Os autores são John Hennessey e David Patterson, vencedores do Turing Award de 2017 "por uma abordagem sistemática e mensurável inovadora ao design e verificação de arquiteturas de computadores que tiveram um impacto duradouro em toda a indústria de microprocessadores". Artigo publicado em Communications of the ACM, fevereiro de 2019, volume 62, nº 2, pp. 48-60, doi: 10.1145 / 3282307 “Quem não se lembra do passado está fadado a repeti-lo”
“Quem não se lembra do passado está fadado a repeti-lo” - George Santayana, 1905
Começamos nossa
palestra em
Turing em 4 de junho de 2018 com uma revisão da arquitetura de computadores a partir dos anos 60. Além dele, destacamos as questões atuais e tentamos identificar oportunidades futuras que prometem uma nova era de ouro no campo da arquitetura de computadores na próxima década. O mesmo da década de 1980, quando realizamos nossa pesquisa para melhorar o custo, a eficiência energética, a segurança e o desempenho dos processadores, pelos quais recebemos esse honorável prêmio.
Ideias-chave
- O progresso do software pode impulsionar a inovação arquitetônica
- Aumentar o nível de interfaces de software e hardware cria oportunidades para inovação arquitetônica
- O mercado finalmente determina o vencedor na disputa pela arquitetura
O software "conversa" com o equipamento através de um dicionário chamado "arquitetura do conjunto de instruções" (ISA). No início dos anos 60, a IBM tinha quatro séries incompatíveis de computadores, cada uma com seu próprio ISA, pilha de software, sistema de E / S e nicho de mercado - orientado para pequenas empresas, grandes empresas, aplicativos científicos e sistemas em tempo real, respectivamente. Os engenheiros da IBM, incluindo o vencedor do Prêmio Turing Frederick Brooks Jr., decidiram criar um único ISA que unisse efetivamente todos os quatro.
Eles precisavam de uma solução técnica sobre como fornecer ISA igualmente rápido para computadores com barramentos de 8 e 64 bits. Em certo sentido, os ônibus são os "músculos" dos computadores: eles fazem o trabalho, mas são relativamente fáceis de "compactar" e "expandir". Então, e agora o maior desafio para os designers é o "cérebro" do equipamento de controle do processador. Inspirado pela programação, o pioneiro da ciência da computação e o vencedor do Prêmio Turing Maurice Wilkes propôs opções para simplificar esse sistema. O controle foi apresentado como uma matriz bidimensional, que ele chamou de "armazenamento de controle" (armazenamento de controle).
Cada coluna da matriz correspondia a uma linha de controle, cada linha era micro-instrução e o registro de micro-instruções era chamado de microprogramação . A memória de controle contém um intérprete ISA escrito por micro-instruções, portanto a execução de uma instrução normal requer várias micro-instruções. A memória de controle é implementada, de fato, na memória e é muito mais barata que os elementos lógicos.
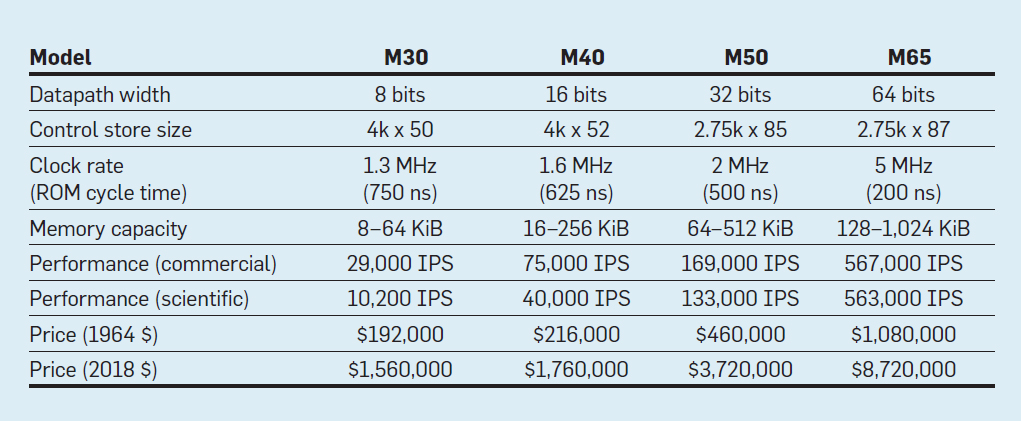 Recursos dos quatro modelos da família IBM System / 360; IPS significa operações por segundo
Recursos dos quatro modelos da família IBM System / 360; IPS significa operações por segundoA tabela mostra quatro modelos do novo ISA no System / 360 da IBM, lançado em 7 de abril de 1964. Os barramentos diferem 8 vezes, a capacidade de memória é 16, a velocidade do relógio é quase 4, o desempenho é 50 e o custo é quase 6. Os computadores mais caros têm a memória de controle mais extensa, porque os barramentos de dados mais complexos usavam mais linhas de controle . Os computadores mais baratos possuem menos memória de controle devido ao hardware mais simples, mas precisavam de mais micro-instruções, pois precisavam de mais ciclos de clock para executar a instrução System / 360.
Graças à microprogramação, a IBM apostou que o novo ISA revolucionaria o setor de computação - e ganhou a aposta. A IBM dominava seus mercados, e os descendentes dos mainframes antigos de 55 anos de idade ainda geram receita de US $ 10 bilhões anualmente.
Como já foi observado repetidamente, embora o mercado seja um árbitro imperfeito como tecnologia, mas devido aos laços estreitos entre arquitetura e computadores comerciais, em última análise, determina o sucesso das inovações arquitetônicas, que geralmente exigem investimentos significativos em engenharia.
Circuitos integrados, CISC, 432, 8086, IBM PC
Quando os computadores mudaram para circuitos integrados, a lei de Moore significava que a memória de controle poderia se tornar muito maior. Por sua vez, isso permitiu um ISA muito mais complexo. Por exemplo, a memória de controle VAX-11/780 da Digital Equipment Corp. em 1977, eram 5120 palavras em 96 bits, enquanto seu antecessor usava apenas 256 palavras em 56 bits.
Alguns fabricantes ativaram o firmware para clientes selecionados que podem ter adicionado recursos personalizados. Isso é chamado de armazenamento de controle gravável (WCS). O computador WCS mais famoso foi o
Alto , que os vencedores do Prêmio Turing Chuck Tucker e Butler Lampson e colegas criaram para o Centro de Pesquisa Xerox Palo Alto em 1973. Foi realmente o primeiro computador pessoal: aqui está o primeiro monitor com imagens elemento a elemento e a primeira rede Ethernet local. Os controladores do inovador monitor e placa de rede eram microprogramas armazenados no WCS com capacidade para 4096 palavras em 32 bits.
Nos anos 70, os processadores ainda permaneciam 8 bits (por exemplo, Intel 8080) e eram programados principalmente em assembler. Os concorrentes adicionaram novas instruções para superar um ao outro, mostrando suas realizações com exemplos de montadores.
Gordon Moore acreditava que o próximo ISA da Intel duraria para sempre para a empresa, então ele contratou muitos médicos inteligentes em ciência da computação e os enviou para uma nova instalação em Portland para inventar o próximo grande ISA. O processador 8800, como a Intel originalmente o chamou, tornou-se um projeto de arquitetura de computador absolutamente ambicioso para qualquer época, é claro, foi o projeto mais agressivo dos anos 80. Ele incluiu endereçamento baseado em capacidade de 32 bits, uma arquitetura orientada a objetos, instruções de comprimento variável e seu próprio sistema operacional na nova linguagem de programação Ada.
Infelizmente, esse projeto ambicioso exigiu vários anos de desenvolvimento, o que forçou a Intel a lançar um projeto de backup de emergência em Santa Clara para lançar rapidamente um processador de 16 bits em 1979. A Intel deu à nova equipe 52 semanas para desenvolver o novo ISA "8086", projetar e construir o chip. Dado um cronograma apertado, o design do ISA levou apenas 10 pessoas-semana por três semanas regulares, principalmente devido à expansão de registros de 8 bits e um conjunto de instruções 8080 para 16 bits. A equipe completou o 8086 dentro do cronograma, mas esse processador foi anunciado sem muita alarde.
A Intel teve muita sorte que a IBM estava desenvolvendo um computador pessoal para competir com o Apple II e precisava de um microprocessador de 16 bits. A IBM estava de olho no Motorola 68000 com um ISA semelhante ao IBM 360, mas estava atrasado no cronograma agressivo da IBM. Em vez disso, a IBM mudou para a versão de 8 bits do barramento 8086. Quando a IBM anunciou o PC em 12 de agosto de 1981, esperava vender 250.000 computadores até 1986. Em vez disso, a empresa vendeu 100 milhões em todo o mundo, apresentando um futuro muito promissor para o ISA de emergência da Intel.
O projeto original Intel 8800 foi renomeado para iAPX-432. Finalmente, foi anunciado em 1981, mas exigia vários chips e apresentava sérios problemas de desempenho. Foi concluída em 1986, um ano após a Intel ter expandido o ISA 8086 de 16 bits para 80386, aumentando os registros de 16 para 32 bits. Portanto, a previsão de Moore em relação ao ISA estava correta, mas o mercado escolheu o 8086 feito pela metade, em vez do iAPX-432 ungido. Como os arquitetos dos processadores Motorola 68000 e iAPX-432 perceberam, o mercado raramente consegue demonstrar paciência.
Do conjunto de instruções complexo ao abreviado
No início dos anos 80, vários estudos de computadores com um conjunto de instruções complexas (CISC) foram realizados: eles possuem grandes microprogramas na grande memória de controle. Quando o Unix demonstrou que mesmo o sistema operacional pode ser escrito em uma linguagem de alto nível, a pergunta principal era: “Quais instruções os compiladores gerarão?” em vez do antigo "Que montador os programadores usarão?" Um aumento significativo no nível da interface hardware-software criou uma oportunidade para inovação na arquitetura.
O vencedor do Prêmio Turing John Kokk e seus colegas desenvolveram ISAs mais simples e compiladores de minicomputadores. Como um experimento, eles reorientaram seus compiladores de pesquisa a usar o IBM 360 ISA para usar apenas operações simples entre registradores e carregar a memória, evitando instruções mais complexas. Eles notaram que os programas são executados três vezes mais rápido se usarem um subconjunto simples. Emer e Clark
descobriram que 20% das instruções do VAX ocupam 60% do microcódigo e apenas 0,2% do tempo de execução. Um autor deste artigo (Patterson) passou umas férias criativas na DEC, ajudando a reduzir erros no microcódigo VAX. Se os fabricantes de microprocessadores seguiriam os projetos ISA com um conjunto de comandos CISC complexos em computadores grandes, esperavam um grande número de erros de microcódigo e queriam encontrar uma maneira de corrigi-los. Ele escreveu
esse artigo , mas a revista
Computer o rejeitou. Os revisores sugeriram que a péssima idéia de construir microprocessadores com o ISA é tão complexa que eles precisam ser reparados em campo. Essa falha colocou em dúvida o valor do CISC para microprocessadores. Ironicamente, os modernos microprocessadores CISC incluem mecanismos de recuperação de microcódigo, mas a recusa em publicar o artigo inspirou o autor a desenvolver um ISA menos complexo para microprocessadores - computadores com um conjunto de instruções reduzido (RISC).
Esses comentários e a transição para idiomas de alto nível permitiram a transição do CISC para o RISC. Primeiro, as instruções RISC são simplificadas, portanto, não há necessidade de um intérprete. As instruções RISC são geralmente simples como micro-instruções e podem ser executadas diretamente por hardware. Em segundo lugar, a memória rápida usada anteriormente para o interpretador de microcódigo CISC foi redesenhada no cache de instruções RISC (o cache é uma memória pequena e rápida que armazena em buffer as instruções executadas recentemente, pois essas instruções provavelmente serão reutilizadas em um futuro próximo). Em terceiro lugar,
alocadores de registro com base no esquema de cores do gráfico de Gregory Chaitin facilitaram muito o uso eficiente de registradores para compiladores, que se beneficiaram dessas ISAs com operações de registro em registro. Finalmente, a lei de Moore levou ao fato de que, na década de 1980, havia transistores suficientes em um chip para acomodar um barramento completo de 32 bits em um único chip, juntamente com caches para instruções e dados.
Por exemplo, na fig. A Figura 1 mostra os microprocessadores
RISC-I e
MIPS desenvolvidos na Universidade da Califórnia em Berkeley e Stanford University em 1982 e 1983, que demonstraram os benefícios do RISC. Como resultado, em 1984 esses processadores foram apresentados na conferência líder em design de circuitos, a Conferência Internacional de Circuitos de Estado Sólido da IEEE (
1 ,
2 ). Foi um momento maravilhoso quando vários estudantes de pós-graduação em Berkeley e Stanford criaram microprocessadores que excederam as capacidades da indústria daquela época.
 Fig. 1. Processadores RISC-I da Universidade da Califórnia em Berkeley e MIPS da Stanford University
Fig. 1. Processadores RISC-I da Universidade da Califórnia em Berkeley e MIPS da Stanford UniversityEsses chips acadêmicos inspiraram muitas empresas a criar microprocessadores RISC, que foram os mais rápidos nos próximos 15 anos. A explicação está relacionada à seguinte fórmula de desempenho do processador:
Tempo / Programa = (Instruções / Programa) × (medidas / instrução) × (tempo / medida)Os engenheiros do DEC
mostraram mais tarde que, para um programa, CISCs mais complexos exigem 75% do número de instruções RISC (o primeiro termo na fórmula), mas em uma tecnologia semelhante (terceiro termo), cada instrução CISC leva de 5 a 6 ciclos a mais (segundo termo), o que torna os microprocessadores RISC cerca de 4 vezes mais rápidos.
Não havia tais fórmulas na literatura de computação dos anos 80, o que nos levou a escrever o livro
Computer Architecture: A Quantitective Approach em 1989. A legenda explica o tema do livro: usar medidas e parâmetros de referência para quantificar compensações, em vez de confiar na intuição e na experiência do designer, como no passado. Nossa abordagem quantitativa também foi inspirada no que
o livro de Donald Knuth, vencedor do prêmio Turing, fez para algoritmos.
VLIW, EPIC, Itanium
O próximo ISA inovador deveria superar o sucesso do RISC e do CISC. A
arquitetura muito longa de instruções de máquinas
VLIW e seu primo EPIC (Computing with paralelismo explícito de instruções de máquinas) da Intel e da Hewlett-Packard usavam instruções longas, cada uma das quais consistindo em várias operações independentes ligadas entre si. Os apoiadores do VLIW e EPIC na época acreditavam que se uma instrução pudesse indicar, digamos, seis operações independentes - duas transferências de dados, duas operações inteiras e duas operações de ponto flutuante - e a tecnologia do compilador poderia atribuir operações com eficiência a seis slots de instruções, então o equipamento pode ser simplificado. Semelhante à abordagem do RISC, o VLIW e o EPIC transferiram o trabalho do hardware para o compilador.
Juntas, a Intel e a Hewlett-Packard desenvolveram um processador baseado em EPIC de 64 bits para substituir a arquitetura de 32 bits x86. Grandes expectativas foram depositadas no primeiro processador EPIC chamado Itanium, mas a realidade não correspondeu às primeiras declarações dos desenvolvedores. Embora a abordagem EPIC tenha funcionado bem para programas de ponto flutuante altamente estruturados, não foi possível obter alto desempenho para programas inteiros com menos ramificação e falhas de cache previsíveis. Como Donald Knuth
observou mais tarde: "O Itanium deveria ser ... incrível - até que os compiladores desejados fossem basicamente impossíveis de escrever". Os críticos notaram atrasos no lançamento do Itanium e o apelidaram de Itanik em homenagem ao infeliz navio de passageiros Titanic. O mercado novamente não demonstrou paciência e adotou a versão de 64 bits do x86, e não o Itanium, como sucessora.
A boa notícia é que o VLIW ainda é adequado para aplicativos mais especializados que executam pequenos programas com ramificações mais simples sem falhas de cache, incluindo o processamento de sinal digital.
RISC vs. CISC na era PC e pós-PC
A AMD e a Intel precisavam de 500 equipes de design e tecnologia superior de semicondutores para preencher a lacuna de desempenho entre x86 e RISC. Novamente, por uma questão de desempenho alcançado por meio de pipelining, um decodificador de instruções on-the-fly converte instruções complexas x86 em microinstruções internas do tipo RISC. A AMD e a Intel então constroem um pipeline para sua implementação. Quaisquer idéias que os designers do RISC usaram para melhorar o desempenho - caches separados de instruções e dados, caches de segundo nível no chip, um pipeline profundo e o recebimento e execução simultâneos de várias instruções - foram incluídos no x86. No auge da era dos computadores pessoais em 2011, a AMD e a Intel enviavam anualmente cerca de 350 milhões de microprocessadores x86. Altos volumes e baixas margens da indústria também significaram preços mais baixos do que os computadores RISC.
Com centenas de milhões de computadores vendidos anualmente, o software se tornou um mercado enorme. Enquanto os fornecedores de software Unix precisavam lançar versões diferentes de software para diferentes arquiteturas RISC - Alpha, HP-PA, MIPS, Power e SPARC - os computadores pessoais tinham um ISA, então os desenvolvedores lançaram software "encolhido" que era binário compatível apenas com arquitetura x86. Devido à sua base de software muito maior, desempenho semelhante e preços mais baixos, até o ano 2000 a arquitetura x86 dominava os mercados de desktops e pequenos servidores.
A Apple ajudou a inaugurar a era pós-PC com o iPhone em 2007. Em vez de comprar microprocessadores, as empresas de smartphones criaram seus próprios sistemas em um chip (SoC) usando o desenvolvimento de outras pessoas, incluindo processadores RISC da ARM. Aqui, os designers são importantes não apenas no desempenho, mas também no consumo de energia e na área de chips, o que coloca em desvantagem a arquitetura CISC. Além disso, a Internet das Coisas aumentou significativamente o número de processadores e as compensações necessárias em tamanho de chip, energia, custo e desempenho. Essa tendência aumentou a importância do tempo e do custo do projeto, piorando ainda mais a posição dos processadores CISC. Na era pós-PC de hoje, as remessas anuais de x86 caíram quase 10% desde o pico de 2011, enquanto os chips RISC dispararam para 20 bilhões. Hoje, 99% dos processadores de 32 e 64 bits no mundo são RISC.
Concluindo esta revisão histórica, podemos dizer que o mercado resolveu a disputa entre RISC e CISC. Embora o CISC tenha vencido as fases posteriores da era dos PCs, o RISC vence agora que a era pós-PC chegou. Não há novas ISAs na CISC há décadas. Para nossa surpresa, o consenso geral sobre os melhores princípios ISA para processadores de uso geral hoje ainda é a favor do RISC, 35 anos após sua invenção.
Desafios modernos para a arquitetura do processador
“Se um problema não tem solução, talvez não seja um problema, mas um fato com o qual você deve aprender a viver” - Shimon Peres
Embora a seção anterior tenha focado no desenvolvimento de uma arquitetura de conjunto de instruções (ISA), a maioria dos designers do setor não desenvolve novos ISAs, mas integra os ISAs existentes à tecnologia de fabricação existente.
Desde o final dos anos 70, a tecnologia predominante tem sido circuitos integrados em estruturas MOS (MOS), primeiro tipo n (nMOS) e, em seguida, complementares (CMOS). O impressionante ritmo de melhoria na tecnologia MOS - capturado pelas previsões de Gordon Moore - foi a força motriz que permitiu aos designers desenvolver métodos mais agressivos para obter desempenho para um determinado ISA. A previsão inicial de Moore em 1965 previa uma duplicação anual da densidade do transistor; em 1975, ele a revisou , prevendo uma duplicação a cada dois anos. No final, essa previsão começou a ser chamada de lei de Moore. Como a densidade dos transistores cresce quadraticamente e a velocidade cresce linearmente, o uso de mais transistores pode aumentar a produtividade.O fim da lei de Moore e da lei de escala de Dennard
Embora a lei de Moore esteja em vigor há muitas décadas (veja a Figura 2), por volta de 2000, ela começou a desacelerar e, em 2018, a diferença entre a previsão de Moore e as capacidades atuais aumentou para 15 vezes. Em 2003, Moore sugeriu que isso era inevitável . Atualmente, espera-se que a diferença continue a aumentar à medida que a tecnologia CMOS se aproxima dos limites fundamentais.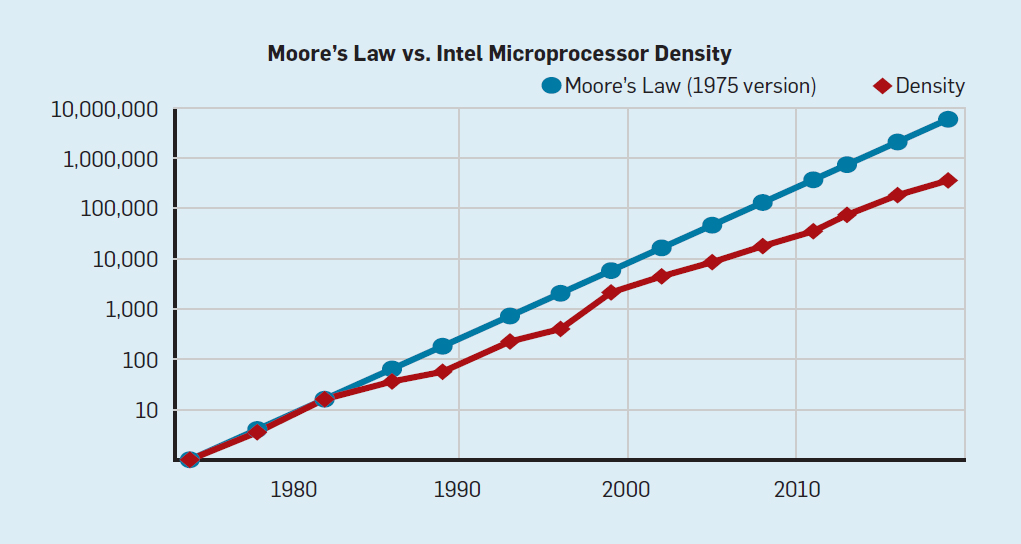 Fig. 2. O número de transistores em um chip Intel comparado àLei de Moore. A Lei de Moore foi acompanhada por uma projeção feita por Robert Dennard chamada "Dennard Scaling"que à medida que a densidade dos transistores aumenta, o consumo de energia do transistor diminui, portanto o consumo por mm² de silício será quase constante. À medida que o poder computacional de um milímetro de silício crescia a cada nova geração de tecnologia, os computadores se tornavam mais eficientes em termos energéticos. A escala de Dennard começou a desacelerar significativamente em 2007 e, em 2012, praticamente não havia chegado a nada (veja a Figura 3).
Fig. 2. O número de transistores em um chip Intel comparado àLei de Moore. A Lei de Moore foi acompanhada por uma projeção feita por Robert Dennard chamada "Dennard Scaling"que à medida que a densidade dos transistores aumenta, o consumo de energia do transistor diminui, portanto o consumo por mm² de silício será quase constante. À medida que o poder computacional de um milímetro de silício crescia a cada nova geração de tecnologia, os computadores se tornavam mais eficientes em termos energéticos. A escala de Dennard começou a desacelerar significativamente em 2007 e, em 2012, praticamente não havia chegado a nada (veja a Figura 3).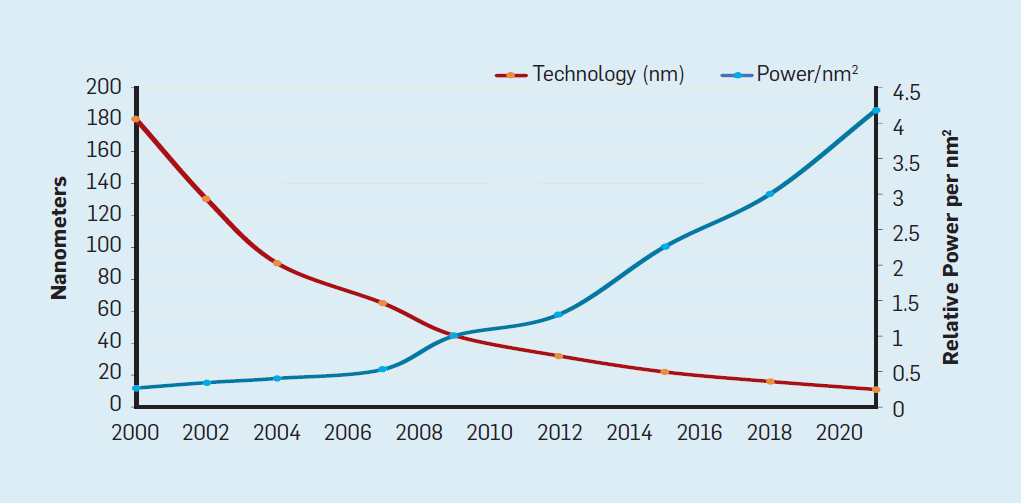 Fig. 3. Número de transistores por chip e consumo de energia por mm²De 1986 a 2002, a concorrência em nível de instrução (ILP) foi o principal método de arquitetura para aumentar a produtividade. Juntamente com o aumento da velocidade dos transistores, isso proporcionou um aumento anual de produtividade de cerca de 50%. O fim do dimensionamento de Dennard significava que os arquitetos tinham que encontrar melhores maneiras de usar a simultaneidade.Para entender por que um aumento na ILP reduziu a eficiência, considere o núcleo dos modernos processadores ARM, Intel e AMD. Suponha que ele tenha um pipeline de 15 estágios e quatro instruções por relógio. Assim, a qualquer momento no transportador existem até 60 instruções, incluindo cerca de 15 ramais, uma vez que elas representam cerca de 25% das instruções executadas. Para preencher o pipeline, as ramificações são previstas e o código é colocado especulativamente no pipeline para execução. A previsão especulativa é a fonte do desempenho e da ineficiência do ILP. Quando a previsão de ramificação é ideal, a especulação melhora o desempenho e apenas aumenta levemente o consumo de energia - e pode até economizar energia - mas quando as ramificações não são previstas corretamente, o processador deve jogar fora os cálculos errados.e todo o trabalho e energia desperdiçados. O estado interno do processador também precisará ser restaurado para o estado que existia antes da ramificação incompreendida, com a despesa de tempo e energia adicionais.Para entender como esse projeto é complexo, imagine a dificuldade de prever corretamente os resultados de 15 ramos. Se o construtor do processador definir um limite de 10% de perdas, o processador deverá prever corretamente cada ramo com uma precisão de 99,3%. Não há muitos programas de ramificação de uso geral que possam ser previstos com tanta precisão.Para avaliar em que consiste esse trabalho desperdiçado, considere os dados na Fig. 4, mostrando a proporção de instruções que são executadas com eficiência, mas são desperdiçadas porque o processador previu incorretamente ramificações. Nos testes SPEC no Intel Core i7, uma média de 19% das instruções são desperdiçadas. No entanto, a quantidade de energia gasta é maior, uma vez que o processador deve usar energia adicional para restaurar o estado quando é previsto incorretamente.
Fig. 3. Número de transistores por chip e consumo de energia por mm²De 1986 a 2002, a concorrência em nível de instrução (ILP) foi o principal método de arquitetura para aumentar a produtividade. Juntamente com o aumento da velocidade dos transistores, isso proporcionou um aumento anual de produtividade de cerca de 50%. O fim do dimensionamento de Dennard significava que os arquitetos tinham que encontrar melhores maneiras de usar a simultaneidade.Para entender por que um aumento na ILP reduziu a eficiência, considere o núcleo dos modernos processadores ARM, Intel e AMD. Suponha que ele tenha um pipeline de 15 estágios e quatro instruções por relógio. Assim, a qualquer momento no transportador existem até 60 instruções, incluindo cerca de 15 ramais, uma vez que elas representam cerca de 25% das instruções executadas. Para preencher o pipeline, as ramificações são previstas e o código é colocado especulativamente no pipeline para execução. A previsão especulativa é a fonte do desempenho e da ineficiência do ILP. Quando a previsão de ramificação é ideal, a especulação melhora o desempenho e apenas aumenta levemente o consumo de energia - e pode até economizar energia - mas quando as ramificações não são previstas corretamente, o processador deve jogar fora os cálculos errados.e todo o trabalho e energia desperdiçados. O estado interno do processador também precisará ser restaurado para o estado que existia antes da ramificação incompreendida, com a despesa de tempo e energia adicionais.Para entender como esse projeto é complexo, imagine a dificuldade de prever corretamente os resultados de 15 ramos. Se o construtor do processador definir um limite de 10% de perdas, o processador deverá prever corretamente cada ramo com uma precisão de 99,3%. Não há muitos programas de ramificação de uso geral que possam ser previstos com tanta precisão.Para avaliar em que consiste esse trabalho desperdiçado, considere os dados na Fig. 4, mostrando a proporção de instruções que são executadas com eficiência, mas são desperdiçadas porque o processador previu incorretamente ramificações. Nos testes SPEC no Intel Core i7, uma média de 19% das instruções são desperdiçadas. No entanto, a quantidade de energia gasta é maior, uma vez que o processador deve usar energia adicional para restaurar o estado quando é previsto incorretamente.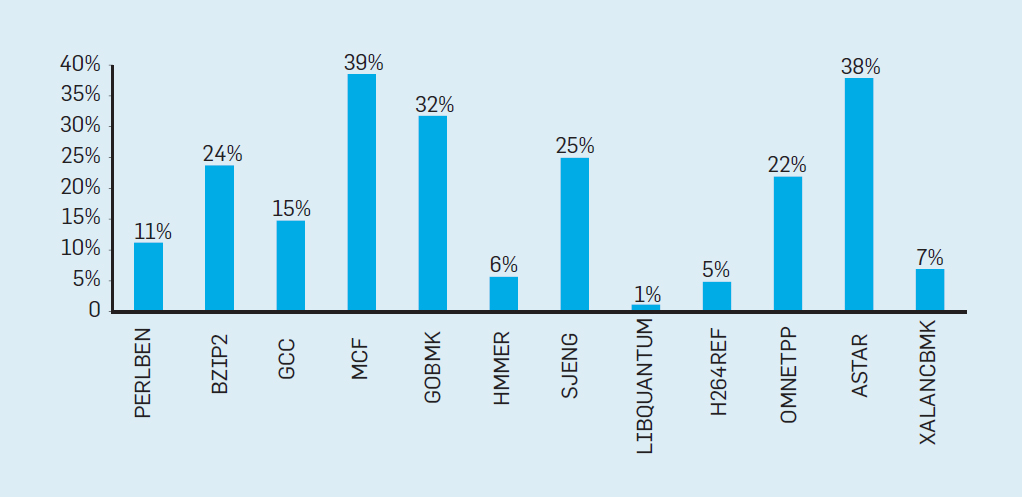 Fig. 4. Instruções desperdiçadas como uma porcentagem de todas as instruções executadas no Intel Core i7 para vários testes SPEC inteiros.Essasmedições levaram muitos a concluir que uma abordagem diferente deve ser buscada para obter melhor desempenho. Assim nasceu a era multicore.Nesse conceito, a responsabilidade de identificar a simultaneidade e decidir como usá-la é transferida para o programador e o sistema de linguagem. O Multicore não resolve o problema da computação com eficiência energética, que foi agravada no final do dimensionamento de Dennard. Cada núcleo ativo consome energia, independentemente de estar envolvido em cálculos eficientes. O principal obstáculo é uma observação antiga chamada lei de Amdahl. Ele diz que os benefícios da computação paralela são limitados pela fração da computação seqüencial. Para avaliar a importância dessa observação, considere a Figura 5. Ele mostra quanto mais rápido o aplicativo trabalha com 64 núcleos em comparação com um núcleo, assumindo uma proporção diferente de cálculos seqüenciais quando apenas um processador está ativo. Por exemplose 1% do tempo o cálculo é realizado seqüencialmente, a vantagem da configuração de 64 processadores é de apenas 35%. Infelizmente, o consumo de energia é proporcional a 64 processadores, portanto, aproximadamente 45% da energia é desperdiçada.
Fig. 4. Instruções desperdiçadas como uma porcentagem de todas as instruções executadas no Intel Core i7 para vários testes SPEC inteiros.Essasmedições levaram muitos a concluir que uma abordagem diferente deve ser buscada para obter melhor desempenho. Assim nasceu a era multicore.Nesse conceito, a responsabilidade de identificar a simultaneidade e decidir como usá-la é transferida para o programador e o sistema de linguagem. O Multicore não resolve o problema da computação com eficiência energética, que foi agravada no final do dimensionamento de Dennard. Cada núcleo ativo consome energia, independentemente de estar envolvido em cálculos eficientes. O principal obstáculo é uma observação antiga chamada lei de Amdahl. Ele diz que os benefícios da computação paralela são limitados pela fração da computação seqüencial. Para avaliar a importância dessa observação, considere a Figura 5. Ele mostra quanto mais rápido o aplicativo trabalha com 64 núcleos em comparação com um núcleo, assumindo uma proporção diferente de cálculos seqüenciais quando apenas um processador está ativo. Por exemplose 1% do tempo o cálculo é realizado seqüencialmente, a vantagem da configuração de 64 processadores é de apenas 35%. Infelizmente, o consumo de energia é proporcional a 64 processadores, portanto, aproximadamente 45% da energia é desperdiçada.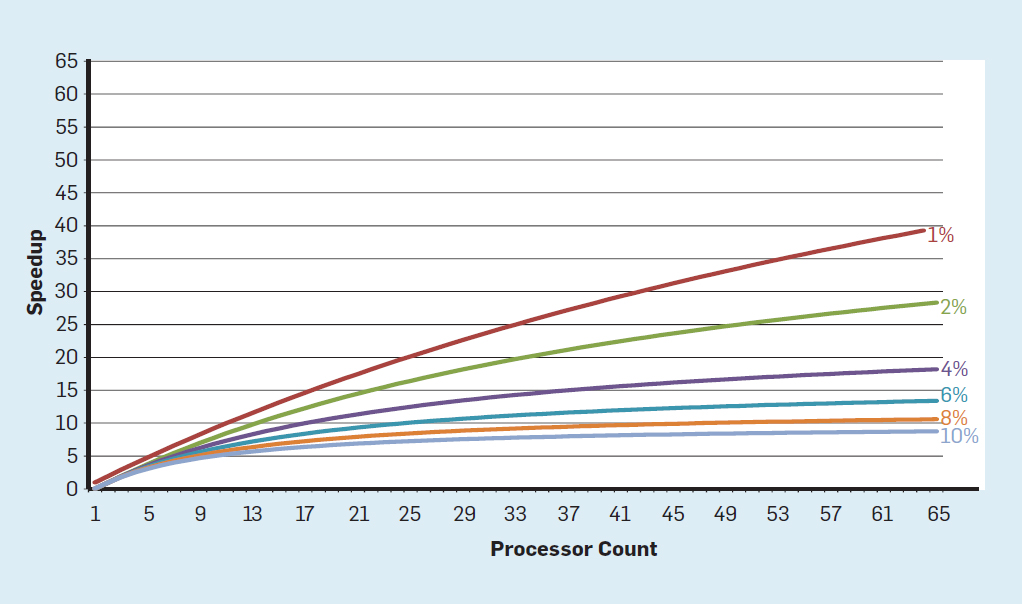 Fig. 5. O efeito da lei de Amdahl no aumento da velocidade, levando em consideração a proporção de medidas no modo seqüencial.É claro que os programas reais têm uma estrutura mais complexa. Existem fragmentos que permitem usar um número diferente de processadores a qualquer momento. No entanto, a necessidade de interagir periodicamente e sincronizá-los significa que a maioria dos aplicativos possui algumas partes que podem usar apenas parte dos processadores com eficiência. Embora a lei de Amdahl tenha mais de 50 anos, ela continua sendo um obstáculo difícil.Com o final da escala de Dennard, um aumento no número de núcleos no chip significava que a potência também aumentava quase na mesma taxa. Infelizmente, a voltagem fornecida ao processador deve ser removida como calor. Assim, os processadores com vários núcleos são limitados pela TDP (Thermal Output Power) ou pela quantidade média de energia que o chassi e o sistema de refrigeração podem remover. Embora alguns data centers sofisticados usem tecnologias de refrigeração mais avançadas, nenhum usuário deseja colocar um pequeno trocador de calor em cima da mesa ou carregar um radiador nas costas para resfriar o telefone móvel. O limite do TDP levou à era do silício escuro, quando os processadores diminuem a velocidade do relógio e desligam os núcleos ociosos para evitar superaquecimento. Outra maneira de considerar essa abordagem éque alguns microcircuitos podem redistribuir seu poder precioso de núcleos inativos para núcleos ativos.A era sem a escala de Dennard, juntamente com a redução da lei de Moore e da lei de Amdahl, significa que a ineficiência limita a melhoria da produtividade a apenas alguns por cento ao ano (veja a Figura 6).
Fig. 5. O efeito da lei de Amdahl no aumento da velocidade, levando em consideração a proporção de medidas no modo seqüencial.É claro que os programas reais têm uma estrutura mais complexa. Existem fragmentos que permitem usar um número diferente de processadores a qualquer momento. No entanto, a necessidade de interagir periodicamente e sincronizá-los significa que a maioria dos aplicativos possui algumas partes que podem usar apenas parte dos processadores com eficiência. Embora a lei de Amdahl tenha mais de 50 anos, ela continua sendo um obstáculo difícil.Com o final da escala de Dennard, um aumento no número de núcleos no chip significava que a potência também aumentava quase na mesma taxa. Infelizmente, a voltagem fornecida ao processador deve ser removida como calor. Assim, os processadores com vários núcleos são limitados pela TDP (Thermal Output Power) ou pela quantidade média de energia que o chassi e o sistema de refrigeração podem remover. Embora alguns data centers sofisticados usem tecnologias de refrigeração mais avançadas, nenhum usuário deseja colocar um pequeno trocador de calor em cima da mesa ou carregar um radiador nas costas para resfriar o telefone móvel. O limite do TDP levou à era do silício escuro, quando os processadores diminuem a velocidade do relógio e desligam os núcleos ociosos para evitar superaquecimento. Outra maneira de considerar essa abordagem éque alguns microcircuitos podem redistribuir seu poder precioso de núcleos inativos para núcleos ativos.A era sem a escala de Dennard, juntamente com a redução da lei de Moore e da lei de Amdahl, significa que a ineficiência limita a melhoria da produtividade a apenas alguns por cento ao ano (veja a Figura 6). Fig. 6. Crescimento do desempenho do computador por testes inteiros (SPECintCPU)Atingir taxas mais altas de melhoria de desempenho - como foi observado nas décadas de 80 e 90 - requer novas abordagens arquitetônicas que tiram vantagem dos circuitos integrados com muito mais eficiência. Voltaremos à discussão de abordagens potencialmente eficazes, mencionando outra séria desvantagem dos computadores modernos - a segurança.
Fig. 6. Crescimento do desempenho do computador por testes inteiros (SPECintCPU)Atingir taxas mais altas de melhoria de desempenho - como foi observado nas décadas de 80 e 90 - requer novas abordagens arquitetônicas que tiram vantagem dos circuitos integrados com muito mais eficiência. Voltaremos à discussão de abordagens potencialmente eficazes, mencionando outra séria desvantagem dos computadores modernos - a segurança.Segurança esquecida
Nos anos 70, os desenvolvedores de processadores garantiram diligentemente a segurança do computador com a ajuda de vários conceitos, desde anéis de proteção até funções especiais. Eles entendiam bem que a maioria dos erros estaria no software, mas acreditavam que o suporte à arquitetura poderia ajudar. Esses recursos geralmente não eram usados por sistemas operacionais que funcionavam em ambientes supostamente seguros (como computadores pessoais). Portanto, as funções associadas a despesas gerais significativas foram eliminadas. Na comunidade de software, muitos acreditavam que testes e métodos formais, como o uso de um microkernel, forneceriam mecanismos eficazes para a criação de software altamente seguro. Infelizmente, a escala de nossos sistemas de software comuns e a busca pelo desempenho fizeram com que esses métodos não pudessem acompanhar o desempenho. Como resultado, grandes sistemas de software ainda apresentam muitas falhas de segurança, e o efeito é amplificado devido à enorme e crescente quantidade de informações pessoais na Internet e ao uso da computação em nuvem, onde os usuários compartilham o mesmo equipamento físico com um possível invasor.
Embora os designers de processadores e outros possam não ter percebido a crescente importância da segurança imediatamente, eles começaram a incluir suporte de hardware para máquinas virtuais e criptografia. Infelizmente, a previsão de ramificação introduziu uma falha de segurança desconhecida, mas significativa, em muitos processadores. Em particular, as
vulnerabilidades Meltdown e Spectre exploram os recursos da microarquitetura, permitindo o vazamento de informações protegidas . Ambos usam os chamados ataques a canais de terceiros quando as informações vazam de acordo com a diferença de tempo gasto na tarefa. Em 2018, os pesquisadores mostraram
como usar uma das opções do Spectre para extrair informações pela rede sem baixar o código no processador de destino . Embora esse ataque, chamado NetSpectre, transfira informações lentamente, o próprio fato de permitir atacar qualquer máquina na mesma rede local (ou no mesmo cluster na nuvem) cria muitos novos vetores de ataque. Posteriormente, foram relatadas mais duas vulnerabilidades na arquitetura de máquinas virtuais (
1 ,
2 ). Um deles, chamado Foreshadow, permite que você penetre nos mecanismos de segurança Intel SGX projetados para proteger os dados mais valiosos (como chaves de criptografia). Novas vulnerabilidades são encontradas mensalmente.
Ataques em canais de terceiros não são novos, mas na maioria dos casos, os bugs de software eram a falha anterior. No Meltdown, Spectre e outros ataques, essa é uma falha na implementação do hardware. Há uma dificuldade fundamental em como os arquitetos de processadores determinam qual é a implementação correta do ISA, porque a definição padrão não diz nada sobre os efeitos de desempenho da execução de uma sequência de instruções, apenas o estado de execução arquitetural visível do ISA. Os arquitetos devem repensar sua definição da implementação correta do ISA para evitar essas falhas de segurança. Ao mesmo tempo, eles devem repensar a atenção que prestam à segurança do computador e como os arquitetos podem trabalhar com desenvolvedores de software para implementar sistemas mais seguros. Arquitetos (e todos os outros) não devem ter segurança de outra maneira que não seja uma necessidade primária.
Oportunidades futuras em arquitetura de computadores
“Temos oportunidades incríveis, disfarçadas de problemas insolúveis.” - John Gardner, 1965
As ineficiências inerentes aos processadores de uso geral, seja a tecnologia ILP ou os processadores com múltiplos núcleos, combinadas com a conclusão do dimensionamento de Dennard e a lei de Moore tornam improvável que arquitetos e desenvolvedores de processadores sejam capazes de manter um ritmo significativo na melhoria do desempenho dos processadores de uso geral. Dada a importância de melhorar a produtividade do software, devemos fazer a pergunta: que outras abordagens promissoras existem?
Existem duas possibilidades óbvias, bem como uma terceira criada pela combinação das duas. Primeiro, os métodos de desenvolvimento de software existentes fazem uso extensivo de linguagens de alto nível com digitação dinâmica. Infelizmente, essas linguagens são geralmente interpretadas e executadas de maneira extremamente ineficiente. Para ilustrar essa ineficiência, Leiserson e colegas
deram um pequeno exemplo: multiplicação de matrizes .
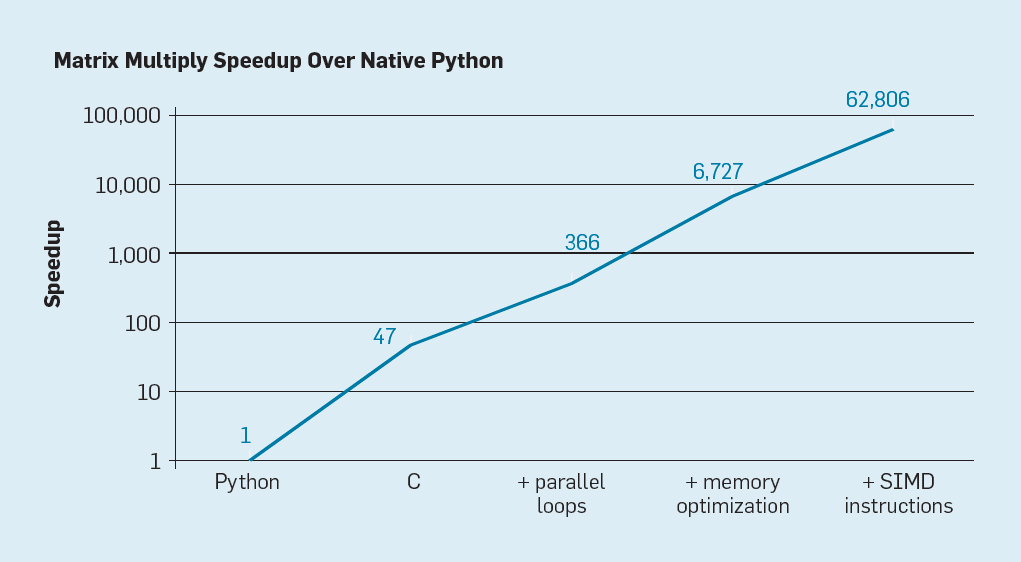 Fig. 7. Aceleração potencial da multiplicação de matrizes Python após quatro otimizações
Fig. 7. Aceleração potencial da multiplicação de matrizes Python após quatro otimizaçõesComo mostrado na fig. 7, simplesmente reescrever o código do Python para C melhora o desempenho em 47 vezes. O uso de loops paralelos em muitos núcleos fornece um fator adicional de cerca de 7. A otimização da estrutura de memória para o uso de caches fornece um fator de 20 e o último fator de 9 vem do uso de extensões de hardware para executar operações SIMD paralelas capazes de executar 16 instruções de 32 bits. Depois disso, a versão final, altamente otimizada, roda no processador multi-core da Intel 62.806 vezes mais rápido que a versão original do Python. Obviamente, este é um pequeno exemplo. Pode-se supor que os programadores usarão uma biblioteca otimizada. Embora a diferença de desempenho seja exagerada, provavelmente existem muitos programas que podem ser otimizados 100-1000 vezes.
Uma área interessante de pesquisa é a questão de saber se é possível preencher algumas lacunas de desempenho com a nova tecnologia de compilador, possivelmente com melhorias na arquitetura. Embora seja difícil traduzir e compilar com eficiência as linguagens de script de alto nível, como o Python, o retorno potencial é enorme. Mesmo uma pequena otimização pode levar ao fato de que os programas Python serão executados dezenas a centenas de vezes mais rápido. Este exemplo simples mostra quão grande é a diferença entre as linguagens modernas focadas no desempenho do programador e as abordagens tradicionais que enfatizam o desempenho.
Arquiteturas especializadas
Uma abordagem mais orientada a hardware é o design de arquiteturas adaptadas a uma área específica, onde elas demonstram eficiência significativa. Essas são arquiteturas específicas de domínio especializadas (arquiteturas específicas de domínio, DSAs). Geralmente, são processadores programáveis e completos, mas levam em consideração uma classe específica de tarefas. Nesse sentido, eles diferem dos circuitos integrados específicos da aplicação (ASICs), que geralmente são usados para a mesma função que o código que raramente muda. Os DSAs são freqüentemente chamados de aceleradores, pois aceleram alguns aplicativos em comparação com a execução de todo o aplicativo em uma CPU de uso geral. Além disso, os DSAs podem oferecer melhor desempenho porque são mais precisamente adaptados às necessidades do aplicativo. Exemplos de DSAs incluem processadores gráficos (GPUs), processadores de rede neural usados para aprendizado profundo e processadores para redes definidas por software (SDNs). Os DSAs alcançam desempenho superior e eficiência energética por quatro razões principais.
Primeiro, os DSAs usam uma forma mais eficiente de simultaneidade para uma área de assunto específica. Por exemplo, o SIMD (fluxo único de instruções, fluxo múltiplo de dados) é
mais eficiente que o MIMD (fluxo múltiplo de instruções, fluxo múltiplo de dados). Embora o SIMD seja menos flexível, é adequado para muitos DSAs. Processadores especializados também podem usar as abordagens ILP da VLIW em vez de mecanismos pouco especulativos. Como mencionado anteriormente, os
processadores VLIW são pouco adequados para códigos de uso geral , mas para áreas estreitas são muito mais eficientes porque os mecanismos de controle são mais simples. Em particular, os processadores de uso geral de ponta são excessivamente multi-pipelines, o que requer lógica de controle complexa para iniciar e concluir as instruções. Por outro lado, o VLIW realiza a análise e o planejamento necessários em tempo de compilação, o que pode funcionar bem para um programa claramente paralelo.
Segundo, os serviços DSA fazem melhor uso da hierarquia de memória. O acesso à memória se tornou muito mais caro que os cálculos aritméticos,
como observou Horowitz . Por exemplo, acessar um bloco em um cache de 32 KB requer cerca de 200 vezes mais energia do que adicionar números inteiros de 32 bits. Uma diferença tão grande faz com que otimizar o acesso à memória seja fundamental para alcançar alta eficiência energética. Os processadores de uso geral executam código no qual os acessos à memória geralmente exibem localidade espacial e temporal, mas, de outra forma, não são muito previsíveis em tempo de compilação. Portanto, para aumentar a taxa de transferência, as CPUs usam caches de vários níveis e ocultam o atraso em DRAMs relativamente lentas fora do chip. Esses caches de vários níveis geralmente consomem cerca de metade da energia do processador, mas evitam quase todas as chamadas para DRAM, o que leva cerca de 10 vezes mais energia do que o acesso ao cache de último nível.
Os caches têm duas falhas notáveis.
Quando os conjuntos de dados são muito grandes . Os caches simplesmente não funcionam bem quando os conjuntos de dados são muito grandes, possuem baixa localidade temporal ou espacial.
Quando caches funcionam bem . Quando os caches funcionam bem, a localidade é muito alta, ou seja, por definição, a maior parte do cache fica ociosa na maioria das vezes.
Em aplicativos em que os padrões de acesso à memória são bem definidos e compreensíveis no momento da compilação, o que é verdade para DSLs (típicas de domínio específico), programadores e compiladores podem otimizar o uso da memória melhor do que os caches alocados dinamicamente. Portanto, os DSAs normalmente usam uma hierarquia de memória móvel explicitamente controlada pelo software, semelhante à maneira como os processadores de vetores funcionam. Nos aplicativos correspondentes, o controle “manual” da memória do usuário permite gastar muito menos energia que o cache padrão.
Em terceiro lugar, o DSA pode reduzir a precisão dos cálculos se não for necessária alta precisão. As CPUs de uso geral geralmente suportam cálculos de números inteiros de 32 e 64 bits, bem como dados de ponto flutuante (FP). Para muitos aplicativos de aprendizado de máquina e gráficos, essa é uma precisão redundante. Por exemplo, em redes neurais profundas, o cálculo geralmente usa números de 4, 8 ou 16 bits, melhorando a taxa de transferência de dados e o poder de processamento. Da mesma forma, os cálculos de ponto flutuante são úteis para o treinamento de redes neurais, mas 32 bits, e geralmente 16 bits, são suficientes.
Por fim, os DSAs se beneficiam de programas escritos em linguagens específicas de domínio que permitem mais simultaneidade, melhoram a estrutura, a apresentação do acesso à memória e simplificam a sobreposição eficiente de aplicativos em um processador especializado.
Idiomas orientados ao assunto
Os DSAs exigem que operações de nível superior sejam adaptadas à arquitetura do processador, mas é muito difícil fazer isso em uma linguagem de uso geral, como Python, Java, C ou Fortran. Os idiomas específicos do domínio (DSLs) ajudam nisso e permitem que você programe efetivamente os DSAs. Por exemplo, as DSLs podem tornar explícitas as operações de vetores explícitos, matriz densa e matriz esparsa, permitindo que o compilador DSL mapeie de maneira eficiente as operações para o processador. Entre as linguagens específicas do domínio estão o Matlab, uma linguagem para trabalhar com matrizes, o TensorFlow para programar redes neurais, P4 para programar redes definidas por software e Halide para processar imagens com transformações de alto nível.
O problema do DSL é como manter independência arquitetural suficiente para que o software nele possa ser portado para várias arquiteturas, enquanto obtém alta eficiência ao comparar o software com um DSA básico. Por exemplo,
um sistema XLA converte o código do
Tensorflow em sistemas heterogêneos com GPUs da Nvidia ou processadores de tensão (TPUs). Equilibrar a portabilidade entre DSAs enquanto mantém a eficiência é uma tarefa de pesquisa interessante para desenvolvedores de linguagem, compiladores e os próprios DSAs.
Exemplo de DSA: TPU v1
Como exemplo do DSA, considere o Google TPU v1, projetado para acelerar a operação de uma rede neural (
1 ,
2 ). Esse TPU é produzido desde 2015 e muitos aplicativos estão sendo executados nele: de consultas de pesquisa a tradução de texto e reconhecimento de imagem no AlphaGo e AlphaZero, programas DeepMind para jogar go e xadrez. O objetivo era aumentar a produtividade e a eficiência energética de redes neurais profundas em 10 vezes.
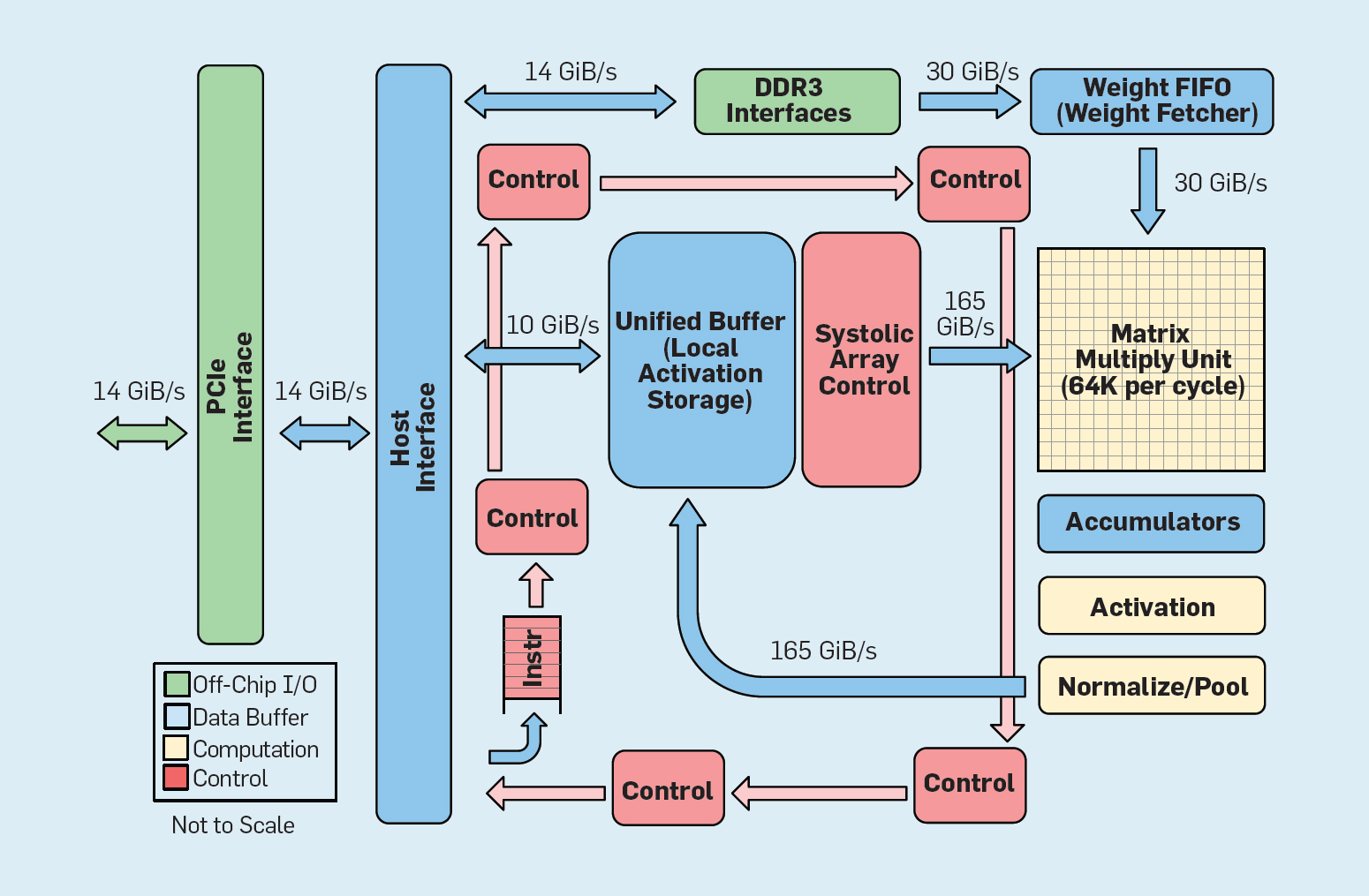 Fig. 8. Unidade funcional de processamento do tensor do Google da organização (TPU v1)
Fig. 8. Unidade funcional de processamento do tensor do Google da organização (TPU v1)Como mostra a Figura 8, a organização de uma TPU é radicalmente diferente de um processador de uso geral. A principal unidade de computação é a unidade da matriz, a
estrutura das matrizes sistólicas , que cada ciclo produz 256 × 256 com acumulação múltipla. A combinação de precisão de 8 bits, uma estrutura sistólica altamente eficiente, controle SIMD e a alocação de uma parte significativa do chip para esta função ajudam a executar cerca de 100 vezes mais operações de multiplicação de acumulação por ciclo do que um núcleo de CPU de uso geral. Em vez de caches, o TPU usa 24 MB de memória local, que é aproximadamente o dobro dos caches de CPU de uso geral de 2015 com o mesmo TDP. Finalmente, a memória de ativação neuronal e a memória de equilíbrio de rede neural (incluindo a estrutura FIFO que armazena os pesos) são conectadas através de canais de alta velocidade controlados pelo usuário. O desempenho médio ponderado da TPU para seis problemas típicos da saída lógica de redes neurais nos datacenters do Google é 29 vezes maior que o dos processadores de uso geral. Como as TPUs requerem menos da metade da energia, sua eficiência energética para essa carga de trabalho é mais de 80 vezes a dos processadores de uso geral.
Sumário
Examinamos duas abordagens diferentes para melhorar o desempenho do programa, aumentando a eficiência do uso de tecnologias de hardware. Primeiro, aumentando a produtividade das linguagens modernas de alto nível que geralmente são interpretadas. Em segundo lugar, criando arquiteturas para áreas específicas, que melhoram significativamente o desempenho e a eficiência em comparação com os processadores de uso geral. Os idiomas específicos do domínio são outro exemplo de como melhorar a interface de hardware e software que permite inovações arquiteturais como o DSA. Para obter um sucesso significativo usando essas abordagens, será necessária uma equipe de projeto verticalmente versada em aplicativos, linguagens orientadas ao assunto e tecnologias de compilação relacionadas, arquitetura de computadores e tecnologia básica de implementação. A necessidade de integração vertical e tomada de decisões de design em diferentes níveis de abstração era típica na maior parte dos trabalhos iniciais no campo da tecnologia da computação antes que o setor se tornasse estruturado horizontalmente. Nesta nova era, a integração vertical tornou-se mais importante. Serão dadas vantagens às equipes que encontrarem e aceitarem compromissos e otimizações complexos.
Essa oportunidade já levou a um aumento na inovação arquitetônica, atraindo muitas filosofias arquitetônicas concorrentes:
GPU As GPUs da Nvidia
usam vários núcleos, cada um com grandes arquivos de registro, vários fluxos de hardware e caches.
TPU As
TPUs do Google
contam com grandes matrizes sistólicas bidimensionais e memória programável no chip.
FPGA A Microsoft Corporation em seus datacenters
implementa matrizes de portas programáveis pelo usuário (FPGAs), usadas em aplicativos de rede neural.
CPU A Intel oferece processadores com muitos núcleos, um grande cache multinível e instruções SIMD unidimensionais, de maneira semelhante ao FPGA da Microsoft, e o
novo neuroprocessador está mais próximo do TPU do que da CPU .
Além desses grandes players,
dezenas de startups implementam suas próprias idéias . Para atender à crescente demanda, os designers estão combinando centenas e milhares de chips para criar supercomputadores de redes neurais.
Essa avalanche de arquiteturas de redes neurais indica que chegou um momento interessante na história da arquitetura de computadores. Em 2019, é difícil prever quais dessas muitas áreas vencerão (se alguém vencer), mas o mercado definitivamente determinará o resultado, assim como resolveu o debate arquitetônico do passado.
Arquitetura aberta
Seguindo o exemplo de software de código aberto bem-sucedido, o ISA aberto representa uma oportunidade alternativa na arquitetura de computadores. Eles são necessários para criar um tipo de "Linux para processadores", para que a comunidade possa criar kernels de código aberto, além de empresas individuais que possuem kernels proprietários. Se muitas organizações projetam processadores usando o mesmo ISA, mais concorrência pode levar a inovações ainda mais rápidas. O objetivo é fornecer arquitetura para processadores que custam de alguns centavos a US $ 100.
O primeiro exemplo é o RISC-V (RISC Five), a
quinta arquitetura do RISC desenvolvida na Universidade da Califórnia em Berkeley . Ela é apoiada por uma comunidade liderada pela
Fundação RISC-V .
A arquitetura aberta permite que a evolução do ISA ocorra aos olhos do público, com o envolvimento de especialistas até que uma decisão final seja tomada. Uma vantagem adicional de um fundo aberto é que é improvável que o ISA se expanda principalmente por razões de marketing, porque às vezes essa é a única explicação para a expansão de seus próprios conjuntos de instruções.O RISC-V é um conjunto de instruções modular. Uma pequena base de instruções lança uma pilha completa de software de código aberto, seguida por extensões padrão adicionais que os designers podem ativar ou desativar, dependendo de suas necessidades. Esse banco de dados contém versões de 32 e 64 bits dos endereços. O RISC-V pode crescer apenas através de extensões opcionais; a pilha de software ainda funcionará bem, mesmo que os arquitetos não aceitem novas extensões. As arquiteturas proprietárias geralmente requerem compatibilidade ascendente no nível binário: isso significa que se a empresa do processador adicionar um novo recurso, todos os futuros processadores também deverão incluí-lo. O RISC-V não, aqui todos os aprimoramentos são opcionais e podem ser removidos se o aplicativo não precisar deles.Aqui estão as extensões padrão no momento, com as primeiras letras do nome completo:- M. Multiplicação / divisão de um número inteiro.
- A. Operações de memória atômica.
- F / d. Operações de ponto flutuante de precisão simples / dupla.
- C. Instruções compactadas.
A terceira característica do RISC-V é a simplicidade do ISA. Embora esse indicador não seja quantificável, aqui estão duas comparações com a arquitetura do ARMv8, desenvolvida em paralelo pelo ARM:- Menos instruções . O RISC-V tem muito menos instruções. Existem 50 no banco de dados e são surpreendentemente semelhantes em número e caráter ao RISC-I original . O restante das extensões padrão (M, A, F e D) adicionam 53 instruções, e C adiciona 34 mais, portanto o número total é 137. Para comparação, o ARMv8 possui mais de 500 instruções.
- . RISC-V : , ARMv8 14.
A simplicidade simplifica o design do processador e a verificação da correção. Como o RISC-V se concentra em tudo, desde datacenters a dispositivos IoT, a validação do projeto pode ser uma parte significativa dos custos de desenvolvimento.Quarto, o RISC-V é um projeto simples após 25 anos, onde os arquitetos aprendem com os erros de seus antecessores. Diferentemente da arquitetura RISC de primeira geração, evita microarquitetura ou funções que dependem de tecnologia (como ramificações e downloads adiados) ou inovações (como janelas de registro), que foram suplantadas pelos avanços do compilador.Por fim, o RISC-V suporta DSA, reservando um amplo espaço de código de operação para aceleradores personalizados.Além do RISC-V, a Nvidia também anunciou (em 2017)Uma arquitetura livre e aberta , ela chama de Nvidia Deep Learning Accelerator (NVDLA). É um DSA escalável e personalizável para inferência no aprendizado de máquina. Os parâmetros de configuração incluem o tipo de dados (int8, int16 ou fp16) e o tamanho da matriz de multiplicação bidimensional. A escala do substrato de silício varia de 0,5 mm² a 3 mm² e o consumo de energia é de 20 mW a 300 mW. ISA, pilha de software e implementação estão abertos.Arquiteturas abertas e simples combinam bem com segurança. Primeiro, os especialistas em segurança não acreditam em segurança pela obscuridade, portanto as implementações de código aberto são atraentes e as implementações de código aberto exigem uma arquitetura aberta. Igualmente importante é o aumento no número de pessoas e organizações que podem inovar no campo das arquiteturas seguras. As arquiteturas proprietárias limitam a participação dos funcionários, mas as arquiteturas abertas permitem que as melhores mentes da academia e da indústria ajudem na segurança. Por fim, a simplicidade do RISC-V simplifica a verificação de suas implementações. Além disso, arquiteturas abertas, implementações e pilhas de software, além da flexibilidade dos FPGAs, significam que os arquitetos podem implantar e avaliar novas soluções on-line com ciclos de lançamento semanais e não anuais. Embora os FPGAs sejam 10 vezes mais lentos que os chips personalizados,mas o desempenho deles é suficiente para trabalhar on-line e exibir inovações de segurança na frente de invasores reais para verificação. Esperamos que as arquiteturas abertas sejam exemplos de design colaborativo de hardware e software por arquitetos e especialistas em segurança.Desenvolvimento de hardware flexível
O Manifesto Flexível de Desenvolvimento de Software (2001) Beck e outros revolucionaram o desenvolvimento de software, eliminando os problemas de um sistema em cascata tradicional com base no planejamento e documentação. Pequenas equipes de programadores criam rapidamente protótipos funcionais, mas incompletos, e recebem feedback do cliente antes de iniciar a próxima iteração. A versão Scrum do Agile reúne equipes de cinco a dez programadores que correm por duas a quatro semanas por iteração.Tendo emprestado a idéia do desenvolvimento de software novamente, é possível organizar o desenvolvimento de hardware flexível. A boa notícia é que as ferramentas modernas de desenho eletrônico auxiliado por computador (ECAD) aumentaram o nível de abstração, permitindo um desenvolvimento flexível. Esse nível mais alto de abstração também aumenta o nível de reutilização do trabalho entre diferentes designs.Sprints de quatro semanas parecem implausíveis para os processadores, considerando os meses entre a criação do projeto e a produção de chips. Na fig.
A Figura 9 mostra como um método flexível pode funcionar modificando um protótipo em um nível apropriado .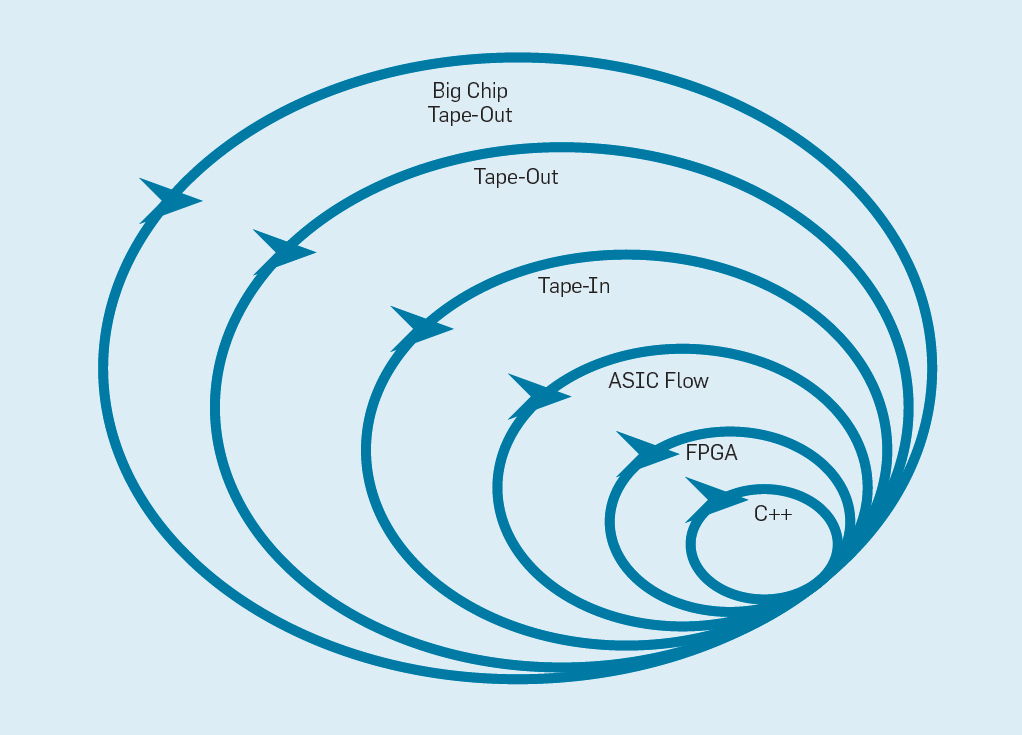 Fig. 9. Metodologia de desenvolvimento de equipamentos flexíveisO nível mais interno é um simulador de software, o local mais fácil e rápido para fazer alterações. O próximo nível são os chips FPGA, que podem funcionar centenas de vezes mais rápido que um simulador de software detalhado. Os FPGAs podem trabalhar com sistemas operacionais e benchmarks completos, como a Standard Performance Evaluation Corporation (SPEC), que permite uma avaliação muito mais precisa dos protótipos. O Amazon Web Services oferece FPGAs na nuvem, para que os arquitetos possam usar os FPGAs sem precisar primeiro comprar equipamentos e montar um laboratório. O próximo nível usa as ferramentas do ECAD para gerar um circuito de chip e documentar o tamanho e o consumo de energia. Mesmo após o trabalho das ferramentas, é necessário seguir algumas etapas manuais para refinar os resultados antes de enviar o novo processador para produção.Os desenvolvedores de processadores chamam esse próximo nível.fita adesiva . Esses quatro primeiros níveis suportam sprints de quatro semanas.Para fins de pesquisa, poderíamos parar no nível quatro, pois as estimativas de área, energia e desempenho são muito precisas. Mas é como um corredor que correu uma maratona e parou 5 metros antes da finalização, porque seu tempo de finalização já está claro. Apesar da difícil preparação para a maratona, ele sentirá falta da emoção e do prazer de realmente cruzar a linha de chegada. Uma das vantagens dos engenheiros de hardware sobre os engenheiros de software é que eles criam coisas físicas. Obter chips da fábrica: medir, executar programas reais, mostrá-los a amigos e familiares é uma grande alegria para o designer.Muitos pesquisadores acreditam que deveriam parar porque a fabricação de chips é muito acessível. Mas se o design é pequeno, é surpreendentemente barato. Os engenheiros podem encomendar 100 microchips de 1 mm² por apenas US $ 14.000. A 28 nm, um chip de 1 mm² contém milhões de transistores: isso é suficiente para o processador RISC-V e o acelerador NVLDA. O nível mais externo é caro se o designer pretende criar um chip grande, mas muitas novas idéias podem ser demonstradas em chips pequenos.
Fig. 9. Metodologia de desenvolvimento de equipamentos flexíveisO nível mais interno é um simulador de software, o local mais fácil e rápido para fazer alterações. O próximo nível são os chips FPGA, que podem funcionar centenas de vezes mais rápido que um simulador de software detalhado. Os FPGAs podem trabalhar com sistemas operacionais e benchmarks completos, como a Standard Performance Evaluation Corporation (SPEC), que permite uma avaliação muito mais precisa dos protótipos. O Amazon Web Services oferece FPGAs na nuvem, para que os arquitetos possam usar os FPGAs sem precisar primeiro comprar equipamentos e montar um laboratório. O próximo nível usa as ferramentas do ECAD para gerar um circuito de chip e documentar o tamanho e o consumo de energia. Mesmo após o trabalho das ferramentas, é necessário seguir algumas etapas manuais para refinar os resultados antes de enviar o novo processador para produção.Os desenvolvedores de processadores chamam esse próximo nível.fita adesiva . Esses quatro primeiros níveis suportam sprints de quatro semanas.Para fins de pesquisa, poderíamos parar no nível quatro, pois as estimativas de área, energia e desempenho são muito precisas. Mas é como um corredor que correu uma maratona e parou 5 metros antes da finalização, porque seu tempo de finalização já está claro. Apesar da difícil preparação para a maratona, ele sentirá falta da emoção e do prazer de realmente cruzar a linha de chegada. Uma das vantagens dos engenheiros de hardware sobre os engenheiros de software é que eles criam coisas físicas. Obter chips da fábrica: medir, executar programas reais, mostrá-los a amigos e familiares é uma grande alegria para o designer.Muitos pesquisadores acreditam que deveriam parar porque a fabricação de chips é muito acessível. Mas se o design é pequeno, é surpreendentemente barato. Os engenheiros podem encomendar 100 microchips de 1 mm² por apenas US $ 14.000. A 28 nm, um chip de 1 mm² contém milhões de transistores: isso é suficiente para o processador RISC-V e o acelerador NVLDA. O nível mais externo é caro se o designer pretende criar um chip grande, mas muitas novas idéias podem ser demonstradas em chips pequenos.Conclusão
“A hora mais escura é antes do amanhecer” - Thomas Fuller, 1650Para se beneficiar das lições da história, os criadores dos processadores devem entender que muito pode ser adotado pela indústria de software, que o aumento do nível de abstração da interface de hardware / software oferece oportunidades para inovação e que o mercado em em última análise, determinar o vencedor. O iAPX-432 e o Itanium demonstram como os investimentos em arquitetura não podem fazer nada, enquanto o S / 360, 8086 e ARM oferecem altos resultados há décadas, sem fim à vista.A conclusão da lei de Moore e a escala de Dennard, bem como a desaceleração no desempenho dos microprocessadores padrão, não são problemas que devem ser resolvidos, mas um dado que, como você sabe, oferece oportunidades interessantes. Linguagens e arquiteturas orientadas para o assunto de alto nível, livres de cadeias de conjuntos de instruções proprietárias, juntamente com a demanda do público por maior segurança, dará início a uma nova era de ouro para a arquitetura de computadores. Nos ecossistemas de código aberto, os chips projetados artificialmente demonstrarão conquistas convincentes e, assim, acelerarão a implementação comercial. A filosofia do processador de propósito geral nesses chips provavelmente é RISC, que resistiu ao teste do tempo. Espere a mesma inovação acelerada que você fez na era de ouro passada,mas desta vez em termos de custo, energia e segurança, não apenas desempenho.Na próxima década, ocorrerá uma explosão cambriana de novas arquiteturas de computadores, significando momentos emocionantes para os arquitetos de computadores na academia e na indústria.