A detecção de ataques faz parte da segurança da informação há décadas. As primeiras implementações conhecidas do sistema de detecção de intrusão (IDS) datam do início dos anos 80.
Atualmente, existe todo um setor de detecção de ataques. Existem vários tipos de produtos - como IDS, IPS, WAF e soluções de firewall - a maioria deles oferece detecção de ataques baseada em regras. A idéia de usar algum tipo de detecção estatística de anomalia para identificar ataques na produção não parece tão realista quanto costumava ser. Mas essa suposição é justificada?
Detecção de anomalias em aplicativos Web
Os primeiros firewalls criados para detectar ataques a aplicativos da Web apareceram no mercado no início dos anos 90. As técnicas de ataque e os mecanismos de proteção evoluíram drasticamente desde então, com os atacantes correndo para dar um passo à frente.
A maioria dos firewalls de aplicativos da Web (WAFs) atuais tenta detectar ataques de maneira semelhante, com um mecanismo baseado em regras incorporado em um proxy reverso de algum tipo. O exemplo mais destacado é mod_security, um módulo WAF para o servidor da web Apache, criado em 2002. A detecção baseada em regras tem algumas desvantagens: por exemplo, falha em detectar novos ataques (dias zero), mesmo que esses mesmos ataques pode ser facilmente detectado por um especialista humano. Esse fato não é surpreendente, uma vez que o cérebro humano funciona de maneira muito diferente de um conjunto de expressões regulares.
Da perspectiva de um WAF, os ataques podem ser divididos em sequenciais (séries temporais) e aqueles que consistem em uma única solicitação ou resposta HTTP. Nossa pesquisa se concentrou na detecção do último tipo de ataque, que inclui:
- Injeção de SQL
- Script entre sites
- Injeção de Entidade Externa XML
- Percurso de caminho
- Comando do SO
- Injeção de objetos
Mas primeiro vamos nos perguntar: como um humano faria isso?
O que um ser humano faria ao ver uma única solicitação
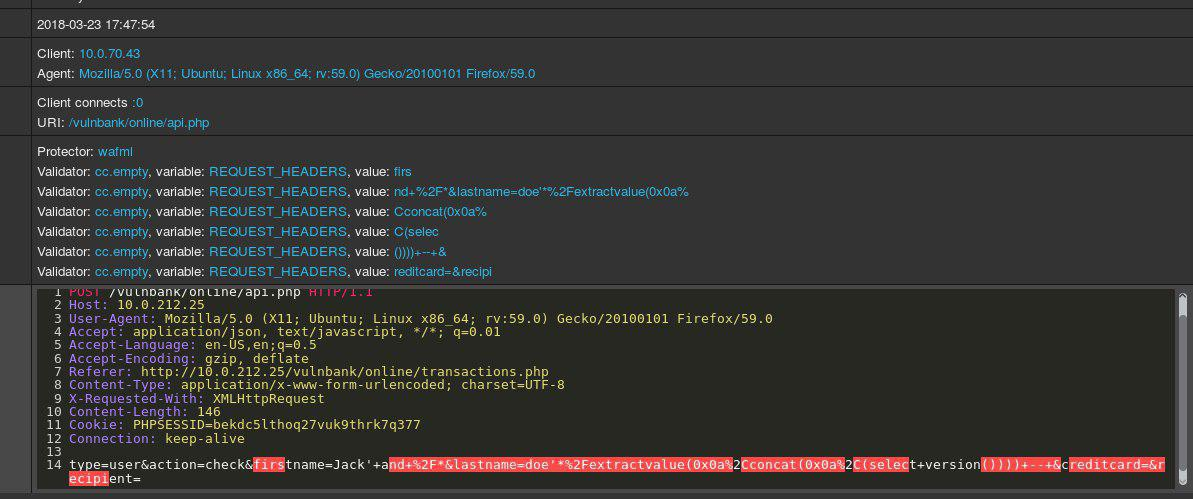
Dê uma olhada em uma amostra de solicitação HTTP regular para algum aplicativo:
Se você tivesse que detectar solicitações maliciosas enviadas a um aplicativo, provavelmente desejaria observar solicitações benignas por um tempo. Depois de examinar solicitações para vários pontos de extremidade de execução de aplicativos, você teria uma idéia geral de como as solicitações seguras são estruturadas e o que elas contêm.
Agora você é apresentado com a seguinte solicitação:

Você imediatamente intui que algo está errado. Leva mais tempo para entender o que exatamente e, assim que você localizar a parte exata da solicitação que é anômala, comece a pensar em que tipo de ataque é. Essencialmente, nosso objetivo é fazer com que nossa IA de detecção de ataques se aproxime do problema de uma maneira que se assemelhe a esse raciocínio humano.
Para complicar nossa tarefa, um certo tráfego, mesmo que pareça malicioso à primeira vista, pode ser normal para um site específico.
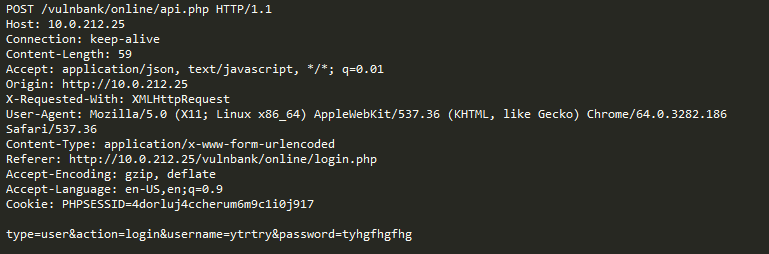
Por exemplo, vejamos a seguinte solicitação:
É uma anomalia? Na verdade, essa solicitação é benigna: é uma solicitação típica relacionada à publicação de erros no rastreador de erros do Jira.
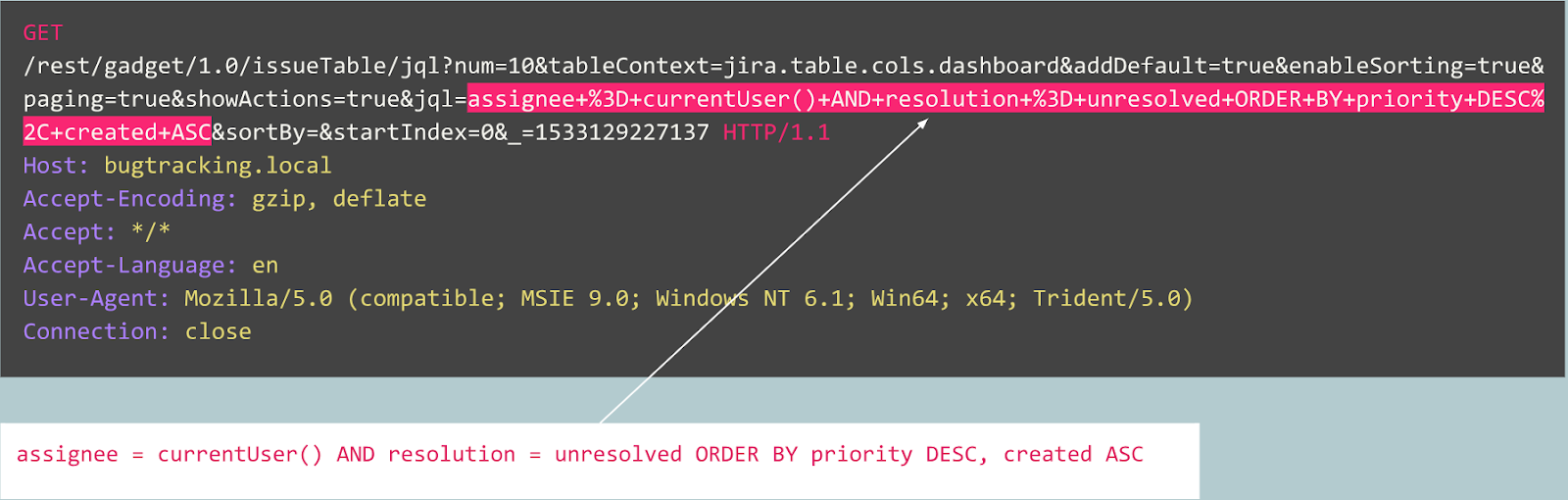
Agora vamos dar uma olhada em outro caso:

Inicialmente, a solicitação se parece com a inscrição típica de um usuário em um site desenvolvido pelo Joomla CMS. No entanto, a operação solicitada é "user.register" em vez do normal "registration.register". A primeira opção foi preterida e contém uma vulnerabilidade, permitindo que qualquer pessoa se inscreva como administrador.
Essa exploração é conhecida como "Joomla <3.6.4 Criação de conta / escalonamento de privilégios" (CVE-2016-8869, CVE-2016-8870).

Como começamos
Primeiro, examinamos as pesquisas anteriores, pois muitas tentativas de criar algoritmos estatísticos ou de aprendizado de máquina diferentes para detectar ataques foram feitas ao longo das décadas. Uma das abordagens mais frequentes é resolver a tarefa de atribuição a uma classe ("solicitação benigna", "Injeção de SQL", "XSS", "CSRF" e assim por diante). Embora seja possível obter uma precisão decente com a classificação de um determinado conjunto de dados, essa abordagem falha ao resolver alguns problemas muito importantes:
- A escolha do conjunto de classes . E se o seu modelo durante o aprendizado for apresentado com três classes ("benigno", "SQLi" e "XSS"), mas na produção ele encontrar um ataque de CSRF ou mesmo uma nova técnica de ataque?
- O significado dessas classes . Suponha que você precise proteger 10 clientes, cada um deles executando aplicativos da Web completamente diferentes. Para a maioria deles, você não teria idéia de como realmente é um único ataque de "SQL Injection" contra o aplicativo. Isso significa que você teria que, de alguma forma, construir artificialmente seus conjuntos de dados de aprendizado - o que é uma péssima idéia, porque você acabará aprendendo com dados com uma distribuição completamente diferente dos dados reais.
- Interpretabilidade dos resultados do seu modelo . Ótimo, então o modelo veio com o rótulo "SQL Injection" - e agora? Você e, mais importante, seu cliente, que é o primeiro a ver o alerta e geralmente não é especialista em ataques na Web, precisam adivinhar qual parte da solicitação o modelo considera maliciosa.
Tendo isso em mente, decidimos tentar a classificação de qualquer maneira.
Como o protocolo HTTP é baseado em texto, era óbvio que tínhamos que dar uma olhada nos classificadores de texto modernos. Um dos exemplos bem conhecidos é a análise de sentimentos do conjunto de dados de revisão de filmes do IMDB. Algumas soluções usam redes neurais recorrentes (RNNs) para classificar essas revisões. Decidimos usar um modelo de classificação RNN semelhante, com algumas pequenas diferenças. Por exemplo, as RNNs de classificação de linguagem natural usam incorporação de palavras, mas não está claro quais são as palavras em uma linguagem não natural como HTTP. Foi por isso que decidimos usar as combinações de personagens em nosso modelo.
Incorporações prontas são irrelevantes para resolver o problema, e é por isso que usamos mapeamentos simples de caracteres para códigos numéricos com vários marcadores internos, como
GO e
EOS .
Depois que terminamos o desenvolvimento e o teste do modelo, todos os problemas previstos anteriormente ocorreram, mas pelo menos nossa equipe passou de uma reflexão ociosa para algo produtivo.
Como procedemos
A partir daí, decidimos tentar tornar os resultados do nosso modelo mais interpretáveis. Em algum momento, encontramos o mecanismo da “atenção” e começamos a integrá-lo ao nosso modelo. E isso produziu alguns resultados promissores: finalmente, tudo se juntou e obtivemos alguns resultados interpretáveis pelo homem. Agora, nosso modelo começou a produzir não apenas os rótulos, mas também os coeficientes de atenção para cada caractere da entrada.
Se isso pudesse ser visualizado, digamos, em uma interface da web, poderíamos colorir o local exato em que um ataque de "SQL Injection" foi encontrado. Esse foi um resultado promissor, mas os outros problemas ainda não foram resolvidos.
Começamos a ver que poderíamos nos beneficiar indo na direção do mecanismo de atenção e afastando-nos da classificação. Depois de ler muitas pesquisas relacionadas (por exemplo, “Atenção é tudo que você precisa”, Word2Vec e arquiteturas de decodificador e decodificador) em modelos de sequência e experimentando nossos dados, conseguimos criar um modelo de detecção de anomalia que funcionaria em mais ou menos da mesma maneira que um especialista humano.
Autoencoders
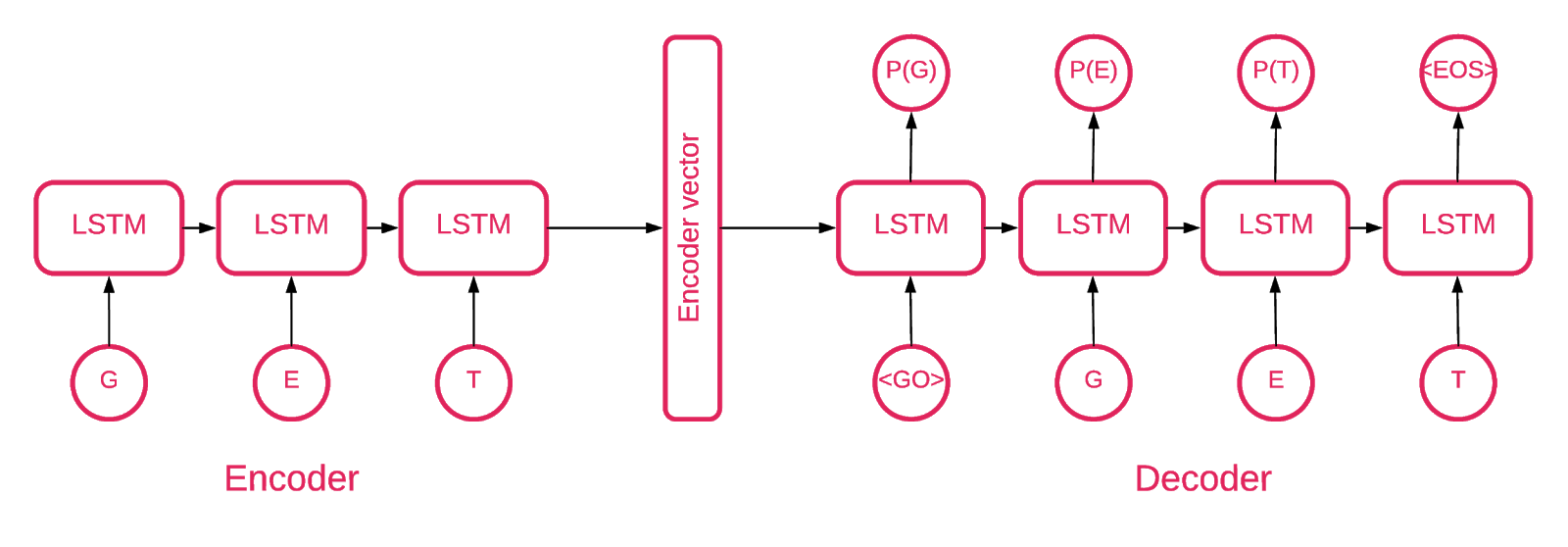
Em algum momento, ficou claro que um auto-codificador de sequência a sequência se encaixava melhor em nosso propósito.
Um modelo de sequência a sequência consiste em dois modelos de memória de longa duração (LSTM) de múltiplas camadas: um codificador e um decodificador. O codificador mapeia a sequência de entrada para um vetor de dimensionalidade fixa. O decodificador decodifica o vetor alvo usando esta saída do codificador.
Portanto, um autoencoder é um modelo de sequência a sequência que define seus valores de destino iguais aos valores de entrada. A idéia é ensinar a rede a recriar as coisas que viu ou, em outras palavras, aproximar uma função de identidade. Se o autoencoder treinado receber uma amostra anômala, é provável que o recrie com um alto grau de erro por nunca ter visto essa amostra anteriormente.
O código
Nossa solução é composta de várias partes: inicialização, treinamento, previsão e validação de modelos.
A maior parte do código localizado no repositório é auto-explicativo, focaremos apenas em partes importantes.
O modelo é inicializado como uma instância da classe Seq2Seq, que possui os seguintes argumentos do construtor:
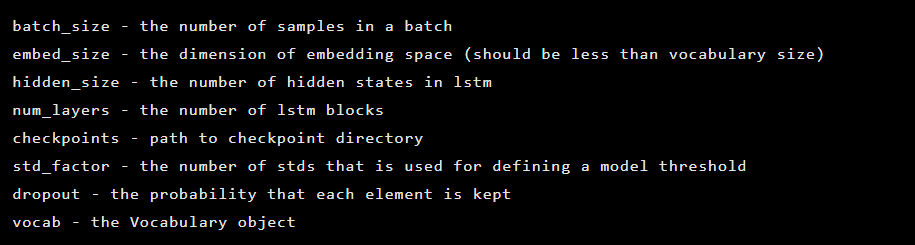
Depois disso, as camadas do autoencoder são inicializadas. Primeiro, o codificador:
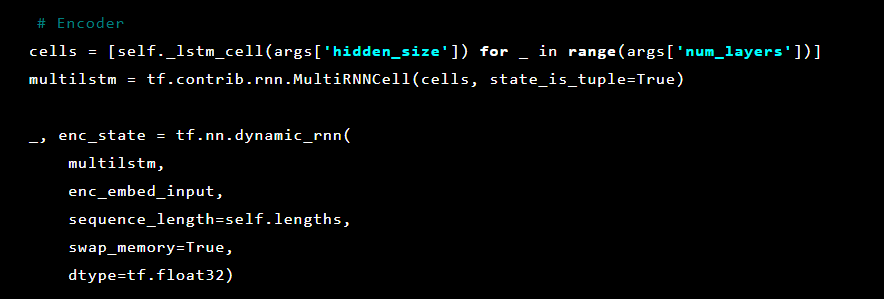
E então o decodificador:
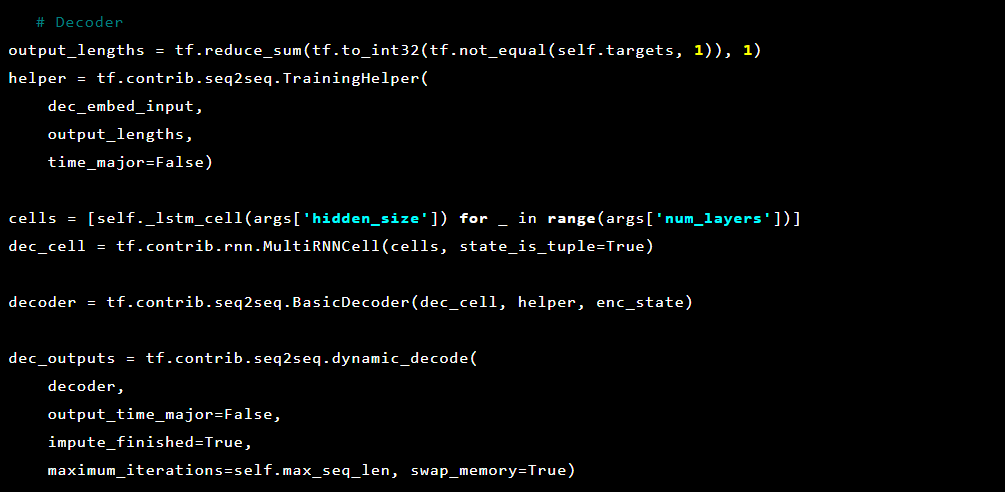
Como estamos tentando resolver a detecção de anomalias, os alvos e entradas são os mesmos. Assim, nosso feed_dict tem a seguinte aparência:
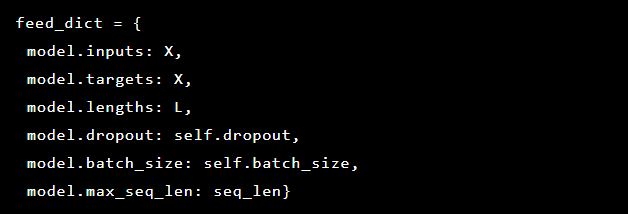
Após cada época, o melhor modelo é salvo como um ponto de verificação, que pode ser carregado posteriormente para fazer previsões. Para fins de teste, um aplicativo da web ao vivo foi configurado e protegido pelo modelo para que fosse possível testar se ataques reais foram bem-sucedidos ou não.
Inspirados pelo mecanismo de atenção, tentamos aplicá-lo ao autoencoder, mas notamos que as probabilidades produzidas na última camada funcionam melhor na marcação das partes anômalas de uma solicitação.

No estágio de teste com nossas amostras, obtivemos resultados muito bons: a precisão e o recall foram próximos de 0,99. E a curva ROC estava em torno de 1. Definitivamente, uma bela visão!
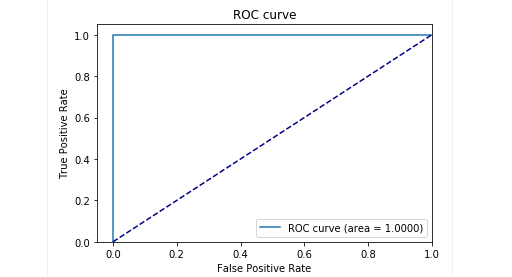
Os resultados
Nosso modelo de autoencoder Seq2Seq descrito demonstrou ser capaz de detectar anomalias em solicitações HTTP com alta precisão.
Esse modelo age como um ser humano: aprende apenas as solicitações de usuário "normais" enviadas para um aplicativo da web. Ele detecta anomalias nas solicitações e destaca o local exato da solicitação considerada anômala. Avaliamos esse modelo contra ataques ao aplicativo de teste e os resultados parecem promissores. Por exemplo, a captura de tela anterior mostra como nosso modelo detectou a injeção de SQL dividida em dois parâmetros de formulário da Web. Essas injeções de SQL são fragmentadas, pois a carga útil do ataque é entregue em vários parâmetros HTTP. WAFs clássicos baseados em regras se saem mal na detecção de tentativas fragmentadas de injeção de SQL porque geralmente inspecionam cada parâmetro por conta própria.
O código do modelo e os dados do trem / teste foram liberados como um notebook Jupyter para que qualquer um possa reproduzir nossos resultados e sugerir melhorias.
Conclusão
Acreditamos que nossa tarefa não era trivial: criar uma maneira de detectar ataques com o mínimo de esforço. Por um lado, procuramos evitar complicar demais a solução e criar uma maneira de detectar ataques que, como que por mágica, aprendem a decidir por si mesmos o que é bom e o que é ruim. Ao mesmo tempo, queríamos evitar problemas com o fator humano quando um especialista (falível) está decidindo o que indica um ataque e o que não indica. E, em geral, o autoencoder com a arquitetura Seq2Seq parece resolver muito bem o nosso problema de detectar anomalias.
Também queríamos resolver o problema da interpretabilidade dos dados. Ao usar arquiteturas de redes neurais complexas, é muito difícil explicar um resultado específico. Quando toda uma série de transformações é aplicada, a identificação dos dados mais importantes por trás de uma decisão se torna quase impossível. No entanto, após repensar a abordagem da interpretação dos dados pelo modelo, conseguimos obter probabilidades para cada caractere da última camada.
É importante observar que essa abordagem não é uma versão pronta para produção. Não podemos divulgar os detalhes de como essa abordagem pode ser implementada em um produto real. Mas avisaremos que não é possível simplesmente pegar esse trabalho e "conectá-lo". Fazemos essa ressalva porque, depois de publicar no GitHub, começamos a ver alguns usuários que tentavam simplesmente implementar nossa solução atual por atacado em seus próprios projetos, com resultados malsucedidos (e não surpreendentes).
A prova de conceito está disponível
aqui (github.com).
Autores: Alexandra Murzina (
murzina_a ), Irina Stepanyuk (
GitHub ), Fedor Sakharov (
GitHub ), Arseny Reutov (
Raz0r )
Leitura adicional
- Noções básicas sobre redes LSTM
- Atenção e redes neurais recorrentes aumentadas
- Atenção É Tudo Que Você Precisa
- Atenção é tudo o que você precisa (anotado)
- Tutorial de Tradução Automática Neural (seq2seq)
- Autoencoders
- Aprendizagem sequência a sequência com redes neurais
- Construindo Autoencoders em Keras