Olá Habr! Apresento a você a tradução do artigo
"Tudo o que você precisa saber sobre gráficos de dispersão para visualização de dados", de George Seif.
Se você estiver envolvido na análise e visualização de dados, provavelmente terá que lidar com gráficos de dispersão. Apesar de sua simplicidade, os gráficos de dispersão são uma ferramenta poderosa para visualizar dados. Ao manipular cores, tamanhos e formas, é possível garantir a flexibilidade e a representatividade dos gráficos de dispersão.
Neste artigo, você aprenderá quase tudo o que precisa saber sobre visualização de dados usando gráficos de dispersão. Vamos tentar analisar todos os parâmetros necessários em seu uso no código python. Você também pode encontrar alguns truques práticos.
Edifício de regressão
Mesmo o uso mais primitivo de um gráfico de dispersão já oferece uma visão geral justa de nossos dados. Na Figura 1, já podemos ver ilhas de dados combinados e identificar rapidamente valores extremos.
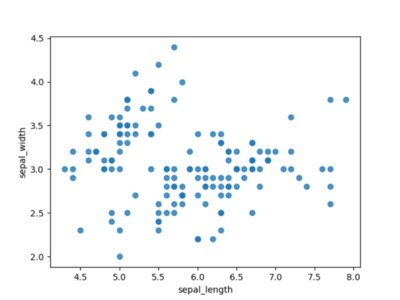 Figura 1
Figura 1
Linhas de regressão apropriadas simplificam visualmente a tarefa de identificar pontos próximos ao meio. Na Figura 2, plotamos um gráfico de linhas. É bem fácil perceber que, nesse caso, a função linear não é representativa, pois muitos pontos estão muito distantes da linha.
 Figura 2
Figura 2
A Figura 3 usa um polinômio de ordem 4 e parece muito mais promissor. Parece que, para modelar esse conjunto de dados, precisamos definitivamente de um polinômio de ordem 4.
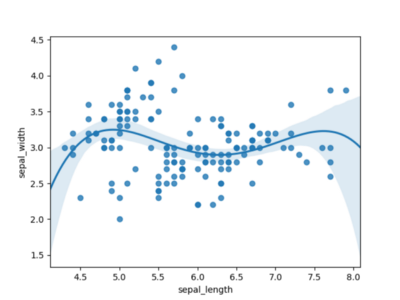 Figura 3
Figura 3
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris')
Cor e forma dos pontos
Cor e forma podem ser usadas para visualizar várias categorias no seu conjunto de dados. Cor e forma são visualmente muito claras. Quando você olha para um gráfico em que grupos de pontos têm cores diferentes de nossas formas, imediatamente se torna aparente que os pontos pertencem a grupos diferentes.
A Figura 4 mostra as classes agrupadas por cor. A Figura 5 mostra as classes, separadas por cor e forma. Nos dois casos, é muito mais fácil ver o agrupamento. Agora sabemos que será fácil separar a classe
setosa e o que devemos focar. Também está claro que um único gráfico de linhas não poderá separar os pontos verde e laranja. Portanto, precisamos adicionar algo para exibir mais dimensões.
A escolha entre cor e forma se torna uma questão de preferência. Pessoalmente, acho a cor um pouco mais clara e intuitiva, mas a escolha é sempre sua.
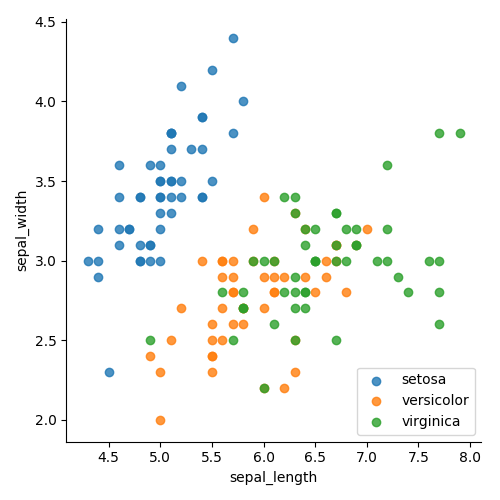 Figura 4
Figura 4
 Figura 5
Figura 5
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris')
Histograma marginal
Um exemplo de gráfico com histogramas marginais é mostrado na Figura 6. Os histogramas marginais são sobrepostos na parte superior e lateral, representando a distribuição de pontos para objetos ao longo das abcissas e ordenadas. Este pequeno acréscimo é ótimo para identificar a distribuição de pontos e discrepâncias.
Por exemplo, na Figura 6, obviamente vemos uma alta concentração de pontos em torno da marcação 3.0. E, graças a este histograma, você pode determinar o nível de concentração. No lado direito, você pode ver que, na marcação 3.0, há pelo menos três vezes mais pontos do que em qualquer outro intervalo discreto. Além disso, usando o histograma do lado direito, é possível reconhecer claramente que os valores discrepantes óbvios estão acima da marca 3,75. O diagrama superior mostra que a distribuição dos pontos ao longo do eixo X é mais uniforme, com exceção dos valores discrepantes no canto direito.
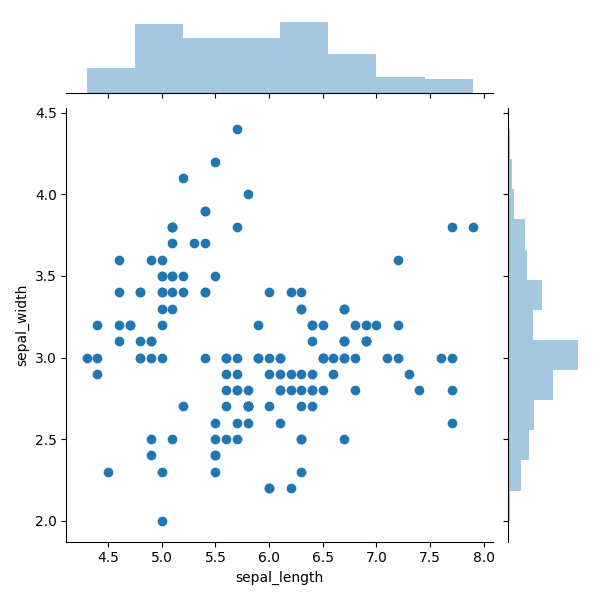 Figura 6
Figura 6
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris') sns.jointplot(x=df["sepal_length"], y=df["sepal_width"], kind='scatter') plt.show()
Bubble Charts
Usando gráficos de bolhas, precisamos usar várias variáveis para codificar informações. O novo parâmetro inerente a esse tipo de visualização é tamanho. Na Figura 7, mostramos a quantidade de batatas fritas consumidas pela altura e peso das pessoas que comeram. Observe que um gráfico de dispersão é apenas uma ferramenta de visualização bidimensional, mas ao usar gráficos de bolhas, podemos exibir com habilidade informações com três dimensões.
Aqui usamos
cor, posição e tamanho , onde a posição das bolhas determina a altura e o peso da pessoa, a cor determina o sexo e o tamanho é determinado pela quantidade de batatas fritas consumidas. O gráfico de bolhas nos permite combinar convenientemente todos os atributos em um gráfico, para que possamos ver informações de tamanho grande em uma forma bidimensional.
 Figura 7
Figura 7
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as mpatches x = np.array([100, 105, 110, 124, 136, 155, 166, 177, 182, 196, 208, 230, 260, 294, 312]) y = np.array([54, 56, 60, 60, 60, 72, 62, 64, 66, 80, 82, 72, 67, 84, 74]) z = (x*y) / 60 for index, val in enumerate(z): if index < 10: color = 'g' else: color = 'r' plt.scatter(x[index], y[index], s=z[index]*5, alpha=0.5, c=color) red_patch = mpatches.Patch(color='red', label='Male') green_patch = mpatches.Patch(color='green', label='Female') plt.legend(handles=[green_patch, red_patch]) plt.title("French fries eaten vs height and weight") plt.xlabel("Weight (pounds)") plt.ylabel("Height (inches)") plt.show()