Muitas organizações, especialmente as financeiras, precisam lidar com vários padrões de segurança - por exemplo, o PCI DSS. Tais certificações requerem criptografia de dados. Criptografia de dados transparente no disco A Criptografia de dados transparente é implementada em muitos DBMSs industriais.
O Apache Ignite é usado em bancos, portanto, foi decidido implementar o TDE nele.
Descreverei como desenvolvemos a TDE através da comunidade, publicamente, através dos processos Apachev.
Abaixo está uma versão em texto do relatório:
Vou tentar falar sobre arquitetura, sobre a complexidade do desenvolvimento, como ele realmente se parece em código aberto.
O que foi feito e o que resta a ser feito?
Atualmente implementado Apache Ignite TDE. Fase 1.
Inclui os recursos básicos do trabalho com caches criptografados:
- Gerenciamento de chaves
- Criando caches criptografados
- Salvando todos os dados do cache em disco no formato criptografado
Na Fase 2, está planejado permitir a possibilidade de rotação (alteração) da chave mestra.
Na fase 3, a capacidade de girar chaves de cache.
Terminologia
- Criptografia de dados transparente - criptografia de dados transparente (para o usuário) ao salvar em disco. No caso de Ignite, criptografia de cache, porque Ignite é sobre caches.
- Ignite cache - cache de valor-chave no Apache Ignite. Os dados do cache podem ser salvos no disco
- Páginas - páginas de dados. No Ignite, todos os dados são paginados. As páginas são gravadas no disco e devem ser criptografadas.
- WAL - escreve o log antecipado. Todas as alterações de dados no Ignite são salvas lá, todas as ações que realizamos para todos os caches.
- Keystore - keystore java padrão, que é gerado pelo keytool Javascript. Ele funciona e é certificado em todos os lugares, nós o usamos.
- Chave mestra - chave mestra. Utilizando-o, as chaves das tabelas são criptografadas, as chaves de criptografia de cache. Armazenado no keystore java.
- Chaves de cache - chaves com as quais os dados são realmente criptografados. Juntamente com a chave mestra, é obtida uma estrutura de dois níveis. A chave mestra é armazenada separadamente do cache e dos dados mestres - por motivos de segurança, separação de direitos de acesso, etc.
Arquitetura
Tudo é implementado de acordo com o seguinte esquema:
- Todos os dados do cache são criptografados usando o novo SPI de criptografia.
- Por padrão, o AES é usado - um algoritmo de criptografia industrial.
- A chave mestra é armazenada em um arquivo JKS - um arquivo java padrão para chaves.
Bancos e outras organizações usam seus próprios algoritmos de criptografia: GOST e outros. É claro que demos a oportunidade de reduzir nosso SPI de criptografia - a implementação de criptografia de que um usuário específico precisa.
Esquema de trabalho
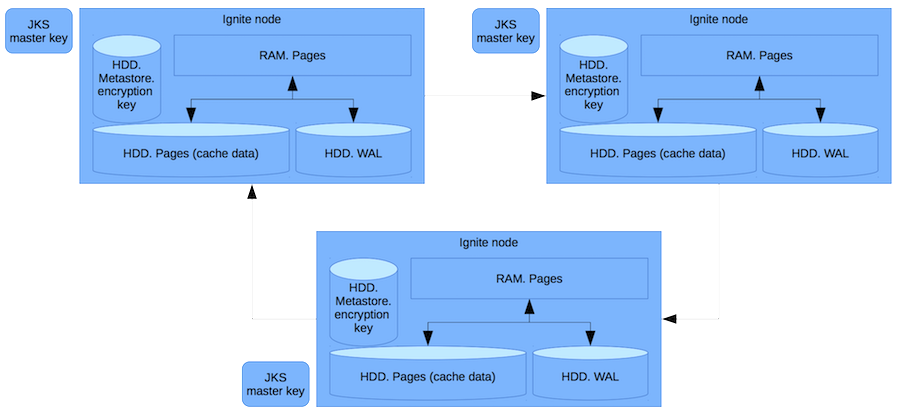
Portanto, temos RAM - memória de acesso aleatório com páginas contendo dados puros. Usar RAM implica que não estamos protegidos contra um hacker que obteve acesso root e despejou toda a memória. Nós nos protegemos do administrador que pega o disco rígido e o vende no mercado Tushino (ou onde dados semelhantes estão sendo vendidos no momento).
Além das páginas com um cache, os dados também são armazenados no log de gravação antecipada, que grava no disco o delta dos registros alterados na transação. O metastore armazena chaves de criptografia de cache. E em um arquivo separado - uma chave mestra.
Sempre que uma chave para o cache é criada, antes de gravar ou transferir para a rede, criptografamos essa chave usando uma chave mestra. Para que ninguém possa obter a chave de cache após receber dados do Ignite. Somente roubando a chave mestra e os dados você pode acessá-los. Isso é improvável, pois o acesso a esses arquivos requer vários direitos.
O algoritmo de ações é o seguinte:
- No início do nó, subtraia a chave mestra de jks.
- No início dos nós, leia o meta store e descriptografe as chaves de cache.
- Quando associar nós em um cluster:
- verifique os hashes da chave mestra.
- verifique as chaves para caches compartilhados.
- salve as chaves para novos caches.
- Ao criar um cache dinamicamente, geramos uma chave e a salvamos na meta-loja.
- Ao ler / escrever uma página, nós a descriptografamos / criptografamos.
- Cada entrada WAL para o cache criptografado também é criptografada.
Agora com mais detalhes:
No início do nó, temos um retorno de chamada que inicia nosso EncryptionSPI. De acordo com os parâmetros, subtraímos a chave mestra do arquivo jks.
Em seguida, quando o metastore estiver pronto, obteremos as chaves de criptografia armazenadas. Nesse caso, já temos uma chave mestra, para que possamos descriptografar as chaves e obter acesso aos dados do cache.
Separadamente, há um processo muito interessante - como unimos um novo nó a um cluster. Já temos um sistema distribuído que consiste em vários nós. Como garantir que o novo nó esteja configurado corretamente e que não seja um invasor?
Realizamos estas ações:
- Quando um novo nó chega, ele envia um hash da chave mestra. Parece que ele corresponde ao existente.
- Em seguida, verificamos as chaves para caches compartilhados. Do nó, vem o identificador de cache e a chave de cache criptografada. Nós os verificamos para garantir que todos os dados em todos os nós sejam criptografados com a mesma chave. Se não for assim, simplesmente não temos o direito de permitir que o nó entre no cluster, caso contrário, ele trafegará por chaves e dados.
- Se houver novas chaves e caches no novo nó, salve-os para uso futuro.
- Ao criar um cache dinamicamente, uma função de geração de chave é fornecida. Nós o geramos, salvamos na meta store e podemos continuar executando as operações descritas.
A segunda parte é uma superestrutura sobre as operações de E / S. As páginas são gravadas no arquivo de partição. Nosso suplemento analisa o cache da página, criptografa-os de acordo e os salva.
O mesmo vale para o WAL. Há um serializador que serializa objetos de registro WAL. E se o registro for para caches criptografados, devemos criptografá-lo e somente salvá-lo em disco.
Dificuldades de desenvolvimento
Dificuldades comuns a todos os projetos de código aberto mais ou menos complexos:
- Primeiro, você precisa entender completamente o dispositivo Ignite. Por que, o que e como foi feito lá, como e em que lugares para anexar seus manipuladores.
- É necessário fornecer compatibilidade com versões anteriores. Isso pode ser bastante difícil, não óbvio. Ao desenvolver um produto usado por outras pessoas, é necessário considerar que os usuários desejam ser atualizados sem problemas. A compatibilidade com versões anteriores é correta e boa. Quando você faz uma melhoria tão grande como a TDE, altera as regras para salvar em disco e criptografa alguma coisa. E a compatibilidade com versões anteriores deve ser trabalhada.
- Outro ponto não óbvio está relacionado à distribuição do nosso sistema. Quando clientes diferentes tentam criar o mesmo cache, você precisa concordar com a chave de criptografia, porque, por padrão, serão gerados dois diferentes. Nós resolvemos esse problema. Não vou me aprofundar em mais detalhes - a solução merece um post separado. Agora temos a garantia de usar uma chave.
- A próxima coisa importante levou a grandes melhorias, quando parecia que tudo estava pronto (uma história familiar?) :). A criptografia possui sobrecarga. Temos um vetor init - zero dados aleatórios que são usados no algoritmo AES. Eles são armazenados de forma aberta e, com a ajuda deles, aumentamos a entropia: os mesmos dados serão criptografados de maneira diferente em diferentes sessões de criptografia. Grosso modo, mesmo se tivermos dois Ivan Petrovs com o mesmo sobrenome, cada vez que criptografamos, receberemos dados criptografados diferentes. Isso reduz a chance de hackers.
A criptografia ocorre em blocos de 16 bytes e, se os dados não estiverem alinhados por 16 bytes, adicionamos informações de preenchimento - a quantidade de dados que realmente criptografamos. Em um disco, você precisa escrever uma página com múltiplos de 2 Kb. Estes são os requisitos de desempenho: devemos usar o buffer de disco. Se não escrevermos 2 Kb (não 4 ou 8, dependendo do buffer do disco), obteremos imediatamente um grande desempenho de queda.
Como resolvemos o problema? Eu tive que rastrear o PageIO, na RAM, e cortar 16 bytes de cada página, que seriam criptografados quando gravados no disco. Nestes 16 bytes, escrevemos o vetor init.
- Outra dificuldade é não quebrar nada. Isso é comum quando você vem e faz algumas alterações. Na realidade, não é tão simples quanto parece.
- No MVP, foram produzidas 6 mil linhas. É difícil revisar, e poucas pessoas querem fazer isso, principalmente de especialistas que já não têm tempo. Temos várias partes - API pública, parte principal, gerenciadores de SPI, armazenamento persistente de páginas, gerenciadores de WAL. Alterações em vários subsistemas exigem que elas sejam revisadas por pessoas diferentes. E isso também impõe dificuldades adicionais. Especialmente quando você trabalha em uma comunidade onde todas as pessoas estão ocupadas com suas tarefas. No entanto, tudo deu certo para nós.
O que acontecerá no TDE.Fase 2 e 3
A fase 1. agora está implementada.Você, como desenvolvedor, pode ajudar na fase 2. Os desafios futuros são interessantes. O PCI DSS, como outros padrões, requer recursos adicionais do sistema de criptografia. Nosso sistema deve poder alterar a chave mestra. Por exemplo, se ele foi comprometido ou a hora acabou de chegar de acordo com a política de segurança. Agora o Ignite não sabe como. Mas em versões futuras, ensinaremos a TDE a alterar a chave mestra.
A mesma coisa com a capacidade de alterar a chave de cache sem parar o cluster e trabalhar com dados. Se o cache tiver vida longa e, ao mesmo tempo, armazenar alguns dados - financeiros, médicos - o Ignite poderá alterar a chave de criptografia do cache e criptografar tudo rapidamente. Vamos resolver esse problema na terceira fase.
Total: como implementar um grande recurso em um projeto de código aberto?
Para resumir. Eles serão relevantes para qualquer fonte aberta. Eu participei do Kafka e de outros projetos - em todos os lugares a história é a mesma.
- Comece com pequenas tarefas. Nunca tente resolver um grande problema imediatamente. É necessário entender o que está acontecendo, como está acontecendo, como está sendo realizado. Quem o ajudará. E em geral - de que lado abordar este projeto.
- Entenda o projeto. Normalmente, todos os desenvolvedores - pelo menos eu - vêm e dizem: tudo precisa ser reescrito. Tudo estava ruim diante de mim, e agora vou reescrevê-lo - e tudo ficará bem. É aconselhável adiar essas declarações, descobrir o que exatamente é ruim e se precisa ser alterado.
- Discuta se são necessárias melhorias. Eu tive casos em que cheguei às várias comunidades com experiência, por exemplo, no Spark. Ele me disse, mas a comunidade não estava interessada por algum motivo. De qualquer forma, isso acontece. Você precisa dessa revisão, mas a comunidade diz: não, não estamos interessados, não vamos nos fundir e ajudar.
- Faça um design. Existem projetos de código aberto nos quais isso é obrigatório. Você não pode começar a codificar sem um design acordado pelo comitê e por pessoas experientes. No Ignite, isso não é formalmente verdade, mas, em geral, é uma parte importante do desenvolvimento. É necessário fazer uma descrição em inglês ou russo competente, dependendo do projeto. Para que o texto possa ser lido e ficou claro o que exatamente você fará.
- Discuta a API pública. O principal argumento: se houver uma API pública bonita e compreensível que seja fácil de usar, o design estará correto. Essas coisas geralmente são adjacentes uma à outra.
Outras dicas mais óbvias que não são tão fáceis de seguir:
- Implemente o recurso sem quebrar nada. Faça os testes.
- Peça e aguarde (isso é mais difícil) uma revisão dos profissionais certos, dos membros certos da comunidade.
- Faça benchmarks, descubra se você tem uma queda no desempenho. Isso é especialmente importante ao finalizar alguns subsistemas críticos.
- Aguarde a mesclagem, faça alguns exemplos e documentação.
Obrigado pela leitura!