
Quando os orquestradores de contêineres como o Kubernetes chegaram, a abordagem para desenvolver e implantar aplicativos mudou drasticamente. Apareceram microsserviços e, para o desenvolvedor, a lógica do aplicativo não está mais conectada à infraestrutura: crie aplicativos para você e ofereça novas funções.
O Kubernetes abstrai dos computadores físicos que controla. Diga a ele quanta memória e capacidade de processamento você precisa - e você obterá tudo. Infraestrutura? Não, não ouvi.
Gerenciar imagens do Docker, Kubernetes e aplicativos o torna portátil. Tendo desenvolvido aplicativos de contêiner com o Kubernetes, você pode implantá-los em qualquer lugar: em uma nuvem aberta, localmente ou em um ambiente híbrido - sem alterar o código.
Adoramos o Kubernetes por escalabilidade, portabilidade e capacidade de gerenciamento, mas ele não armazena o estado. Mas temos quase todos os aplicativos com estado, ou seja, eles precisam de armazenamento externo.
Kubernetes tem uma arquitetura muito dinâmica. Os contêineres são criados e destruídos, dependendo da carga e das instruções dos desenvolvedores. Vagens e recipientes são auto-reparáveis e replicáveis. Eles são essencialmente efêmeros.
O armazenamento externo é muito difícil para essa variabilidade. Não obedece às regras da criação e destruição dinâmicas.
Só é necessário implantar um aplicativo com estado em outra infraestrutura: em outra nuvem, local ou em um modelo híbrido - como ele tem problemas de portabilidade. O armazenamento externo pode ser vinculado a uma nuvem específica.
Mas somente nesses depósitos de aplicativos em nuvem o próprio diabo quebrará a perna. E vá entender os significados fictícios e os significados da terminologia de armazenamento no Kubernetes . E existem repositórios próprios da Kubernetes, plataformas de código aberto, serviços gerenciados ou pagos ...
Aqui estão alguns exemplos de armazenamento em nuvem CNCF :

Parece que implantou o banco de dados no Kubernetes - você só precisa selecionar a solução apropriada, empacotá-lo em um contêiner para trabalhar no disco local e implantá-lo no cluster como a próxima carga de trabalho. Mas o banco de dados tem suas próprias peculiaridades, portanto, pensar não é um gelo.
Contêineres - eles são tão pavimentados que não preservam seu estado. Por isso é tão fácil começar e parar. E como não há nada para salvar e transferir, o cluster não se preocupa com as operações de leitura e cópia.
Você precisará armazenar o estado no banco de dados. Se um banco de dados implantado em um cluster em um contêiner não migra para lugar nenhum e não inicia com muita frequência, a física do armazenamento de dados entra em jogo. Idealmente, os contêineres que usam dados devem estar no mesmo ambiente que o banco de dados.
Em alguns casos, o banco de dados, é claro, pode ser implantado em um contêiner. Em um ambiente de teste ou em tarefas em que há poucos dados, os bancos de dados vivem confortavelmente em clusters.
A produção geralmente requer armazenamento externo.
O Kubernetes se comunica com o repositório através de interfaces do plano de controle. Eles vinculam o Kubernetes ao armazenamento externo. O armazenamento externo anexado ao Kubernetes é chamado de plugins de volume. Com eles, você pode abstrair o armazenamento e transferir o armazenamento.
Os plug-ins de volume costumavam ser criados , vinculados, compilados e entregues usando a base de código do Kubernetes. Isso limitou muito os desenvolvedores e exigiu manutenção adicional: se você deseja adicionar novos repositórios, altere a base de código do Kubernetes.
Agora implante plugins de volume no cluster - não quero. E você não precisa se aprofundar na base de código. Agradecimentos a CSI e Flexvolume.
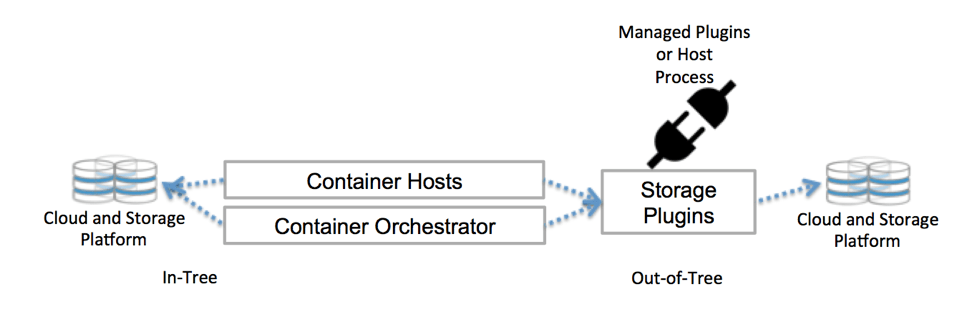
Armazenamento nativo do Kubernetes
Como o Kubernetes resolve problemas de armazenamento? Existem várias soluções: opções efêmeras, armazenamento persistente em volumes persistentes, consultas de Reivindicação de Volume Persistente, classes de armazenamento ou StatefulSets. Vá descobrir isso, em geral.
Volumes Persistentes (PV) são unidades de armazenamento preparadas pelo administrador. Eles não dependem de lares e de suas vidas fugazes.
Reivindicação de volume persistente (PVC) são solicitações de armazenamento, ou seja, PV. Com o PVC, você pode vincular o armazenamento a um nó, e este nó o utilizará.
Você pode trabalhar com armazenamento estaticamente ou dinamicamente.
Com uma abordagem estática, o administrador prepara PVs que devem ser veiculados antes, antes de solicitações, e esses PVs são vinculados manualmente a pods específicos usando PVCs explícitos.
Na prática, PVs especialmente definidos não são compatíveis com a estrutura portátil do Kubernetes - o armazenamento depende do ambiente, como o AWS EBS ou uma unidade permanente GCE. Para ligar manualmente, você precisa apontar para um repositório específico no arquivo YAML.
A abordagem estática geralmente contradiz a filosofia do Kubernetes: CPUs e memória não são alocadas antecipadamente e não estão vinculadas a pods ou contêineres. Eles são emitidos dinamicamente.
Para provisionamento dinâmico, usamos classes de armazenamento. O administrador do cluster não precisa criar o PV antecipadamente. Ele cria vários perfis de armazenamento, como modelos. Quando um desenvolvedor faz uma solicitação de PVC, no momento da solicitação, um desses padrões é criado e anexado à lareira.

Portanto, nos termos mais gerais, o Kubernetes trabalha com armazenamento externo. Existem muitas outras opções.
CSI - Interface de armazenamento de contêineres
Existe uma coisa - Interface de Armazenamento de Contêiner . O CSI foi criado pelo grupo de trabalho do cofre do CNCF, que decidiu definir uma interface de armazenamento de contêiner padrão para que os drivers do cofre trabalhassem com qualquer orquestra.
As especificações da CSI já estão adaptadas para o Kubernetes e existem vários plugins de driver para implantações no cluster Kubernetes. Você deve acessar o repositório através de um driver de volume compatível com CSI - use o tipo de volume csi no Kubernetes.
Com o CSI, o armazenamento pode ser considerado outra carga de trabalho para conteinerização e implantação no cluster Kubernetes.
Para mais detalhes, ouça Jie Yu falar sobre CSI em nosso podcast .
Projetos de código aberto
As ferramentas e os projetos das tecnologias em nuvem se multiplicam rapidamente, e uma boa parte dos projetos de código aberto - o que é lógico - resolve um dos principais problemas de produção: trabalhar com armazenamento na arquitetura em nuvem.
Os mais populares deles são Ceph e Rook.
O Ceph é um cluster de armazenamento distribuído gerenciado dinamicamente com escala horizontal. O Ceph fornece uma abstração lógica para recursos de armazenamento. Não possui um único ponto de falha, gerencia a si próprio e trabalha com base em software. O Ceph fornece interfaces para armazenar blocos, objetos e arquivos simultaneamente para um único cluster de armazenamento.
O Ceph possui uma arquitetura muito complexa com os algoritmos RADOS, librados, RADOSGW, RDB, CRUSH e vários componentes (monitores, OSD, MDS). Não vamos nos aprofundar na arquitetura, basta entender que o Ceph é um cluster de armazenamento distribuído que simplifica a escalabilidade, elimina um único ponto de falha sem sacrificar o desempenho e fornece um único armazenamento com acesso a objetos, blocos e arquivos.
Naturalmente, o Ceph é adaptado para a nuvem. Você pode implantar um cluster Ceph de maneiras diferentes, por exemplo, usando Ansible ou em um cluster Kubernetes por meio de CSI e PVC.
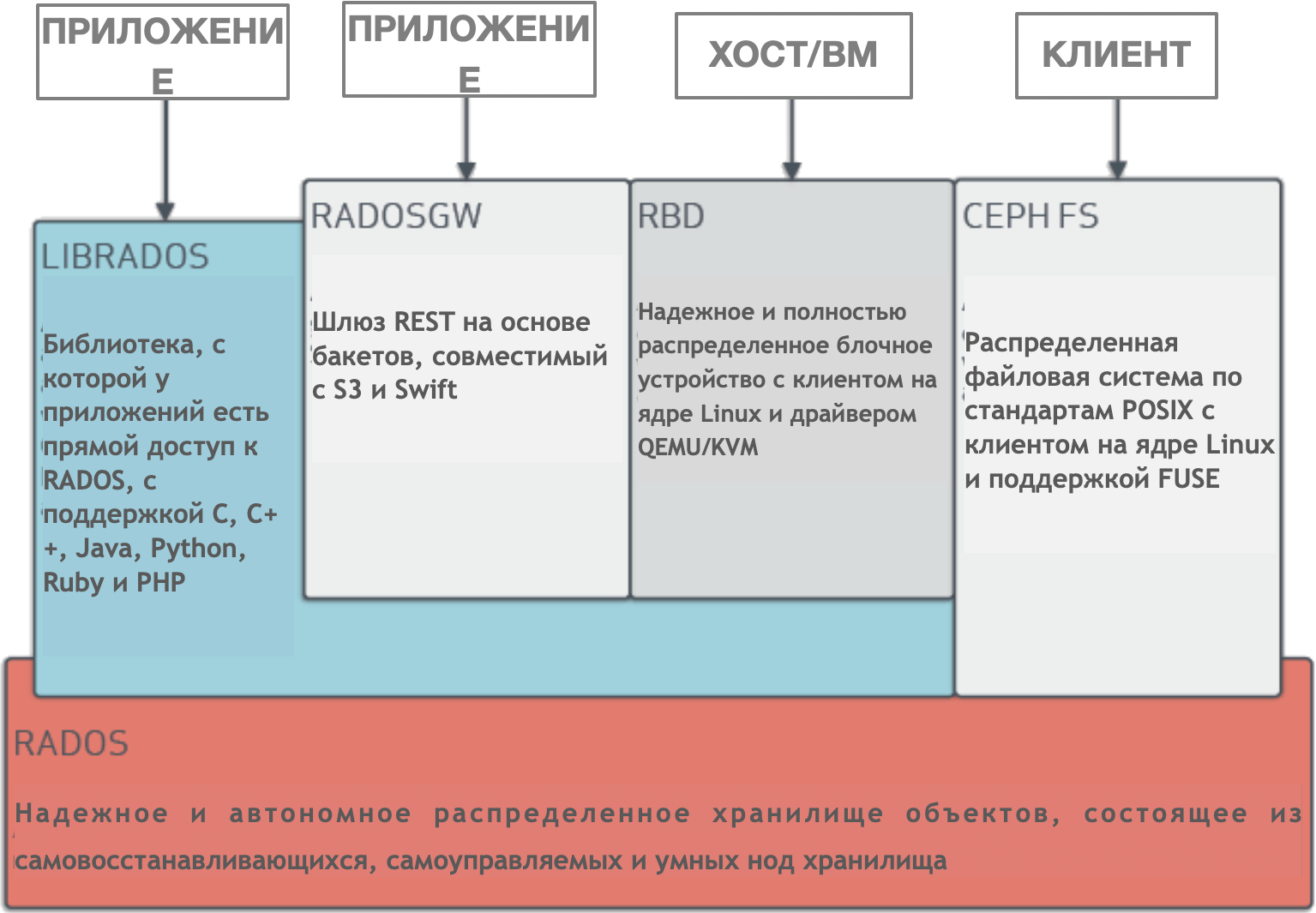
Arquitetura Ceph
Rook é outro projeto interessante e popular. Ele combina o Kubernetes com sua computação e o Ceph com seus repositórios em um cluster.
Rook é um orquestrador de armazenamento em nuvem que complementa o Kubernetes. Eles empacotam o Ceph em contêineres e usam a lógica de gerenciamento de cluster para uma operação confiável do Ceph no Kubernetes. O Rook automatiza a implantação, autoinicialização, ajuste, dimensionamento, reequilíbrio - em geral, tudo o que o administrador do cluster faz.
Com o Rook, um cluster Ceph pode ser implantado no yaml, como o Kubernetes. Neste arquivo, o administrador descreve o que ele precisa no cluster. Rook inicia um cluster e começa a monitorar ativamente. Isso é algo como um operador ou controlador - garante que todos os requisitos do yaml sejam atendidos. Rook funciona com ciclos de sincronização - ele vê o estado e executa uma ação se houver desvios.
Ele não tem seu estado permanente e não precisa ser controlado. Está no espírito de Kubernetes.
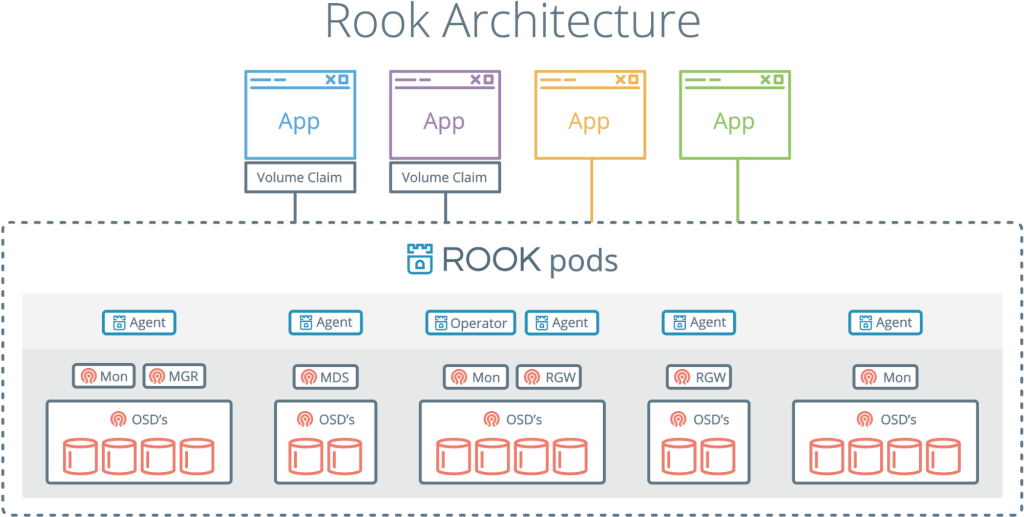
Rook, combinando Ceph e Kubernetes, é uma das soluções de armazenamento em nuvem mais populares: 4.000 estrelas no Github, 16,3 milhões de downloads e mais de cem colaboradores.
O projeto Rook já foi aceito no CNCF e , recentemente, acabou em uma incubadora .
Bassam Tabara lhe dirá mais sobre Rook em nosso episódio do repositório Kubernetes .
Se o aplicativo tiver um problema, você precisará descobrir os requisitos e criar um sistema ou usar as ferramentas necessárias. Isso também se aplica ao armazenamento em nuvem. E embora o problema não seja dos simples, as ferramentas e abordagens ficaram aquém. A tecnologia em nuvem continua a evoluir e novas soluções certamente nos aguardam.