Dodo IS é um sistema global que ajuda você a gerenciar efetivamente seus negócios na Dodo Pizza. Fecha questões de pedidos de pizza, ajuda o franqueado a acompanhar os negócios, melhora a eficiência dos funcionários e às vezes cai. O último é o pior para nós. Cada minuto dessas quedas leva à perda de lucros, insatisfação do usuário e noites sem dormir dos desenvolvedores.
Mas agora dormimos melhor. Aprendemos a reconhecer cenários de apocalipse sistêmico e processá-los. Abaixo, mostrarei como fornecemos estabilidade do sistema.

Uma série de artigos sobre o colapso do sistema Dodo IS * :
1. O dia em que Dodo está parado. Script síncrono.
2. O dia em que o Dodo está parado. Script assíncrono.
* Os materiais foram escritos com base no meu desempenho no DotNext 2018 em Moscou .
Dodo é
O sistema é uma grande vantagem competitiva de nossa franquia, porque os franqueados obtêm um modelo de negócios pronto. Estes são ERP, HRM e CRM, tudo em um.
O sistema apareceu alguns meses após a abertura da primeira pizzaria. É usado por gerentes, clientes, caixas, cozinheiros, compradores misteriosos, funcionários de call center - isso é tudo. Convencionalmente, o Dodo IS é dividido em duas partes. O primeiro é para os clientes. Isso inclui um site, um aplicativo móvel, um centro de contato. O segundo para parceiros franqueados, ajuda a gerenciar pizzarias. Por meio do sistema, faturas de fornecedores, gerenciamento de pessoal, pessoas que fazem turnos, contabilidade automática da folha de pagamento, treinamento on-line para pessoal, certificação de gerentes, sistema de controle de qualidade e compradores misteriosos passam pelo sistema.
Desempenho do sistema
Desempenho do sistema Dodo IS = Confiabilidade = Tolerância a falhas / recuperação. Vamos nos concentrar em cada um dos pontos.
Confiabilidade
Não temos grandes cálculos matemáticos: precisamos atender a um certo número de pedidos, há certas zonas de entrega. O número de clientes não varia particularmente. É claro que ficaremos felizes quando crescer, mas isso raramente acontece em grandes explosões. Para nós, o desempenho se resume a quão poucas falhas ocorrem, à confiabilidade do sistema.
Tolerância a falhas
Um componente pode depender de outro componente. Se ocorrer um erro em um sistema, o outro subsistema não deve cair.
Resiliência
Falhas de componentes individuais ocorrem todos os dias. Isso é normal. É importante a rapidez com que podemos nos recuperar de uma falha.
Cenário de falha do sistema síncrono
O que é isso
O instinto de um grande negócio é atender muitos clientes ao mesmo tempo. Assim como é impossível trabalhar para uma pizzaria de cozinha que trabalha para entrega da mesma maneira que uma dona de casa em uma cozinha em casa, um código projetado para execução síncrona não pode funcionar com êxito no atendimento ao cliente em massa em um servidor.
Há uma diferença fundamental entre executar o algoritmo em uma única instância e executar o mesmo algoritmo que um servidor na estrutura de serviço em massa.
Dê uma olhada na imagem abaixo. À esquerda, vemos como as solicitações ocorrem entre dois serviços. Essas são chamadas RPC. A próxima solicitação termina após a anterior. Obviamente, essa abordagem não é escalável - pedidos adicionais serão alinhados.
Para atender a muitos pedidos, precisamos da opção certa:
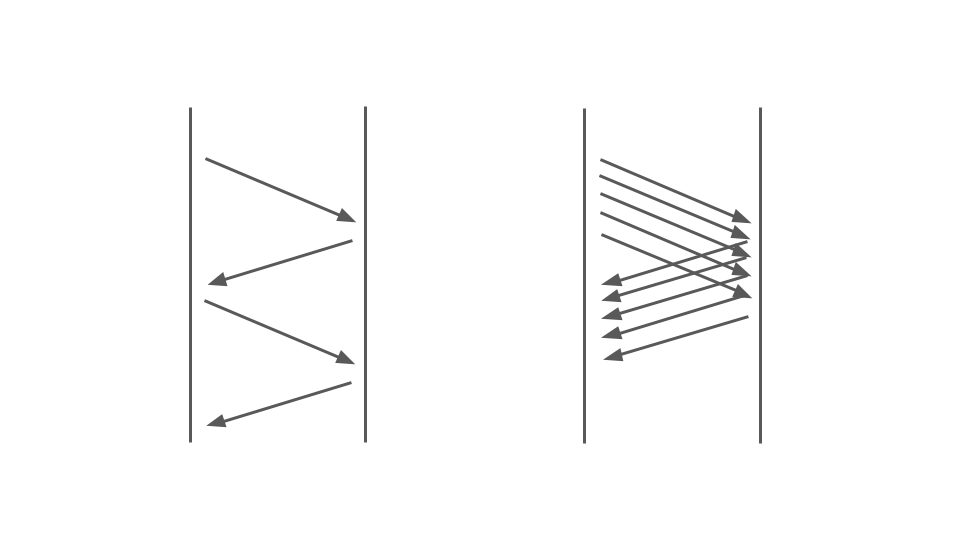
A operação do código de bloqueio em um aplicativo síncrono é bastante afetada pelo modelo de multithreading usado, ou seja, multitarefa preemptiva. Só isso pode levar a falhas.
A multitarefa simplificada e preventiva pode ser ilustrada da seguinte maneira:

Blocos coloridos são o trabalho real que a CPU faz, e vemos que o trabalho útil indicado por verde no diagrama é bastante pequeno no contexto geral. Precisamos despertar o fluxo, colocá-lo para dormir, e isso é uma sobrecarga. Esse sono / vigília ocorre durante a sincronização em quaisquer primitivas de sincronização.
Obviamente, o desempenho da CPU diminuirá se você diluir o trabalho útil com um grande número de sincronizações. Com que intensidade a multitarefa preemptiva afeta o desempenho?
Considere os resultados de um teste sintético:
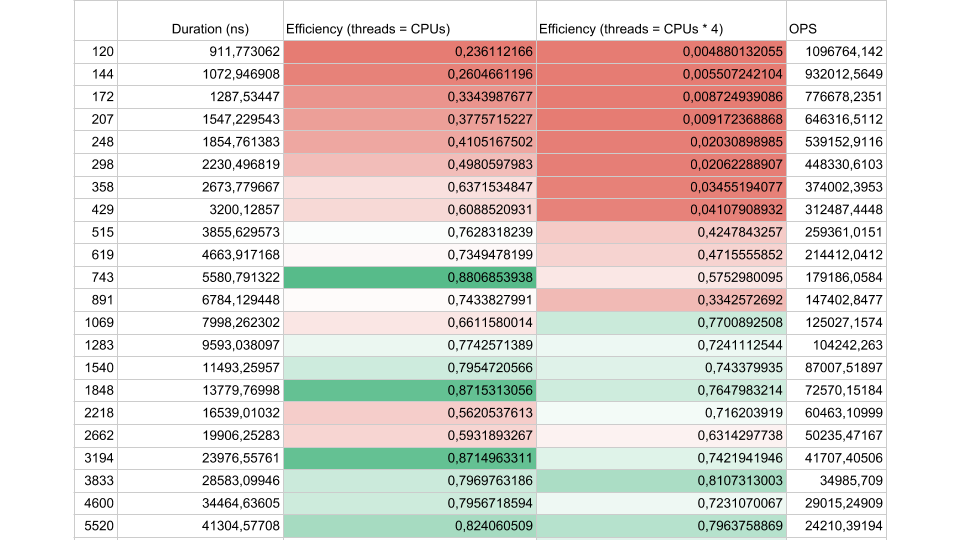
Se o intervalo de fluxo entre as sincronizações for de cerca de 1000 nanossegundos, a eficiência será bastante pequena, mesmo que o número de Threads seja igual ao número de núcleos. Nesse caso, a eficiência é de cerca de 25%. Se o número de threads for 4 vezes maior, a eficiência cai drasticamente, para 0,5%.
Pense bem: na nuvem, você encomendou uma máquina virtual com 72 núcleos. Custa dinheiro e você usa menos da metade de um núcleo. É exatamente isso que pode acontecer em um aplicativo multiencadeado.
Se houver menos tarefas, mas sua duração for maior, a eficiência aumenta. Vemos que em 5.000 operações por segundo, em ambos os casos, a eficiência é de 80 a 90%. Para um sistema multiprocessador, isso é muito bom.
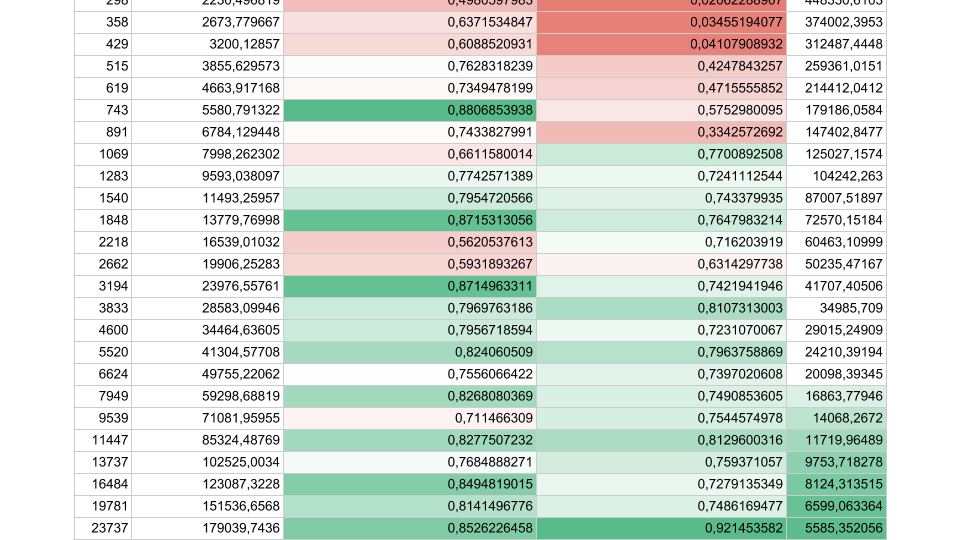
Em nossos aplicativos reais, a duração de uma operação entre sincronizações fica em algum lugar no meio, portanto o problema é urgente.
O que está havendo?
Preste atenção ao resultado do teste de estresse. Nesse caso, era o chamado "teste de extrusão".
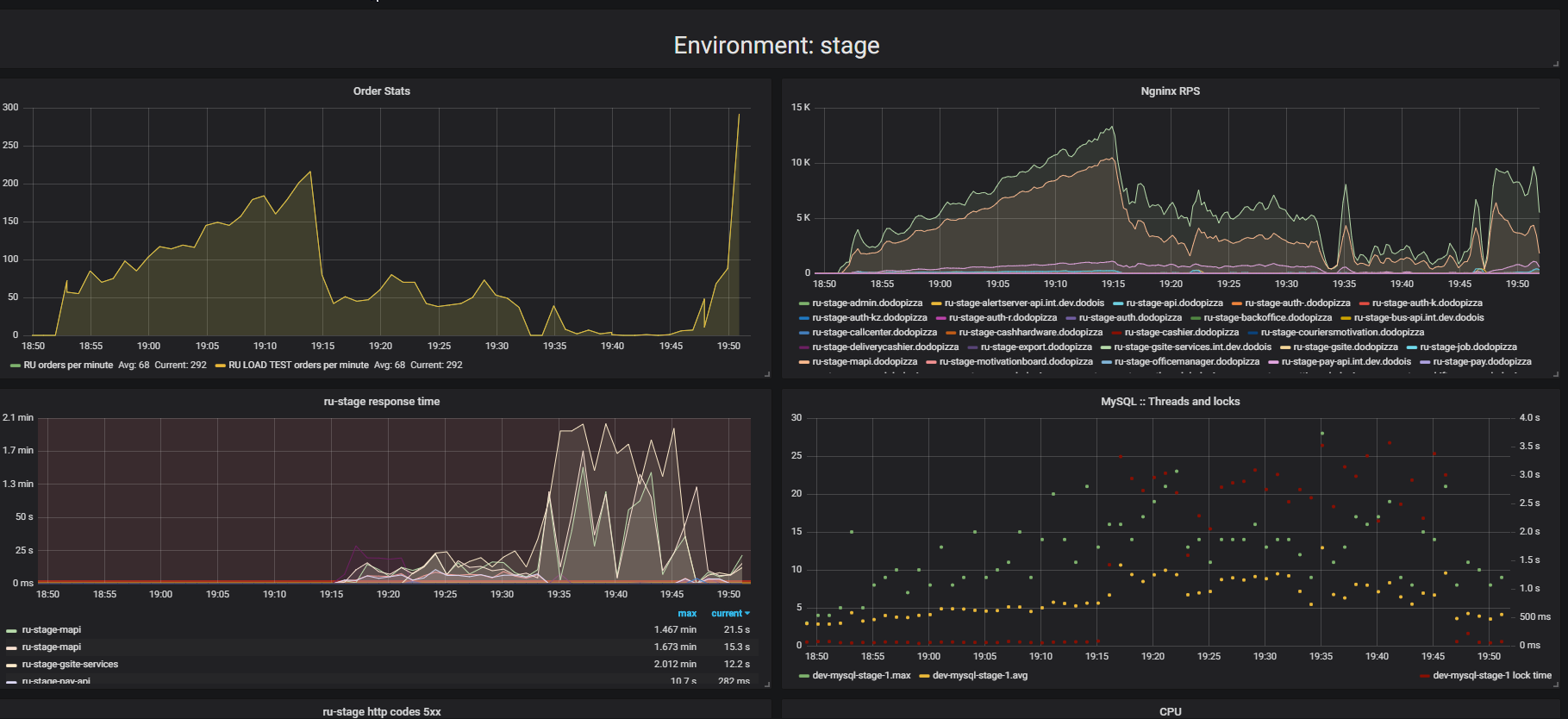
A essência do teste é que, usando um suporte de carga, enviamos mais e mais solicitações artificiais ao sistema, tentamos fazer o maior número possível de pedidos por minuto. Tentamos encontrar o limite após o qual o aplicativo se recusará a atender solicitações além de seus recursos. Intuitivamente, esperamos que o sistema seja executado até o limite, descartando solicitações adicionais. É exatamente o que aconteceria na vida real, por exemplo - ao servir em um restaurante lotado de clientes. Mas algo mais acontece. Os clientes fizeram mais pedidos e o sistema começou a servir menos. O sistema começou a atender tão poucos pedidos que pode ser considerado uma falha completa, avaria. Isso acontece com muitos aplicativos, mas deveria ser?
No segundo gráfico, o tempo para processar uma solicitação aumenta, durante esse intervalo, menos solicitações são atendidas. Os pedidos que chegaram mais cedo são atendidos muito mais tarde.
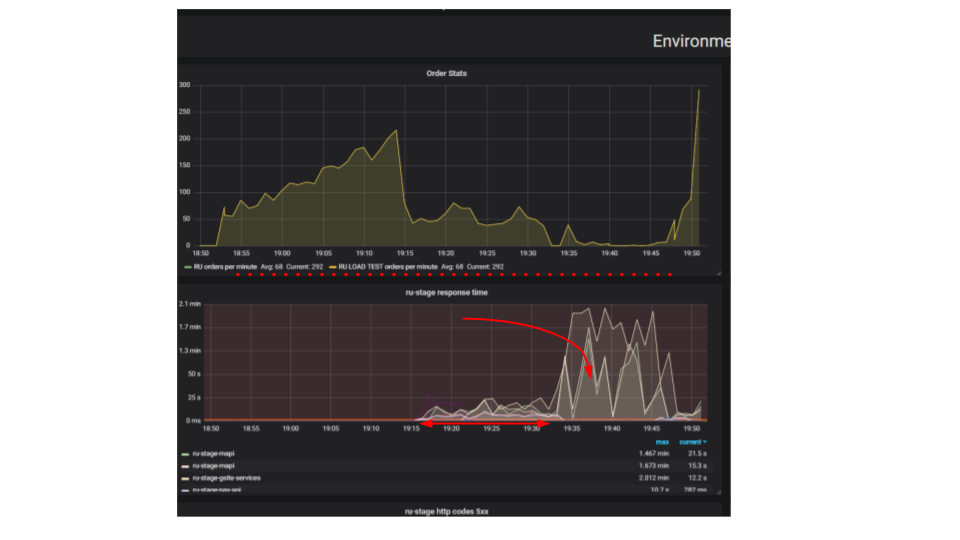
Por que o aplicativo está parando? Havia um algoritmo, funcionou. Começamos a partir da nossa máquina local, funciona muito rapidamente. Pensamos que, se pegarmos uma máquina cem vezes mais poderosa e executarmos cem solicitações idênticas, elas deverão ser executadas ao mesmo tempo. Acontece que solicitações de diferentes clientes colidem. Entre eles, surge a contenção e esse é um problema fundamental em aplicativos distribuídos. Solicitações separadas lutam por recursos.
Maneiras de encontrar um problema
Se o servidor não funcionar, primeiro tentaremos encontrar e corrigir os problemas triviais dos bloqueios dentro do aplicativo, no banco de dados e durante a E / S do arquivo. Ainda existe toda uma classe de problemas nas redes, mas até agora nos limitaremos a esses três, isso é suficiente para aprender a reconhecer problemas semelhantes e estamos principalmente interessados nos problemas que causam a Contenção - a luta por recursos.
Bloqueios em processo
Aqui está uma solicitação típica em um aplicativo de bloqueio.
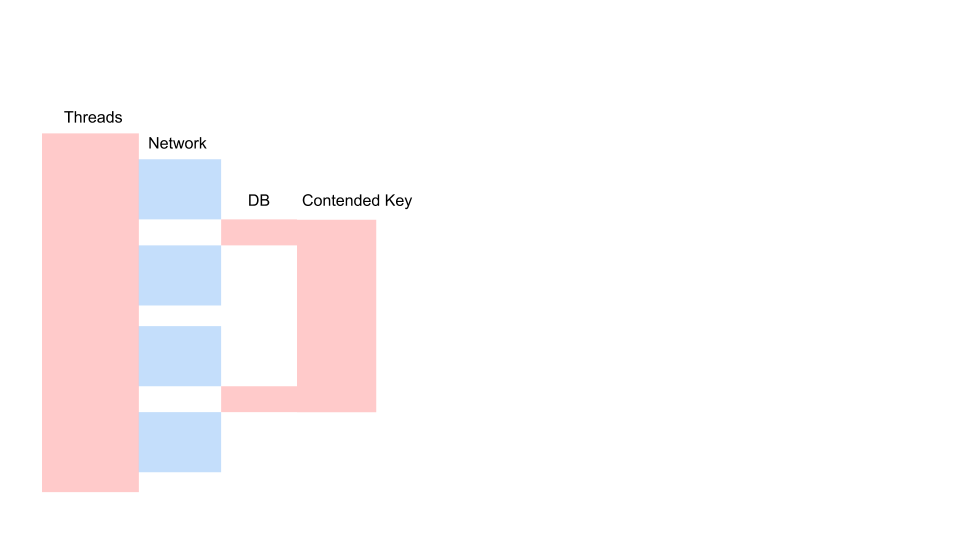
Essa é uma variação do diagrama de sequência que descreve o algoritmo para a interação do código do aplicativo e do banco de dados como resultado de alguma operação condicional. Vemos que uma chamada de rede está sendo feita e, em seguida, algo acontece no banco de dados - o banco de dados é um pouco usado. Em seguida, outro pedido é feito. Durante todo o período, uma transação no banco de dados e uma chave comum a todas as solicitações são usadas. Pode ser dois clientes diferentes ou dois pedidos diferentes, mas um e o mesmo objeto de menu de restaurante, armazenados no mesmo banco de dados dos pedidos dos clientes. Trabalhamos usando uma transação para obter consistência; duas consultas contêm Contenção na chave do objeto comum.
Vamos ver como ele escala.
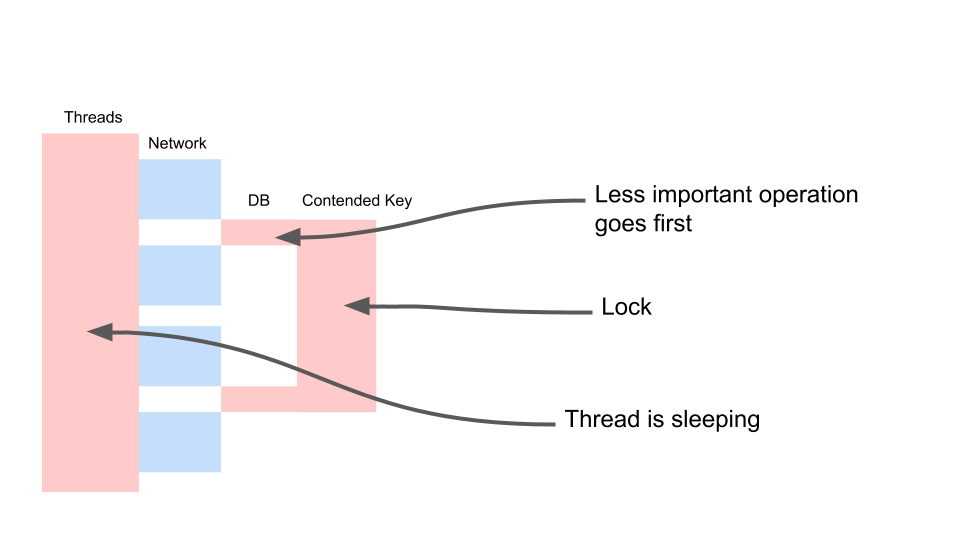
Thread dorme na maioria das vezes. Ele, de fato, não faz nada. Temos um bloqueio que interfere com outros processos. O mais irritante é que a operação menos útil em uma transação que bloqueou uma chave ocorre no início. Aumenta as transações de escopo no tempo.
Vamos lutar dessa maneira.
var fallback = FallbackPolicy<OptionalData> .Handle<OperationCancelledException>() .FallbackAsync<OptionalData>(OptionalData.Default); var optionalDataTask = fallback .ExecuteAsync(async () => await CalculateOptionalDataAsync());
Esta é a consistência eventual. Assumimos que alguns de nossos dados podem ser menos recentes. Para fazer isso, precisamos trabalhar com o código de maneira diferente. Devemos aceitar que os dados são de qualidade diferente. Não veremos o que aconteceu antes - o gerente alterou algo no menu ou o cliente clicou no botão "checkout". Para nós, não faz diferença qual deles pressionou o botão dois segundos antes. E para os negócios não há diferença.
Não há diferença, podemos fazer exatamente isso. Condicionalmente, chame-o de opcionalData. Ou seja, algum valor que podemos prescindir. Temos um fallback - o valor que obtemos do cache ou passamos algum valor padrão. E para a operação mais importante (a variável necessária), aguardaremos. Vamos esperar por ele com firmeza e só então esperaremos uma resposta aos pedidos de dados opcionais. Isso nos permitirá acelerar o trabalho. Há outro ponto significativo - essa operação pode não ser realizada por algum motivo. Suponha que o código para esta operação não seja o ideal e no momento exista um erro. Se a operação falhar, faça o fallback. E então trabalhamos com isso como com o significado usual.
DB Locks
Obtemos aproximadamente o mesmo layout quando reescrevemos em assíncrono e alteramos o modelo de consistência.
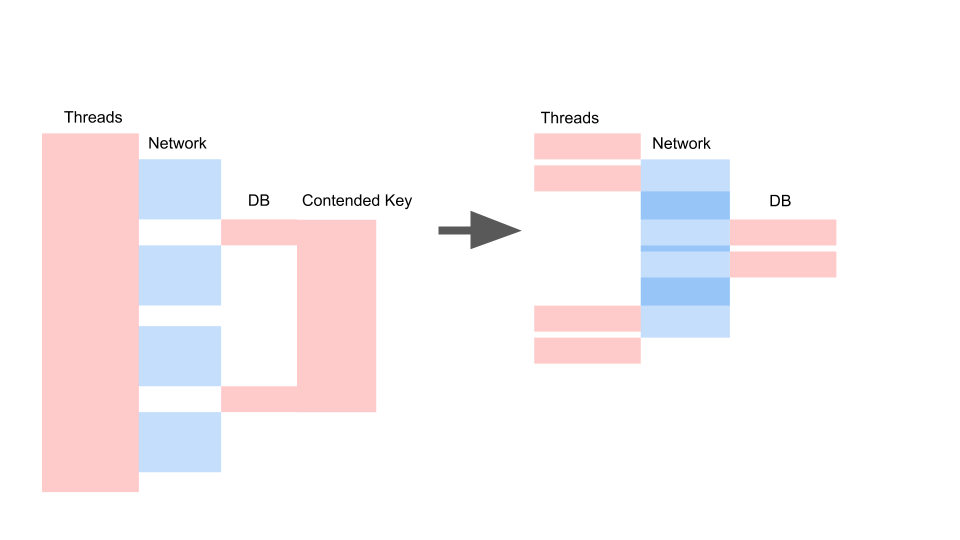
O que importa aqui não é que a solicitação tenha se tornado mais rápida no tempo. O importante é que não temos contenção. Se adicionarmos solicitações, apenas o lado esquerdo da imagem ficará saturado conosco.
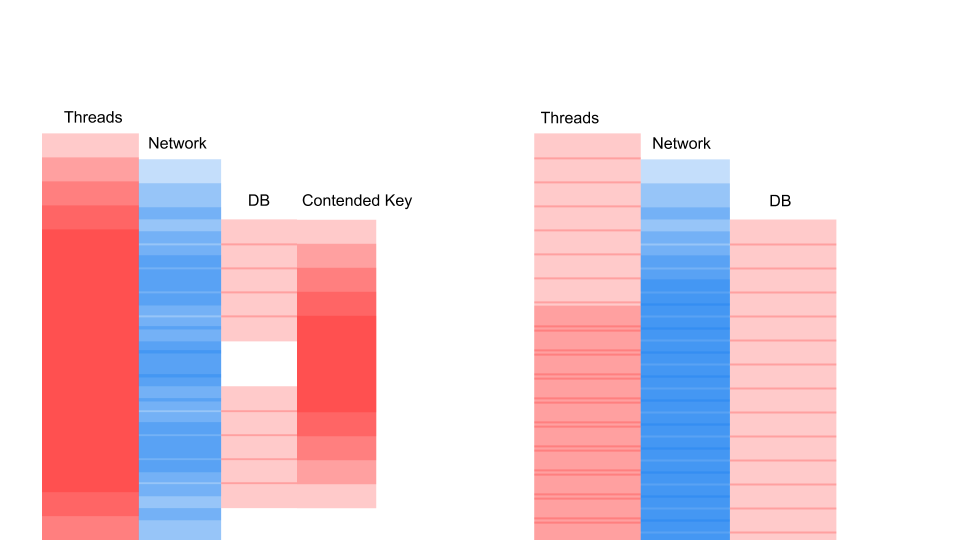
Esta é uma solicitação de bloqueio. Aqui os Threads se sobrepõem e as chaves nas quais a Contenção ocorre. À direita, não temos nenhuma transação no banco de dados e elas são executadas silenciosamente. O caso certo pode funcionar neste modo indefinidamente. Esquerda causará uma falha no servidor.
Sync io
Às vezes, precisamos de logs de arquivos. Surpreendentemente, o sistema de registro pode causar falhas desagradáveis. Latência em disco no Azure - 5 milissegundos. Se escrevermos um arquivo em uma linha, serão apenas 200 solicitações por segundo. É isso aí, o aplicativo parou.

Só que seu cabelo fica arrepiado quando você vê isso - mais de 2000 Threads foram criados no aplicativo. 78% de todos os segmentos são da mesma pilha de chamadas. Eles pararam no mesmo local e estão tentando entrar no monitor. Este monitor delimita o acesso ao arquivo em que todos nós registramos. Claro, isso deve ser cortado.

Aqui está o que você precisa fazer no NLog para configurá-lo. Criamos um alvo assíncrono e escrevemos nele. E o destino assíncrono grava no arquivo real. Obviamente, podemos perder uma certa quantidade de mensagens no log, mas o que é mais importante para os negócios? Quando o sistema caiu por 10 minutos, perdemos um milhão de rublos. Provavelmente, é melhor perder várias mensagens no log de serviço, que falharam e foram reinicializadas.
Tudo está muito ruim
A contenção é um grande problema em aplicativos com vários threads, o que não permite que você simplesmente dimensione um aplicativo com thread único. As fontes de contenção precisam ser capazes de identificar e eliminar. Um grande número de threads é desastroso para aplicativos e as chamadas de bloqueio devem ser reescritas para serem assíncronas.
Eu tive que reescrever muito legado do bloqueio de chamadas assíncronas, eu mesmo frequentemente iniciei essa atualização. Frequentemente, alguém aparece e pergunta: "Ouça, estamos reescrevendo há duas semanas, quase todas assíncronas. E quanto vai funcionar mais rápido? ” Gente, eu vou incomodá-lo - não vai funcionar mais rápido. Vai se tornar ainda mais lento. Afinal, o TPL é um modelo competitivo em cima do outro - multitarefa cooperativa sobre multitarefa preemptiva, e isso é uma sobrecarga. Em um de nossos projetos - aproximadamente + 5% para uso e carregamento da CPU no GC.
Há mais uma notícia ruim - o aplicativo pode funcionar muito pior depois de reescrever no modo assíncrono, sem perceber os recursos do modelo competitivo. Falarei sobre esses recursos em detalhes no próximo artigo.
Isso levanta a questão - é necessário reescrever?
O código síncrono é reescrito no modo assíncrono, a fim de desvincular o modelo da execução competitiva do processo (Modelo de Concorrência) e livrar-se do modelo de Multitarefa Preemptiva. Vimos que o número de threads pode afetar adversamente o desempenho, portanto, você precisa se libertar da necessidade de aumentar o número de threads para aumentar a simultaneidade. Mesmo se tivermos o Legacy e não quisermos reescrever esse código, esse é o principal motivo para reescrevê-lo.
A boa notícia no final é que agora sabemos algo sobre como se livrar dos problemas triviais da Contenção de código de bloqueio. Se você encontrar esses problemas em seu aplicativo de bloqueio, é hora de se livrar deles antes de reescrever para assíncrono, porque eles não desaparecerão por conta própria.