigo e um novo é um algoritmo complicado e nem sempre funciona, principalmente se os arquivos mudam significativamente ou são renomeados.No PVS-Studio, isso é extremamente útil. Esse é um dos principais recursos do produto, que, infelizmente, é difícil de ser descrito nos artigos, por isso as pessoas não estão muito familiarizadas com ele. Reunimos informações sobre os erros existentes em uma base. E não apenas “o nome do arquivo e a linha”, mas também informações adicionais (marca de hash de três linhas - atual, anterior, seguinte), para que, em caso de alteração do fragmento de código, ainda possamos encontrá-lo. Portanto, ao fazer pequenas modificações, ainda entendemos que é um erro antigo. E o analisador não se queixa. Agora, alguém pode dizer: "Bem, e se o código mudou muito, então isso não funcionou, e você reclama disso como se fosse o recém-escrito?" Sim Nós reclamamos. Mas, na verdade, esse é um novo código. Se o código mudou muito, agora é um novo código, e não o antigo.
Graças a esse recurso, participamos pessoalmente da implementação do projeto com 10 milhões de linhas de código C ++, que são todos os dias "tocadas" por vários desenvolvedores. Tudo correu sem problemas. Portanto, recomendamos o uso desse recurso do PVS-Studio para qualquer pessoa que introduz a análise estática em seu processo. A opção de corrigir o número de avisos de acordo com um release parece ser menos agradável para mim.
3.
Qualquer que seja a maneira que você opte por introduzir sua análise de entrega, a versão do analisador deve ser corrigidaEu não posso concordar com isso. Um adversário definitivo de tal abordagem. Eu recomendo atualizar o analisador no modo automático. À medida que adicionamos novos diagnósticos e aprimoramos os antigos. Porque Primeiro, você receberá avisos de novos erros reais. Em segundo lugar, alguns falsos positivos antigos podem desaparecer se os superarmos.
Não atualizar o analisador é o mesmo que não atualizar bancos de dados de antivírus ("e se eles começarem a notificar sobre vírus"). Não discutiremos aqui a verdadeira utilidade do software antivírus como um todo.
Se após a atualização da versão do analisador você tiver muitos novos avisos, suprima-os, como escrevi acima, por meio dessa função. Mas não para atualizar a versão ... Como regra, esses clientes (com certeza existem alguns) não atualizam a versão do analisador há anos. Não há tempo para isso. PAGAM pela renovação da licença, mas não usam as novas versões. Porque Porque uma vez eles decidiram fixar uma versão. O produto hoje e nos três anos atrás é noite e dia. Acontece que "eu comprarei o ingresso, mas não chegará".
Ivan Ponomarev1. Aqui você está certo. Estou pronto para concordar com um compilador / analisador no início e isso deve ser alterado no artigo! Por exemplo, os notórios
spotbugs não conseguem agir de maneira diferente, pois analisam o
spotbugs compilado. Há casos exóticos, por exemplo, no pipeline de manuais Ansible, é melhor definir a análise estática antes da análise, porque é mais leve lá. Mas este é o exótico em si)
2.
A opção de corrigir o número de avisos de acordo com um release parece ser menos agradável para mim ... - bem, sim, é menos agradável, menos técnico, mas muito prático :-) O principal é que é um método geral, pelo qual posso implementar efetivamente a análise estática em qualquer lugar, mesmo no projeto mais assustador, com qualquer base de código e qualquer analisador (não necessariamente o seu), usando scripts Groovy ou bash no CI. A propósito, agora estamos contando os avisos separadamente para diferentes módulos e ferramentas do projeto, mas se os dividirmos de maneira mais granulativa (para arquivos), será muito mais próximo do método de comparação de novos / antigos. Mas nos sentimos assim e eu gostei dessa catraca porque estimula os desenvolvedores a monitorar o número total de avisos e diminuir lentamente esse número. Se tivéssemos o método dos antigos / novos, isso motivaria os desenvolvedores a monitorar a curva do número de avisos? - provavelmente sim, pode ser, não.
Quanto ao ponto 3, aqui está um exemplo real da minha experiência. Veja
este commit . De onde veio? Definimos linters no script TravisCI. Eles trabalharam lá como portões de qualidade. Mas de repente, quando uma nova versão do Ansible-lint, que estava encontrando mais avisos, algumas compilações de solicitações pull começaram a falhar devido a avisos no código, que não haviam sido alterados !!! No final, o processo foi interrompido e as solicitações de recebimento urgentes foram mescladas sem passar por portões de qualidade.
Ninguém diz que não é necessário atualizar os analisadores. Claro que sim! Como todos os outros componentes de construção. Mas deve ser um processo consciente, refletido no código fonte. E toda vez que as ações dependerem das circunstâncias (corrigimos os avisos detectados novamente ou apenas redefinimos a "catraca")
Evgeniy RyzhkovQuando me perguntam: “Existe a capacidade de verificar cada commit no PVS-Studio?”, Respondo que sim, existe. E então adicione: "Só por Deus, não falhe na construção se o PVS-Studio encontrar alguma coisa!" Porque, caso contrário, mais cedo ou mais tarde, o PVS-Studio será percebido como algo perturbador. E há situações em que É NECESSÁRIO confirmar rapidamente, em vez de lutar com as ferramentas, que não deixam a confirmação passar.
Minha opinião é ruim para falhar a compilação neste caso. É bom enviar mensagens aos autores do código do problema.
Ivan PonomarevMinha opinião é que não existe algo como "precisamos nos comprometer rapidamente". Tudo isso é apenas um processo ruim. Um bom processo gera velocidade, não porque quebramos as portas de um processo / qualidade, quando precisamos “fazê-lo rapidamente”.
Isso não contradiz o fato de que podemos fazer isso sem falhar na construção de algumas classes de resultados de análises estáticas. Significa apenas que o portão está configurado da maneira que certos tipos de descobertas são ignoradas e, para outras descobertas, temos tolerância zero.
Minha confirmação favorita no tópico "rapidamente".Evgeniy RyzhkovSou um adversário definitivo da abordagem para usar a versão antiga do analisador. E se um usuário encontrasse um bug nessa versão? Ele escreve para um desenvolvedor de ferramentas e um desenvolvedor de ferramentas até o corrige. Mas na nova versão. Ninguém suportará a versão antiga para alguns clientes. Se não estamos falando de contratos no valor de milhões de dólares.
Ivan PonomarevEvgeniy, não estamos falando sobre isso. Ninguém diz que devemos mantê-los velhos. Trata-se de corrigir versões de dependências de componentes de compilação para suas atualizações controladas - é uma disciplina comum, aplica-se a tudo, incluindo bibliotecas e ferramentas.
Evgeniy RyzhkovEu entendo como "isso deve ser feito em teoria". Mas vejo apenas duas escolhas feitas pelos clientes. Atenha-se ao novo ou ao antigo. Portanto, QUASE quase não temos essas situações em que "temos disciplina e ficamos para trás da versão atual em dois lançamentos". Não é importante para mim dizer agora que é bom ou ruim. Eu apenas digo o que vejo.
Ivan PonomarevEu entendi. De qualquer forma, tudo depende fortemente de quais ferramentas / processos seus clientes possuem e de como os utilizam. Por exemplo, não sei nada sobre como tudo funciona no mundo C ++.