
Eu gostaria de apresentar o conceito de
Programação Funcional para iniciantes da maneira mais simples, destacando algumas de suas vantagens das muitas outras que realmente tornarão o código mais legível e expressivo. Peguei algumas demos interessantes para você que estão no
Playground no
Github .
Programação Funcional: Definição
Primeiro de tudo, a
Programação Funcional não é uma linguagem ou sintaxe, mas provavelmente uma maneira de resolver problemas dividindo processos complexos em processos mais simples e sua composição subseqüente. Como o nome indica, “
Programação Funcional ”
, a unidade de composição para essa abordagem é uma
função ; e o objetivo dessa
função é evitar alterar estados ou valores fora de seu
scope) .
No
Swift World, existem todas as condições para isso, porque as
funções aqui são participantes tão plenos do processo de programação quanto os
objetos, e o problema da
mutation é resolvido no nível do conceito de
value TYPES (estruturas e
enum enuméricas) que ajudam a gerenciar a mutabilidade (
mutation ) e comunique claramente como e quando isso pode acontecer.
No entanto, o
Swift não
Swift no sentido pleno da linguagem de
programação funcional , não o força a
programar com
funcionalidade , embora reconheça as vantagens das abordagens
funcionais e encontre maneiras de incorporá-las.
Neste artigo, focaremos o uso dos elementos
internos da Programação Funcional no
Swift (isto é, "pronto para uso") e entender como você pode usá-los confortavelmente em seu aplicativo.
Abordagens Imperativas e Funcionais: Comparação
Para avaliar a Abordagem
Funcional , vamos comparar as soluções para um problema simples de duas maneiras diferentes. A primeira solução é "
Imperativo "
, na qual o código altera o estado dentro do programa.
Observe que manipulamos os valores dentro da matriz mutável denominada
numbers e, em seguida, imprimimos no console. Observando este código, tente responder às seguintes perguntas que discutiremos em um futuro próximo:
- O que você está tentando alcançar com seu código?
- O que acontece se outro
thread tentar acessar a matriz de numbers enquanto seu código estiver em execução? - O que acontece se você deseja ter acesso aos valores originais na matriz de
numbers ? - Quão confiável esse código pode ser testado?
Agora vamos ver uma abordagem alternativa "
Funcional ":
Neste trecho de código, obtemos o mesmo resultado no console, abordando a solução do problema de uma maneira completamente diferente. Observe que desta vez nossa matriz de
numbers é imutável graças à palavra-chave
let .
timesTen() o processo de multiplicação de números da matriz de
numbers para o método
timesTen() , localizado na extensão de
extension Array . Ainda usamos um loop
for e modificamos uma variável chamada
output , mas o
scope dessa variável é limitado apenas por esse método. Da mesma forma, nosso argumento de entrada
self é passado para o método
timesTen() por valor (
by value ), tendo o mesmo escopo que a variável de
output . O método
timesTen() é chamado e podemos imprimir no console a matriz de
numbers original e o resultado da matriz de
result .
Vamos voltar às nossas 4 perguntas.
1. O que você está tentando alcançar com seu código?Em nosso exemplo, realizamos uma tarefa muito simples multiplicando os números na matriz de
numbers por
10 .
Com uma abordagem
imperativa , para obter uma saída, você precisa pensar como um computador, seguindo as instruções no loop
for . Nesse caso, o código mostra
você consegue o resultado. Com a Abordagem
Funcional , “
” é “
timesTen() ” no método
timesTen() . Desde que esse método tenha sido implementado em outro lugar, você poderá realmente ver apenas a expressão
numbers.timesTen() . Esse código mostra claramente o
alcançado por esse código, e não
a tarefa é resolvida. Isso é chamado de
Programação Declarativa e é fácil adivinhar por que essa abordagem é atraente.
A abordagem
imperativa faz o desenvolvedor entender
código funciona para determinar o
ele deve fazer.
A abordagem
funcional comparada à abordagem
Imperative é muito mais "expressiva" e oferece ao desenvolvedor uma oportunidade de luxo de simplesmente assumir que o método faz o que ele afirma fazer! (Obviamente, essa suposição se aplica apenas ao código pré-verificado).
2. O que acontece se outro thread tentar acessar a matriz de numbers enquanto seu código estiver em execução?Os exemplos apresentados acima existem em um espaço completamente isolado, embora em um ambiente multiencadeado complexo, é bem possível que dois
threads tentem acessar os mesmos recursos simultaneamente. No caso da abordagem
Imperative , é fácil ver que quando outro
thread tiver acesso à matriz de
numbers no processo de uso, o resultado será ditado pela ordem em que os
threads acessam a matriz de
numbers . Essa situação é chamada de
race condition e pode levar a comportamento imprevisível e até instabilidade e travamento do aplicativo.
Em comparação, a Abordagem
Funcional não tem "efeitos colaterais". Em outras palavras, a saída do método de
output não altera nenhum valor armazenado em nosso sistema e é determinada apenas pela entrada. Nesse caso, qualquer thread (
threads ) que tenha acesso à matriz
numbers receberá SEMPRE os mesmos valores e seu comportamento será estável e previsível.
3. O que acontece se você deseja ter acesso aos valores originais armazenados na matriz de
numbers ?
Esta é uma continuação da nossa discussão sobre "efeitos colaterais". Obviamente, as mudanças de estado não são rastreadas. Portanto, com a abordagem
Imperative , perdemos o estado inicial de nossa matriz de
numbers durante o processo de conversão. Nossa solução, baseada na Abordagem
Funcional , salva a matriz de
numbers originais e gera uma nova matriz de
result com as propriedades desejadas na saída. Ele deixa a matriz de
numbers original intacta e adequada para processamento futuro.
4. Quão confiável esse código pode ser testado?
Como a abordagem
Funcional destrói todos os "efeitos colaterais", a funcionalidade testada está completamente dentro do método. A entrada desse método NUNCA sofrerá alterações, portanto, você pode testar várias vezes usando o ciclo quantas vezes quiser e sempre obterá o mesmo resultado. Nesse caso, o teste é muito fácil. Em comparação, testar a solução
Imperative em um loop alterará o início da entrada e você obterá resultados completamente diferentes após cada iteração.
Resumo dos Benefícios
Como vimos em um exemplo muito simples, a Abordagem
Funcional é uma coisa interessante se você estiver lidando com um Modelo de Dados porque:
- É declarativo
- Corrige problemas relacionados a threads, como
race condition e deadlocks - Ele deixa o estado inalterado, que pode ser usado para transformações subsequentes.
- É fácil de testar.
Vamos um pouco mais longe no aprendizado da Programação
Funcional no
Swift . Ele assume que os principais "atores" são funções e devem ser principalmente
objetos da primeira classe .
Funções de primeira classe e funções de ordem superior
Para que uma função seja de primeira classe, ela deve ter a capacidade de ser declarada como uma variável. Isso permite gerenciar a função como um TIPO de dados normal e, ao mesmo tempo, executá-la. Felizmente, em
Swift funções são objetos da primeira classe, ou seja, são suportadas passando-as como argumentos para outras funções, retornando-as como resultado de outras funções, atribuindo-as a variáveis ou armazenando-as em estruturas de dados.
Por isso, temos outras funções no
Swift - funções de ordem superior que são definidas como funções que assumem outra função como argumento ou retornam uma função. Existem muitos deles:
map ,
filter ,
reduce ,
forEach ,
flatMap ,
compactMap ,
sorted , etc. Os exemplos mais comuns de funções de ordem superior são
map ,
filter e
reduce . Eles não são globais, estão todos "apegados" a certos TIPOS. Eles funcionam em todos os TIPOS de
Sequence , incluindo a
Collection , que é representada por estruturas de dados
Swift , como uma
Array , um
Dictionary e um
Set . No
Swift 5 , funções de ordem superior também funcionam com um TYPE -
Result completamente novo.
map(_:)
No
map(_:) Swift map(_:) assume uma função como parâmetro e converte os valores de um determinado
acordo com esta função. Por exemplo, aplicando
map(_:) a uma matriz de valores de
Array , aplicamos uma função de parâmetro a cada elemento da matriz original e obtemos uma matriz de
Array , mas também os valores convertidos.
No código acima, criamos a função
timesTen (_:Int) , que pega um valor inteiro
Int e retorna o valor inteiro
Int multiplicado por
10 , e o usamos como parâmetro de entrada para nossa função de
map(_:) ordem superior
map(_:) , aplicando-a à nossa matriz
numbers . Temos o resultado que precisamos na matriz de
result .
O nome da função de parâmetro
timesTen para funções de ordem superior como
map(_:) não importa, o
parâmetro de entrada e o valor de retorno são importantes, ou seja, a assinatura
(Int) -> Int parâmetro de entrada de função. Portanto, podemos usar funções anônimas no
map(_:) - closures - de qualquer forma, incluindo aquelas com nomes abreviados de argumentos
$0 ,
$1 , etc.
Se olharmos para a função
map(_ :) para uma
Array , ela pode ser assim:
func map<T>(_ transform: (Element) -> T) -> [T] { var returnValue = [T]() for item in self { returnValue.append(transform(item)) } return returnValue }
Este é um código imperativo que nos é familiar, mas não é mais um problema de desenvolvedor, é um problema da
Apple , um problema do
Swift . A implementação da função de
map(_:) ordem superior
map(_:) é otimizada pela
Apple em termos de desempenho, e nós, os desenvolvedores, temos a funcionalidade do
map(_:) garantida, para que possamos expressar corretamente corretamente com a função de argumento de
transform queremos, sem se preocupar com
será implementado. Como resultado, obtemos um código perfeitamente legível na forma de uma única linha, que funcionará melhor e mais rapidamente.
O
retornado pela função de parâmetro pode não coincidir com o
elementos na coleção original.
No código acima, temos possíveis números inteiros
possibleNumbers , representados como seqüências de caracteres, e queremos convertê-los em números inteiros de
Int , usando o inicializador disponível
Int(_ :String) representado pelo fechamento
{ str in Int(str) } . Fazemos isso usando
map(_:) e obtemos uma matriz
mapped de
Optional como a saída:

foi possível converter
elementos da nossa matriz
possibleNumbers em números inteiros, como resultado, uma parte recebeu o valor
nil , indicando a impossibilidade de converter a
String em um inteiro
Int e a outra parte transformada em
Optionals , que possuem valores:
print (mapped)
compactMap(_ :)
Se a função de parâmetro passada para a função de ordem superior tiver um valor
Optional na saída, pode ser mais útil usar outra função de ordem superior, com significado semelhante -
compactMap(_ :) , que faz a mesma coisa que
map(_:) , mas adicionalmente "expande" os valores recebidos na saída
Optional e remove valores
nil da coleção.

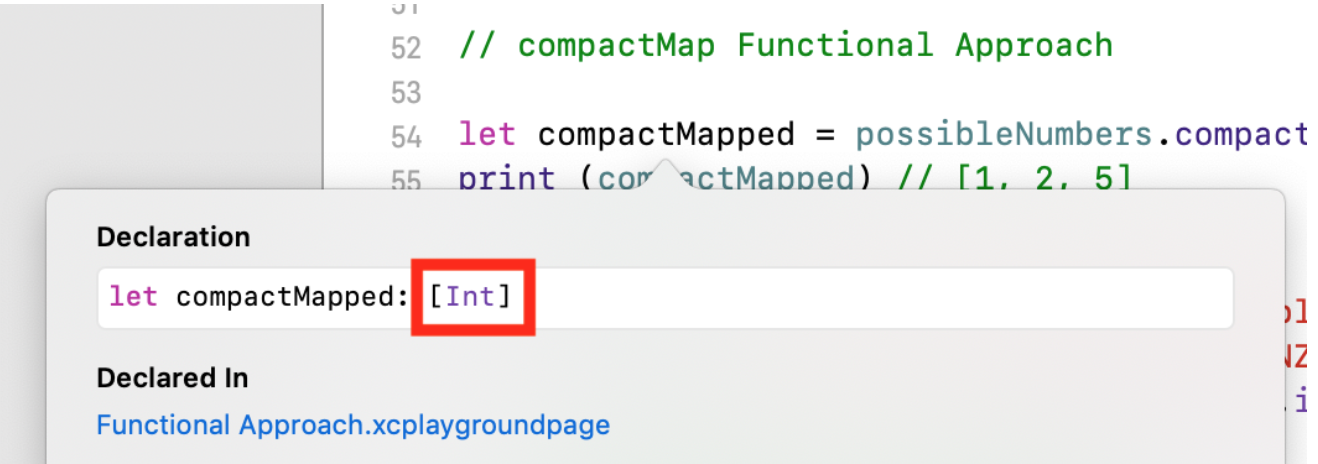
Nesse caso, obtemos uma matriz de
compactMapped TYPE
[Int] , mas possivelmente menor:
let possibleNumbers = ["1", "2", "three", "///4///", "5"] let compactMapped = possibleNumbers.compactMap(Int.init) print (compactMapped)
Sempre que você usar o
init?() Como a função de transformação, será necessário usar o
compactMap(_ :) :
Devo dizer que existem razões mais do que suficientes para usar a função de ordem superior
compactMap(_ :) .
Swift “ama” Valores
Optional , eles podem ser obtidos não apenas usando o
init?() “
failable ”
init?() , mas também usando o
as? "Fundição":
let views = [innerView,shadowView,logoView] let imageViews = views.compactMap{$0 as? UIImageView}
... e a
try? ao processar erros gerados por alguns métodos. Devo dizer que a
Apple preocupada que o uso de
try? muitas vezes leva a dobrar
Optional e no
Swift 5 agora deixa apenas um nível
Optional depois de aplicar a
try? .
Há mais uma função semelhante no nome do
flatMap(_ :) ordem superior
flatMap(_ :) , sobre o qual um pouco menor.
Às vezes, para usar o
map(_:) funções de ordem superior
map(_:) , é útil usar o método
zip (_:, _:) para criar uma sequência de pares a partir de duas seqüências diferentes.
Suponha que tenhamos uma
view na qual vários pontos são representados, conectados entre si e formando uma linha quebrada:
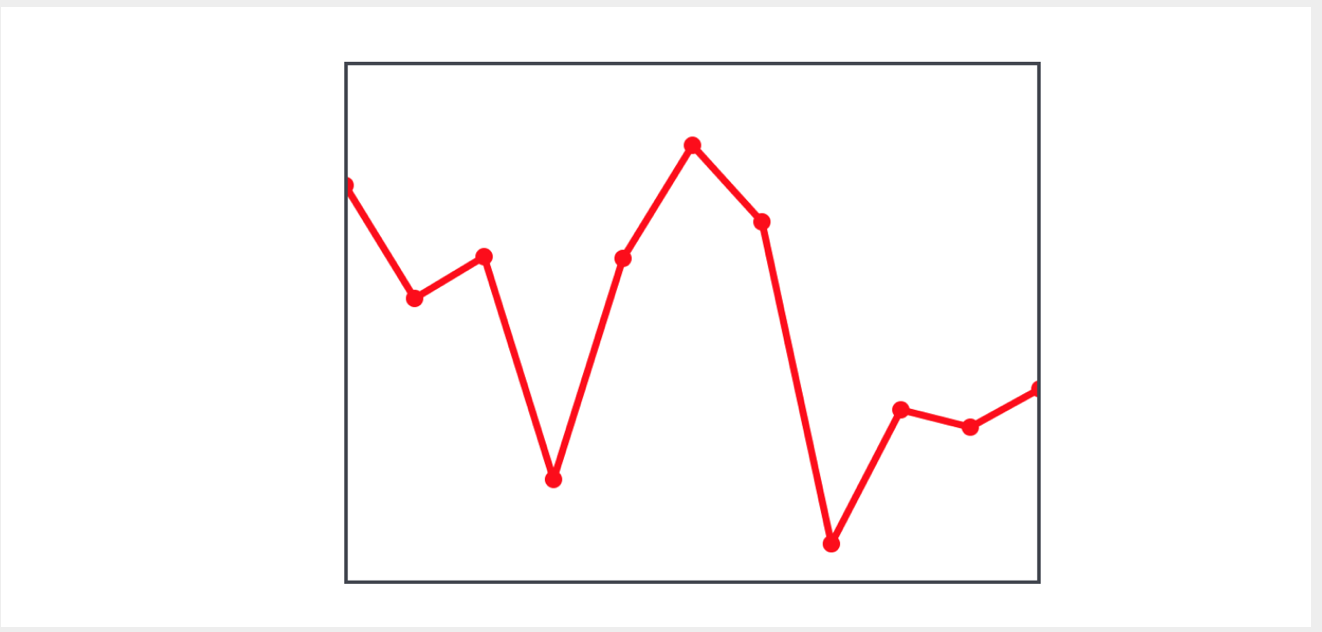
Precisamos construir outra linha quebrada conectando os pontos médios dos segmentos da linha quebrada original:

Para calcular o ponto médio de um segmento, precisamos ter as coordenadas de dois pontos: o atual e o próximo. Para fazer isso, podemos criar uma sequência que consiste em pares de pontos - o atual e o próximo - usando o método
zip (_:, _:) points.dropFirst() zip (_:, _:) , no qual usaremos a matriz de pontos iniciais e a matriz dos seguintes
points.dropFirst() :
let pairs = zip (points,points.dropFirst()) let averagePoints = pairs.map { CGPoint(x: ($0.x + $1.x) / 2, y: ($0.y + $1.y) / 2 )}
Tendo essa sequência, calculamos muito facilmente os pontos médios usando o
map(_:) funções de ordem superior
map(_:) e os exibimos no gráfico.
filter (_:)
No
Swift , o
filter (_:) função de ordem superior
filter (_:) está disponível para a maioria dos
quais a função de
map(_:) está disponível. Você pode filtrar qualquer
Sequence sequência com o
filter (_:) , isso é óbvio! O método
filter (_:) assume outra função como parâmetro, que é uma condição para cada elemento da sequência e, se a condição for satisfeita, o elemento será incluído no resultado e, se não, não será incluído. Essa "outra função" pega um valor único - um elemento da sequência
Sequence - e retorna um
Bool , o chamado predicado.
Por exemplo, para matrizes de
Array , o
filter (_:) função de ordem superior
filter (_:) aplica a função de predicado e retorna outra matriz que consiste apenas nos elementos da matriz original para os quais a função de predicado de entrada retorna
true .
Aqui, o
filter (_:) função de ordem superior
filter (_:) pega cada elemento da matriz de
numbers (representado por
$0 ) e verifica se esse elemento é um número par. Se esse for um número par, os elementos da matriz de
numbers caem na nova matriz
filted , caso contrário não. Nós, de forma declarativa, informamos ao programa o que queremos obter, em vez de nos preocuparmos com
devemos fazê-lo.
Vou dar outro exemplo de como usar o
filter (_:) função de ordem superior
filter (_:) para obter apenas os
20 primeiros números de Fibonacci com valores
< 4000 :
let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) }) .prefix(20).map{$0.0} .filter {$0 % 2 == 0 && $0 < 4000} print (fibonacci)
Obtemos uma sequência de tuplas que consiste em dois elementos da sequência de Fibonacci: a n-ésima e (n + 1) -a:
(0, 1), (1, 1), (1, 2), (2, 3), (3, 5) …
Para processamento adicional, limitamos o número de elementos aos vigésimos primeiros elementos usando o
prefix (20) e
0 o
0 elemento da tupla formada usando o
map {$0.0 } , que corresponderá à sequência de Fibonacci iniciando com
0 :
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
Poderíamos pegar o
1 elemento da tupla formada usando o
map {$0.1 } , que corresponderia à sequência de Fibonacci começando com
1 :
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
Obtemos os elementos necessários com a ajuda do
filter {$0 % 2 == 0 && $0 < 4000} função de ordem superior
filter {$0 % 2 == 0 && $0 < 4000} , que retorna uma matriz de elementos de sequência que satisfazem o predicado especificado. No nosso caso, será uma matriz de números inteiros
[Int] :
[0, 2, 8, 34, 144, 610, 2584]
Há outro exemplo útil de uso de
filter (_:) para uma
Collection .
Me deparei com
um problema real quando você tem uma série de imagens que são exibidas usando o
CollectionView e pode usar a tecnologia
Drag & Drop para coletar um "pacote" inteiro de imagens e movê-las para qualquer lugar, incluindo "dumping" para " lixeira ".

Nesse caso, a matriz de índices
removedIndexes despejadas na "lixeira" é corrigida e você precisa criar uma nova matriz de imagens, excluindo aquelas cujos índices estão na matriz
removedIndexes . Suponha que tenhamos uma matriz de
images inteiras que simula imagens e uma matriz de índices desses inteiros
removedIndexes que precisam ser removidos. Usaremos o
filter (_:) para resolver nosso problema:
var images = [6, 22, 8, 14, 16, 0, 7, 9] var removedIndexes = [2,5,0,6] var images1 = images .enumerated() .filter { !removedIndexes.contains($0.offset) } .map { $0.element } print (images1)
O método
enumerated() retorna uma sequência de tuplas que consiste em índices de
offset e valores de
element matriz.
Em seguida, aplicamos um filtro filterà sequência resultante de tuplas, deixando apenas aquelas cujo índice $0.offsetnão está contido na matriz removedIndexes. A próxima etapa, selecionamos o valor da tupla $0.elemente obtemos a matriz que precisamos images1.reduce (_:, _:)
O método reduce (_:, _:)também está disponível para a maioria dos map(_:)e métodos filter (_:). O método reduce (_:, _:)"recolhe" a sequência Sequencepara um único valor acumulado e possui dois parâmetros. O primeiro parâmetro é o valor inicial da acumulação e o segundo parâmetro é uma função que combina o valor acumulado com o elemento de sequência Sequencepara obter um novo valor acumulado.A função do parâmetro de entrada é aplicada a cada elemento da sequência Sequence, um após o outro, até chegar ao final e criar o valor acumulado final. let sum = Array (1...100).reduce(0, +)
Este é um exemplo trivial clássico do uso de uma função de ordem superior reduce (_:, _:)- contando a soma dos elementos de uma matriz Array. 1 0 1 0 +1 = 1 2 1 2 2 + 1 = 3 3 3 3 3 + 3 = 6 4 6 4 4 + 6 = 10 . . . . . . . . . . . . . . . . . . . 100 4950 100 4950 + 100 = 5050
Usando a função, reduce (_:, _:)podemos calcular muito facilmente a soma dos números de Fibonacci que atendem a uma determinada condição: let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) }) .prefix(20).map{$0.0} .filter {$0 % 2 == 0 && $0 < 4000} print (fibonacci)
Mas existem aplicações mais interessantes de uma função de ordem superior reduce (_:, _:).Por exemplo, podemos determinar de maneira muito simples e concisa um parâmetro muito importante para UIScrollView- o tamanho da área "rolável" contentSize- com base em seu tamanho subviews: let scrollView = UIScrollView() scrollView.addSubview(UIView(frame: CGRect(x: 300.0, y: 0.0, width: 200, height: 300))) scrollView.addSubview(UIView(frame: CGRect(x: 100.0, y: 0.0, width: 300, height: 600))) scrollView.contentSize = scrollView.subviews .reduce(CGRect.zero,{$0.union($1.frame)}) .size
Nesta demonstração, o valor acumulado é GCRecte a operação acumulativa é a operação de combinar os unionretângulos que são framenossos subviews.Apesar de uma função de ordem superior reduce (_:, _:)assumir um caráter acumulativo, ela pode ser usada em uma perspectiva completamente diferente. Por exemplo, para dividir uma tupla em partes em uma matriz de tuplas:
Swift 4.2introduziu um novo tipo de função de ordem superior reduce (into:, _:). O método reduce (into:, _:)é preferível em eficiência em comparação com o método reduce (:, :)se COW (copy-on-write) Arrayou for usado como a estrutura resultante Dictionary.Ele pode ser usado efetivamente para remover valores correspondentes em uma matriz de números inteiros:
... ou ao contar o número de elementos diferentes em uma matriz:
flatMap (_:)
Antes de prosseguir para esta função de ordem superior, vejamos uma demonstração muito simples. let maybeNumbers = ["42", "7", "three", "///4///", "5"] let firstNumber = maybeNumbers.map (Int.init).first
Se executarmos esse código para executar Playground, tudo parecerá bom e o nosso firstNumberserá igual 42: mas, se você não souber,
mas, se você não souber, Playgroundmuitas vezes oculta o verdadeiro firstNumber. De fato, a constante firstNumbertem Optional: Isso ocorre porque,
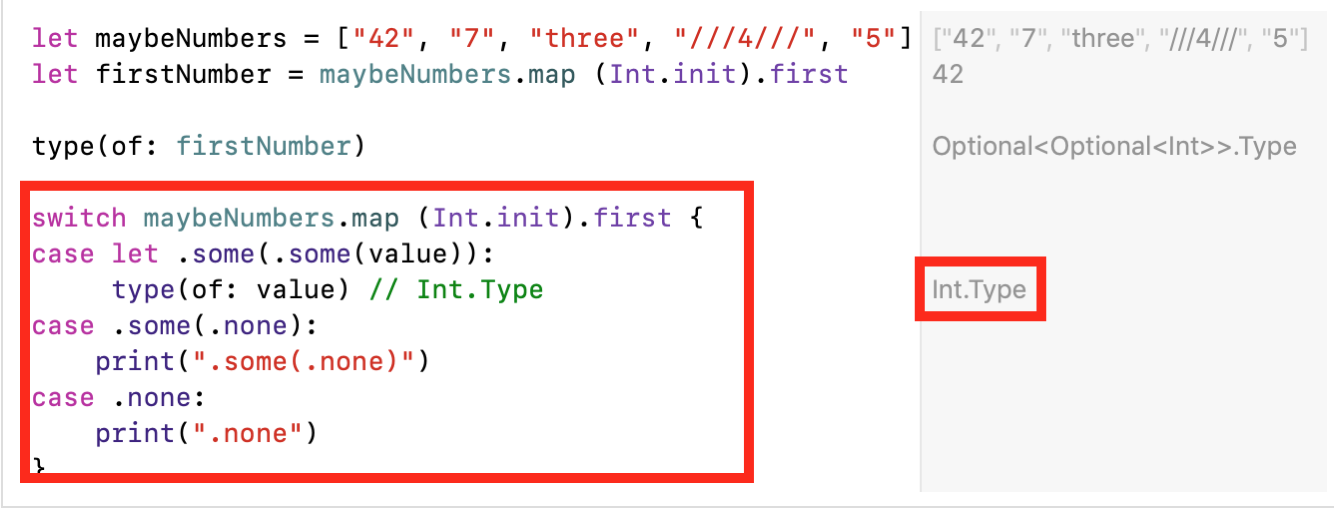
Isso ocorre porque, map (Int.init)na saída, forma uma matriz Optionalde valores TYPE [Int?], pois nem todas as linhas Stringpodem ser convertidas Inte o inicializador Int.intestá "caindo" ( failable). Em seguida, pegamos o primeiro elemento da matriz formada usando a função firstda matriz Array, que também forma a saídaOptional, pois a matriz pode estar vazia e não conseguiremos obter o primeiro elemento da matriz. Como resultado, temos um duplo Optional, ou seja Int??.Temos uma estrutura aninhada Optionalna Optionalqual é realmente mais difícil trabalhar e que naturalmente não queremos ter. Para obter o valor dessa estrutura aninhada, precisamos “mergulhar” em dois níveis. Além disso, quaisquer transformações adicionais podem aprofundar Optionalainda mais o nível .Obter o valor do aninhado duplo é Optionalrealmente oneroso.Temos três opções e todas elas exigem um conhecimento profundo do idioma Swift.if let , ; «» «» Optional , — «» Optional :

if case let ( pattern match ) :

?? :

- ,
switch :
, «»
, (
generic ) ,
map . ,
Array .
. ,
multilineString , , () :
let multilineString = """ , , ; , — , : — , . , , . . , , « » . , , ! """ let words = multilineString.lowercased() .split(separator: "\n") .map{$0.split(separator: " ")}
,
words , ( ) ()
lowercased() , c
split(separatot: "\n") ,
map {$0.split(separator: " ")} .
:
[["", ",", "", ","], ["", "", ";", "", "", "", "", ",", "—"], ["", ",", "", "", ":"], ["", "—", "", "", ",", "", "", "."], ["", "", ",", "", "", ","], ["", "", ".", "", ""], ["", ".", "", ",", ""], ["", "", "", ""], ["", "", ",", "", "«", "»"], ["", ".", "", ","], ["", ",", "", "", "!"]]
... e wordstem um Array: novamente temos uma estrutura de dados "aninhada", mas desta vez não temos
novamente temos uma estrutura de dados "aninhada", mas desta vez não temos Optional, mas Array. Se quisermos continuar processando as palavras recebidas words, por exemplo, para encontrar o espectro de letras desse texto com várias linhas, primeiro teremos que "endireitar" de maneira alguma a matriz da dupla Arraye transformá-la em uma única matriz Array. Isso é semelhante ao que fizemos com o dobro Optionalde uma demonstração no início desta seção flatMap: let maybeNumbers = ["42", "7", "three", "///4///", "5"] let firstNumber = maybeNumbers.map (Int.init).first
Swift .
Swift Array Optional .
flatMap !
map , , «» «»,
map .
flatMap , «» (
flattens )
map .
flatMap firstNumber :

c
Optional .
flatMap Array .
words map flatMap: ... e acabamos de obter uma matriz de palavras
... e acabamos de obter uma matriz de palavras wordssem nenhum "aninhamento": ["", ",", "", ",", "", "", ";", "", "", "", "", ",", "—", "", ",", "", "", ":", "", "—", "", "", ",", "", "", ".", "", "", ",", "", "", ",", "", "", ".", "", "", "", ".", "", ",", "", "", "", "", "", "", "", ",", "", "«", "»", "", ".", "", ",", "", ",", "", "", "!"]
Agora podemos continuar o processamento que precisamos da matriz de palavras resultante words, mas tenha cuidado. Se o aplicarmos novamente flatMapa cada elemento da matriz words, obteremos, talvez, um resultado inesperado, mas bastante compreensível. Temos uma única matriz, não "aninhada", de letras e símbolos
Temos uma única matriz, não "aninhada", de letras e símbolos [Character]contidos em nossa frase de várias linhas: ["", "", "", "", "", "", "", "", "", "", "", "", ",", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ",", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ";", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ...]
O fato é que a string Stringé uma coleção de Collectioncaracteres [Character]e, aplicando-se flatMapa cada palavra individual, abaixamos novamente o nível de "aninhamento" e chegamos a uma variedade de caracteres flattenCharacters.Talvez seja exatamente isso que você deseja ou talvez não. Preste atenção nisso.Juntando tudo: resolvendo alguns problemas
TAREFA 1
Podemos continuar o processamento que precisamos da matriz de palavras obtida na seção anterior wordse calcular a frequência de ocorrência de letras em nossa frase de várias linhas. Para começar, vamos "colar" todas as palavras da matriz wordsem uma linha grande e excluir todos os sinais de pontuação, ou seja, deixe apenas as letras: let wordsString = words.reduce ("",+).filter { "" .contains($0)}
Então, nós temos todas as letras que precisamos. Agora vamos fazer um dicionário deles, onde a chave keyé a letra e o valor valueé a frequência de sua ocorrência no texto.Podemos fazer isso de duas maneiras.O primeiro método está associado ao uso de uma nova Swift 4.2variedade de uma função de ordem superior que apareceu reduce (into:, _:). Este método é bastante adequado para organizarmos um dicionário letterCountcom a frequência de ocorrência de letras em nossa frase de várias linhas: let letterCount = wordsString.reduce(into: [:]) { counts, letter in counts[letter, default: 0] += 1} print (letterCount)
Como resultado, obteremos um dicionário letterCount [Character : Int]no qual as chaves keysão os caracteres encontrados na frase em estudo e como o valor valueé o número desses caracteres.O segundo método envolve inicializar o dicionário usando o agrupamento, que fornece o mesmo resultado: let letterCountDictionary = Dictionary(grouping: wordsString ){ $0}.mapValues {$0.count} letterCount == letterCountDictionary
Gostaríamos de classificar o dicionário em letterCountordem alfabética: let lettersStat = letterCountDictionary .sorted(by: <) .map{"\($0.0):\($0.1)"} print (lettersStat)
Mas não podemos classificar o dicionário diretamente Dictionary, pois não é fundamentalmente uma estrutura de dados ordenada. Se aplicarmos a função sorted (by:)ao dicionário Dictionary, ele retornará para nós os elementos da sequência classificada com o predicado fornecido na forma de uma matriz de tuplas nomeadas, que maptransformamos em uma matriz de seqüências de caracteres que [":17", ":5", ":18", ...]refletem a frequência de ocorrência da letra correspondente.Vemos que desta vez sorted (by:)apenas o operador " <" é passado como predicado para uma função de ordem superior . A função sorted (by:)espera uma "função de comparação" como o único argumento na entrada. É usado para comparar dois valores adjacentes e decidir se eles estão ordenados corretamente (neste caso, retornatrue) ou não (retorna false). Podemos atribuir a essa "função de comparação" funções sorted (by:)na forma de um fechamento anônimo: sorted(by: {$0.key < $1.key}
E podemos apenas fornecer o operador " <", que possui a assinatura de que precisamos, como foi feito acima. Essa também é uma função e a classificação por chave está em andamento key.Se queremos classificar o dicionário por valores valuee descobrir quais letras são mais frequentemente encontradas nesta frase, teremos que usar o fechamento da função sorted (by:): let countsStat = letterCountDictionary .sorted(by: {$0.value > $1.value}) .map{"\($0.0):\($0.1)"} print (countsStat )
Se dermos uma olhada na solução para o problema de determinar o espectro de letras de uma frase multilinha como um todo ... let multilineString = """ , , ; , — , : — , . , , . . , , « » . , , ! """ let words = multilineString.lowercased() .split(separator: "\n") .flatMap{$0.split(separator: " ")} let wordsString = words.reduce ("",+).filter { "" .contains($0)} let letterCount = wordsString.reduce(into: [:]) { counts, letter in counts[letter, default: 0] += 1} let lettersStat = letterCountDictionary .sorted(by: <) .map{"\($0.0):\($0.1)"} print (lettersStat)
… , (
var ,
let) () , , :
split - ,
map —
flatMap - ( ),
filter - ,
sorted - ,
reduce -
, . «» ,
map , ,
flatMap, se quisermos selecionar apenas determinados dados, usaremos filteretc. Todas essas funções de "ordem mais alta" são projetadas e testadas Applelevando em consideração a otimização do desempenho. Portanto, esse trecho de código é muito confiável e conciso - não precisávamos de mais de cinco frases para resolver nosso problema. Este é um exemplo de programação funcional.A única desvantagem da aplicação da abordagem funcional nesta demonstração é que, por uma questão de imutabilidade, testabilidade e legibilidade, perseguimos repetidamente nosso texto por várias funções de ordem superior. No caso de um grande número de itens de coleção, o Collectiondesempenho pode despencar. Por exemplo, se usarmos primeiro filter(_:)e, e depois - first.EmSwift 4 Algumas novas opções de recursos foram adicionadas para melhorar o desempenho, e aqui estão algumas dicas para escrever código mais rápido.1. Use contains, NÃOfirst( where: ) != nil
A verificação de que um objeto está em uma coleção Collectionpode ser feita de várias maneiras. O melhor desempenho é fornecido pela função contains.CÓDIGO CORRETO let numbers = [0, 1, 2, 3] numbers.contains(1)
CÓDIGO INCORRETO let numbers = [0, 1, 2, 3] numbers.filter { number in number == 1 }.isEmpty == false numbers.first(where: { number in number == 1 }) != nil
2. Use validação isEmpty, NÃO uma comparação countcom zero
Como em algumas coleções, o acesso à propriedade counté realizado através da iteração sobre todos os elementos da coleção.CÓDIGO CORRETO let numbers = [] numbers.isEmpty
CÓDIGO INCORRETO let numbers = [] numbers.count == 0
3. Verifique a string vazia StringcomisEmpty
String Stringin Swifté uma coleção de caracteres [Character]. Isso significa que para strings Stringtambém é melhor usar isEmpty.CÓDIGO CORRETO myString.isEmpty
CÓDIGO INCORRETO myString == "" myString.count == 0
4. Obtenção do primeiro elemento que satisfaz certas condições
A iteração de toda a coleção para obter o primeiro objeto que satisfaz determinadas condições pode ser executada usando um método filterseguido por um método first, mas o método é o melhor em termos de velocidade first (where:). Esse método para de percorrer a coleção assim que ela atende às condições necessárias. O método filtercontinuará a percorrer toda a coleção, independentemente de ter atendido aos elementos necessários ou não.Obviamente, o mesmo vale para o método last (where:).CÓDIGO CORRETO let numbers = [3, 7, 4, -2, 9, -6, 10, 1] let firstNegative = numbers.first(where: { $0 < 0 })
CÓDIGO INCORRETO let numbers = [0, 2, 4, 6] let allEven = numbers.filter { $0 % 2 != 0 }.isEmpty
Às vezes, quando a coleção Collectioné muito grande e o desempenho é crítico para você, vale a pena comparar as abordagens imperativas e funcionais e escolher a que mais lhe convém.TAREFA 2
Há outro ótimo exemplo de um uso muito conciso de uma função de ordem superior reduce (_:, _:)que me deparei. Este é um jogo SET .Aqui estão suas regras básicas. O nome do jogo SETvem da palavra em inglês "set" - "set". O jogo SETenvolve 81 cartas, cada uma com uma imagem única: Cada carta possui 4 atributos, listados abaixo:Quantidade : cada carta possui um, dois ou três caracteres.Tipo de caracteres : ovais, losangos ou ondas.Cor : os símbolos podem ser vermelhos, verdes ou roxos.Preenchimento : os caracteres podem estar vazios, sombreados ou sombreados.Objetivo do jogo
Cada carta possui 4 atributos, listados abaixo:Quantidade : cada carta possui um, dois ou três caracteres.Tipo de caracteres : ovais, losangos ou ondas.Cor : os símbolos podem ser vermelhos, verdes ou roxos.Preenchimento : os caracteres podem estar vazios, sombreados ou sombreados.Objetivo do jogoSET : 12 , ,
SET (), 3- , , 3- . .
, 3- , , 3- , , …
SET struct SetCard SET 3-
isSet( cards:[SetCard]) :
struct SetCard: Equatable { let number: Variant
—
number ,
shape ,
color fill —
Variant , 3 :
var1 ,
var2 var3 , 3-
rawValue —
1,2,3 .
rawValue . - , ,
color ,
rawValue colors 3- , ,
colors 3- ,
3 ,
6 9 , ,
6 . 3-
rawValue colors 3- . , , 3
SET . , 3
SET ,
SetCard -
number ,
shape ,
color fill —
rawValue 3-.
static isSet( cards:[SetCard]) sums rawValue 3- 4-
reduce ,
0 ,
{$0 + $1.number.rawValue} ,
{$0 + $1.color.rawValue} ,
{$0 + $1.shape.rawValue} ,
{ {$0 + $1.fill.rawValue} .
sums 3-,
reduce , ,
true "
AND "
{$0 && ($1 % 3) == 0} .
Swift 5 isMultiply(of:) % . :
{ $0 && ($1.isMultiply(of:3) } .
, 3
SetCard SET -, "
" ,
Playground :

SET (
UI )
,
.
. . , (, ) (, ). .
Swift point.free " Functions " " Side Effects " ,
" " « » .
Em um sentido matemático, isso significa aplicar uma função ao resultado de outra função. Em uma Swiftfunção, eles podem retornar um valor que você pode usar como entrada para outra função. Esta é uma prática de programação comum.Imagine que temos uma matriz de números inteiros e queremos obter uma matriz de quadrados de números pares únicos na saída. Normalmente, reimplementamos isso da seguinte maneira: var integerArray = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5] func unique(_ array: [Int]) -> [Int] { return array.reduce(into: [], { (results, element) in if !results.contains(element) { results.append(element) } }) } func even(_ array: [Int]) -> [Int] { return array.filter{ $0%2 == 0} } func square(_ array: [Int]) -> [Int] { return array.map{ $0*$0 } } var array = square(even(unique(integerArray)))
, , . ( ) , ( ) . —
inegerArray ,
unique , —
even , ,
square .
«»
>>> |> , ,
integerArray «» :
var array1 = integerArray |> unique >>> even >>> square
F# ,
Elixir Elm «» .
Swift «»
>>> |> ,
Generics , (
closure )
infix :
precedencegroup ForwardComposition{ associativity: left higherThan: ForwardApplication } infix operator >>> : ForwardComposition func >>> <A, B, C>(left: @escaping (A) -> B, right: @escaping (B) -> C) -> (A) -> C { return { right(left($0)) } } precedencegroup ForwardApplication { associativity: left } infix operator |> : ForwardApplication func |> <A, B>(a: A, f: (A) -> B) -> B { return f(a) }
, , . ,
map «»
>>> ,
map :
var integerArray1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5] let b = integerArray1.map( { $0 + 1 } >>> { $0 * 3 } >>> String.init) print (b)
Mas nem sempre uma abordagem funcional produz um efeito positivo.No início, quando apareceu Swiftem 2014, todos correram para escrever bibliotecas com operadores para "composição" de funções e resolver uma tarefa difícil para a época, como analisar JSONusando operadores de programação funcional em vez de usar construções infinitamente aninhadas if let. Eu mesmo traduzi o artigo sobre a análise funcional do JSON que me encantou com sua solução elegante e era fã da biblioteca Argo .Mas os desenvolvedores Swiftseguiram um caminho completamente diferente e propuseram, com base na tecnologia orientada a protocolos, uma maneira muito mais concisa de escrever código. Para "entregar" os JSONdados diretamente aoCodable, que implementa automaticamente este protocolo, se o seu modelo é composto pelas conhecidas Swiftestruturas de dados: String, Int, URL, Array, Dictionary, etc. struct Blog: Codable { let id: Int let name: String let url: URL }
Tendo JSONdados desse famoso artigo ... [ { "id" : 73, "name" : "Bloxus test", "url" : "http://remote.bloxus.com/" }, { "id" : 74, "name" : "Manila Test", "url" : "http://flickrtest1.userland.com/" } ]
... no momento, você só precisa de uma linha de código para obter uma variedade de blogs blogs: let blogs = Bundle.main.path(forResource: "blogs", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Blog].self, from: $0) } print ("\(blogs!)")
Todo mundo se esqueceu com segurança de usar os operadores da "composição" de funções para analisar JSON, se houver outra maneira mais compreensível e fácil de fazer isso usando protocolos.Se tudo é tão fácil, podemos "enviar" JSONdados para modelos mais complexos. Suponha que tenhamos um arquivo de JSONdados que tenha um nome user.jsone esteja localizado em nosso diretório.Ele Resources.contém dados sobre um determinado usuário: { "email": "blob@pointfree.co", "id": 42, "name": "Blob" }
E temos um Codable Usercom um inicializador a partir dos dados json: struct User: Codable { let email: String let id: Int let name: String init?(json: Data) { if let newValue = try? JSONDecoder().decode(User.self, from: json) { self = newValue } else { return nil } } }
Podemos facilmente obter um novo usuário newUsercom um código funcional ainda mais simples: let newUser = Bundle.main.path(forResource: "user", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { User.init(json: $0) }
,
newUser Optional ,
User? :

,
Resources invoices.json .
[ { "amountPaid": 1000, "amountDue": 0, "closed": true, "id": 1 }, { "amountPaid": 500, "amountDue": 500, "closed": false, "id": 2 } ]
,
User .
struct Invoice …
struct Invoice: Codable { let amountDue: Int let amountPaid: Int let closed: Bool let id: Int }
…
JSON invoices ,
decode :
let invoices = Bundle.main.path(forResource: "invoices", ofType: "json") .map( URL.init(fileURLWithPath:) ) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) }
invoices [Invoice]? :

user invoices ,
nil , , ,
UserEnvelope , :
struct UserEnvelope { let user: User let invoices: [Invoice] }
Em vez de executar duas vezes if let... if let newUser = newUser, let invoices = invoices { }
... vamos escrever um análogo funcional do duplo if letcomo uma Genericfunção auxiliar zipque converte dois Optionalvalores em uma Optionaltupla: func zip<A, B>(_ a: A?, _ b: B?) -> (A, B)? { if let a = a, let b = b { return (a, b) } return nil }
Agora não temos motivos para atribuir algo às variáveis newUsere invoices, apenas incorporamos tudo à nossa nova função zip, usamos o inicializador UserEnvelope.inite tudo funcionará! let userEnv = zip( Bundle.main.path(forResource: "user", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { User.init(json: $0) }, Bundle.main.path(forResource: "invoices", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) } ).flatMap (UserEnvelope.init) print ("\(userEnv!)")
Em uma única expressão, um algoritmo inteiro para fornecer JSONdados a um complexo struct UserEnvelope.zip , , . user , JSON , invoices , JSON . .map , , «» .flatMap , , , .
zip ,
map flatMap - (domain-specific language, DSL) .
,
pointfree.co .
, .
Swf t « »,
map ,
flatMap ,
reduce ,
filter Sequence ,
Optional Result . « »
, value
—
struct enum .
iOS .
,
Playground ,
Github .
Playground , :
«» Xcode Playground «Launching Simulator» «Running Playground».Referências:
Functional Programming in Swift: An Introduction.An Introduction to Functional Programming in Swift.The Many Faces of Flat-Map: Part 3Inside the Standard Library: Sequence.map()Practical functional programming in Swift