Olá novamente. Hoje continuamos a compartilhar material dedicado ao lançamento do curso
"Engenheiro de Rede" , que começa já no início de março. Vimos que muitos estavam interessados na
primeira parte do artigo "Abordagem sinestésica-máquina para detectar ataques de DDoS na rede" e hoje queremos compartilhar com você a segunda - a parte final.
3.2 Classificação da imagem no problema de detecção de anomaliasO próximo passo é resolver o problema de classificação da imagem resultante. Em geral, a solução para o problema de detectar classes (objetos) em uma imagem é usar algoritmos de aprendizado de máquina para criar modelos de classe e, em seguida, algoritmos para procurar classes (objetos) em uma imagem.

A construção de um modelo consiste em dois estágios:
a) Extração de recursos para uma classe: plota vetores de recursos para os membros da classe.

Fig. 1
b) Treinamento nos recursos de modelo obtidos para tarefas de reconhecimento subseqüentes.
O objeto de classe é descrito usando vetores de recursos. Os vetores são formados a partir de:
a) informações de cores (histograma de gradiente orientado);
b) informação contextual;
c) dados sobre o arranjo geométrico de partes do objeto.
O algoritmo de classificação (previsão) pode ser dividido em dois estágios:
a) Extraia recursos da imagem. Nesta fase, duas tarefas são executadas:
- Como a imagem pode conter objetos de várias classes, precisamos encontrar todos os representantes. Para fazer isso, você pode usar uma janela deslizante que passa pela imagem do canto superior esquerdo para o canto inferior direito.
- A imagem é dimensionada porque a escala dos objetos na imagem pode mudar.
b) associar uma imagem a uma classe específica. Uma descrição formal da classe, ou seja, um conjunto de recursos destacados por suas imagens de teste, é usada como entrada. Com base nessas informações, o classificador decide se a imagem pertence à classe e avalia o grau de certeza da conclusão.
Métodos de classificação. Os métodos de classificação variam de abordagens predominantemente heurísticas a procedimentos formais com base em métodos de estatística matemática. Não existe uma classificação geralmente aceita, mas várias abordagens à classificação de imagens podem ser distinguidas:
- métodos de modelagem de objetos com base em detalhes;
- métodos do "saco de palavras";
- métodos de correspondência de pirâmides espaciais.
Para a implementação apresentada neste artigo, os autores escolheram o algoritmo “word bag”, pelos seguintes motivos:
- Os algoritmos para modelagem baseados em detalhes e em pirâmides espaciais correspondentes são sensíveis à posição dos descritores no espaço e à sua posição relativa. Essas classes de métodos são eficazes nas tarefas de detecção de objetos em uma imagem; no entanto, devido aos recursos característicos dos dados de entrada, eles são pouco aplicáveis ao problema de classificação de imagens.
- O algoritmo "saco de palavras" foi amplamente testado em outros campos do conhecimento, mostra bons resultados e é bastante simples de implementar.
Para analisar o fluxo de vídeo projetado a partir do tráfego, usamos o classificador ingênuo de Bayes [25]. É frequentemente usado para classificar textos usando o modelo de bolsa de palavras. Nesse caso, a abordagem é semelhante à análise de texto, em vez de palavras, apenas descritores são usados. O trabalho deste classificador pode ser dividido em duas partes: a fase de treinamento e a fase de previsão.
Fase de aprendizado . Cada quadro (imagem) é alimentado na entrada do algoritmo de pesquisa do descritor, neste caso, a transformação de recurso invariável em escala (SIFT) [26]. Depois disso, é executada a tarefa de correlação de pontos singulares entre os quadros. Um ponto específico na imagem de um objeto é um ponto que provavelmente aparecerá em outras imagens desse objeto.
Para resolver o problema de comparar pontos especiais de um objeto em imagens diferentes, um descritor é usado. Um descritor é uma estrutura de dados, um identificador para um ponto singular que o distingue do restante. Pode ou não ser invariável em relação às transformações da imagem do objeto. No nosso caso, o descritor é invariável em relação às transformações de perspectiva, ou seja, dimensionamento. O identificador permite comparar o ponto de recurso de um objeto em uma imagem com o mesmo ponto de recurso em outra imagem desse objeto.
Em seguida, o conjunto de descritores obtidos de todas as imagens é classificado em grupos por similaridade, usando o método de agrupamento k-means [26, 27]. Isso é feito para treinar o classificador, o que dará uma conclusão sobre se a imagem representa um comportamento anormal.
A seguir, é apresentado um algoritmo passo a passo para o treinamento do classificador do descritor de imagens:
Etapa 1 Extraia todos os descritores de conjuntos com e sem ataque.
Etapa 2 Agrupando todos os descritores usando o método k-means em n clusters.
Etapa 3 Cálculo da matriz A (m, k), em que m é o número de imagens e k é o número de clusters. O elemento (i; j) armazenará o valor da frequência com que os descritores do j-ésimo cluster aparecem na i-ésima imagem. Essa matriz será chamada de matriz da frequência de ocorrência.
Etapa 4 Cálculo dos pesos dos descritores pela fórmula tf idf [28]:
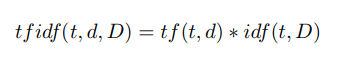
Aqui tf ("termo frequência") é a frequência de aparência do descritor nesta imagem e é definida como
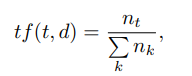
onde t é o descritor, k é o número de descritores na imagem, nt é o número de descritores t na imagem. Além disso, idf ("frequência inversa do documento") é a frequência inversa da imagem com um determinado descritor na amostra e é definida como
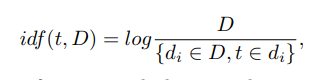
onde D é o número de imagens com um descritor especificado na amostra, {di D, t = di} é o número de imagens em D, onde t está em nt! = 0.
Etapa 5 Substituindo os pesos correspondentes em vez dos descritores na matriz A.
Etapa 6 Classificação. Utilizamos a amplificação de classificadores ingênuos de Bayes (adaboost).
Etapa 7 Salvando o modelo treinado em um arquivo.
Etapa 8 Isso conclui a fase de treinamento.
Fase de previsão . As diferenças entre a fase de treinamento e a fase de previsão são pequenas: os descritores são extraídos da imagem e correlacionados com os grupos existentes. Com base nessa proporção, um vetor é construído. Cada elemento desse vetor é a frequência de aparecimento dos descritores desse grupo na imagem. Ao analisar esse vetor, o classificador pode fazer uma previsão de ataque com uma certa probabilidade.
Um algoritmo de previsão geral baseado em um par de classificadores é apresentado abaixo.
Etapa 1 Extraia todos os descritores da imagem;
Etapa 2 Agrupar o conjunto resultante de descritores;
Etapa 3 Cálculo do vetor [1, k];
Etapa 4 Cálculo do peso para cada descritor de acordo com a fórmula tf idf apresentada acima;
Etapa 5 Substituir a frequência de ocorrência em vetores pelo seu peso;
Etapa 6 Classificação do vetor resultante de acordo com um classificador previamente treinado;
Etapa 7 Conclusão sobre a presença de anomalias na rede observada com base na previsão do classificador.
4. Avaliação da eficiência da detecçãoA tarefa de avaliar a eficácia do método proposto foi resolvida experimentalmente. No experimento, vários parâmetros estabelecidos experimentalmente foram utilizados. Para clustering, 1000 clusters foram utilizados. As imagens geradas tinham 1000 por 1000 pixels.
4.1 Conjunto de dados experimentaisPara experimentos, a instalação foi montada. É composto por três dispositivos conectados por um canal de comunicação. O diagrama de blocos de instalação é mostrado na Figura 2.
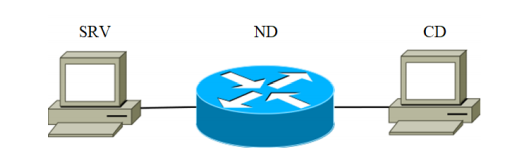
Fig. 1
O dispositivo SRV atua como o servidor atacante (a seguir denominado servidor de destino). Os dispositivos listados na Tabela 1 com o código SRV foram usados sequencialmente como o servidor de destino. O segundo é um dispositivo de rede projetado para transmitir pacotes de rede. As características do dispositivo são mostradas na Tabela 1, com o código ND-1.
Tabela 1. Especificações do dispositivo de rede
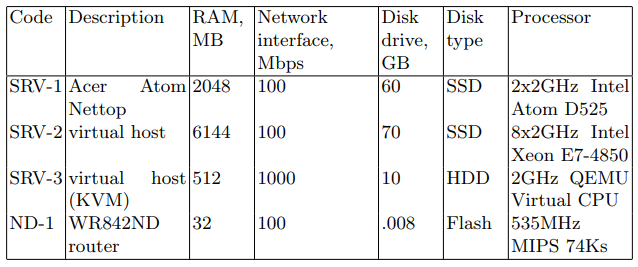
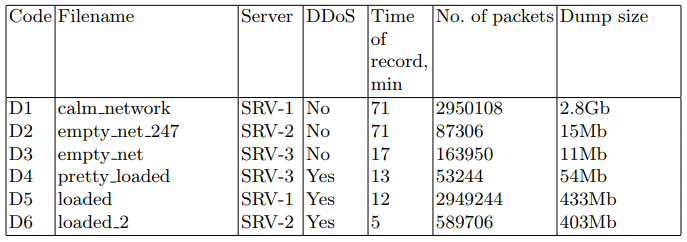
Nos servidores de destino, os pacotes de rede foram gravados em um arquivo PCAP para uso posterior em algoritmos de descoberta. O utilitário tcpdump foi usado para esta tarefa. Os conjuntos de dados são descritos na tabela 2.
Tabela 2. Conjuntos de pacotes de rede interceptados
O seguinte software foi utilizado nos servidores de destino: distribuição Linux, servidor web nginx 1.10.3, DBMS postgresql 9.6. Um aplicativo Web especial foi gravado para emular a inicialização do sistema. O aplicativo solicita um banco de dados com uma grande quantidade de dados. A solicitação foi projetada para minimizar o uso de vários caches. Durante os experimentos, foram gerados pedidos para este aplicativo da web.
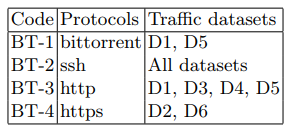
O ataque foi realizado no terceiro dispositivo cliente (tabela 1) usando o utilitário Apache Benchmark. A estrutura do tráfego em segundo plano durante o ataque e o restante do tempo é apresentada na Tabela 3.
Tabela 3. Funções de tráfego em segundo plano
Como ataque, implementamos a versão DoS distribuída da inundação HTTP GET. Tal ataque, de fato, é a geração de um fluxo constante de solicitações GET, neste caso a partir de um dispositivo CD-1. Para gerá-lo, usamos o utilitário ab do pacote apache-utils. Como resultado, foram recebidos arquivos contendo informações sobre o status da rede. As principais características desses arquivos são apresentadas na tabela 2. Os principais parâmetros do cenário de ataque são mostrados na tabela 4.
A partir do despejo de tráfego de rede recebido, foram obtidos conjuntos de imagens geradas TD # 1 e TD # 2, usadas na fase de treinamento. A amostra TD # 3 foi usada para a fase de previsão. Um resumo dos conjuntos de dados de teste é apresentado na tabela 5.
4.2 Critérios de desempenhoOs principais parâmetros avaliados durante este estudo foram:
Tabela 4. Recursos de um ataque DDoS

Tabela 5. Conjuntos de imagens de teste

a) DR (Taxa de detecção) - o número de ataques detectados em relação ao número total de ataques. Quanto maior esse parâmetro, maior a eficiência e a qualidade do ADS.
b) FPR (taxa de falsos positivos) - o número de objetos "normais", erroneamente classificados como um ataque, em relação ao número total de objetos "normais". Quanto menor esse parâmetro, maior a eficiência e a qualidade do sistema de detecção de anomalias.
c) CR (taxa complexa) é um indicador complexo que leva em consideração a combinação dos parâmetros DR e FPR. Como os parâmetros DR e FPR foram considerados de importância igual no estudo, o indicador complexo foi calculado da seguinte forma: CR = (DR + FPR) / 2.
1000 imagens marcadas como "anormais" foram enviadas ao classificador. Com base nos resultados do reconhecimento, a RD foi calculada dependendo do tamanho da amostra de treinamento. Os seguintes valores foram obtidos: para TD # 1 DR = 9,5% e para TD # 2 DR = 98,4%. Além disso, a segunda metade das imagens (“normal”) foi classificada. Com base no resultado, foi calculado o FPR (para TD # 1 FPR = 3,2% e para TD # 2 FPR = 4,3%). Assim, foram obtidos os seguintes indicadores abrangentes de desempenho: para TD # 1 CR = 53,15% e para TD # 2 CR = 97,05%.
5. Conclusões e pesquisas futurasA partir dos resultados experimentais, observa-se que o método proposto para detectar anomalias mostra altos resultados na detecção de ataques. Por exemplo, em uma amostra grande, o valor de um indicador de desempenho abrangente chega a 97%. No entanto, este método tem algumas limitações na aplicação:
1. Os valores de DR e FPR mostram a sensibilidade do algoritmo ao tamanho do conjunto de treinamento, que é um problema conceitual para algoritmos de aprendizado de máquina. Aumentar a amostra melhora o desempenho da detecção. No entanto, nem sempre é possível implementar um conjunto de treinamento suficientemente grande para uma rede específica.
2. O algoritmo desenvolvido é determinístico, a mesma imagem é classificada cada vez com o mesmo resultado.
3. Os indicadores de eficácia da abordagem são bons o suficiente para confirmar o conceito, mas o número de falsos positivos também é grande, o que pode levar a dificuldades na implementação prática.
Para superar a limitação descrita acima (ponto 3), supõe-se que o classificador bayesiano ingênuo mude para uma rede neural convolucional que, segundo os autores, deve aumentar a precisão do algoritmo de detecção de anomalias.
Referências1. Mohiuddin A., Abdun NM, Jiankun H.: Uma pesquisa de técnicas de detecção de anomalias de rede. In: Journal of Network and Computer Applications. Vol. 60, p. 21 (2016)
2. Afontsev E.: anomalias de rede, 2006
nag.ru/articles/reviews/15588 setevyie-anomalii.html
3. Berestov AA: Arquitetura de agentes inteligentes baseados em um sistema de produção para proteção contra ataques de vírus na Internet. In: XV Conferência da Rússia sobre problemas de segurança da informação no sistema de ensino superior ”, pp. 180? 276 (2008)
4. Galtsev AV: Análise do sistema de tráfego para identificar condições anômalas da rede: A tese do grau de candidato de ciências técnicas. Samara (2013)
5. Kornienko AA, Slyusarenko IM: Sistemas e Métodos de Detecção de Intrusão: Estado Atual e Direção da Melhoria, 2008
citforum.ru/security internet / ids overview /
6. Kussul N., Sokolov A.: Detecção adaptativa de anomalias no comportamento de usuários de sistemas de computador usando cadeias de Markov de ordem variável. Parte 2: Métodos de detecção de anomalias e os resultados das experiências. Em: Problemas de Informática e Controle. Edição 4, pp. 83-88 (2003)
7. Mirkes EM: Neurocomputador: rascunho do padrão. Science, Novosibirsk, pp. 150-176 (1999)
8. Tsvirko DA Previsão de uma rota de ataque à rede usando métodos de modelo de produção, 2012
academy.kaspersky.com/downloads/academycup participantes / cvirko d. ppt
9. Somayaji A.: Resposta automatizada usando atrasos nas chamadas do sistema. In: USENIX Security Symposium 2000, pp. 185-197, 2000
10. Ilgun K.: USTAT: Um sistema de detecção de intrusão em tempo real para UNIX. In: Simpósio IEEE sobre Pesquisa em Segurança e Privacidade, Universidade da Califórnia (1992)
11. Eskin E., Lee W. e Stolfo SJ: O sistema de modelagem exige detecção de intrusão com tamanhos de janelas dinâmicos. In: Conferência e Exposição de Sobrevivência da Informação da DARPA (DISCEX II), junho de 2001
12. Ye N., Xu M. e Emran SM: redes probabilísticas com links não direcionados para detecção de anomalias. In: Workshop IEEE de 2000 sobre Garantia e Segurança da Informação, West Point, NY (2000)
13. Michael CC e Ghosh A.: Duas abordagens baseadas no estado para detecção de anomalias baseadas em programas. In: Transações ACM sobre informações e segurança do sistema. Não. 5 (2), 2002
14. Garvey TD, Lunt TF: detecção de intrusão baseada em modelo. In: 14a Nation conference security security, Baltimore, MD (1991)
15. Theus M. e Schonlau M.: Detecção de intrusão com base em zeros estruturais. In: Boletim Estatístico de Computação e Gráficos. Não. 9 (1), pp. 12-17 (1998)
16. Tan K .: A aplicação de redes neurais à segurança de computadores unix. In: Conferência Internacional IEEE sobre Redes Neurais. Vol. 1, pp. 476-481, Perth, Austrália (1995)
17. Ilgun K., Kemmerer RA, Porras PA: Análise de Transição de Estado: Um Sistema de Detecção de Intrusão Baseado em Regras. Em: IEEE Trans. Eng. De software Vol. 21, n. 3 (1995)
18. Eskin E.: Detecção de anomalias em dados ruidosos usando distribuições de probabilidade aprendidas. In: 17th International Conf. sobre aprendizado de máquina, pp. 255-262. Morgan Kaufmann, São Francisco, CA (2000)
19. Ghosh K., Schwartzbard A. e Schatz M.: Aprendendo perfis de comportamento do programa para detecção de intrusão. In: 1º Workshop USENIX sobre detecção de intrusão e monitoramento de rede, pp. 51-62, Santa Clara, Califórnia (1999)
20. Ye N.: Um modelo de cadeia temporal de markov de comportamento temporal para detecção de anomalias. In: 2000 Workshop de Sistemas IEEE, Homem e Cibernética, Garantia de Informação e Segurança (2000)
21. Axelsson S.: A falácia da taxa básica e suas implicações para a dificuldade da detecção de intrusões. In: Conferência ACM sobre Segurança de Computadores e Comunicações, pp. 1-7 (1999)
22. Chikalov I, Moshkov M, Zielosko B. Otimização das regras de decisão com base em métodos de programação dinâmica. Em Vestnik, da Universidade Estadual Lobachevsky de Nizhni Novgorod, n. 6, pp. 195-200
23. Chen CH: Manual de reconhecimento de padrões e visão computacional. Universidade de Massachusetts Dartmouth, EUA (2015)
24. Gantmacher FR: Teoria das matrizes, p. 227. Ciência, Moscou (1968)
25. Murty MN, Devi VS: Reconhecimento de padrões: um algoritmo. Pp. 93-94 (2011)
Tradicionalmente, aguardamos seus comentários e convidamos todos para um
dia aberto , que será realizado na próxima segunda-feira.