Hacking de música para democratizar o conteúdo derivadoIsenção de responsabilidade: Todas as propriedades intelectuais, designs e métodos descritos neste artigo são divulgados nos documentos US10014002B2 e US9842609B2.
Eu gostaria de poder voltar a 1965, bater na porta da frente do estúdio da Abby Road com um passe, entrar e ouvir as vozes reais de Lennon e McCartney ... Bem, vamos tentar. Entrada: MP3 de qualidade média dos Beatles,
podemos resolver isso . A faixa superior é o mix de entrada, a faixa inferior são os vocais isolados que nossa rede neural destacou.
Formalmente, esse problema é conhecido como
separação das fontes de som ou
separação do sinal (separação da fonte de áudio). Consiste em restaurar ou reconstruir um ou mais dos sinais originais, que são misturados com outros sinais como resultado de um processo
linear ou convolucional . Esse campo de pesquisa tem muitas aplicações práticas, incluindo a melhoria da qualidade do som (fala) e a eliminação de ruídos, remixes de músicas, distribuição espacial do som, remasterização etc. Os engenheiros de som às vezes chamam essa técnica de desmistificação. Existem muitos recursos nesse tópico, desde a separação cega de sinais com análise de componentes independentes (ACI) até a fatoração semi-controlada de matrizes não-negativas e terminando com abordagens posteriores baseadas em redes neurais. Você pode encontrar boas informações sobre os dois primeiros pontos
nesses mini-guias da CCRMA, que ao mesmo tempo foram muito úteis para mim.
Mas antes de mergulhar no desenvolvimento ... um pouco da filosofia aplicada ao aprendizado de máquina ...Eu estava envolvido no processamento de sinais e imagens mesmo antes de o slogan "aprendizado profundo resolver tudo" se espalhar, para que eu possa apresentar uma solução como uma viagem de
engenharia de recursos e mostrar
por que uma rede neural é a melhor abordagem para esse problema em particular . Porque Muitas vezes, vejo pessoas escreverem algo assim:
“Com o aprendizado profundo, você não precisa mais se preocupar em escolher recursos; fará isso por você.ou pior ...
“A diferença entre aprendizado de máquina e aprendizado profundo [ei ... aprendizado profundo ainda é aprendizado de máquina!] É
que no ML você extrai os atributos e no aprendizado profundo isso acontece automaticamente na rede.”Essas generalizações provavelmente vêm do fato de que os DNNs podem ser muito eficazes na exploração de bons espaços ocultos. Mas, portanto, é impossível generalizar. Fico muito chateado quando recém-formados e profissionais sucumbem aos conceitos errados acima e adotam a abordagem de "aprender profundamente tudo". Assim, basta lançar um monte de dados brutos (mesmo após um pequeno processamento preliminar) - e tudo funcionará como deveria. No mundo real, você precisa cuidar de coisas como desempenho, execução em tempo real, etc. Por causa de tais equívocos, você ficará preso no modo de experimento por muito tempo ...
A Engenharia de recursos continua sendo uma disciplina muito importante no projeto de redes neurais artificiais. Como em qualquer outra técnica de ML, na maioria dos casos, é o que distingue soluções efetivas do nível de produção de experimentos malsucedidos ou ineficazes. Uma profunda compreensão dos seus dados e sua natureza ainda significa muito ...A a Z
Ok, eu terminei o sermão. Agora vamos ver porque estamos aqui! Como em qualquer problema de processamento de dados, vamos primeiro ver como ele é. Veja a próxima parte dos vocais da gravação original do estúdio.
Vocais de estúdio 'One Last Time', Ariana GrandeNão é muito interessante, certo? Bem, isso é porque visualizamos o sinal
no tempo . Aqui vemos apenas mudanças de amplitude ao longo do tempo. Mas você pode extrair todo tipo de outras coisas, como envelopes de amplitude (envelope), valores quadráticos médios da raiz (RMS), a taxa de alteração de valores positivos de amplitude para negativos (taxa de cruzamento zero) etc., mas esses
sinais são muito
primitivos e não são suficientemente distintos, para ajudar no nosso problema. Se queremos extrair vocais de um sinal de áudio, primeiro precisamos determinar de alguma forma a estrutura da fala humana. Felizmente, a Janela
Fourier Transform (STFT) vem em socorro.
Espectro de amplitude STFT - tamanho da janela = 2048, sobreposição = 75%, escala de frequência logarítmica [Sonic Visualizer]Embora eu
adore o processamento de fala e definitivamente
adore brincar com
simulações de filtro de entrada, cepstrums, sottotami, LPC, MFCC e assim por diante
, pularemos toda essa bobagem e focaremos nos principais elementos relacionados ao nosso problema para que o artigo possa ser entendido pelo maior número possível de pessoas, não apenas especialistas em processamento de sinais.
Então, o que a estrutura da fala humana nos diz?
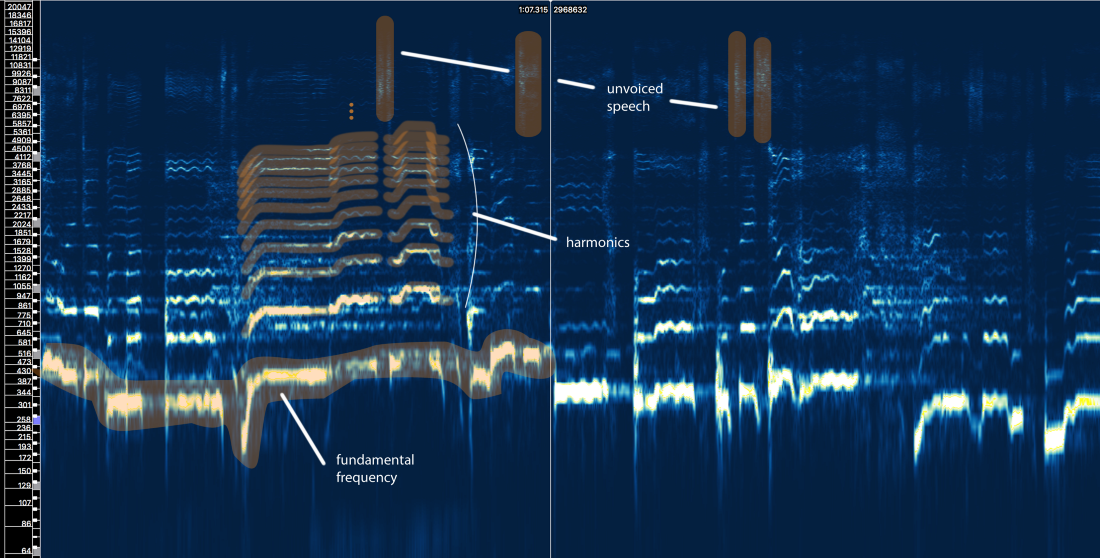
Bem, podemos definir três elementos principais aqui:
- A frequência fundamental (f0), que é determinada pela frequência de vibração de nossas cordas vocais. Nesse caso, Ariana canta na faixa de 300 a 500 Hz.
- Uma série de harmônicos acima de f0 que seguem uma forma ou padrão semelhante. Esses harmônicos aparecem em frequências que são múltiplos de f0.
- Fala não verbalizada, que inclui consoantes como 't', 'p', 'k', 's' (que não é produzida pela vibração das cordas vocais), respiração etc. Tudo isso se manifesta na forma de rajadas curtas na região de alta frequência.
Primeira tentativa com regras
Vamos esquecer por um segundo o que é chamado de aprendizado de máquina. Um método de extração vocal pode ser desenvolvido com base em nosso conhecimento do sinal? Deixe-me tentar ...
Isolamento vocal ingênuo V1.0:- Identifique áreas com vocais. Há muitas coisas no sinal original. Queremos focar nas áreas que realmente contêm conteúdo vocal e ignorar todo o resto.
- Distinga entre voz e voz. Como vimos, eles são muito diferentes. Eles provavelmente precisam ser tratados de maneira diferente.
- Avalie a mudança na frequência fundamental ao longo do tempo.
- Com base no pino 3, aplique algum tipo de máscara para capturar harmônicos.
- Faça algo com fragmentos de fala não verbalizada ...

Se trabalharmos dignamente, o resultado deve ser um
soft ou
bitmask , cuja aplicação à amplitude do STFT (multiplicação por elementos) fornece uma reconstrução aproximada da amplitude dos vocais do STFT. Em seguida, combinamos esse STFT vocal com informações sobre a fase do sinal original, calculamos o STFT inverso e obtemos o sinal de tempo do vocal reconstruído.
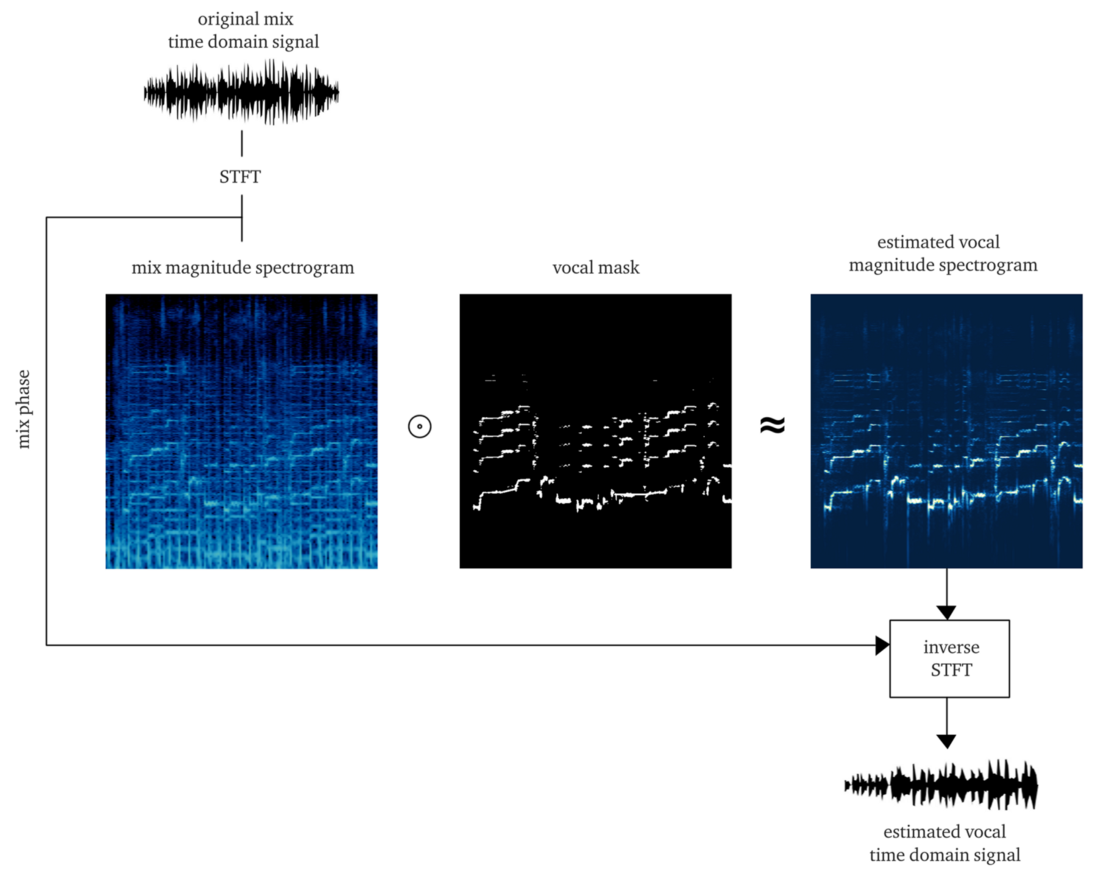
Fazer isso do zero já é um grande trabalho. Mas, para fins de demonstração, a implementação do
algoritmo pYIN é aplicável . Embora se pretenda resolver o passo 3, mas com as configurações corretas, ele executa decentemente os passos 1 e 2, rastreando a base vocal mesmo na presença de música. O exemplo abaixo contém a saída após o processamento desse algoritmo, sem processar a fala não verbalizada.
E o que ...? Ele parece ter feito todo o trabalho, mas não há boa qualidade nem perto. Talvez gastando mais tempo, energia e dinheiro, melhoraremos esse método ...
Mas deixe-me perguntar-lhe ...
O que acontece se
algumas vozes aparecerem na faixa, e ainda assim elas são encontradas em pelo menos 50% das faixas profissionais modernas?
O que acontece se os vocais forem processados por
reverb, atrasos e outros efeitos? Vamos dar uma olhada no último refrão de Ariana Grande dessa música.
Você já sente dor ...? Eu sou
Tais métodos em regras estritas muito rapidamente se transformam em um castelo de cartas. O problema é muito complicado. Muitas regras, muitas exceções e muitas condições diferentes (efeitos e configurações de mixagem). Uma abordagem em várias etapas também implica que os erros em uma etapa estendem os problemas para a próxima etapa. Melhorar cada etapa se tornará muito caro: será necessário um grande número de iterações para acertar. E por último, mas não menos importante, é provável que, no final, tenhamos um transportador que consome muitos recursos, o que por si só pode negar todos os esforços.
Em tal situação, é hora de começar a pensar em uma abordagem mais abrangente e deixar o ML descobrir parte dos processos e operações básicos necessários para resolver o problema. Mas ainda precisamos mostrar nossas habilidades e participar da engenharia de recursos, e você verá o porquê.Hipótese: use a rede neural como uma função de transferência que traduz misturas em vocais
Observando as realizações das redes neurais convolucionais no processamento de fotos, por que não aplicar a mesma abordagem aqui?
 As redes neurais resolvem com sucesso problemas como colorização de imagens, nitidez e resolução.
As redes neurais resolvem com sucesso problemas como colorização de imagens, nitidez e resolução.No final, você pode imaginar o sinal sonoro "como uma imagem" usando a transformada de Fourier de curto prazo, certo? Embora essas
imagens sonoras não correspondam à distribuição estatística das imagens naturais, elas ainda possuem padrões espaciais (no espaço de tempo e frequência) nos quais treinar a rede.
 Esquerda: batida de bateria e linha de base abaixo, vários sons de sintetizador no meio, todos misturados com vocais. Direita: apenas vocais
Esquerda: batida de bateria e linha de base abaixo, vários sons de sintetizador no meio, todos misturados com vocais. Direita: apenas vocaisA realização de tal experimento seria uma tarefa cara, pois é difícil obter ou gerar os dados de treinamento necessários. Mas na pesquisa aplicada, sempre tento usar essa abordagem: primeiro,
para identificar um problema mais simples que confirme os mesmos princípios , mas que não exige muito trabalho. Isso permite avaliar a hipótese, iterar mais rapidamente e corrigir o modelo com perdas mínimas, se não funcionar como deveria.
A condição implícita é que a
rede neural deve entender a estrutura da fala humana . Um problema mais simples pode ser o seguinte:
uma rede neural pode determinar a presença de fala em um fragmento arbitrário de uma gravação de som . Estamos falando de um
detector de atividade de voz confiável
(VAD) , implementado na forma de um classificador binário.
Nós projetamos o espaço dos sinais
Sabemos que os sinais sonoros, como música e fala humana, são baseados em dependências de tempo. Simplificando, nada acontece isoladamente em um determinado momento. Se eu quiser saber se há uma voz em uma determinada peça de gravação de som, preciso examinar as regiões vizinhas. Esse
contexto de tempo fornece boas informações sobre o que está acontecendo na área de interesse. Ao mesmo tempo, é desejável executar a classificação com incrementos de tempo muito pequenos para reconhecer uma voz humana com a maior resolução possível de tempo.

Vamos contar um pouco ...
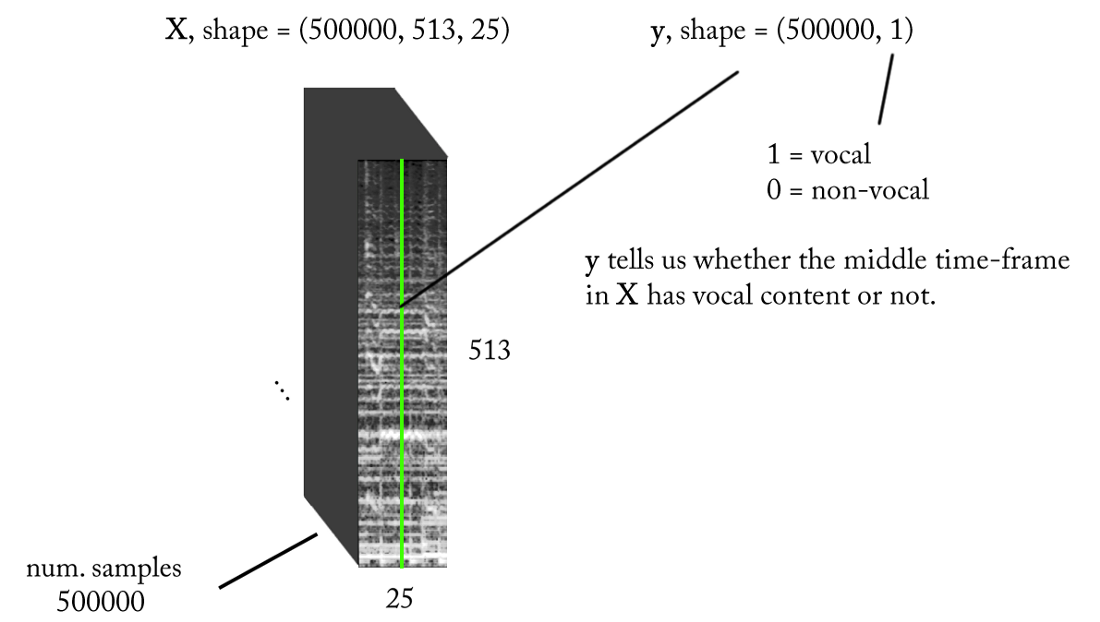
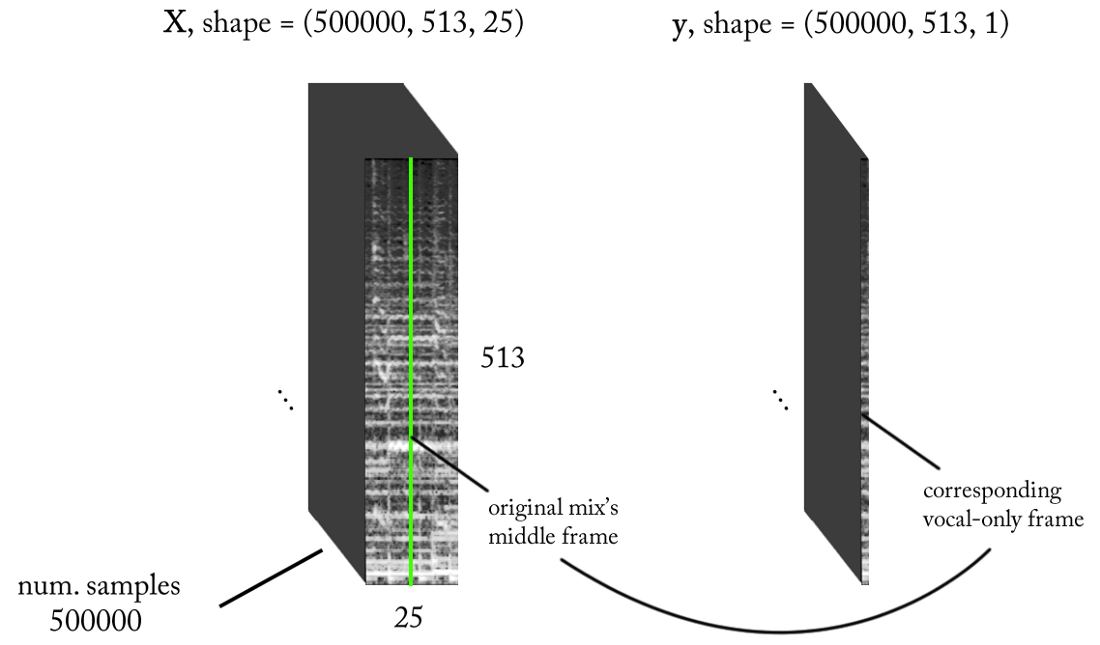
- Frequência de amostragem (fs): 22050 Hz (diminuímos a amostra de 44100 para 22050)
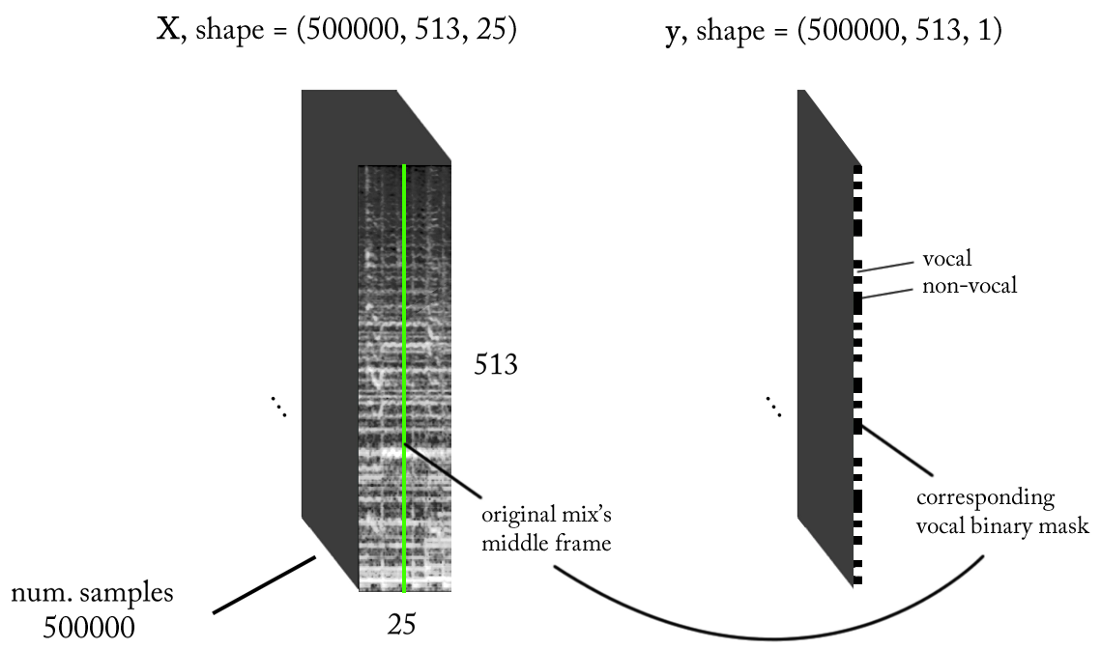
- Projeto STFT: tamanho da janela = 1024, tamanho do salto = 256, interpolação da escala de giz para o filtro de ponderação, levando em consideração a percepção. Como nossa entrada é real , você pode trabalhar com metade do STFT (uma explicação está além do escopo deste artigo ...) enquanto mantém o componente DC (opcional), o que fornece 513 compartimentos de frequência.
- Resolução da classificação alvo: um quadro STFT (~ 11,6 ms = 256/22050)
- Contexto do tempo alvo: ~ 300 milissegundos = 25 quadros STFT.
- O número alvo de exemplos de treinamento: 500 mil.
- Supondo que usamos uma janela deslizante em incrementos de 1 intervalo de tempo STFT para gerar dados de treinamento, precisamos de cerca de 1,6 horas de som marcado para gerar 500 mil amostras de dados
Com os requisitos acima, a entrada e a saída do nosso classificador binário são as seguintes:
Modelo
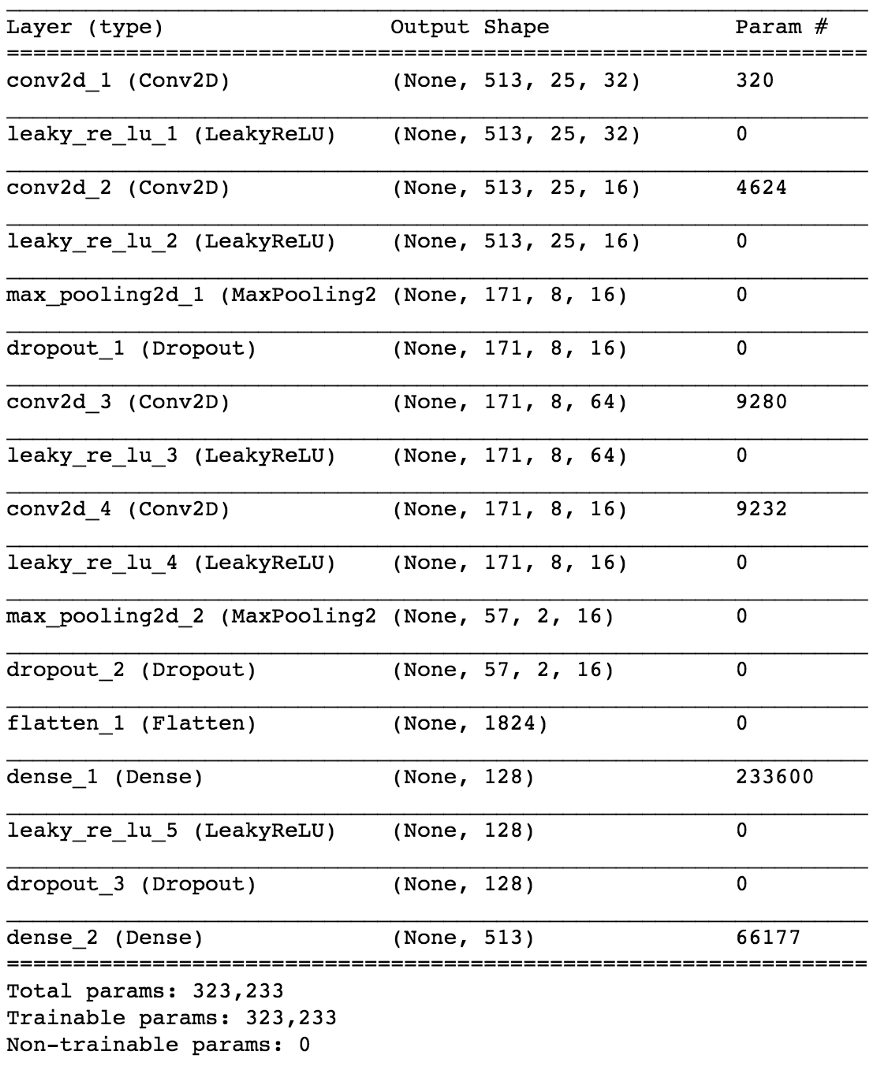
Usando Keras, construiremos um pequeno modelo de rede neural para testar nossa hipótese.
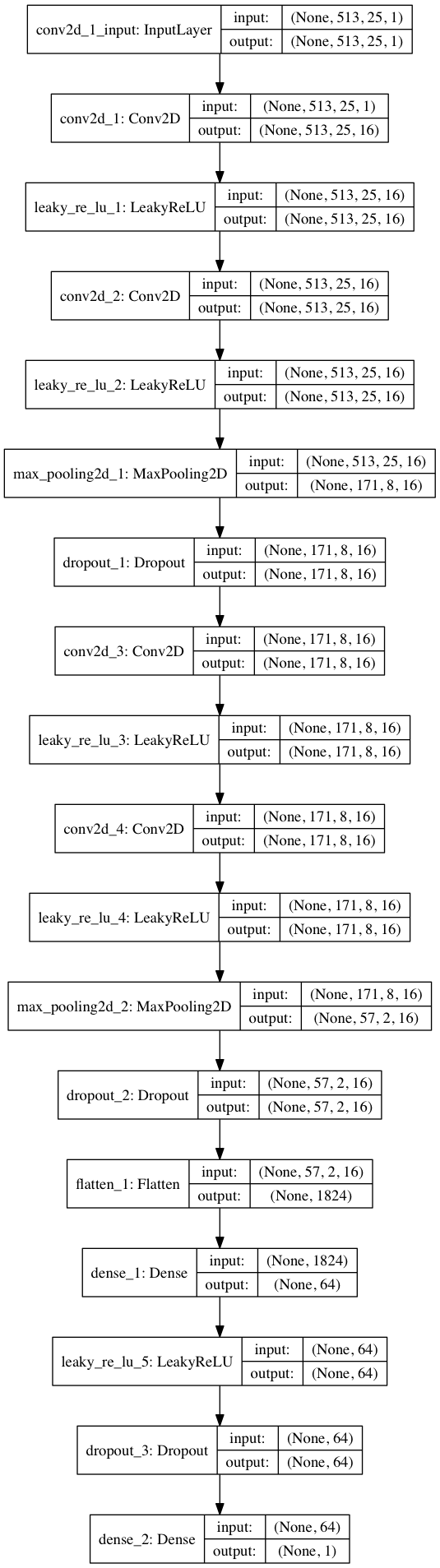
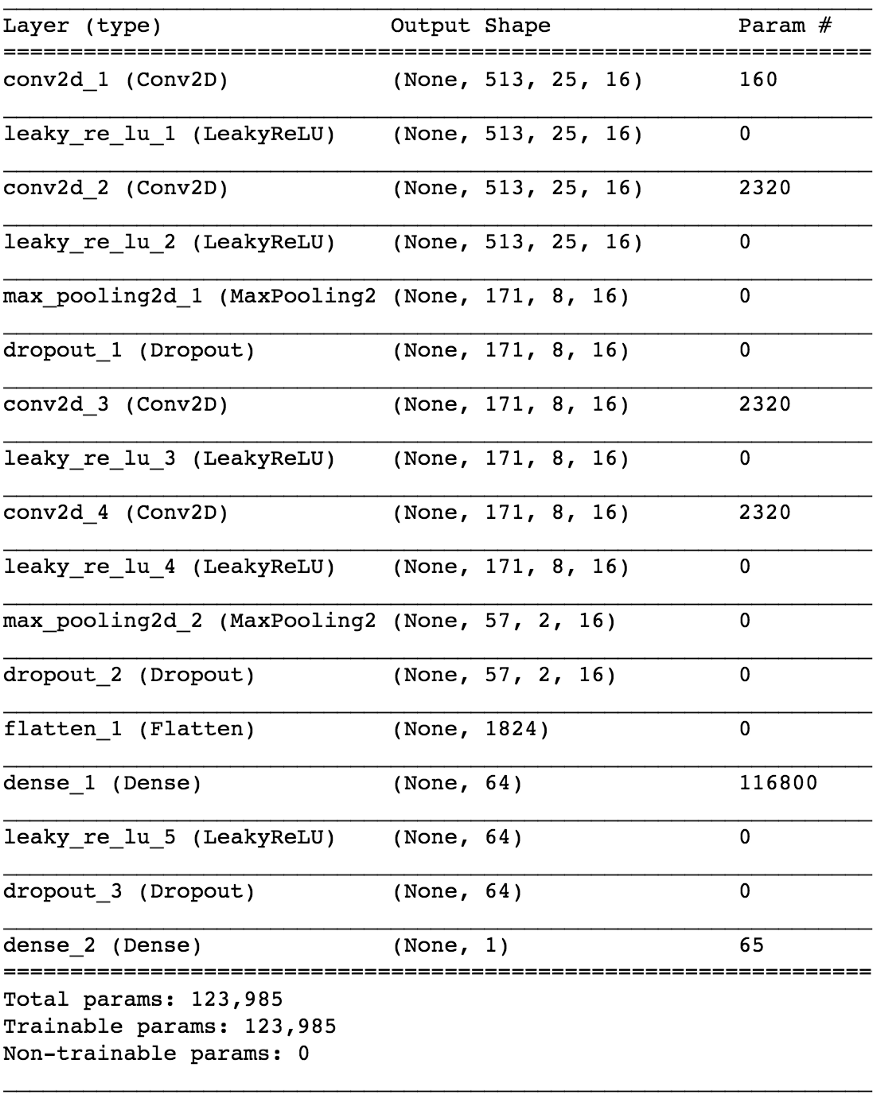
import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D from keras.optimizers import SGD from keras.layers.advanced_activations import LeakyReLU model = Sequential() model.add(Conv2D(16, (3,3), padding='same', input_shape=(513, 25, 1))) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(64)) model.add(LeakyReLU()) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss=keras.losses.binary_crossentropy, optimizer=sgd, metrics=['accuracy'])
Ao dividir os dados 80/20 em treinamento e teste após ~ 50 épocas, obtemos a
precisão ao testar ~ 97% . Isso é evidência suficiente de que nosso modelo é capaz de distinguir entre vocais em fragmentos de som musical (e fragmentos sem vocais). Se verificarmos alguns mapas de características da quarta camada convolucional, podemos concluir que a rede neural parece ter otimizado seus kernels para executar duas tarefas: filtrar músicas e filtrar vocais ...
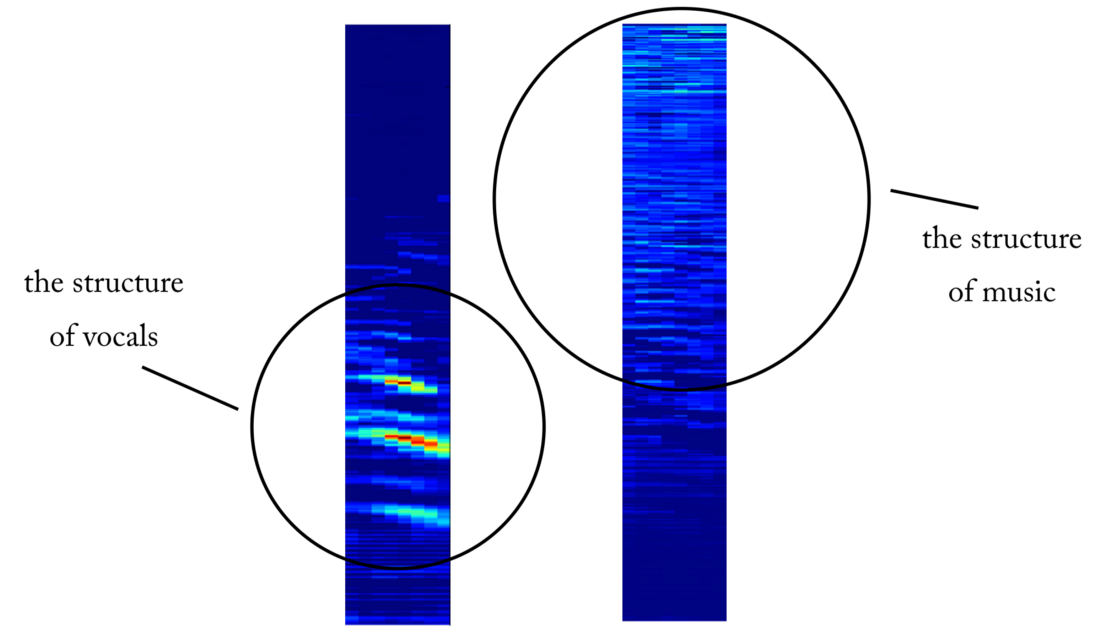 Um exemplo de um mapa de objetos na saída da 4ª camada convolucional. Aparentemente, a saída à esquerda é o resultado de operações do kernel na tentativa de preservar o conteúdo vocal enquanto ignora a música. Valores altos se assemelham à estrutura harmoniosa da fala humana. O mapa de objetos à direita parece ser o resultado da tarefa oposta.
Um exemplo de um mapa de objetos na saída da 4ª camada convolucional. Aparentemente, a saída à esquerda é o resultado de operações do kernel na tentativa de preservar o conteúdo vocal enquanto ignora a música. Valores altos se assemelham à estrutura harmoniosa da fala humana. O mapa de objetos à direita parece ser o resultado da tarefa oposta.Do detector de voz à desconexão do sinal
Tendo resolvido o problema mais simples de classificação, como podemos avançar para a verdadeira separação dos vocais da música? Bem, olhando o primeiro método
ingênuo , ainda queremos obter um espectrograma de amplitude para os vocais. Agora isso está se tornando uma tarefa de regressão. O que queremos fazer é calcular o espectro de amplitude apropriado para os vocais neste período de tempo a partir de um período de tempo específico do STFT do sinal original, ou seja, o mix (com um contexto de tempo suficiente).
E o conjunto de dados de treinamento? (você pode me perguntar neste momento)Porra ... por que sim. Eu ia considerar isso no final do artigo para não me distrair do tópico!
Se nosso modelo é bem treinado, para uma conclusão lógica, você só precisa implementar uma janela deslizante simples no mix STFT. Após cada previsão, mova a janela para a direita em 1 período, preveja o próximo quadro com os vocais e associe-o à previsão anterior. Quanto ao modelo, vamos pegar o mesmo modelo usado para o detector de voz e fazer pequenas alterações: a forma de onda de saída é agora (513.1), ativação linear na saída, MSE em função de perdas. Agora começamos o treinamento.
Não se alegrar ainda ...Embora essa representação de E / S faça sentido, após treinar nosso modelo várias vezes, com vários parâmetros e normalizações de dados, não há resultados. Parece que estamos pedindo demais ...
Passamos de um classificador binário para
regressão em um vetor 513-dimensional. Embora a rede esteja estudando o problema até certo ponto, os vocais restaurados ainda têm artefatos óbvios e interferência de outras fontes. Mesmo após adicionar camadas adicionais e aumentar o número de parâmetros do modelo, os resultados não mudam muito. E então surge a pergunta:
como "simplificar" a tarefa da rede por engano e, ao mesmo tempo, alcançar os resultados desejados?E se, em vez de estimar a amplitude dos vocais do STFT, treinarmos a rede para obter uma máscara binária, que quando aplicada ao mix STFT nos fornecer um espectrograma de amplitude simplificado, mas
perceptivamente aceitável dos vocais?
Experimentando várias heurísticas, criamos uma maneira muito simples (e, é claro, pouco ortodoxa em termos de processamento de sinal ...) para extrair vocais de mixagens usando máscaras binárias. Sem entrar em detalhes, a essência é a seguinte. Imagine a saída como uma imagem binária, onde o valor '1' indica a
presença predominante de conteúdo vocal em uma determinada frequência e período de tempo, e o valor '0' indica a presença predominante de música em um determinado local. Podemos chamá-lo de
binarização da percepção , apenas para criar um nome. Visualmente, parece muito feio, para ser honesto, mas os resultados são surpreendentemente bons.
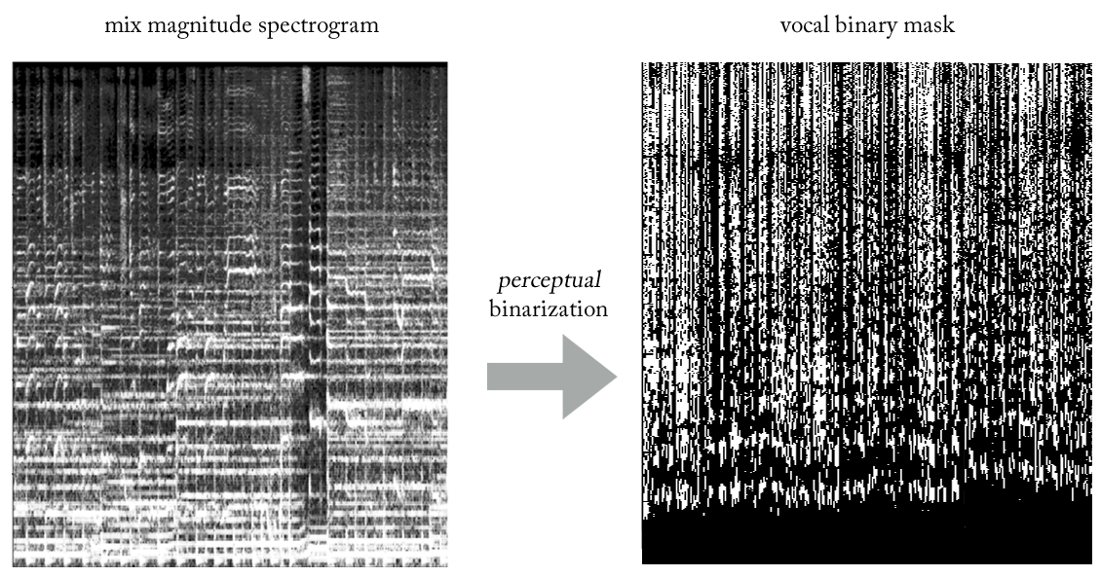
Agora, nosso problema se torna um tipo de classificação de regressão híbrida (mais ou menos ...). Pedimos ao modelo para “classificar pixels” na saída como vocal ou não vocal, embora conceitualmente (bem como do ponto de vista da função de perda MSE usada) a tarefa permaneça regressiva.
Embora essa distinção possa parecer inadequada para alguns, de fato é de grande importância na capacidade do modelo de estudar a tarefa, a segunda das quais é mais simples e mais limitada. Ao mesmo tempo, isso nos permite manter nosso modelo relativamente pequeno em termos de número de parâmetros, dada a complexidade da tarefa, algo muito desejável para o trabalho em tempo real, que nesse caso era um requisito de design. Após alguns pequenos ajustes, o modelo final fica assim.
Como recuperar um sinal no domínio do tempo?
De fato, como no
método ingênuo . Nesse caso, para cada passagem, prevemos um período de tempo da máscara de vocais binários. Novamente, percebendo uma janela deslizante simples com uma etapa de um período, continuamos a avaliar e combinar períodos sucessivos, que compõem toda a máscara binária vocal.

Crie um conjunto de treinamento
Como você sabe, um dos principais problemas ao ensinar com um professor (deixe esses exemplos de brinquedos com conjuntos de dados prontos) são os dados corretos (em quantidade e qualidade) para o problema específico que você está tentando resolver. Com base nas representações descritas de entrada e saída, para treinar nosso modelo, primeiro você precisará de um número significativo de mixagens e suas faixas vocais correspondentes, perfeitamente alinhadas e normalizadas. Esse conjunto pode ser criado de várias maneiras, e usamos uma combinação de estratégias, desde a criação manual de pares [mix <-> vocais] com base em várias cappelas encontradas na Internet, até a pesquisa de material de música de banda de rock e scrapbooking do Youtube. Só para você ter uma idéia de como esse processo é trabalhoso e penoso, parte do projeto foi o desenvolvimento de uma ferramenta para criar automaticamente pares [mix <-> vocais]:

É necessária uma quantidade realmente grande de dados para a rede neural aprender a função de transferência para a transmissão de mixagens para os vocais. Nosso conjunto final consistiu em aproximadamente 15 milhões de amostras de misturas de 300 ms e suas máscaras binárias vocais correspondentes.
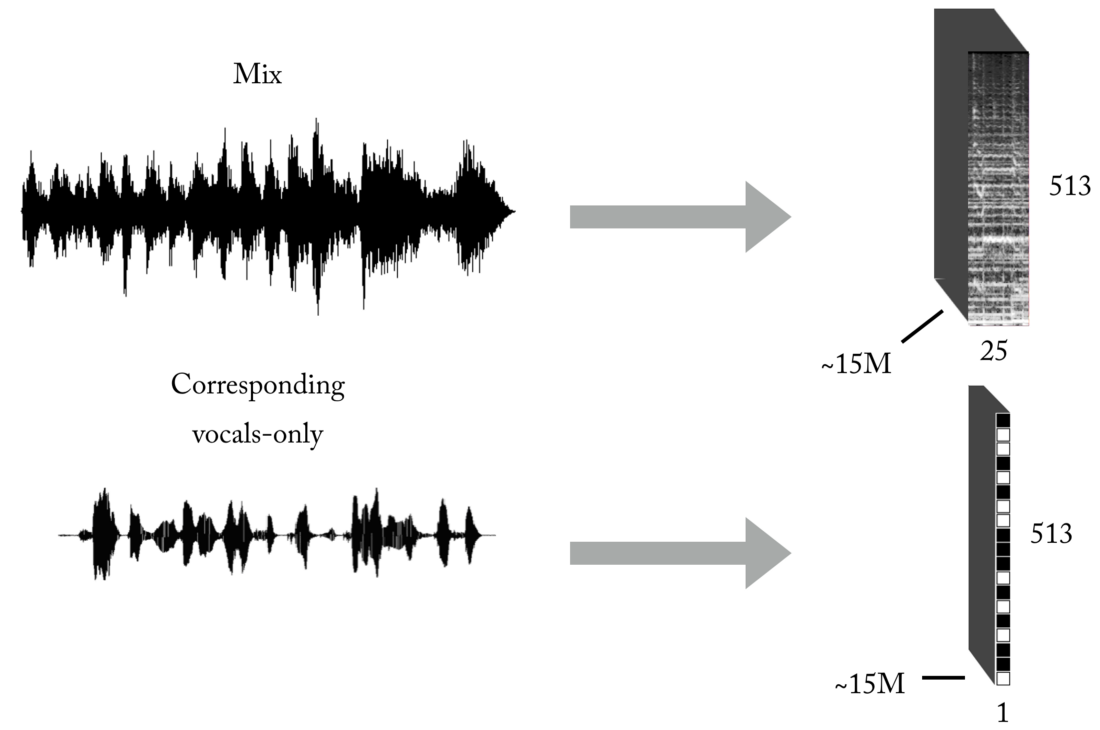
Arquitetura de Pipeline
Como você provavelmente sabe, criar um modelo de ML para uma tarefa específica é apenas metade da batalha. No mundo real, você precisa pensar na arquitetura de software, especialmente se precisar trabalhar em tempo real ou próximo a ela.
Nesta implementação específica, a reconstrução no domínio do tempo pode ocorrer imediatamente após a previsão da máscara de vocais binários completos (modo autônomo) ou, mais interessante, no modo multithread, onde recebemos e processamos dados, restauramos vocais e reproduzimos sons - tudo em pequenos segmentos, próximo a streaming e até quase em tempo real, processando músicas gravadas em tempo real com o mínimo atraso. Na verdade, este é um tópico separado, e deixarei para outro artigo
sobre pipelines ML em tempo real ...
Eu acho que disse o suficiente, então por que não ouvir alguns exemplos!?
Daft Punk - Get Lucky (gravação de estúdio)
Aqui você pode ouvir alguma interferência mínima da bateria ...Adele - Atear fogo à chuva (gravação ao vivo!)
Observe como, no início, nosso modelo extrai os gritos da multidão como conteúdo vocal :). Nesse caso, há alguma interferência de outras fontes. Como se trata de uma gravação ao vivo, parece aceitável que os vocais extraídos tenham pior qualidade do que os anteriores.Sim, e "outra coisa" ...
Se o sistema funciona para vocais, por que não aplicá-lo a outros instrumentos ...?
O artigo já é bastante amplo, mas, devido ao trabalho realizado, você merece ouvir a última demonstração. Com exatamente a mesma lógica de quando extraímos vocais, podemos tentar dividir a música estéreo em componentes (bateria, baixo, voz, outros), fazendo algumas mudanças em nosso modelo e, é claro, tendo o treinamento apropriado :).
Obrigado pela leitura. Como nota final: como você pode ver, o modelo atual de nossa rede neural convolucional não é tão especial. O sucesso deste trabalho foi determinado pela
Feature Engineering e pelo puro processo de teste de hipóteses, sobre o qual escreverei em artigos futuros!