O que fazer se você precisar trabalhar com dados que ainda não são grandes volumes de dados, mas já são mais do que o que cabe na memória do computador e para quais recursos do Excel são suficientes? Para os amantes de bicicleta, a resposta é óbvia - você precisa escrever algo próprio (sim, não estamos procurando maneiras fáceis).
Mas e se o código que você escreveu no passado for terrível e não lhe der a oportunidade de desenvolver o projeto? Separe os desenvolvimentos antigos, dê lugar a um novo, eterno e brilhante (sim, sim, e aqui também, sem opções).
 Citação da CF Matrix: “Um tablet é suficiente, Neo.” Diretor: Irmãos e irmãs Wachowski. 1999. EUA
Citação da CF Matrix: “Um tablet é suficiente, Neo.” Diretor: Irmãos e irmãs Wachowski. 1999. EUAHá mais de 10 anos, escrevi o código para o ASH Viewer (mais sobre o meu caminho
aqui ), publiquei primeiro no
sourceforge.net e depois no
github para que as pessoas se conectem e possam adicionar funcionalidades, corrija os erros. O projeto foi construído usando Gradle, resolvendo problemas com a exibição de gráficos: uma lista quase completa de melhorias
por referência .
No entanto, percebi que o código escrito há dez anos é, para dizer o mínimo, imperfeito. Externamente, tudo parecia bom, a funcionalidade foi desenvolvida, as pessoas ativamente usadas e agradeceram. Mas dentro do programa havia todos os erros da primeira experiência de codificação e, é claro, isso impediu muito o desenvolvimento do projeto.
Para todos que estavam prontos para começar a trabalhar seriamente no aplicativo (por exemplo,
dcvetkov ), eu disse que o código requer uma alteração completa. E com todas as tentativas de implementar qualquer funcionalidade ou corrigir bugs, fiquei convencido disso. Informo que a edição do código legado é uma tortura terrível, especialmente a minha :). Espero que, no futuro, os robôs aprendam a reescrever tudo eles mesmos, mas, por enquanto, foi tomada uma decisão obstinada para começar do zero, levando em conta a experiência já adquirida na criação de programas e na criação de código.
Desde seu primeiro lançamento, o ASH Viewer está ativo nessa área. Três projetos razoavelmente grandes baseados no
JfreeChart para análise de dados foram feitos. Além desses projetos, tentei diferentes abordagens, paradigmas e bibliotecas. Como resultado, decidi que tudo deveria ser escrito em Java puro, sem o uso de bibliotecas especialmente projetadas para criar uma interface gráfica do zero. Ainda assim, o uso de bibliotecas de terceiros para resolver algumas tarefas altamente especializadas é bastante aceitável - isso permitirá que você mantenha o nível necessário de flexibilidade e não exigirá um investimento significativo de tempo na correção de bugs e no desenvolvimento da funcionalidade necessária com suas próprias mãos.
Como tudo começou
Eu sempre fiquei preocupado, mas há um exemplo no domínio público que daria o básico de escrever corretamente aplicativos de média complexidade no Java Swing? Obviamente, eles me enviaram para a própria biblioteca ou para alguns exemplos simples de livros didáticos. E de certa forma eles estavam certos.
Mas pesquisei persistentemente o código do aplicativo que poderia ser usado como um exemplo de "como fazer direito" no Java Swing. E eu queria ter um sistema de trabalho diante dos meus olhos para que pudesse ser "sentido".
Ele começou a estudar o código-fonte dos aplicativos Java Swing (todos eles não podem ser contados). Em algum lugar, eles eram simples de fazer, em algum lugar muito complicado (para mim naquela época); em alguns, eles falhavam em qualidade e, às vezes, havia os dois. Eu li artigos sobre Habré, escrevi um código. Mas ainda faltava alguma coisa. Talvez naquela época eu estivesse adquirindo uma quantidade crítica de conhecimento para resolver esse problema.
Um dia, encontrei o
Angry IP Scanner dos respeitados
Antonkeks Antonkeks , olhei para ele e percebi imediatamente - aqui está ele! Java Swing, funcionalidade simples, código limpo, modularidade - prazer em ler! Em geral, usei as abordagens usadas ao escrever um dos meus projetos anteriores e depois ao reescrever o ASH Viewer.
Software e bibliotecas que ajudaram a melhorar a qualidade do código e simplificaram o trabalho
IDÉIA : Estou usando esse IDE para programação Java há cerca de cinco anos. Confirmo a opinião da maioria - este é um programa realmente útil e uma ferramenta muito conveniente para escrever código. Quando mudei para ele a partir do Eclipse
www.eclipse.org/ide (e a primeira versão foi escrita neste IDE), depois de um breve treinamento, percebi que o IDEA o guia e informa quando você tenta mudar para o lado obscuro :). Destacar repetições no código mantém você em boa forma e evita que você faça cópias e colagens estúpidas. Ave JetBrains!
Java 8 : expressões lambda que permitem escrever código mais curto, uma nova API do Time que permite cancelar o uso de uma biblioteca Joda Time de terceiros.
Adaga 2 : Estrutura de injeção de dependência que nunca usei antes. Mas, de alguma forma, espiei como essa biblioteca é usada por Anton
antonkeks e comecei a fazê-lo de acordo com o modelo. Divida o programa em módulos, sempre que possível, use injeção de dependência. Onde isso
não era
possível , ele usou a criação de objetos de shell com antecedência e, em seguida, definiu os atributos necessários ou simplesmente não usou o DI.
Sistema de compilação
Maven . Esse é o sistema de compilação que é o padrão de fato, então decidi fazer a adição de bibliotecas de maneira limpa através do pom.xml e usar o sistema de módulos Maven para trabalhar com o código JFreeChart e Gantt em um projeto.
Lombok : também uma biblioteca incrivelmente conveniente, para não escrever ou apoiar os "passos" do código uniforme (getters, setters, etc.). É verdade que em alguns casos eu me recusei a usá-lo, pois era necessário redefinir iguais e compararTo, mas não encontrei como fazer isso rapidamente no Lombok.
Registro no diário: criando o programa Java perfeito? Portanto, sem meios modernos de registro no diário, em lugar nenhum. Portanto, tomamos o
Simple Logging Facade para Java SLF4J e
Logback como base .
Gerente de layout: Eu uso principalmente o
Miglayout . É muito difícil aprender (em alguns lugares eu uso os gerenciadores de layout Swing à moda antiga), mas é curto. Permite que você faça
efeitos interessantes como na guia Detalhes.
Swingx by Swinglabs: a interface do usuário Java Swing abandonada há muito tempo. Estou ativamente usando o JXTable. A seleção arbitrária de colunas da tabela e uma pesquisa interna do conteúdo das células facilitam uma análise detalhada dos dados do histórico das sessões ativas.
ommons-dbcp2 : útil para criar um conjunto de conexões para conexões com o banco de dados. Na versão antiga, usei uma implementação modificada que encontrei na Internet.
Bibliotecas que passaram da versão antiga
Oracle Berkeley DB Java Edition v. 5.0.73: armazenamento de valor-chave incorporado. Para armazenar dados de histórico agregados de sessões ativas.
JFreeChart : milhares de projetos de análise de dados escritos usando esta biblioteca. Peguei a versão experimental, publicada no github, e a adicionei como um módulo. Isso foi feito para facilitar o trabalho com o código, pois eram
necessárias alterações para que o Gráfico Empilhado exibisse o gráfico conforme necessário.
E-Gantt : uma biblioteca para criar gráficos de Gantt no Java Swing. Vestígios dele agora não podem ser encontrados nem na Internet, infelizmente. Também colocado como um módulo Maven separado no projeto.
Do interessante no código, no que você pode prestar atenção
Alterações arquitetônicas:- Agora as configurações são armazenadas em um banco de dados interno separado, não em arquivos de texto sem formatação. Como não há muitos dados, um padrão avançado de EAV é usado para armazenar as configurações de conexão;
- Para armazenar os dados de monitoramento, decidi criar uma aparência de um mecanismo OLAP. Primeiro, para acelerar a exibição do detalhamento de Gantt por SQL_ID / SESSION_ID no intervalo selecionado. Em segundo lugar, pela possibilidade de obter uma pesquisa rápida em SQL_ID / SESSION_ID em gráficos empilhados e Gantt. Em terceiro lugar, a formação da visualização futura do histórico das sessões ativas (top de expectativas, drill de expectativas, drill de SQL_ID / SESSION_ID). Tudo é armazenado em uma entidade (dados por um segundo, 15 segundos e, no futuro, para outros intervalos estendidos são fisicamente separados);
- Um efeito colateral da arquitetura limpa é a capacidade de oferecer suporte ao monitoramento do histórico de sessões ativas de outros bancos de dados. Suporte ao Postgres atualmente implementado. Para conectar outros bancos de dados, você precisa de uma interface pronta para os dados do histórico de sessões ativas (que foram adicionadas ao Postgres ou tal implementação ) ou de uma coleção auto-configurada do histórico de sessões ativas em uma tabela separada, que pode ser acessada posteriormente.
Como habilitar o suporte para outro banco de dados- Crie uma nova classe e implemente a interface IProfile. Faça o mesmo que no caso do Postgres;
- Adicione a implementação da nova versão do banco de dados ao procedimento loadProfile da classe ConnectToDbArea e enum Function da classe ConstantManager ;
- Conecte e verifique o aplicativo.
GUI
Formulário de conexão com o banco de dadosCompletamente reescrito do zero, anteriormente usava as melhores práticas do projeto
Squirrel-sql aberto. Agora tudo está em
um arquivo. Beleza!
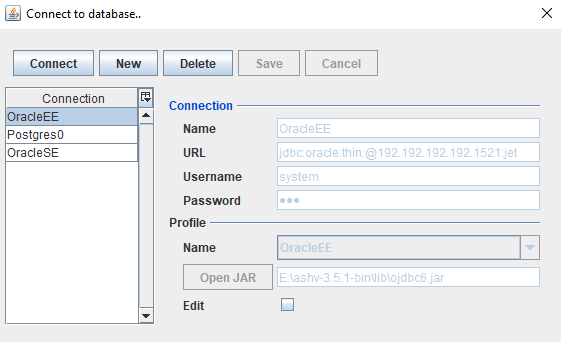
Como se conectar ao banco de dados- Crie uma nova conexão;
- Especifique o nome, a URL (JDBC é padrão para Oracle: jdbc: oracle: thin: @host: port: SID, para Postgres: jdbc: postgresql: // host: port: database), nome de usuário / senha, perfil e selecione a biblioteca jdbc;
- Para Oracle, tudo funciona com ojdbc6.jar; para PostgresDB, trabalho com postgresql-42.2.5 é verificado
Atividade principal / interface de detalhesAqui, sem alterações significativas, semelhante à versão antiga, apenas sem visualizar a história.
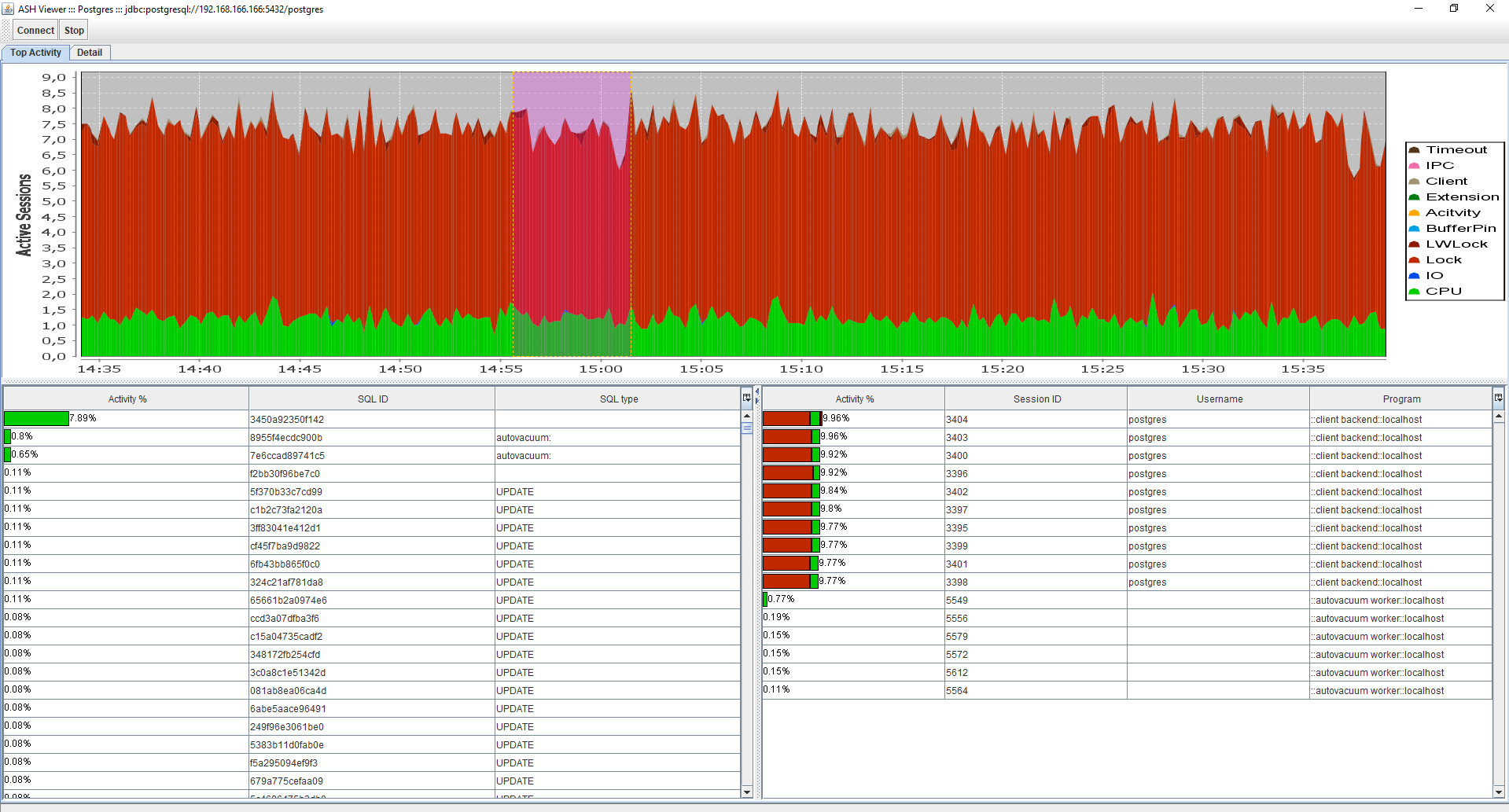 Detalhar por SQL_ID / SESSION_IDSQL
Detalhar por SQL_ID / SESSION_IDSQL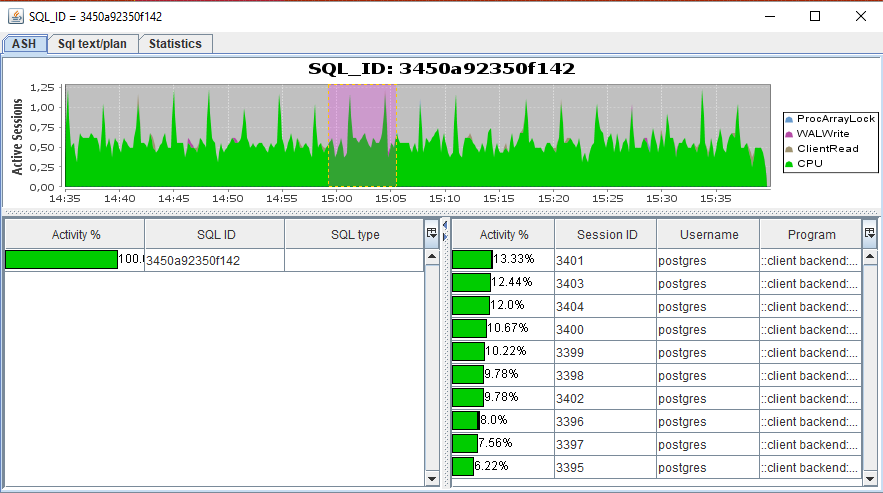 ASH
ASH : gráfico de atividade para um SQL_ID específico, chamado clicando duas vezes na linha com SQL_ID no gráfico de Gantt.
Sql text / plan : para Oracle / Postgres, é possível obter o texto completo da solicitação. Somente para Oracle são fornecidos planos de execução de consulta para todos os plan_hash_value.
Estatísticas : dados da tabela por SQL_ID: busque em V $ SQL. O código tem a capacidade de adicionar mais entidades para as quais você pode fazer uma seleção (consulte
implementação ). mas você precisa ter muito cuidado, pois pode haver problemas de desempenho: por exemplo, buscar do
V $ SQLAREA em sistemas carregados é muito lento).
Sessão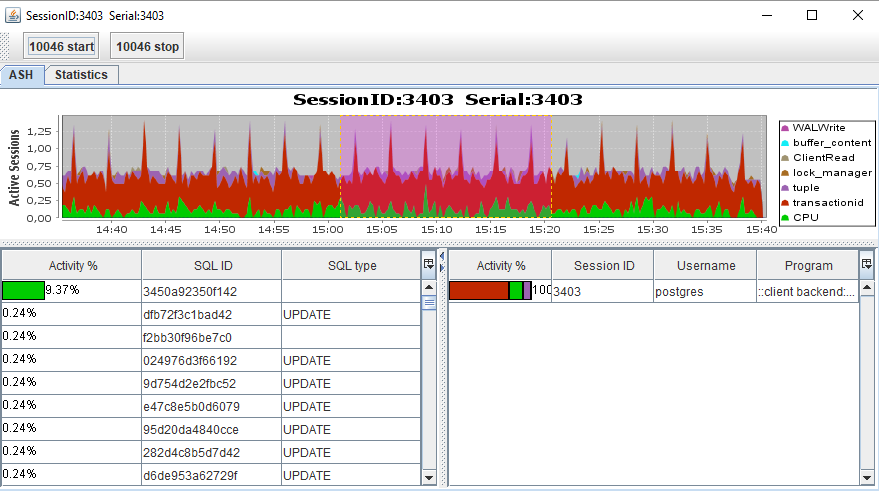 ASH
ASH : gráfico de atividade para session_id, semelhante ao SQL, clique duas vezes na linha da sessão no gráfico de Gantt.
Estatísticas : dados da tabela por SQL_ID: busca de V $ SESSION e V $ PROCESS. O código tem a capacidade de adicionar mais entidades para as quais você pode fazer uma seleção (consulte
implementação ).
Planos adicionais
- Instale a API. Realize a refatoração final do código. Implementar armazenamento dinâmico dos dados iniciais de monitoramento, o que não dependeria das versões e tipos do banco de dados;
- Realmente não há testes suficientes para testar os principais módulos do sistema, IC e outras práticas recomendadas.
Código de projeto Github,
arquivos de projeto;
Link para o grupo no Telegram
t.me/ashviewer para informar sobre as atualizações mais recentes;
PS Quem decide se conectar ao desenvolvimento - escreva para o PM, sem entusiasmo excessivo e sem criar uma queda, é claro :).
Só isso. Obrigado pela atenção!