Há alguns meses, nossos colegas do Google
realizaram um concurso no Kaggle para criar um classificador para as imagens recebidas no aclamado
jogo "Quick, Draw!". A equipe, na qual o desenvolvedor de Yandex Roman Vlasov participou, ficou em quarto lugar na competição. Na sessão de treinamento em aprendizado de máquina de janeiro, Roman compartilhou as idéias de sua equipe, a implementação final do classificador e práticas interessantes de seus rivais.
- Olá pessoal! Meu nome é Roma Vlasov, hoje vou falar sobre o Quick, Draw! Desafio de reconhecimento do Doodle.

Havia cinco pessoas em nossa equipe. Entrei para ela bem na frente do prazo de mesclagem. Tínhamos azar, estávamos um pouco abalados, mas estávamos sombreados por dinheiro, e eles eram da posição de ouro. E conquistamos um quarto lugar honroso.
(Durante a competição, as equipes observaram-se na classificação, formada de acordo com os resultados mostrados em uma parte do conjunto de dados proposto. A classificação final, por sua vez, foi formada na outra parte do conjunto de dados. Isso é feito para que os participantes da competição não ajustem seus algoritmos a dados específicos. Portanto, nas finais, ao alternar entre classificações, as posições "tremem" um pouco (do inglês para cima - embaralhe): em outros dados e o resultado pode ser diferente. A equipe de Roman foi a primeira entre as três primeiras. AU troika - é dinheiro, zona rankings de dinheiro, uma vez que apenas os três primeiros locais baseou prêmio Depois que a equipe "agitação apa' já estava no quarto lugar da mesma forma a outra equipe perdeu a vitória, a posição de ouro -... Ed) ..
A competição também foi significativa porque Yevgeny Babakhnin recebeu grandes mestres para ele, Ivan Sosin - mestres, Roman Solovyov permaneceu um grande mestre, Alex Parinov recebeu um mestre, me tornei um especialista, e agora já sou mestre.
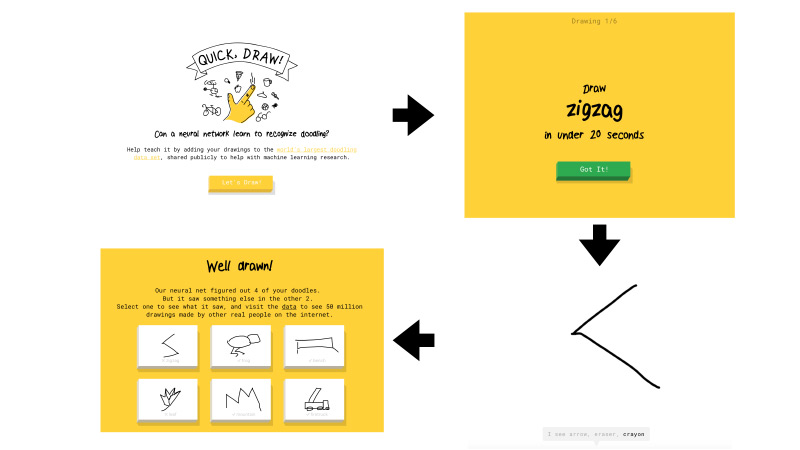
O que é isso Quick, Draw? Este é um serviço do Google. O Google pretendia popularizar a IA e, com esse serviço, queria mostrar como as redes neurais funcionam. Você vai lá, clique em Vamos desenhar, e uma nova página aparece onde você recebe instruções: desenhe um zigue-zague, você tem 20 segundos para fazer isso. Você tenta desenhar um zigue-zague em 20 segundos, como aqui, por exemplo. Se tudo der certo para você, a rede diz que é um zigue-zague e você segue em frente. Existem apenas seis dessas imagens.
Se a rede do Google não reconhecer o que você desenhou, uma cruz foi colocada na tarefa. Mais tarde, vou lhe dizer o que significa no futuro se o desenho é reconhecido pela rede ou não.
Este serviço reuniu um número bastante grande de usuários e todas as imagens que os usuários desenharam foram registradas.

Foi possível coletar quase 50 milhões de fotos. A partir disso, a data do trem e do teste para nossa competição foi formada. A propósito, a quantidade de dados no teste e o número de classes não são em vão em negrito. Eu vou falar sobre eles um pouco mais tarde.
O formato dos dados foi o seguinte. Essas não são apenas imagens RGB, mas, grosso modo, o log de tudo o que o usuário fez. A palavra é nosso alvo, o código do país é de onde o doodle é, o carimbo de data e hora é a hora. A etiqueta reconhecida apenas mostra se a rede do Google reconheceu a imagem ou não. E desenhar em si é uma sequência, uma aproximação da curva que o usuário desenha com pontos. E horários. Este é o tempo desde o início do desenho da imagem.
Os dados foram apresentados em dois formatos. Este é o primeiro formato e o segundo é simplificado. Eles mediram os intervalos a partir daí e aproximaram esse conjunto de pontos com um conjunto menor de pontos. Para fazer isso, eles usaram
o algoritmo Douglas-Pecker . Você tem um grande conjunto de pontos que simplesmente se aproxima de uma linha reta e pode realmente aproximar essa linha com apenas dois pontos. Essa é a ideia do algoritmo.
Os dados foram distribuídos da seguinte forma. Tudo é uniforme, mas existem alguns valores discrepantes. Quando resolvemos o problema, não olhamos para ele. O principal é que não havia classes realmente poucas, não precisávamos fazer amostradores ponderados e sobreamostragem de dados.

Como eram as fotos? Esta é a classe de aeronave e os exemplos são rotulados como reconhecidos e não reconhecidos. A proporção deles estava entre 1 e 9. Como você pode ver, os dados são bastante barulhentos. Eu sugeriria que este é um avião. Se você olhar para não reconhecido, na maioria dos casos, é apenas ruído. Alguém até tentou escrever "avião", mas aparentemente em francês.
A maioria dos participantes simplesmente pegou grades, renderizou dados dessa sequência de linhas como imagens RGB e as jogou na rede. Eu pintei aproximadamente da mesma maneira: peguei uma paleta de cores, pintei a primeira linha com uma cor, que estava no início desta paleta, a última com outra, que estava no final da paleta e em todos os lugares interpolados nessa paleta. A propósito, isso deu um resultado melhor do que se você desenhar como no primeiro slide - apenas preto.
Outros membros da equipe, como Ivan Sosin, tentaram abordagens ligeiramente diferentes do desenho. Com um canal, ele simplesmente desenhou uma imagem cinza, com outro canal, desenhava cada traçado com um gradiente do começo ao fim, de 32 a 255, e o terceiro canal desenhava um gradiente em todos os traçados de 32 a 255.
Outra coisa interessante é que Alex Parinov lançou informações na rede via código do país.
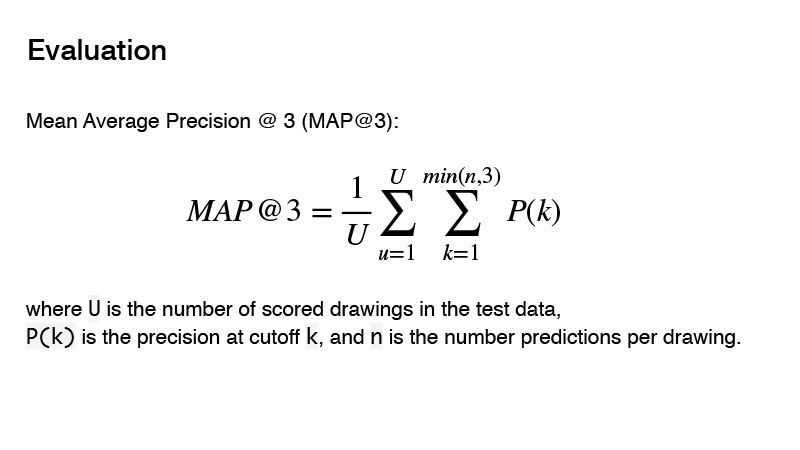
A métrica usada na competição é Precisão Média Média. Qual é a essência dessa métrica para a competição? Você pode fornecer três preditores e, se esses três preditores não estiverem corretos, você obtém 0. Se houver um preditivo correto, sua ordem será levada em consideração. E o resultado para o destino será considerado 1, dividido pela ordem da sua previsão. Por exemplo, você fez três previsões, e a primeira é a correta, então você divide 1 por 1 e obtém 1. Se o preditor estiver correto e sua ordem for 2, então 1 divisão por 2, obtém 0,5. Bem, etc.

Com o pré-processamento de dados - como desenhar figuras e assim por diante - decidimos um pouco. Quais arquiteturas usamos? Tentamos usar arquiteturas arrojadas, como PNASNet, SENet e já arquiteturas clássicas como SE-Res-NeXt, elas estão cada vez mais entrando em novas competições. Havia também ResNet e DenseNet.



Como nós ensinamos isso? Todos os modelos que adotamos, nós nos treinamos previamente na imagenet. Embora existam muitos dados, 50 milhões de fotos, mas ainda assim, se você usar uma rede pré-treinada na imagenet, ela apresentou um resultado melhor do que se você a treinasse do zero.
Que técnicas de treinamento usamos? Este é o Custeio de Recozimento com Reinicializações Quentes, falarei um pouco mais tarde. Esta é uma técnica que uso em quase todas as minhas últimas competições e, com elas, resulta muito bem treinar as redes, atingir um bom mínimo.

Em seguida, reduza a taxa de aprendizado no platô. Você começa a treinar a rede, define uma taxa de aprendizado específica, aprende e depois a perda converge gradualmente para algum valor específico. Você verifica isso, por exemplo, mais de dez épocas, a perda não foi alterada. Você reduz sua taxa de aprendizado por algum valor e continua aprendendo. Novamente, ele cai um pouco, converge em um determinado mínimo e, novamente, você reduz a taxa de aprendizado e assim por diante, até que sua rede finalmente converge.
Outra técnica interessante: não decaia a taxa de aprendizado, aumente o tamanho do lote. Existe um artigo com o mesmo nome. Quando você treina a rede, não precisa diminuir a taxa de aprendizado, basta aumentar o tamanho do lote.
Essa técnica, aliás, foi usada por Alex Parinov. Ele começou com um lote igual a 408 e, quando a rede chegou a algum patamar, ele simplesmente dobrou o tamanho do lote, etc.
Na verdade, não me lembro de que valor o tamanho do lote alcançou, mas, curiosamente, havia equipes no Kaggle que usavam a mesma técnica, o tamanho do lote era de cerca de 10.000. Aliás, estruturas modernas de aprendizado profundo, como O PyTorch, por exemplo, permite que você faça isso de maneira muito simples. Você gera seu lote e o envia para a rede não como está na sua totalidade, mas o divide em pedaços para que se encaixe na sua placa de vídeo, conte os gradientes e, depois de calcular o gradiente para todo o lote, você atualiza as escalas.
A propósito, grandes tamanhos de lote ainda entraram nessa competição, porque os dados eram muito barulhentos e um tamanho de lote grande ajudou a aproximar com mais precisão o gradiente.
Pseudo-dabbing também foi usado, na maioria das vezes, foi usado por Roman Soloviev. Ele coletou metade dos dados do teste e, nesses lotes, treinou a grade.
O tamanho das fotos desempenhou um papel importante, mas o fato é que você possui muitos dados, precisa treinar por um longo tempo e, se o tamanho da foto for muito grande, você treinará por um longo tempo. Mas isso não trouxe muito para a qualidade do seu classificador final; portanto, valeu a pena usar algumas trocas. E eles tentaram apenas fotos de tamanho não muito grande.
Como tudo isso aprendeu? A princípio, foram tiradas fotos de tamanho pequeno, várias épocas foram executadas, rapidamente levou tempo. Em seguida, foram fornecidas imagens grandes, a rede aprendeu, e ainda mais, ainda mais, para não treiná-la do zero e não gastar muito tempo.
Sobre otimizadores. Usamos SGD e Adam. Dessa forma, foi possível obter um modelo único, que proporcionava uma velocidade de 0,941-0,946 em uma tabela de classificação pública, o que é muito bom.
Se você montar os modelos de alguma forma, chegará a algum lugar em 0,951. Se você aplicar outra técnica, obterá a velocidade final no quadro público 0,954, conforme recebemos. Mas mais sobre isso mais tarde. A seguir, mostrarei como montamos os modelos e como essa velocidade final foi alcançada.
Em seguida, eu gostaria de falar sobre o recozimento de custo com reinicializações a quente ou descida estocástica por gradiente com reinicializações a quente. Grosso modo, em princípio, você pode manter qualquer otimizador, mas o ponto principal é este: se você treinar uma rede e gradualmente convergir para um mínimo, tudo estará bem, você obterá uma rede, cometerá alguns erros, mas você pode ensiná-la um pouco diferente. Você definirá uma taxa de aprendizado inicial e diminuirá gradualmente de acordo com esta fórmula. Você o subestima, sua rede chega a um determinado mínimo, depois economiza pesos e define novamente a taxa de aprendizado, que estava no início do treinamento, desse modo suba a algum lugar e subestime novamente sua taxa de aprendizado.
Assim, você pode visitar vários pontos baixos ao mesmo tempo, nos quais terá a perda mais ou menos a mesma. Mas o fato é que redes com esses pesos apresentarão erros diferentes em sua data. Ao calculá-los, você obterá uma certa aproximação e sua velocidade será maior.
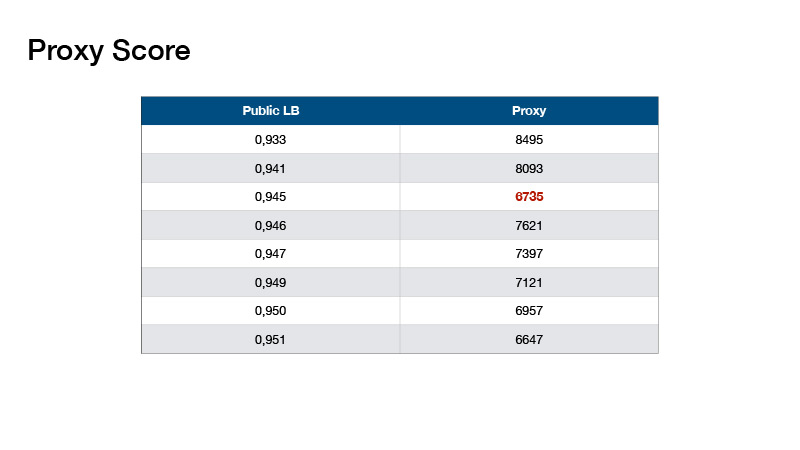
Sobre como montamos nossos modelos. No início da apresentação, eu disse para prestar atenção na quantidade de dados no teste e no número de aulas. Se você adicionar 1 ao número de destinos no conjunto de testes e dividir pelo número de classes, obterá o número 330 e foi escrito sobre isso no fórum - que as classes no teste são equilibradas. Isso pode ser usado.
Com base nisso, Roman Solovyov inventou a métrica, denominada Proxy Score, que se correlacionava muito bem com a tabela de classificação. A linha inferior é: você faz uma previsão, pega o top 1 das suas previsões e conta o número de objetos para cada classe. Subtraia 330 de cada valor e adicione os valores absolutos resultantes.
Tais valores acabaram. Isso nos ajudou a não fazer um placar de teste, mas a validar localmente e selecionar coeficientes para nossos conjuntos.
Com o conjunto, você pode obter essa velocidade. O que mais fazer? Suponha que você tenha usado as informações de que as classes em seu teste são equilibradas.
O equilíbrio foi diferente.
Um exemplo de um deles é o equilíbrio entre os caras que conquistaram o primeiro lugar.
O que nós fizemos? Nosso balanceamento foi bastante simples, foi proposto por Evgeny Babakhnin. Primeiro, classificamos nossas previsões pelo top 1 e selecionamos candidatos a partir deles - para que o número de classes não excedesse 330. Mas para algumas classes, verifica-se que há menos previsões do que 330. Ok, vamos classificar pelo top 2 e top 3, e também escolher candidatos.
Como nosso equilíbrio diferia do equilíbrio em primeiro lugar? Eles usaram uma abordagem iterativa, pegaram a classe mais popular e reduziram as probabilidades para essa classe em um número pequeno - até que essa classe não se tornou a mais popular. Eles fizeram a próxima aula mais popular. Tão mais longe e reduzido até o número de todas as classes se tornar igual.
Todos usaram uma abordagem de mais ou menos uma para treinar redes, mas nem todos usaram o balanceamento. Usando o balanceamento, você pode entrar em ouro e, se tiver sorte, então em mani.
Como pré-processar uma data? Todos pré-processaram a data mais-menos da mesma maneira - eles criaram recursos artesanais, tentaram codificar horários com cores diferentes de traços, etc. Alexey Nozdrin-Plotnitsky, que ficou em 8º lugar, estava falando sobre isso.

Ele fez diferente. Ele disse que todos esses recursos artesanais não funcionam, você não precisa fazer isso, sua rede deve aprender tudo isso sozinho. E, em vez disso, ele criou módulos de aprendizado que pré-processavam seus dados. Ele jogou neles os dados de origem sem pré-processamento - as coordenadas de pontos e tempos.
Além disso, ele pegou a diferença nas coordenadas e calculou a média ao longo dos tempos. E ele tem uma matriz bastante longa. Ele usou a convolução 1D várias vezes para obter uma matriz 64xn, onde n é o número total de pontos e 64 é feito para alimentar a matriz resultante a uma camada de alguma rede convolucional que aceita 64 canais. acabou sendo uma matriz de 64xn; daí, foi necessário compor um tensor de algum tamanho para que o número de canais fosse 64. Ele normalizou todos os pontos X, Y no intervalo de 0 a 32 para criar um tensor de tamanho 32x32. Não sei por que ele queria 32x32, aconteceu. E nessa coordenada ele colocou um fragmento dessa matriz de tamanho 64xn. Assim, ele simplesmente recebeu o tensor 32x32x64, que poderia ser colocado ainda mais na sua rede neural convolucional. Eu tenho tudo