
Quando me apresento e digo o que nossa startup faz, o interlocutor imediatamente levanta a questão: você trabalhou no Facebook antes ou o seu desenvolvimento foi criado sob a influência do Facebook? Muitos estão cientes dos esforços do Facebook para manter seu gráfico social, porque a empresa publicou
vários artigos sobre a infraestrutura deste gráfico, que foi cuidadosamente construída.
O Google falou sobre
o gráfico de conhecimento dela , mas nada sobre a infraestrutura interna. No entanto, a empresa também possui subsistemas especializados. De fato, muita atenção está sendo dada ao gráfico do conhecimento. Pessoalmente, coloquei pelo menos duas das minhas promoções neste cavalo - e comecei a trabalhar em um novo gráfico em 2010.
O Google precisava criar a infraestrutura não apenas para servir relacionamentos complexos no Gráfico de conhecimento, mas também para oferecer suporte a todos os blocos temáticos do
OneBox nos resultados de pesquisa que têm acesso a dados estruturados. A infraestrutura é necessária para 1) contornar a qualidade dos fatos com 2) uma largura de banda alta o suficiente e 3) um atraso suficientemente baixo para conseguir obter uma boa parte das consultas de pesquisa na web. Acontece que nenhum sistema ou banco de dados disponível pode executar as três ações.
Agora, quando eu lhe disse por que a infraestrutura é necessária, no restante do artigo, falarei sobre minha experiência na construção de tais sistemas, inclusive para o
Knowledge Graph e o
OneBox .
Como eu sei disso?
Vou me apresentar brevemente. Trabalhei no Google de 2006 a 2013. Primeiro como estagiário, depois como engenheiro de software na infraestrutura de pesquisa na web. O Google
adquiriu a Metaweb em 2010, e minha equipe acabou de lançar o
Caffeine . Eu queria fazer outra coisa - e comecei a trabalhar com os caras da Metaweb (em San Francisco), passando um tempo viajando entre San Francisco e Mountain View. Eu queria descobrir como usar o gráfico de conhecimento para melhorar minha pesquisa na web.
Existem projetos desse tipo no Google antes de mim. Vale ressaltar que o projeto chamado
Squared foi criado em um escritório de Nova York e houve algumas conversas sobre cartões de conhecimento. Houve esforços esporádicos de indivíduos / equipes pequenas, mas naquela época não havia uma cadeia de equipes estabelecida, o que acabou me forçando a deixar o Google. Mas voltaremos a isso mais tarde ...
História da Metaweb
Como já mencionado, o Google adquiriu a Metaweb em 2010. A Metaweb construiu um gráfico de conhecimento de alta qualidade usando vários métodos, incluindo rastreamento e análise da Wikipedia, bem como um sistema de edição no estilo wiki de crowdsourcing usando o
Freebase . Tudo isso funcionou com base no próprio banco de dados de gráficos do Graphd - o daemon de gráficos (agora
publicado no GitHub).
O Graphd tinha algumas propriedades bastante típicas. Como daemon, funcionou em um servidor, armazenou todos os dados na memória e pode emitir um site inteiro do Freebase. Após a compra, o Google definiu uma das tarefas para continuar trabalhando com o Freebase.
O Google construiu um império com hardware padrão e software distribuído. Um DBMS do servidor nunca seria capaz de exibir resultados de rastreamento, indexação e pesquisa. Primeiro, criei o SSTable, depois o Bigtable, que é dimensionado horizontalmente para centenas ou milhares de máquinas que compartilham petabytes de dados. As máquinas são alocadas pelo Borg (o
K8 veio daqui), elas se comunicam via Stubby (o gRPC veio daqui) com a resolução de endereços IP através do serviço de nomes Borg (BNC dentro do K8) e armazenam dados no Google File System (
GFS , você pode dizer o Hadoop FS).
Os processos podem morrer, as máquinas podem quebrar, mas o sistema como um todo é indestrutível e continuará a zumbir.Graphd entrou em tal ambiente. A idéia de um banco de dados que serve um site inteiro em um servidor é estranha ao Google (inclusive a mim). Em particular, o Graphd precisava de 64 GB ou mais de memória para rodar. Se lhe parece que isso é um pouco, lembre-se: este é 2010. A maioria dos servidores do Google está equipada com no máximo 32 GB. De fato, o Google teve que comprar máquinas especiais com RAM suficiente para servir o Graphd em sua forma atual.
Substituição Graphd
O brainstorming começou sobre como mover os dados do Graphd ou reescrever o sistema para funcionar de maneira distribuída. Mas, veja bem, os gráficos são complicados. Este não é um banco de dados de valores-chave para você, onde você pode simplesmente pegar um dado, movê-lo para outro servidor e emiti-lo quando solicitar uma chave. Os gráficos executam junções e soluções alternativas eficientes que exigem que o software funcione de uma maneira específica.
Uma idéia era usar um projeto chamado MindMeld (IIRC). Supunha-se que a memória de outro servidor estivesse disponível muito mais rapidamente através de equipamentos de rede. Deveria ter sido mais rápido que os RPCs regulares, rápido o suficiente para pseudo-replicar o acesso direto à memória exigido pelo banco de dados na memória. Mas a ideia não foi longe demais.
Outra idéia que realmente se tornou um projeto foi criar um sistema de serviço gráfico verdadeiramente distribuído. Algo que não só pode substituir o Graphd for Freebase, mas também realmente funciona na produção.
Ela se chamava Dgraph - um gráfico distribuído, invertido do Graphd (daemon-gráfico).Se você estiver interessado, então sim. Minha startup, Dgraph Labs, a empresa e o projeto de código aberto Dgraph são nomeados após esse projeto no Google (nota: Dgraph é uma marca comercial da Dgraph Labs; até onde eu sei, o Google não libera projetos com nomes que correspondam aos internos).
Em quase todo o restante do texto, quando menciono Dgraph, quero dizer o projeto interno do Google, e não o projeto de código aberto que criamos. Mas mais sobre
isso mais tarde.
A história da Cerebro: o mecanismo do conhecimento
Criando inadvertidamente infraestrutura para gráficosEmbora eu geralmente soubesse que o Dgraph estava tentando substituir o Graphd, meu objetivo era criar algo para melhorar a pesquisa na web. Na Metaweb, conheci um engenheiro de pesquisa da DH que criou o
Cubed .
Como mencionei, um grupo heterogêneo de engenheiros da divisão de Nova York desenvolveu o Google
Squared . Mas o sistema DH estava
muito melhor. Comecei a pensar em como implementá-lo no Google. O Google tinha peças de quebra-cabeça que eu poderia usar facilmente.
A primeira parte do quebra-cabeça é o mecanismo de busca. Essa é uma maneira de determinar com precisão quais palavras estão relacionadas entre si. Por exemplo, quando você vê uma frase como [tom hanks movies], pode dizer que [tom] e [hanks] estão relacionados. Da mesma forma, a partir de [san francisco weather], vemos uma conexão entre [san] e [francisco]. Essas são coisas óbvias para as pessoas, mas não tão óbvias para os carros.
A segunda parte do quebra-cabeça é entender a gramática. Quando na consulta [livros de autores franceses], a máquina pode interpretar isso como [livros] de [autores franceses], ou seja, livros daqueles autores franceses. Mas ela também pode interpretar isso como [livros em francês] de [autores], ou seja, livros em francês por qualquer autor. Usei o etiquetador POS (
Part-Of-Speech ) da Universidade de Stanford para analisar melhor a gramática e construir a árvore.
A terceira parte do quebra-cabeça é entender as entidades. [francês] pode significar muito. Pode ser um país (região), nacionalidade (relacionada ao povo francês), culinária (relacionada à comida) ou idioma. Em seguida, apliquei outro sistema para obter uma lista de entidades às quais uma palavra ou frase pode corresponder.
A quarta parte do quebra-cabeça era entender o relacionamento entre entidades. Quando se sabe como conectar palavras a frases, em que ordem as frases devem ser executadas, ou seja, sua gramática e a quais entidades elas podem corresponder, é necessário encontrar o relacionamento entre essas entidades para criar interpretações de máquina. Por exemplo, executamos a consulta [livros de autores franceses] e o POS diz que são [livros] de [autores franceses]. Temos várias entidades para [francês] e várias para [autores]: o algoritmo deve determinar como eles estão relacionados. Por exemplo, eles podem ser relacionados por local de nascimento, ou seja, autores que nasceram na França (embora possam escrever em inglês). Ou podem ser autores que são cidadãos franceses. Autores que sabem falar ou escrever francês (mas podem não estar relacionados à França como país) ou autores que simplesmente amam a culinária francesa.
Sistema de gráfico de índice de pesquisa
Para determinar se há uma conexão entre os objetos e como eles estão conectados, você precisa de um sistema de gráficos. O Graphd nunca chegaria ao nível do Google, mas você poderia usar a própria pesquisa. Os dados do gráfico de conhecimento são armazenados no formato triplos triplos, ou seja, cada fato é representado por três partes: assunto (entidade), predicado (relação) e objeto (outra entidade). As solicitações são como
[SP] → [O] ou
[PO] → [S] e, algumas vezes,
[SO] → [P] .
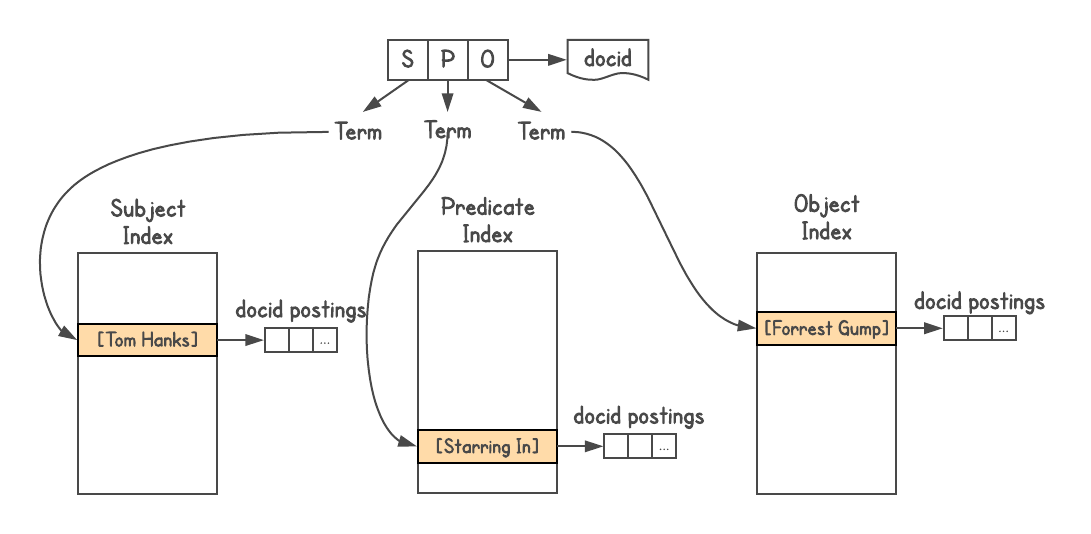 Usei o índice de pesquisa do Google
Usei o índice de pesquisa do Google , atribuí um docid a cada triplo e construí três índices, um para S, P e O. Além disso, o índice é aninhado, então adicionei informações sobre o tipo de cada entidade (ou seja, ator, livro, pessoa e etc.)
Eu criei esse sistema, embora tenha visto um problema com a profundidade das junções (que é explicada abaixo) e não é adequado para consultas complexas. Na verdade, quando alguém da equipe da Metaweb me pediu para publicar um sistema para colegas, eu recusei.Para determinar o relacionamento, você pode ver quantos resultados cada consulta fornece. Por exemplo, quantos resultados [francês] e [autor] dão? Tomamos esses resultados e vemos como eles estão relacionados a [livros], etc. Assim, muitas interpretações de máquina da consulta apareceram. Por exemplo, a consulta [tom hanks movies] gera uma variedade de interpretações, como [filmes dirigidos por tom hanks], [filmes estrelados por tom hanks], [filmes produzidos por tom hanks], mas rejeita automaticamente interpretações como [filmes chamados tom hanks].
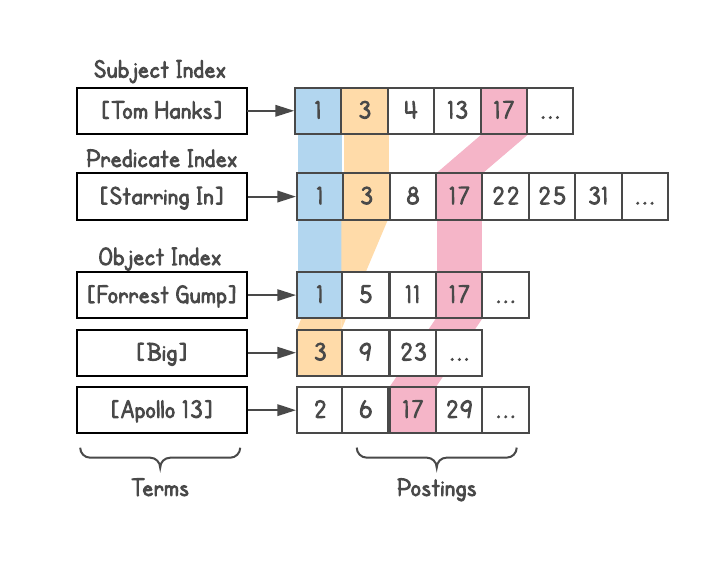
Cada interpretação gera uma lista de resultados - entidades válidas no gráfico - e também retorna seus tipos (presentes em anexos). Isso provou ser uma função extremamente poderosa, porque a compreensão do tipo de resultados abriu possibilidades como filtragem, classificação ou expansão adicional. Você pode classificar os filmes com o ano de lançamento, a duração do filme (curta, longa), o idioma, os prêmios recebidos etc.
O projeto parecia tão inteligente que nós (a DH também estava parcialmente envolvida como especialista no gráfico do conhecimento) denominamos Cerebro, em homenagem ao dispositivo com o mesmo nome do filme
“X-Men” .
O Cerebro frequentemente revelava fatos muito interessantes que não estavam originalmente na consulta de pesquisa. Por exemplo, a pedido dos [presidentes dos EUA], a Cerebro perceberá que os presidentes são pessoas, e as pessoas têm crescimento. Isso nos permite classificar os presidentes por crescimento e mostrar que Abraham Lincoln é o mais alto presidente dos Estados Unidos. Além disso, as pessoas podem ser filtradas por nacionalidade. Nesse caso, a América e o Reino Unido aparecem na lista, porque os Estados Unidos tinham um presidente britânico, chamado George Washington. (Aviso: os resultados são baseados no estado do gráfico de conhecimento no momento do experimento; não posso garantir sua exatidão).
Links azuis versus conhecimento
O Cerebro conseguiu realmente entender as solicitações dos usuários. Tendo recebido dados para o gráfico inteiro, poderíamos gerar interpretações de máquina da consulta, gerar uma lista de resultados e entender muito desses resultados para um estudo mais aprofundado do gráfico. Foi explicado acima: assim que o sistema entende que está lidando com filmes, pessoas ou livros, etc., certos filtros e tipos podem ser ativados. Você pode até percorrer os nós e mostrar informações relacionadas: de [presidentes dos EUA] a [escolas que frequentaram] ou [filhos que tiveram pai]. Aqui estão algumas outras perguntas que o próprio sistema gerou: [mulheres afro-americanas políticas], [atores de bollywood casados com políticos], [filhos de nós presidentes], [filmes estrelados por tom hanks lançados nos anos 90]
A DH demonstrou essa oportunidade de passar de uma lista para outra em outro projeto chamado
Parallax .
O Cerebro mostrou um resultado muito impressionante, e o gerenciamento da Metaweb o apoiou. Mesmo em termos de infraestrutura, ele se mostrou eficiente e funcional. Eu chamei de
mecanismo de conhecimento (como um mecanismo de pesquisa). Mas no Google, ninguém abordou especificamente esse tópico. Ela era de pouco interesse para o meu gerente, eles me aconselharam a conversar com uma pessoa e depois com outra e, como resultado, tive a chance de demonstrar o sistema a um gerente de pesquisa muito alto.
A resposta não era a que eu estava esperando . Para demonstrar os resultados do mecanismo de conhecimento de [livros de autores franceses], ele lançou uma pesquisa no Google, mostrou dez linhas com links azuis e disse que o Google poderia fazer o mesmo. Além disso, eles não querem receber tráfego de sites porque ficam com raiva.
Se você acha que ele está certo, pense sobre isso: quando o Google faz uma pesquisa na Internet, ele realmente não entende a solicitação. O sistema procura as palavras certas na posição correta, levando em consideração o peso da página e assim por diante. Este é um sistema muito complexo, mas não entende a consulta nem os resultados. O próprio usuário faz todo o trabalho: ler, analisar, extrair as informações necessárias dos resultados e pesquisas adicionais, adicionando uma lista completa de resultados, etc.
Por exemplo, para [livros de autores franceses] uma pessoa primeiro tenta encontrar uma lista exaustiva, embora uma página com essa lista possa não ser encontrada. Em seguida, classifique esses livros por anos de publicação ou filtre pelos editores e assim por diante - tudo isso exige que uma pessoa processe uma grande quantidade de informações, várias pesquisas e processe os resultados. O Cerebro é capaz de reduzir esses esforços e tornar a interação do usuário simples e sem falhas.
Mas então não havia um entendimento completo da importância do gráfico de conhecimento. O manual não tinha certeza de sua utilidade ou de como relacioná-lo à pesquisa.
Essa nova abordagem do conhecimento não é fácil para a organização que alcançou um sucesso tão significativo ao fornecer aos usuários links para páginas da web.Ao longo do ano, lutei com um mal-entendido dos gerentes e, eventualmente, desisti. Um gerente do escritório de Xangai se virou para mim e entreguei o projeto a ele em junho de 2011. Ele colocou uma equipe de 15 engenheiros. Passei uma semana em Xangai, transmitindo aos engenheiros tudo o que eu criei e aprendi. DH também esteve envolvido nesse negócio e liderou a equipe por um longo tempo.
Problema de profundidade de junção
O sistema de gráficos Cerebro teve um problema com a profundidade da união. A junção é realizada quando o resultado de uma consulta inicial é necessário para concluir uma consulta posterior. Uma união típica inclui alguns
SELECT , isto é, um filtro em certos resultados de um conjunto de dados universal e, em seguida, esses resultados são usados para filtrar por outra parte do conjunto de dados. Vou explicar com um exemplo.
Digamos que você queira conhecer [pessoas em SF que comem sushi]. Todas as pessoas recebem alguns dados, incluindo quem mora em qual cidade e que tipo de comida eles comem.
A consulta acima é uma associação de nível único. Se o aplicativo acessar o banco de dados, ele fará uma solicitação para a primeira etapa. Depois, faça algumas consultas (uma para cada resultado) para descobrir o que cada pessoa come, escolhendo apenas aqueles que comem sushi.
O segundo passo sofre com o problema de fan-out. Se o primeiro passo der um milhão de resultados (a população de São Francisco), o segundo passo deve ser dado a todos, solicitando seus hábitos alimentares e aplicando um filtro.

Os engenheiros de sistemas distribuídos geralmente resolvem esse problema por
difusão , ou seja, por distribuição onipresente. Eles acumulam os resultados correspondentes, fazendo uma solicitação para cada servidor no cluster. Isso fornece uma junção, mas causa problemas com a latência da solicitação.
A transmissão não funciona bem em um sistema distribuído. Esse problema é melhor explicado por
Jeff Dean, do Google, em seu discurso "Atingindo uma resposta rápida em grandes serviços online" (
vídeos ,
slides ). O atraso total é sempre maior que o atraso do componente mais lento.
Um pequeno brilho nos computadores individuais causa atrasos, e a inclusão de muitos computadores na consulta aumenta drasticamente a probabilidade de atrasos.Considere um servidor com um atraso de mais de 1 ms em 50% dos casos e mais de 1 s em 1% dos casos. Se a solicitação for enviada para apenas um desses servidores, apenas 1% das respostas excederão um segundo. Mas se a solicitação for enviada para centenas desses servidores, 63% das respostas excederão um segundo.
Assim, a transmissão de uma solicitação aumenta muito o atraso. Agora pense, e se você precisar de duas, três ou mais associações? É muito lento para ser executado em tempo real.
O problema da implantação de ventiladores quando a transmissão de solicitação é inerente à maioria dos bancos de dados não nativos de gráficos, incluindo o
gráfico Janus , o
Twitter FlockDB e o
Facebook TAO .
Associações distribuídas são um problema complexo. Os bancos de dados de gráficos nativos permitem evitar esse problema, armazenando um conjunto de dados universal em um único servidor (banco de dados independente) e executando todas as junções sem acessar outros servidores. Por exemplo, o
Neo4j faz isso.
Dgraph: uniões com profundidade arbitrária
Após concluir o trabalho no Cerebro e ter experiência na construção de um sistema de gerenciamento de gráficos, participei do projeto Dgraph, tornando-me um dos três gerentes de projetos técnicos. Aplicamos conceitos inovadores que resolveram o problema da profundidade da união.
Em particular, o Dgraph separa os dados do gráfico para que cada junção possa ser realizada completamente por uma máquina. Retornando ao
subject-predicate-object (SPO), cada instância Dgraph contém todos os assuntos e objetos correspondentes a cada predicado nesta instância. Vários predicados são armazenados em uma instância, cada um sendo completamente armazenado.
Isso nos permitiu atender solicitações com uma profundidade arbitrária de associações , eliminando o problema de implantação de ventiladores durante a transmissão. Por exemplo, a consulta [pessoas no SF que comem sushi] gerará no
máximo duas chamadas de rede no banco de dados, independentemente do tamanho do cluster. O primeiro desafio encontrará todas as pessoas que moram em São Francisco. O segundo pedido enviará esta lista para cruzar com todas as pessoas que comem sushi. Em seguida, você pode adicionar restrições ou ramais adicionais, cada etapa ainda prevê não mais que uma chamada de rede.

Isso cria o problema de predicados muito grandes no mesmo servidor, mas pode ser resolvido dividindo-os ainda mais entre duas ou mais instâncias à medida que o tamanho aumenta. Na pior das hipóteses, um predicado será dividido em todo o cluster. Mas isso acontecerá apenas em uma situação fantástica, quando todos os dados corresponderem a apenas um predicado. Em outros casos, essa abordagem pode reduzir significativamente o atraso de solicitações em sistemas reais.
Sharding não foi a única inovação em Dgraph. Todos os objetos receberam identificadores inteiros atribuídos, eles foram classificados e salvos na forma de uma lista (lista de lançamentos) para cruzar rapidamente essas listas posteriormente. Isso permite que você filtre rapidamente durante a mesclagem, encontre links comuns etc. etc. As idéias dos mecanismos de pesquisa do Google também são úteis aqui.
Combinando todos os blocos OneBox através do Plasma
O dgraph do Google não era um banco de dados . Este foi um dos subsistemas, que também respondeu às atualizações. Então ela precisava de indexação. Eu tenho uma vasta experiência trabalhando com sistemas de indexação incremental em tempo real executando sob
cafeína .
Iniciei um projeto para unificar todo o OneBox nesse sistema de indexação de gráficos, incluindo previsão do tempo, horários de voos, eventos e assim por diante. Você pode não conhecer o termo OneBox, mas definitivamente o viu - é uma janela separada que aparece quando determinados tipos de consultas são executados, nos quais o Google retorna informações mais ricas. Para ver o OneBox em ação, tente [
clima em sf ].
Anteriormente, cada OneBox trabalhava em um back-end autônomo e era suportado por diferentes grupos de desenvolvimento.
Havia um rico conjunto de dados estruturados, mas as unidades OneBox não trocavam dados entre si. Em primeiro lugar, back-end diferentes aumentaram os custos de mão-de-obra muitas vezes. Em segundo lugar, a falta de compartilhamento de informações limitava a variedade de solicitações às quais o Google poderia responder.
Por exemplo, [eventos em SF] podem mostrar eventos e [clima em SF] pode mostrar o tempo. Mas se [os eventos em SF] entendessem que estava chuvoso agora, você poderia filtrar ou classificar eventos por tipo “dentro de casa” ou “ao ar livre” (
talvez seja melhor ir ao cinema em vez de futebol sob chuva forte) )
Com a ajuda da equipe da Metaweb, começamos a converter todos esses dados para o formato SPO e indexá-los em um sistema. Chamei-o de
Plasma, um mecanismo de indexação de gráficos em tempo real para servir o Dgraph.
Gerenciamento do Leapfrog
Como o Cerebro, o projeto Plasma recebeu poucos recursos, mas continuou a ganhar impulso. No final, quando a gerência percebeu que os blocos OneBox eram inevitavelmente parte de nosso projeto, decidiu imediatamente colocar as
“pessoas certas” para gerenciar o sistema gráfico. No auge do jogo político, três líderes foram substituídos, cada um deles com zero experiência em trabalhar com gráficos.
Durante esse salto do Dgraph, os gerentes de projeto da
Spanner chamaram o Dgraph de
um sistema
muito complexo . Para referência, o Spanner é um banco de dados SQL distribuído mundialmente que precisa de seu próprio relógio GPS para garantir consistência global.
A ironia disso ainda está soprando meu teto.Dgraph foi cancelado, o plasma sobreviveu. E, à frente do projeto, eles colocaram uma nova equipe com um novo líder, com uma hierarquia clara e se reportando ao CEO. A nova equipe - com um entendimento insuficiente dos gráficos e problemas relacionados - decidiu criar um subsistema de infraestrutura com base no índice de pesquisa do Google existente (como fiz no Cerebro). Sugeri usar o sistema que já fiz para o Cerebro, mas ele foi rejeitado. Modifiquei o Plasma para rastrear e expandir cada nó de conhecimento em vários níveis, para que o sistema possa visualizá-lo como um documento da web. Eles chamaram esse sistema de TS (
abreviação ).
Isso significava que o novo subsistema não seria capaz de realizar associações profundas. Novamente, essa é uma maldição que vejo em muitas empresas, porque os engenheiros começam com a idéia errada de que "os gráficos são um problema simples que pode ser resolvido simplesmente construindo uma camada sobre outro sistema".
Alguns meses depois, em maio de 2013, deixei o Google depois de trabalhar no Dgraph / Plasma por cerca de dois anos.
Posfácio
- Alguns anos depois, a seção “Infraestrutura de pesquisa na Internet” foi renomeada para “Infraestrutura de pesquisa na Internet e gráfico de conhecimento”, e o líder a quem uma vez mostrei à Cerebro dirigiu a direção “Gráfico de conhecimento”, informando sobre como eles pretendem substituir os sistemas simples. links de conhecimento azuis para responder às perguntas do usuário diretamente o mais rápido possível.
- Quando a equipe de Xangai que trabalhava na Cerebro estava perto de colocá-lo em produção, o projeto foi retirado deles e entregue à divisão de Nova York. No final, foi lançado como Knowledge Strip. Se você estiver procurando por [ filmes de tom hanks ], verá no topo. Ele melhorou um pouco desde o primeiro lançamento, mas ainda não suporta o nível de filtragem e classificação estabelecido no Cerebro.
- Todos os três gerentes técnicos que trabalharam no Dgraph (inclusive eu) acabaram saindo do Google. Até onde eu sei, o resto está trabalhando na Microsoft e no LinkedIn.
- Consegui receber duas promoções no Google e deveria receber uma terceira quando saí da empresa como engenheiro de software sênior (Senior Software Engineer).
- A julgar por alguns rumores fragmentários, a versão atual do TS está realmente muito próxima do design do sistema de gráficos Cerebro, e cada sujeito, predicado e objeto tem um índice. Portanto, ela ainda sofre com o problema da profundidade da unificação.
- Desde então, o plasma foi reescrito e renomeado, mas continua a funcionar como um sistema de indexação de gráficos em tempo real para o TS. Juntos, eles continuam postando e processando todos os dados estruturados no Google, incluindo o Gráfico de conhecimento.
- A incapacidade do Google de fazer uniões profundas é visível em muitos lugares. Por exemplo, ainda não vemos a troca de dados entre os blocos OneBox: [cidades com maior quantidade de chuva na Ásia] não fornece uma lista de cidades, embora todos os dados estejam na coluna de conhecimento (em vez disso, a página da web é citada nos resultados da pesquisa); [eventos em SF] não podem ser filtrados pelo clima; Os resultados [presidentes dos EUA] não são classificados, filtrados ou expandidos por outros fatos: seus filhos ou as escolas onde estudaram. Acredito que essa foi uma das razões para a descontinuação do suporte do Freebase .
Dgraph: Phoenix Bird
Dois anos depois de deixar o Google, decidi
desenvolver o Dgraph . Em outras empresas, vejo a mesma indecisão em relação aos gráficos que no Google. Havia muitas soluções inacabadas no espaço gráfico, em particular, muitas soluções personalizadas montadas às pressas sobre bancos de dados relacionais ou NoSQL, ou como um dos muitos recursos de bancos de dados de vários modelos. Se havia uma solução nativa, ela sofria de problemas de escalabilidade.
Nada do que vi tinha uma história coerente com um design produtivo e escalável.
Criar um banco de dados de gráfico escalável horizontalmente com junções de baixa latência e profundidade arbitrária é uma tarefa extremamente difícil , e eu queria ter certeza de que construímos o Dgraph corretamente.
A equipe da Dgraph passou os últimos três anos não apenas estudando minha própria experiência, mas também investindo muitos de seus esforços no design - criando um banco de dados de gráficos que não possui análogos no mercado. Assim, as empresas têm a oportunidade de usar uma solução confiável, escalável e produtiva em vez de outra solução semi-acabada.